【收藏必备】LangChain+Embedding实战:从零构建本地知识问答系统,小白程序员必学指南
LangChain作为热门RAG框架,通过Embedding技术实现高效检索。文章详解Embedding技术原理、主流模型比较及LangChain集成方法,提供本地知识问答系统完整实现案例,包括文档处理、向量存储和检索优化技巧。通过合理选择Embedding模型和优化RAG流程,开发者可构建高效智能问答系统,最大化非结构化数据价值。
目录
- LangChain简介
- Embeddings技术概述
- 主流Embedding模型比较
- LangChain中的Embedding集成
- 实践案例:构建本地知识问答系统
- 总结与展望
LangChain简介
LangChain作为当前最热门的开源RAG(Retrieval-Augmented Generation,检索增强生成)框架,正在重塑我们处理非结构化数据的方式。在RAG框架中,检索环节至关重要,而Embeddings技术则是实现高效检索的核心组件之一。

RAG框架的工作流程通常包括:
- 文本预处理与分块
- 通过Embedding模型转换为向量表示
- 存储到向量数据库
- 查询时进行相似性检索
- 将检索结果输入生成模型
LangChain的独特价值在于它提供了标准化的接口,使开发者能够灵活组合不同的嵌入模型、向量数据库和LLM,构建端到端的智能应用。
Embeddings技术概述
Embedding技术通过将离散的符号(如单词、句子)映射到连续的向量空间,使计算机能够理解和处理语义信息。这种表示方法具有几个关键优势:
-
语义保留
:语义相似的项在向量空间中距离相近
-
维度压缩
:将高维稀疏表示转换为低维稠密向量
-
跨模态能力
:同一空间可嵌入文本、图像、音频等多种数据类型
现代Embedding模型通常基于深度神经网络,特别是Transformer架构,能够捕捉复杂的上下文关系。
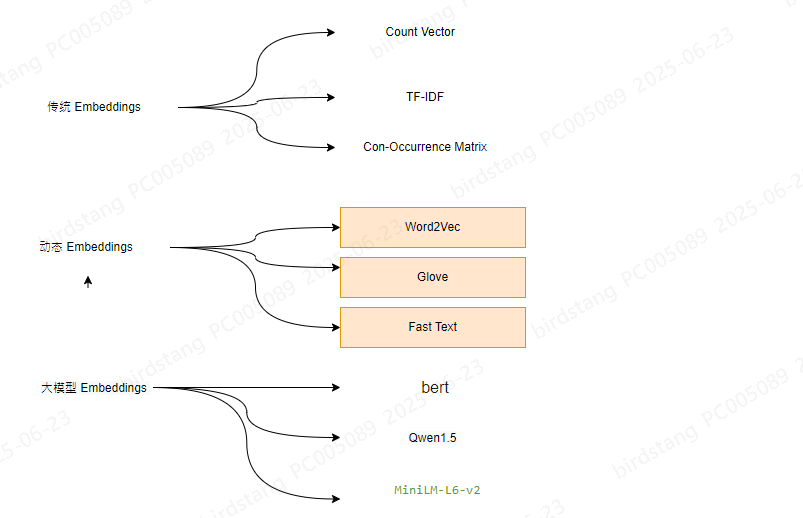
主流Embedding模型比较
| 模型名称 | 发布时间 | 核心特点 | 典型应用场景 |
|---|---|---|---|
| Word2Vec | 2013 | 基于浅层神经网络,CBOW/Skip-Gram架构 | 词语相似度计算,简单语义分析 |
| GloVe | 2014 | 基于全局词共现统计,结合矩阵分解 | 需要全局语义信息的任务 |
| FastText | 2016 | 引入子词(subword)概念,处理未登录词 | 多语言应用,拼写错误容忍 |
| BERT | 2018 | 双向Transformer,上下文相关表示 | 需要深层语义理解的任务 |
| Sentence-BERT | 2019 | 针对句子级语义优化的BERT变体 | 语义检索,文本匹配 |
LangChain中的Embedding集成
LangChain提供了统一的Embedding接口,支持多种后端实现:
from langchain_community.embeddings import(
HuggingFaceEmbeddings,
OpenAIEmbeddings,
CohereEmbeddings
)
# HuggingFace嵌入
hf_embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={'device':'cpu'},
encode_kwargs={'normalize_embeddings':False}
)
# OpenAI嵌入
openai_embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
# Cohere嵌入
cohere_embeddings = CohereEmbeddings(model="embed-english-v2.0")
-
model_name:指定预训练模型
-
model_kwargs:模型推理参数(如设备选择)
-
encode_kwargs:编码过程参数(如归一化)
实践案例:构建本地知识问答系统
系统架构
-
数据层
:本地文本文件存储知识库
-
嵌入层
:Sentence-Transformers处理文本
-
存储层
:Chroma向量数据库
-
应用层
:LangChain编排处理流程
# -*- coding: utf-8 -*-
"""
LangChain RAG完整实现
基于本地文档构建问答系统
使用sentence-transformers/all-MiniLM-L6-v2嵌入模型
Chroma向量数据库存储
"""
import os
from dotenv import load_dotenv
from typing import List, Dict, Any
# 加载环境变量
load_dotenv()
# 设置国内镜像源(加速下载)
os.environ['HF_ENDPOINT']='https://hf-mirror.com'
# 1. 导入所需库
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_community.chat_models import ChatOpenAI
from langchain.schema import Document
import chromadb
classRAGSystem:
def__init__(self, config: Dict[str, Any]):
"""
初始化RAG系统
参数:
config: 配置字典,包含:
- document_path: 文档路径
- embedding_model: 嵌入模型名称
- persist_directory: 向量数据库存储路径
- chunk_size: 文本分块大小
- chunk_overlap: 分块重叠大小
- llm_config: LLM配置
"""
self.config = config
self.llm = self._initialize_llm()
self.embeddings = self._initialize_embeddings()
self.vectorstore = self._initialize_vectorstore()
self.retriever = self.vectorstore.as_retriever(
search_type="mmr",
search_kwargs={"k":3,"lambda_mult":0.5}
)
self.chain = self._create_chain()
def_initialize_llm(self)-> ChatOpenAI:
"""初始化语言模型"""
return ChatOpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_API_BASE"),
model=self.config.get("llm_config",{}).get("model","gpt-3.5-turbo"),
temperature=0.7,
streaming=True
)
def_initialize_embeddings(self)-> HuggingFaceEmbeddings:
"""初始化嵌入模型"""
return HuggingFaceEmbeddings(
model_name=self.config.get("embedding_model","sentence-transformers/all-MiniLM-L6-v2"),
model_kwargs={'device':'cpu'},
encode_kwargs={'normalize_embeddings':False}
)
def_initialize_vectorstore(self)-> Chroma:
"""初始化向量数据库"""
# 加载文档
loader = TextLoader(self.config["document_path"], encoding="utf-8")
documents = loader.load()
# 文本分块
text_splitter = CharacterTextSplitter(
chunk_size=self.config.get("chunk_size",1000),
chunk_overlap=self.config.get("chunk_overlap",200)
)
chunks = text_splitter.split_documents(documents)
# 创建向量存储
return Chroma.from_documents(
documents=chunks,
embedding=self.embeddings,
persist_directory=self.config["persist_directory"],
collection_name="knowledge_base"
)
def_create_chain(self):
"""创建处理链"""
# 定义提示模板
template ="""你是一个专业的知识助手,请基于以下上下文回答问题。
如果不知道答案,就说你不知道,不要编造答案。
上下文:
{context}
问题: {question}
回答:"""
prompt = ChatPromptTemplate.from_template(template)
# 格式化检索结果
defformat_docs(docs: List[Document])->str:
return"\n\n".join(doc.page_content for doc in docs)
# 构建处理链
return(
{"context": self.retriever | format_docs,"question": RunnablePassthrough()}
| prompt
| self.llm
| StrOutputParser()
)
defquery(self, question:str)->str:
"""执行查询"""
return self.chain.invoke(question)
defsave_vectorstore(self):
"""保存向量数据库"""
self.vectorstore.persist()
if __name__ =="__main__":
# 配置参数
config ={
"document_path":"knowledge.txt",# 替换为你的文档路径
"embedding_model":"sentence-transformers/all-MiniLM-L6-v2",
"persist_directory":"db",# 向量数据库存储目录
"chunk_size":1000,
"chunk_overlap":200,
"llm_config":{
"model":"gpt-3.5-turbo"
}
}
# 初始化系统
rag = RAGSystem(config)
# 交互式问答
print("知识问答系统已启动,输入'exit'退出")
whileTrue:
try:
question =input("\n提问: ")
if question.lower()in["exit","quit"]:
rag.save_vectorstore()
print("系统已退出,向量数据库已保存")
break
print("\n思考中...", end="")
response = rag.query(question)
print(f"\n回答: {response}")
except KeyboardInterrupt:
rag.save_vectorstore()
print("\n系统已退出,向量数据库已保存")
break
except Exception as e:
print(f"\n发生错误: {str(e)}")
continue

核心代码实现
# 初始化组件
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
# 文档处理
text_splitter = CharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
documents = text_splitter.split_documents(
TextLoader("knowledge.txt").load()
)
# 向量存储
vectorstore = Chroma.from_documents(
documents=documents,
embedding=embeddings,
persist_directory="db"
)
# 检索增强生成链
retriever = vectorstore.as_retriever()
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(),
chain_type="stuff",
retriever=retriever
)
性能优化技巧
-
分块策略:
- 技术文档:500-1000字符,重叠200字符
- 对话记录:按对话轮次分块
- 代码文件:按函数/类分块
-
检索优化:
retriever = vectorstore.as_retriever( search_type="mmr",# 最大边际相关性 search_kwargs={"k":5,"lambda_mult":0.5} ) -
缓存机制:
from langchain.cache import SQLiteCache import langchain langchain.llm_cache = SQLiteCache(database_path=".langchain.db")
总结与展望
LangChain与Embeddings技术的结合为构建智能应用提供了强大基础。未来发展趋势包括:
-
多模态Embedding
:统一处理文本、图像、视频等数据
-
动态Embedding
:根据任务自适应调整向量表示
-
量化压缩
:减小模型大小同时保持性能
-
领域自适应
:针对垂直领域微调Embedding模型
通过合理选择Embedding模型和优化RAG流程,开发者可以构建出高效、准确的智能问答系统,将非结构化数据的价值最大化。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 27
27 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)