
收藏!小白程序员必看:如何将大模型Agent从Demo成功落地工程实践?
上周有个朋友拿着一个 Agent 项目来问我。 他做的是代码变更助手:用户提一句“给订单模块加一个优惠券核销能力”,Agent 自动读代码、查接口文档、改代码、跑测试,最后生成 PR。
Demo 很顺。
第一轮它能找到 OrderService,第二轮能补 DTO,第三轮还能顺手生成单测。
然后一接真实仓库,问题全出来了。
它读了 20 个文件以后开始忘记前面看过什么;接口文档明明写着“核销接口需要幂等键”,它生成的代码没有带;工具调用到一半报权限错误,它没有停下来,反而继续用错误上下文写代码;产品只说“优惠券核销”,它自己脑补了退款逻辑。
最后 PR 能跑,但不能合。
朋友问我:“是不是模型不够强?换一个更大的模型会不会好一点?”
我的判断很直接:
Agent 工程的核心,不是把模型换大,而是把 Token、Skill、RAG、MCP、SDD、Harness 这条链路搭稳。
这些词不是六个并列概念。
它们描述的是同一个系统从“能回答”走向“能交付”的六层约束:
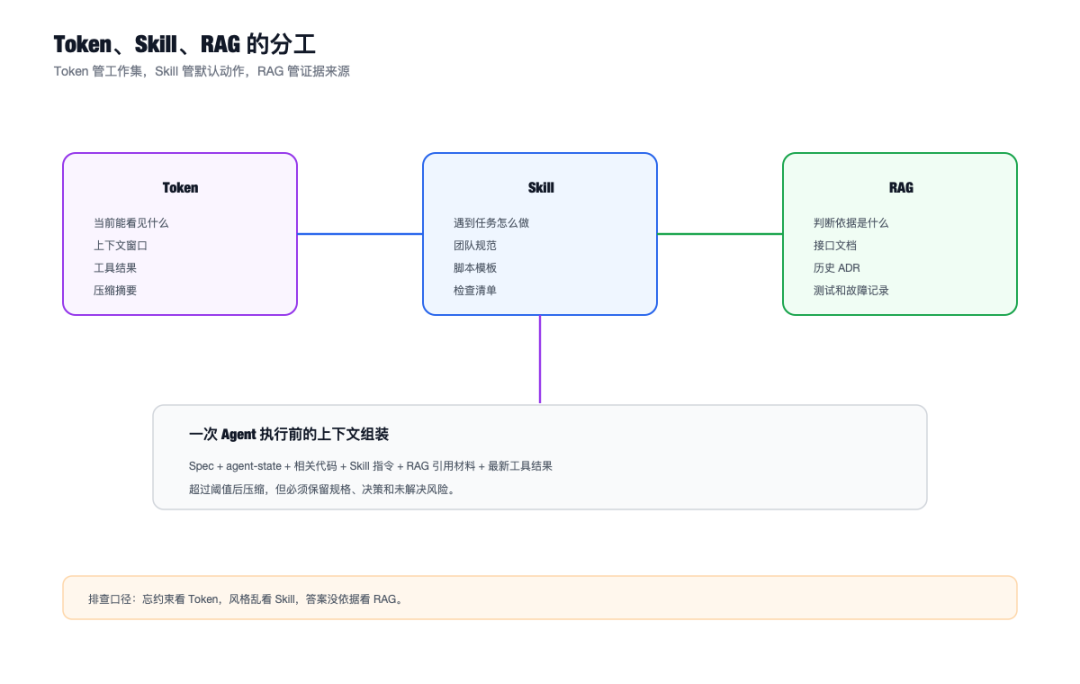
- Token 决定 Agent 当前能看见多少东西
- Skill 决定 Agent 遇到重复任务时按什么规矩做
- RAG 决定 Agent 缺知识时从哪里补证据
- MCP 决定 Agent 怎么安全、标准地接触外部系统
- SDD 决定 Agent 写代码之前有没有明确规格
- Harness 决定这些能力能不能稳定跑成一个闭环
这篇文章就讲一个主问题:
为什么很多 Agent demo 很聪明,一到工程交付就变蠢?
答案就在这条链里。

Token:Agent 的工作台,不是仓库
先说最底层。
Token 很容易被讲成计费单位,这当然没错,但做 Agent 时更应该把它理解成一个东西:
Agent 的工作台。
模型这一次推理能参考的指令、历史对话、工具结果、代码片段、错误日志、检索材料,都要摆在这张工作台上。
工作台越大,能同时处理的材料越多;但它再大,也不是无限仓库。
现场问题:代码库装不进上下文
假设你让 Agent 修改订单模块。
它一开始可能读这些文件:
src/order/OrderService.javasrc/order/OrderController.javasrc/order/dto/CreateOrderRequest.javasrc/coupon/CouponClient.javasrc/common/IdempotencyInterceptor.javadocs/coupon-api.mdlogs/test-failure.log
看起来不多。
但真实工程不是只读文件名。每个文件有代码,每段代码有依赖,每次测试失败又会产生新的日志。工具结果一轮轮塞进上下文,很快就会挤掉旧信息。
于是你会看到一种很典型的现象:
Round 1: Agent 发现 CouponClient.redeem() 需要 idempotencyKeyRound 2: Agent 修改 OrderService,但没有传 idempotencyKeyRound 3: Agent 解释说“当前代码中未发现幂等要求”
不是它没看过。
是它看过的内容在多轮执行里被冲淡、截断、摘要错了,或者被新的工具输出挤出了工作台。
工程解法:上下文要被管理,不能靠运气
OpenAI 的文档把 compaction 描述为一种把长对话压缩成摘要、避免超过上下文窗口的机制。这个动作在 Agent 里不是锦上添花,而是基础设施。
一个比较稳的上下文策略,至少要有四件事:
| 动作 | 解决什么问题 | 工程实现 |
|---|---|---|
| 分层读代码 | 防止一次塞爆 | 先读目录和符号索引,再按任务选择文件 |
| 摘要工具结果 | 防止日志淹没关键信息 | 长日志只保留失败用例、堆栈、关键断言 |
| 固化决策 | 防止多轮失忆 | 把已确认约束写入 agent-notes.md 或任务状态库 |
| 压缩上下文 | 防止超过窗口 | 超过阈值后把历史对话压成结构化摘要 |
这里有一个很小的伪代码,表达的是思想:
def build_context(task, state): context = [] context.append(load_system_policy()) context.append(load_spec(task.spec_id)) context.append(load_task_state(task.id)) files = retrieve_relevant_files(task.query, limit=8) context.extend(summarize_if_large(file) for file in files) failures = latest_test_failures(task.id) context.append(compact_logs(failures)) if token_count(context) > state.max_context * 0.8: context = compact_context(context, keep=["spec", "decisions", "open_risks"]) return context
这段代码没有什么玄学。
它只是在说一件事:上下文不是聊天记录堆叠,而是一次执行前主动组装出来的工作集。
Token 这一层不稳,后面的 RAG、工具调用、代码生成都会跟着抖。
Skill:把“每次提醒”变成“默认动作”
Token 解决的是“看得见多少”。
Skill 解决的是另一个问题:
看见以后,按什么规矩做。
很多人做 Agent,喜欢把团队规范写进 prompt:
请遵守我们的代码规范:1. Controller 不写业务逻辑2. Service 必须有单测3. 金额用 BigDecimal4. 日志不能打印手机号和身份证5. 外部接口必须加超时和重试
第一次有效。
第二次忘一半。
第三次换个人写 prompt,又变了。
Skill 的本质:可复用的操作手册
Anthropic 的 Claude Skills 把技能定义成可被 Claude 加载的指令、脚本和资源集合。翻译成工程话,就是:
把一类任务的做法沉淀成可复用包。
比如一个 Java 后端代码修改 Skill,可以长这样:
java-service-change/ SKILL.md scripts/ run_unit_tests.sh check_sensitive_logs.sh references/ error-code-convention.md transaction-boundary.md
SKILL.md 不是写鸡汤,而是写执行纪律:
# Java Service ChangeWhen changing service logic:1. Locate controller, service, repository, DTO, and tests before editing.2. Never put business logic in controller.3. Use BigDecimal for money.4. Add or update unit tests for changed branches.5. Run `scripts/check_sensitive_logs.sh` before final response.Stop and ask for review if:- The change needs a database migration.- The API contract is ambiguous.- Existing tests contradict the requested behavior.
这比“请认真一点”强太多。
因为它把团队的经验从一次性 prompt 变成了默认动作。
Skill 和 Prompt 的区别
| 对比项 | 普通 Prompt | Skill |
|---|---|---|
| 生命周期 | 当前对话 | 可长期复用 |
| 内容形态 | 文字指令为主 | 指令、脚本、模板、参考资料 |
| 维护方式 | 个人随手写 | 项目级版本管理 |
| 适合内容 | 临时任务要求 | 稳定流程和团队规范 |
所以 Skill 不负责补业务知识。
它负责让 Agent 在做同类事情时,不要每次都重新学做人。
RAG:不是让模型“多读点”,而是让答案有证据
Skill 解决“怎么做”。
RAG 解决“依据什么做”。
你让 Agent 加优惠券核销,Skill 可以告诉它“外部接口要加超时、错误码要统一、日志要脱敏”。
但 Skill 不知道你们公司的优惠券接口今天改成了什么字段。
这时候就要 RAG。
RAG 最怕的是检索到一堆看似相关的垃圾
很多 RAG 系统翻车,不是因为没有检索。
恰恰是因为检索太随意。
比如用户问:
订单核销优惠券时,幂等键应该怎么传?
一个粗糙的 RAG 可能返回:
1. coupon-api-v1.md:老接口,字段叫 requestId2. coupon-api-v2.md:新接口,字段叫 idempotencyKey3. refund-coupon.md:退款返券逻辑,也提到了 idempotencyKey4. marketing-campaign.md:营销活动发券,不是核销
模型看到一堆材料,很可能拼出一个“看起来合理但业务错误”的答案。
这就是 RAG 幻觉的常见来源:
模型不是没有资料,而是资料版本、范围、可信度混在一起了。
工程解法:RAG 要有过滤、重排和引用
我更建议把 RAG 做成三段:
Query Rewrite -> Retrieval -> Rerank / Filter -> Grounded Answer
落到代码上,大概是这样:
def retrieve_contract(question, module, version): query = rewrite_query(question, hints={ "module": module, "doc_type": "api_contract", "version": version }) candidates = hybrid_search( query=query, filters={ "module": module, "status": "active", "doc_type": ["api_contract", "adr", "test_case"] }, top_k=20 ) passages = rerank(question, candidates, top_k=5) return require_citations(passages)
这里最关键的是三个细节:
filters:先把过期文档、错模块文档过滤掉rerank:再按问题相关性重排require_citations:最后要求回答必须带引用,不能凭感觉补
RAG 的目标不是让模型显得懂很多。
RAG 的目标是让模型每个关键判断都能落回证据。
MCP:工具调用从“手写适配”变成“协议接入”
到这里,Agent 已经能管理上下文,也有规范和知识了。
但它还只是会“想”和“写”。
真要交付,它必须接触外部系统:Git、数据库、CI、工单、浏览器、对象存储、内部 API。
这就进入 MCP。
MCP,Model Context Protocol,官方定位是给 AI 应用连接外部工具和数据源的开放协议。它的价值不在于“又多一种调用工具的方法”,而在于把工具接入标准化。
Function Calling 和 MCP 不是一回事
Function Calling 更像一次模型 API 调用里的工具声明:
{ "name": "get_order", "description": "Get order detail by order id", "parameters": { "type": "object", "properties": { "orderId": { "type": "string" } }, "required": ["orderId"] }}
这很好用,但它通常是应用自己维护工具列表、认证方式、错误处理和服务连接。
MCP 则更像一个标准插座。
一个 MCP 系统里通常有三类角色:
- Host:用户实际使用的 Agent 应用
- Client:Host 内部负责维护连接的客户端
- Server:暴露 tools、resources、prompts 的外部能力服务
Agent 不需要在 prompt 里记住某个内部系统怎么调。它通过 MCP Server 发现能力,再按 schema 调用。
这解决的是工程治理问题
比如你要接三个系统:
GitLab:创建分支、提交 MR、读取 diffJira:读取需求、更新状态、写评论CI:触发流水线、读取测试结果
如果全靠项目里手写 function calling,很快会变成这样:
| 问题 | 手写工具适配的后果 |
|---|---|
| 认证分散 | 每个工具一套 token 管理 |
| 错误格式不同 | Agent 很难判断能不能重试 |
| 权限边界不清 | 读写能力混在一起 |
| 工具描述漂移 | prompt 里写的和真实 API 不一致 |
MCP 的意义,就是把这些东西收敛到 Server 边界里。
Server 负责暴露能力、描述 schema、处理认证、返回结构化错误;Host 负责选择和调用。
工程上会清爽很多。
但也别把 MCP 神化。
MCP 不能保证 Agent 调用得对,它只是让“能调用什么、怎么调用、用什么权限调用”变得更标准。
真正防止乱调用,还要靠后面的 SDD 和 Harness。
SDD:先写规格,再让 Agent 写代码
Agent 最危险的地方,不是它不会写。
是它太会写。
你给它一句模糊需求,它也能写出一堆看起来完整的代码。
这在 demo 里很好看,在工程里很可怕。
模糊需求会被模型自动补全
还是优惠券核销这个例子。
产品说:
订单支付前支持优惠券核销。
如果没有规格,Agent 可能会自己脑补:
- 核销失败是否阻断下单
- 优惠券是否支持叠加
- 支付失败后是否返还优惠券
- 是否需要冻结库存
- 是否需要幂等键
- 是否要写操作日志
这些不是代码细节。
这是业务决策。
Agent 不能替业务和架构师做这些决策。
SDD 的价值:把“猜”变成“按合同实现”
SDD,Spec-Driven Development,规格驱动开发。GitHub 的 Spec Kit 也把“先规格、再计划、再任务、再实现”作为核心工作流。
用在 Agent 工程里,SDD 的关键不是多写文档,而是建立一个门禁:
没有规格,不进入实现。规格没评审,不拆任务。任务没验收标准,不让 Agent 自由改代码。
一个最小规格可以这样写:
# Spec: 优惠券核销接入订单支付前置流程## Scope- 只支持单张优惠券- 只在订单支付前核销- 本次不处理支付失败后的返券## Rules- 核销请求必须携带 idempotencyKey- 核销失败时订单保持 CREATED,不进入 PAYING- 同一订单重复提交时必须复用同一个 idempotencyKey- 日志不得打印用户手机号、优惠券完整码## Acceptance- 新增 CouponRedeemService 单测- 覆盖核销成功、核销失败、重复提交三个场景- 集成测试必须验证 OrderStatus 状态流转
这份规格不长,但它把 Agent 最容易乱猜的地方钉住了。
更重要的是,它让后面的验证变得可能。
没有规格,你只能问“代码写得好不好”。
有规格,你可以问“代码是否满足第 3 条验收标准”。
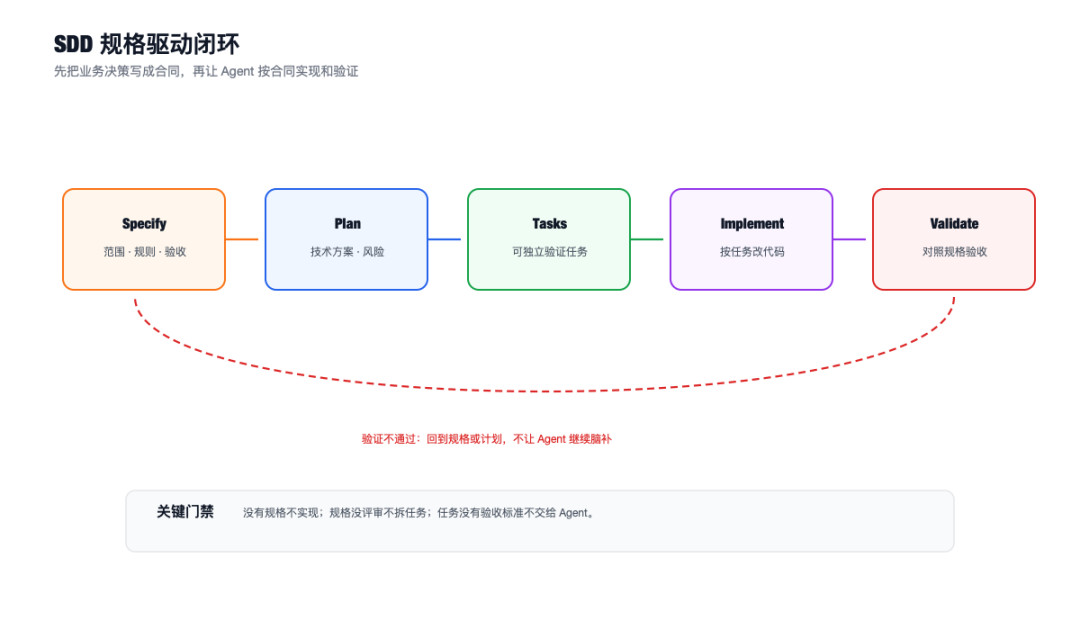
Harness:把模型包成一个可观测、可回滚、可审计的执行系统
最后一层是 Harness。
这个词中文很难一对一翻译,可以理解成 Agent 的执行框架、脚手架、运行时外壳。
如果说模型是发动机,Harness 就是车架、仪表盘、刹车、方向盘、安全带和维修接口。
没有 Harness,Agent 只是一轮轮调用模型。
有 Harness,Agent 才是一个工程系统。
一个生产 Agent 至少要有这些部件
OpenAI Agents SDK 这类框架会把工具、handoff、guardrails、tracing 等能力放进 Agent 构建流程里。不同框架名字不完全一样,但工程含义类似。
我建议你按这张表理解 Harness:
| 部件 | 作用 | 没有它会怎样 |
|---|---|---|
| Planner | 拆任务和选择下一步 | Agent 想到哪做到哪 |
| Tool Registry | 管理工具 schema 和权限 | 工具调用混乱 |
| Context Manager | 管理 Token 和压缩 | 多轮执行失忆 |
| Guardrail | 输入输出和动作门禁 | 危险操作直接执行 |
| Evaluator | 检查结果是否符合规格 | 代码能跑但不符合需求 |
| Trace | 记录每一步决策和工具结果 | 出错后无法复盘 |
| Human Approval | 人工审批敏感动作 | 删库、发版、改权限无法兜底 |
Harness 的执行循环
一个比较实用的 Agent 循环大概长这样:
Load Spec -> Build Context -> Plan Next Step -> Select Tool -> Check Permission -> Execute Tool -> Record Trace -> Evaluate Against Spec -> Continue / Ask Human / Finish
注意这里有两个门:
第一道门在工具执行前。
if tool.name in ["delete_branch", "run_migration", "deploy_prod"]: require_human_approval(tool_call)
第二道门在执行结果后。
result = evaluate_against_spec( spec=load_spec(task.spec_id), diff=git_diff(), tests=latest_test_result())if result.has_blocker: agent.replan(result.feedback)
这两道门决定了 Agent 是“帮你干活”,还是“替你制造事故”。
Harness 真正难的是副作用治理
问答机器人答错一句,大不了重新问。
Agent 调错一个工具,可能会创建错误 PR、改错数据库、触发错误流水线、把错误状态同步到工单系统。
所以 Harness 一定要把副作用分级:
| 动作级别 | 示例 | 策略 |
|---|---|---|
| 只读 | 读文件、查文档、查 CI 日志 | 默认允许,记录 trace |
| 可回滚写 | 改本地文件、创建草稿 PR | 自动执行,但保留 diff |
| 外部写 | 更新工单、评论 MR | 需要明确任务上下文 |
| 高风险写 | 发版、迁移、删除、权限变更 | 人工审批 |
很多 Agent 项目不稳定,不是模型不会推理,而是 Harness 没有把这些边界管住。
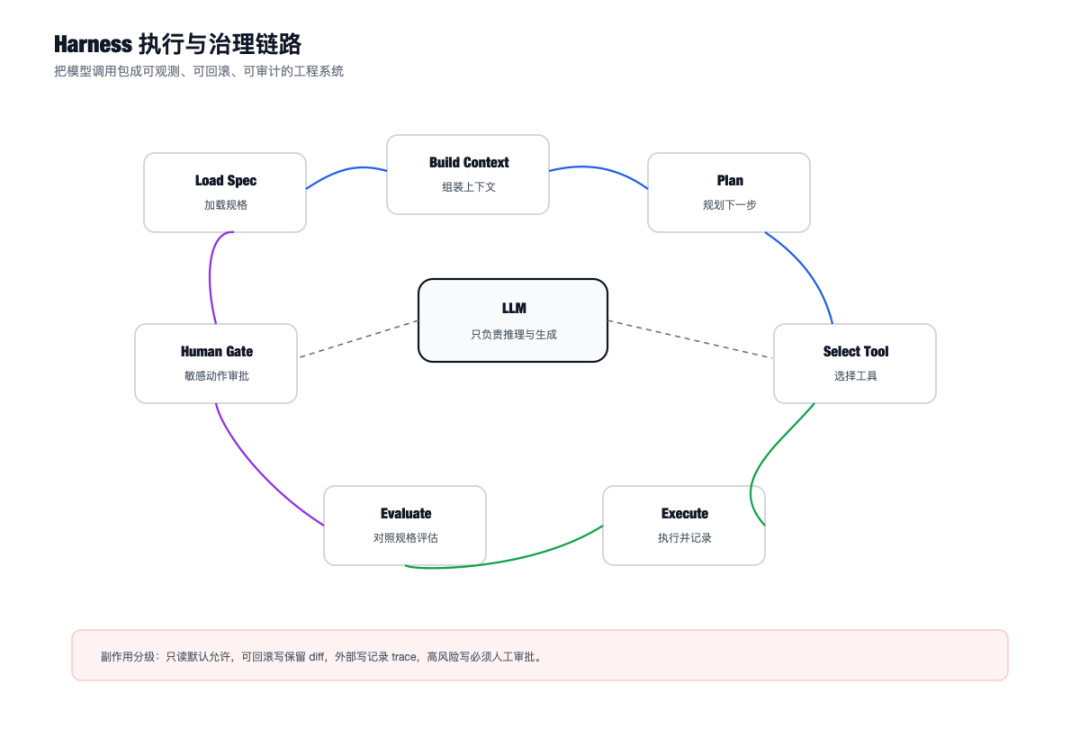
六层放在一起,Agent 才从 demo 变成系统
现在回头看这六个概念,它们不是概念墙。
它们是一条链。
Token -> Skill -> RAG -> MCP -> SDD -> Harness
每一层都在回答一个工程问题:
| 层 | 核心问题 | 典型故障 |
|---|---|---|
| Token | 当前执行能看见什么 | 多轮失忆、上下文污染 |
| Skill | 重复任务按什么规矩做 | 产出风格不一致、规范遗漏 |
| RAG | 缺知识时引用什么证据 | 引用旧文档、一本正经胡说 |
| MCP | 怎么连接外部系统 | 工具碎片化、权限混乱 |
| SDD | 写代码前规格是否清楚 | 需求跑偏、模型脑补业务 |
| Harness | 执行过程是否可控 | 不可观测、不可回滚、不可审计 |
这张表也可以当排查清单。
Agent 忘了前面约束,先看 Token 和 Context Manager。
Agent 每次代码风格不一样,先看 Skill。
Agent 答案没依据,先看 RAG 检索和引用。
Agent 工具越来越难维护,先看 MCP 或工具注册表。
Agent 写出来不是你要的,先看 SDD。
Agent 时好时坏、出错说不清,先看 Harness。
工程落地:一个小团队怎么开始
如果你现在手上只有一个普通代码助手,不要一上来就搭大平台。
我建议按这个顺序做。
第一阶段:先管住上下文和规格
这是投入最小、收益最大的两件事。
- 为每个任务创建
spec.md - 为每次执行创建
agent-state.md - 让 Agent 每轮开始前读取规格和状态
- 让 Agent 每轮结束后更新已确认约束、已修改文件、未解决风险
目录可以很简单:
.agent/ tasks/ coupon-redeem/ spec.md plan.md agent-state.md trace.md
这一步做完,你会发现 Agent 稳很多。
因为它不再完全靠对话历史记忆任务。
第二阶段:沉淀 Skill 和 RAG
把稳定规范变成 Skill,把变化知识放进 RAG。
不要反过来。
代码规范、安全检查、错误码约定、测试要求,这些适合 Skill。
接口文档、数据库表结构、历史 ADR、线上故障复盘,这些适合 RAG。
一个简单原则:
三个月不怎么变的,放 Skill;每周都可能变的,走 RAG。
第三阶段:工具接入标准化
当你发现工具越来越多,就该抽工具层了。
不一定所有团队第一天都要上 MCP。
但你至少要做到:
- 工具 schema 清楚
- 错误码结构化
- 读写权限分开
- 高风险动作可审批
- 每次工具调用有 trace
如果你的 Agent 要接多个外部系统,或者要给多个客户端复用工具能力,MCP 的价值会明显变大。
第四阶段:补 Harness 的观测和评估
最后才是更完整的 Harness。
你需要开始关心指标:
| 指标 | 含义 |
|---|---|
| task_success_rate | 任务最终通过验收的比例 |
| human_intervention_rate | 需要人工介入的比例 |
| tool_error_rate | 工具调用失败比例 |
| spec_violation_count | 违反规格的次数 |
| token_per_task | 单任务 Token 成本 |
| rollback_count | 需要回滚的执行次数 |
这些指标比“模型回答看起来聪明”有用。
因为工程交付看的不是一次高光,而是稳定成功率。
面试怎么答
如果面试官问你:
“你怎么理解 AI Agent 的核心架构?”
不要只回答“LLM + Tools + Memory + Planning”。
这个回答不算错,但太像背概念。
你可以这么说:
★
我会把 Agent 工程拆成六层。
最底层是 Token,它决定一次执行能看见什么,所以要做上下文组装、压缩和外部状态记录。
第二层是 Skill,把团队稳定的操作流程封装起来,避免每次靠 prompt 临时提醒。
第三层是 RAG,给 Agent 补动态知识,但重点不是多检索,而是过滤、重排、引用和版本控制。
第四层是 MCP 或工具协议层,解决 Agent 连接外部系统时的标准化、权限和可发现性问题。
第五层是 SDD,先把需求边界、验收标准和非功能约束写成规格,再让 Agent 实现,防止模型脑补业务。
最上层是 Harness,也就是执行框架,负责规划、工具注册、上下文管理、权限门禁、评估、trace 和人工审批。
这六层串起来,Agent 才不是一个会聊天的模型,而是一个可观测、可回滚、可审计的工程系统。
如果面试官继续追问“你们项目里最容易出问题的是哪层?”
可以答:
★
最容易被低估的是 SDD 和 Harness。很多团队以为 Agent 跑偏是模型问题,其实是规格不清;以为工具调用错是 prompt 问题,其实是 Harness 没有做权限、trace 和评估。模型能力当然重要,但生产环境更看重边界和闭环。
这个回答会比“我们用了 RAG 和 Function Calling”扎实很多。
回到开头那个 PR
朋友那个代码变更助手,后来没有先换模型。
他们先做了三件小事:
- 每个需求先生成
spec.md,人工确认后再实现 - 每轮执行把关键约束写进
agent-state.md - 对 Git、CI、工单工具做读写权限分级,高风险动作必须审批
效果很朴素。
Agent 还是会犯错,但错得更早、更小、更容易复盘。
这就是 Agent 工程真正要追求的状态。
不是让模型一次性变成全能程序员。
而是用 Token 管理、Skill、RAG、MCP、SDD 和 Harness,把一个不确定的模型,包进一个确定性更强的工程系统里。
概念讲到最后,其实就一句话:
Agent 的上限来自模型,Agent 的下限来自工程。
真正决定能不能上线的,往往是下限。
普通人如何抓住AI大模型的风口?
领取方式在文末
2026年入行AI大模型的黄金窗口!!!
AI产业正迎来前所未有的爆发式增长。 从DeepSeek以百万年薪重金招募顶尖研究员,到百度、阿里、腾讯等头部企业加速推进AI Agent商业化布局,再到国家层面持续出台政策,大力扶持数字经济与AI人才培育体系,多重信号清晰指向一个共识:AI的“黄金十年”已全面开启
在产业浪潮的强劲推动下,AI人才争夺战日趋白热化。技术迭代与场景落地双轮驱动,催生海量高价值岗位。放眼未来,AI领域的职业发展前景广阔无垠,正涌现出大量高潜机遇,堪称一片值得深耕的**“人才蓝海”**。
脉脉数据显示📊:
2026年1-2月,AI岗位数量同比增长约12倍,增速远超新经济行业整体增幅;AI岗位在全部新经济岗位中的占比也从2025年同期的2.29%跃升至26.23%,几乎占据新经济招聘市场的四分之一。
与此同时,AI新发岗位平均月薪高达60738元,较新经济行业整体平均月薪48189元高出约26%。
这一切都说明一件事:2026年,正是入行AI大模型的黄金窗口❗️❗️
最佳学习路线
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)