
Skill-RM:通过智体技能统一异构评估标准
26年6月来自阿里千问、中山大学、港中文、北大、ETH和苏黎世大学的论文“Skill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill”。
奖励模型(RM)为大语言模型(LLM)的后训练阶段——特别是在强化微调(RFT)和强化学习(RL)流程中——提供了关键的反馈信号。然而,当前的奖励评估依赖于多种异构标准,如基于规则的验证器、标准参考答案、程序化检查清单以及复杂的评分准则,且尚缺乏一种能整合各类评估依据的统一机制。为此,提出“技能奖励模型”(Skill-RM)。该统一框架将奖励建模重新定义为一种可复用的“奖励评估技能”的执行过程。Skill-RM 将奖励计算视为一项结构化的智体(agentic)任务,通过提供统一接口来协调异构资源,并根据每个输入的具体需求动态选择与聚合评估依据。这种方法使奖励模型摆脱静态评估的局限,从而确保跨多样化任务的一致性与透明度。在奖励评估基准及下游应用(包括 Best-of-N 筛选和强化学习)上的大量实验表明,Skill-RM 的表现始终优于传统的“裁判”基线模型。
“智体技能”(Agent skills)作为一种机制应运而生,旨在将程序性知识和任务资源封装为可供大语言模型(LLM)智体复用的制品。Anthropic 在 Claude 中引入“智体技能”概念,将其定义为包含指令、脚本和资源的文件夹(Anthropic, 2025a),并随后将其设计描述为一种赋予现实世界智体可移植程序性知识的途径(Zhang et al., 2025)。开放的“智体技能”规范将这一设计标准化,构建以 SKILL.md 文件为核心的目录结构,并通过“渐进式披露”机制提供可选的脚本、参考资料和资产(Agent Skills Contributors, 2025)。早期的技能库智体(如 Voyager)已证明,可执行的行为能够被存储并在不同任务与环境中复用(Wang et al., 2023)。在 Claude 的产品体系中,“技能”被明确区分于提示词(prompts)、项目(Projects)、MCP 和子智体(subagents)(Anthropic, 2025b)。近期的综述研究从架构、获取方式、安全性、应用场景及生命周期阶段等维度对体技能进行了分类梳理(Xu & Yan, 2026; Zhou et al., 2026);同时,系统化研究工作通过适用条件、执行策略、终止准则及可复用接口等要素,将智体技能与原子级工具调用区分开来(Jiang et al., 2026)。实证分析探讨公开的 Claude 技能库(Ling et al., 2026),而 SkillsBench 基准测试则评估技能内容及策展方式对任务性能的影响(Li et al., 2026b)。此外,相关研究还涉及结构化技能表示(Liang et al., 2026)以及生态系统层面的技能选择与编排(Li et al., 2026a)。Skill-RM 则专门针对奖励建模(reward modeling)优化技能抽象,将奖励准则、参考资料、验证器、证据字段及聚合规则整合为一套可执行的评估流程。
如图1 所示技能-奖励模型(Skill-RM)概览。“奖励评估技能”由一份程序性文档和一个结构化资源库(包含评分标准、核查清单、验证器及聚合规则)构成。在评估过程中,Skill-RM 能够动态检索相关资源,并执行具有智体特性的评估流程。这种适应输入的推理过程,有效地将多种奖励评估范式统一到一个一致且灵活的框架之中。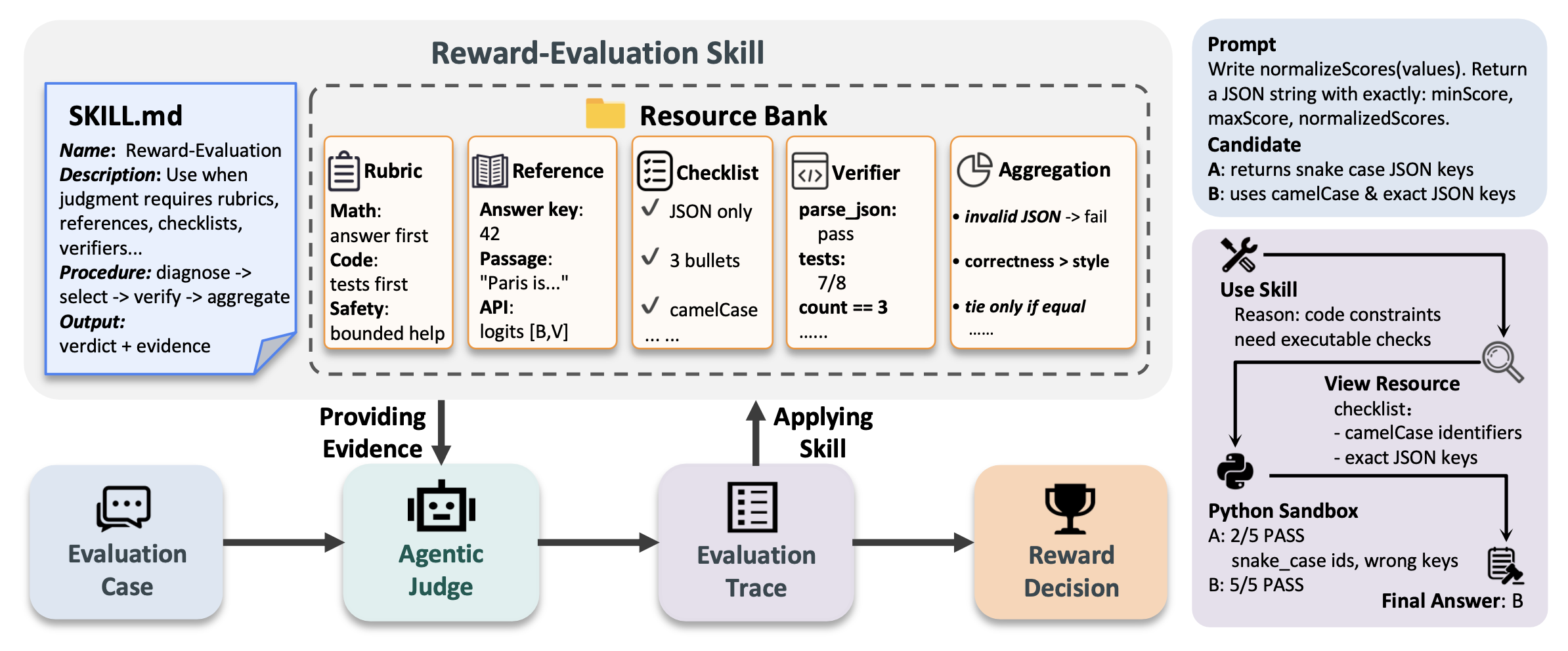
Skill-RM 的基本设计理念是,奖励知识不会隐式地隐藏在模型权重中,也不会被压缩到单一的提示中。相反,它被具体化为跨不同实例和领域的可重用技能。这项技能作为奖励能力的原子单位,编码一个全面的评估逻辑:它不仅规定评估的标准,还规定如何检索证据以及如何合成证据以证实最终的奖励决策。
将“奖励评估资源”定义为一种结构化的单元,包含任务相关的证据或可执行的评估程序,可在技能执行过程中加以参考。
资源库 U_RM 涵盖贯穿奖励计算全生命周期的各类评估工具,包括分析评估标准、获取可验证的观测结果以及汇总证据以形成最终判定。表 1 列出这些资源的分类及其在判定过程中的功能角色。关键在于,与那些用庞杂且扁平的上下文信息让评估者不堪重负的传统方法不同,该框架维护一个潜在资源库。资源在被技能规范 MRM 触发之前保持非激活状态;这种机制确保在判定过程中仅调用与任务相关的资源子集,从而最大限度地减少上下文噪声,并提升智体评估者(agentic judge)的判定精度。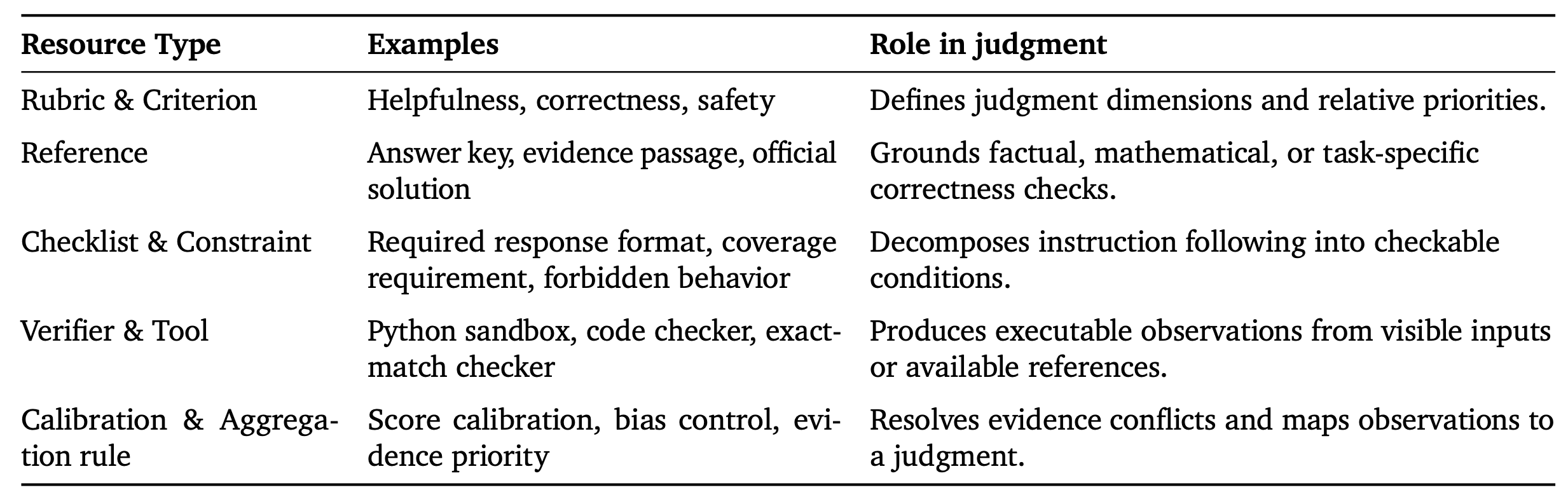
通过一个由大语言模型(LLM)辅助的筛选流程来构建该资源库,以确保其一致性与模块化。从多种来源汇集候选资源,包括现有的奖励建模文献、标准化的评估协议、基准测试文档以及可验证的评估实践。为确保资源的可复用性,为每项资源定义明确的适用条件,合并冗余条目,并剔除特定任务的启发式规则,从而生成通用的功能模块。最终确定的资源库在评估前会进行版本控制并锁定状态,以确保评估结果的可复现性。
给定输入提示 𝒙 和一组候选回复 Y = {𝒚_1, . . . , 𝒚_𝐾},Skill-RM 通过智体判别模型 𝜋_𝜙 调用技能组件 SRM 来执行奖励评估。启动时,判别模型会加载程序化规范 MRM,该规范作为当前评估任务的执行蓝图。在整个过程中,判别模型严格遵循 MRM 定义的调用协议,按需动态检索或执行 URM 中的资源。这确保评估过程并非简单的单次推理,而是针对输入具体需求而精心编排的一系列动作序列。
在操作上,评估遵循阶段性的执行逻辑:(1)确定评估目标和期望的输出格式; (2) 激活MRM规定的相关标准; (3)动态检索必要的资源。随着流程的展开,裁判将这些观察结果映射为标准级证据,确保只有在满足所有强制性证据字段后才填充结构化判断𝑧。通过形式化这一过程,奖励评估转变为严格的、受协议控制的计算,取代传统提示级奖励模型基于启发式的一次性决策特征。
任务所需的奖励输出由确定性读出函数 A(·) 导出。
奖励评估技能(Reward-Evaluation Skills)的构建
本研究中的奖励评估技能是通过大语言模型(LLM)辅助的整理流程构建的。该流程将公开的或基准测试允许使用的评估材料组织成可复用的技能;它并不涉及自动化的技能学习算法。源材料涵盖奖励建模论文、“LLM作为裁判”(LLM-as-a-Judge)的协议、基准测试文档、评分标准、参考资料、约束条件、检查清单以及验证实践。在整理流程中,利用基于LLM的编码助手起草候选技能指令和资源条目,并由人工进行最终的筛选、合并、编辑及剔除决策。
针对每项技能,明确其评估标准、协议允许使用的证据以及基准测试要求的输出格式。将这些材料标准化为资源库条目,每个条目记录资源类型、内容、适用范围及访问操作。程序性文件 SKILL.md 规定技能加载时机、资源选择方式、记录的证据模式(schema),以及奖励输出如何将结构化判断映射为所需格式。因此,最终产物并非包含所有材料的单一提示词(prompt),而是一份程序性技能文档与配套资源库的组合。
针对源材料依据(grounding)、模式一致性、资源适用性、重复条目及数据泄露风险进行重点人工核查。剔除隐藏的基准测试标签、直接的目标偏好标签、模型身份信息、答案顺序记录、特定案例的解题过程以及既往评估反馈。在评估前,会锁定构建完成的技能与资源库。构建阶段的LLM辅助交互仅为中间创作材料,不属于推理阶段评估协议的一部分;最终可复现的产物包括锁定的技能文件、资源索引、调用协议、基准测试适配器以及随代码发布的评估脚本。
对于标记为“+ sample-spec.”(特定样本资源)的条目,其额外资源来源于公开的OpenRS数据和提示词文件,而非本研究中的新标注。这些资源包括协议公开的答案证据、指令遵循约束或检查清单、查询类型元数据,以及适用的OpenRS评分标准或验证提示词。它们仅在“特定样本资源”变体中加载,不会被整合进默认的奖励评估技能中。OpenRS中的模型身份、答案顺序记录及目标偏好标签均不作为可供裁判使用的资源。
提示词模板
Skill-RM 保持基准测试(benchmark)提供的用户提示词和候选回复不变。系统消息中增加一项可选的“奖励评估技能”(Reward-Evaluation Skill),并允许评判者选择直接回答或调用 use_skill。用于奖励建模运行的提示词模板如下所示;其中的占位符由基准测试格式化程序及所选的“奖励评估技能”进行填充。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)