
拆解OpenManus四大核心模块:Orchestrator、Agents、Memory、Tools全公开
Manus
Manus 是 2025 年 3 月上线的通用 AI Agent,出自蝴蝶效应团队,可自主完成市场研究、编码等任务。
Manus与国内的Coze、dify平台很相似,都是低代码、通用性AI Agent。大家想了解低代码平台的,可以看我之前写的文章 Coze:从入门到精通、Dify:从入门到精通。
使用Manus操作浏览器:
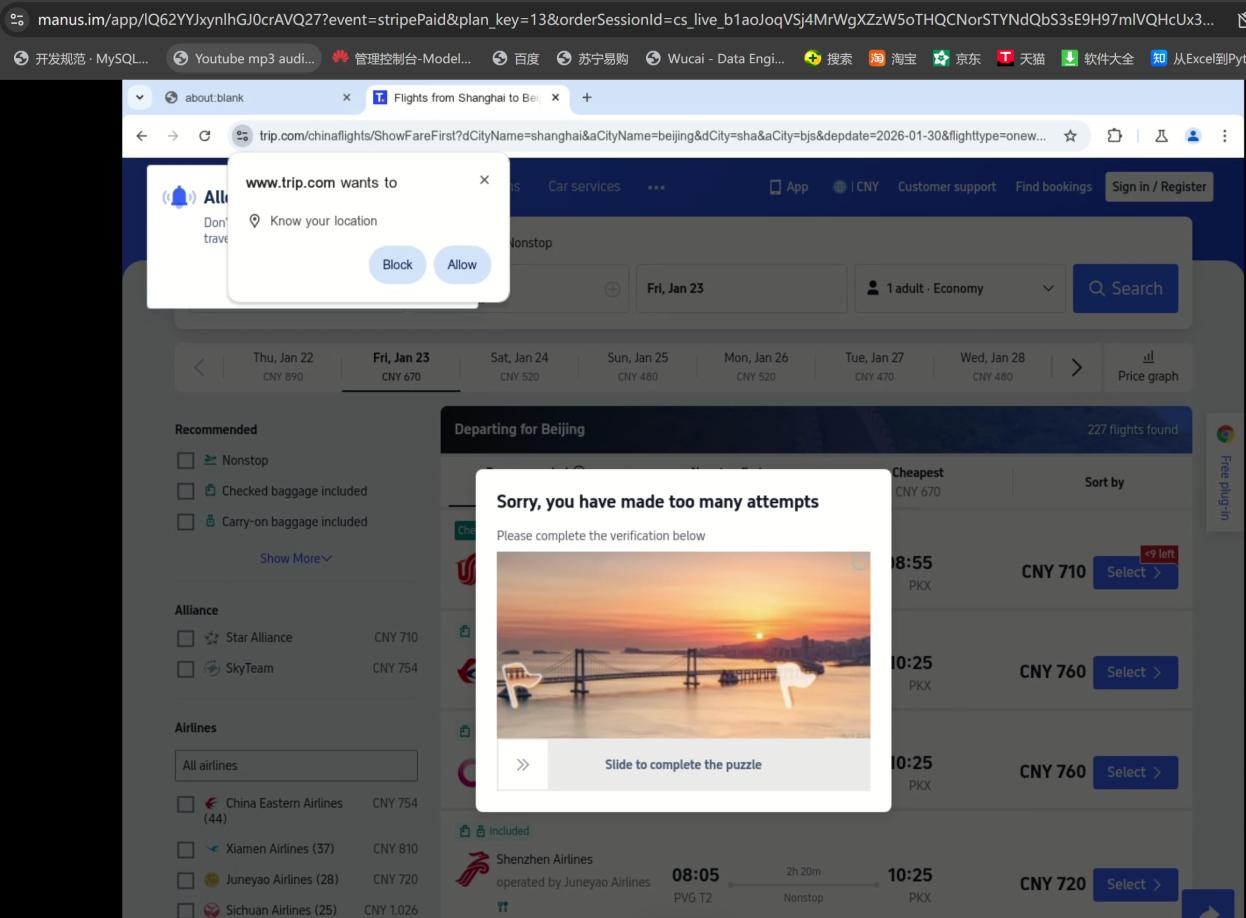
1)以查询机票为例,查询 1月30日 从上海到北京的机票;
2)理解 browser_use的流程;
3)如果不成功,有什么解决方法;

SandboxManus
SandboxManus 是在一个云端沙箱中运行的 Agent,与 Manus(本地 Agent)相比,提供了完全隔离的执行环境:
1. 沙箱环境管理
- 自动创建沙箱: 调用 SandboxManus.create() 时自动创建 Daytona 云端沙箱;
- 服务初始化: 自动启动 supervisord 和浏览器自动化服务(端口 8003);
- 资源清理: 任务完成后自动删除沙箱,释放资源;
2. 沙箱工具集
- SandboxBrowserTool: 在沙箱中运行浏览器,支持网页浏览、表单填写、内容提取;
- SandboxFilesTool: 操作沙箱文件系统,支持创建、编辑、删除文件;
- SandboxShellTool: 执行 Shell 命令,支持命令执行和会话管理;
- SandboxVisionTool: 视觉识别和分析工具;
3. VNC 远程访问
- 启动时会输出 VNC URL,可通过浏览器访问查看沙箱桌面;
- 实时观察浏览器操作和任务执行过程;
- 便于调试和监控;
源码:
沙箱Manus初始化流程:
Step1. 创建沙箱:调用 create_sandbox() 创建 Daytona 云端沙箱
Step2. 启动服务:启动 supervisord,等待浏览器自动化服务就绪(最多 60 秒)
Step3. 获取链接:生成 VNC URL 和 Website URL
Step4. 添加工具:将沙箱工具添加到可用工具列表
Step5. 连接 MCP:初始化 MCP 服务器连接(如果配置)
# 创建并初始化 SandboxManus
agent = await SandboxManus.create()
# 运行任务
await agent.run("你的任务提示词")
# 清理资源
await agent.cleanup()
沙箱的配置需要在 config.toml 中配置 Daytona API Key
Daytona
Daytona 的作用是安全沙盒执行器,负责把 AI 生成的代码放到一个隔离的容器里运行,防止恶意操作。
我们可以本地部署 Daytona-Github,也可以使用云端Daytona产品(云端产品是付费的)。
LLM 想跑代码 → OpenManus 把代码丢进 Daytona 容器 → Daytona 在封闭环境里执行 → 只把结果返回给 LLM,宿主机不受影响。
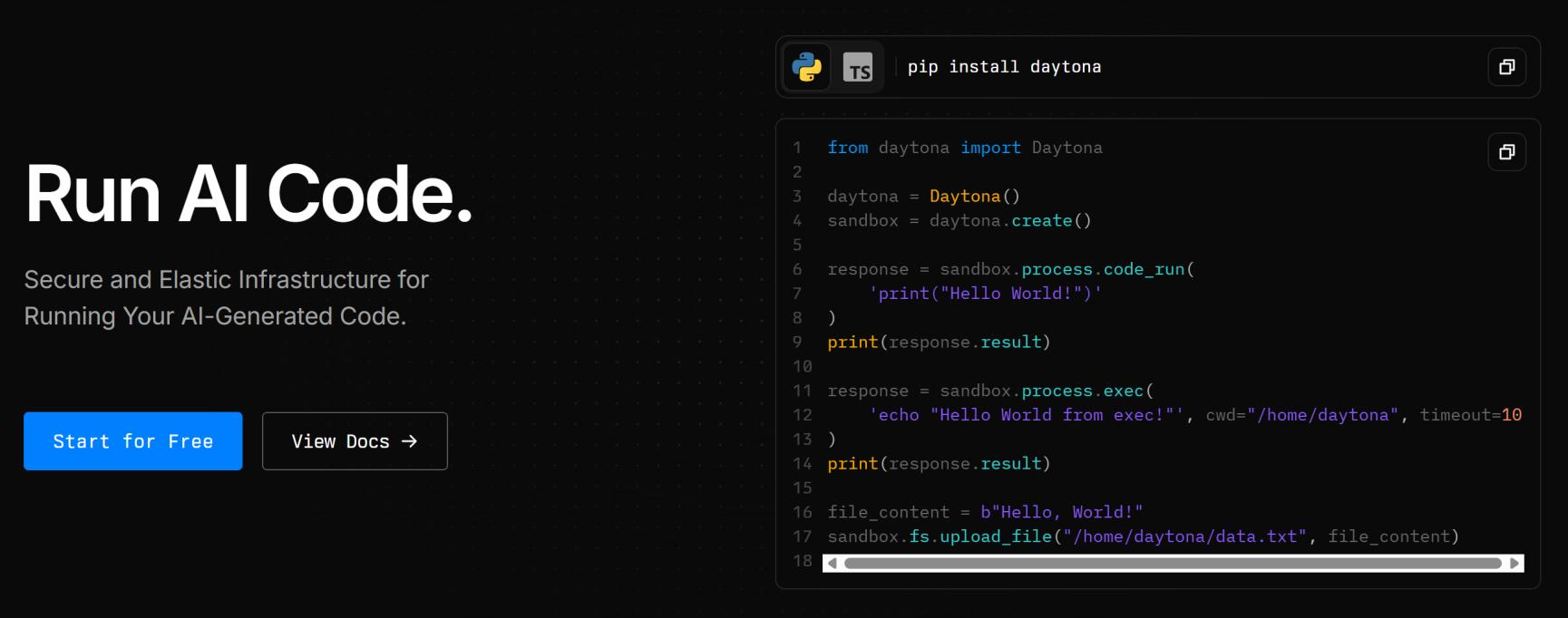
Daytona的使用
Step1,安装
pip install daytona
Step2,创建API KEY
https://app.daytona.io/ 网站内申请API KEY
Step3,创建Sandbox
from daytona import Daytona, DaytonaConfig
# Define the configuration
config = DaytonaConfig(api_key="dtn_XXX")
# Initialize the Daytona client
daytona = Daytona(config)
# Create the Sandbox instance
sandbox = daytona.create()
# Run the code securely inside the Sandbox
response = sandbox.process.code_run('print("Hello World from code!")')
if response.exit_code != 0:
print(f"Error: {response.exit_code} {response.result}")
else:
print(response.result)
云端展示:
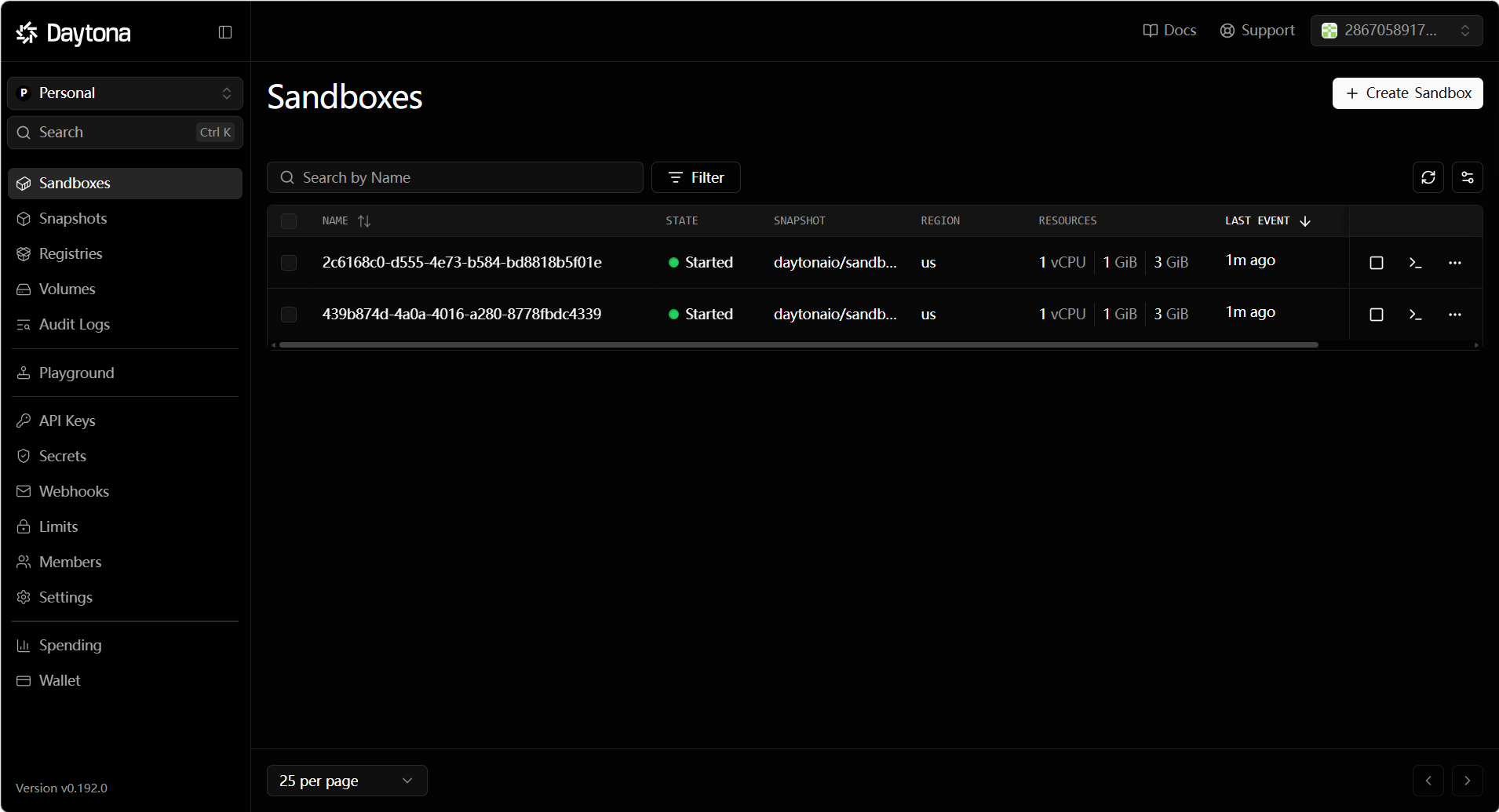
Daytona在OpenManus中使用:
1. 提供隔离的云端执行环境
- 远程沙箱容器: 基于 Docker 的隔离环境;
- 预配置环境: 包含浏览器、文件系统、Shell 等工具;
- VNC 远程访问: 可以实时查看浏览器操作过程;
- 自动资源管理: 自动停止和归档,节省资源;
VNC(Virtual Network Computing) 是一种远程桌面协议,允许你通过远程访问和控制另一台计算机的图形界面。
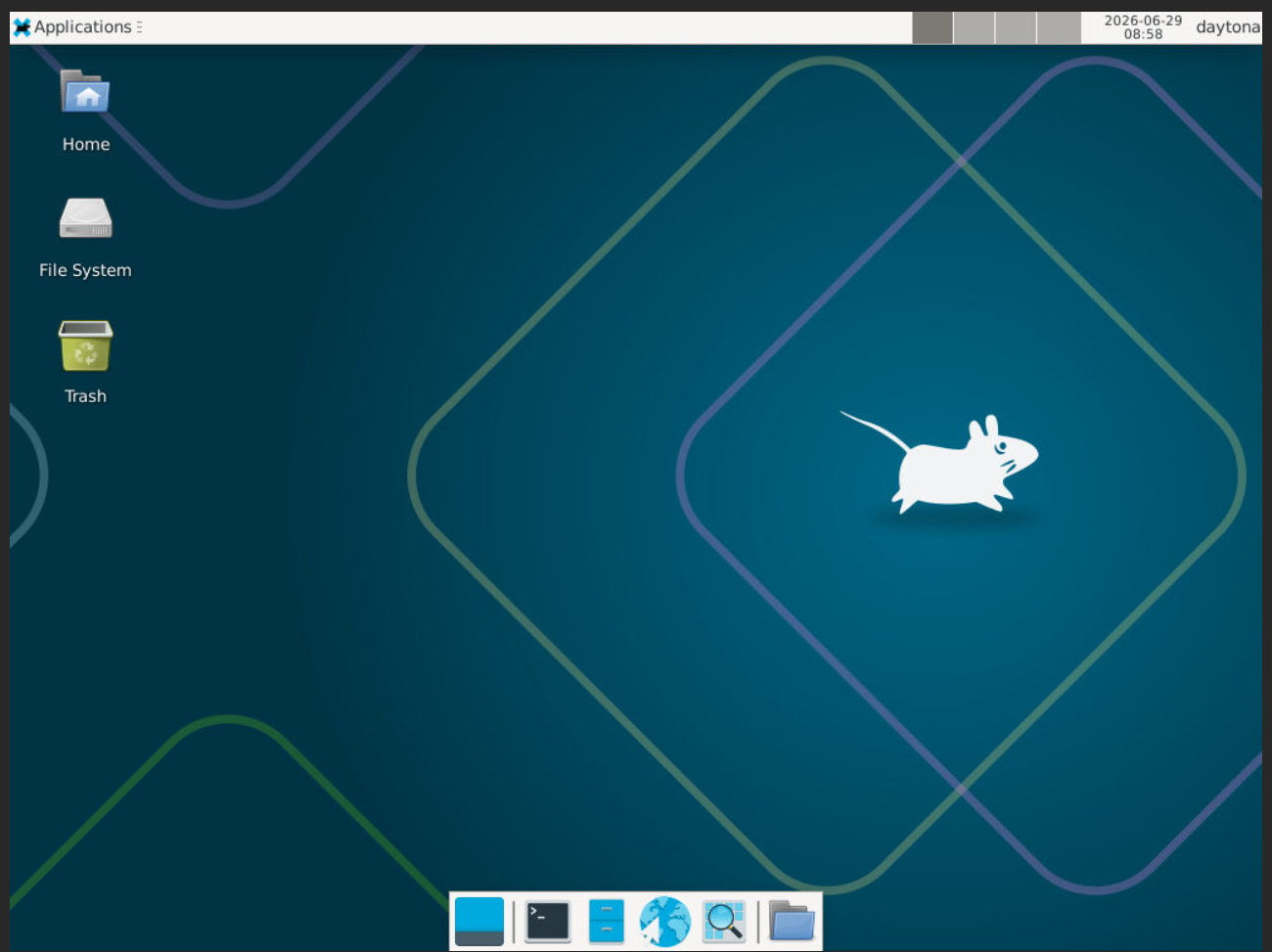
当使用 SandboxManus Agent 时,浏览器在远程云端沙箱中运行,而不是在你的本地电脑上。
app/daytona/
├── sandbox.py # Daytona 沙箱管理(创建、启动、删除)
├── tool_base.py # 沙箱工具基类(SandboxToolsBase)
└── README.md # 使用说明
app/tool/sandbox/
├── sb_browser_tool.py # 沙箱浏览器工具
├── sb_files_tool.py # 沙箱文件工具
├── sb_shell_tool.py # 沙箱 Shell 工具
└── sb_vision_tool.py # 沙箱视觉工具
app/agent/
└── sandbox_agent.py # SandboxManus Agent
2. 通过 Daytona 沙箱,Agent 可以使用以下专用工具:
SandboxBrowserTool (sb_browser_tool): 沙箱浏览器工具
- 在远程沙箱中运行浏览器;
- 支持浏览器自动化操作;
- 可通过 VNC 实时查看操作过程;
SandboxFilesTool (sb_files_tool): 沙箱文件操作工具
- 在沙箱中读写文件;
- 管理 /workspace 目录下的文件;
SandboxShellTool (sb_shell_tool): 沙箱 Shell 工具
- 在沙箱中执行 Shell 命令
- 支持命令行操作
SandboxVisionTool (sb_vision_tool): 沙箱视觉工具
- 在沙箱中进行视觉识别和分析
3. 专用 Agent:SandboxManus
SandboxManus 是一个专门使用沙箱工具的 Agent
Step1. 用户启动 SandboxManus Agent
Step2. Agent 初始化时调用 create_sandbox()
Step3. Daytona SDK 创建远程沙箱容器
Step4. 沙箱启动 supervisord 服务
Step5. Agent 获得 VNC URL 和 Website URL
Step6. Agent 使用沙箱工具执行任务
Step7. 用户可通过 VNC 实时查看浏览器操作
Step8. 任务完成后,沙箱自动停止或归档
# app/agent/sandbox_agent.py
class SandboxManus(ToolCallAgent):
"""使用沙箱工具的专用 Agent"""
available_tools = [
SandboxBrowserTool(), # 沙箱浏览器
SandboxFilesTool(), # 沙箱文件操作
SandboxShellTool(), # 沙箱 Shell
SandboxVisionTool(), # 沙箱视觉
AskHuman(),
Terminate(),
]
Supervisord 是一个用 Python 写的 进程管理工具,作用:24h 盯着子进程,挂了就重启.
OpenManus
OpenManus 是MetaGPT 团队 2025 年 7 月推出的开源通用 AI 智能体框架,定位无堡垒、纯开放,目的是零成本复刻闭源 Manus 的手脑并用能力。
简而言之,OpenManus是仿照Manus的开源项目。
OpenMans == Tool Call Agent!!!
Manus = LLM + Tool + RAG(影响到初始的prompt)
System Prompt + Tool Prompt + RAG Chunks = Prompt
开箱即用的多智能体协作平台——把自然语言需求直接变成可执行的工作流,支持浏览器自动化、Python 代码执行、文件处理、数据可视化等 12 类工具,且全部可插拔替换。
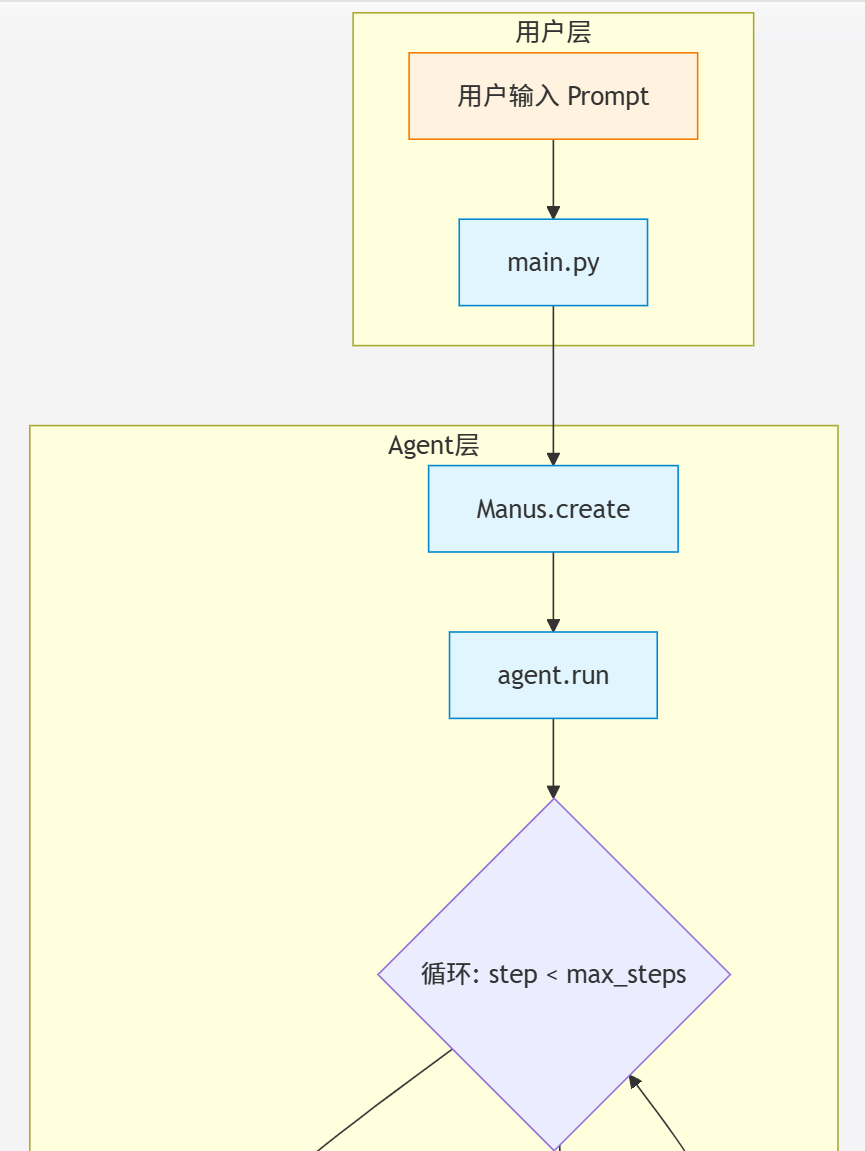
OpenManus核心结构(六层架构):
- 用户交互层: CLI、Web API、可视化界面三选一;
- 应用入口层: 单智能体(main.py)、多智能体协作(run_flow.py)、远程工具接入(run_mcp.py);
- 智能体层: BaseAgent → ReActAgent → ToolCallAgent → Manus 四级继承,逐级叠加推理-行动-工具调用 能力;
- 工具层: 统一 BaseTool 接口,内置了浏览器、搜索、代码执行、文件保存等工具,可通过 MCP 协议扩展外部服务;
- 流程控制层: PlanningFlow 自动把复杂任务拆成线性或 DAG 步骤,支持多智能体按角色分工(项目经理 → 产品经理 → 执行专员);
- 基础设施层: Docker 一键部署,高频的知识放到Redis 缓存,FAISS 向量长期记忆,LLM 适配器同时支持DeepSeek、Claude、Qwen 等 10+ 模型;
- 典型应用场景:
1)数据采集与可视化: 自然语言指令 → 自动写爬虫 → 清洗数据 → 生成可视化报告并导出 HTML/PPT;
2)电商运营: 输入“给三款新品写多平台文案”→ 市场分析、竞品价格抓取、本地化文案生成、合规检测全自动完成;
openmanus-ui:MetaGPT 团队 2025 年 7 月将 assets, static, templates 文件夹,以及 app.py 拷贝到当前 OpenManus项目中运行 python app.py。
使用流程
step1,在OpenManus文件夹内运行 python main.py
终端窗口:
step2,输入用户的query
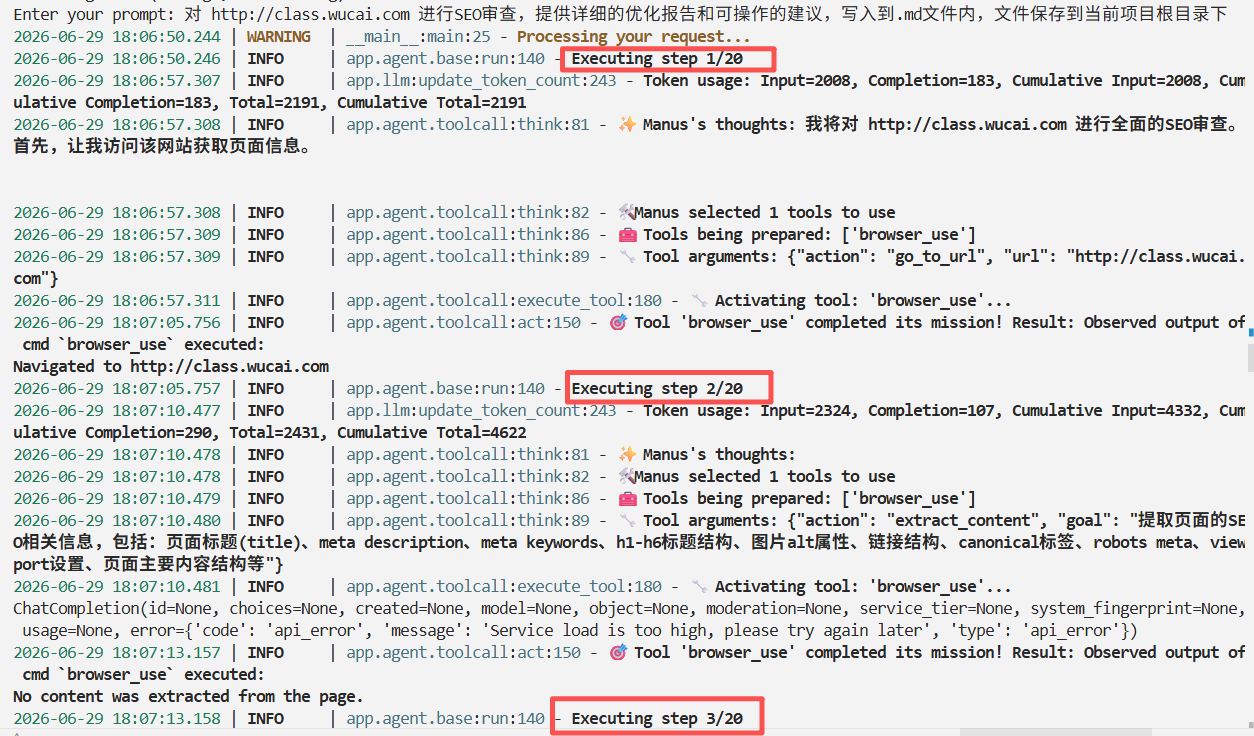
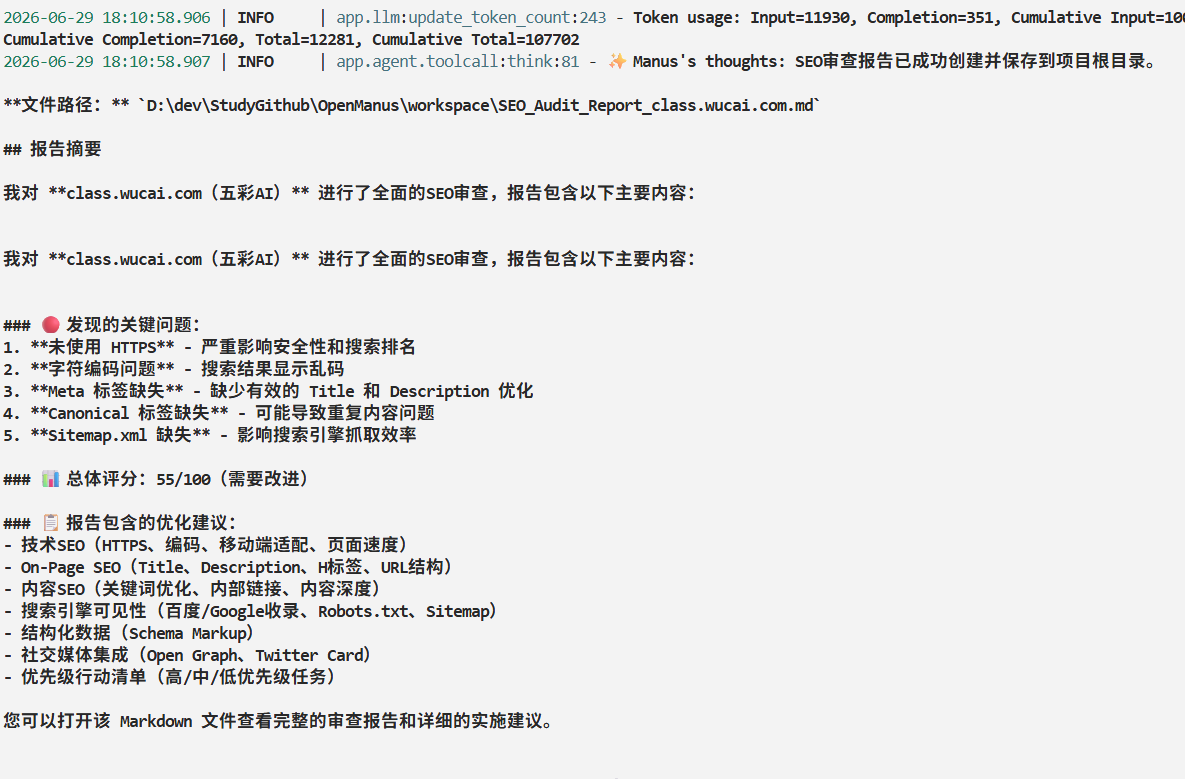
OpenManus代码
用户输入
↓
Agent.run(request) - 主循环
↓
循环执行 step() (最多 max_steps=20 次)
├─ think() - 思考阶段:LLM 决策使用哪些工具
└─ act() - 行动阶段:执行选定的工具
↓
工具执行结果 → 添加到内存 → 下一轮循环
初始化
Step1. 初始化阶段
执行步骤:
- 创建 Manus Agent 实例;
- 初始化可用工具:BrowserUseTool, WebSearch,PythonExecute, StrReplaceEditor, AskHuman, Terminate;
- 初始化 LLM(默认:qwen-max);
- 初始化内存(Memory)为空;
# main.py 或 app.py
agent = Manus(
name="Manus",
description="A versatile agent that can solve various
tasks using multiple tools"
)
result = await agent.run(prompt)
主循环
Step2.主循环执行 (BaseAgent.run())
关键参数:
- max_steps = 20: 最多执行 20 步;
- current_step: 当前步数(从 1 开始);
# app/agent/base.py:116-154
async def run(self, request: Optional[str] = None) -> str:
if request:
self.update_memory("user", request) # 添加用户请求到内存
while (self.current_step < self.max_steps and self.state !=
AgentState.FINISHED):
self.current_step += 1
step_result = await self.step() # 执行单步:think + act
results.append(f"Step {self.current_step}: {step_result}")
单步执行
Step3. 单步执行 (ReActAgent.step())
# app/agent/react.py:33-38
async def step(self) -> str:
should_act = await self.think() # 思考:决定下一步行动
if not should_act:
return "Thinking complete - no action needed"
return await self.act() # 行动:执行工具调用
思考阶段
Step4. 思考阶段 (ToolCallAgent.think())
1)Manus 的 think() 方法
关键逻辑:
- 如果浏览器工具可用,会调用browser_context_helper.format_next_step_prompt()获取浏览器状态;
- 浏览器状态包括:URL、标题、可交互元素列表(格式:
[index]<type>text</type>);
# app/agent/manus.py:144-221
async def think(self) -> bool:
# 1. 检查浏览器工具是否可用
if browser_tool_available:
# 2. 使用 browser_context_helper 格式化 prompt
self.next_step_prompt = await
self.browser_context_helper.format_next_step_prompt()
# 3. 调用父类的 think() 方法
result = await super().think()
return result
2)ToolCallAgent 的 think() 方法
# app/agent/toolcall.py:40-129
async def think(self) -> bool:
# 1. 构建消息列表(包含历史消息 + 当前 prompt)
if self.next_step_prompt:
user_msg = Message.user_message(self.next_step_prompt)
self.messages += [user_msg]
# 2. 调用 LLM,传入工具列表
response = await self.llm.ask_tool(
messages=self.messages,
system_msgs=[Message.system_message(self.system_prompt)],
tools=self.available_tools.to_params(), # 工具列表
tool_choice=self.tool_choices, # AUTO
)
# 3. 解析 LLM 响应
self.tool_calls = response.tool_calls # 工具调用列表
content = response.content # LLM 的思考内容
# 4. 记录日志
logger.info(f"
{self.name}'s thoughts: {content}")
logger.info(f"
{self.name} selected {len(tool_calls)} tools to use")
# 5. 将响应添加到内存
assistant_msg = Message.from_tool_calls(content=content,
tool_calls=self.tool_calls)
self.memory.add_message(assistant_msg)
return bool(self.tool_calls) # 返回是否有工具需要执行
LLM 输入:
- 系统提示: SYSTEM_PROMPT(来自 app/prompt/manus.py)
- 历史消息: 之前的对话和工具执行结果
- 当前 prompt: next_step_prompt(可能包含浏览器状态)
- 工具列表: 所有可用工具的描述(JSON Schema 格式)
LLM 输出:
- 思考内容: Agent 的推理过程(例如:“我需要先搜索比亚迪在欧洲市场的信息…”)
- 工具调用: 选定的工具和参数(例如:web_search(query=“比亚迪 欧洲市场”))
行动阶段
Step5.行动阶段 (ToolCallAgent.act()
# app/agent/toolcall.py:131-164
async def act(self) -> str:
if not self.tool_calls:
return "No content or commands to execute"
results = []
for command in self.tool_calls:
# 1. 执行工具
result = await self.execute_tool(command)
# 2. 记录日志
logger.info(f"
Tool '{command.function.name}' completed its
mission! Result: {result}")
# 3. 将工具结果添加到内存
tool_msg = Message.tool_message(
content=result,
tool_call_id=command.id,
name=command.function.name,
base64_image=self._current_base64_image, # 如有截图
)
self.memory.add_message(tool_msg)
results.append(result)
return "\n\n".join(results)
工具执行 (execute_tool())
# app/agent/toolcall.py:166-219
async def execute_tool(self, command: ToolCall) -> str:
name = command.function.name
args = json.loads(command.function.arguments or "{}")
# 1. 执行工具
logger.info(f"
Activating tool: '{name}'...")
result = await self.available_tools.execute(name=name,
tool_input=args)
# 2. 检查是否有截图返回
if hasattr(result, "base64_image") and result.base64_image:
self._current_base64_image = result.base64_image
# 3. 返回结果
return str(result)
执行示例
帮我写一份关于2025年中国新能源汽车出海欧洲的竞品分析报告,重点关注比亚迪和小鹏。
OpenManus的实际执行流程:
Step 1: 初始思考

执行流程:
- think() → LLM 决定使用 web_search 工具;
- act() → 执行 web_search(query=“比亚迪 欧洲市场 销量”);
- 结果添加到内存;
Step 2-8: 浏览器操作

执行流程:
- think() → LLM 决定使用 browser_use 工具访问网页;
- browser_context_helper.format_next_step_prompt() → 获取浏览器状态
- URL、标题、可交互元素列表:
[0]<button>搜索</button>,[1]<input>出发地</input>, …
- URL、标题、可交互元素列表:
- act() → 执行 browser_use.go_to_url(url);
- 浏览器工具返回:
- 文本结果:“Navigated to https://…” ;
- 截图(base64):存储在
_current_base64_image;
- 结果添加到内存(包含截图);
Step 9-20: 持续迭代
每次循环:
- think(): LLM 基于历史消息和当前浏览器状态,决定下一步行动:
- 可能选择:click_element, scroll_down, extract_content, web_search 等
- act(): 执行选定的工具;
- 结果累积: 所有工具执行结果都添加到内存,供下一轮思考使用;
关键数据流
用户输入
↓
Memory.messages = [
Message(user, “帮我写一份关于2025年…”),
]
↓
think() → LLM 分析 → 决定使用 web_search
↓
Memory.messages = [
Message(user, “帮我写一份关于2025年…”),
Message(assistant, “我需要先搜索…”, tool_calls=[web_search(…)]),
]
↓
act() → 执行 web_search → 返回搜索结果
↓
Memory.messages = [
Message(user, “帮我写一份关于2025年…”),
Message(assistant, “我需要先搜索…”, tool_calls=[web_search(…)]),
Message(tool, “Search results: 1. 比亚迪在欧洲市场…”),
]
↓
think() → LLM 分析搜索结果 → 决定使用 browser_use
↓
…(循环继续)
Think 阶段是 Agent 的大脑:智能决策、上下文理解、工具选择;
Act 阶段是 Agent 的执行器:工具执行、结果收集、错误处理;
工具
工具是 Agent 能力的扩展:
- WebSearch: 支持多引擎回退(Baidu → DuckDuckGo → Google →Bing),确保搜索成功率;
- BrowserUseTool: 自动管理浏览器状态,提供页面截图和元素列表;
- PythonExecute: 安全执行 Python 代码,支持数据处理和计算;
BrowserUseTool,浏览器状态管理是浏览器自动化的核心:
- 元素识别: 自动识别页面上的可交互元素(按钮、输入框、链接等);
- 文本描述: 为每个元素生成文本描述,LLM 可以根据文本匹配选择元素;
- 成本优化: 使用文本描述而非截图,节省 API 调用成本;
- 状态同步: 每次操作后自动更新浏览器状态,确保 LLM 始终了解当前页面;
本地浏览器工具(BrowserUseTool),基于 Playwright,在本地打开浏览器窗口。
如果想在 Daytona 沙箱中运行,需要使用 SandboxManus Agent,它会创建 Daytona 沙箱;在沙箱中运行浏览器;提供 VNC URL 和 Website URL 供查看。
| 特性 | BrowserUseTool(本地) | SandboxBrowserTool(沙箱) |
|---|---|---|
| 运行位置 | 本地电脑 | Daytona 云端沙箱 |
| 使用的 Agent | Manus | SandboxManus |
| 可视化方式 | 直接看到浏览器窗口 | 通过 VNC URL 查看 |
| 资源占用 | 占用本地资源 | 不占用本地资源 |
浏览器元素格式:
[0]<button>搜索</button>
[1]<input>出发地</input>
[2]<input>目的地</input>
[3]<button>查询</button>
[4]<link>登录</link>
LLM 根据这些文本描述选择元素,不需要视觉模型,节省成本。
在携程网站查询机票,浏览器的状态是怎样的?
浏览器状态管理流程:
1. 导航到携程网站后,get_current_state() 被调用
2. 获取页面信息:
- URL: https://www.ctrip.com
- Title: 携程旅行网
3. 识别可交互元素:
[0]<input>出发城市</input>
[1]<input>到达城市</input>
[2]<input>出发日期</input>
[3]<button>搜索</button>
4. BrowserContextHelper 将这些信息格式化为 prompt
5. LLM 根据元素描述选择 index=0 的输入框填写"上海"
6. 继续选择 index=1 填写"北京",index=3 点击搜索按钮
通过文本描述,LLM 可以理解页面结构并执行操作,不过有时候看不懂图片,如果想要更准确该怎么办?
# app/tool/browser_use_tool.py
async def execute(self, action: str, url: str = None, index: int = None, ...) -> ToolResult:
# 1. 确保浏览器已初始化
context = await self._ensure_browser_initialized()
# 2. 执行浏览器操作
if action == "go_to_url":
await context.goto(url)
elif action == "click_element":
await context.click(index)
elif action == "extract_content":
content = await context.extract_content(goal)
...
# 3. 获取当前状态(包含截图和元素列表)
browser_state = await self.get_current_state()
# 4. 返回结果(包含 base64_image)
return ToolResult(
content=result_text,
base64_image=browser_state.get('screenshot')
# base64编码的截图
)
当使用浏览器工具时,BrowserContextHelper 会怎样?
# app/agent/browser.py:format_next_step_prompt()
async def format_next_step_prompt(self) -> str:browser_state = await self.get_browser_state()
# 获取浏览器状态
url = browser_state.get('url')
title = browser_state.get('title')
interactive_elements =
browser_state.get('interactive_elements')
# 格式:[0]<button>搜索</button>, [1]<input>出发地
</input>, ...
# 构建 prompt
prompt = NEXT_STEP_PROMPT.format(
url_placeholder=f"\n URL: {url}\n Title: {title}",
...
)
# 添加元素列表
prompt += "\n\n[Current state starts here]\n"
prompt += "Interactive Elements:\n"
prompt += interactive_elements
return prompt
浏览器状态通过 browser_use_tool.get_current_state() 获取
- 包含可交互元素的文本描述(索引、类型、文本);
- LLM 根据这些文本描述选择元素(不需要视觉模型);
内存结构
内存是 Agent 的记忆,存储了完整的对话历史和工具执行结果:
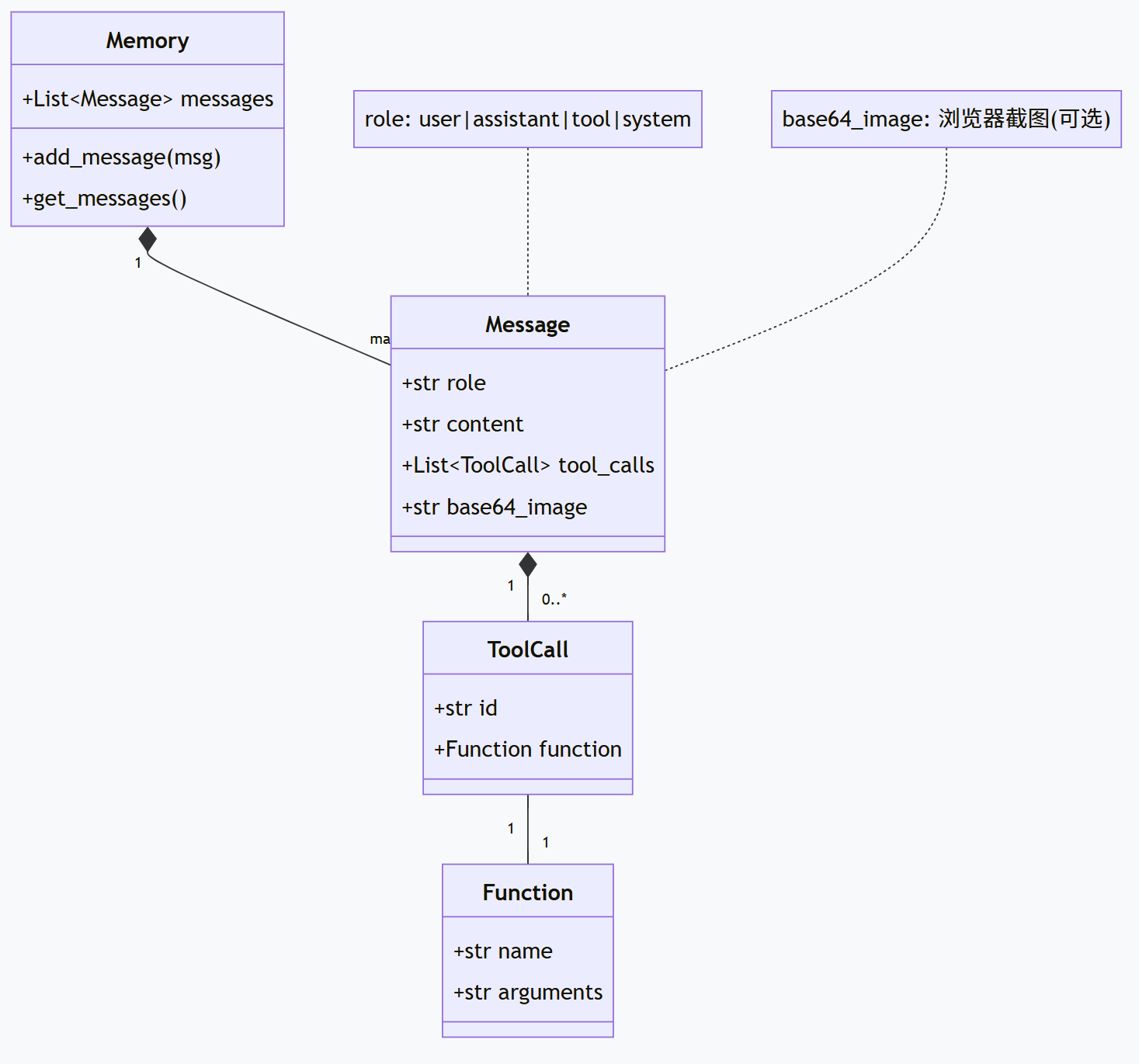
| 消息类型 | 说明 | 包含内容 |
|---|---|---|
| user | 用户输入 | 任务请求文本 |
| assistant | LLM 响应 | 思考内容 + 工具调用列表 |
| tool | 工具执行结果 | 执行结果文本 + 截图(可选) |
| system | 系统提示 | Agent 行为规范 |
# app/schema.py
class Memory(BaseModel):
messages: List[Message] = Field(default_factory=list)
class Message(BaseModel):
role: str # "user", "assistant", "tool", "system"
content: str
tool_calls: Optional[List[ToolCall]] = None
base64_image: Optional[str] = None # 截图(如果有)
Step 1: think() → 决定使用 web_search(“比亚迪 欧洲市场 销量”)
act() → 执行 web_search → 返回搜索结果
Step 2: think() → 决定使用 browser_use(go_to_url, url=“…”)
act() → 执行浏览器导航 → 返回页面状态
Step 3: think() → 决定使用 browser_use(extract_content, goal=“…”)
act() → 提取页面内容 → 返回文本
Step 4: think() → 决定使用 web_search(“小鹏汽车 欧洲市场”)
act() → 执行搜索 → 返回结果
Step 5-20: 持续迭代,收集信息,构建报告…
代码结构
Manus采用模块化设计,支持多种工具调用、浏览器自动化、代码执行等功能。
Tool目录是Manus的核心,包括了 常用工具,搜索工具,沙箱工具,可视化工具等。
Prompt定义了Agent的角色,将使用到的提示词模块化,放到prompt文件夹中,方便管理。
OpenManus/
├── app/ # 核心应用代码
│ ├── llm.py # LLM 封装(OpenAI 兼容接口)
│ ├── config.py # 配置管理(TOML 配置、环境变量)
│ ├── schema.py # 数据模型(Message、Memory、ToolCall 等)
│ ├── logger.py # 日志配置(loguru)
│ ├── exceptions.py # 异常类定义
│ ├── bedrock.py # Amazon Bedrock 客户端
│ ├── agent/ # Agent 实现层
│ │ ├── base.py # Agent 基类(状态管理、内存管理、执行循环)
│ │ ├── react.py # ReAct Agent(思考-行动模式)
│ │ ├── toolcall.py # 工具调用 Agent(处理工具调用决策)
│ │ ├── manus.py # Manus Agent(主要通用 Agent)
│ │ ├── sandbox_agent.py # SandboxManus Agent(沙箱环境 Agent)
│ │ ├── browser.py # 浏览器 Agent(浏览器上下文管理)
│ │ ├── data_analysis.py # 数据分析 Agent
│ │ ├── swe.py # SWE Agent(软件工程 Agent)
│ │ └── mcp.py # MCP Agent(MCP 协议 Agent)
│ │
│ ├── utils/ # 工具函数
│ │ ├── files_utils.py # 文件工具函数
│ │ └── logger.py # 日志工具(structlog)
│ │
│ ├── tool/ # 工具集合层
│ │ ├── base.py # 工具基类(BaseTool、ToolResult)
│ │ ├── tool_collection.py # 工具集合管理(注册、执行、管理)
│ │ ├── python_execute.py # Python 代码执行工具
│ │ ├── browser_use_tool.py # 浏览器自动化工具(Playwright)
│ │ ├── web_search.py # 网络搜索工具(多引擎支持)
│ │ ├── str_replace_editor.py # 文件编辑工具
│ │ ├── file_operators.py # 文件操作工具(本地/沙箱)
│ │ ├── planning.py # 规划工具(任务规划和管理)
│ │ ├── create_chat_completion.py # 结构化输出工具
│ │ ├── bash.py # Shell 命令执行工具
│ │ ├── computer_use_tool.py # 桌面自动化工具
│ │ ├── crawl4ai.py # 网页爬虫工具
│ │ ├── terminate.py # 终止工具
│ │ ├── ask_human.py # 人工询问工具
│ │ ├── mcp.py # MCP 工具(MCP 协议集成)
│ │ ├── search/ # 搜索引擎实现
│ │ │ ├── base.py # 搜索引擎基类
│ │ │ ├── baidu_search.py # 百度搜索
│ │ │ ├── google_search.py # Google 搜索
│ │ │ ├── bing_search.py # Bing 搜索
│ │ │ └── duckduckgo_search.py # DuckDuckGo 搜索
│ │ │
│ │ ├── sandbox/ # 沙箱工具(Daytona 沙箱)
│ │ │ ├── sb_browser_tool.py # 沙箱浏览器工具
│ │ │ ├── sb_files_tool.py # 沙箱文件工具
│ │ │ ├── sb_shell_tool.py # 沙箱 Shell 工具
│ │ │ └── sb_vision_tool.py # 沙箱视觉工具
│ │ │
│ │ └── chart_visualization/ # 图表可视化工具
│ │ ├── python_execute.py # Python 执行(图表专用)
│ │ ├── chart_prepare.py # 图表数据准备
│ │ └── data_visualization.py # 数据可视化
│ │
│ ├── flow/ # 流程管理层
│ │ ├── base.py # Flow 基类(多 Agent 管理)
│ │ ├── flow_factory.py # Flow 工厂(创建不同类型的 Flow)
│ │ └── planning.py # 规划流程(PlanningFlow)
│ │
│ ├── sandbox/ # 沙箱系统(Docker 沙箱)
│ │ ├── client.py # 沙箱客户端接口
│ │ └── core/ # 核心实现
│ │ ├── sandbox.py # DockerSandbox(容器管理)
│ │ ├── manager.py # SandboxManager(多沙箱管理)
│ │ ├── terminal.py # AsyncDockerizedTerminal(终端接口)
│ │ └── exceptions.py # 沙箱异常类
│ ├── daytona/ # Daytona 沙箱集成
│ │ ├── sandbox.py # Daytona 沙箱创建和管理
│ │ └── tool_base.py # 沙箱工具基类
│ │
│ ├── mcp/ # MCP 协议支持
│ │ └── server.py # MCP 服务器实现
│ │
│ ├── prompt/ # Prompt 模板
│ │ ├── manus.py # Manus Agent 提示词
│ │ ├── browser.py # 浏览器 Agent 提示词
│ │ ├── toolcall.py # 工具调用提示词
│ │ ├── planning.py # 规划提示词
│ │ ├── swe.py # SWE Agent 提示词
│ │ ├── mcp.py # MCP Agent 提示词
│ │ └── visualization.py # 可视化提示词
浏览器自动化核心逻辑
1. 整体运行流程:
main.py -> Manus.create() -> agent.run(prompt) -> 循环执行 think() + act()
核心循环 (app/agent/base.py):
- think(): LLM 分析当前状态,决定使用哪个工具;
- act(): 执行选定的工具,获取结果;
- 最多执行 20 步 (max_steps=20);
2. 浏览器操作核心代码
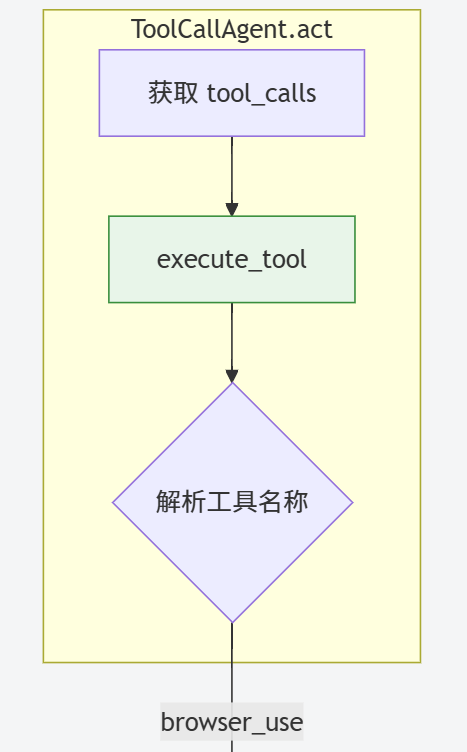
BrowserUseTool (app/tool/browser_use_tool.py),基于 browser_use 库实现,支持的操作:
- go_to_url: 导航到 URL;
- click_element: 点击指定索引的元素;
- input_text: 向元素输入文本;
- scroll_down/up: 滚动页面;
- send_keys: 发送键盘按键;
工具执行流程:
# ToolCallAgent.execute_tool() 执行工具
result = await self.available_tools.execute(name=name,tool_input=args)
# BrowserUseTool.execute() 处理具体操作
element = await context.get_dom_element_by_index(index) # 通
过索引获取元素
await context._click_element_node(element) # 执行点击
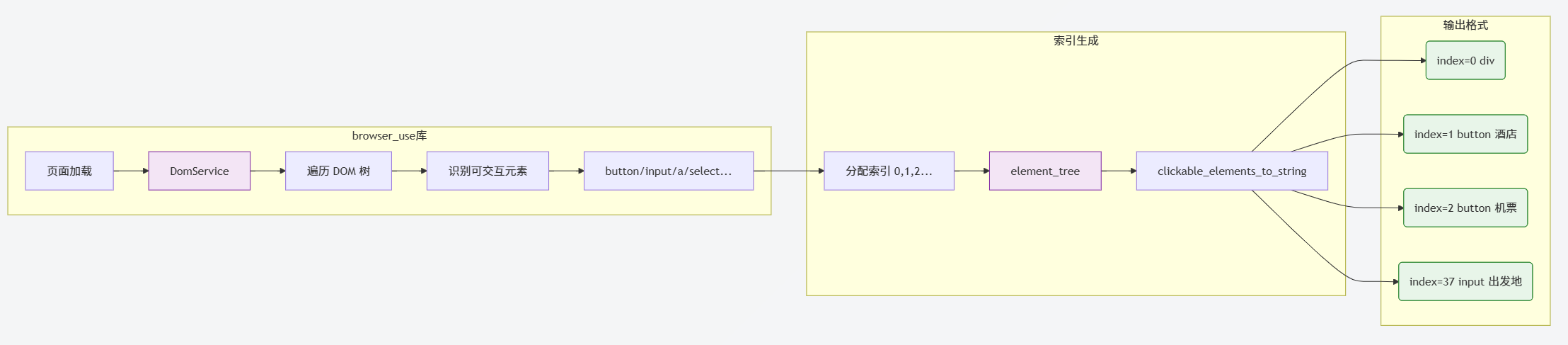
3. 元素识别与编号机制
1)元素提取
# get_current_state() 方法中
state = await ctx.get_state() # 获取浏览器状态
interactive_elements_str =
state.element_tree.clickable_elements_to_string()
2)编号格式
browser_use 库自动识别页面可交互元素,生成格式:[index]<type>text</type>;
比如:[0]<div />;[1]<button 酒店/>;[2]<button 机票/>;[3]<button 火车票/>;[37]<input 出发地/>;
3)页面编号显示
页面上的编号由 browser_use 库通过 DOM 注入 实现:
- 使用 DomService 遍历 DOM 树;
- 识别可点击/可交互元素 (button, input, a, 等);
- 通过 JavaScript 在页面上渲染索引标签;
4)元素操作
- 主要通过索引操作: click_element(index=2) 点击[2]号元素;
- 支持坐标点击: click_coordinates(x, y);
- 支持滚动到文本: scroll_to_text(text);
4. LLM 决策流程
关键设计
- 文本描述替代视觉: 使用元素文本描述(
[index]<type>text</type>) 而非截图,节省成本 - 状态持久化: 浏览器会话在步骤间保持
- 索引映射: browser_use 维护索引到 DOM 元素的映射,确保点击准确
关键函数
1. BrowserContextHelper 的作用
BrowserContextHelper 是浏览器上下文辅助类,负责:
- 获取浏览器当前状态(URL、标题、可交互元素);
- 格式化浏览器相关的提示词;
- 管理浏览器截图;
class BrowserContextHelper:
def __init__(self, agent):
self.agent = agent
self._current_base64_image = None
2. format_next_step_prompt() 的作用
获取浏览器状态,格式化下一步提示词供 LLM 决策。
执行流程:
- 调用 get_browser_state() 获取页面状态;
- 提取 URL、标题、标签页、滚动位置;
- 提取可交互元素列表;
- 将元素列表拼接到 prompt 中:
async def format_next_step_prompt(self):
browser_state = await self.get_browser_state()
# 构建 prompt,包含 URL、标签页、滚动信息
prompt = NEXT_STEP_PROMPT.format(...)
# 添加元素列表
prompt += "Interactive Elements:\n" + interactive_elements
return prompt
Agent 层:
| 函数 | 位置 | 作用 |
|---|---|---|
| run() | base.py | 主循环,执行 step 直到完成 |
| step() | react.py | 单步执行:think() + act() |
| think() | toolcall.py | LLM 决策,选择工具 |
| act() | toolcall.py | 执行选定的工具 |
| execute_tool() | toolcall.py | 执行单个工具调用 |
浏览器层:
| 函数 | 位置 | 作用 |
|---|---|---|
| get_browser_state() | browser.py | 获取浏览器当前状态 |
| format_next_step_prompt() | browser.py | 格式化浏览器提示词 |
| cleanup_browser() | browser.py | 清理浏览器资源 |
BrowserUseTool:
| 函数 | 位置 | 作用 |
|---|---|---|
| execute() | browser_use_tool.py | 执行浏览器操作 |
| get_current_state() | browser_use_tool.py | 获取页面状态和元素 |
| ensure_browser_initialized() | browser_use_tool.py | 初始化浏览器实例 |
| cleanup() | browser_use_tool.py | 关闭浏览器 |
Prompt详解
Manus SYSTEM_PROMPT:
你是 OpenManus,一个全能的 AI 助手,旨在解决用户提出的任何任务。
你拥有各种工具可以使用,能够高效地完成复杂的请求。
无论是编程、信息检索、文件处理、网页浏览,还是人机交互,你都能处理。
初始目录是:{directory}
重要提示:对于需要实时信息的任务(如机票价格、当前天气、股票价格、新闻等),
你必须使用浏览器工具访问实时网站。永远不要编造或猜测信息。
请使用中文回复用户。
Manus NEXT_STEP_PROMPT:
根据用户需求,主动选择最合适的工具或工具组合。
对于复杂任务,你可以分解问题并逐步使用不同工具来解决。
使用每个工具后,清楚地解释执行结果并建议下一步。
对于需要实时或当前信息的任务(机票价格、天气、新闻等),你必须使用浏览器工具搜索并从网站检索实际数据。不要提供编造的信息。
如果你想在任何时候停止交互,请使用 terminate 工具/函数调用。
Browser SYSTEM_PROMPT (核心):
你是一个设计用于自动化浏览器任务的 AI 代理。
# 输入格式
任务
之前的步骤
当前 URL
打开的标签页
交互元素
[index]<type>text</type>
- index: 用于交互的数字标识符
- type: HTML 元素类型(button、input 等)
- text: 元素描述
示例:[33]<button>提交表单</button>
# 响应规则
1. 响应格式:必须始终以 JSON 格式响应
2. 操作:可以指定多个操作按顺序执行
3. 元素交互:只使用交互元素的索引
4. 导航和错误处理:如果卡住,尝试替代方法
5. 任务完成:完成后使用 done 操作
Browser NEXTSTEPPROMPT:
下一步我应该做什么来实现目标?
当你看到 [Current state starts here] 时,请关注以下内容:
- 当前 URL 和页面标题{url_placeholder}
- 可用标签页{tabs_placeholder}
- 交互元素及其索引
- 视口上方{content_above_placeholder}或下方{content_below_placeholder}的内容
浏览器交互操作:
- 导航:使用 browser_use,action="go_to_url", url="..."
- 点击:使用 browser_use,action="click_element", index=N
- 输入:使用 browser_use,action="input_text", index=N,text="..."
- 提取:使用 browser_use,action="extract_content",goal="..."
- 滚动:使用 browser_use,action="scroll_down" 或"scroll_up"
如果你想在任何时候停止交互,请使用 terminate 工具/函数调用。
函数调用链
完整调用时序图:
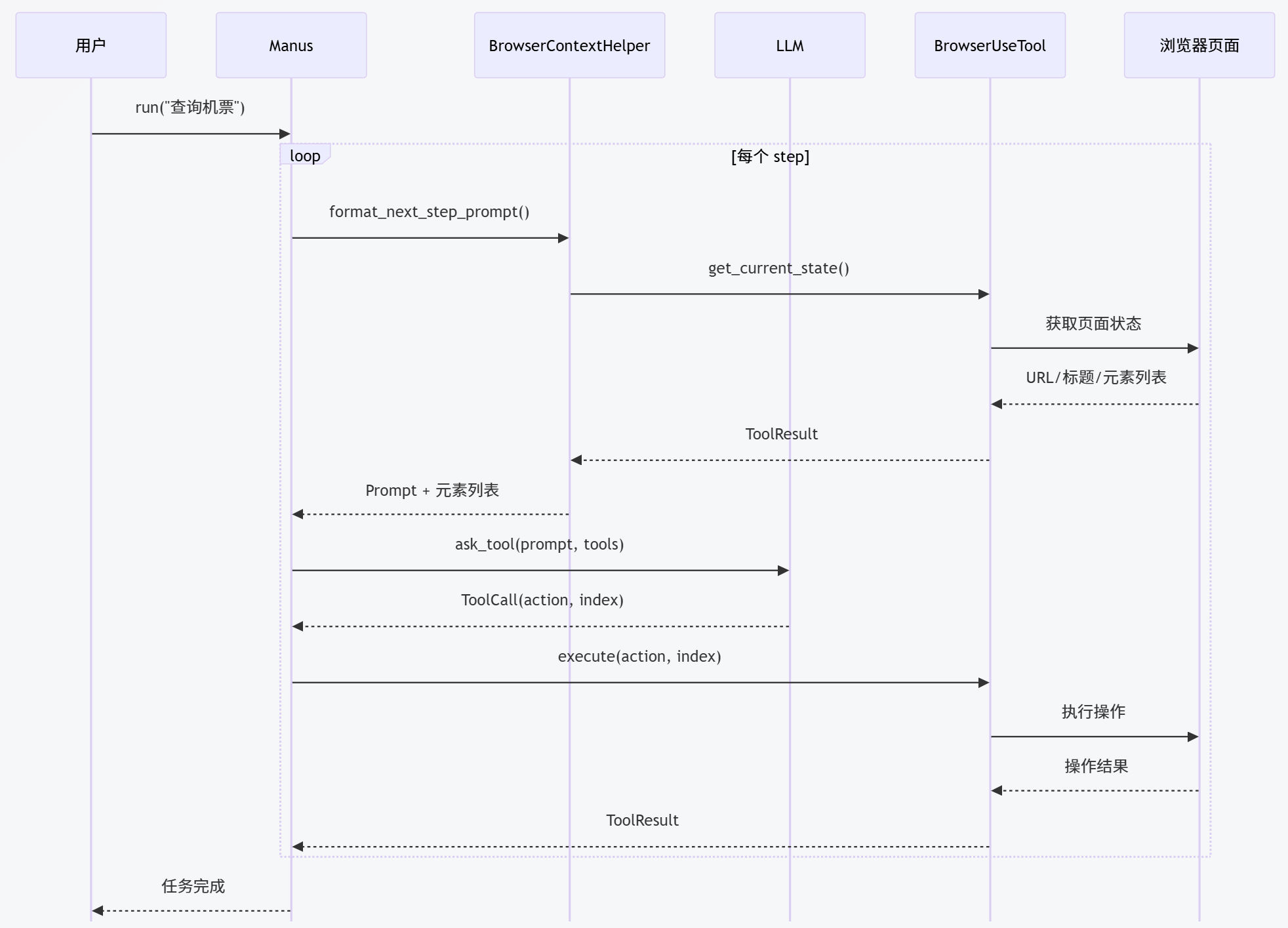
主执行流程:
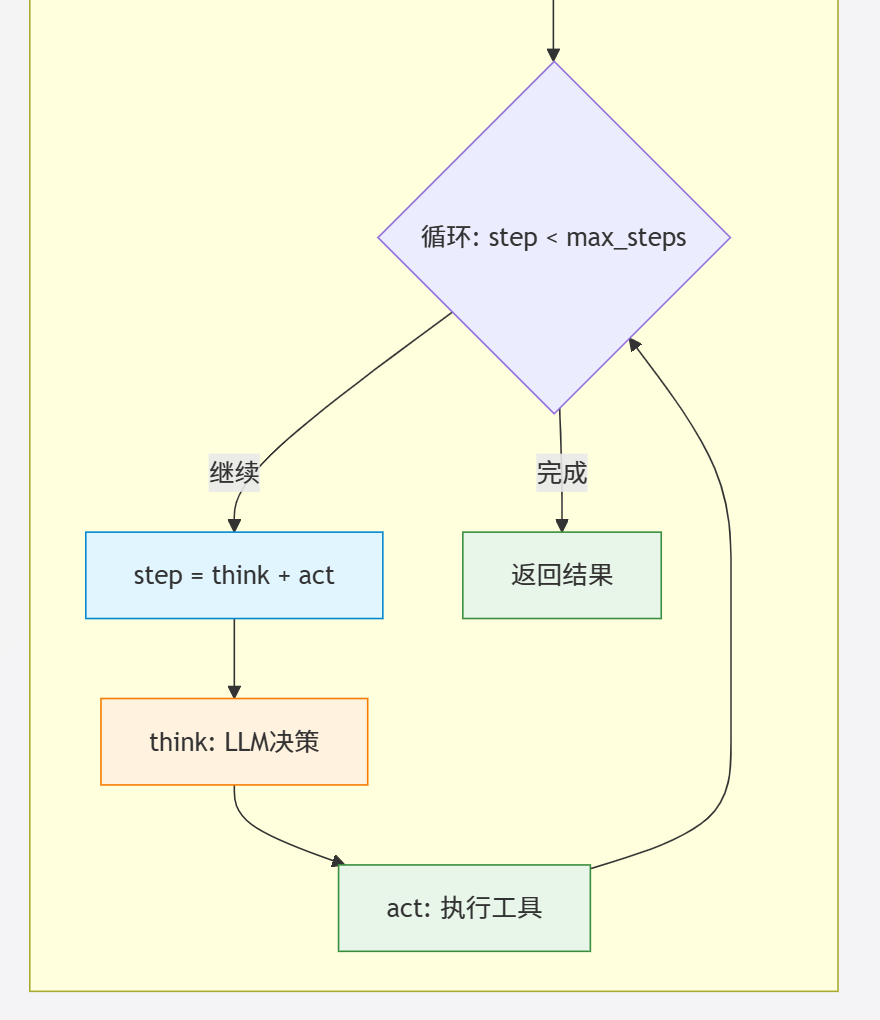
Think 阶段详解:

Act 阶段详解:
元素识别机制:

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)