【懒人版】RAG技术快速入门(4)——详解嵌入模型下、Milvus实战
介绍了Milvus向量数据库
·
Milvus数据库介绍
向量嵌入可以做什么?
-
查找相似的图像、视频或音频文件。通过比较存储在向量数据库中的嵌入表示来进行高级搜索,例如通过声音线索找到图像或通过图像查询找到视频;
-
加速药物发现。编码化合物的化学结构,通过测量其与目标蛋白质的相似性来识别有前景的药物候选物;
-
提升搜索相关性的语义搜索。通过将内部文档嵌入到向量中,组织可以利用语义搜索来提高搜索结果的相关性,即使用检索增强生成的概念来理解查询背后的意图;
-
推荐系统。通过将用户和项目表示为嵌入来测量相似性,从而改变了推荐系统。这种方法使得可以根据个人偏好提供个性化推荐;
-
异常检测。通过将数据点表示为嵌入,可以通过计算距离或不相似性来检测异常,从而实现对潜在问题的早期识别和预防措施。
使用Milvus的原因
- 可拓展和弹性的架构。面向服务设计,确保了不同计算任务可以根据不同的工作负载独立扩展,提供细粒度的资源分配和隔离;
- 多样化的索引支持。支持超过 10 种索引类型,包括广泛使用的 HNSW、IVF、产品量化和基于 GPU 的索引;
- 多样化的搜索能力。提供了各种搜索类型,包括 Top-K Approximate Nearest Neighbor(ANN)、Range ANN 和带元数据过滤的搜索,混合密集和稀疏向量搜索等;
- 可调节的一致性。允许用户为查询数据指定“陈旧容忍度”,实现查询性能和数据新鲜度之间的平衡;
- 硬件加速计算支持。跟据不同应用程序的独特需求调整资源使用。
Milvus工作原理
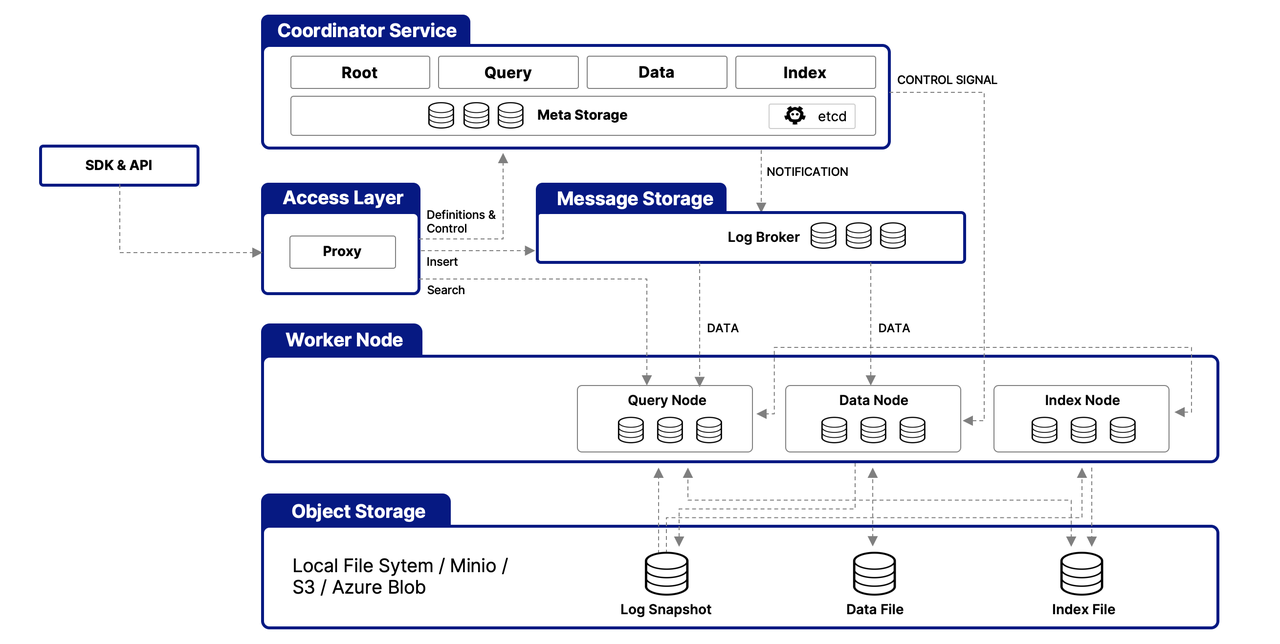
单机版部署安装
- 环境准备
安装Docker 与 Docker Compose
- 下载并启动Milvus
# docker-compose.yml定义了 Milvus Standalone 及其运行所需的两个核心依赖服务:etcd用于存储元数据,MinIO用于对象存储
wget https://github.com/milvus-io/milvus/releases/download/v2.5.14/milvus-standalone-docker-compose.yml -O docker-compose.yml
#在docker-compose.yml文件所在的目录中,启动Milvus
docker compose up -d
#验证 Milvus 是否成功启动
docker ps
#停用服务
docker compose down
#彻底清理
docker compose down -v
核心组件
数据容器——集合
Collection 是一个二维表,具有固定的列和变化的行。每列代表一个字段,每行代表一个实体。
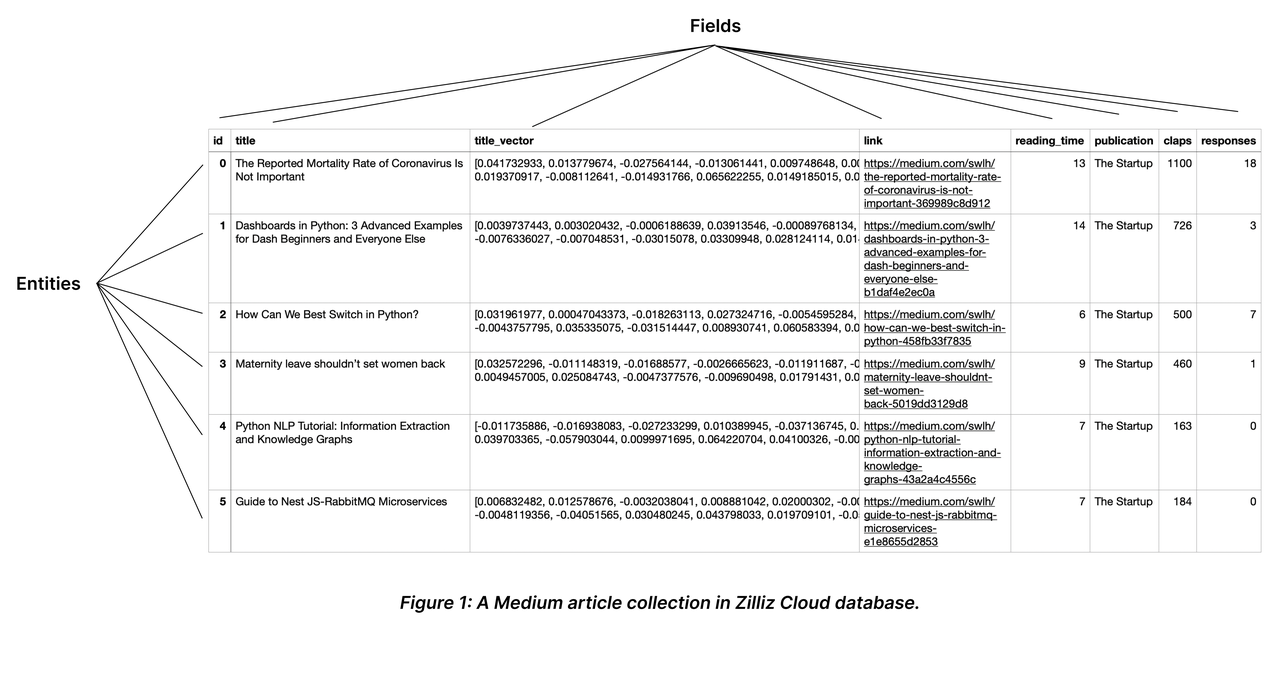
检索引擎——索引
向量数据库_浮动向量索引算法对比表
| 索引算法 | 核心原理 | 核心优点 | 核心缺点 | 适用场景 |
|---|---|---|---|---|
| FLAT(精确查找) | 暴力搜索(Brute-force Search),计算查询向量与集合内所有向量的实际距离,返回精确结果 | 1. 召回率100%,无遗漏相关向量; 2. 结果精度最高,无近似误差; 3. 索引构建简单,无需复杂预处理 |
1. 检索速度慢,随数据量增长呈线性变慢; 2. 内存占用大,需加载全量向量; 3. 无法应对海量数据 |
1. 数据规模较小(百万级以内); 2. 对精度要求极高(如科研实验、小样本精准匹配); 3. 低频查询场景 |
| IVF 系列(倒排文件索引) | 1. 先通过聚类将全量向量分成多个“桶”(nlist);2. 查询时仅搜索最相似的几个“桶”,桶内可结合 FLAT/SQ8/PQ 进一步优化 |
1. 大幅缩小搜索范围,检索速度远快于 FLAT; 2. 支持向量压缩(如SQ8/PQ),降低内存占用; 3. 性能与精度平衡,通用性强 |
1. 召回率非100%,可能遗漏跨“桶”的相关向量; 2. 聚类质量影响检索效果,需合理设置 nlist 等参数 |
1. 通用场景(如企业知识库检索、常规语义匹配); 2. 大规模数据集(千万级至亿级); 3. 需要高吞吐量的批量查询场景 |
| HNSW(基于图的索引) | 1. 构建多层邻近图(上层稀疏、下层密集); 2. 查询时从上层“快速导航”定位目标区域,再到下层精准搜索 |
1. 检索速度极快,支持低延迟查询(毫秒级响应); 2. 召回率高(接近 FLAT),近似误差小; 3. 对高维向量(如文本、图像嵌入)适配性好 |
1. 内存占用极大,需存储图结构与向量数据; 2. 索引构建时间长,预处理成本高; 3. 动态数据更新(增删向量)效率低 |
1. 对查询延迟有严格要求(如实时推荐、在线搜索、即时问答); 2. 高维向量检索场景(如多模态数据匹配); 3. 中大规模数据(千万级至亿级)且内存充足 |
| DiskANN(基于磁盘的索引) | 专为 SSD 等高速磁盘优化的图索引,将部分索引数据存储于磁盘,仅加载核心导航数据至内存 | 1. 支持超海量数据集(十亿级甚至更大),突破内存容量限制; 2. 兼顾低延迟(接近内存索引)与海量存储; 3. 存储成本低,无需依赖超大内存服务器 |
1. 延迟略高于纯内存索引(如 HNSW); 2. 检索性能依赖磁盘读写速度,对硬件有一定要求; 3. 索引维护(如动态更新)复杂度高 |
1. 数据规模巨大(十亿级及以上),无法全量加载至内存; 2. 需平衡存储成本与查询延迟(如大规模日志检索、海量商品库匹配); 3. 冷数据与热数据分离的场景 |
检索算法
Milvus 核心检索功能总结表
| 检索类型 | 核心定义与原理 | 关键参数/配置 | 典型应用场景 | 核心价值 |
|---|---|---|---|---|
| 基础向量检索 --近似最相邻ANN Search | 基于预构建索引,从海量数据中快速查找与查询向量最相似的 Top-K 结果,平衡检索速度与精度 | - anns_field:指定检索的向量字段- data:输入查询向量- limit/top_k:返回结果数量- search_params:含距离计算方式(metric_type)、索引参数 |
通用语义匹配场景,如: - 文本相似度检索(如“查找与‘AI伦理’语义相似的文章”) - 简单图像匹配(如“查找与目标图片风格相似的图像”) |
提供 Milvus 核心的向量相似性检索能力,是所有增强检索的基础,兼顾速度与精度 |
| 过滤检索 (Filtered Search) | 结合“向量相似性检索”与“标量字段过滤”,先按标量条件筛选实体子集,再在子集内执行 ANN 检索 | - 基础 ANN 参数(同上) - filter:标量过滤表达式(如“price < 500 AND stock > 0”) |
带条件约束的精准检索,如: - 电商:“相似红色连衣裙,价格低于500元且有库存” - 知识库:“AI相关文档,技术分类且2023年后发布” |
缩小检索范围,避免无关结果,大幅提升查询精准度,匹配实际业务中的多条件需求 |
| 范围检索 (Range Search) | 不限制返回数量,仅返回“与查询向量的距离/相似度落在指定阈值范围内”的所有实体 | - 基础 ANN 参数(同上) - 距离/相似度阈值( radius和range_filter) |
需限定相似度范围的场景,如: - 人脸识别:“相似度超0.9的身份匹配” - 异常检测:“与正常样本距离过大的异常数据筛选” |
满足“非Top-K”的范围化需求,适用于有明确相似度标准的验证、筛选场景 |
| 多向量混合检索 (Hybrid Search) | 同时检索多个向量字段(如文本密集向量、关键词稀疏向量、图像向量),并行ANN检索后通过重排策略(如 RRFRanker/WeightedRanker)融合结果 |
- 多向量字段配置(如文本向量+图像向量) - 重排策略(Reranker) - 各向量字段的检索参数 |
多模态/多维度精准匹配,如: - 多模态商品检索:“文本‘白色降噪耳机’+ 耳机图片向量联合检索” - 增强RAG:“密集语义向量+关键词稀疏向量融合检索文档” |
整合多维度向量信息,解决单一向量检索的局限性,提升结果全面性与准确性 |
| 分组检索 (Grouping Search) | 按指定标量字段(如 document_id/author)分组,确保每组仅返回1个(或指定数量)最相似实体,提升结果多样性 |
- 基础 ANN 参数(同上) - group_by_field:分组字段 ``group_size`:指定每个组要返回的实体数量。) |
需结果多样性的场景,如: - 视频检索:“‘可爱猫咪’视频,来自不同博主” - 文档检索:“‘数据库索引’文章,来自不同书籍” |
避免结果集中出现大量同源数据,提升检索结果的多样性与覆盖度,优化用户体验 |
milvus多模态实践
import os
from tqdm import tqdm
from glob import glob
import torch
from visual_bge.visual_bge.modeling import Visualized_BGE
from pymilvus import MilvusClient, FieldSchema, CollectionSchema, DataType
import numpy as np
import cv2
from PIL import Image
# 1. 初始化设置
MODEL_NAME = "BAAI/bge-base-en-v1.5"
MODEL_PATH = "../../models/bge/Visualized_base_en_v1.5.pth"
DATA_DIR = "../../data/C3"
COLLECTION_NAME = "multimodal_demo"
MILVUS_URI = "http://localhost:19530"
# 2. 定义工具 (编码器和可视化函数)
class Encoder:
"""编码器类,用于将图像和文本编码为向量。"""
def __init__(self, model_name: str, model_path: str):
self.model = Visualized_BGE(model_name_bge=model_name, model_weight=model_path)
self.model.eval()
def encode_query(self, image_path: str, text: str) -> list[float]:
with torch.no_grad():
query_emb = self.model.encode(image=image_path, text=text)
return query_emb.tolist()[0]
def encode_image(self, image_path: str) -> list[float]:
with torch.no_grad():
query_emb = self.model.encode(image=image_path)
return query_emb.tolist()[0]
def visualize_results(query_image_path: str, retrieved_images: list, img_height: int = 300, img_width: int = 300, row_count: int = 3) -> np.ndarray:
"""从检索到的图像列表创建一个全景图用于可视化。"""
panoramic_width = img_width * row_count
panoramic_height = img_height * row_count
panoramic_image = np.full((panoramic_height, panoramic_width, 3), 255, dtype=np.uint8)
query_display_area = np.full((panoramic_height, img_width, 3), 255, dtype=np.uint8)
# 处理查询图像
query_pil = Image.open(query_image_path).convert("RGB")
query_cv = np.array(query_pil)[:, :, ::-1]
resized_query = cv2.resize(query_cv, (img_width, img_height))
bordered_query = cv2.copyMakeBorder(resized_query, 10, 10, 10, 10, cv2.BORDER_CONSTANT, value=(255, 0, 0))
query_display_area[img_height * (row_count - 1):, :] = cv2.resize(bordered_query, (img_width, img_height))
cv2.putText(query_display_area, "Query", (10, panoramic_height - 20), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
# 处理检索到的图像
for i, img_path in enumerate(retrieved_images):
row, col = i // row_count, i % row_count
start_row, start_col = row * img_height, col * img_width
retrieved_pil = Image.open(img_path).convert("RGB")
retrieved_cv = np.array(retrieved_pil)[:, :, ::-1]
resized_retrieved = cv2.resize(retrieved_cv, (img_width - 4, img_height - 4))
bordered_retrieved = cv2.copyMakeBorder(resized_retrieved, 2, 2, 2, 2, cv2.BORDER_CONSTANT, value=(0, 0, 0))
panoramic_image[start_row:start_row + img_height, start_col:start_col + img_width] = bordered_retrieved
# 添加索引号
cv2.putText(panoramic_image, str(i), (start_col + 10, start_row + 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
return np.hstack([query_display_area, panoramic_image])
# 3. 初始化客户端
print("--> 正在初始化编码器和Milvus客户端...")
encoder = Encoder(MODEL_NAME, MODEL_PATH)
milvus_client = MilvusClient(uri=MILVUS_URI)
# 4. 创建 Milvus Collection
print(f"\n--> 正在创建 Collection '{COLLECTION_NAME}'")
if milvus_client.has_collection(COLLECTION_NAME):
milvus_client.drop_collection(COLLECTION_NAME)
print(f"已删除已存在的 Collection: '{COLLECTION_NAME}'")
image_list = glob(os.path.join(DATA_DIR, "dragon", "*.png"))
if not image_list:
raise FileNotFoundError(f"在 {DATA_DIR}/dragon/ 中未找到任何 .png 图像。")
dim = len(encoder.encode_image(image_list[0]))
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=dim),
FieldSchema(name="image_path", dtype=DataType.VARCHAR, max_length=512),
]
# 创建集合 Schema
schema = CollectionSchema(fields, description="多模态图文检索")
print("Schema 结构:")
print(schema)
# 创建集合
milvus_client.create_collection(collection_name=COLLECTION_NAME, schema=schema)
print(f"成功创建 Collection: '{COLLECTION_NAME}'")
print("Collection 结构:")
print(milvus_client.describe_collection(collection_name=COLLECTION_NAME))
# 5. 准备并插入数据
print(f"\n--> 正在向 '{COLLECTION_NAME}' 插入数据")
data_to_insert = []
for image_path in tqdm(image_list, desc="生成图像嵌入"):
vector = encoder.encode_image(image_path)
data_to_insert.append({"vector": vector, "image_path": image_path})
if data_to_insert:
result = milvus_client.insert(collection_name=COLLECTION_NAME, data=data_to_insert)
print(f"成功插入 {result['insert_count']} 条数据。")
# 6. 创建索引
print(f"\n--> 正在为 '{COLLECTION_NAME}' 创建索引")
index_params = milvus_client.prepare_index_params()
index_params.add_index(
field_name="vector",
index_type="HNSW",
metric_type="COSINE",
params={"M": 16, "efConstruction": 256}
)
milvus_client.create_index(collection_name=COLLECTION_NAME, index_params=index_params)
print("成功为向量字段创建 HNSW 索引。")
print("索引详情:")
print(milvus_client.describe_index(collection_name=COLLECTION_NAME, index_name="vector"))
milvus_client.load_collection(collection_name=COLLECTION_NAME)
print("已加载 Collection 到内存中。")
# 7. 执行多模态检索
print(f"\n--> 正在 '{COLLECTION_NAME}' 中执行检索")
query_image_path = os.path.join(DATA_DIR, "dragon", "query.png")
query_text = "一条龙"
query_vector = encoder.encode_query(image_path=query_image_path, text=query_text)
search_results = milvus_client.search(
collection_name=COLLECTION_NAME,
data=[query_vector],
output_fields=["image_path"],
limit=5,
search_params={"metric_type": "COSINE", "params": {"ef": 128}}
)[0]
retrieved_images = []
print("检索结果:")
for i, hit in enumerate(search_results):
print(f" Top {i+1}: ID={hit['id']}, 距离={hit['distance']:.4f}, 路径='{hit['entity']['image_path']}'")
retrieved_images.append(hit['entity']['image_path'])
# 8. 可视化与清理
print(f"\n--> 正在可视化结果并清理资源")
if not retrieved_images:
print("没有检索到任何图像。")
else:
panoramic_image = visualize_results(query_image_path, retrieved_images)
combined_image_path = os.path.join(DATA_DIR, "search_result.png")
cv2.imwrite(combined_image_path, panoramic_image)
print(f"结果图像已保存到: {combined_image_path}")
Image.open(combined_image_path).show()
milvus_client.release_collection(collection_name=COLLECTION_NAME)
print(f"已从内存中释放 Collection: '{COLLECTION_NAME}'")
milvus_client.drop_collection(COLLECTION_NAME)
print(f"已删除 Collection: '{COLLECTION_NAME}'")
参考:

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)