
Cursor与Trae AI:代码智能工具核心技术揭秘
代码智能工具双雄:Cursor 与 Trae AI 底层原理全解析
目录
Trae AI——这款主打“上下文感知+实时协作”的新一代 LLM 代码工具,与 Cursor 并列为当下开发者最关注的 AI 编码助手。本文将从技术内核、数据流转全链路、实战场景出发,拆解这两款工具的核心逻辑
一、Cursor:LLM 深度耦合的代码创作引擎
1. 核心原理:编辑器与大模型的“原生融合”
Cursor 不是简单的“编辑器 + AI 插件”,而是以 GPT-4/GPT-4o 为基座,专为代码场景深度定制的一体化创作工具。其核心突破在于打破了“编辑器”与“AI 模型”的边界,原理可概括为三层架构:
- 基座层:基于通用大模型做代码专项微调(Code Fine-tuning),强化代码生成、语法纠错、逻辑推理能力;
- 上下文层:自研“项目级上下文感知引擎”,能解析项目目录结构、跨文件依赖、代码风格规范,而非仅捕获当前行文本;
- 交互层:将 AI 能力拆解为“实时补全、选中改写、对话生成、调试解释”等原子功能,无缝嵌入光标操作、快捷键、选中区域等编辑器交互。
Cursor 核心工作流程:
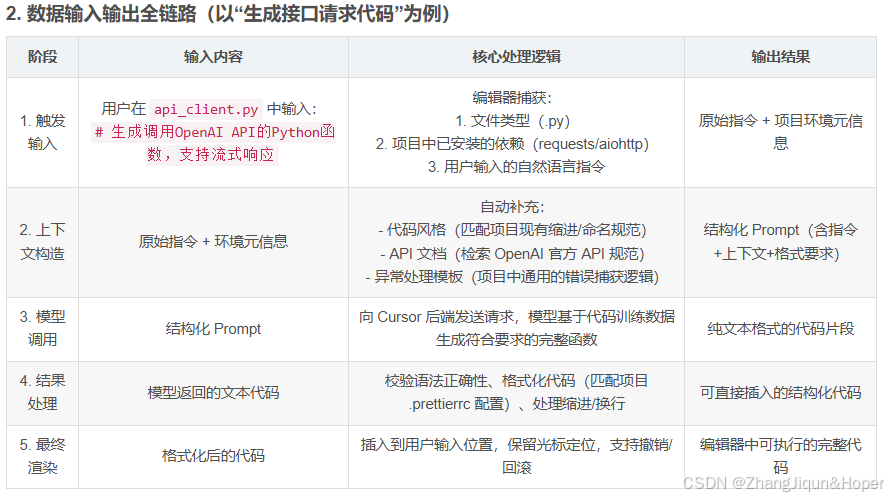
2. 数据输入输出全链路(以“生成接口请求代码”为例)
| 阶段 | 输入内容 | 核心处理逻辑 | 输出结果 |
|---|---|---|---|
| 1. 触发输入 | 用户在 api_client.py 中输入:# 生成调用OpenAI API的Python函数,支持流式响应 |
编辑器捕获: 1. 文件类型(.py) 2. 项目中已安装的依赖(requests/aiohttp) 3. 用户输入的自然语言指令 |
原始指令 + 项目环境元信息 |
| 2. 上下文构造 | 原始指令 + 环境元信息 | 自动补充: - 代码风格(匹配项目现有缩进/命名规范) - API 文档(检索 OpenAI 官方 API 规范) - 异常处理模板(项目中通用的错误捕获逻辑) |
结构化 Prompt(含指令+上下文+格式要求) |
| 3. 模型调用 | 结构化 Prompt | 向 Cursor 后端发送请求,模型基于代码训练数据生成符合要求的完整函数 | 纯文本格式的代码片段 |
| 4. 结果处理 | 模型返回的文本代码 | 校验语法正确性、格式化代码(匹配项目 .prettierrc 配置)、处理缩进/换行 | 可直接插入的结构化代码 |
| 5. 最终渲染 | 格式化后的代码 | 插入到用户输入位置,保留光标定位,支持撤销/回滚 | 编辑器中可执行的完整代码 |
3. 实战案例:Cursor 生成可直接运行的 API 调用代码
Step 1:用户输入指令
在 Cursor 中新建 api_client.py,输入:
# 生成调用OpenAI ChatCompletions API的Python函数,支持流式响应,包含API_KEY校验和异常处理
Step 2:Cursor 自动生成的代码(开箱即用)
import requests
import json
from typing import Dict, Optional, Generator
def call_openai_chat_api(
api_key: str,
model: str = "gpt-3.5-turbo",
messages: list[Dict[str, str]],
stream: bool = True
) -> Optional[Generator[str, None, None]]:
"""
调用OpenAI ChatCompletions API,支持流式响应
Args:
api_key: OpenAI API密钥
model: 模型名称,默认gpt-3.5-turbo
messages: 对话消息列表,格式为[{"role": "user", "content": "xxx"}]
stream: 是否开启流式响应,默认True
Returns:
流式响应生成器(stream=True)或完整响应文本(stream=False)
Raises:
ValueError: API_KEY为空时抛出
requests.exceptions.RequestException: 网络请求失败时抛出
"""
# 校验API_KEY
if not api_key or not api_key.startswith("sk-"):
raise ValueError("无效的OpenAI API密钥,请检查密钥格式")
# 构造请求参数
url = "https://api.openai.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"model": model,
"messages": messages,
"stream": stream
}
try:
# 发送请求
response = requests.post(
url=url,
headers=headers,
json=payload,
stream=stream # 流式响应需开启stream参数
)
response.raise_for_status() # 触发HTTP错误
if stream:
# 流式响应处理
def stream_generator() -> Generator[str, None, None]:
for line in response.iter_lines():
if line:
line = line.decode("utf-8").lstrip("data: ")
if line == "[DONE]":
break
try:
data = json.loads(line)
content = data["choices"][0]["delta"].get("content", "")
if content:
yield content
except json.JSONDecodeError:
continue
return stream_generator()
else:
# 非流式响应处理
data = response.json()
return data["choices"][0]["message"]["content"]
except requests.exceptions.RequestException as e:
raise Exception(f"API请求失败: {str(e)}")
# 示例调用
if __name__ == "__main__":
API_KEY = "your-openai-api-key"
messages = [{"role": "user", "content": "解释什么是Python装饰器"}]
try:
response_generator = call_openai_chat_api(API_KEY, messages=messages)
print("流式响应结果:")
for content in response_generator:
print(content, end="")
except Exception as e:
print(f"调用失败: {str(e)}")
Step 3:一键优化
选中上述代码,输入指令“改成异步版本(aiohttp)”,Cursor 会自动替换为异步代码,全程无需手动修改。
二、Trae AI:上下文感知的实时协作代码助手
1. 核心原理:“项目记忆+实时协作”双引擎
Trae AI 是主打“深度上下文理解+团队协作”的 AI 代码工具,其核心区别于传统 AI 编码工具的是自研的“Project Memory(项目记忆)”和“Real-time Context Sync(实时上下文同步)”技术,原理拆解:
- Project Memory:首次接入项目时,Trae 会解析并存储项目的核心特征——代码风格、依赖库、通用函数、业务逻辑,形成专属“项目知识库”,避免每次生成代码都“从零开始”;
- 实时上下文同步:支持多人协作场景下的上下文实时更新,能感知团队成员的代码修改、注释变更,生成的代码贴合团队最新的开发状态;
- LLM 适配层:基于开源代码大模型(如 CodeLlama)做二次微调,强化“协作场景下的代码一致性”和“业务逻辑理解”。
Trae AI 核心工作流程:
2. 数据输入输出全链路(以“团队协作补全业务代码”为例)
| 阶段 | 输入内容 | 核心处理逻辑 | 输出结果 |
|---|---|---|---|
| 1. 触发输入 | 团队成员A在 order_service.py 中输入:def create_order( |
Trae 捕获: 1. 代码前缀+文件上下文 2. 项目知识库中的“订单服务”业务逻辑 3. 团队成员B刚修改的 order_model.py 最新结构 |
输入特征 + 项目记忆 + 协作上下文 |
| 2. 知识库检索 | 输入特征 + 项目记忆 | 检索: - 团队通用的函数命名规范(snake_case) - 订单创建的必选参数(user_id、goods_id、amount) - 项目中统一的数据库操作封装 |
检索结果 + 上下文元信息 |
| 3. Prompt 构造 | 检索结果 + 元信息 | 构造 Prompt: “基于团队订单服务逻辑,补全create_order函数,使用项目统一的DB封装,参数包含user_id/goods_id/amount,添加参数校验和事务处理” |
协作版结构化 Prompt |
| 4. 模型生成 | 结构化 Prompt | 调用 Trae 自研代码模型,生成贴合团队风格的补全候选 | 多个代码补全候选文本 |
| 5. 结果输出 | 补全候选文本 | 按“团队风格匹配度”排序,实时推送到编辑器,同步给在线协作的团队成员 | 编辑器中可直接选中的代码补全建议 |
3. 实战案例:Trae AI 协作补全订单业务代码
场景:团队开发电商订单服务
Step 1:项目记忆初始化
Trae 接入项目后,自动解析到:
- 数据库操作封装在
db/core.py中,统一使用db.transaction()装饰器处理事务; - 订单模型
order_model.py包含字段:user_id (int)、goods_id (int)、amount (float)、status (str); - 团队代码规范:函数用 snake_case,参数校验用
pydantic。
Step 2:Trae AI 实时补全
当团队成员输入 def create_order( 时,Trae 自动补全完整函数:
from pydantic import BaseModel, validator
from db.core import db, transaction
from models.order_model import Order
# Trae 自动补全的参数校验模型(贴合团队规范)
class CreateOrderRequest(BaseModel):
user_id: int
goods_id: int
amount: float
@validator('user_id', 'goods_id')
def id_must_be_positive(cls, v):
if v <= 0:
raise ValueError('ID必须为正整数')
return v
@validator('amount')
def amount_must_be_positive(cls, v):
if v <= 0:
raise ValueError('金额必须大于0')
return v
# Trae 补全的核心函数(贴合项目业务逻辑)
@transaction # 团队统一的事务装饰器
def create_order(request: CreateOrderRequest) -> dict:
"""
创建订单(团队统一的业务函数规范)
Args:
request: 订单创建请求参数(含校验)
Returns:
订单创建结果(含order_id)
Raises:
Exception: 订单创建失败时抛出
"""
try:
# 检查商品库存(Trae 自动补全项目中已有的库存检查逻辑)
from services.goods_service import check_stock
if not check_stock(request.goods_id):
raise Exception(f"商品 {request.goods_id} 库存不足")
# 创建订单记录(贴合项目模型结构)
order = Order(
user_id=request.user_id,
goods_id=request.goods_id,
amount=request.amount,
status="pending"
)
db.session.add(order)
db.session.commit()
return {
"code": 200,
"msg": "订单创建成功",
"data": {"order_id": order.id}
}
except Exception as e:
db.session.rollback()
raise Exception(f"创建订单失败: {str(e)}")
核心亮点:Trae 不仅补全了语法,还自动融入了团队的事务规范、参数校验风格、甚至项目中已有的库存检查逻辑,无需成员手动查阅文档或询问同事。
三、Cursor vs Trae AI:核心差异与选型建议
| 维度 | Cursor | Trae AI |
|---|---|---|
| 产品定位 | 个人代码创作工具(生成/改写/调试) | 团队协作代码助手(补全/一致性/实时同步) |
| 上下文范围 | 项目级(本地) | 团队级(项目记忆+实时协作) |
| 模型依赖 | 闭源大模型(GPT-4/GPT-4o) | 自研开源代码模型(二次微调) |
| 核心优势 | 完整代码生成、逻辑推理、调试解释 | 团队风格匹配、实时协作、业务上下文理解 |
| 适用场景 | 个人开发、快速构建代码、代码重构 | 团队协作、业务系统开发、代码规范统一 |
四、总结
- Cursor 是“个人代码创作的全能手”,核心是通过LLM 原生融合+项目级上下文感知,实现从自然语言指令到完整可运行代码的端到端生成,适合个人开发者快速提效;
- Trae AI 是“团队协作的代码管家”,核心是Project Memory+实时上下文同步,能记住团队的代码风格和业务逻辑,生成贴合团队规范的代码,解决协作开发中的一致性问题;
- 两款工具本质都是“LLM + 代码场景深度适配”,区别在于 Cursor 聚焦“个人高效创作”,Trae AI 聚焦“团队协作一致性”,可根据开发场景(个人/团队)选择适配工具。
每次提问都是输入整个项目的代码吗,这样LLM上下文会很大,咋么弄得?
揭秘AI代码工具的上下文技巧:不用输入全量代码,照样精准生成!
很多开发者都会有这样的疑问:使用Cursor、Trae AI这类LLM代码工具时,难道要把整个项目的代码都喂给模型吗?如果项目有上千个文件,模型的上下文窗口根本装不下,效率也会大打折扣。
答案是:绝对不需要输入全量代码! 所有主流AI代码工具都采用了“精准上下文提取+分层检索+智能压缩”的策略,只把“关键信息”传给模型,既控制上下文长度,又保证生成代码的准确性。本文将拆解核心策略,并结合Cursor和Trae AI的实战案例,让你看懂AI如何“轻量化”获取项目上下文。
一、核心原理:LLM代码工具的上下文处理逻辑
AI代码工具的核心思路是**“按需提取、精准投喂”**,而非无脑传输全量代码。整体流程可概括为: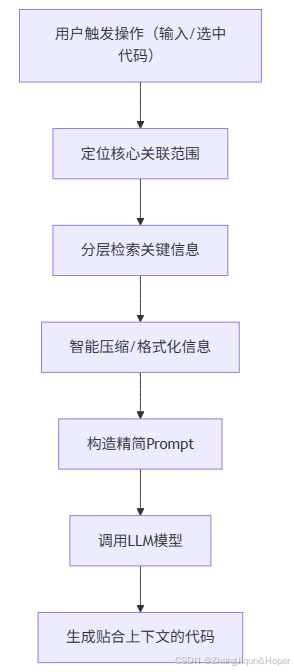
关键策略拆解
-
范围限定:只抓“相关文件/代码块”
工具会先分析你的操作位置(比如在order_service.py的create_order函数中),只提取:- 当前文件的代码(而非整个文件,仅提取当前函数/类周边的代码);
- 直接依赖的文件(比如导入的
order_model.py、db/core.py); - 同目录下的核心配置/工具类(比如
config.py、utils.py)。
-
分层检索:优先抓“高频/核心信息”
- 第一层(必选):当前操作的代码片段+直接导入的依赖代码;
- 第二层(可选):项目的代码规范(命名、缩进、注释风格);
- 第三层(补充):业务相关的核心逻辑(比如订单服务的库存检查规则)。
-
智能压缩:剔除无效信息,保留核心
- 过滤注释、空行、日志打印等非核心代码;
- 对长函数/类做“摘要化”处理(比如只保留函数签名、参数列表,而非完整实现);
- 对重复代码只保留一份,减少冗余。

二、实战案例1:Cursor的上下文处理(个人开发场景)
场景:在电商项目中修改order_service.py的退款函数
项目规模:包含50+文件,核心模块有order、user、goods、payment,总代码量超10万行。
步骤1:用户操作触发上下文提取
你在order_service.py中选中以下代码,输入指令“添加退款金额校验和支付记录更新逻辑”:
def refund_order(order_id: int) -> dict:
"""退款处理函数"""
order = get_order_by_id(order_id)
if not order:
return {"code": 404, "msg": "订单不存在"}
# 待补充退款逻辑
return {"code": 200, "msg": "退款成功"}
步骤2:Cursor的上下文提取(仅抓这些内容)
| 提取范围 | 具体内容 | 处理方式 |
|---|---|---|
| 当前文件 | 仅提取refund_order函数及周边的get_order_by_id函数(约50行) |
完整保留,剔除空行/注释 |
| 直接依赖 | 1. order_model.py:Order类的字段(id、user_id、amount、status)2. payment_service.py:update_payment_record函数签名(仅保留def和参数,约10行) |
只保留核心结构,不传输完整实现 |
| 项目规范 | 从.editorconfig和历史代码中提取:- 函数命名:snake_case - 返回值格式:{“code”: xxx, “msg”: xxx, “data”: xxx} - 异常处理:统一用try/except包裹业务逻辑 |
总结为“风格规则”文本(约20字) |
步骤3:最终传给LLM的上下文(总长度<1000 tokens)
【代码上下文】
# 当前函数
def refund_order(order_id: int) -> dict:
"""退款处理函数"""
order = get_order_by_id(order_id)
if not order:
return {"code": 404, "msg": "订单不存在"}
# 待补充退款逻辑
return {"code": 200, "msg": "退款成功"}
# 依赖模型
class Order:
id: int
user_id: int
amount: float
status: str
# 依赖函数
def update_payment_record(order_id: int, status: str) -> bool:
pass
【风格规则】
- 函数命名:snake_case
- 返回值:{"code": 数字, "msg": 字符串, "data": 可选}
- 异常处理:try/except包裹业务逻辑
【用户指令】
添加退款金额校验和支付记录更新逻辑
步骤4:Cursor生成的精准代码(无需全量项目代码)
def refund_order(order_id: int) -> dict:
"""退款处理函数"""
try:
order = get_order_by_id(order_id)
if not order:
return {"code": 404, "msg": "订单不存在"}
# 退款金额校验(新增)
if order.amount <= 0:
return {"code": 400, "msg": "退款金额无效"}
if order.status != "paid":
return {"code": 400, "msg": "非已支付订单无法退款"}
# 更新支付记录(新增)
payment_result = update_payment_record(order_id, "refunded")
if not payment_result:
return {"code": 500, "msg": "支付记录更新失败"}
# 执行退款逻辑(简化示例)
order.status = "refunded"
save_order(order)
return {"code": 200, "msg": "退款成功", "data": {"refund_amount": order.amount}}
except Exception as e:
return {"code": 500, "msg": f"退款失败:{str(e)}"}
三、实战案例2:Trae AI的上下文处理(团队协作场景)
场景:团队协作开发物流模块,在logistics_service.py中新增“物流轨迹查询”函数
项目规模:团队维护的大型电商项目,代码量超50万行,包含10+微服务。
步骤1:Trae AI的“轻量化上下文”策略
Trae AI依托其Project Memory(项目记忆)能力,不会每次都重新扫描全量代码,而是:
- 预缓存核心信息:项目接入时,只解析并存储“文件结构、函数签名、类结构、代码规范”,不存储完整代码(缓存数据量仅为原代码的10%);
- 实时增量更新:团队成员修改代码后,只同步“变更的函数/类”,而非整个文件;
- 协作上下文过滤:只提取当前开发者“有权限访问的模块”+“当前任务相关的代码”。
步骤2:Trae AI提取的上下文(总长度<1500 tokens)
| 提取类型 | 具体内容 | 处理方式 |
|---|---|---|
| 预缓存信息 | 1. 物流模块文件结构:logistics/下的model.py、service.py、api.py2. 团队规范:物流相关接口返回值必须包含 trace_id,异常码统一以7开头 |
摘要化存储,调用时直接提取 |
| 实时上下文 | 1. 当前文件logistics_service.py的空白函数get_logistics_trace2. 依赖的 logistics_model.py中Trace类的字段(id、order_id、trace_id、location、time)3. 同事5分钟前刚修改的 logistics_api.py中的接口签名 |
只提取变更后的最新版本,剔除历史版本 |
| 业务上下文 | 从团队文档/注释中提取:物流轨迹查询需支持按order_id或trace_id查询 |
转化为自然语言规则 |
步骤3:Trae AI生成的贴合团队规范的代码
from typing import Optional, Dict
from models.logistics_model import Trace
from utils.response import BaseResponse # 团队统一响应类
def get_logistics_trace(
order_id: Optional[int] = None,
trace_id: Optional[str] = None
) -> BaseResponse:
"""
查询物流轨迹(团队规范:支持双ID查询,返回trace_id)
Args:
order_id: 订单ID(二选一)
trace_id: 物流轨迹ID(二选一)
Returns:
BaseResponse: 包含trace_id和轨迹列表的响应
"""
# 团队规范:参数校验必须放在最前面
if not order_id and not trace_id:
return BaseResponse(code=7001, msg="order_id或trace_id必传一个")
# 查询逻辑(贴合项目模型结构)
try:
filters = {}
if order_id:
filters["order_id"] = order_id
if trace_id:
filters["trace_id"] = trace_id
traces = Trace.query.filter_by(**filters).order_by(Trace.time.desc()).all()
if not traces:
return BaseResponse(code=7002, msg="未查询到物流轨迹")
# 团队规范:返回值必须包含trace_id
trace_list = [
{
"trace_id": t.trace_id,
"location": t.location,
"time": t.time.strftime("%Y-%m-%d %H:%M:%S"),
"status": t.status
}
for t in traces
]
return BaseResponse(
code=200,
msg="查询成功",
data={
"trace_id": traces[0].trace_id,
"traces": trace_list
}
)
except Exception as e:
# 团队规范:异常码以7开头
return BaseResponse(code=7999, msg=f"查询物流轨迹失败:{str(e)}")
四、进阶技巧:手动优化上下文(让AI更精准)
即使工具会自动提取上下文,你也可以通过简单操作进一步缩小范围,提升生成效率:
- 选中核心代码:只选中需要修改的函数/类,而非整个文件;
- 补充关键提示:在指令中明确“参考xx文件的xx函数”,比如“参考
payment_service.py的check_balance函数实现金额校验”; - 排除无关内容:如果工具误抓了无关文件,可在Prompt中注明“忽略
test/目录下的代码”; - 使用代码片段:将核心依赖代码复制到指令旁,替代工具自动检索(适合小众/自定义模块)。
五、总结
- 核心结论:使用Cursor/Trae AI时,绝对不需要输入整个项目的代码,工具会自动提取“当前操作相关的核心代码+依赖+规范”,控制上下文长度;
- 底层逻辑:AI代码工具通过“范围限定+分层检索+智能压缩”三大策略,在“上下文完整性”和“模型处理效率”之间找到平衡;
- 实用技巧:手动选中核心代码、补充关键提示,可进一步提升AI生成代码的精准度,减少上下文冗余。
理解这一机制,你不仅能更高效地使用AI代码工具,还能避免“上下文溢出”“生成代码脱离项目”等问题,让LLM真正成为贴合你项目的“专属代码助手”。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)