RAG的10个优化技巧
这篇视频讲解了RAG(检索增强生成)系统的10种优化技巧:1. Small-to-Big检索:先检索小文档块,返回大文档块作为上下文;2. 摘要检索:用摘要定位,用原文回答;3. 子问题检索:分解复杂问题为子问题并行检索;4. 句子窗口检索:精准定位中心句并返回上下文窗口;5. 多路召回:结合多种检索策略提高召回率;6. 重排序:对召回结果精细排序;7. 生成优化:改进生成质量;8. Refine
大佬的视频讲解在下面,对其中提到的10中优化技巧进行整理。
检索优化
small to big
-
“Small”(小):在检索阶段,使用较小的、细粒度的文档块(例如一个段落、几个句子)进行向量相似度计算。
-
“Big”(大):在提供给LLM的阶段,则返回这些小文档块所属的、更大的父文档块作为上下文。
摘要检索
用摘要来寻找,用原文来回答。
在检索阶段,并不直接拿用户的查询去匹配庞大的原始文档,而是去匹配预先为这些文档生成好的、高度浓缩的摘要。一旦找到相关的摘要,再定位到该摘要所对应的完整原始文档,并将这些原始文档作为上下文提供给大语言模型(LLM)来生成最终答案。
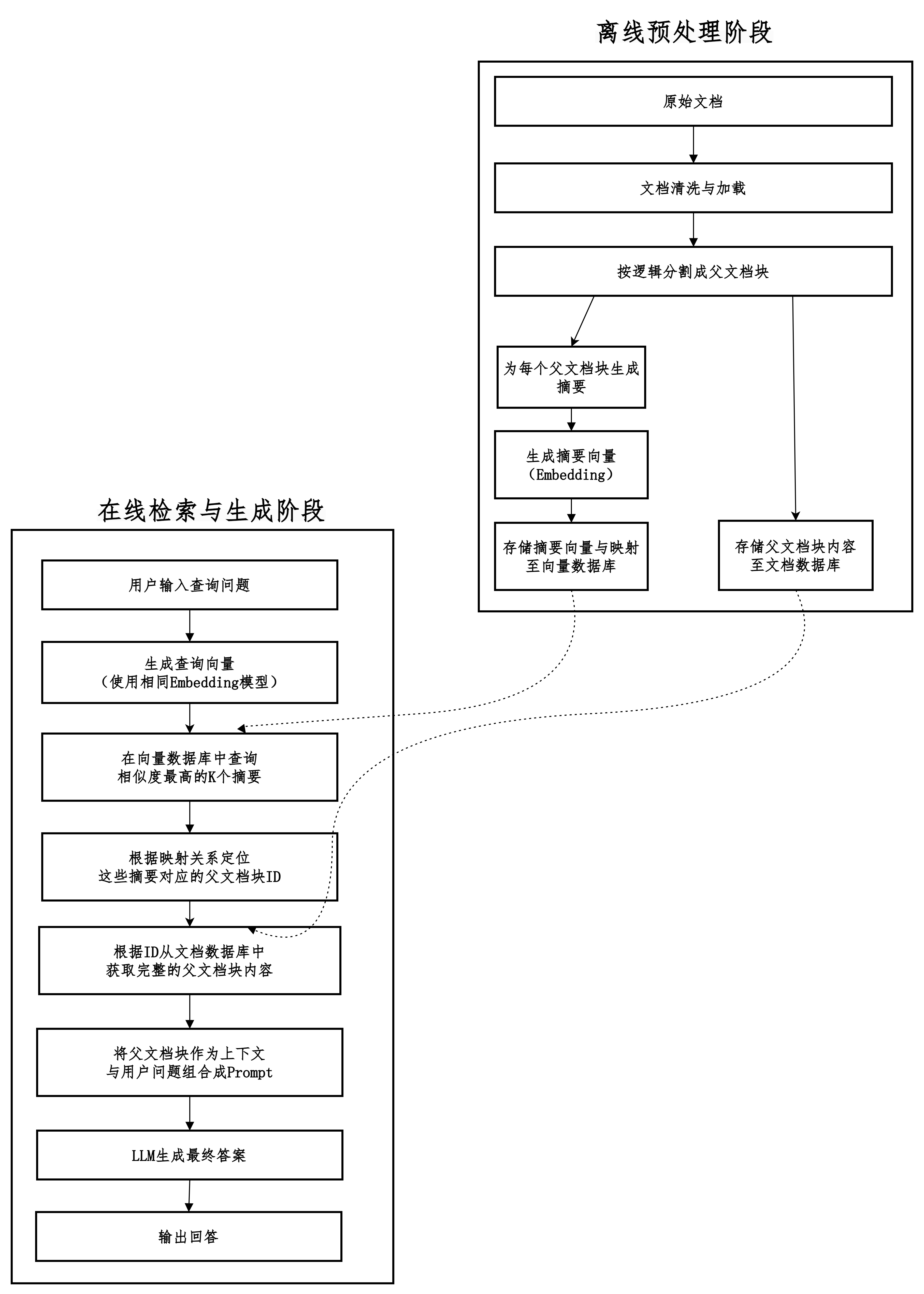
摘要如何生成?
| 特性 | 生成式摘要 (Generative) | 抽取式摘要 (Extractive) |
|---|---|---|
| 原理 | 理解并重新表述:像“实习生”一样阅读原文后,用自己的话写出核心观点。 | 选择并拼接:像“荧光笔”一样选出原文中最重要的句子(如TOP3)组合起来。 |
| 优点 | 简洁流畅:摘要更短、可读性更强、更像人写的。 重点突出:能更好地捕捉核心主旨,进行概括和整合。 |
忠实原文:不会引入事实性错误或“幻觉”。 |
| 缺点 | 可能产生幻觉:可能生成原文中不存在的信息或曲解原意。 计算成本高:需要更强大的模型。 |
连贯性差:拼凑的句子可能生硬、不连贯。 可能冗长:不会进行概括,摘要可能不够精炼。 |
| 适用性 | 非常适合RAG:目标是创建高度浓缩的语义表示,用于检索。 | 不太适合RAG:检索精度和语义密度通常不如生成式摘要。 |
使用大语言模型(LLM) + 提示词(Prompt)生成符合要求的摘要。
prompt_template = """
你是一个专业的文档分析助手。请为以下文本生成一个简洁且信息丰富的摘要,需捕捉所有核心观点和关键事实。
【要求】
1. 摘要长度严格控制在100字以内。
2. 只基于提供的文本内容生成,不要添加任何外部知识或你自己知道的信息。
3. 确保摘要客观、准确,完全忠实于原文。
4. 使摘要本身具有自明性,无需依赖上下文即可理解。
5. 避免使用“本文介绍了”、“作者认为”等元语句,直接陈述事实。
【待摘要的文本】
{text} # 此处插入要摘要的父文档块内容
"""生成摘要的要求需要满足以下的几个方面。
-
一致性:确保所有摘要的风格、长度和详细程度保持一致,这样才能保证检索的公平性和效果。
-
元数据集成:可以在摘要中保留关键元数据(如日期、人名、核心数据),这对后续的元数据过滤也有帮助。
-
成本与效率:如果知识库文档非常多(数万或数十万),使用GPT-4等API生成摘要的成本可能很高。需要权衡效果与成本,可以考虑使用高效的开源模型。
-
迭代优化:初期可以手动检查一批生成的摘要,评估其质量并根据问题调整Prompt(例如,如果发现幻觉,就在Prompt中加强“忠于原文”的指令)。
子问题检索
先拆解,分头找,再汇总。
当系统接收到一个复杂的用户问题时,并不直接用它去检索文档,而是先让一个大语言模型(LLM)将这个复杂问题分解成一系列逻辑相关的、更简单的子问题。然后,系统并行地为每一个子问题独立地进行检索,获取相关的文档片段。最后,将所有子问题检索到的信息综合起来,交给LLM生成一个全面、准确的最终答案。
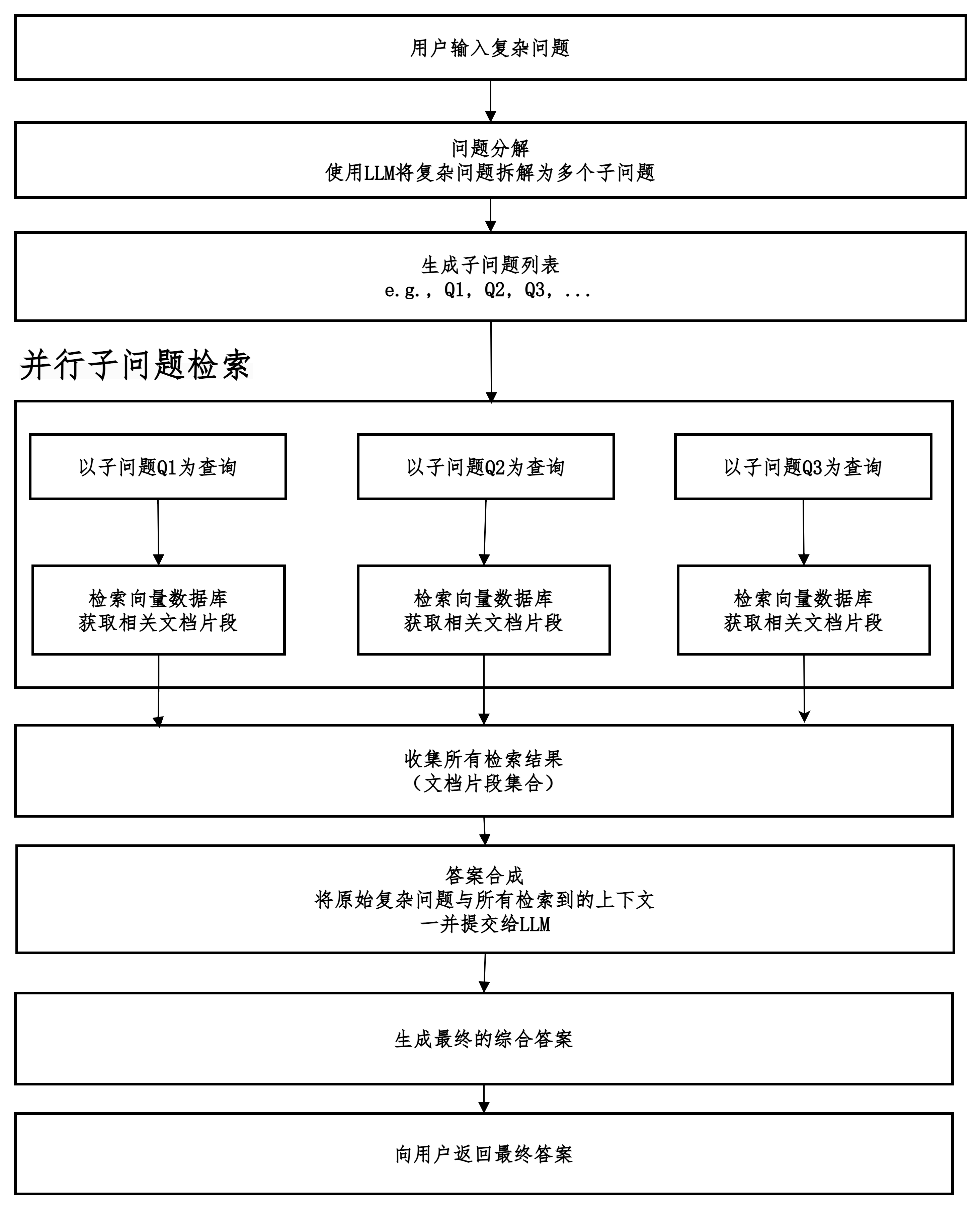
子问题如何进行分解?
基于提示工程(Prompt Engineering)
-
角色设定(Role Playing):让LLM扮演一个善于分解复杂问题的专家,如“研究员”、“分析师”或“侦探”。
-
核心指令(Core Instruction):明确告诉模型它的任务是将一个复杂问题分解成一系列更简单、更容易回答的子问题。
-
约束条件(Constraints):规定子问题需要满足的质量要求,例如:
-
自包含性:每个子问题应该独立且完整,不需要依赖其他子问题的答案就能被理解。
-
具体性:问题应该具体、聚焦,避免模糊和宽泛。
-
相关性:所有子问题都必须与原始问题高度相关,是为了最终回答原问题而服务的。
-
逻辑顺序:子问题之间最好有逻辑上的先后顺序或依赖关系。
-
-
输出格式(Output Format):指定模型输出的格式,例如要求以数字列表的形式返回子问题,方便后续程序自动化处理。
-
示例(Few-Shot Examples)(可选但强烈推荐):提供一两个“输入-输出”示例,让模型更清楚地理解我们的期望。
你是一个善于研究和分析的专业助手。你的任务是将用户提出的复杂问题分解成一系列更简单、更具体的子问题,这些子问题的答案组合起来将能够完整地回答原始问题。
请遵循以下要求:
- 子问题必须简单、明确,可以直接用于事实检索。
- 子问题必须是自包含的,不需要额外的上下文就能被理解。
- 子问题应该与原始问题高度相关,并且有逻辑顺序。
- 以数字列表的形式输出子问题。
示例:
原始问题: "苹果公司和微软公司的主要竞争领域是什么,它们各自的策略有何不同?"
子问题:
1. 苹果公司的主要产品和市场有哪些?
2. 微软公司的主要产品和市场有哪些?
3. 苹果公司和微软公司在哪些领域存在直接竞争?
4. 苹果公司在竞争中的核心策略是什么?
5. 微软公司在竞争中的核心策略是什么?
现在,请分解以下问题:
问题: “比较法国和德国在二战后的经济发展模式,并分析其对欧盟政策的影响。”
子问题:| 要素 | 说明 | 示例 |
|---|---|---|
| 理解指令 | LLM需要明白它的角色和任务是分解,而不是直接回答。 | 扮演“分析师”,任务是将大问题拆小。 |
| 逻辑推理 | LLM需要识别问题中的比较、因果、时序、列举等逻辑关系。 | 识别出“比较”意味着需要为每个对象生成子问题。 |
| 领域知识 | LLM利用内置的知识来让子问题更具体和准确。 | 知道德国的模式叫“社会市场经济”,从而生成更精确的查询。 |
| 提示工程 | 人类的提示词设计是成功的关键,它通过示例和约束条件“编程”LLM。 | 提供输出格式和质量要求,确保结果可用于后续自动化检索。 |
句子窗口检索
先检索最相关的单个句子,然后自动地将这个句子的原始上下文(即它前后相邻的句子)“窗口”一并找回,最终将这个完整的“窗口”提供给LLM。
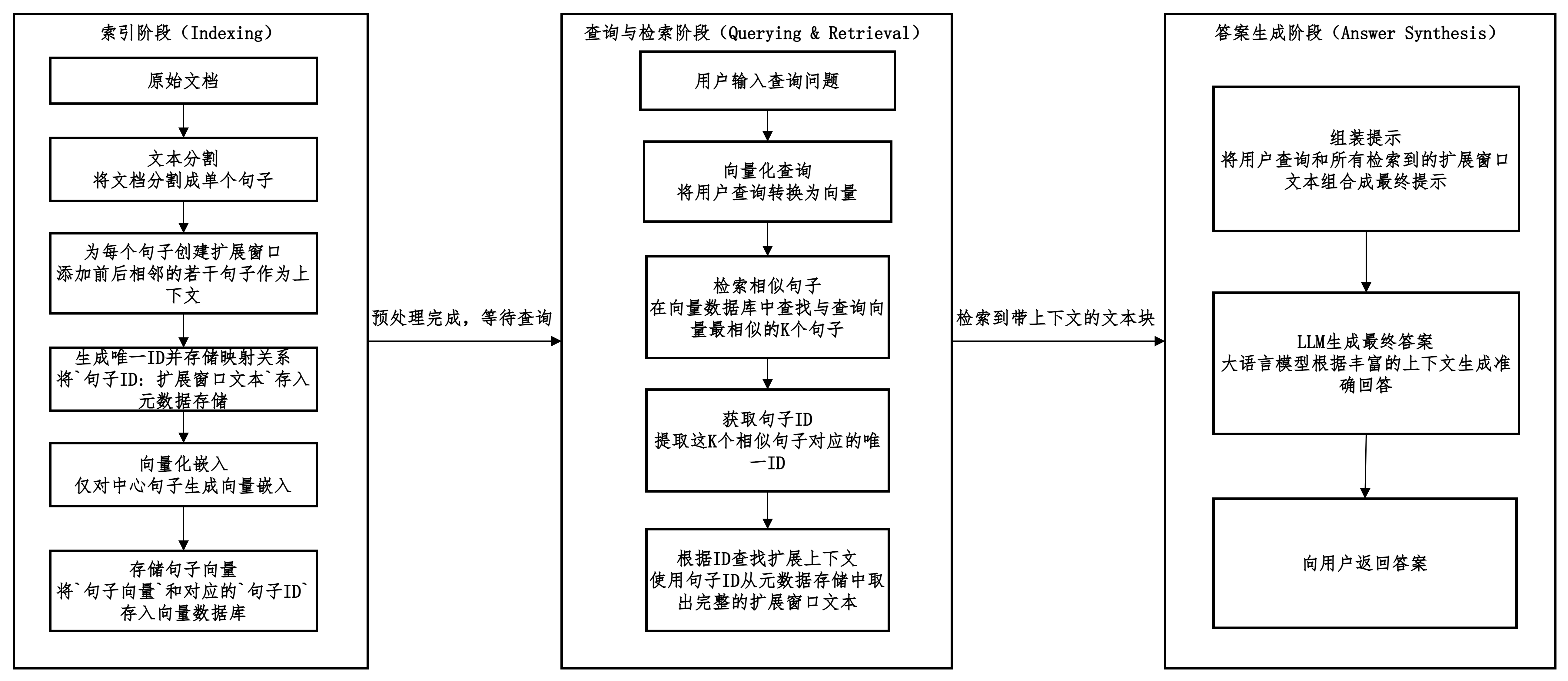
句子窗口检索的优缺点对比。
| 优点 | 缺点 |
|---|---|
| 1. 上下文更连贯:确保关键信息不被割裂,提供LLM所需的完整背景。 | 1. 索引更复杂:需要维护两个数据库(向量库 + 键值存储)及其之间的映射关系。 |
| 2. 检索精度更高:检索小颗粒度的句子,相似性匹配更精准,噪声更少。 | 2. 窗口大小需调试:“窗口”应该取前后多少句需要根据数据集进行实验和调试。 |
| 3. 答案质量提升:LLM基于高质量上下文生成的答案显著更准确、可靠。 | 3. 不适合所有文档:对于上下文关联性不强的文档(如电话簿),优势不明显。 |
三种检索优化之间的比较如表中所示。
| 特性 | 摘要检索 (Summary Retrieval) | 子问题检索 (Sub-Question Retrieval) | 句子窗口检索 (Sentence Window Retrieval) |
|---|---|---|---|
| 核心思想 | 用摘要的“小”实现高效主题检索,用原文的“大”保证答案细节。 | “分而治之”:将复杂问题分解为子问题,并行检索后再综合答案。 | “精准定位”:用单一句子“小”实现极致精度,用周围窗口“大”提供最小必要上下文。 |
| 主要流程 | 1. 为父文档块生成摘要。 2. 对摘要做向量化并索引。 3. 检索到相关摘要。 4. 返回摘要对应的完整父文档给LLM。 |
1. LLM分解复杂主问题为多个子问题。 2. 并行检索:对每个子问题执行独立检索(可搭配其他策略)。 3. 综合生成:将所有子问题的检索结果合并,交给LLM生成最终答案。 |
1. 将文本分割成单一句子。 2. 为每个句子构建上下文窗口。 3. 对中心句做向量化并索引。 4. 检索到相关中心句。 5. 返回中心句对应的完整窗口给LLM。 |
| 优点 | 1. 主题检索效率高,避免长文档噪音。 2. 最终上下文完整丰富,保证生成质量。 3. 检索索引更小,速度快。 |
1. 系统性强,能全面覆盖复杂问题的所有方面。 2. 答案质量极高,LLM拥有回答每个子问题的充足材料。 3. 子问题检索可并行化,效率高。 |
1. 检索精度最高,能命中“答案点”。 2. 提供的上下文最小且充分,无冗余信息。 3. 完美解决指代歧义(如“它”、“这个”等)。 |
| 缺点 | 1. 依赖摘要质量,劣质摘要会导致检索偏差。 2. 可能丢失细节:若摘要未包含关键细节,即使原文有,也无法被检索到。 3. 预处理成本高:为所有文档生成高质量摘要开销大。 |
1. 延迟和成本最高:需要进行多次LLM调用(分解+多次检索+生成)和多次检索。 2. 实现复杂度高:需要管理多轮检索和结果的合并。 3. 过度分解可能使问题变得琐碎。 |
1. 预处理复杂:需要精密的分句和构建窗口映射。 2. 窗口大小难定义:窗口太小可能上下文不足,太大则引入噪声。 3. 对短文档或结构性差的文本效果提升有限。 |
| 适用场景 | - 处理长文档(报告、论文、书籍)。 - 希望进行主题和核心观点检索,而非碎片化事实检索。 |
- 回答复杂、复合型的用户问题。 - 问题涉及多个方面、需要对比或总结。 - 对答案质量要求极高,不计较延迟和成本。 |
- 处理事实性、细节性强的问答。 - 答案高度集中在关键句上。 - 需要消除指代歧义,理解句子的隐含上下文。 |
多路召回
不要把所有的鸡蛋放在一个篮子里。
采用多种不同的策略、方法或渠道(即“多路”)分别进行信息检索,然后将各路的结果进行合并、去重和排序,最终筛选出最相关的结果集合。

如何进行评分?
| 关键词检索 (如BM25) | BM25分数 | 基于统计学的算法,根据查询词在文档中的词频(TF)和逆文档频率(IDF) 计算得分。分数越高,表示关键词匹配度越好。 |
| 向量检索 | 余弦相似度 / 点积 / L2距离 | 将查询和文档转换为向量后,计算它们在高维空间中的距离或相似度。最常用的是余弦相似度,值越接近1,语义越相似。 |
| 元数据过滤 | 二进制匹配 | 通常没有连续分数,只有“匹配”或“不匹配”。有时可以赋予权重(如新发布的文档权重更高)。 |
因为是采用不同的算法和尺度得到的分数,所以无法直接进行比较,故而需要重排序后进行评分。
交叉编码器 (Cross-Encoder)
- 工作原理:将查询和整个文档一起输入到一个Transformer模型中。模型会同时处理两者,通过深层的注意力机制(Attention)分析查询和文档中每一个词之间的关系,然后直接输出一个相关性分数(通常是一个0-1之间的值)。
- 优点:精度极高。因为模型能看到完整的查询和文档信息,能进行非常精细的语义匹配和推理。
- 缺点:计算成本高。因为每个(查询,文档)对都需要单独通过模型计算一次,不能预先计算。当候选文档很多时,速度较慢。
列表式排序 (Listwise Learning to Rank)
- 工作原理:训练一个机器学习模型,输入是查询和一组文档的特征(如BM25分数、向量相似度分数、文档长度、点击率等),模型学习如何综合这些特征,为这组文档输出一个最优的全局排序。
- 优点:可以考虑更多样的特征,理论上能做出更优的全局决策。
- 缺点:需要大量标注好的训练数据(<查询,相关文档,不相关文档>三元组),实现非常复杂。
加权融合 (Weighted Fusion)
- 工作原理:将不同召回器得到的分数归一化到同一个区间(如0-1),然后为每一路的分数赋予一个权重,最后计算每个文档的加权总分。
最终分数 = w1 * 归一化_BM25分数 + w2 * 归一化_向量相似度分数 + ...- 优点:实现简单,速度快。
- 缺点:权重需要人工凭经验调试,效果通常不如基于模型的重排序。
Rerank
初步检索到一批相关文档后,使用一个更精细、更强大的模型对这些文档进行重新评估和排序,以挑选出与问题真正最相关的少数几个文档的过程。
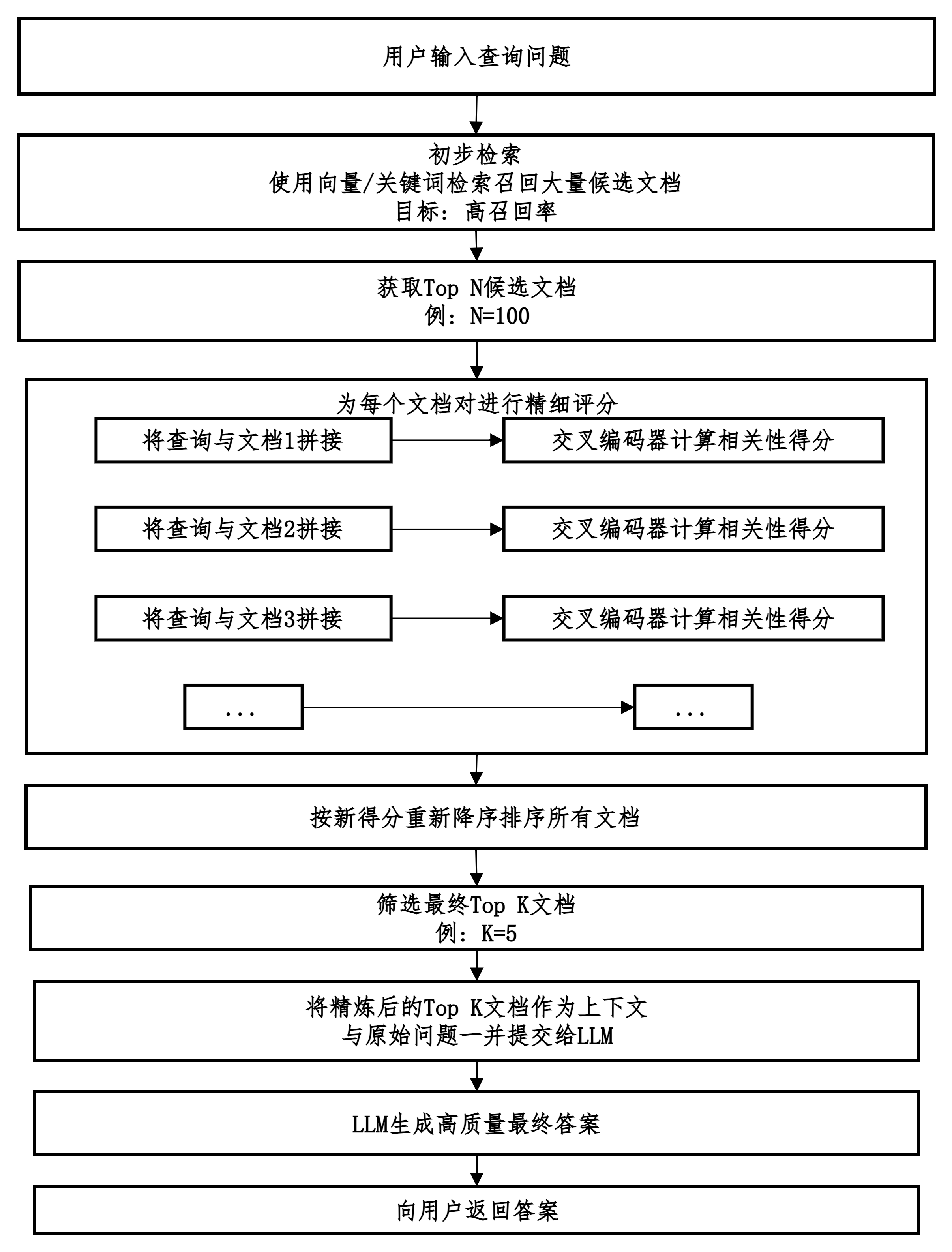
多路召回和重排序对比。
| 特性 | 多路召回 (Multi-Vector Recall) | 重排序 (Rerank) |
|---|---|---|
| 核心目标 | 提高召回率 (Recall) 千方百计找到所有可能相关的文档,宁可错抓,不可放过。 |
提高精确率 (Precision) 对召回的大量文档进行精细排序,将最相关的少数文档排在顶部。 |
| 阶段定位 | 检索阶段的前置和扩展步骤 是“检索”的一部分,负责产生候选集。 |
检索阶段的后处理步骤 是“检索”和“生成”之间的精筛网关。 |
| 工作原理 | 并行多种策略: 1. 语义检索(向量搜索) 2. 关键词检索(如BM25) 3. 元数据过滤等 然后合并结果。 |
深度计算相关性: 使用更复杂的模型(如Cross-Encoder)对查询和每个候选文档进行一对一深度交互计算,给出精细分数。 |
| 技术实现 | - 向量搜索引擎(Chroma, Pinecone) - 关键词搜索引擎(Elasticsearch) - 数据库过滤条件 |
- 专门的重排序模型(BGE-Reranker, Cohere Rerank) - Cross-Encoder 架构 |
| 输出结果 | 一个数量大、范围广但可能嘈杂的候选文档列表(例如100-200篇)。 | 一个数量小、排序精准的顶级文档列表(例如Top 3-5)。 |
| 性能开销 | 中等。并行检索多个策略,但每个策略本身相对高效。 | 较高。需要将查询与每个候选文档逐一进行深度计算,计算量大,延迟较高。 |
| 比喻 | “撒网” 或 “海选” 派出多支队伍(不同策略)广泛搜寻候选人。 |
“专家面试” 或 “总决赛” 让资深HR对海选出的候选人进行一对一深入面试,选出最适合的几位。 |
生成优化
refine模式
不一次性处理所有上下文,而是通过多次、迭代的方式,让LLM逐步地、不断地优化和精炼答案。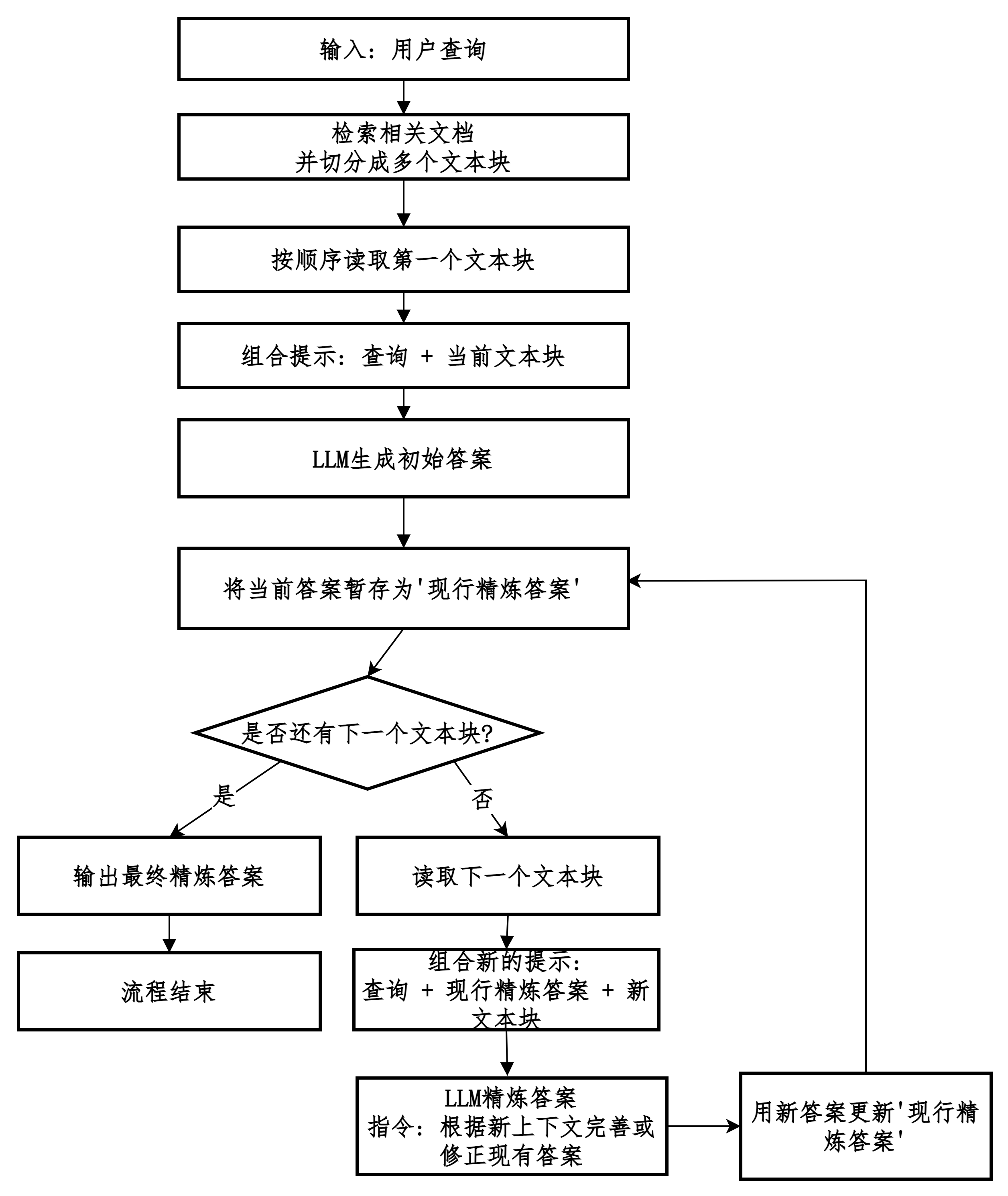
多文档场景的refine
不一次性处理所有文档,而是让LLM迭代地、一个接一个(或一小批接一小批)地处理文档,并不断地基于新看到的信息来优化、修正和扩展之前的答案。

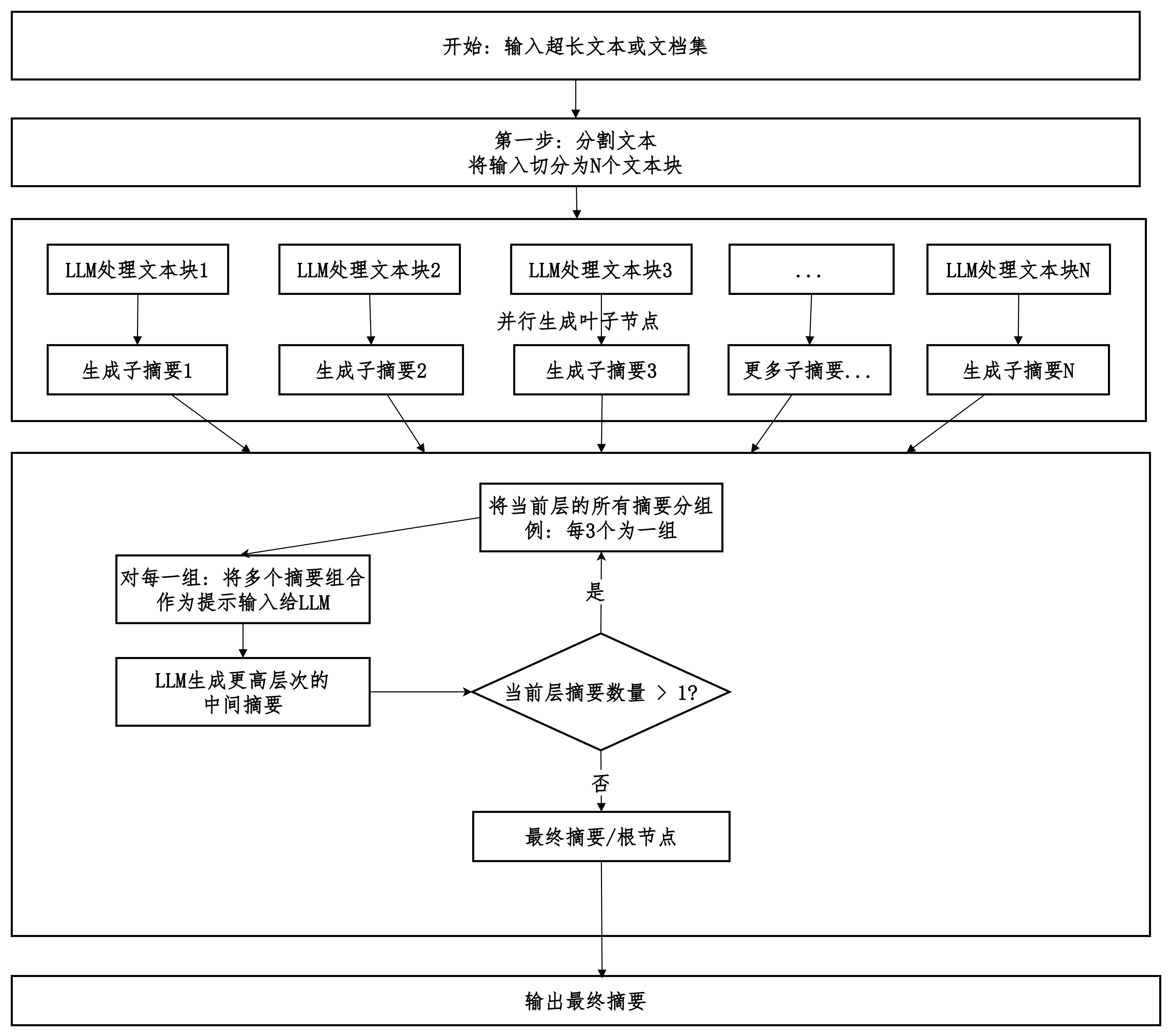
tree_summarize
分而治之。
-
通过并行处理文本块来显著提高速度、降低延迟。
-
通过分层递归汇总来突破上下文窗口限制,处理超长文档。
| 模式 | 优点 | 缺点 |
|---|---|---|
| Stuff | 快,成本低,保持连贯性。 | 受限于上下文窗口长度,无法处理长文档。 |
| Refine | 能处理极长文档,摘要质量高。 | 极慢(串行),极贵(调用次数多),可能错误累积。 |
| Tree Summarize | 较快(并行),能处理极长文档,成本低于Refine。 | 最终摘要可能丢失一些最底层的细节,结构更复杂。 |
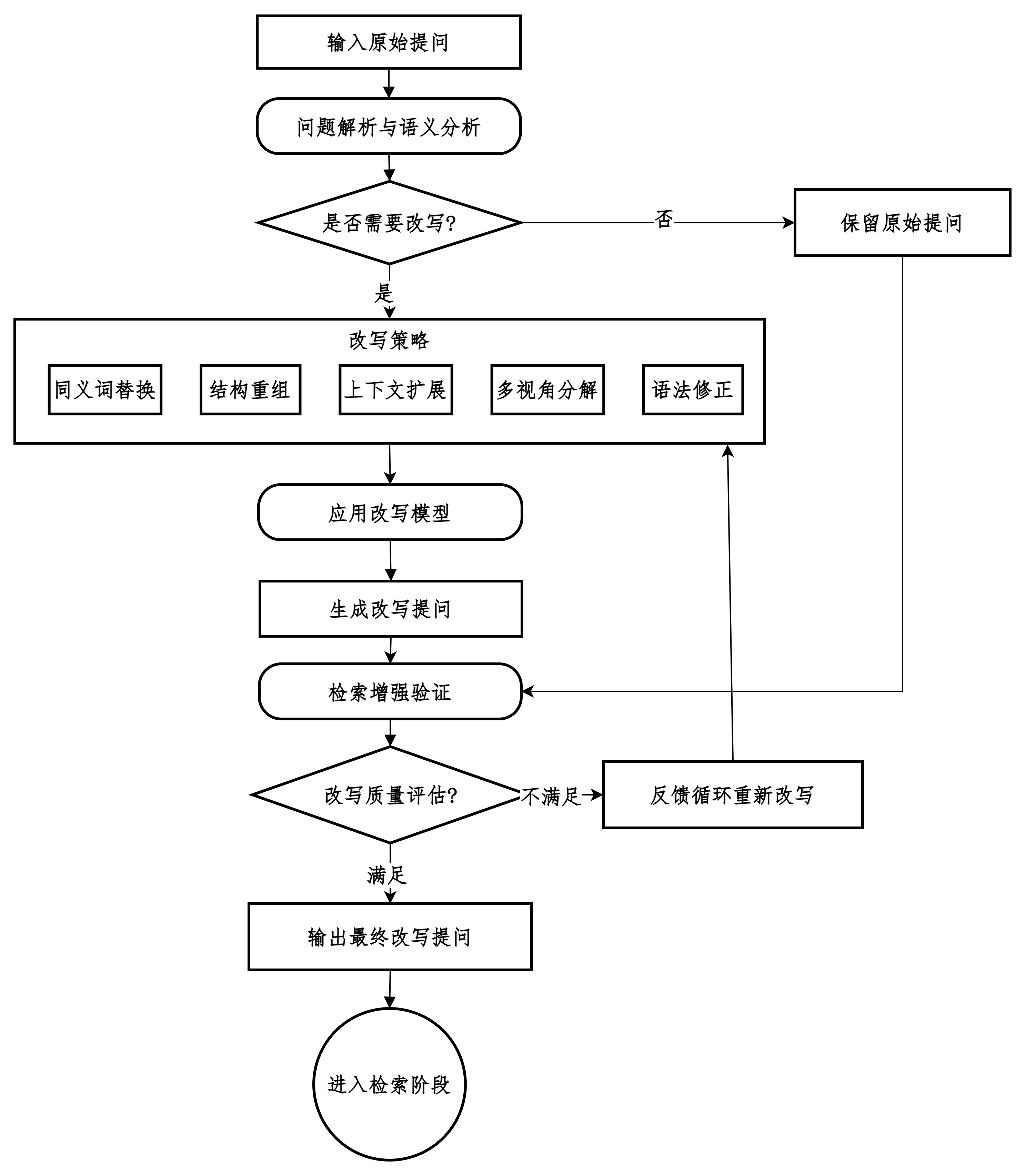
改写提问
在保持用户原始意图不变的前提下,对用户输入的问题或查询(Query)进行重新表述、扩展或优化,以提升后续检索或回答质量的技术。
合理利用元数据
元数据是描述数据的数据。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)