
告别传统微调!Context Engineering打造强大AI Agent!
本文分享了Manus团队构建AI Agent时,从传统Fine-tuning转向Context Engineering的实战经验。文章详细阐述了六大核心工程实践:KV-Cache优化架构设计、Logit Masking解决Tool爆炸问题、文件系统作为外置显存、通过背诵对抗注意力衰减、保留错误轨迹增强学习、引入结构化噪声避免少样本陷阱。这些方法旨在解决Agent在长周期任务中的成本、延迟、准确性和

这篇文章是基于 Manus 团队的技术文章《Context Engineering for AI Agents[1]》整理而成。原文分享了他们在构建通用 Agent(Manus)过程中,如何放弃传统的 Fine-tuning 路线,转而通过深度优化的 Context Engineering 来挖掘前沿 LLM 潜力的实战经验。
个人觉得,这篇文章透露出的 insights 对于从事 Agent 开发、RAG 及推理优化的人很有参考价值。
用文章结尾的一句话做引言:
“The agentic future will be built one context at a time. Engineer them well.”
一、Why Context Engineering?
在 LLM 应用开发中,通常面临两条路径:
- • Fine-tuning:训练端到端模型。缺点是反馈循环慢(周级),且容易被基座模型的升级淘汰。
- • In-Context Learning:基于强基座模型进行语境构建。
Manus 团队选择了后者,他们认为 Agent 开发的核心在于 Context Engineering,即如何构建和管理输入给模型的 Context。作者将这种通过人工尝试、Prompt 调整和架构搜索的过程戏称为 Stochastic Graduate Descent。
二、核心技术策略
文章详细阐述了六个核心工程实践,来解决 Agent 在长周期任务中的 成本、延迟、准确性 和 鲁棒性 问题。
2.1 围绕 KV-Cache 进行架构设计
背景:Agent 场景的 Token 特征是 Input 极长(Context),Output 较短(Action),比例可达 100:1。因此,KV-Cache Hit Rate 是决定 TTFT (Time-to-First-Token) 和推理成本的最关键指标。
优化策略:
保持前缀稳定 (Prefix Stability):
- • 由于 Transformer 的自回归特性,Token t_i 的变更会导致 t_i 之后所有 KV Cache 失效。
- • ❌ Anti-Pattern:在 System Prompt 头部放入精确到秒的时间戳。
- • ✅ Best Practice:将动态信息移后,保持头部静态。
Append-only Context:
- • 严禁修改历史 Action/Observation。
- • 保证序列化的确定性,防止 JSON key 顺序变化导致 Cache Miss。
显式 Cache Breakpoints:
- • 在 System Prompt 结束等关键位置手动插入断点,适配不支持自动增量缓存的框架。
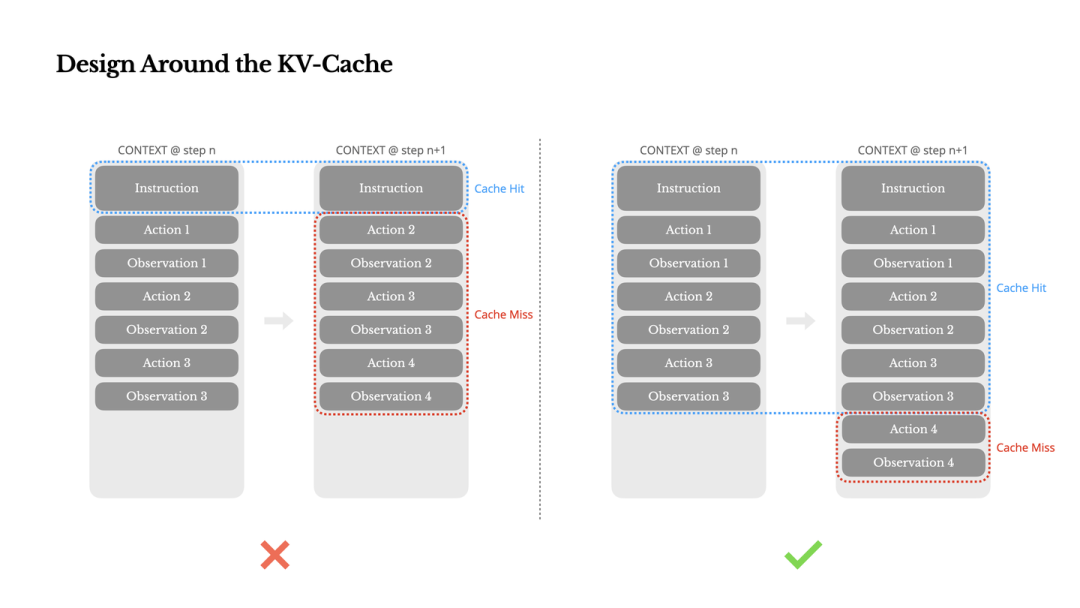
KV-Cache 在多轮对话中如何被复用及失效的示意图
2.2 对 Logits 做 mask 解决 Tool 爆炸的问题
挑战:Agent 随能力扩展,Tool 数量爆炸。若全部放入 Context,会增加干扰;若动态移除(RAG-style),会导致 Cache 失效且模型困惑(Context 中有历史调用但定义已消失)。
解决方案:Logit Masking (Constrained Decoding) 利用有限状态机管理当前状态下可用的工具,在 Decoding 阶段直接修改 Logits 分布,将不可用工具的概率置为 -\infty,而不是修改 Prompt 中的工具定义。
实现细节:
- • 利用 im_start 等 token 进行 Response Prefill。
- • 工具命名规范化(如 browser_, shell_),便于基于前缀进行 Masking。
- • 三种调用模式控制:Auto (可选), Required (必选), Specified (指定子集)。
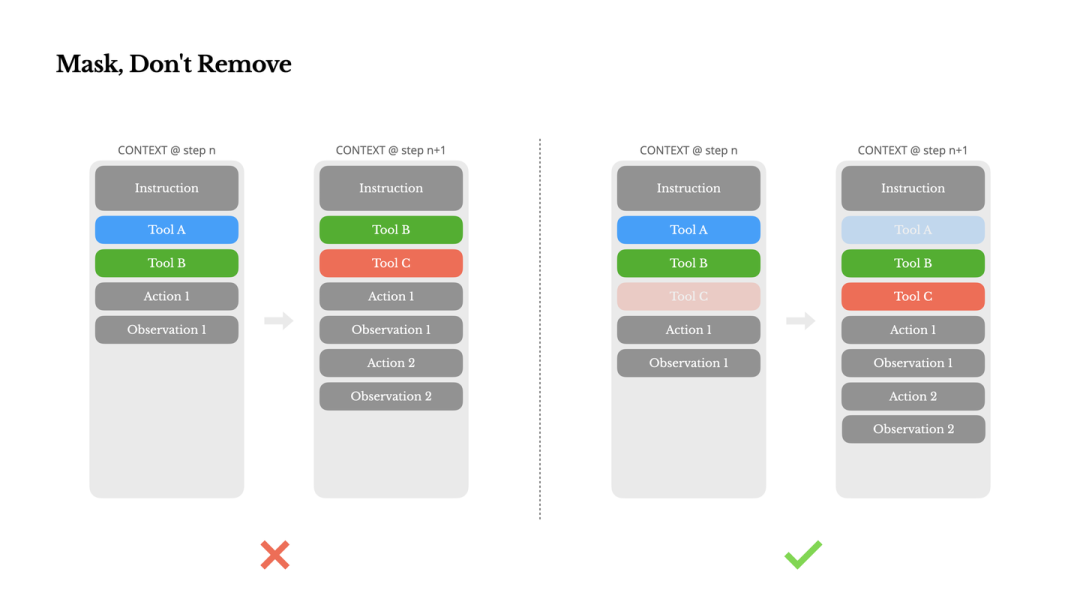
如何通过 Logit Masking 限制模型在特定状态下的动作选择
2.3 文件系统即外置显存
痛点:尽管 Context Window 达到 128k+,但 Observation(如网页、PDF)过大且昂贵,且长窗口会导致 Lost-in-the-middle 现象。
策略:
FS as Memory:
- • 将文件系统视为无限、持久的 Context。
可恢复压缩:
- • 在 Context 中不直接放入网页全文,而是保留 URL 或文件路径。
- • 模型学会使用工具 read_file(path) 按需加载数据。
- • 思想延伸:作者认为这种机制使得 Transformer 模拟了 Neural Turing Machine,并推测具备文件读写能力的 SSM (State Space Models) 可能是未来 Agent 的形态。
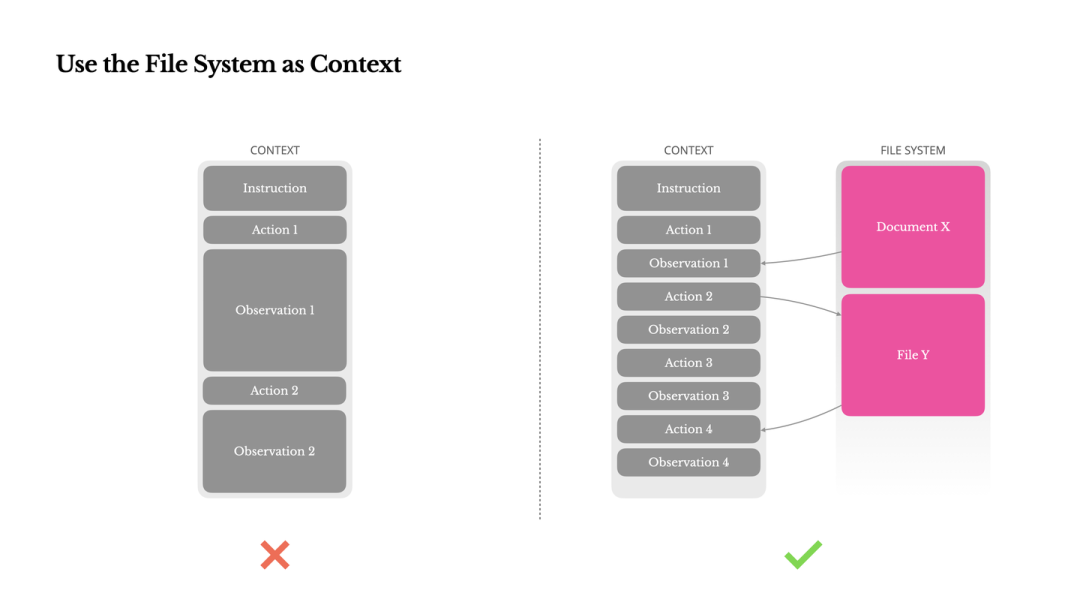
文件系统作为外部存储与 Context 交互的架构图
2.4 通过背诵(Recitation)对抗注意力衰减
现象:长任务(50+ steps)中,模型容易遗忘初始目标。
机制:Todo List Recitation。 Agent 维护一个 todo.md 文件,并在每一步更新它。这不仅仅是记录,更是一种 Attention Engineering。通过不断在 Context 末尾背诵当前进度和剩余目标,强行将 Global Plan 拉入模型的 最近注意力区域。
注:通过将目标放在 K, V 的末端,利用 Recency Bias 增强模型对目标的关注。
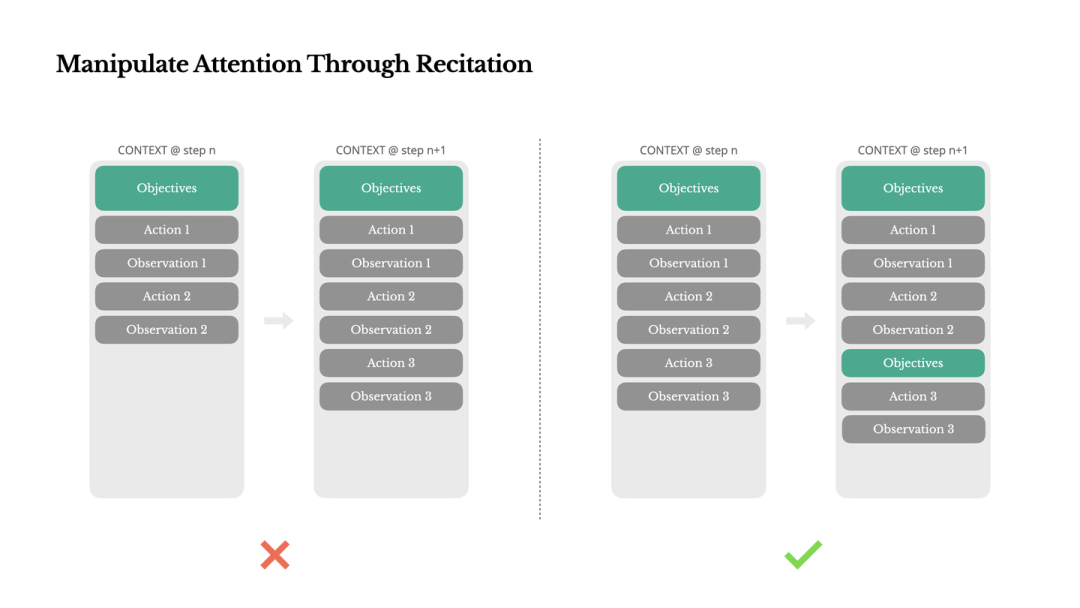
Manus 运行过程中 todo.md 的动态更新示例
2.5 保留错误轨迹
反直觉洞察:Agent 犯错是必然的。
- • ❌ 常见做法:隐藏错误,重置状态重试(以此保持 Context 干净)。
- • ✅ Manus 做法:保留错误的 Action 和报错的 Observation。
原理:错误轨迹构成了负样本(Negative Prompting)。当模型看到 Action A -> Error,它会更新内部信念,降低再次选择 A 的概率。Error Recovery 是 Agent 智能的重要体现,抹除错误等于抹除学习机会。
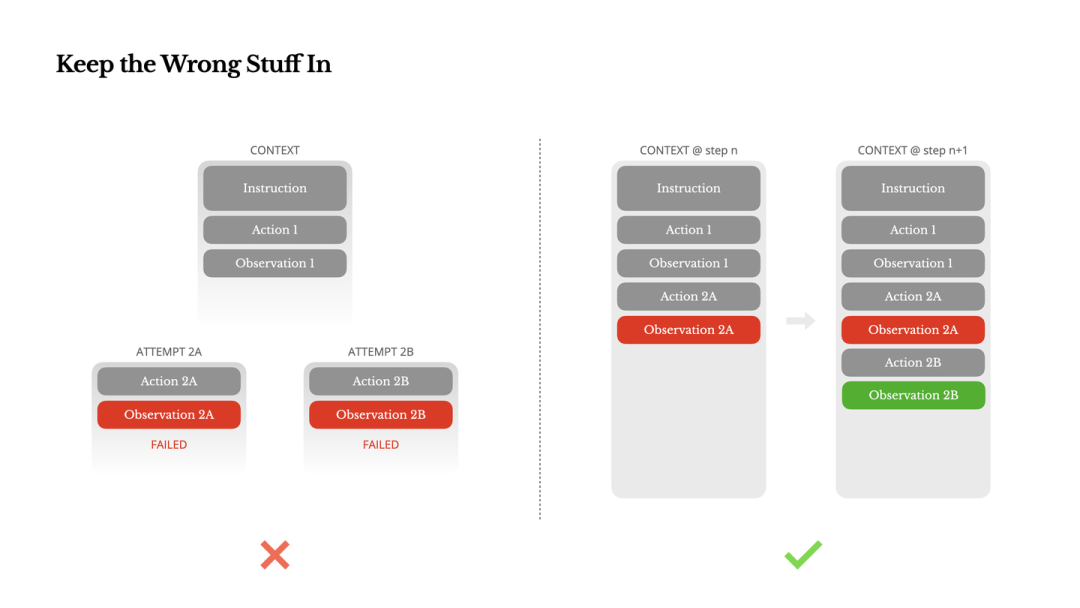
展示保留错误轨迹如何帮助模型进行自我修正
2.6 避免少样本陷阱
风险:LLM 是强模仿者。如果 Context 中充满了重复的、类似的“动作-观察”对(例如批处理20份简历),模型会陷入 Pattern Repetition,导致过拟合、死循环或幻觉。
对策:引入结构化噪声。
- • 在序列化模板、措辞、顺序上引入微小的随机变化。
- • 目的:打破 Context 的单一模式,强迫模型每次都进行推理而非单纯的补全。
三、个人总结
这篇文章讨论当前 Agent 系统从 Demo 走向 Production 中遇到的核心问题:如何在有限的 Context Window 和昂贵的推理成本下,维持 Agent 的长期规划能力和稳定性。
文章中给出了 Manus 自己的解法:
1、KV-Cache 是生命线:Agent 的系统设计必须向 Cache 机制妥协(如放弃 System Prompt 中的动态时间戳)。
2、推理时干预好过提示词工程:通过 Logit Masking 控制生成,比单纯写复杂的 System Prompt 更可靠、更节省 Context。
3、Context 并非越大越好:学会利用外部存储(文件系统)和动态加载,保持 Context 的流动性和高信噪比。
4、接受错误:Agent 的鲁棒性来自于从错误中恢复的能力,而非仅仅依靠一次成功的规划。
四、如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 39
39 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)