
用上下文工程打造更强 LangChain Agent
本文将介绍如何利用 LangChain 和 LangGraph 这两款强大的 AI 开发工具,有效实现“上下文工程”,从而提升 AI Agent 的能力。
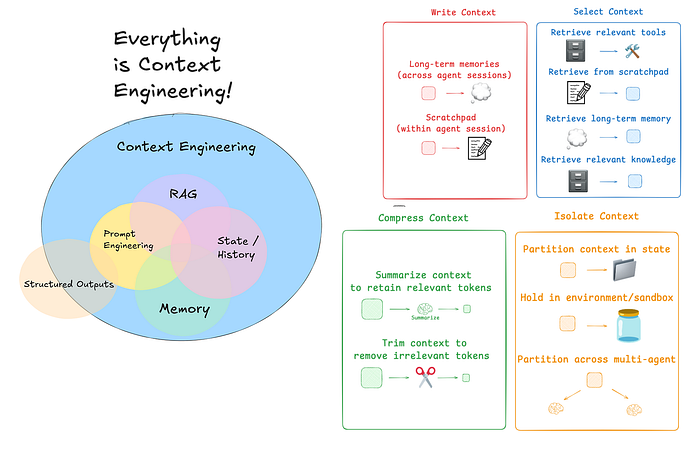
上下文工程,指的是在让 AI 执行任务前,为其搭建合适的“环境”。这个环境通常包括:
- 指令:告诉 AI 该如何表现,比如让它扮演一位贴心的省钱旅行顾问。
- 有用的信息:比如数据库、文档或实时数据源中的资料。
- 对话记忆:记住之前的交流,避免重复或遗忘。
- 可用工具:如计算器、搜索功能等。
- 关于你的关键信息,比如偏好、地理位置等。
上下文工程(参考 LangChain 和 12Factor
AI 工程师正在从提示工程转向上下文工程,原因在于——
上下文工程关注为 AI 提供合适的背景和工具,让 AI 的回答更智能、更有用。
本文将介绍如何利用 LangChain 和 LangGraph 这两款强大的 AI 开发工具,有效实现“上下文工程”,从而提升 AI Agent 的能力。所有代码均可在 GitHub 仓库获取,地址见文末。
文章较长,建议收藏!!
目录
- 什么是上下文工程?
- 使用 LangGraph 构建 Scratchpad
- 创建 StateGraph 状态图
- LangGraph 中的记忆写入机制
- Scratchpad 的选择策略
- 记忆选择能力优化
- LangGraph 在大工具调用中的优势
- 结合上下文工程实现 RAG 检索增强生成
- 与知识型 Agent 协作的压缩策略
- 利用子智能体架构实现上下文隔离
- 使用沙盒环境进行上下文隔离
- LangGraph 中的状态隔离机制
- 全文总结与关键洞察
什么是上下文工程?
大模型(LLM)就像一种全新的操作系统。LLM 本身类似于 CPU,而它的上下文窗口就像 RAM,是它的短期记忆。但和 RAM 一样,上下文窗口的容量有限,能容纳的信息是有限的。
正如操作系统决定哪些内容进入 RAM,“上下文工程”就是为 LLM 挑选应该保留在上下文中的信息。
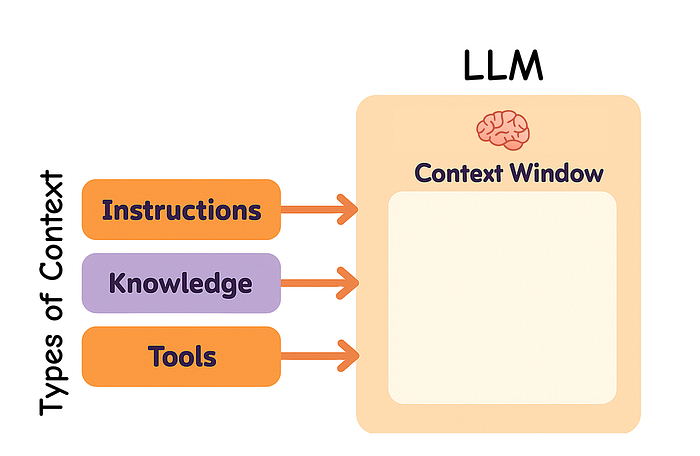
不同类型的上下文,Fareed Khan 制作
开发 LLM 应用时,我们需要管理多种类型的上下文。上下文工程主要涵盖以下几类:
- 指令:提示词、示例、记忆、工具说明等
- 知识:事实、存储的信息、记忆等
- 工具:工具调用的反馈和结果
今年,越来越多的人关注 Agent,因为 LLM 在推理和工具调用方面表现更好。Agent 通过结合 LLM 和工具,能处理更长、更复杂的任务,并根据工具反馈决定下一步行动。
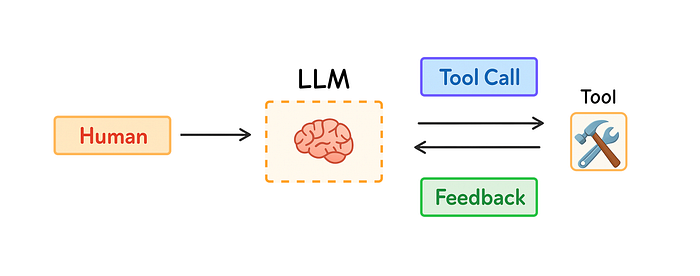
Agent 工作流程,Fareed Khan 制作
但长任务和大量工具反馈会消耗大量 Token,带来一系列问题:上下文窗口溢出、成本和延迟增加,Agent 表现反而变差。
Drew Breunig 曾指出,过多的上下文会损害性能,包括:
- 上下文污染:指的是当错误或幻觉被加入到上下文中时。
- 上下文干扰:指的是当上下文信息过多,导致模型被搞糊涂。
- 上下文混淆:指的是多余、不必要的细节影响了模型的回答。
- 上下文冲突:指的是上下文中的不同部分给出了互相矛盾的信息。
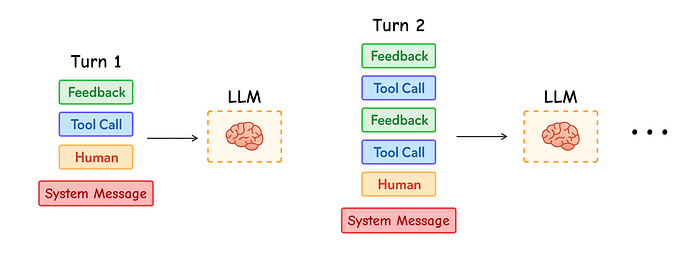
Agent 中的多轮对话,Fareed Khan 制作
Anthropic 在他们的研究中强调了这一点:
Agent 往往需要进行上百轮对话,因此如何精细管理上下文至关重要。
那么,现在大家是如何解决这个问题的呢?Agent 上下文工程的常见策略大致可以分为四类:
- 编写:创造清晰且有用的上下文
- 选择:只挑选最相关的信息
- 压缩:缩短上下文以节省空间
- 隔离:将不同类型的上下文分开管理
LangGraph 正是为支持这些策略而设计的。接下来我们会逐一介绍这些组件,并看看它们如何帮助 AI Agent 更好地工作。
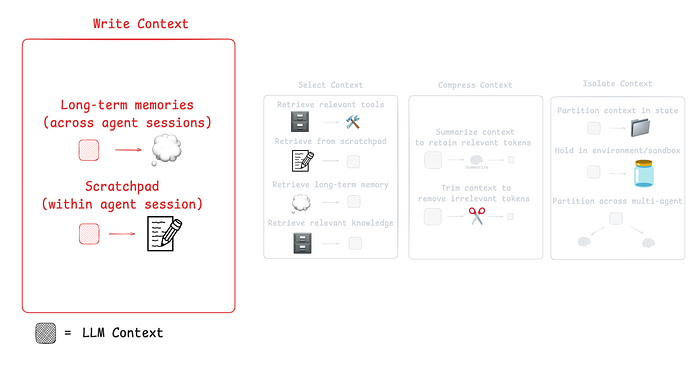
使用 LangGraph 构建 Scratchpad
就像人类会记笔记以便后续查阅,Agent 同样可以用 Scratchpad 来记录信息。Scratchpad 把信息存储在上下文窗口之外,Agent 需要时随时可以查阅。
CE 的第一个组件,引用自 LangChain 文档
一个很好的例子是 Anthropic 的 多 Agent 研究系统:
LeadResearcher 会规划自己的方案并将其保存到记忆中,因为如果上下文窗口超过 20 万个 token,内容就会被截断,提前保存计划可以避免信息丢失。
Scratchpad 的实现方式有多种:
- 作为一种工具调用,比如写入文件。
- 作为运行时状态对象中的一个字段,在会话期间持续保存。
简而言之,Scratchpad 帮助 Agent 在会话过程中随时记录关键信息,从而更高效地完成任务。
在 LangGraph 中,既支持短期记忆(线程级别),也支持长期记忆。
- 短期记忆通过检查点机制保存 Agent 状态,就像一个 Scratchpad,允许你在 Agent 运行时存储信息,之后随时取用。
状态对象是各个图节点之间传递的核心结构。你可以自定义它的格式(通常是 Python 字典),它就像一个共享的 Scratchpad,每个节点都能读取和更新其中的特定字段。
我们会在需要时再导入相关模块,这样可以循序渐进、清晰易懂地学习。
为了让输出更美观,我们将用 Python 的 pprint 模块和 rich 库的 Console 模块来格式化打印。首先导入并初始化它们:
# 导入所需库from typing import TypedDict # 用于带类型提示地定义状态结构from rich.console import Console # 用于美观地输出结果from rich.pretty import pprint # 用于美观地打印Python对象# 初始化一个控制台对象,用于在notebook中格式化输出console = Console()
接下来,我们将为状态对象创建一个 TypedDict。
# 用TypedDict定义图状态的结构。# 这个类作为数据结构,在图中各节点之间传递。# 它保证了状态结构的一致性,并为类型提示提供支持。class State(TypedDict): """ 定义了笑话生成流程中状态的结构。 属性说明: topic: 输入的话题,用于生成笑话。 joke: 输出字段,用于存放生成的笑话。 """ topic: str joke: str
这个状态对象会存储我们要求智能体根据指定话题生成的笑话及其话题。
创建 StateGraph 状态图
定义好状态对象后,我们可以通过 StateGraph 向其写入上下文。
StateGraph 是 LangGraph 用于构建有状态智能体或工作流的核心工具。你可以把它理解为一个有向图:
- 节点代表工作流中的步骤。每个节点接收当前状态作为输入,更新状态后返回变更内容。
- 边则连接各节点,定义执行流程,可以是线性的、条件分支的,甚至是循环的。
接下来我们要做:
- 选择 Anthropic 模型之一,创建一个对话模型。
- 在 LangGraph 工作流中使用它。
# 导入环境管理、显示和LangGraph所需的库import getpassimport osfrom IPython.display import Image, displayfrom langchain.chat_models import init_chat_modelfrom langgraph.graph import END, START, StateGraph# --- 环境与模型初始化 ---# 设置Anthropic API密钥以进行身份验证from dotenv import load_dotenvapi_key = os.getenv("ANTHROPIC_API_KEY")ifnot api_key: raise ValueError("环境变量中缺少ANTHROPIC_API_KEY")# 初始化工作流中要用的对话模型# 这里选用特定的Claude模型,temperature=0保证输出确定性llm = init_chat_model("anthropic:claude-sonnet-4-20250514", temperature=0)
我们已经初始化了 Sonnet 模型。LangChain 通过 API 支持多种开源和闭源模型,你可以任选其一。
接下来,需要编写一个函数,利用 Sonnet 模型生成回复。
# --- 定义工作流节点 ---def generate_joke(state: State) -> dict[str, str]: """ 节点函数:根据当前状态中的话题生成笑话。 本函数从state中读取'topic',调用LLM生成笑话, 并返回一个字典,用于更新状态中的'joke'字段。 参数: state: 图的当前状态,必须包含'topic'。 返回: 包含'joke'键的字典,用于更新状态。 """ # 从状态中读取话题 topic = state["topic"] print(f"正在生成关于「{topic}」的笑话...") # 调用大模型生成笑话 msg = llm.invoke(f"Write a short joke about {topic}") # 返回生成的笑话,写回状态 return {"joke": msg.content}
这个函数只需返回一个包含生成结果(即笑话)的字典。
现在,我们可以用 StateGraph 轻松搭建并编译整个流程图。下面就来实现。
# --- 构建与编译流程图 ---# 用预定义的 State 数据结构初始化一个新的 StateGraphworkflow = StateGraph(State)# 将 'generate_joke' 函数作为节点添加到流程图中workflow.add_node("generate_joke", generate_joke)# 定义流程的执行路径:# 流程从 START 节点开始,流向 'generate_joke' 节点workflow.add_edge(START, "generate_joke")# 'generate_joke' 节点执行完毕后,流程结束workflow.add_edge("generate_joke", END)# 将流程图编译为可执行的链式结构chain = workflow.compile()# --- 可视化流程图 ---# 展示编译后的流程图的可视化效果display(Image(chain.get_graph().draw_mermaid_png()))
```
我们生成的流程图,Fareed Khan 制作
现在我们可以执行这个流程了。
```plaintext
# --- 执行流程 ---# 使用包含初始主题的状态调用编译好的流程图# `invoke` 方法会从 START 节点运行到 END 节点joke_generator_state = chain.invoke({"topic": "cats"})# --- 展示最终状态 ---# 打印流程执行后的最终状态# 这会显示输入的 'topic' 和输出的 'joke'console.print("\n[bold blue]Joke Generator State:[/bold blue]")pprint(joke_generator_state)#### 输出示例 ####{'topic': 'cats','joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'}
它返回了一个字典,实际上就是我们智能体的笑话生成状态。这个简单的例子展示了如何将上下文写入状态。
你可以进一步了解 Checkpointing(检查点),用于保存和恢复流程状态;以及 Human-in-the-loop(人工介入),可以在流程中暂停以等待人工输入后再继续。
LangGraph 中的记忆写入机制
Scratchpad 可以帮助智能体在单次会话内记忆内容,但有时智能体需要跨多次会话记住信息。
- Reflexion 提出了智能体每轮反思并复用自我生成提示的思路。
- Generative Agents 通过总结过往反馈,为智能体构建了长期记忆。
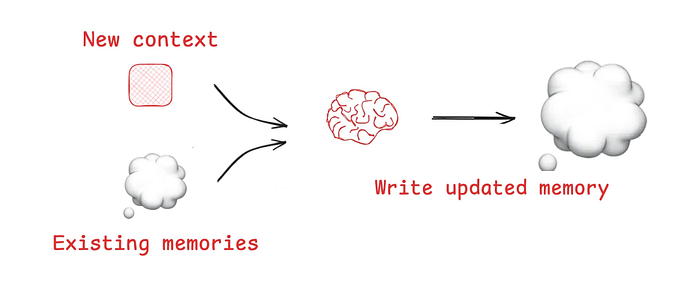
记忆写入,图片来自 LangChain 文档
这些理念已经被应用到 ChatGPT、Cursor 和 Windsurf 等产品中,实现了自动从用户交互中生成长期记忆。
- 检查点机制会在每一步将流程状态保存到一个线程中。每个线程有唯一 ID,通常对应一次交互,比如 ChatGPT 的一次对话。
- 长期记忆可以让你在不同线程间保留特定上下文。你可以保存单个文件(如用户档案)或记忆集合。
- 它基于 BaseStore 接口实现,是一种键值存储。你可以在内存中使用(如下所示),也可以结合 LangGraph 平台部署。
下面我们创建一个 InMemoryStore,用于本笔记本的多次会话。
from langgraph.store.memory import InMemoryStore# --- 初始化长期记忆存储 ---# 创建 InMemoryStore 实例,提供简单的、非持久化的键值存储系统,适用于当前会话store = InMemoryStore() # --- 定义命名空间以便组织管理 ---# 命名空间用于在存储中对相关数据进行逻辑分组。# 这里我们用元组来表示分层命名空间,# 比如可以对应用户ID和应用上下文。namespace = ("rlm", "joke_generator")# --- 向内存存储写入数据 ---# 使用 `put` 方法将键值对保存到指定命名空间中。# 这样可以将前面生成的笑话持久化存储,# 方便在不同会话或线程间随时读取。store.put( namespace, # 要写入的命名空间 "last_joke", # 数据条目的键 {"joke": joke_generator_state["joke"]}, # 要存储的值)
接下来我们会讲解如何从命名空间中选择上下文。现在,可以用 search 方法查看命名空间下的所有条目,确认数据确实写入成功。
# 查询命名空间下的所有存储条目stored_items = list(store.search(namespace))# 用富文本格式展示存储内容console.print("\n[bold green]内存中的存储条目:[/bold green]")pprint(stored_items)#### 输出示例 ####[ Item(namespace=['rlm', 'joke_generator'], key='last_joke', value={'joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'}, created_at='2025-07-24T02:12:25.936238+00:00', updated_at='2025-07-24T02:12:25.936238+00:00', score=None)]
现在,让我们把上面的内容整合进一个 LangGraph 工作流。
编译工作流时,我们传入两个参数:
checkpointer用于在每个线程步骤保存图状态。store用于在不同线程间共享上下文。
from langgraph.checkpoint.memory import InMemorySaverfrom langgraph.store.base import BaseStorefrom langgraph.store.memory import InMemoryStore# 初始化存储组件checkpointer = InMemorySaver() # 用于线程级状态持久化memory_store = InMemoryStore() # 用于跨线程的内存存储def generate_joke(state: State, store: BaseStore) -> dict[str, str]: """带记忆功能的笑话生成器。 这个增强版会先检查内存中是否已有笑话, 如果没有再生成新的。 参数: state:当前状态,包含主题 store:用于持久化上下文的内存存储 返回: 包含生成笑话的字典 """ # 检查内存中是否已有笑话 existing_jokes = list(store.search(namespace)) if existing_jokes: existing_joke = existing_jokes[0].value print(f"已有笑话:{existing_joke}") else: print("已有笑话:暂无") # 根据主题生成新笑话 msg = llm.invoke(f"Write a short joke about {state['topic']}") # 将新笑话写入长期记忆 store.put(namespace, "last_joke", {"joke": msg.content}) # 返回笑话,加入状态 return {"joke": msg.content}# 构建具备记忆功能的工作流workflow = StateGraph(State)# 添加带记忆的笑话生成节点workflow.add_node("generate_joke", generate_joke)# 连接工作流各部分workflow.add_edge(START, "generate_joke")workflow.add_edge("generate_joke", END)# 编译时同时启用检查点和内存存储chain = workflow.compile(checkpointer=checkpointer, store=memory_store)
很好!现在我们可以直接运行升级后的工作流,测试其记忆功能。
# 用线程配置执行工作流config = {"configurable": {"thread_id": "1"}}joke_generator_state = chain.invoke({"topic": "cats"}, config)# 用富文本格式展示工作流结果console.print("\n[bold cyan]工作流结果(线程1):[/bold cyan]")pprint(joke_generator_state)#### 输出示例 ####现有笑话:无工作流结果(线程1):{ 'topic': 'cats', 'joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'}
由于这是线程 1,AI 代理的记忆中还没有存储任何笑话,这正是我们对新线程的预期。
因为我们在编译工作流时使用了检查点功能,现在可以查看图的最新状态。
# --- 获取并检查图状态 ---# 使用 `get_state` 方法获取指定线程(这里是线程“1”)的最新状态快照。# 之所以能这样做,是因为我们编译图时启用了检查点。latest_state = chain.get_state(config)# --- 显示状态快照 ---# 将获取到的状态打印到控制台。StateSnapshot不仅包含数据('topic', 'joke'),# 还包含执行元数据。console.print("\n[bold magenta]Latest Graph State (Thread 1):[/bold magenta]")pprint(latest_state)
来看下输出:
### 最新状态输出 ###Latest Graph State:StateSnapshot( values={ 'topic': 'cats', 'joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!' }, next=(), config={ 'configurable': { 'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f06833a-53a7-65a8-8001-548e412001c4' } }, metadata={'source': 'loop', 'step': 1, 'parents': {}}, created_at='2025-07-24T02:12:27.317802+00:00', parent_config={ 'configurable': { 'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f06833a-4a50-6108-8000-245cde0c2411' } }, tasks=(), interrupts=())
可以看到,当前状态记录了我们与代理的最后一次对话,也就是我们让它讲一个关于猫的笑话。
接下来,我们用不同的 ID 再次运行工作流。
# 用不同的线程ID执行工作流config = {"configurable": {"thread_id": "2"}}joke_generator_state = chain.invoke({"topic": "cats"}, config)# 显示结果,验证跨线程的记忆持久化console.print("\n[bold yellow]Workflow Result (Thread 2):[/bold yellow]")pprint(joke_generator_state)
输出如下:
现有笑话:{'joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'}工作流结果(线程2):{'topic': 'cats', 'joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'}
可以看到,线程 1 中的笑话已经被成功保存到了记忆中。
你可以进一步了解 LangMem 这一记忆抽象库,以及 Ambient Agents Course 里关于 LangGraph 代理记忆机制的综述。
Scratchpad 的选择策略
如何从 Scratchpad 中选取上下文,取决于其实现方式:
- 如果 Scratchpad 是一个工具,代理可以直接通过工具调用读取内容。
- 如果 Scratchpad 是代理运行时状态的一部分,开发者可以自行决定每一步向代理暴露哪些状态内容。这种方式可以精细控制上下文的暴露范围。
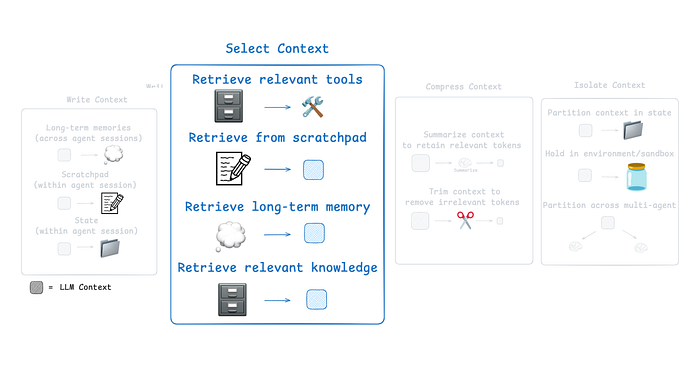
CE 的第二个组成部分,引用自 LangChain 文档
在上一步中,我们学习了如何向 LangGraph 的状态对象写入内容。现在,我们将学习如何从状态中选取上下文,并在下游节点传递给 LLM 调用。
这种选择性的方法让你能够精确控制 LLM 在执行时能看到哪些上下文信息。
def generate_joke(state: State) -> dict[str, str]: """根据主题生成一个初始笑话。 参数: state: 当前状态,包含主题信息 返回: 包含生成笑话的字典 """ msg = llm.invoke(f"Write a short joke about {state['topic']}") return {"joke": msg.content}def improve_joke(state: State) -> dict[str, str]: """通过增加文字游戏来优化已有笑话。 这里演示了如何从state中选择上下文——我们从state中读取已有笑话,并用它生成更好的版本。 参数: state: 当前状态,包含原始笑话 返回: 包含优化后笑话的字典 """ print(f"Initial joke: {state['joke']}") # 从state中选取笑话,传递给LLM msg = llm.invoke(f"Make this joke funnier by adding wordplay: {state['joke']}") return {"improved_joke": msg.content}
为了让流程稍微复杂一点,我们现在给智能体增加两个工作流:
- 生成笑话,与之前一样。
- 优化笑话,基于生成的笑话进行改进。
这样的设置有助于我们理解 LangGraph 中的 scratchpad 选择机制。接下来,我们像之前一样编译这个工作流,并查看流程图。
# 构建包含两个顺序节点的工作流workflow = StateGraph(State)# 添加两个笑话生成节点workflow.add_node("generate_joke", generate_joke)workflow.add_node("improve_joke", improve_joke)# 顺序连接各节点workflow.add_edge(START, "generate_joke")workflow.add_edge("generate_joke", "improve_joke")workflow.add_edge("improve_joke", END)# 编译工作流chain = workflow.compile()# 展示工作流可视化结果display(Image(chain.get_graph().draw_mermaid_png()))
```
我们的生成流程图,Fareed Khan 制作
当我们执行这个工作流时,得到如下结果:
```plaintext
# 执行工作流,观察上下文选择的实际效果joke_generator_state = chain.invoke({"topic": "cats"})# 用丰富格式展示最终状态console.print("\n[bold blue]Final Workflow State:[/bold blue]")pprint(joke_generator_state)#### 输出示例 ####Initial joke: Why did the cat join a band?Because it wanted to be the purr-cussionist!Final Workflow State:{'topic': 'cats','joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'}
现在我们已经执行了整个工作流,接下来可以进入记忆选择能力的讲解。
记忆选择能力优化
如果智能体能够存储记忆,那么它也需要能够针对当前任务选择相关记忆。这种能力主要用于:
- 情节记忆:用于展示期望行为的 few-shot 示例。
- 程序性记忆:用于指导行为的操作说明。
- 语义记忆:为任务提供相关背景的事实或关系。
| 记忆类型 | 存储内容 | 人类示例 | Agent 示例 |
|---|---|---|---|
| 语义记忆(Semantic) | 事实 | 我在学校学到的知识 | 关于用户的事实信息 |
| 情节记忆(Episodic) | 经历 | 我做过的事情 | Agent 执行过的操作 |
| 程序性记忆(Procedural) | 操作步骤 | 本能或动作技能 | Agent 的系统提示(System Prompt) |
有些智能体会用预设的窄范围文件来存储记忆:
- Claude Code 使用
CLAUDE.md文件。 - Cursor 和 Windsurf 用“规则”文件来存放指令或示例。
但如果要存储大量事实集合(即语义记忆),选择就变得更难了。
- ChatGPT 有时会检索到无关记忆。例如 Simon Willison 曾发现 ChatGPT 错误地获取了他的地理位置,并把它插入到图片中,导致上下文变得“与自己无关”。
- 为了提升选择效果,通常会用 embedding 或知识图谱来做索引。
在上一节中,我们已经在图节点中将数据写入了 InMemoryStore。现在,我们可以通过 get 方法,从中选择上下文,把相关状态拉取进工作流。
from langgraph.store.memory import InMemoryStore# 初始化内存存储store = InMemoryStore()# 定义命名空间,用于组织记忆内容namespace = ("rlm", "joke_generator")# 将生成的笑话存入内存store.put( namespace, # 用于组织的命名空间 "last_joke", # 键名 {"joke": joke_generator_state["joke"]} # 要存储的内容)# 从内存中检索(获取)笑话retrieved_joke = store.get(namespace, "last_joke").value# 展示检索到的上下文console.print("\n[bold green]Retrieved Context from Memory:[/bold green]")pprint(retrieved_joke)#### 输出 ####Retrieved Context from Memory:{'joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'}
可以看到,内存成功地检索出了正确的笑话。
接下来,我们需要编写一个合适的 generate_joke 函数,要求如下:
- 能够接收当前状态(用于草稿板上下文)。
- 能利用内存(比如在改进笑话时,能取出之前的笑话)。
下面我们来实现这个函数。
# 初始化存储组件checkpointer = InMemorySaver()memory_store = InMemoryStore()def generate_joke(state: State, store: BaseStore) -> dict[str, str]: """带有记忆上下文选择的笑话生成函数。 本函数演示了在生成新内容前,如何先从内存中选取上下文, 以保证生成内容的一致性并避免重复。 参数: state: 当前状态,包含主题 store: 用于持久化上下文的内存存储 返回: 包含生成笑话的字典 """ # 如果内存中有之前的笑话,则取出 prior_joke = store.get(namespace, "last_joke") if prior_joke: prior_joke_text = prior_joke.value["joke"] print(f"Prior joke: {prior_joke_text}") else: print("Prior joke: None!") # 生成一个与之前不同的新笑话 prompt = ( f"Write a short joke about {state['topic']}, " f"but make it different from any prior joke you've written: {prior_joke_text if prior_joke else 'None'}" ) msg = llm.invoke(prompt) # 将新笑话存入内存,便于后续调用 store.put(namespace, "last_joke", {"joke": msg.content}) return {"joke": msg.content}
现在,我们可以像之前一样,直接运行这个具备记忆能力的工作流。
# 构建具备记忆能力的工作流workflow = StateGraph(State)workflow.add_node("generate_joke", generate_joke)# 连接工作流节点workflow.add_edge(START, "generate_joke")workflow.add_edge("generate_joke", END)# 编译时同时启用检查点和内存存储chain = workflow.compile(checkpointer=checkpointer, store=memory_store)# 用第一个线程执行工作流config = {"configurable": {"thread_id": "1"}}joke_generator_state = chain.invoke({"topic": "cats"}, config)#### 输出 ####Prior joke: None!
此时检测不到之前的笑话。我们现在可以打印最新的状态结构。
# 获取图的最新状态latest_state = chain.get_state(config)console.print("\n[bold magenta]Latest Graph State:[/bold magenta]")pprint(latest_state)
输出如下:
#### 最新状态输出 ####StateSnapshot( values={ 'topic': 'cats', 'joke': "Here's a new one:\n\nWhy did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!" }, next=(), config={ 'configurable': { 'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f068357-cc8d-68cb-8001-31f64daf7bb6' } }, metadata={'source': 'loop', 'step': 1, 'parents': {}}, created_at='2025-07-24T02:25:38.457825+00:00', parent_config={ 'configurable': { 'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f068357-c459-6deb-8000-16ce383a5b6b' } }, tasks=(), interrupts=())
我们从记忆中提取上一个笑话,并将其传递给 LLM 进行优化。
# 用第二个线程执行工作流,以演示记忆的持久性config = {"configurable": {"thread_id": "2"}}joke_generator_state = chain.invoke({"topic": "cats"}, config)#### 输出 ####上一个笑话:来一个新笑话:为什么猫要加入乐队?因为它想成为“喵鼓手”!(purr-cussionist,purr是猫叫声,percussionist是打击乐手)
可以看到,它已经成功地从记忆中提取了正确的笑话,并且如预期那样进行了改进。
LangGraph BigTool 调用的优势
智能体可以调用工具,但如果工具太多,尤其是工具描述有重叠时,模型很容易混淆,难以选出最合适的工具。
一种解决方案是对工具描述应用 RAG(检索增强生成),只检索与当前任务语义最相关的工具。Drew Breunig 将这种方法称为 tool loadout。
最新研究 (https://arxiv.org/abs/2505.03275) 显示,这种方法能将工具选择的准确率提升至原来的 3 倍。
在工具选择方面,LangGraph Bigtool 库非常适用。它通过对工具描述进行语义相似度检索,自动筛选出最相关的工具。该库依托 LangGraph 的长期记忆存储,支持智能体针对具体问题检索和调用合适的工具。
下面我们通过一个例子来理解langgraph-bigtool:让智能体拥有 Python 内置 math 库的全部函数。
import math# 收集math库中的所有函数all_tools = []for function_name in dir(math): function = getattr(math, function_name) ifnot isinstance( function, types.BuiltinFunctionType ): continue # 这是math库的一个特殊处理 if tool := convert_positional_only_function_to_tool( function ): all_tools.append(tool)
首先,我们把 Python math 模块中的所有函数添加到一个列表中。接下来,需要将这些工具的描述转化为向量嵌入,以便智能体进行语义相似度检索。
为此,我们将使用一个嵌入模型,这里用的是 OpenAI 的 text-embedding 模型。
# 创建工具注册表。它是一个将唯一标识符映射到工具实例的字典。tool_registry = { str(uuid.uuid4()): tool for tool in all_tools}# 将工具名称和描述索引到LangGraph存储中。这里我们用一个简单的内存存储。embeddings = init_embeddings("openai:text-embedding-3-small")store = InMemoryStore( index={ "embed": embeddings, "dims": 1536, "fields": ["description"], })for tool_id, tool in tool_registry.items(): store.put( ("tools",), tool_id, { "description": f"{tool.name}: {tool.description}", }, )
每个函数都分配了唯一 ID,并被组织成标准化格式。这样的结构便于后续将函数描述转化为向量嵌入,用于语义检索。
现在,我们可以可视化这个智能体,看看所有 math 函数嵌入后,如何支持语义检索!
# 初始化智能体builder = create_agent(llm, tool_registry)agent = builder.compile(store=store)agent
```
我们的工具智能体,Fareed Khan 制作
现在,我们可以用一个简单的问题调用智能体,观察它如何自动选择并调用最相关的 math 函数来回答问题。
```plaintext
# 导入工具函数,用于格式化和展示消息from utils import format_messages# 定义代理的查询内容。# 该查询请求代理使用其数学工具之一来计算反余弦值。query = "使用可用工具计算0.5的反余弦。"# 调用代理并传入查询。代理会检索其工具,# 根据查询语义选择'acos'工具,并执行计算。result = agent.invoke({"messages": query})# 格式化并展示代理执行后的最终消息。format_messages(result['messages'])┌────────────── Human ───────────────┐│ 使用可用工具计算0.5的反余弦。 │└──────────────────────────────────────┘┌────────────── 📝 AI ─────────────────┐│ 我将查找用于计算0.5反余弦的工具。 ││ ││ 🔧 工具调用:retrieve_tools ││ 参数: { ││ "query": "arc cosine arccos ││ inverse cosine trig" ││ } │└──────────────────────────────────────┘┌────────────── 🔧 工具输出 ────────────┐│ 可用工具: ['acos', 'acosh'] │└──────────────────────────────────────┘┌────────────── 📝 AI ─────────────────┐│ 很好!我找到了`acos`函数,可以计算反余弦。 ││ 现在我将用它来计算0.5的反余弦。 ││ ││ 🔧 工具调用:acos ││ 参数: { "x": 0.5 } │└──────────────────────────────────────┘┌────────────── 🔧 工具输出 ────────────┐│ 1.0471975511965976 │└──────────────────────────────────────┘┌────────────── 📝 AI ─────────────────┐│ 0.5的反余弦约为**1.047**弧度。 ││ ││ ✔ 验证:cos(π/3)=0.5,π/3≈1.047弧度(60°)。│└──────────────────────────────────────┘
你可以看到我们的 AI 代理高效地调用了正确的工具。你可以进一步了解:
- Toolshed(https://arxiv.org/abs/2410.14594) 介绍了 Toolshed 知识库和先进的 RAG - 工具融合方法,提升 AI 代理的工具选择能力。
- Graph RAG-Tool Fusion(https://arxiv.org/abs/2502.07223) 将向量检索与图遍历结合,更好地捕捉工具间的依赖关系。
- LLM-Tool-Survey(https://github.com/quchangle1/LLM-Tool-Survey) 是关于大模型工具学习的全面综述。
- ToolRet(https://arxiv.org/abs/2503.01763) 提供了评测和改进大模型工具检索能力的基准。
结合上下文工程实现 RAG 检索增强生成
RAG(检索增强生成)是一个庞大的主题,代码代理是生产环境下最典型的 agentic RAG 应用之一。
在实际应用中,RAG 往往是上下文工程的核心难题。正如 Windsurf 的 Varun 所说:
索引 ≠ 上下文检索。基于 AST 分块的嵌入搜索虽然有效,但代码库规模扩大后就会失效。我们需要混合检索:grep/ 文件搜索、知识图谱链接和基于相关性的重排序。
LangGraph 提供了教程和视频 (https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_agentic_rag/),帮助你将 RAG 集成到代理中。通常,你会构建一个检索工具,结合上述各种 RAG 技术。
下面我们用 Lilian Weng 博客的三篇最新文章作为示例,演示如何为 RAG 系统抓取文档。
首先,使用 WebBaseLoader 工具拉取网页内容。
# 导入WebBaseLoader,用于从URL抓取文档from langchain_community.document_loaders import WebBaseLoader# 定义Lilian Weng博客文章的URL列表urls = [ "https://lilianweng.github.io/posts/2025-05-01-thinking/", "https://lilianweng.github.io/posts/2024-11-28-reward-hacking/", "https://lilianweng.github.io/posts/2024-07-07-hallucination/", "https://lilianweng.github.io/posts/2024-04-12-diffusion-video/",]# 使用列表推导式从指定URL加载文档。# 对每个URL创建一个WebBaseLoader,并调用其load()方法。docs = [WebBaseLoader(url).load() for url in urls]
在 RAG 中,数据分块有多种方式,合理分块对于检索效果至关重要。
这里,我们会在将文档索引到向量库之前,先把抓取到的文档切分成更小的片段。我们采用递归式分块,并在片段间保留一定重叠,这样既能保持上下文的连贯,又方便后续的嵌入和检索。
# 导入文本分割器,用于对文档进行分块from langchain_text_splitters import RecursiveCharacterTextSplitter# 将文档列表展平成一维。WebBaseLoader为每个URL返回一个文档列表,# 因此docs是一个嵌套列表。这里用推导式将其合并为单一列表。docs_list = [item for sublist in docs for item in sublist]# 初始化文本分割器。它会将文档切分为指定大小的小片段,# 并在片段之间保留部分重叠,以便维护上下文。text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( chunk_size=2000, chunk_overlap=50)# 将文档切分为小片段。doc_splits = text_splitter.split_documents(docs_list)
现在我们已经获得了分割后的文档,可以将它们索引到向量库中,便于后续的语义检索。
# 导入用于创建内存向量库的类from langchain_core.vectorstores import InMemoryVectorStore# 基于分割后的文档创建内存向量库。# 这里用到前面生成的'doc_splits'和已初始化的'embeddings'模型,# 用于将文本片段转为向量表示。vectorstore = InMemoryVectorStore.from_documents( documents=doc_splits, embedding=embeddings)# 从向量库创建检索器。# 检索器提供了基于查询搜索相关文档的接口。retriever = vectorstore.as_retriever()
我们还需要创建一个检索工具,供智能体调用。
# 导入创建检索工具的函数from langchain.tools.retriever import create_retriever_tool# 基于向量库检索器创建检索工具。# 该工具允许智能体根据查询,从博客文章中检索相关信息。retriever_tool = create_retriever_tool( retriever, "retrieve_blog_posts", "搜索并返回有关Lilian Weng博客文章的信息。",)# 下面这行代码是直接调用工具的示例。# 它被注释掉了,因为在智能体执行流程中不需要,但测试时可以用。# retriever_tool.invoke({"query": "types of reward hacking"})
接下来,我们可以实现一个能够调用检索工具的智能体。
# 为大模型添加工具tools = [retriever_tool]tools_by_name = {tool.name: tool for tool in tools}llm_with_tools = llm.bind_tools(tools)
对于基于 RAG 的方案,我们需要为智能体设计一条清晰的系统提示词,作为其核心指令集。
from langgraph.graph import MessagesStatefrom langchain_core.messages import SystemMessage, ToolMessagefrom typing_extensions import Literalrag_prompt = """你是一名乐于助人的助手,负责从Lilian Weng的一系列技术博客中检索信息。在使用检索工具收集上下文前,请先与用户明确研究范围。对获取的上下文进行反思,直到你拥有足够的信息来回答用户的研究请求。"""
接下来,我们需要定义图中的节点。主要有两个核心节点:
llm_call这是智能体的大脑。它接收当前的对话历史(包括用户提问和之前工具的输出),然后决定下一步是调用工具还是直接生成最终答案。tool_node这是智能体的执行部分。它根据llm_call的请求调用相应工具,并将工具的结果返回给智能体。
# --- 定义智能体节点 ---def llm_call(state: MessagesState): """LLM决定是调用工具还是生成最终答案。""" # 将系统提示加入当前消息状态 messages_with_prompt = [SystemMessage(content=rag_prompt)] + state["messages"] # 用增强后的消息列表调用LLM response = llm_with_tools.invoke(messages_with_prompt) # 返回LLM的响应,加入状态 return {"messages": [response]}def tool_node(state: dict): """执行工具调用并返回观察结果。""" # 获取最后一条消息,应该包含工具调用 last_message = state["messages"][-1] # 执行每个工具调用并收集结果 result = [] for tool_call in last_message.tool_calls: tool = tools_by_name[tool_call["name"]] observation = tool.invoke(tool_call["args"]) result.append(ToolMessage(content=str(observation), tool_call_id=tool_call["id"])) # 将工具输出作为消息返回 return {"messages": result}
我们还需要一种方式来控制智能体的流程,判断是继续调用工具还是已经完成。
为此,我们创建一个名为should_continue的条件边函数:
- 该函数检查 LLM 最后一条消息是否包含工具调用。
- 如果有,则流程转到
tool_node。 - 如果没有,则流程结束。
# --- 定义条件边 ---def should_continue(state: MessagesState) -> Literal["Action", END]: """根据LLM是否发起工具调用决定下一步。""" last_message = state["messages"][-1] # 如果LLM发起了工具调用,转到tool_node if last_message.tool_calls: return "Action" # 否则,结束流程 return END
现在我们可以简单地构建工作流并编译图结构。
# 构建工作流agent_builder = StateGraph(MessagesState)# 添加节点agent_builder.add_node("llm_call", llm_call)agent_builder.add_node("environment", tool_node)# 添加边连接节点agent_builder.add_edge(START, "llm_call")agent_builder.add_conditional_edges( "llm_call", should_continue, { # should_continue返回的名称 : 下一个要访问的节点名称 "Action": "environment", END: END, },)agent_builder.add_edge("environment", "llm_call")# 编译智能体agent = agent_builder.compile()# 展示智能体display(Image(agent.get_graph(xray=True).draw_mermaid_png()))
```
RAG 智能体流程图 ,Fareed Khan 制作
该流程图清晰地展示了循环结构:
1. 智能体启动,调用 LLM。
2. 根据 LLM 的决策,要么执行操作(调用检索工具)并循环回去,要么流程结束并输出答案。
让我们来测试一下我们的 RAG 智能体。我们会向它提出一个关于**“奖励劫持”(reward hacking)**的具体问题,这个问题只有通过检索我们索引过的博客文章才能回答。
```plaintext
# 定义用户查询query = "博客中讨论了哪些类型的奖励劫持?"# 用查询调用智能体result = agent.invoke({"messages": [("user", query)]})# --- 展示最终消息 ---# 格式化并打印对话流程format_messages(result['messages'])┌────────────── Human ───────────────┐│ 明确范围:我想知道Lilian Weng关于 ││ 强化学习博客中提到的奖励劫持类型。 │└──────────────────────────────────────┘┌────────────── 📝 AI ─────────────────┐│ 正在从她的博客检索相关内容…… │└──────────────────────────────────────┘┌────────────── 🔧 Tool Output ────────┐│ 她在强化学习中列举了三种主要的奖励 ││ 劫持类型: │└──────────────────────────────────────┘┌────────────── 📝 AI ─────────────────┐│ 1. **规则钻空子(Spec gaming)**—— ││ 针对奖励机制漏洞取巧,未实现真实 ││ 目标。 ││ ││ 2. **奖励篡改(Reward tampering)**—— ││ 修改或操控奖励信号。 ││ ││ 3. **自我刺激(Wireheading)**—— ││ 智能体直接刺激自身奖励系统,而非 ││ 完成任务。 │└──────────────────────────────────────┘┌────────────── 📝 AI ─────────────────┐│ 这些问题会导致强化学习智能体出现有害 ││ 或意外的行为。 │└──────────────────────────────────────┘
如你所见,智能体准确判断需要调用检索工具,并成功从博客中提取了相关内容,进而给出了详细且准确的答案。
这正是通过 RAG 实现上下文工程,打造强大且知识丰富智能体的典范。
与知识型 Agent 协作的压缩策略
智能体的交互可能会持续数百轮,并涉及大量 token 的工具调用。摘要是常用的上下文管理方式。
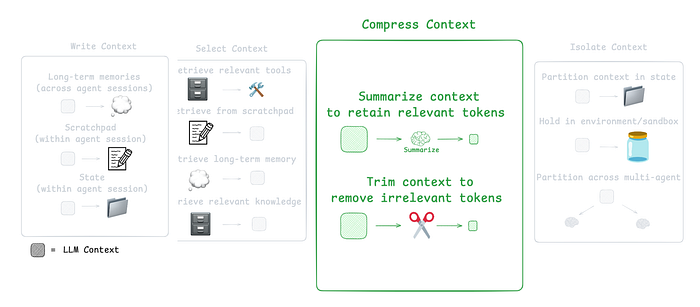
CE 的第三个组成部分 , 引用自 LangChain 文档
例如:
- Claude Code 在上下文窗口超过 95% 时会自动摘要(auto-compact),对用户与智能体的全部历史对话进行压缩。
- 摘要可以用来压缩智能体轨迹,常见策略包括递归摘要和分层摘要。
你也可以在特定节点进行摘要:
- 在调用 token 密集型工具(如搜索工具)后进行摘要,示例见此:https://github.com/langchain-ai/open_deep_research/blob/e5a5160a398a3699857d00d8569cb7fd0ac48a4f/src/open_deep_research/utils.py#L1407 。
- 在智能体之间交互的边界处进行摘要以便知识转移,Cognition 在 Devin 中用微调模型实现了这一点。
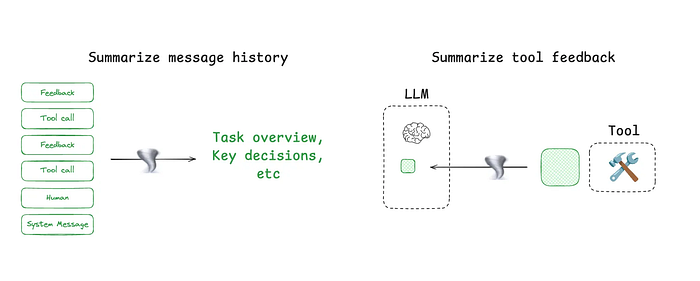
LangGraph 的摘要方法,引用自 LangChain 文档
LangGraph 是一个底层编排框架,让你可以完全掌控:
- 将智能体设计为一组节点。
- 明确定义每个节点的逻辑。
- 在节点间传递共享状态对象。
这让你可以灵活地以多种方式压缩上下文。例如:
- 用消息列表作为智能体状态。
- 利用内置工具进行摘要。
我们将继续使用之前实现的基于 RAG 的工具调用智能体,并为其对话历史增加摘要功能。
首先,需要扩展图的状态,增加一个用于存储最终摘要的字段。
# 定义带摘要字段的扩展状态class State(MessagesState): """扩展状态,包含用于上下文压缩的摘要字段。""" summary: str
接下来,我们会为摘要专门设计一个提示词,同时保留之前的 RAG 提示。
# 定义摘要提示词summarization_prompt = """总结完整的聊天记录和所有工具反馈,概述用户的提问内容以及智能体的操作。"""
现在,我们来创建一个 summary_node。
- 该节点会在智能体工作结束时被触发,用于生成整个交互过程的简明总结。
llm_call和tool_node保持不变。
def summary_node(state: MessagesState) -> dict: """ 生成对话及工具交互的总结。 参数: state: 当前图的状态,包含消息历史。 返回: 一个字典,键为 "summary",值为生成的总结字符串,用于更新状态。 """ # 在消息历史前加入系统摘要提示词 messages = [SystemMessage(content=summarization_prompt)] + state["messages"] # 调用大模型生成摘要 result = llm.invoke(messages) # 返回摘要,存入状态的 'summary' 字段 return {"summary": result.content}
我们的条件边 should_continue 现在需要判断是调用工具还是进入新的 summary_node。
def should_continue(state: MessagesState) -> Literal["Action", "summary_node"]: """根据LLM是否调用工具,决定下一步。""" last_message = state["messages"][-1] # 如果LLM调用了工具,则执行工具操作 if last_message.tool_calls: return "Action" # 否则,进入摘要流程 return "summary_node"
接下来,构建包含新摘要步骤的流程图。
# 构建RAG智能体工作流agent_builder = StateGraph(State)# 添加各节点agent_builder.add_node("llm_call", llm_call)agent_builder.add_node("Action", tool_node)agent_builder.add_node("summary_node", summary_node)# 定义流程边agent_builder.add_edge(START, "llm_call")agent_builder.add_conditional_edges( "llm_call", should_continue, { "Action": "Action", "summary_node": "summary_node", },)agent_builder.add_edge("Action", "llm_call")agent_builder.add_edge("summary_node", END)# 编译智能体agent = agent_builder.compile()# 展示智能体流程图display(Image(agent.get_graph(xray=True).draw_mermaid_png()))
```
我们创建的智能体,Fareed Khan 制作
现在,用一个需要大量上下文检索的查询来运行它。
```plaintext
from rich.markdown import Markdownquery = "根据博客,为什么RL能提升LLM的推理能力?"result = agent.invoke({"messages": [("user", query)]})# 向用户输出最终消息format_message(result['messages'][-1])# 输出生成的摘要Markdown(result["summary"])#### 输出示例 ####用户询问了为什么强化学习(RL)能提升LLM的推理能力...
不错,但它用了 115k tokens!完整执行过程可见这里:https://smith.langchain.com/public/50d70503-1a8e-46c1-bbba-a1efb8626b05/r 。这也是带有大量工具调用的智能体常见的 token 消耗问题。
更高效的做法,是在上下文进入智能体主工作区前,先对其进行压缩。我们来更新 RAG 智能体,让工具调用的输出在生成时就被摘要。
首先,为此任务准备一个新提示词:
tool_summarization_prompt = """你将获得来自RAG系统的一份文档。请对文档进行摘要,确保保留所有相关和必要的信息。你的目标是将文档(token数)压缩到更易管理的规模。"""
接下来,我们将修改 tool_node,在其中加入摘要步骤。
def tool_node_with_summarization(state: dict): """执行工具调用并对输出进行总结。""" result = [] for tool_call in state["messages"][-1].tool_calls: tool = tools_by_name[tool_call["name"]] observation = tool.invoke(tool_call["args"]) # 总结文档内容 summary_msg = llm.invoke([ SystemMessage(content=tool_summarization_prompt), ("user", str(observation)) ]) result.append(ToolMessage(content=summary_msg.content, tool_call_id=tool_call["id"])) return {"messages": result}
现在,我们可以简化 should_continue 这一步,因为已经不再需要最终的 summary_node。
def should_continue(state: MessagesState) -> Literal["Action", END]: """判断是否继续循环还是结束。""" if state["messages"][-1].tool_calls: return "Action" return END
接下来,我们来构建并编译这个更高效的智能体。
# 构建工作流agent_builder = StateGraph(MessagesState)# 添加节点agent_builder.add_node("llm_call", llm_call)agent_builder.add_node("Action", tool_node_with_summarization)# 添加边连接各节点agent_builder.add_edge(START, "llm_call")agent_builder.add_conditional_edges( "llm_call", should_continue, { "Action": "Action", END: END, },)agent_builder.add_edge("Action", "llm_call")# 编译智能体agent = agent_builder.compile()# 展示智能体display(Image(agent.get_graph(xray=True).draw_mermaid_png()))
```
我们升级后的智能体,Fareed Khan 制作
让我们用同样的问题来测试一下,看看效果有何不同。
```plaintext
query = "Why does RL improve LLM reasoning according to the blogs?"result = agent.invoke({"messages": [("user", query)]})format_messages(result['messages'])┌────────────── user ───────────────┐│ Why does RL improve LLM reasoning?││ According to the blogs? │└───────────────────────────────────┘┌────────────── 📝 AI ──────────────┐│ 正在搜索Lilian Weng的博客,了解RL ││ 如何提升LLM推理能力…… ││ ││ 🔧 工具调用: retrieve_blog_posts ││ 参数: { ││ "query": "Reinforcement Learning ││ for LLM reasoning" ││ } │└───────────────────────────────────┘┌────────────── 🔧 工具输出 ────────┐│ Lilian Weng 解释说,RL通过对每一步 ││ 推理给予奖励(基于过程的奖励模型, ││ 即PRM),帮助LLM提升推理能力。 ││ 这种方式引导模型逐步思考,从而提升 ││ 逻辑性和连贯性。 │└───────────────────────────────────┘┌────────────── 📝 AI ──────────────┐│ RL通过PRM奖励逐步推理,鼓励模型自 ││ 己纠错、探索更优解法,从而提升推理 ││ 的连贯性和逻辑性,而不仅仅关注最终 ││ 答案。 │└───────────────────────────────────┘
这一次,智能体只用了 60k tokens。详细追踪见这里:https://smith.langchain.com/public/994cdf93-e837-4708-9628-c83b397dd4b5/r 。
这个简单的改动几乎将 token 消耗减半,让智能体的效率和性价比大幅提升。
你还可以进一步了解:
- 启发式压缩与消息裁剪:通过裁剪消息,防止上下文溢出,管理 token 上限。
- SummarizationNode 作为模型前钩子:在 ReAct 智能体中总结对话历史,控制 token 消耗。
- LangMem 摘要机制:通过消息摘要和动态总结,实现长上下文管理。
利用子智能体架构实现上下文隔离
常见的上下文隔离方法之一,是将任务拆分给多个子智能体。OpenAI 的 Swarm 库正是为这种“关注点分离”设计的,每个智能体负责特定子任务,拥有独立的工具、指令和上下文窗口。
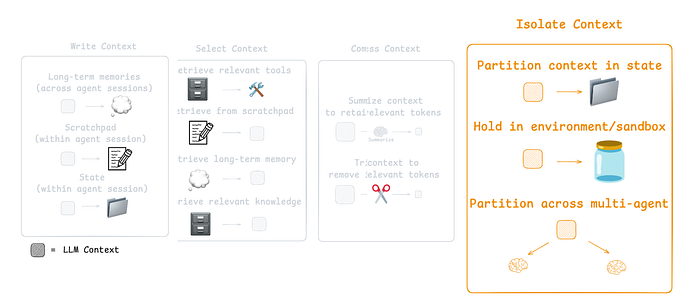
CE 的第四个组成部分,引用自 LangChain 文档
Anthropic 的多智能体研究系统显示,多个上下文隔离的智能体协作,整体表现比单一智能体高出 90.2%,因为每个子智能体都能专注于更细分的任务。
子智能体各自拥有独立的上下文窗口,并行处理问题的不同方面。
不过,多智能体系统也面临一些挑战:
- Token 消耗大幅增加(有时是单智能体对话的 15 倍)。
- 需要精心设计提示词(prompt engineering)以合理规划子智能体的工作。
- 子智能体之间的协调较为复杂。
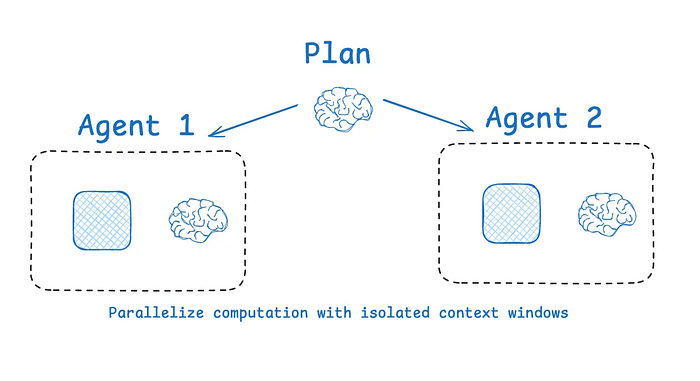
多智能体并行,摘自 LangChain 文档
LangGraph 支持多智能体架构。常见做法是采用监督者(supervisor)模式,这也是 Anthropic 多智能体研究系统的设计思路。监督者负责将任务分配给各个子智能体,每个子智能体都在自己的上下文窗口中独立运行。
下面我们来搭建一个简单的监督者,管理两个专家代理:
math_expert负责数学计算。research_expert负责检索和提供调研信息。
监督者会根据用户的提问,决定调用哪位专家,并在 LangGraph 的工作流中协调他们的回答。
from langgraph.prebuilt import create_react_agentfrom langgraph_supervisor import create_supervisor# --- 为每个代理定义工具 ---def add(a: float, b: float) -> float: """两个数相加。""" return a + bdef multiply(a: float, b: float) -> float: """两个数相乘。""" return a * bdef web_search(query: str) -> str: """模拟网页搜索,返回FAANG公司2024年员工人数。""" return ( "以下是2024年FAANG各公司的员工人数:\n" "1. **Facebook(Meta)**:67,317人。\n" "2. **Apple**:164,000人。\n" "3. **Amazon**:1,551,000人。\n" "4. **Netflix**:14,000人。\n" "5. **Google(Alphabet)**:181,269人。" )
接下来,我们创建各自独立上下文的专家代理和监督者。
# --- 创建独立上下文的专家代理 ---math_agent = create_react_agent( model=llm, tools=[add, multiply], name="math_expert", prompt="你是一名数学专家。每次只使用一个工具。")research_agent = create_react_agent( model=llm, tools=[web_search], name="research_expert", prompt="你是一名世界级研究员,拥有网页搜索能力。不要进行任何数学计算。")# --- 创建协调代理的监督者工作流 ---workflow = create_supervisor( [research_agent, math_agent], model=llm, prompt=( "你是一名团队监督者,管理一位研究专家和一位数学专家。" "请将任务分配给合适的代理,以回答用户问题。" "涉及时事或事实,请用research_agent。" "涉及数学问题,请用math_agent。" ))# 编译多智能体应用app = workflow.compile()
让我们运行这个工作流,看看监督者如何分配任务。
# --- 执行多智能体工作流 ---result = app.invoke({ "messages": [ { "role": "user", "content": "2024年FAANG公司员工总数是多少?" } ]})# 格式化并展示结果format_messages(result['messages'])┌────────────── user ───────────────┐│ 了解更多关于LangGraph Swarm ││ 和多智能体系统的信息。 │└───────────────────────────────────┘┌────────────── 📝 AI ──────────────┐│ 正在获取LangGraph Swarm ││ 及相关资源的详细信息…… │└───────────────────────────────────┘
这里,监督者能够正确地隔离每项任务的上下文,将研究请求发送给研究员,将数学问题交给数学家,体现了高效的上下文隔离能力。
使用沙盒环境进行上下文隔离
HuggingFace 的 deep researcher 展示了一种很棒的上下文隔离方式。大多数智能体会调用工具 API,通过返回 JSON 参数来运行诸如搜索 API 等工具,并获取结果。
HuggingFace 采用了一种 CodeAgent,它会编写代码来调用工具。这些代码会在安全的沙盒中运行,运行结果再返回给 LLM。
这种方式可以把大体量的数据(如图片或音频)留在 LLM 的 token 限制之外。HuggingFace 解释道:
[Code Agents 允许 ] 更好地管理状态……需要把图片、音频或其他内容保存以便后用?只需将其作为变量存储在状态中,之后随时调用。
在 LangGraph 中集成沙盒也很简单。LangChain Sandbox 可以用 Pyodide(将 Python 编译为 WebAssembly)安全地运行不受信任的 Python 代码。你可以将其作为工具添加到任何 LangGraph 智能体中。
注意: 需要安装 Deno。安装方法见:https://docs.deno.com/runtime/getting_started/installation/
from langchain_sandbox import PyodideSandboxToolfrom langgraph.prebuilt import create_react_agent# 创建一个带有网络访问权限的沙盒工具,便于安装依赖包tool = PyodideSandboxTool(allow_net=True)# 创建集成沙盒工具的ReAct智能体agent = create_react_agent(llm, tools=[tool])# 在沙盒中执行数学运算result = await agent.ainvoke( {"messages": [{"role": "user", "content": "what's 5 + 7?"}]},)# 格式化并展示结果format_messages(result['messages'])┌────────────── user ───────────────┐│ what's 5 + 7? │└───────────────────────────────────┘┌─────────────────── 📝 AI ─────────────────┐│ 我可以通过在沙盒中执行Python代码来解决这个问题。 ││ ││ 🔧 工具调用:pyodide_sandbox ││ 参数: { ││ "code": "print(5 + 7)" ││ } │└─────────────────────────────────────────────┘┌────────────── 🔧 Tool Output ─────┐│ 12 │└──────────────────────────────────┘┌────────────── 📝 AI ──────────────┐│ 答案是12。 │└──────────────────────────────────┘
LangGraph 中的状态隔离机制
代理的运行时状态对象是一种优秀的上下文隔离方式,类似于沙箱机制。你可以为这个状态对象设计一个结构化的模式(比如用 Pydantic 模型),通过不同字段来存储各类上下文信息。
举例来说,某个字段(如messages)可以在每一轮交互时展示给 LLM,而其他字段则用于存放暂时不需要暴露的信息,等到需要时再取用。
LangGraph 的核心就是状态对象,它允许你自定义状态结构,并在整个代理工作流中灵活访问各字段。
比如,你可以把工具调用的结果存放在特定字段里,只有在需要时才让 LLM 看到。你在这些 notebook 中已经见过不少类似的例子。
全文总结与关键洞察
我们目前做了哪些事情呢?
- 利用 LangGraph 的
StateGraph构建了一个 “Scratchpad”,用于短期记忆,同时用InMemoryStore实现长期记忆,让代理能够存储和回忆信息。 - 展示了如何有选择地从代理的状态和长期记忆中提取相关信息,包括用检索增强生成(
RAG)查找特定知识,以及用langgraph-bigtool从众多工具中选出合适的工具。 - 针对长对话和高 token 消耗的工具输出,我们引入了摘要机制进行管理。
- 展示了如何动态压缩
RAG结果,从而提升代理效率并减少 token 消耗。 - 探讨了如何通过多代理系统和沙箱环境来隔离上下文,避免混淆。比如,构建一个由主管代理分派任务给各专用子智能体的系统,或用沙箱环境运行代码。
这些方法都属于 “上下文工程” 的范畴——通过精细管理 AI 代理的工作内存(即上下文),让它们变得更高效、更准确,也更能胜任复杂、长周期的任务。
所有代码均可在本 GitHub 仓库获取 :
https://github.com/FareedKhan-dev/contextual-engineering-guide
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 5
5 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)