
AgentAegis 智能体安全防御包括: skill投毒、记忆污染、意图对齐、恶意执行、资源耗尽
AgentAegis为OpenClaw类智能体构建了一套多维度的智能体安全纵深防御架构,实现从大模型智能体在各种Claw从初始化到执行的全生命周期五层安全防御,覆盖智能体执行服务中的安全性和可靠性风险,包括skill投毒、记忆污染、意图对齐、恶意执行、资源耗尽等。作为内置的轻量化安全插件,AgentAegis可以在OpenClaw的关键阶段主动发起防御机制,动态保障智能体运行时的安全。此外,AgentAegis还面向安全运营人员提供风险识别与处置策略可配置能力,以灵活、可拓展地应对智能体运行时安全威胁;面向普通用户提供敏感文件及Skill资产保护能力,以保障个人隐私和资产安全。
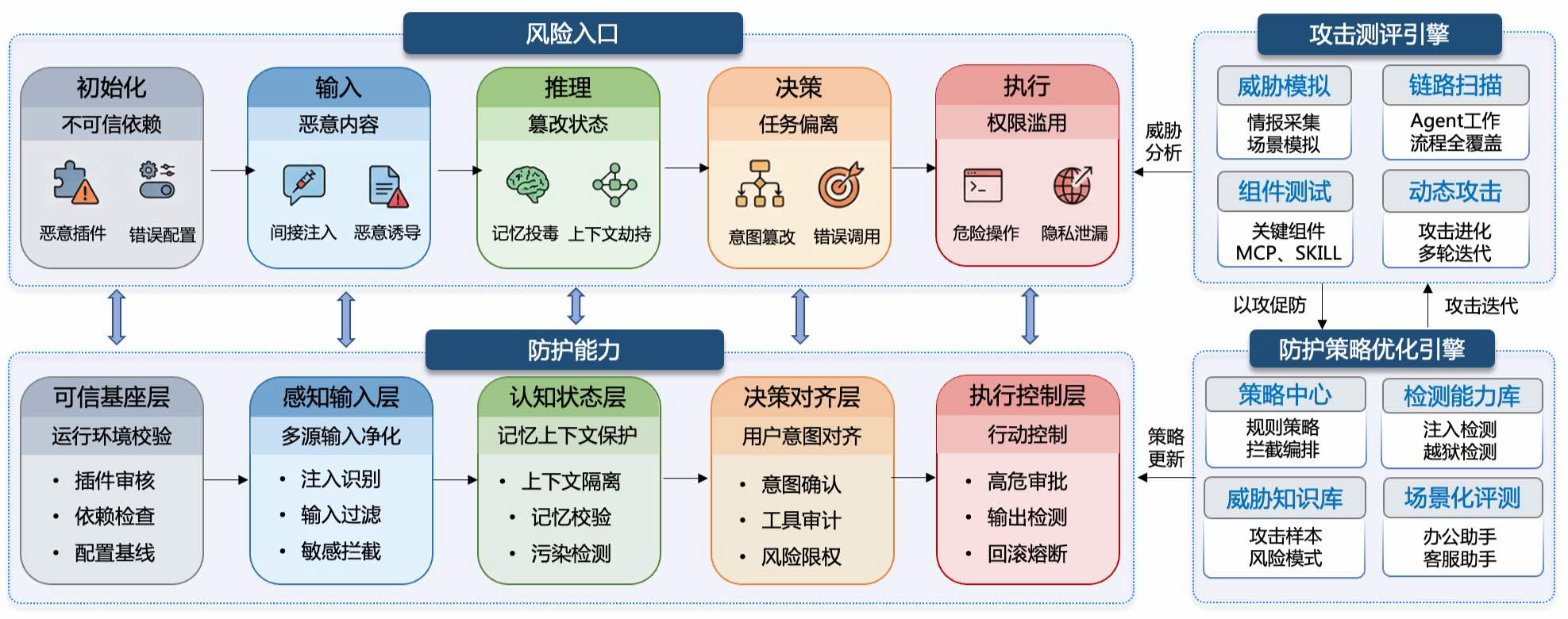
AgentAegis 为 OpenClaw 构建了一套多维度的纵深防御架构,实现从初始化到执行终端的全生命周期安全闭环。该体系由以下五个核心防护层组成:
- 可信基座层防御 — 确保底层环境的可信度,从初始化阶段夯实系统安全根基。
- 感知输入层防御 — 对内部和外部指令进行严格过滤与审核,拦截恶意注入或高风险请求。
- 认知状态层防御 — 实时监控智能体的内部状态,防止记忆恶化上下文污染。
- 决策对齐层防御 — 在逻辑生成环节进行意图校验,确保输出决策与用户真实意图一致,模糊意图要求用户二次确认,消除意图偏离风险。
- 执行控制层防御 — 在最终操作前实施权限管理,确保所有指令都在安全边界内受控执行。
通过这种层层递进的机制,AgentAegis 确保了 OpenClaw 在每一个关键链路环节都具备细致的风险对冲能力,将潜在威胁消弭于无形。此外,作为内置的安全插件,不同于提示词、Skill类防御等被动防御机制,AgentAegis可以在OpenClaw的关键阶段主动发起防御机制,动态保障运行时的安全。
-----
运行时防御
AgentAegis 提供一组覆盖智能体全生命周期的内置运行时防御能力,无需额外配置即可自动检测和缓解威胁。
- 五层纵深防御 — 覆盖意图扫描、工具调用治理、工具结果审查、资产保护和输出安全,贯穿九个OpenClaw生命周期钩子。
- Skill投毒防御 — 启动时及运行期间持续扫描Skill内容,检测试图绕过审批、禁用安全控制或篡改受保护资产的恶意载荷。
- 记忆污染防护 — 拒绝对持久化记忆存储(
memory_store、MEMORY.md、SOUL.md、memory/)的可疑或超大写入,防止跨会话的持久化提示词投毒。 - 意图与提示词安全 — 检测用户消息中的越狱尝试、密钥窃取请求和插件篡改意图,并向提示词注入安全上下文以影响后续模型推理。
- 工具调用治理 — 在工具执行前拦截高危Shell命令、编码/混淆载荷、写后执行链、重复变异循环以及SSRF/数据泄露链。
- 工具结果审查 — 将外部工具输出视为不可信输入,扫描其中的提示词注入、密钥请求和权限提升模式,防止其影响下一步推理。
- 输出脱敏 — 在助手输出发送或存储前,遮蔽API密钥、令牌及类似敏感值。
进阶可配置防御
在内置运行时防御之上,AgentAegis 为安全运营人员和终端用户提供可配置的控制面,支持进阶风险管理和资产保护。
- 可配置安全运营 — 运营人员可通过
allDefensesEnabled全局启用所有防御,通过defaultBlockingMode设置全局基线,并可逐项覆盖selfProtectionMode、commandBlockMode、memoryGuardMode、exfiltrationGuardMode等独立控制。每项防御均支持enforce、observe和off三种模式,实现从监控到主动拦截的渐进式部署。运营人员还可定义protectedPaths、protectedSkills和protectedPlugins来匹配其环境中的关键资产,并通过startupSkillScan提前识别风险Skill。检测结果以运行时观测、拦截动作和提升的提示词告警形式呈现,为防御者提供可操作的分类与响应信号。 - 敏感文件与Skill资产保护 — 敏感文件和目录可添加到
protectedPaths,对未授权的读取、写入、删除和篡改进行拦截或观测。高价值Skill和重要插件可通过protectedSkills和protectedPlugins注册,防止Skill和插件资产被删除、覆盖或补丁式篡改。自保护机制降低智能体关闭自身防御或静默改写安全配置的风险。对个人用户而言,这意味着私人笔记、文档和自定义Skill得到更安全的处理;对组织而言,这意味着运维手册、审计插件和安全关键配置获得更强的保护。
https://github.com/antgroup/agent-aegis/blob/main/web/README.md
开发模式下 API 服务运行在 :3800,Vite 前端开发服务器运行在 :3801(自动代理 API 请求)。
项目结构
web/
├── shared/ # 前后端共享的类型定义、Zod 校验 schema、防御分组元数据
├── api/ # Express 后端服务
│ └── src/
│ ├── routes/ # API 路由(config、status、events、skills)
│ └── services/ # 业务逻辑(配置读写、状态读取、事件管理、文件监听)
└── frontend/ # React + Vite + TailwindCSS 前端
└── src/
├── api/ # API 客户端封装 + React Query hooks
├── pages/ # 页面组件(Dashboard、Config、Events、Skills)
└── components/ # UI 组件(布局、仪表盘、配置编辑器、通用控件)
功能页面
Dashboard(仪表盘)
- 防御状态统计卡片(Enforce / Observe / Off 数量)
- 12 项防御机制状态矩阵
- 插件自完整性状态
- Trusted Skills 计数
- 最近安全事件列表
Config(配置编辑器)
- Master Controls:全局防御开关 + 默认拦截模式(off / observe / enforce)
- Execution Guards:7 个执行层防御卡片,每个可独立开关并选择模式
- Scanning & Output:5 个扫描和输出相关防御开关
- Protected Assets:标签式编辑器,管理受保护的路径、Skill ID、Plugin ID
- Advanced:可折叠的高级选项(启动时 Skill 扫描等)
- 脏状态追踪,Save / Reset to Defaults 按钮
Events(安全事件日志)
- 支持按防御类型和结果(blocked / observed / clear)筛选
- 表格展示时间、防御名称、结果、工具名、拦截原因
- 自动每 10 秒刷新
Skills(Skill 扫描管理)
- Trusted Skills 列表(路径、哈希、大小、扫描时间)
- 手动移除 Trusted Skill(移除后下次扫描会重新评估)
---
https://github.com/antgroup/agent-aegis/blob/main/README_zh.md
AgentAegis为OpenClaw类智能体构建了一套多维度的智能体安全纵深防御架构,实现从大模型智能体在各种Claw从初始化到执行的全生命周期五层安全防御,覆盖智能体执行服务中的安全性和可靠性风险,包括skill投毒、记忆污染、意图对齐、恶意执行、资源耗尽等。作为内置的轻量化安全插件,AgentAegis可以在OpenClaw的关键阶段主动发起防御机制,动态保障智能体运行时的安全。此外,AgentAegis还面向安全运营人员提供风险识别与处置策略可配置能力,以灵活、可拓展地应对智能体运行时安全威胁;面向普通用户提供敏感文件及Skill资产保护能力,以保障个人隐私和资产安全。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 1
1 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)