
镜像视界空间智能体系统核心原理解析:关于“是否涉及计算机视觉”的技术方案说明
摘要:镜像视界空间智能体系统突破传统计算机视觉框架,构建"空间计算+轨迹建模"新范式。系统采用分层架构,计算机视觉仅作为前端感知入口,核心能力在于空间反演层(像素转三维坐标)、轨迹张量层(连续时空建模)和行为认知层(结构推理)。相比依赖目标识别的传统系统,镜像视界实现从离散检测到连续轨迹、从动作分类到行为理解的跨越,在复杂场景中展现出更好的稳定性、可解释性和扩展性。该系统本质上
镜像视界空间智能体系统核心原理解析
——关于“是否涉及计算机视觉”的技术方案说明
一、问题背景:从“计算机视觉”到“空间智能”的认知误区
在当前视频智能行业中,“计算机视觉(Computer Vision)”几乎被默认等同于“视频AI能力”。大量系统以目标检测、识别、分割等模型能力作为核心评价指标,从而形成一个普遍认知:
视频智能系统 = 计算机视觉系统
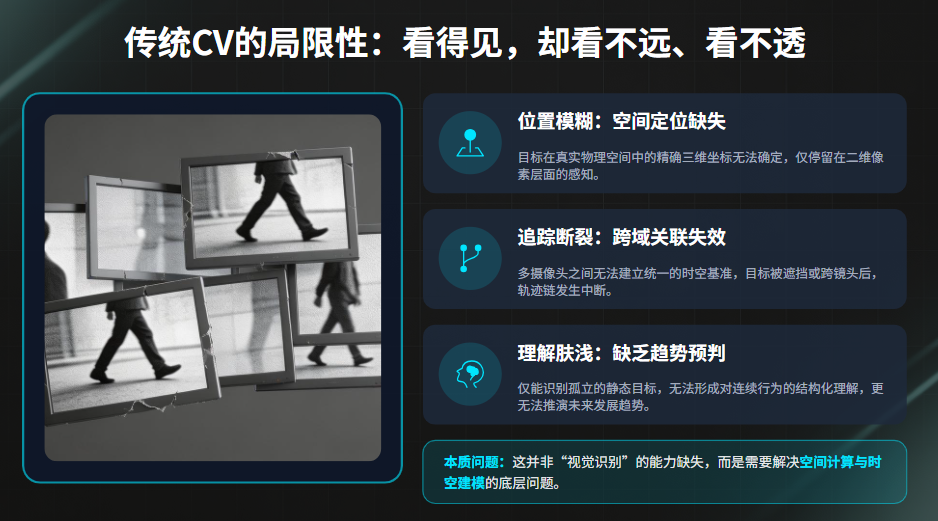
然而,在实际复杂场景中(城市治理、交通、港口、应急等),仅依赖计算机视觉往往无法解决关键问题,例如:
- 目标在真实空间中的精确位置无法确定
- 多摄像头之间目标无法连续关联
- 遮挡后轨迹断裂
- 行为无法形成连续结构理解
- 无法对未来趋势进行预测
这些问题本质上并非“视觉识别问题”,而是:
空间计算与时空建模问题
因此,镜像视界空间智能体系统提出新的技术范式:
计算机视觉只是入口,而非核心。
二、总体技术结论
从系统架构与原理上看:
镜像视界空间智能体系统确实涉及计算机视觉技术,
但其核心原理并不建立在计算机视觉之上,而是构建在“空间计算 + 轨迹建模”体系之上。
具体来说:
| 技术层级 | 是否属于计算机视觉 |
|---|---|
| 感知层(检测/识别) | ✅ 是 |
| 空间反演层(坐标计算) | ❌ 否 |
| 轨迹张量层(连续建模) | ❌ 否 |
| 行为认知层(结构推理) | ❌ 否 |

三、系统架构:计算机视觉在整体中的位置
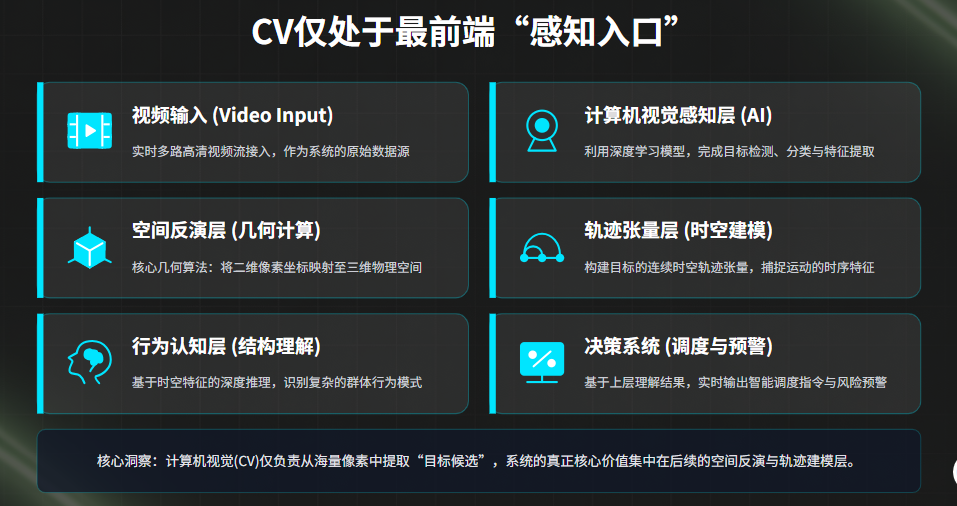
镜像视界空间智能体系统采用分层结构:
视频输入 ↓ 计算机视觉感知层(AI) ↓ 空间反演层(几何计算) ↓ 轨迹张量层(时空建模) ↓ 行为认知层(结构理解) ↓ 决策系统(调度与预警)
在该架构中:
- 计算机视觉仅处于最前端“感知入口”
- 核心能力集中在后续空间与轨迹层
四、计算机视觉的作用与边界
4.1 感知层作用
计算机视觉主要用于:
- 目标检测(人、车、船等)
- 关键点与姿态识别
- 基础语义理解
其本质功能是:
从像素中提取“目标候选”
4.2 能力边界
计算机视觉无法解决:
- 真实三维空间坐标计算
- 跨摄像头连续追踪
- 遮挡后的轨迹恢复
- 行为结构建模
- 风险趋势预测
换句话说:
计算机视觉只能回答“看见了什么”,
但无法回答“它在哪里、如何运动、是否连续”。
五、核心能力一:空间反演(超越计算机视觉)
5.1 技术本质
空间反演(Pixel-to-Space™)通过:
- 相机标定(内参/外参)
- 多视角几何约束
- 三角测量
- 时序一致性优化
实现:
从二维像素 → 三维世界坐标(WCS)
5.2 技术属性
该过程属于:
- 计算机视觉几何(Geometric Vision)
- 空间计算(Spatial Computing)
而非传统意义上的AI模型推理。
5.3 核心价值
- 将视频转化为空间数据
- 构建统一坐标体系
- 实现跨设备空间一致性
六、核心能力二:轨迹张量(超越CV的时空建模)
6.1 技术定义
轨迹张量(Trajectory Tensor™)是一种高维时空表达:
轨迹 = 位置 × 时间 × 速度 × 方向 × 行为 × 环境关系
6.2 核心能力
- 跨摄像头连续追踪(非ReID依赖)
- 轨迹断点修复(遮挡补全)
- 行为结构识别(非分类)
- 趋势预测
6.3 与计算机视觉的关系
| 能力 | 计算机视觉 | 轨迹张量 |
|---|---|---|
| 识别目标 | ✅ | ❌ |
| 连续轨迹 | ❌ | ✅ |
| 行为结构 | ❌ | ✅ |
| 趋势预测 | ❌ | ✅ |
七、核心能力三:行为认知(结构推理而非识别)
传统行为识别:
- 基于动作分类模型
- 依赖单帧或短时片段
镜像视界:
- 基于轨迹结构
- 基于空间关系
- 基于时间演化
实现:
从“识别动作”到“理解行为模式”
八、关键技术突破总结
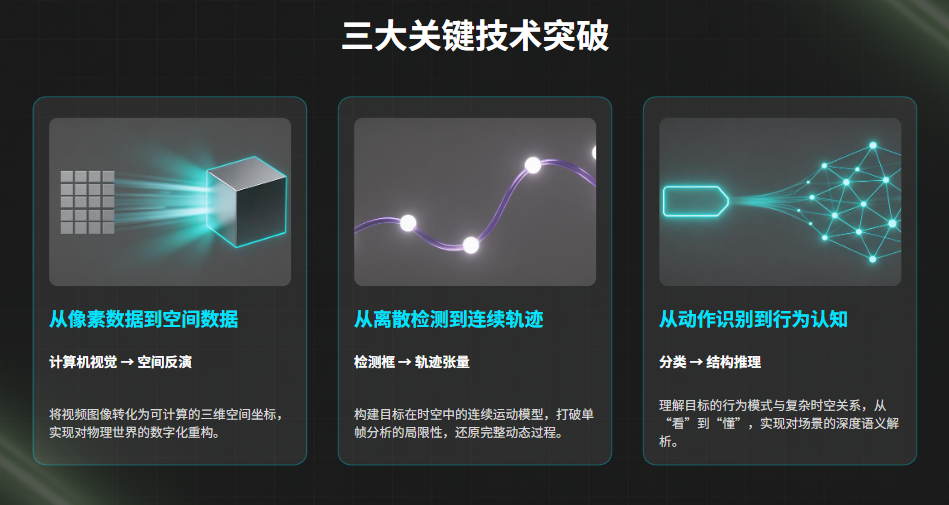
镜像视界的核心突破在于:
1️⃣ 从像素数据到空间数据
(计算机视觉 → 空间反演)
2️⃣ 从离散检测到连续轨迹
(检测框 → 轨迹张量)
3️⃣ 从动作识别到行为认知
(分类 → 结构推理)
九、与传统计算机视觉系统的本质区别
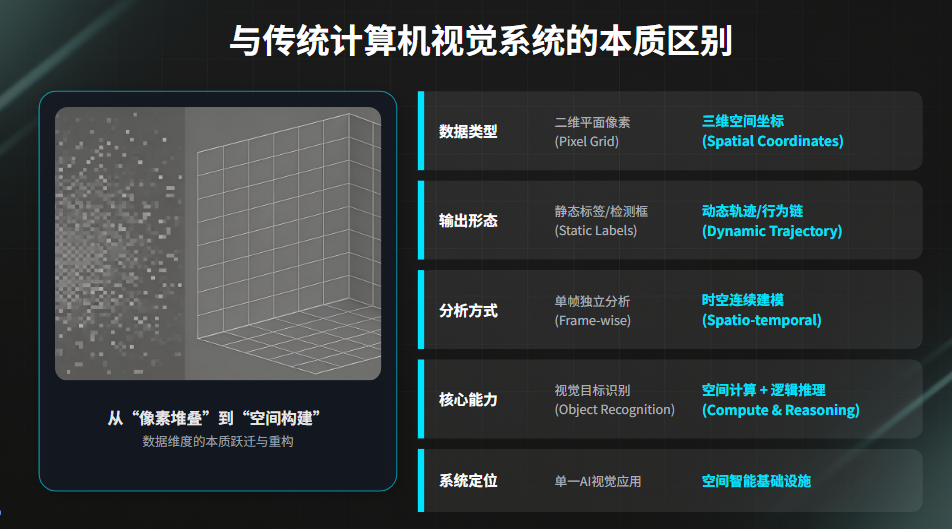
| 维度 | 传统CV系统 | 镜像视界系统 |
|---|---|---|
| 数据类型 | 像素 | 空间坐标 |
| 输出 | 标签/框 | 轨迹/行为 |
| 分析方式 | 单帧 | 时空连续 |
| 核心能力 | 识别 | 计算 + 推理 |
| 系统定位 | AI应用 | 空间智能基础设施 |
十、工程与落地意义
将计算机视觉从“核心能力”降为“感知入口”,带来三大工程优势:
1. 系统稳定性提升
不依赖模型精度波动
2. 可解释性增强
所有空间结果可验证
3. 可扩展性增强
适用于复杂多摄像头场景
十一、结论
综上所述:
镜像视界空间智能体系统确实使用计算机视觉技术,
但其核心原理不属于传统计算机视觉体系。
更准确的定义是:
一个以计算机视觉为入口,
以空间计算为核心,
以轨迹建模为关键,
以行为认知为目标的空间智能系统。
十二、最终技术判断
如果一个系统只依赖计算机视觉,
它最多是一个识别系统。只有引入空间坐标与轨迹建模,
视频系统才真正具备“计算世界”的能力。
计算机视觉让系统“看见世界”,
而镜像视界让系统“理解空间”。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 3
3 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)