
AI Agent落地挑战与Agent Infra核心价值:从实验到生产的关键一步!
本文探讨了AI Agent从实验走向生产所面临的落地挑战,强调了Agent Infra基础设施的关键作用。文章详细解析了Agent Infra的六大核心组件及其功能,阐述了其降低开发成本、提升系统稳定性、保障合规安全和支持灵活扩展的核心价值。通过对比开源轻量化和企业级商业技术方案,为不同规模企业提供了落地参考,强调了坚实的Agent Infra是智能体从"潜力"走向"生产力"的核心引擎。
简介
本文探讨了AI Agent从实验走向生产所面临的落地挑战,强调了Agent Infra基础设施的关键作用。文章详细解析了Agent Infra的六大核心组件及其功能,阐述了其降低开发成本、提升系统稳定性、保障合规安全和支持灵活扩展的核心价值。通过对比开源轻量化和企业级商业技术方案,为不同规模企业提供了落地参考,强调了坚实的Agent Infra是智能体从"潜力"走向"生产力"的核心引擎。
回顾2025年,AI Agent的落地速度正在超出预期。据相关数据,2023-2027年中国企业级AI Agent市场规模复合增长率将达到120%,预计到2027年,国内企业级AI Agent市场规模将达到655亿元。
然而,当这些在实验中表现惊艳的AI Agent投入真实的高并发业务环境时,便频频陷入跑不动、不安全、不兼容的窘境。这些底层支撑的短板,让众多Agent项目止步于试点,无法真正释放价值。
所以,2026年开始,卓越的智能体必须建立在坚实的Infra(基础设施)之上,一个强大的Agent Infra,是智能体从“潜力”走向“生产力”的核心引擎。它不仅是AI Agent稳定、安全、高效运行的技术基座,更是推动其从“可用”走向“好用”的关键引擎。
那么,什么是Agent Infra?它有什么核心作用?
Agent Infra是:支撑多智能体系统落地的底层技术栈
Agent Infra(Agent Infrastructure,智能体基础设施)是支撑单个或多智能体(Multi-Agent)系统从开发、部署、运行到运维的全套底层技术体系—— 类比传统 IT 基础设施(服务器、网络、数据库),Agent Infra 是智能体的 “地基”,解决 “智能体如何高效协作、稳定运行、安全扩展” 的核心问题,而非智能体本身的业务逻辑(如 “数据分析”“客服对话”)。
其核心目标是:降低智能体系统的开发门槛、提升运行稳定性、保障企业级合规与扩展性,让开发者无需关注底层技术细节,专注于业务场景与智能体能力设计(如 Agent Skills、任务流程)。
Environment
作用是给 Agent 执行任务提供容器,是一个 Agent-native computer;
Context 层
是在 Agent 工作中赋予记忆 Memory 和领域知识的重要中间层;
Tools
由于 MCP 协议的统一而百花齐放,同时目前 Tools 的核心用户还是开发者,普通用户的使用门槛太高;
Agent Security
是在 Agent 产品范式固定之后会涌现的大机会,需要同时确保避免 Agent 受攻击和发起攻击。
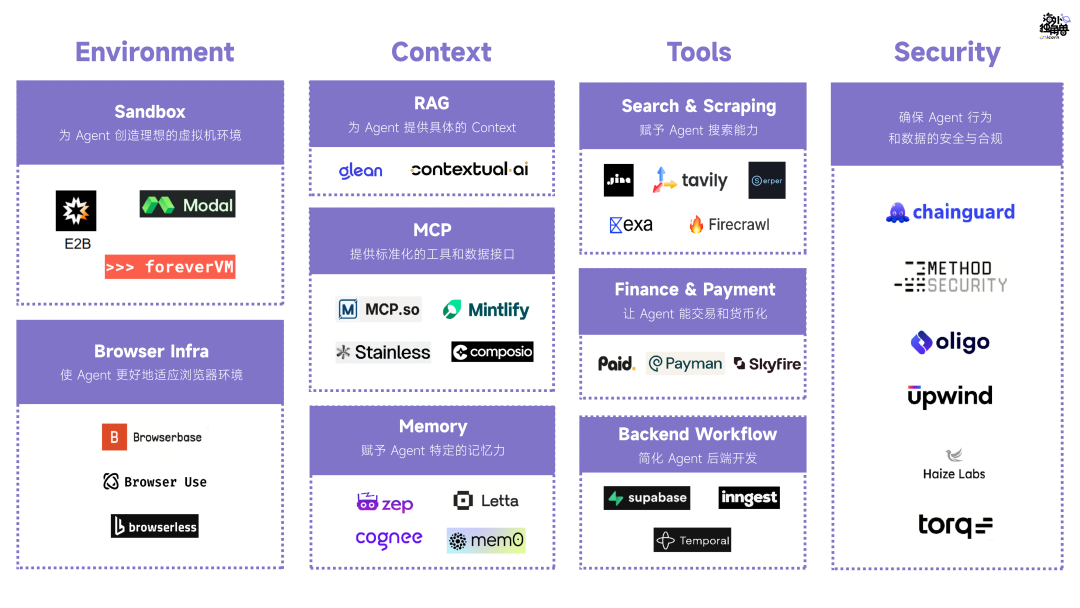
一、Agent Infra 的核心组件
Agent Infra 是 “多组件协同的技术矩阵”,覆盖智能体运行的全生命周期,关键组件可分为 6 大核心层,结合之前提到的多智能体架构(如 Supervisor、LangGraph)和企业落地场景(如巴斯夫涂料案例)拆解说明:
- 编排调度层(核心中枢)
负责多智能体的 “任务分配、流程控制、协作逻辑”,是多智能体系统的 “大脑操作系统”:
核心组件
编排框架(如 LangGraph、Mosaic AI Agent Framework、AutoGen):支持智能体的工作流定义(分支、循环、条件路由)、状态管理(共享上下文)、Agent 间协作规则配置;
调度引擎:负责任务优先级排序、Agent 负载均衡(避免单个 Agent 过载)、资源动态分配(如 CPU / 内存调度)。
核心作用
解决 “多 Agent 如何有序协作” 的问题 —— 比如巴斯夫涂料的多智能体系统,通过 LangGraph(编排框架)定义 “Supervisor→Genie Agent→Function-calling Agent” 的协作流程,调度引擎根据任务复杂度分配算力资源。
- 通信交互层(协作桥梁)
对应之前提到的 “Agent 之间通信” 需求,是智能体间、智能体与外部系统间的 “信息传递通道”:
核心组件
消息中间件(如 RabbitMQ、Kafka):支持 Agent 间异步通信,避免 “直接通信” 的耦合问题,提升大规模 Agent 协作的稳定性;
共享状态存储(如 Redis、Databricks Delta Tables):用于存储多 Agent 共享的上下文(如任务进度、中间结果),保证信息一致性;
标准化通信协议(如 MCP、OpenAI Function Call、JSON Schema):定义 Agent 间消息的格式、字段、鉴权规则,实现跨平台 / 跨厂商 Agent 互操作。
核心作用
打破 “Agent 孤岛”,让信息高效、可靠地在 Agent 间 / Agent 与外部系统(如企业数据库、第三方 API)流转 —— 比如巴斯夫的 Supervisor 通过共享状态存储同步 Genie Agent 的结构化数据结果,再通过标准化协议调用 Function-calling Agent。
- 工具与数据层(能力扩展接口)
为智能体提供 “外部能力接入” 和 “数据访问” 的标准化接口,解决智能体 “能力边界” 问题:
核心组件
工具注册中心(如 Mosaic AI Tools Catalog、LangChain Tool Hub):统一管理智能体可调用的工具(API、函数、第三方服务),支持工具元数据(功能描述、参数格式、权限要求)注册与检索;
数据连接器(如 Unity Catalog、JDBC/ODBC 接口):对接企业内外部数据(结构化数据如 Delta 表、非结构化数据如 PDF / 文档、向量数据库如 Milvus),支持智能体按需检索 / 读写数据;
向量数据库:用于 RAG 场景的非结构化数据检索,为智能体提供实时知识补充(避免 LLM 知识过时)。
核心作用
让智能体 “无需自带所有能力”,通过标准化接口调用外部工具 / 数据 —— 比如 Genie Agent 通过 Unity Catalog 连接器访问巴斯夫的销售 Delta 表,Function-calling Agent 通过工具注册中心调用向量检索工具。
- 运行时环境层(执行载体)
为智能体提供 “安全、隔离、可扩展” 的运行环境,避免智能体执行过程中影响系统稳定性:
核心组件
容器化 / 虚拟化技术(如 Docker、Kubernetes、Agent Virtual Machine):将每个智能体 / 工具封装为独立容器,实现环境隔离(如不同 Agent 的依赖包不冲突)、快速部署与扩容;
沙箱环境(Sandbox):用于执行高风险操作(如代码运行、外部 API 调用),限制智能体的操作权限(如禁止修改系统文件),防止恶意行为或误操作;
算力调度平台(如 Databricks Model Serving、AWS SageMaker):提供 LLM 推理所需的 CPU/GPU 算力,支持动态扩缩容(如高峰时段增加算力)。
核心作用
保障智能体 “稳定运行、安全可控”—— 比如巴斯夫的智能体在 Docker 容器中运行,通过沙箱环境调用外部工具,避免影响企业核心系统。
- 监控运维层(可观测性保障)
用于监控智能体系统的运行状态、排查问题、优化性能,是企业级落地的 “必备组件”:
核心组件
日志系统(如 ELK Stack、Databricks Logging):记录智能体的执行日志(任务状态、工具调用记录、错误信息)、Agent 间通信日志,支持全链路追溯;
监控面板(如 Grafana、Databricks Monitoring):实时展示关键指标(响应延迟、任务成功率、工具调用失败率、算力使用率);
评估工具(如 RLHF 框架、人工反馈收集系统):持续评估智能体的输出质量(准确性、合规性),支持系统迭代优化。
核心作用
让开发者 / 运维人员 “看得见、管得住” 智能体系统 —— 比如通过监控面板发现某 Agent 的工具调用失败率过高,通过日志定位是 API 超时问题。
- 安全合规层(企业级保障)
解决企业级场景的 “数据安全、权限管控、合规审计” 痛点,是智能体从原型走向生产的关键:
核心组件
权限管理系统(如 IAM、Unity Catalog 权限控制):精细化管控智能体的数据访问权限(如 Genie Agent 仅能查询指定数据表)、工具调用权限(如高敏感工具需 Supervisor 审核);
数据加密模块:对智能体的通信数据、存储数据(如用户上下文)进行加密,防止数据泄露;
审计系统:记录智能体的所有操作(数据访问、工具调用、任务执行),满足行业合规要求(如化工、金融的审计标准)。
核心作用
降低企业级部署的安全风险 —— 比如巴斯夫的智能体系统通过 Unity Catalog 管控数据权限,审计系统记录所有数据查询行为,满足化工行业的合规要求。
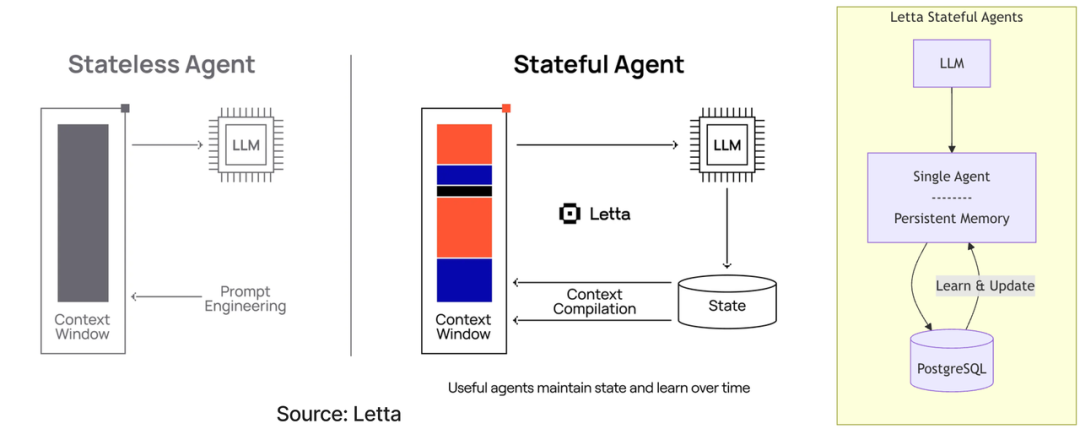
二、Agent Infra 的核心价值(为什么需要它?)
Agent Infra 的价值本质是 “让智能体系统从‘实验室原型’走向‘企业级生产应用’”,具体解决以下 4 个核心痛点:
- 降低开发成本:避免 “重复造轮子”
开发者无需从零构建 “Agent 协作、工具调用、状态管理” 等底层逻辑,直接基于 Infra 组件快速搭建系统 —— 比如用 LangGraph 定义多 Agent 工作流,用工具注册中心对接外部 API,大幅缩短开发周期(如从数月缩短至数周)。
- 提升系统稳定性:解决 “规模化运行难题”
单智能体原型可能 “小而美”,但多 Agent 大规模协作时易出现 “通信拥堵、流程混乱、资源过载”——Agent Infra 通过容器化隔离、消息队列异步通信、负载均衡调度,保障系统在高并发场景下(如日活 10 万用户的客服 Agent)稳定运行。
- 保障合规与安全:适配企业级需求
企业落地智能体时,最关注 “数据安全、权限管控、审计追溯”——Agent Infra 的权限管理、数据加密、审计系统,刚好满足这些需求,避免因智能体 “越权访问数据”“操作无记录” 导致的合规风险。
- 支持灵活扩展:适配业务增长
当业务场景扩展(如新增 “供应链 Agent”)或 Agent 数量增加时,Agent Infra 的模块化设计支持 “按需扩容”—— 比如新增 Agent 只需在编排框架中配置协作规则,在工具注册中心添加所需工具,无需重构整个底层架构。

三、典型 Agent Infra 技术企业落地案例
不同规模、场景的智能体系统,Infra 技术栈选择不同,以下是两类典型组合:
- 开源轻量化技术(适合中小企业)
编排调度:LangGraph + Celery(调度引擎);
通信交互:Redis(共享状态) + Kafka(消息队列) + OpenAI Function Call(通信协议);
工具与数据:LangChain Tool Hub(工具注册) + Milvus(向量数据库) + SQLite(结构化数据);
运行时环境:Docker + 本地沙箱;
监控运维:ELK Stack(日志) + Grafana(监控)。
- 企业级商业技术(适合大型企业 / 生产级部署)
编排调度:Mosaic AI Agent Framework + Databricks Workflows(调度);
通信交互:Databricks Delta Tables(共享状态) + Azure Service Bus(消息队列) + MCP(通信协议);
工具与数据:Mosaic AI Tools Catalog + Unity Catalog(数据连接器) + Databricks Vector Search(向量检索);
运行时环境:Kubernetes + Azure Bot Service(容器化部署) + 企业级沙箱;
监控运维:Databricks Monitoring + Azure Monitor(监控) + 定制化审计系统;
安全合规:Azure IAM(权限) + 数据加密(传输 / 存储)。
四、Agent Infra 的本质
Agent Infra 不是 “单个工具”,而是 “围绕智能体运行全生命周期的技术协同体系”—— 它的核心是 “标准化、模块化、可扩展”,让智能体系统从 “依赖定制化开发” 走向 “工业化落地”。
对于企业而言,选择 Agent Infra 的核心逻辑是:匹配自身的业务规模、合规要求、技术栈现状—— 中小企业可从开源轻量化组件入手,大型企业则更适合商业级 Infra(如 Databricks、Azure 生态),兼顾稳定性与合规性。
Agent Infra 是 “智能体的地基”,没有它,多智能体系统只能停留在 “小范围原型”;有了它,才能支撑起更多跨部门、大规模、高合规要求的企业级应用。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝 一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝 一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)