
别让AI“失忆“!OpenClaw三步打造靠谱的长期记忆架构
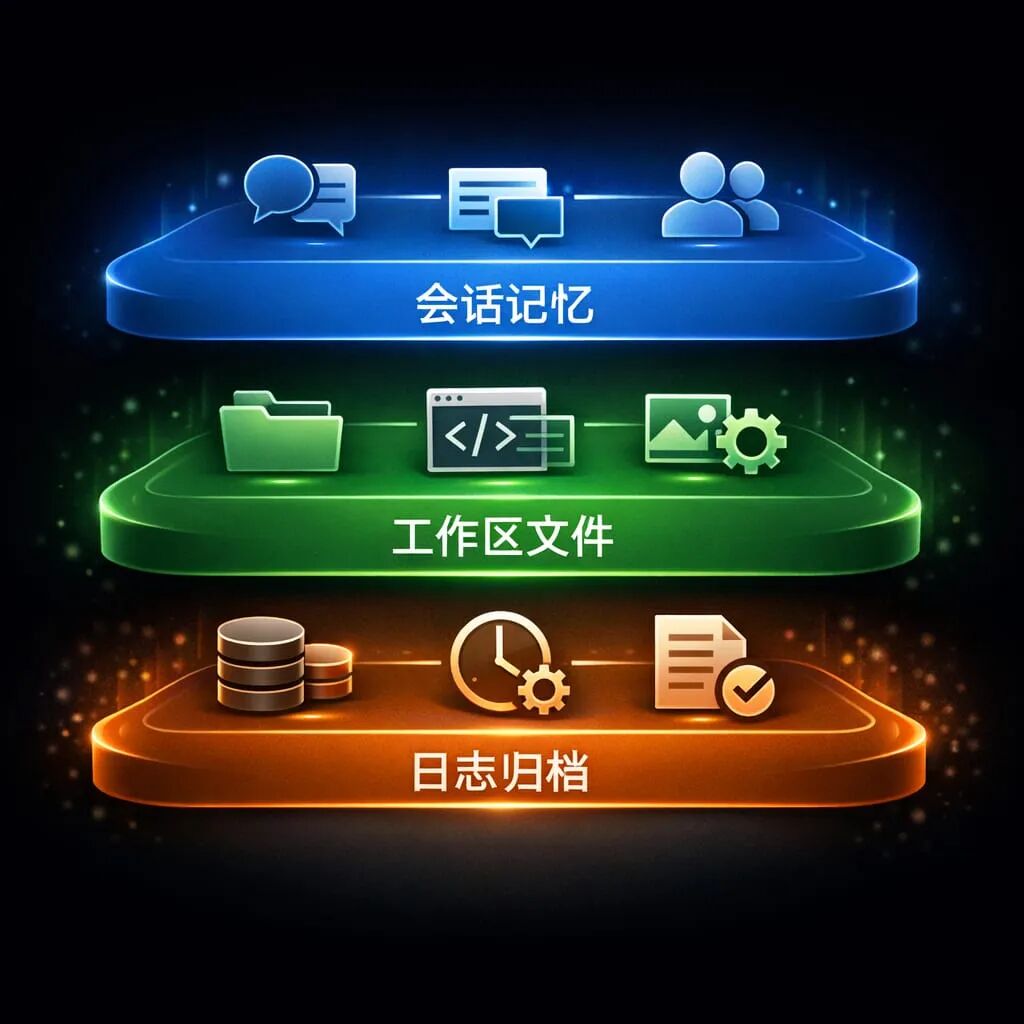
《AI记忆架构设计:OpenClaw的三层记忆系统解析》 当前AI面临的核心痛点在于无法保持连续性记忆,导致每次对话都像重启。OpenClaw创新性地提出三层记忆架构:1)会话记忆层处理当前任务,通过压缩机制保持单次任务连贯性;2)工作区文件层存储稳定偏好,以可编辑的Markdown文件形式保存用户设定和工具配置;3)日志归档层记录历史交互,形成可检索的长期经验库。这种分层设计将记忆从黑箱变为透明
都会经历一个非常别扭的瞬间:当下聊得很顺,它也能执行任务、读文件、调工具,像一个已经进入工作状态的同事;可一旦你结束对话、隔天再来,之前反复强调过的偏好、项目背景、口吻要求、工作习惯,常常像被一键清空。
这也是为什么很多人会觉得,AI 很聪明,但"不靠谱"——它能回答问题,却不一定能持续协作;它能完成任务,却很难形成真正的连续关系。归根到底,不是模型完全不行,而是"记忆"这件事如果只靠聊天窗口本身,天然就不够。
OpenClaw 的设计很有产品感——它没有把"记忆"理解成单一功能,而是拆成三层,用不同机制承载不同类型的信息。
一、会话记忆:处理眼前任务的工作记忆
第一层是最直观的——会话上下文。你在当前对话中说过的话、上传过的文件、确认的任务目标、执行过的步骤,都在这层里。非常像人的工作记忆:最快、最贴近当前任务、也是 AI 作出连续反应的基础。
OpenClaw 在这层不是简单堆 token,而是配合压缩机制。当上下文变长,系统会做 compaction,把重要信息结构化压缩后继续执行。
这层解决的核心问题:AI 如何在单次任务流程中保持连贯,而不是每一步都像重新开始。
二、工作区文件:把稳定偏好变成持久设定
真正让 OpenClaw 有"长期记忆感"的是第二层——工作区文件记忆。思路很朴素也很有效:与其让模型猜,不如把稳定信息显式写进文件,新会话启动时自动注入。
常见的工作区文件:

-
SOUL.md— 定义 agent 的人格、边界、语气和行为偏好
-
USER.md— 记录用户是谁、喜欢什么风格、有哪些长期项目
-
TOOLS.md— 保存环境细节,如设备、常用路径、操作注意事项
-
AGENTS.md— 说明多 agent 的分工方式和协作流程
-
IDENTITY.md— 沉淀 agent 自己的身份设定与风格形象
这些文件承载的是稳定、不应反复解释的信息。从产品设计角度看,它把"记忆"从黑箱拉到了用户可编辑、可审阅、可迁移的表层——你能看到它、改动它、版本化它,甚至团队共享。这种可控性,本身就是信任的一部分。
三、日志归档:沉淀经历,不只是保存设定
如果第二层解决的是"你是谁、你怎么做事",第三层解决的就是"你们一起经历过什么"。
OpenClaw 的第三层是日志归档记忆,如 memory/YYYY-MM-DD.md 按日期沉淀的记录,适合保存每日进展、关键结论、重要事件、踩过的坑、做过的决策。
**AI 不只是"知道规则",还能"记得经历"。**对一个长期运行的 agent 来说,经历往往比设定更有价值。
四、三层如何协作
- 用户在当前会话里提出任务 → 第一层承接当前目标与最近动作
- 系统启动时自动注入工作区文件 → 第二层把长期偏好、身份设定带进来
- 执行完成后归档到日志 → 第三层供未来检索和复用
真正成熟的长期记忆,不是把所有内容塞进一次对话,而是把不同类型的信息放进正确容器,需要时组合召回。
五、为什么这比"AI 自带记忆"更靠谱
市面上很多"记忆型 AI"会强调能自动记住偏好、总结习惯、形成个性化画像。这类能力有价值,但底层机制如果不可见、不可控,用户最终还是不放心。
OpenClaw 这套三层方案的优势在于更工程化、更透明——用户能明确区分"当前上下文"“长期设定”"历史归档"三类信息;第二层和第三层都以文件形式存在,天然支持审阅、修改、备份和迁移。
六、如果你也想搭一个"不会失忆"的 AI Agent

不妨先问自己三个问题:
- 当前任务的临时状态,是否有专门一层承接?
- 稳定偏好是否被显式写成可维护文件?
- 每次执行产生的经验,是否被持续归档且可检索?
把记忆分层,把信息归位,把经验沉淀。
总结
很多人以为 AI 是否有长期记忆取决于模型强不强。其实更关键的问题是:有没有一套好的记忆架构。
OpenClaw 的答案很直接——会话上下文负责当前任务;工作区文件保存稳定设定;日志归档沉淀长期经历。三层协作后,AI 看起来才像"没有忘记你"。
一句话:不是让 AI 记住一切,而是让它把重要信息放进正确的位置,需要时重新取回来。
如果你正在搭建自己的 AI Agent,这个思路比单纯追模型参数,更值得先做对。
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 **,**却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是最佳时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
-
掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
-
学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 8
8 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)