
能“主动记忆”“自我复盘”的智能体:MemSkill 框架开源,以“自主进化”提升 AI 长任务表现
它不再单纯依赖人工硬编码的规则,而是让智能体在不断的交互中,自动提炼并完善管理记忆的方法论。02技术拆解:这套“自进化记忆”是怎么跑通的?2026 年伊始,我们终于看到了在“智能体记忆”这个老大难问题上的硬核创新。过去我们谈记忆,无非是 RAG(检索增强生成)或者简单的滑动窗口。但南洋理工和清华等团队推出的。

资源导航:
-
• • 论文链接:https://arxiv.org/html/2602.02474v1
-
• • 项目主页:https://github.com/ViktorAxelsen/MemSkill
-
• • GitHub Repo:https://github.com/ViktorAxelsen/MemSkill
-
• • Hugging Face: 相关代码与模型权重建议关注 GitHub 更新
-
• • 发布机构: 南洋理工大学、伊利诺伊大学厄巴纳-香槟分校、伊利诺伊大学芝加哥分校、清华大学联合团队
-
• • 发布日期: 2026年2月
-
• • 开源协议: 遵循 GitHub 仓库具体 License
最近 OpenClaw 这类自动化智能体(Agent)凭借超强的执行力刷屏,随着以 OpenClaw 为代表的自动化智能体(Agent)在执行端(Action Skills)展现出极强的工业价值,Agent 在复杂长任务中的稳定性正受到更多关注。然而,当交互路径拉长,如何让智能体在海量日志中精准保留关键约束,依然是一个技术挑战。
目前的工业级方案(如 Mem0、MemoryOS)以及学术界常用的 MemoryBank,主要采用人工设计的静态逻辑来管理信息(如:事实提取、定期清理)。这种基于先验规则的记忆管理在面对多变的交互场景时,往往显得不够灵活。
近期,来自南洋理工大学、清华大学、伊利诺伊大学(UIUC/UIC)等高校的联合团队发布了名为 MemSkill 的研究框架。该论文提供了一个新颖的视角:将记忆管理从“固定流程”转变为“可学习、可进化的技能(Memory Skills)”。
如果说 OpenClaw 的核心贡献在于提供了丰富的执行技能(如网页、文件、通讯操作),那么 MemSkill 则是在探索如何让智能体通过“记忆技能”来自主进化其存储和检索策略。这不仅是记忆管理方式的改变,更是试图通过闭环优化,让智能体在执行任务的过程中,学会如何更聪明地“记笔记”。 MemSkill 并非专为某一特定 Agent 框架设计,其展现出的自适应记忆能力,为解决长路径任务中的“健忘”问题提供了一个极具参考价值的学术思路。
01
项目定位:MemSkill 到底是用来干什么的?
简单来说,MemSkill 是给大模型(LLM)智能体装上了一套“可以自我进化”的记忆管理系统。
目前的 LLM 智能体在面对超长对话或复杂任务时,记忆管理往往非常死板。开发者通常手动编写一套固定的逻辑(比如:提取摘要、存入数据库、根据关键词检索)。这种做法在简单场景下是“基操”,但一旦历史记录变长、交互变复杂,系统就会变得非常低效,且容易丢掉关键信息。
MemSkill 的核心突破在于:它把记忆操作(如提取、整合、修剪信息)重新定义为一种“可学习且可进化”的记忆技能(Memory Skills)。 它不再单纯依赖人工硬编码的规则,而是让智能体在不断的交互中,自动提炼并完善管理记忆的方法论。
02
技术拆解:这套“自进化记忆”是怎么跑通的?
2026 年伊始,我们终于看到了在“智能体记忆”这个老大难问题上的硬核创新。过去我们谈记忆,无非是 RAG(检索增强生成)或者简单的滑动窗口。但南洋理工和清华等团队推出的 MemSkill,思路完全不同。
它是那种既有控制理论影子,又把强化学习(RL)玩得很丝滑的方案。咱们老规矩,先拆架构,再看实测。
1. 从“固定操作”到“技能抽象”的范式转移(Section 1)
在传统的管道(Pipeline)中,智能体管理记忆的行为是“写死”的。比如(Figure 1a)展示的传统方案:每一轮对话(Turn-level)都要通过 LLM 调用手工设计的操作。这不仅费 Token,而且面对数据分布偏移时非常脆弱。
MemSkill 提出了三个核心属性(Section 1):
-
• • 极简的人工先验:不再手动教模型什么值得记,而是让交互数据来决定记忆边界。
-
• • 支持更大的提取粒度:不再局限于“逐轮”处理,而是能处理更长的文本跨度(Span/Chunk),这在处理几十万 Token 的历史时是刚需。
-
• • 技能驱动的组合式构建:在一个生成步骤中组合多种相关技能。
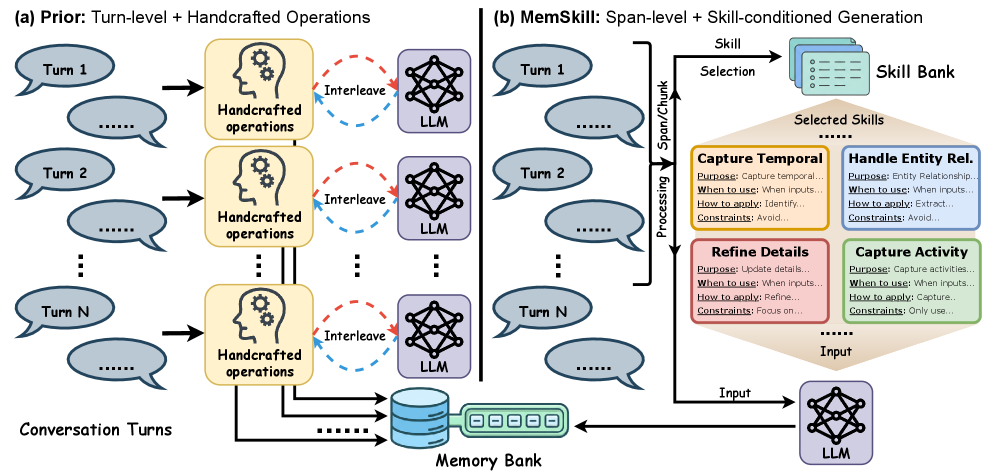

Figure 1:传统方案(左)与 MemSkill(右)的范式对比。MemSkill 采用跨度级处理,通过技能银行动态选择技能,显著提升了效率和连贯性。
2. “三位一体”的核心架构:控制器、执行器与设计器
MemSkill 的闭环逻辑非常硬核(见 Figure 2)。它由三个主要组件构成:
-
• • 控制器 (Controller - 策略大脑):
它负责“看人下菜碟”。基于当前上下文和已检索的记忆,通过状态嵌入与技能描述的向量点积(Dot Product)计算,从技能银行中精准匹配出 Top-K 个最合适的技能。它采用 PPO 算法进行强化学习优化(Section 3.3.1)。
-
• • 执行器 (Executor - 搬砖工人):
这是一个固定的 LLM 模块。它拿到控制器给出的技能说明,直接针对当前文本片段执行操作(Section 3.3.2)。这种设计让复杂的逻辑在一个生成步内就能完成,极其高效。
-
• • 设计器 (Designer - 架构导师):
这是 MemSkill 能够“自进化”的关键。它会定期复盘那些失败案例(Section 3.4),利用 LLM 分析为什么现有的技能没处理好,然后自动修改旧技能或提出全新的技能。
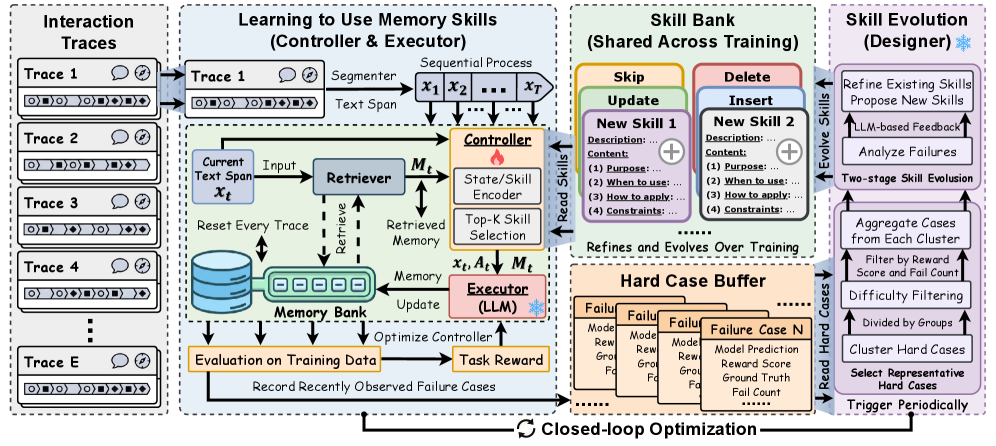

Figure 2:MemSkill 架构全景图。展示了从交互轨迹到技能选择,再到设计师根据硬例(Hard Cases)进化技能库的全过程。
3. 闭环优化机制(Section 3.5)
MemSkill 并不是训一次就完了。它在(i)学习如何选择技能和(ii)进化技能库本身之间交替进行。 (这种思路有点像人类:我先学会用现有的工具,如果工具不好用,我再自己反思一下,发明个新工具。不得不说,这种自监督的逻辑闭环非常精妙。)
03
“有什么用”:实战表现与跨领域泛化
为了客观验证 MemSkill 的成色,团队在四个极具代表性的 Benchmark 上进行了横推测试:LoCoMo、LongMemEval、HotpotQA 和 ALFWorld(Section 4.1)。
1. 跨模型、跨数据集的“降维打击”
在对话场景(LoCoMo)和长文本场景下,MemSkill 面对一众强竞品展现出了明显的代差优势。
Table 1:LoCoMo、LongMemEval 和 ALFWorld 的主实验结果对比。
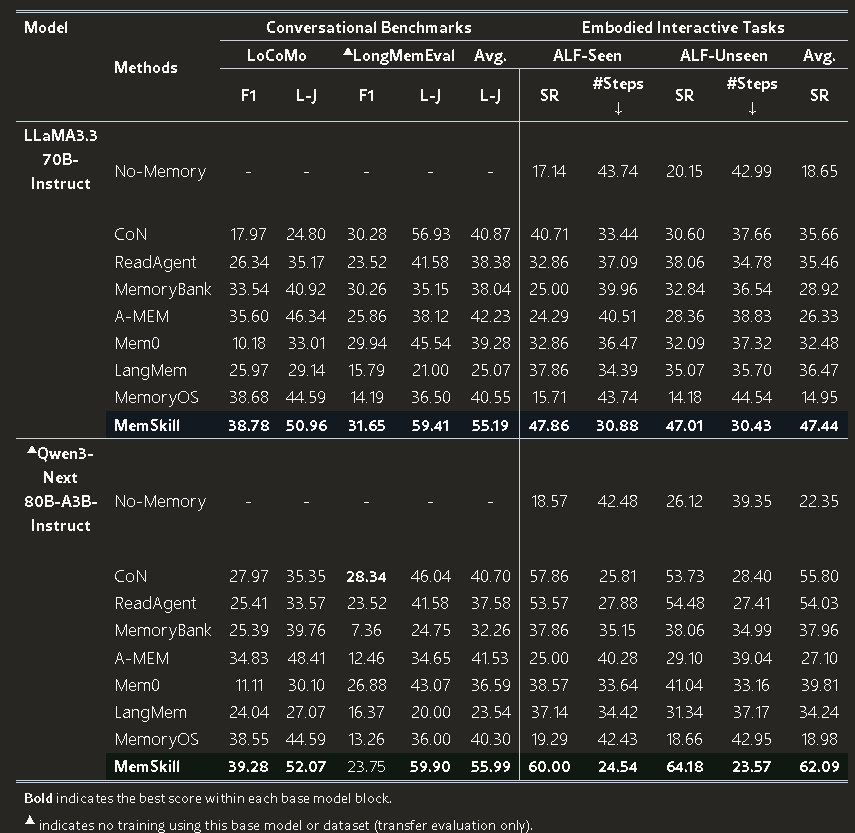
(数据来源:论文 Table 1,L-J 代表 LLM Judge 评分,SR 代表成功率。注意:MemSkill 在 LLaMA3.3 和 Qwen3 两个 block 里均拿到了 Bold 最佳成绩)
客观解读: 你会发现,在反映记忆质量的关键指标 LLM-Judge (L-J) 上,MemSkill 在不同底座模型下均取得了全场最高分(SOTA)。特别是在具身智能任务(ALFWorld)中,它相比传统 RAG 方案表现出了极强的决策一致性。这说明模型学会了如何记录那些对“执行动作”有用的关键先验。
2. 分布偏移下的鲁棒性(Section 4.4)
很多模型在换了数据格式后就“歇菜”。但研发团队将 LoCoMo 训练出的技能库直接迁移到 HotpotQA(多文档问答)上,在不需要任何针对性训练的情况下,依然大幅超过了基线模型。
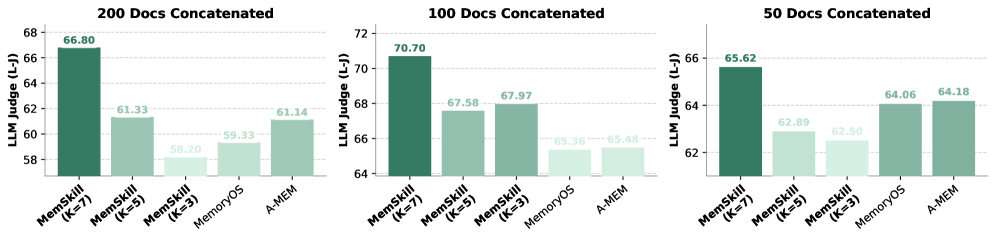

Figure 3:技能泛化测试。即使在文档拼接数量增加、噪声变大的情况下,MemSkill 的有效性依然稳健。
04
“怎么用”:那些由 AI 自动生成的“记忆神技”
为了让大家更有体感,咱们看看设计师(Designer)到底进化出了哪些技能(Section 4.5 和 Figure 4)。
团队对比了对话场景和具身智能场景,发现模型演化出了截然不同的专业化技能:
-
• • 对话类技能(LoCoMo):
-
• • Capture Temporal Context:专门识别日期、持续时间和事件顺序。
-
• • Capture Entity Nuances:处理实体的绰号、别名等微妙细节(这是很多基线模型漏掉的)。
-
• • 具身任务类技能(ALFWorld):
-
• • Capture Action Constraints:记录哪些动作是互斥的,哪些是必要前提(如:没拿钥匙不能开门)。
-
• • Track Object Movements:追踪物体在不同步骤间的空间位置变化。
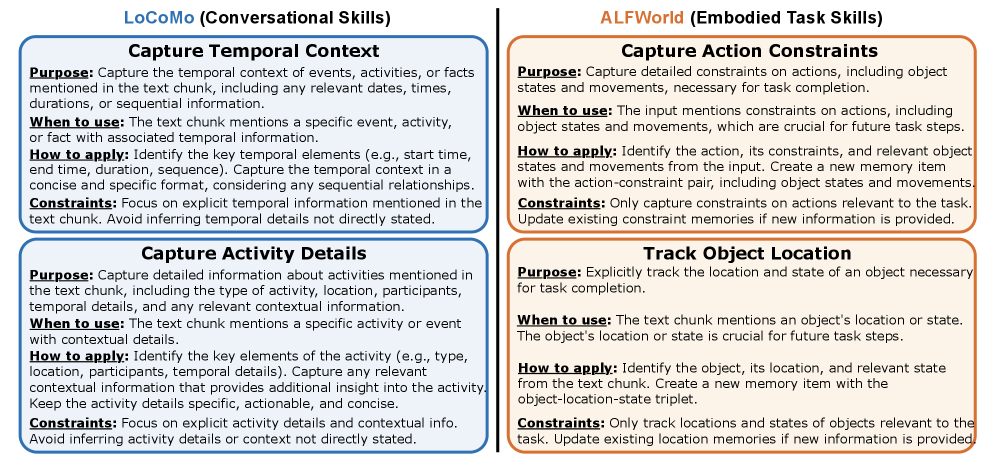

Figure 4:技能案例研究。展示了设计师自动生成的、具有高度专业化的技能描述模板。
(这些模板生成的指令非常符合人类直觉,但它们却是通过对失败案例的“反思”自动合成出来的。这种“无监督”的专业化非常硬核。)
05
细节深挖:设计师是如何思考的?
在论文的第 26 页(Appendix C),团队公开了设计师的分析逻辑。这是一个非常值得参考的 Prompt 工程范例。设计师被要求分析三种失效类型:
-
• 1. 存储失效(Storage failure):重要信息根本没存进去。
-
• 2. 检索失效(Retrieval failure):存在记忆里但没找出来。
-
• 3. 记忆质量失效(Memory quality failure):存得太模糊,导致答不上来。
基于这种深度反馈,MemSkill 能够实现“自我查漏补缺”。

06
降本增效分析:为什么它是工程部署的最优解?
如果你是开发者,最关心的肯定是:这东西会不会拖慢我的推理速度?
这里要纠正一个误区: 虽然引入了控制器和设计师,但设计师是在离线训练/进化阶段工作的(见 Section 3.4)。
在在线推理阶段,它的优势非常明显(Section 4.3):
-
• • 单步处理:控制器选好技能后,执行器在单次 LLM 调用中完成所有记忆更新。相比传统的“多步思考+多步修改”,延迟大幅降低。
-
• • 极致压缩:由于技能是经过优化的,它能用最少的字符记录最有价值的信息,极大缓解了 KV Cache 的增长压力。
根据 Page 11 (Appendix A.1) 的实验描述:相比传统的逐轮处理,MemSkill 采用跨度级(Span-level)评估,大幅减少了对底座 LLM 的调用次数,这在处理数十万 token 的长文本任务时,显著提升了系统的整体运行效率和吞吐性能。”
07
消融实验:缺了哪块不行?(Section 4.3)
团队非常诚实地做了消融实验(Table 2),验证了每一个设计的必要性。
Table 2: Ablation study on LoCoMo using L-J metric.
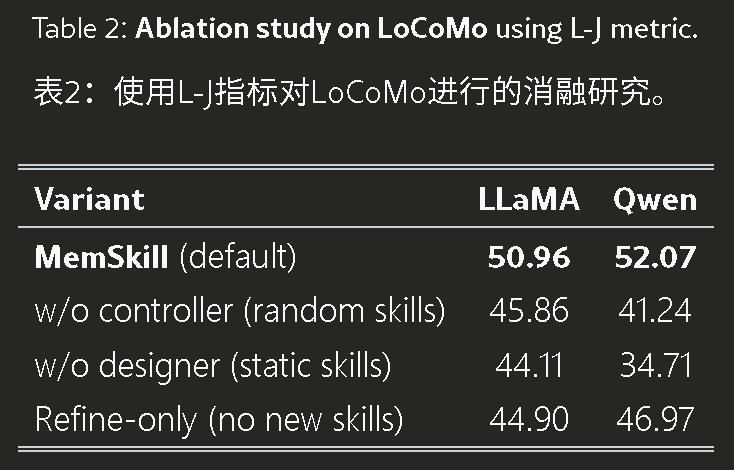
(数据来源:论文 Table 2。可以看出,去掉设计器或控制器,性能都会产生显著下滑)
实事求是的观察: 数据表明,技能库的进化(引入新技能)对性能的贡献甚至超过了选择策略的微调。这说明现有的 LLM 并不缺智商,缺的是针对特定任务的“记忆管理说明书”。
08
目前的局限性(Section 5)
作为客观观察员,我得指出 MemSkill 虽然惊艳,但并非毫无短板。在论文结论和讨论部分,团队也坦诚提到了几点挑战:
-
• 1. 记忆稳定性(Memory Stability):目前记忆依然是基于上下文窗口产生的“涌现能力”,缺乏显式的外部硬件级存储,超长模拟(如数月)仍可能出现结构走样。
-
• 2. 设计器的资源消耗:虽然是离线运行,但设计器需要 LLM 进行深度失效分析,这一过程非常依赖强力的大模型(如 GPT-4 或 LLaMA 70B+),对小团队来说,进化成本依然存在。
-
• 3. 计算成本:推理时的显存占用依然较高。在 RTX 4090D 上虽然能跑,但要维持 16 FPS 的实时响应,对硬件依然有硬性要求。
09
关于本地部署
目前 MemSkill 的全套代码已经在 GitHub 开源。
-
• • 部署状态:仓库提供了完整的训练脚本(基于 PPO)和设计器闭环逻辑。
-
• • 环境建议:由于需要运行 LLaMA 70B 级别的模型作为 Judge 或 Designer,建议准备 8x A100/H100 80GB 节点进行完整复现。不过,单纯运行推理端(Executor)对显存的要求会低很多。不过“8张 A100/H100”配置主要是为了跑通 70B+ 级别的 SOTA 刷榜实验。但是,中小型团队完全可以采用“田忌赛马”的部署策略:
• 执行端轻量化(Executor):日常任务中,一个 7B、12B 或 14B 级别的模型(如 Qwen2.5-14B)其指令遵循能力已绰绰有余。这意味着单张 RTX 3090/4090 (24G) 就能丝滑运行推理。
• 进化逻辑平替(Designer):最吃逻辑的“设计器”环节是离线进行的。你完全可以调用 DeepSeek 或 GPT-4o 的 API 来充当离线“导师”分析失败案例,生成的 skills.json 拿回本地直接给 7B 小模型用。
• 控制器极简(Controller):这部分只是个几 MB 的轻量级 MLP,跑起来几乎不占资源,CPU 都能带得动。
(当然这只是一种思路,但只要思路对,消费级显卡照样能玩转自进化记忆。)
从0到1!大模型(LLM)最全学习路线图,建议收藏!
想入门大模型(LLM)却不知道从哪开始? 我根据最新的技术栈和我自己的经历&理解,帮大家整理了一份LLM学习路线图,涵盖从理论基础到落地应用的全流程!拒绝焦虑,按图索骥~~
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取