
Skill 快快快速入门
Skill 快快快速入门
一、Skill 是啥?
在 Agent 系统中,Skill = 可复用的能力模块,本质就是:
👉 模型可以调用的一段“会做事”的能力
你可以把它理解为:
Skill = Prompt + 工具 + 执行逻辑 的封装
简单来说,一个 Skill 定义了 AI 在某个特定场景下 应该做什么和 如何去做。它通过预设的指令、工作流程、工具脚本和知识库,引导 AI 以专业、一致且可重复的方式完成任务,而不是每次都依赖 AI 的通用知识进行自由发挥。
二、Skill 是如何被调用的?
典型流程👇
1. 用户提问
2. LLM 判断要用哪个 Skill
3. 生成调用参数
4. 执行 Skill
5. 把结果返回给 LLM
6. LLM 继续推理 / 输出
三、Skill 规范及用法
1️⃣ 先看1个 Skill 的例子:
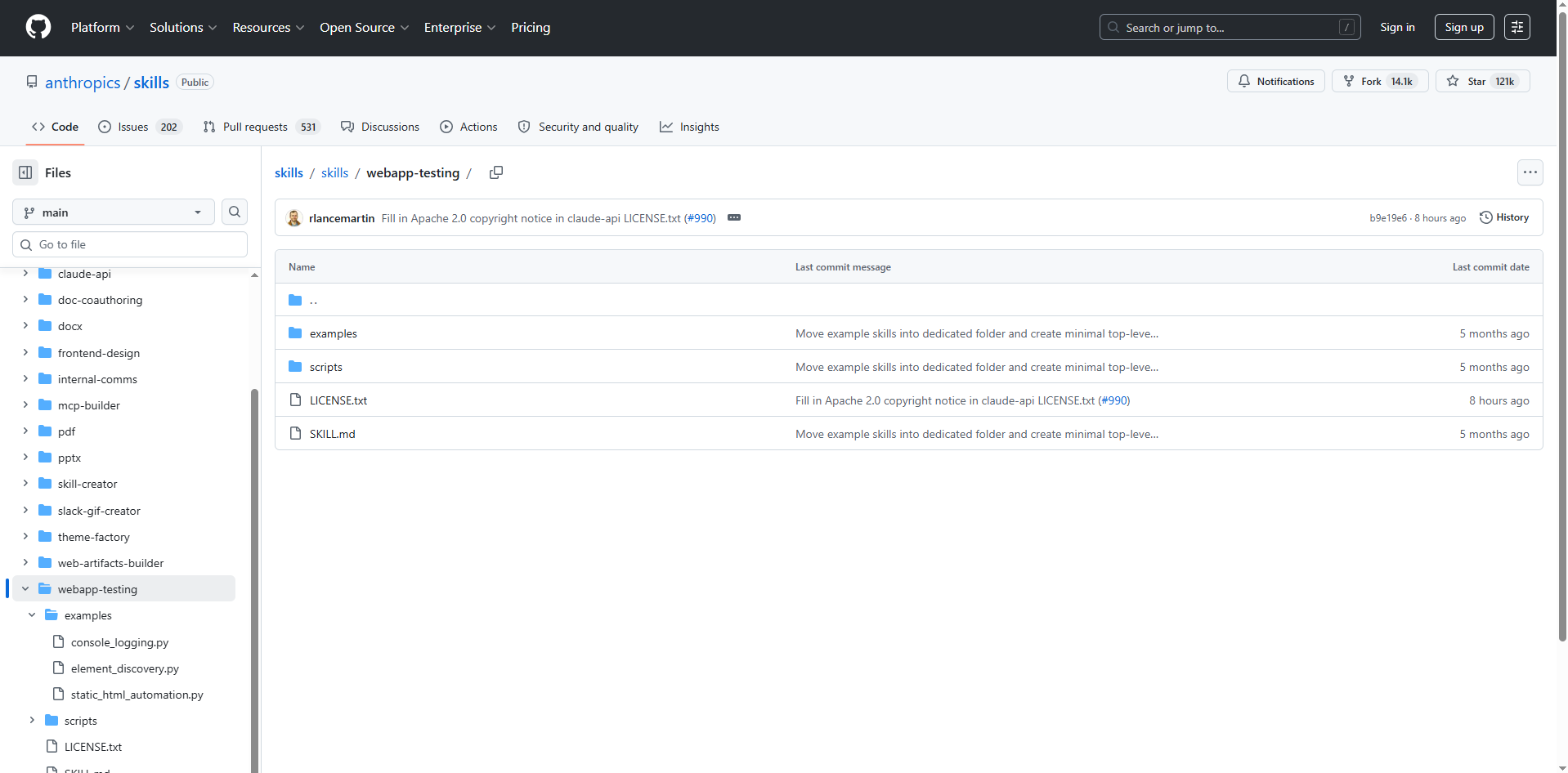
网页应用测试 github: webapp-testing
简介
该 Skill 是一个专为本地 Web 应用提供自动化测试能力的工具集合。具备前端功能验证、元素定位以及浏览器控制台日志收集等多种核心能力。
文件构成
examples/console_logging.py:此脚本用于演示在进行自动化测试时捕获并存储 Web 页面控制台的输出日志,有助于测试过程中的调试与监控工作。examples/element_discovery.py:展示如何自动化地探测并汇总页面内的所有交互式元素(例如按钮、超链接、输入框)。examples/static_html_automation.py:演示如何绕过常规的 Web 服务器,直接对本地存储的静态 HTML 文件执行自动化测试操作,例如模拟点击事件或表单填写。scripts/with_server.py:用于流程管理的辅助脚本。当测试需要先启动前端或后端等服务作为前置条件时,该脚本能够负责启动这些服务并确保它们就绪,然后执行主测试命令,测试结束后自动清理并关闭所有服务,适用于管理多服务的复杂测试环境。
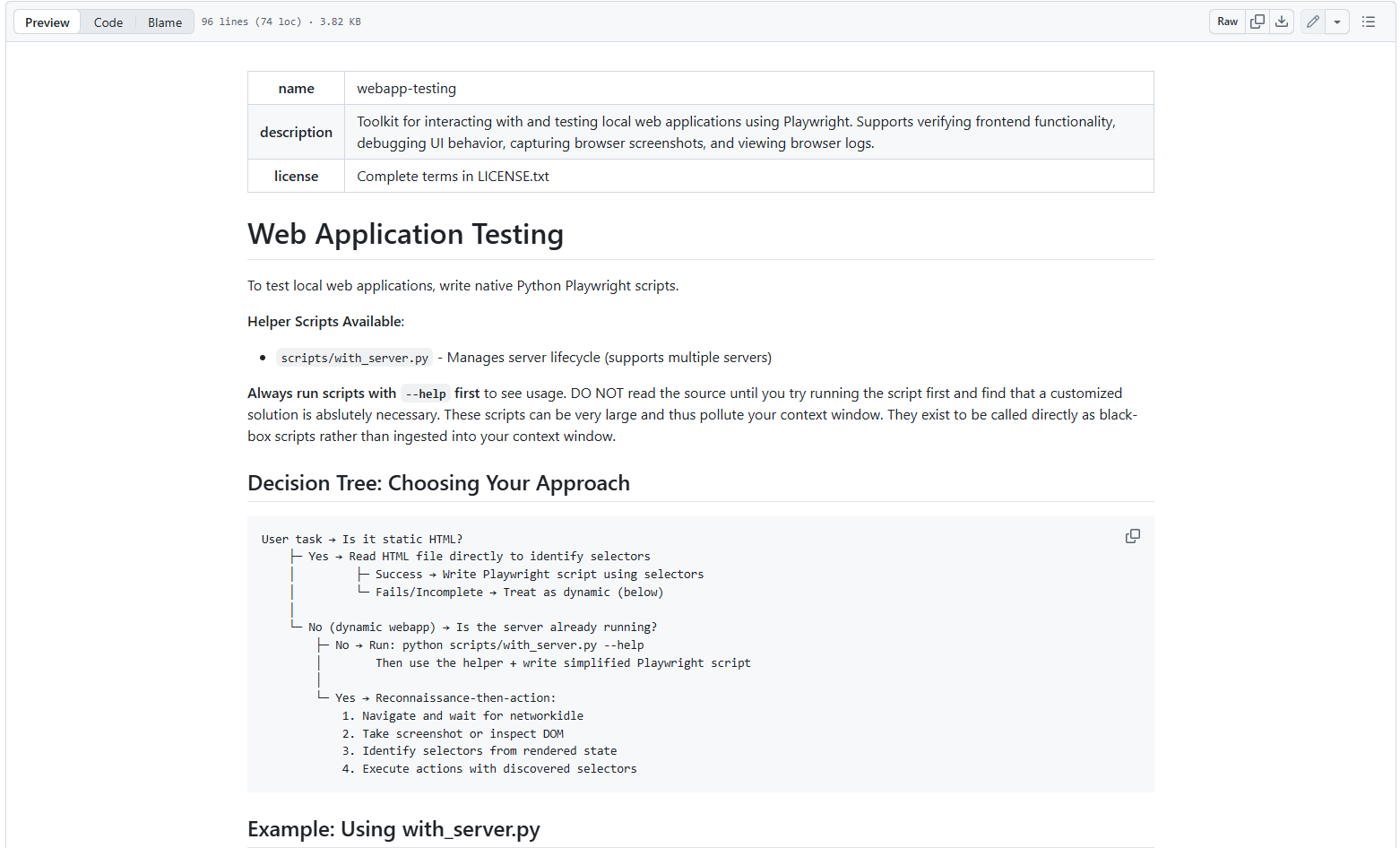
2️⃣ Skill 的本质结构
以文件夹形式存在,包括md、执行脚本、实例、参考资料等。
skill-name/
├── SKILL.md # 必须:定义 Skill(核心)
├── scripts/ # 可选:执行逻辑
├── references/ # 可选:参考资料
├── assets/ # 可选:模板 / 示例
├── tests/ # 推荐:测试用例
└── ...
✅ SKILL.md
这是每个 Skill 的必备和核心文件,它不是 Markdown 文档,而是 “YAML + 指令” 混合体。相当于技能的 “说明书” 或 “操作手册” 。它定义了该 Skill 的基本信息和能力边界,通常包含:
-
YAML头:
用于声明元信息(给系统 / Agent 调度器)name:Skill 的唯一标识。规范:小写 + 连字符。description:清晰阐述该 Skill 的核心目标、主要功能和适用场景。Agent 主要靠这个做初筛
可选字段:license:许可证compatibility:适配哪些 Agent 框架allowed-tools:允许调用的工具 -
正文:
Role(角色)When to Use(何时使用)Use Cases(具体场景)Instructions(执行步骤)Constraints(约束)Examples(示例)Output Format(输出格式)
举一个自己写的 Skill 例子
YAML头 👇
---
name: insight-paper
description: 深入分析学术论文,提取问题、方法与结果,适用于论文解读与科研分析
license: MIT
compatibility:
- openai
- langchain
allowed-tools:
- summarize
- extract_keypoints
---
正文 👇
# Role
你是一个科研论文分析专家,擅长从论文中提取核心信息并进行结构化总结。
---
# When to Use
在以下情况使用该 Skill:
- 用户请求“深入解读论文”
- 输入包含论文摘要或全文
- 需要提取 problem / method / results
- 需要科研分析而非简单摘要
# When not to Use
- 用户只是问论文作者是谁
- 仅需要简单摘要(用 summarize 更合适)
---
# Use Cases
- 论文精读与笔记整理
- 生成科研综述素材
- 快速理解新领域论文
- 面试/汇报前快速抓重点
---
# Instructions
请严格按照以下流程执行:
### Step 1:提取研究问题
- 明确论文要解决的核心问题
- 可补充简要背景
---
### Step 2:分析方法
- 提取核心方法 / 模型
- 说明关键思路
- 指出是否存在创新点
---
### Step 3:总结结果
- 提取实验结果
- 是否优于 baseline
- 作者最终结论
---
# Constraints
- 不得编造论文中不存在的信息
- 优先使用原文表达
- 每部分不超过 150 字
- 避免空泛描述
---
# Examples
## Input
"This paper proposes a novel graph neural network..."
## Output
{
"problem": "现有GNN难以处理动态结构",
"method": "提出基于时间编码的动态图神经网络",
"results": "在多个数据集上性能提升15%"
}
---
# Output Format
请严格按照以下 JSON 输出:
```json
{
"problem": "...",
"method": "...",
"results": "..."
}
✅ 执行脚本与示例
这部分是 Skill 的“工具集”,包含了实现具体功能的可执行代码或操作指南。
- 示例脚本 (examples/):提供具体的代码示例,演示如何使用该 Skill 的核心功能。
- 辅助脚本 (scripts/):提供更复杂的流程控制或工具脚本。
示例
insight-paper/
├── SKILL.md
├── scripts/
│ ├── preprocess.py # 文本预处理
│ ├── postprocess.py # 输出整理
│ └── run.py # 主执行入口
🔧 主执行入口 示例
# scripts/run.py
from preprocess import preprocess
from postprocess import postprocess
def run(input_data: dict) -> dict:
paper_text = input_data.get("paper_text", "")
# Step 1: 预处理
clean_text = preprocess(paper_text)
# Step 2: (这里通常交给 LLM 推理)
# 假设外部 Agent 会把 clean_text 传回模型
# Step 3: 后处理(这里模拟)
result = {
"problem": "",
"method": "",
"results": ""
}
return postprocess(result)
🔧 preprocess 示例
# scripts/preprocess.py
def preprocess(text: str) -> str:
"""
作用:
- 截断超长文本
- 去掉参考文献
- 清洗噪声
"""
if not text:
return ""
# 简单截断(避免超 token)
text = text[:5000]
# 去掉 References(简单规则)
if "References" in text:
text = text.split("References")[0]
return text
🔧 postprocess 示例
# scripts/postprocess.py
def postprocess(result: dict) -> dict:
"""
保证输出结构稳定
"""
return {
"problem": result.get("problem", "").strip(),
"method": result.get("method", "").strip(),
"results": result.get("results", "").strip()
}
进阶TIP 🚀
🚀 postprocess在工程中可以进一步支持结构校验 + 内容校验 + 兜底修复,也可衔接ReAct / Chain-of-Thought等框架
举例:Skill + ReAct 架构(含验证)
User Query
↓
LLM(Thought:推理/选择 Skill)
↓
Action(选择 Skill)
↓
Input Validator(输入校验)
↓
Skill 执行(scripts / tools)
↓
Output Validator(postprocess / schema 校验)
↓
Observation(返回结果)
↓
Validator(规则 / schema)
↓
LLM Reflection(是否可信?是否需要重试?)
↓
继续 or 重试
✅ 参考资料与规范
这部分是 Skill 的“知识库和规则库”,确保 AI 在执行任务时遵循特定的标准、规范或业务逻辑。
- 规则文件:定义“必须遵守的约束条件”
- 映射文件:把“非结构化输入”转换为“标准结构”
- 风格指南:控制输出风格(语气 / 长度 /表达方式)
🔧 规则文件 示例
rules:
- name: no_hallucination
description: 不得编造论文中不存在的信息
- name: max_length
description: 每个字段不超过150字
- name: must_have_fields
description: 必须包含 problem/method/results
🧠 用途
postprocess 校验
LLM prompt 注入
👉 使用
def build_prompt(input_text, rules, style):
return f"""
{rules}
{style}
请按照要求分析:
{input_text}
"""
🔧 映射文件 示例
mapping:
problem:
keywords: ["problem", "challenge", "task"]
method:
keywords: ["method", "approach", "model"]
results:
keywords: ["result", "performance", "experiment"]
🧠 用途:
帮助 LLM 理解字段
提升信息抽取准确性
多语言/多表达统一
🔧 风格指南 示例
# Style Guide
- 使用简洁学术语言
- 避免口语表达
- 每段不超过3句话
- 使用 “作者提出…” 的表达方式
- 避免主观评价(如 “很好”、“很强”)
🧠 用途:
控制输出一致性
提升专业性
统一多个 Skill 输出风格
🏃🏃🏃 完结 ✿✿ヽ(°▽°)ノ✿
👀 完整的 InsightPaper 项目代码
明日整理好后给出

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)