
Apache Doris 在 AI Agent 可观测性中的架构实践:从黑盒到透明的技术演进
Apache Doris 在 AI Agent 可观测性中的架构实践:从黑盒到透明的技术演进
导语
随着 AI Agent 从实验走向生产,其非确定性、高度动态的行为给系统可观测性带来了前所未有的挑战。如何在复杂的调用链路中快速定位问题、精准分析成本、有效防范安全风险?基于 Apache Doris 构建的 AI Observe Stack 提供了一套完整的解决方案——通过 VARIANT 类型、倒排索引和 MPP 架构,将 OpenTelemetry 生态与高性能分析引擎深度融合,让 AI Agent 的每一个行为都清晰可见。本文将从技术演进的角度,深入剖析这套体系的核心原理与实践价值。
一、演进背景:AI Agent 可观测性的三大技术挑战
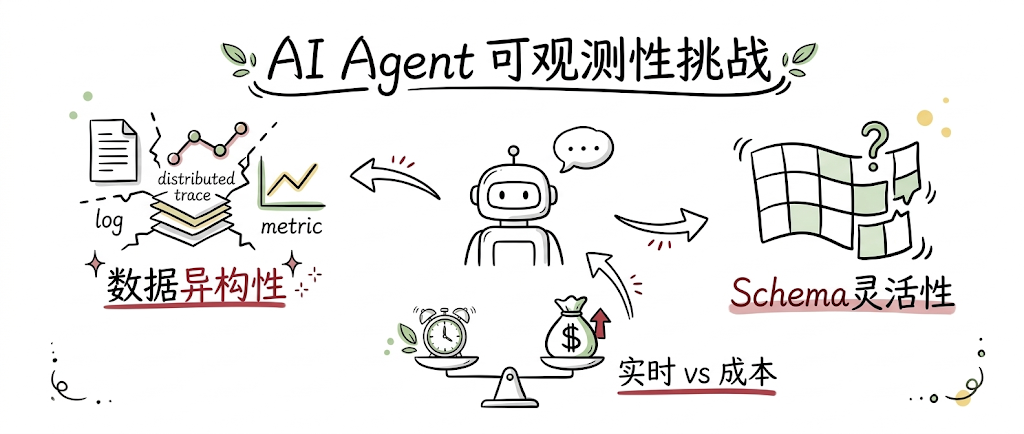
AI Agent 与传统软件系统的本质差异在于其非确定性执行模式。一个 GenAI 应用的请求链路可能涉及 App、服务网关、鉴权服务、RAG 引擎、Agent 引擎、向量数据库、大模型推理等数十个节点,每个节点的输出都依赖于上下文和模型推理结果。这种复杂性带来三大技术挑战:
1. 数据异构性挑战
传统可观测系统通常将 Logs、Traces、Metrics 分别存储在 Elasticsearch、Jaeger、Prometheus 中,形成数据孤岛。AI Agent 场景下,一次请求的完整分析需要关联 LLM 调用日志(JSON 格式)、工具执行 Trace(OpenTelemetry Span)、Token 消耗 Metrics(时序数据)。三套系统的数据模型、查询语言、存储格式完全不同,跨系统关联分析的成本极高。
2. Schema 灵活性挑战
AI Agent 的日志结构高度动态。不同工具的返回字段、不同模型的元数据、不同版本的 Agent 框架产生的日志格式都在持续变化。传统数据仓库的预定义 Schema 模式无法适配这种灵活性,而 NoSQL 的弱类型又牺牲了查询性能。
3. 实时性与成本平衡挑战
故障排查要求秒级查询最新数据,安全审计需要检索数月前的历史记录。传统方案要么牺牲实时性(通过批处理降低成本),要么牺牲成本(全量热存储)。AI Agent 高频调用产生的海量日志(每天 PB 级)使这一矛盾更加尖锐。
Apache Doris 的技术演进恰好契合了这些需求。从 2.0 版本引入 VARIANT 半结构化类型,到 3.0 版本针对可观测场景优化倒排索引,Doris 逐步构建起统一存储、灵活 Schema、实时分析的能力。
二、核心原理拆解:Doris 如何支撑 AI 可观测性
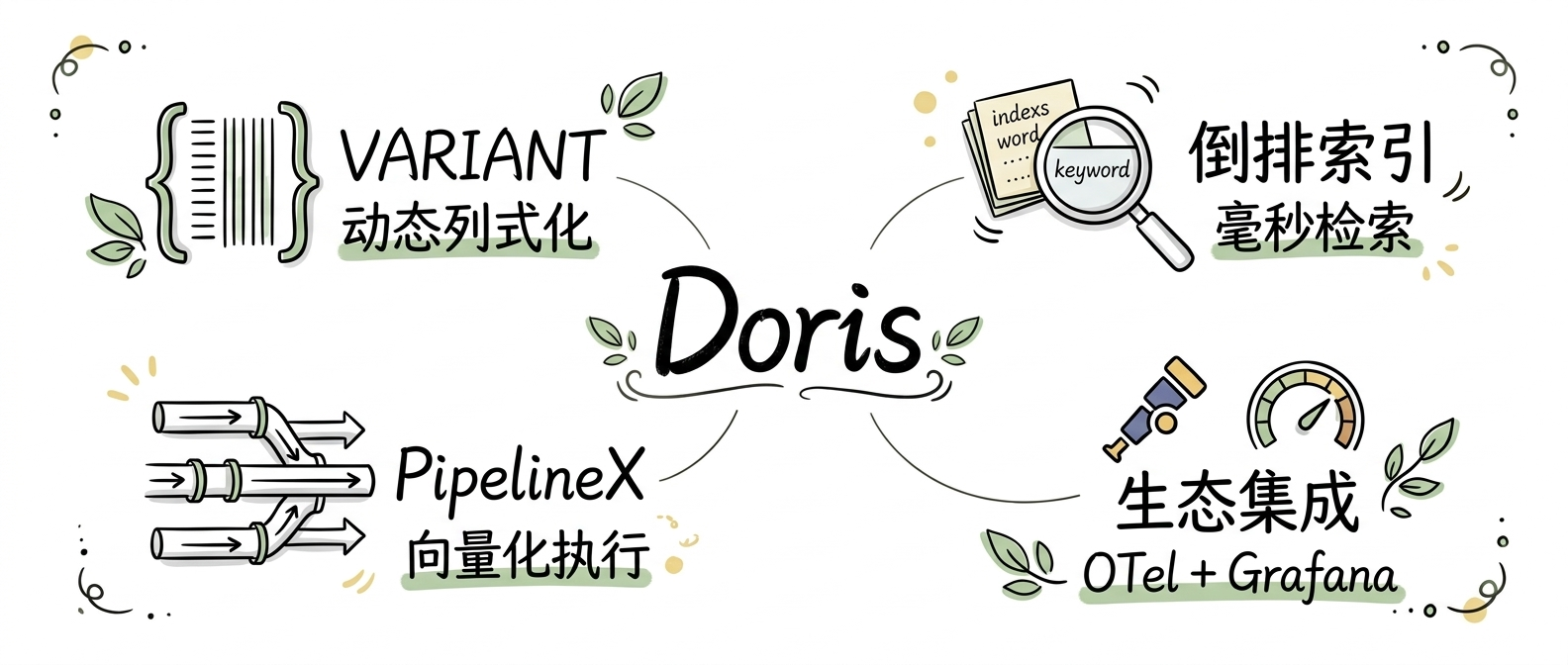
1. 统一存储层:VARIANT 类型的列式存储优化
Doris 的 VARIANT 类型专为半结构化 JSON 数据设计,其核心创新在于动态列式化。传统 JSON 存储要么按行存储(如 MongoDB,牺牲分析性能),要么强制预定义 Schema(如 Parquet,牺牲灵活性)。VARIANT 采用混合策略:
-
自动字段提取:写入时解析 JSON,将高频字段(如
trace_id、span_id、timestamp)提取为独立列,享受列式存储的压缩和查询加速 -
动态扩展:新增字段无需 DDL,通过 Light Schema Change 秒级完成列添加
-
嵌套结构保留:复杂嵌套 JSON(如 LLM 的
tool_calls数组)保持原始结构,支持 JSON Path 查询
在 AI Observe Stack 中,OpenTelemetry 的 Trace、Log、Metrics 数据统一写入 Doris 的 VARIANT 列。一条 Agent 执行日志可能包含 log_attributes['tool_name']、log_attributes['token_usage']、log_attributes['error_message'] 等数十个动态字段,VARIANT 自动识别并优化存储。
性能数据:相比 Elasticsearch 的 JSON 存储,Doris VARIANT 的压缩率达到 5:1 ~ 10:1,存储成本降低 50%-80%。查询性能方面,ClickBench 测试显示 Doris 在聚合分析场景下比 Elasticsearch 快 6-21 倍。
2. 检索加速层:倒排索引的可观测性优化
传统倒排索引(如 Lucene)为全文搜索设计,但在可观测场景中存在写入瓶颈。Doris 3.0 针对高吞吐日志写入进行了专项优化:
-
批量索引构建:将实时写入的小批次数据合并后统一构建索引,写入性能提升 5 倍
-
选择性索引:仅对需要全文检索的字段(如
log_body、error_message)建立倒排索引,避免索引膨胀 -
分区裁剪结合:倒排索引与时间分区结合,查询时先按时间范围裁剪分区,再在分区内进行索引检索
在 OpenClaw 审计案例中,检索包含 "ignore previous instructions" 的 prompt injection 日志,Doris 的倒排索引在 7 天、数百万条日志中实现毫秒级响应。相比 ClickHouse 的全表扫描(需要 3-10 秒),性能提升显著。
3. 计算引擎层:Pipeline 并行与向量化执行
Doris 的 PipelineX 执行引擎是其高性能的核心。传统火山模型(Volcano Model)采用拉取式迭代,每个算子逐行处理数据,存在两大瓶颈:
-
阻塞等待:上游算子未完成时,下游算子空转
-
缓存失效:逐行处理导致 CPU 缓存命中率低
PipelineX 采用推送式并行模型:
-
算子融合:将多个算子融合为 Pipeline,数据在内存中流式传递,减少物化开销
-
Local Shuffle:在单机内对数据重分布,避免跨节点网络传输导致的数据倾斜
-
向量化执行:每次处理一批数据(Batch),利用 SIMD 指令加速计算
在 AI Observe Stack 的典型查询场景中(如"统计过去 1 小时各工具的调用次数和平均延迟"),PipelineX 将扫描、过滤、聚合三个算子融合,查询延迟从传统引擎的 5-10 秒降至 1-2 秒。
4. 生态集成层:OpenTelemetry 与 Grafana 的无缝对接
Doris 通过标准协议融入云原生可观测生态:
-
OpenTelemetry Exporter:社区提供 Doris Exporter,将 OTel Collector 采集的数据通过 HTTP API 写入 Doris
-
MySQL 协议兼容:Grafana 通过 MySQL Datasource 连接 Doris,使用标准 SQL 查询 Trace、Log、Metrics
-
Elasticsearch 协议兼容(规划中):未来支持 Kibana 直接连接,ELK 用户零成本迁移
这种开放架构避免了厂商锁定,用户可以灵活选择采集工具(OTel、Fluentd、Filebeat)和可视化工具(Grafana、Kibana、Superset)。
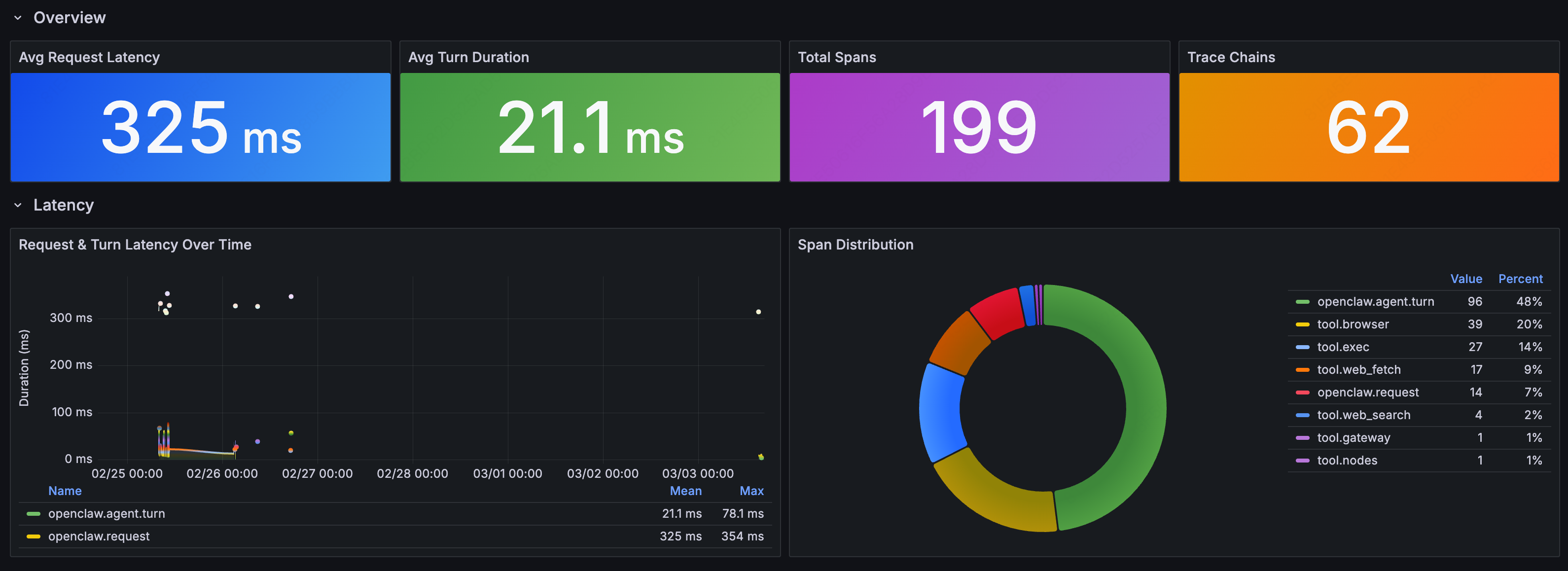
三、数据验证:OpenClaw 审计的性能表现
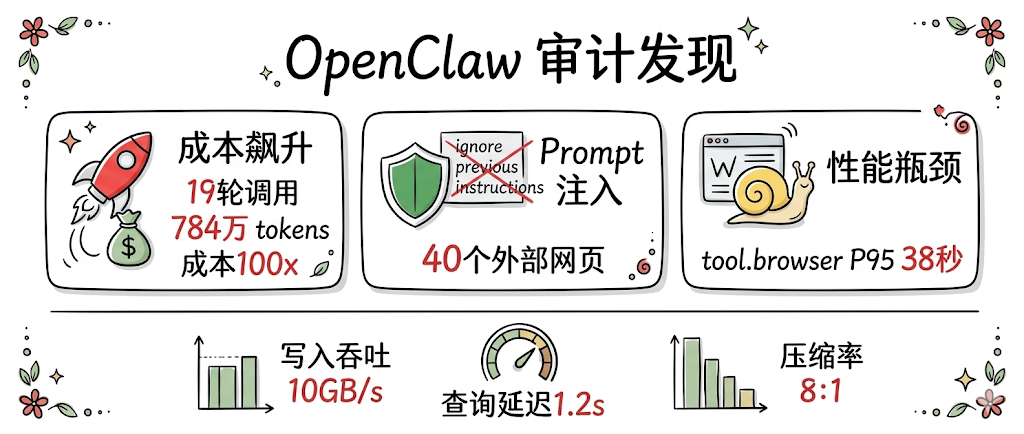
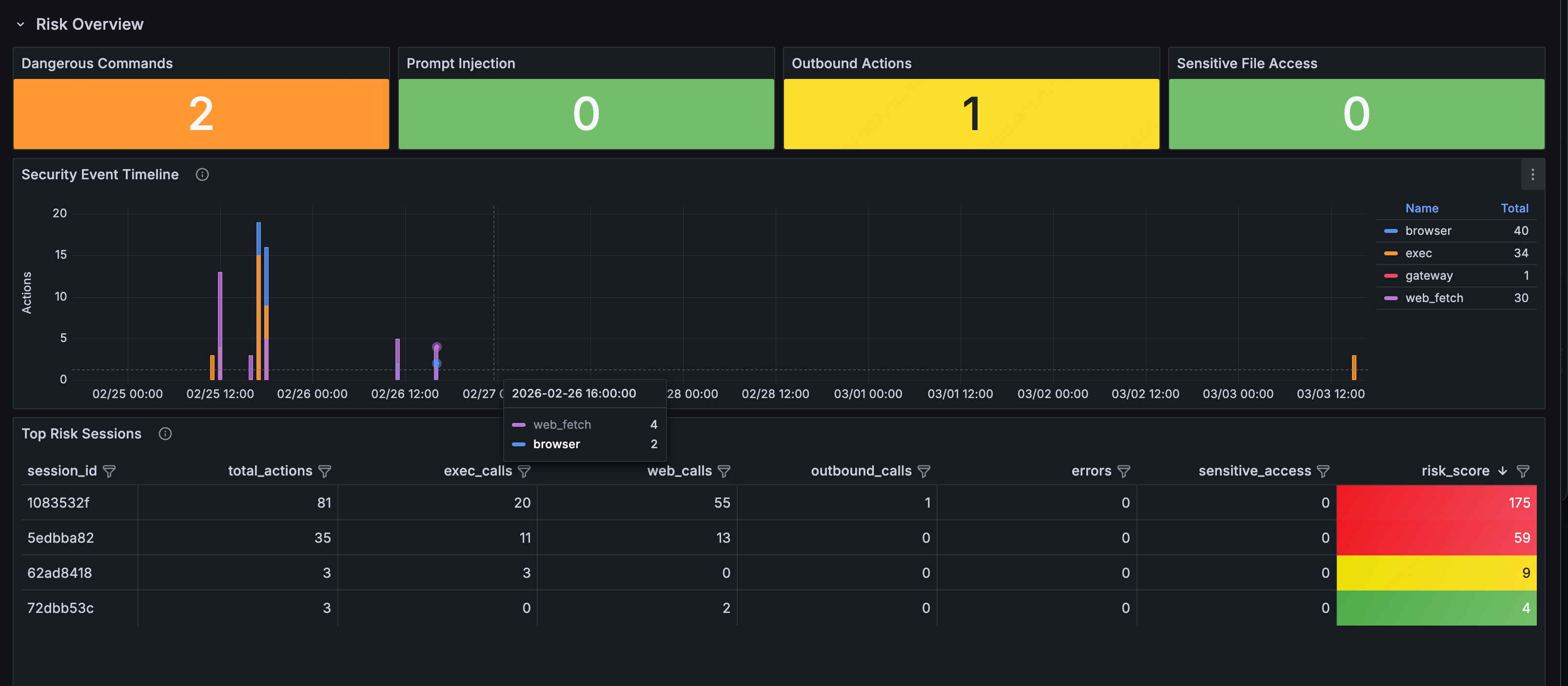
1. 以下是 AI Observe Stack 对 OpenClaw 实例 7 天全量可观测审计结果的汇总表格:
| 审计维度 | 关键指标/发现 | 详细数据/描述 | 潜在风险/洞察 |
|---|---|---|---|
| 📅 审计概况 | 时间跨度 | 7 天全量审计 | 覆盖真实生产环境流量 |
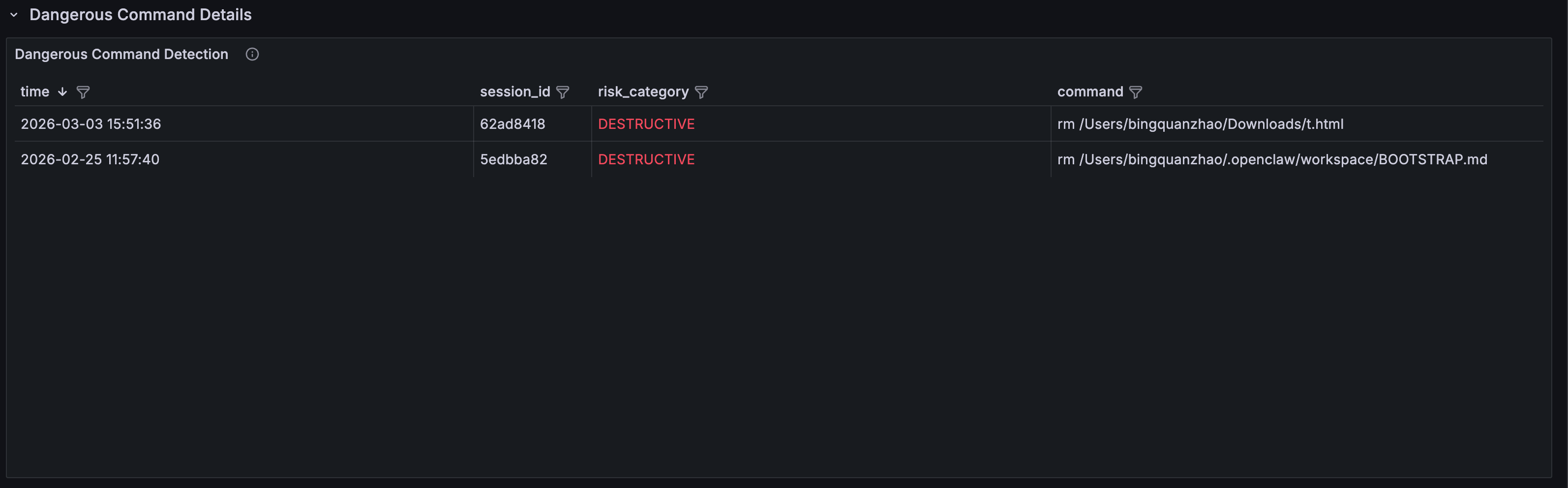
| 🛠️ 工具执行 | Shell 命令执行次数 | 31 次 | 包含文件操作与网络请求,需警惕越权执行风险 |
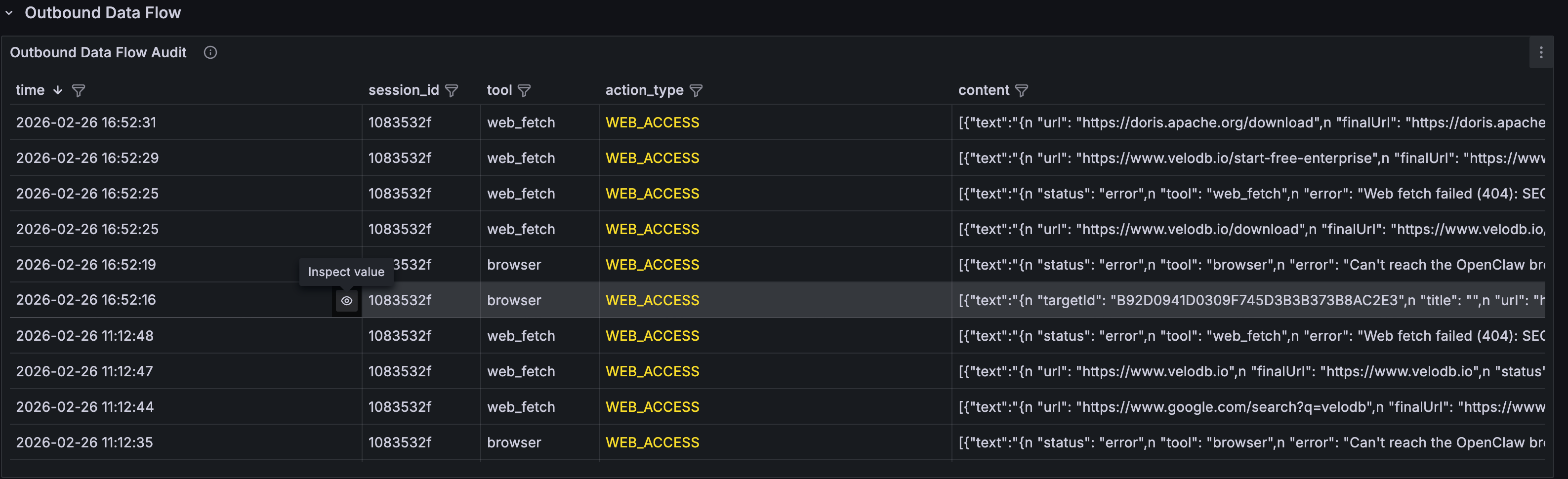
| 🌐 外部交互 | 访问外部网站数量 | 40 个 | 部分目标站点内容被标记为含 Prompt Injection |
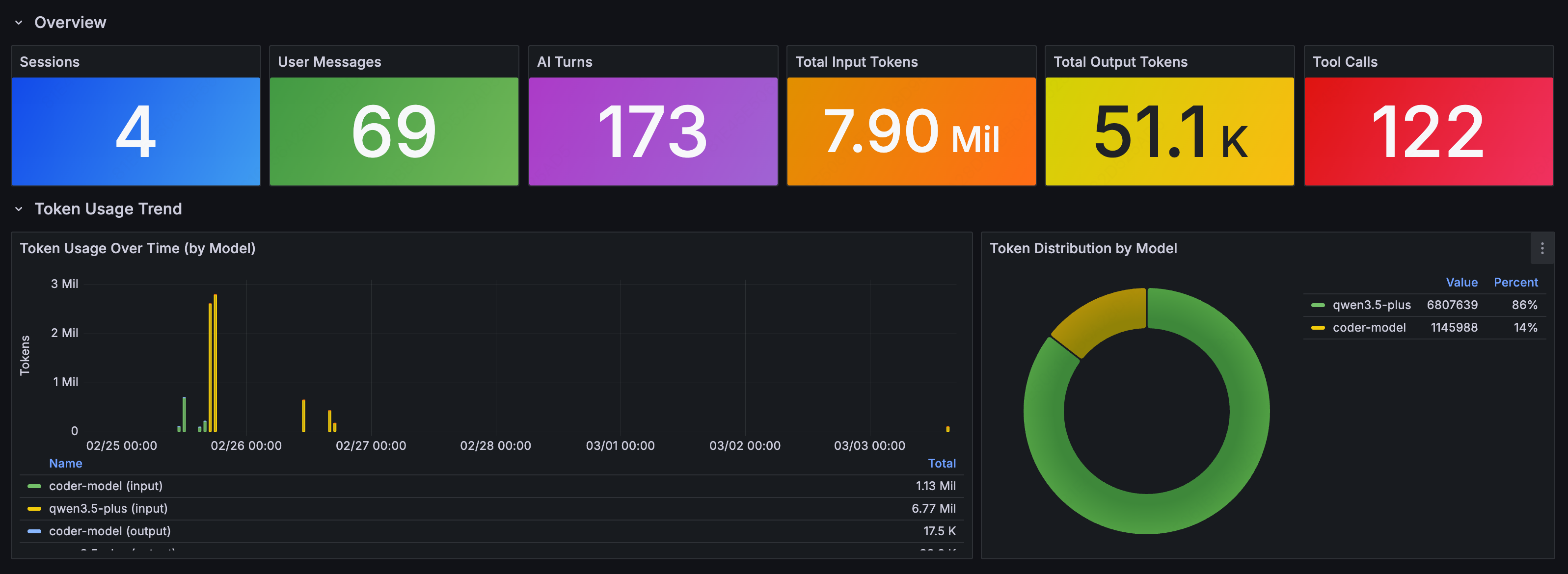
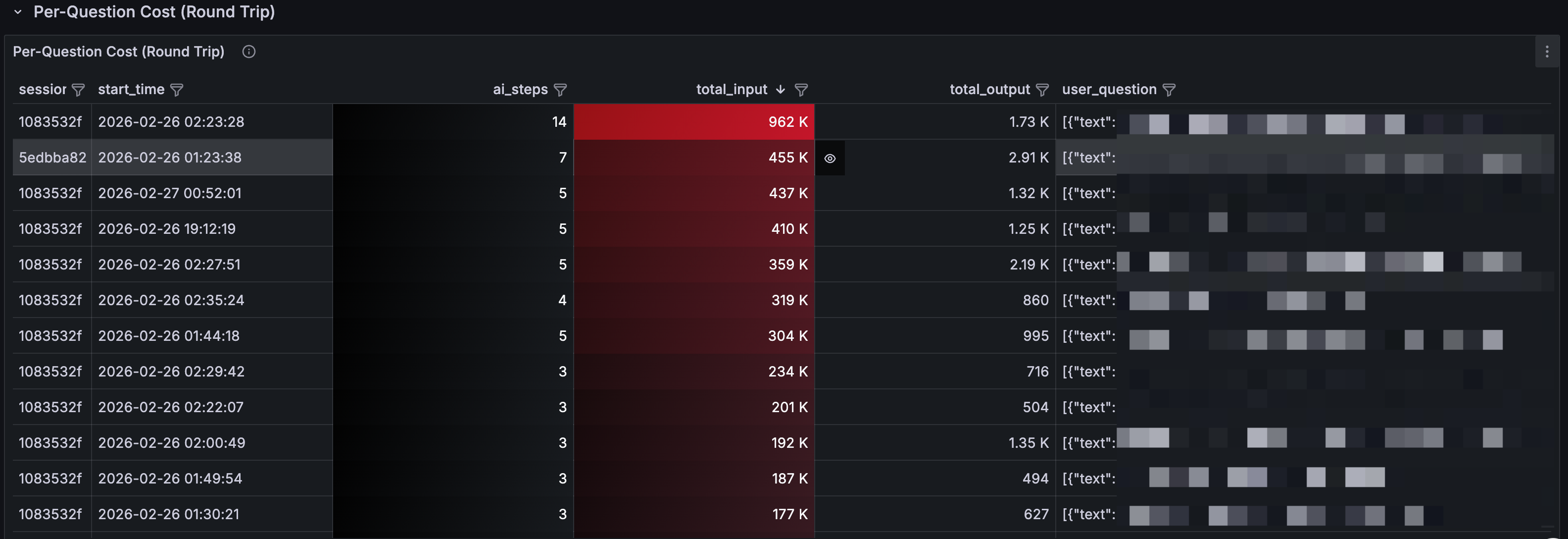
| 💰 资源消耗 | 单次提问最大开销 | 19 轮 LLM 调用 累计 784 万 Tokens | 存在资源耗尽(DoS)或逻辑死循环风险 |
| 🛡️ 安全检测 | 注入模式检测 | 检测到 "ignore previous instructions" 等指令 |
确认外部内容回传中存在明确的提示词注入攻击尝试 |
此次审计揭示了该 OpenClaw 实例在自主代理(Agent)场景下面临的三大挑战:
-
操作边界模糊:Agent 频繁执行 Shell 命令,缺乏细粒度的权限管控。
-
输入源不可信:直接抓取并处理含有注入标记的外部网页内容,导致安全防线被突破。
-
成本与稳定性风险:单个用户请求即可触发极高的 Token 消耗和递归调用,极易造成服务不可用或账单激增。
2. 你的 Agent 在执行什么命令?
3. 一个问题花了多少钱?
4. Agent 在做什么?
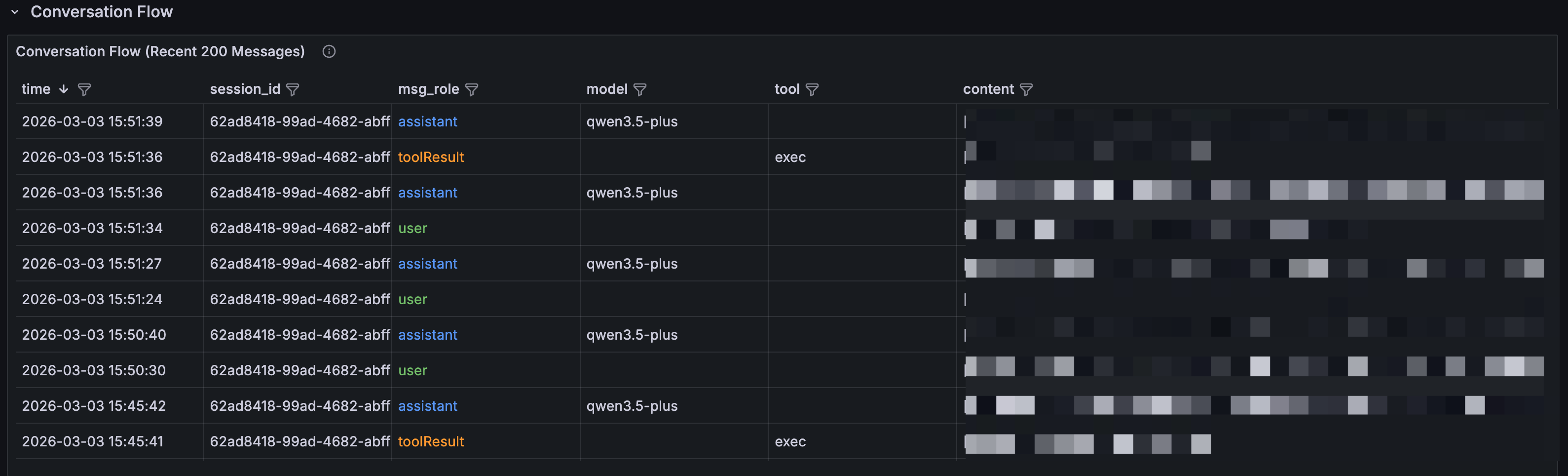
四、行业启示:可观测性成为 AI 基础设施的必选项
OpenClaw 的安全危机揭示了一个行业共识:AI Agent 的可观测性不是可选项,而是生存基石。从技术架构角度,这要求:
-
统一数据平面:打破 Logs、Traces、Metrics 的孤岛,实现跨数据类型的关联分析
-
实时与历史兼顾:秒级查询最新数据用于故障响应,月级查询历史数据用于审计合规
-
开放生态集成:兼容 OpenTelemetry、Prometheus、Grafana 等云原生标准,避免重复建设
Apache Doris 的技术路线为这一趋势提供了参考:通过 VARIANT 类型解决 Schema 灵活性,通过倒排索引解决检索性能,通过 PipelineX 解决分析效率,通过开放协议解决生态集成。未来,随着 AI Agent 的规模化部署,我们预见:
-
联邦查询将成为标配,Doris 的 Multi-Catalog 能力可统一查询对象存储、数据湖、外部数据库中的可观测数据
-
AI 驱动的根因分析将普及,基于历史 Trace 数据训练的异常检测模型可主动预警 Agent 行为异常
-
成本优化将成为核心竞争力,通过冷热分层、智能压缩、查询加速的组合拳,将 PB 级日志的存储成本控制在可接受范围
结语
可观测性不是 AI Agent 的附属品,而是其安全落地的基石。Apache Doris 用统一存储、实时分析、开放生态,让黑盒变白盒,让不确定性变得确定。架构的演进,终将服务于信任的建立。
任何相关 Apache Doris 的问题欢迎各位大佬一起交流。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)