基于GraphRAG+Ollama验证知识图谱和检索增强融合
之前介绍了知识图谱与检索增强的融合探索GraphRAG这里尝试在CPU环境,基于GraphRAG+Ollama,验证GraphRAG构建知识图谱和查询过程。
之前介绍了知识图谱与检索增强的融合探索GraphRAG。
https://blog.csdn.net/liliang199/article/details/151189579
这里尝试在CPU环境,基于GraphRAG+Ollama,验证GraphRAG构建知识图谱和检索增强查询过程,测试输入数据整理自网络。
1 环境安装
1.1 GraphRAG安装
在本地cpu环境,基于linux conda安装python,pip安装graphrag,过程如下。
conda create -n graphrag python=3.10
conda activate graphrag
pip install graphrag==0.5.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
安装graphrag 0.5.0(之后版本可能和ollama有兼容问题)
1.2 Ollama LLM安装
假设ollama已安装,具体安装过程参考
https://blog.csdn.net/liliang199/article/details/149267372
这里ollama下载llm模型mistral和embedding模型nomic-embed-text
ollama pull nomic-embed-text
ollama pull mistral
默认ollama模型上下文长度为2048,不能有效支持GraphRAG,需要对上下文长度进行修改。
导出现有llm模型配置,配置文件为Modelfile
ollama show --modelfile mistral:latest > Modelfile
修改Modelfile,在PARAMETER区域添加如下配置,支持10k上下文,可依据具体情况设定。
PARAMETER num_ctx 10000
修改后示例如下
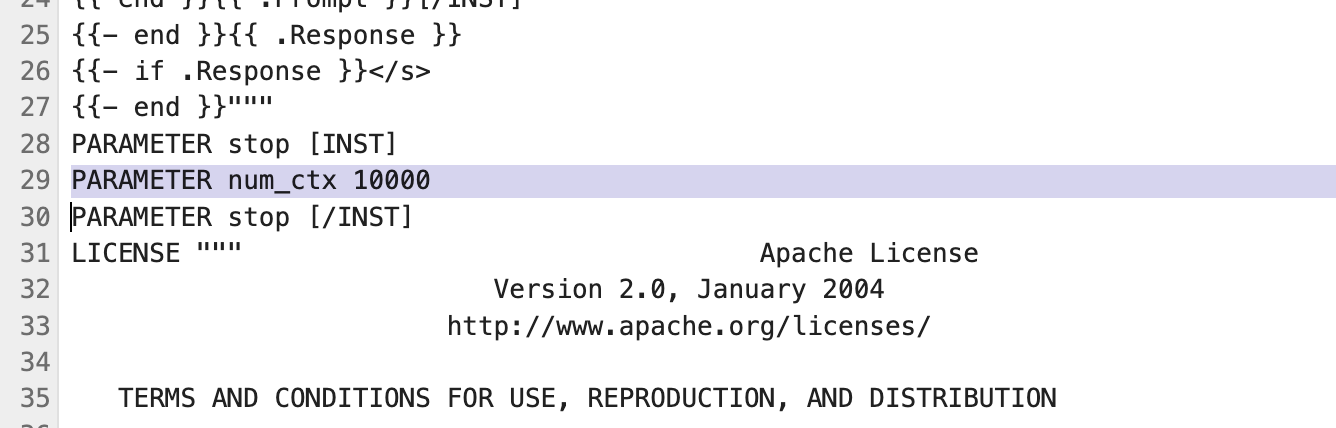
基于修改后的Modelfile,创建新的ollama模型,指令如下。
ollama create mistral:10k -f Modelfile
查看新创建模型
ollama list
2 图谱构建验证
2.1 测试数据准备
首先创建工作目录
mkdir ragtest/input -p
本地CPU处理能力有限,需要控制篇幅,这次使用如下示例输入,将示例文本保存到./ragtest/input下的Transformers_intro.txt,文件名随意。
Introduction to Transformer Neural Networks
Transformer neural networks represent a revolutionary architecture in the field of deep learning, particularly for natural language processing (NLP) tasks. Introduced in the seminal paper "Attention is All You Need" by Vaswani et al. in 2017, transformers have since become the backbone of numerous state-of-the-art models due to their ability to handle long-range dependencies and parallelize training processes. Unlike traditional recurrent neural networks (RNNs) and convolutional neural networks (CNNs), transformers rely entirely on a mechanism called self-attention to process input data. This mechanism allows transformers to weigh the importance of different words in a sentence or elements in a sequence simultaneously, thus capturing context more effectively and efficiently.
Architecture of Transformers
The core component of the transformer architecture is the self-attention mechanism, which enables the model to focus on different parts of the input sequence when producing an output. The transformer consists of an encoder and a decoder, each made up of a stack of identical layers. The encoder processes the input sequence and generates a set of attention-weighted vectors, while the decoder uses these vectors, along with the previously generated outputs, to produce the final sequence. Each layer in the encoder and decoder contains sub-layers, including multi-head self-attention mechanisms and position-wise fully connected feed-forward networks, followed by layer normalization and residual connections. This design allows the transformer to process entire sequences at once rather than step-by-step, making it highly parallelizable and efficient for training on large datasets.
Applications of Transformer Neural Networks
Transformers have revolutionized various applications across different domains. In NLP, they power models like BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformer), and T5 (Text-to-Text Transfer Transformer), which excel in tasks such as text classification, machine translation, question answering, and text generation. Beyond NLP, transformers have also shown remarkable performance in computer vision with models like Vision Transformer (ViT), which treats images as sequences of patches, similar to words in a sentence. Additionally, transformers are being explored in areas such as speech recognition, protein folding, and reinforcement learning, demonstrating their versatility and robustness in handling diverse types of data. The ability to process long-range dependencies and capture intricate patterns has made transformers indispensable in advancing the state of the art in many machine learning tasks.
Challenges and Limitations
Despite their success, transformer neural networks come with several challenges and limitations. One of the primary concerns is their computational and memory requirements, which are significantly higher compared to traditional models. The quadratic complexity of the self-attention mechanism with respect to the input sequence length can lead to inefficiencies, especially when dealing with very long sequences. To mitigate this, various approaches like sparse attention and efficient transformers have been proposed. Another challenge is the interpretability of transformers, as the attention mechanisms, though providing some insights, do not fully explain the model's decisions. Furthermore, transformers require large amounts of data and computational resources for training, which can be a barrier for smaller organizations or those with limited resources. Addressing these challenges is crucial for making transformers more accessible and scalable for a broader range of applications.
Future Directions
The future of transformer neural networks is bright, with ongoing research focused on enhancing their efficiency, scalability, and applicability. One promising direction is the development of more efficient transformer architectures that reduce computational complexity and memory usage, such as the Reformer, Linformer, and Longformer. These models aim to make transformers feasible for longer sequences and real-time applications. Another important area is improving the interpretability of transformers, with efforts to develop methods that provide clearer explanations of their decision-making processes. Additionally, integrating transformers with other neural network architectures, such as combining them with convolutional networks for multimodal tasks, holds significant potential. The application of transformers beyond traditional domains, like in time-series forecasting, healthcare, and finance, is also expected to grow. As advancements continue, transformers are set to remain at the forefront of AI and machine learning, driving innovation and breakthroughs across various fields.
此时,./ragtest包含测试数据,初始化指令如下。
graphrag init --root ./ragtest
生成参数配置文件ragtest/settings.yaml
2.2 环境变量设置
1)直接export设置环境变量
设置GRAPHRAG_API_KEY和GRAPHRAG_CLAIM_EXTRACTION_ENABLED
export GRAPHRAG_API_KEY=ollama
export GRAPHRAG_CLAIM_EXTRACTION_ENABLED=True
设置GRAPHRAG_CLAIM_EXTRACTION_ENABLED=True,否则无法生成协变量,Local Search出错。
2)修改ragtest/.env设置环境变量
或者直接修改ragtest/.env ,设置环境变量。
GRAPHRAG_API_KEY=ollama
GRAPHRAG_CLAIM_EXTRACTION_ENABLED=True
2.3 模型参数配置
模型参数配置文件ragtest/settings.yaml
修改llm model为mistral:10k,embedding model为nomic-embed-text
调用本地ollama llm服务,所以设置api_base: http://localhost:11434/v1
本地cpu部署,计算很慢,所以设置一个很长的request_timeout: 18000
没有GPU,过大concurrent_requests没效果,反而导致超时,设置concurrent_requests: 1
### This config file contains required core defaults that must be set, along with a handful of common optional settings.
### For a full list of available settings, see https://microsoft.github.io/graphrag/config/yaml/### LLM settings ###
## There are a number of settings to tune the threading and token limits for LLM calls - check the docs.encoding_model: cl100k_base # this needs to be matched to your model!
llm:
api_key: ${GRAPHRAG_API_KEY} # set this in the generated .env file
type: openai_chat # or azure_openai_chat
model: mistral:10kapi_base: http://localhost:11434/v1
request_timeout: 18000
concurrent_requests: 1
model_supports_json: true # recommended if this is available for your model.
# audience: "https://cognitiveservices.azure.com/.default"
# api_base: https://<instance>.openai.azure.com
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>parallelization:
stagger: 0.3
# num_threads: 50async_mode: threaded # or asyncio
embeddings:
async_mode: threaded # or asyncio
vector_store:
type: lancedb
db_uri: 'output/lancedb'
container_name: default
overwrite: true
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_embedding # or azure_openai_embedding
model: nomic-embed-text
api_base: http://localhost:11434/v1
request_timeout: 18000concurrent_requests: 1
# api_base: https://<instance>.openai.azure.com
# api_version: 2024-02-15-preview
# audience: "https://cognitiveservices.azure.com/.default"
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>### Input settings ###
input:
type: file # or blob
file_type: text # or csv
base_dir: "input"
file_encoding: utf-8
file_pattern: ".*\\.txt$"chunks:
size: 1200
overlap: 100
group_by_columns: [id]### Storage settings ###
## If blob storage is specified in the following four sections,
## connection_string and container_name must be providedcache:
type: file # or blob
base_dir: "cache"reporting:
type: file # or console, blob
base_dir: "logs"storage:
type: file # or blob
base_dir: "output"## only turn this on if running `graphrag index` with custom settings
## we normally use `graphrag update` with the defaults
update_index_storage:
# type: file # or blob
# base_dir: "update_output"### Workflow settings ###
skip_workflows: []
entity_extraction:
prompt: "prompts/entity_extraction.txt"
entity_types: [organization,person,geo,event]
max_gleanings: 1summarize_descriptions:
prompt: "prompts/summarize_descriptions.txt"
max_length: 500claim_extraction:
enabled: false
prompt: "prompts/claim_extraction.txt"
description: "Any claims or facts that could be relevant to information discovery."
max_gleanings: 1community_reports:
prompt: "prompts/community_report.txt"
max_length: 2000
max_input_length: 8000cluster_graph:
max_cluster_size: 10embed_graph:
enabled: false # if true, will generate node2vec embeddings for nodesumap:
enabled: false # if true, will generate UMAP embeddings for nodessnapshots:
graphml: false
raw_entities: false
top_level_nodes: false
embeddings: false
transient: false### Query settings ###
## The prompt locations are required here, but each search method has a number of optional knobs that can be tuned.
## See the config docs: https://microsoft.github.io/graphrag/config/yaml/#querylocal_search:
prompt: "prompts/local_search_system_prompt.txt"global_search:
map_prompt: "prompts/global_search_map_system_prompt.txt"
reduce_prompt: "prompts/global_search_reduce_system_prompt.txt"
knowledge_prompt: "prompts/global_search_knowledge_system_prompt.txt"drift_search:
prompt: "prompts/drift_search_system_prompt.txt"
2.4 数据索引构建
然后就是构建索引,这里需要设置--reporter "rich",不设置会报错。
nohup graphrag index --root ./ragtest --reporter "rich" > run.log &
如下所示,看到All workflows completed successfully时,就说明索引构建成功。
结果保存在./ragtest/output下,其中parquet可经过处理导入Neo4J,展示可视化图谱。
⠋ GraphRAG Indexer
├── Loading Input (text) - 2 files loaded (1 filtered) ━━━━━━━━━━━━ 100% 0:00:00 0:00:00
├── create_base_text_units
├── create_final_documents
├── create_base_entity_graph
├── create_final_entities
├── create_final_nodes
├── create_final_communities
├── create_final_relationships
├── create_final_text_units
├── create_final_community_reports
└── generate_text_embeddings🚀 All workflows completed successfully.
本地CPU运行ollama速度慢,建索引耗时12h,随意所以最好用GPU跑。
另外,如果不差钱,也可以借助于OneAPI调用外部LLM服务,OneAPI使用方法参考
https://blog.csdn.net/liliang199/article/details/151393128
3 图谱搜索验证
3.1 全局搜索
从全局角度提问,比如 "What is the main idea of this text?",全局搜索命令如下所示。
graphrag query --root ./ragtest --method global --query "What is the main idea of this text?"
输出如下所示
creating llm client with {'api_key': 'REDACTED,len=6', 'type': "openai_chat", 'model': 'mistral:10k', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 1.0, 'n': 1, 'request_timeout': 18000.0, 'api_base': 'http://localhost:11434/v1', 'api_version': None, 'organization': None, 'proxy': None, 'audience': None, 'deployment_name': None, 'model_supports_json': True, 'tokens_per_minute': 0, 'requests_per_minute': 0, 'max_retries': 10, 'max_retry_wait': 10.0, 'sleep_on_rate_limit_recommendation': True, 'concurrent_requests': 1}
SUCCESS: Global Search Response:
Transformer Neural Networks, a significant advancement in Natural Language Processing (NLP), computer vision, speech recognition, protein folding, and reinforcement learning, are under discussion due to their self-attention mechanism [Data: Reports (1, 3)]. However, they face challenges such as interpretability issues due to complex attention mechanisms and high resource requirements for training [Data: Reports (2, 7, 34, 46, 64, +more)].Transformer Neural Networks have been applied in various domains, including NLP, computer vision, speech recognition, protein folding, and reinforcement learning. They are a crucial development in the field of AI [Data: Reports (1, 3)].
The complexity of Transformer Neural Networks' attention mechanisms poses issues in fields where understanding the decision-making process is essential [Data: Reports (2, 7, 34, 46, 64, +more)]. This lack of transparency could potentially create problems.
Large amounts of data and computational resources are required for training Transformer Neural Networks, which may lead to an uneven distribution of AI advancements across different sectors and organizations [Data: Reports (2, 7, 34, 46, 64, +more)].
Efficient transformer architectures like Linformer and Longformer are proposed as potential solutions to address some of the resource requirements issues for Transformer Neural Networks. However, their effectiveness and applicability across various domains remain to be seen [Data: Reports (1, 3)].
同样本地CPU运行global query速度也很慢,全局搜索耗时4h左右。
3.2 局部搜索
从局部实体角度提问,比如"What is the relationship between transformers and traditional RNNs?",局部搜索命令如下。
graphrag query --root ./ragtest --method local --query "What is the relationship between transformers and traditional RNNs?"
输出如下
INFO: Vector Store Args: {
"type": "lancedb",
"db_uri": "/data/apps/llm/graphrag/ragtest/output/lancedb",
"container_name": "==== REDACTED ====",
"overwrite": true
}
creating llm client with {'api_key': 'REDACTED,len=6', 'type': "openai_chat", 'model': 'mistral:10k', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 1.0, 'n': 1, 'request_timeout': 18000.0, 'api_base': 'http://localhost:11434/v1', 'api_version': None, 'organization': None, 'proxy': None, 'audience': None, 'deployment_name': None, 'model_supports_json': True, 'tokens_per_minute': 0, 'requests_per_minute': 0, 'max_retries': 10, 'max_retry_wait': 10.0, 'sleep_on_rate_limit_recommendation': True, 'concurrent_requests': 1}
request_timeout: 18000.0
creating embedding llm client with {'api_key': 'REDACTED,len=6', 'type': "openai_embedding", 'model': 'nomic-embed-text', 'max_tokens': 4000, 'temperature': 0, 'top_p': 1, 'n': 1, 'request_timeout': 18000.0, 'api_base': 'http://localhost:11434/v1', 'api_version': None, 'organization': None, 'proxy': None, 'audience': None, 'deployment_name': None, 'model_supports_json': None, 'tokens_per_minute': 0, 'requests_per_minute': 0, 'max_retries': 10, 'max_retry_wait': 10.0, 'sleep_on_rate_limit_recommendation': True, 'concurrent_requests': 1}SUCCESS: Local Search Response:
Transformers and Recurrent Neural Networks (RNNs) are both deep learning architectures used for processing sequential data, but they differ significantly in their approach.Traditional RNNs process input sequences one element at a time, maintaining an internal hidden state that captures the context of the processed elements. This hidden state is then updated with each new input, allowing RNNs to model long-term dependencies between elements in the sequence [Data: Entities (0)]. However, this sequential processing makes RNNs less efficient for handling long sequences and parallelizing training processes compared to transformers.
Transformers, on the other hand, process entire sequences at once by using a mechanism called self-attention. This allows them to weigh the importance of different elements in the sequence simultaneously, thus capturing context more effectively and efficiently [Data: Entities (0)]. Transformers consist of an encoder and a decoder, each made up of a stack of identical layers containing sub-layers like multi-head self-attention mechanisms and position-wise fully connected feed-forward networks. This design makes transformers highly parallelizable and efficient for training on large datasets [Data: Entities (0)].
The introduction of transformers in the seminal paper "Attention is All You Need" by Vaswani et al. in 2017 marked a significant advancement in natural language processing tasks, as transformers have since become the backbone of numerous state-of-the-art models due to their ability to handle long-range dependencies and parallelize training processes [Data: Entities (0)].
In summary, while both RNNs and transformers are used for processing sequential data, transformers offer several advantages over traditional RNNs in terms of efficiency, scalability, and the ability to capture context effectively. This has made transformers indispensable in advancing the state of the art in many machine learning tasks, particularly in natural language processing.
[Data: Entities (0), Relationships (1)]
同样本地CPU运行local query速度也很慢,局部搜索耗时3h左右。
4 中文输入验证
4.1 中文输入示例
中文输入示例文本如下。
机器学习是通过数据学习模式和规律,从而使计算机能够在没有显式编程的情况下完成特定任务的一门技术。其核心思想是利用数据构建模型,使其能够对新数据进行预测或决策。机器学习根据不同的任务目标和学习方式可以分为监督学习、无监督学习、半监督学习、强化学习以及自监督学习等几个主要类别。监督学习是最常见的一种,它依赖于带标签的数据集,通过输入和输出的映射关系训练模型,典型任务包括回归问题和分类问题。回归问题的目标是预测连续数值,例如通过历史房价数据预测未来房价;而分类问题则用于预测离散类别,例如垃圾邮件检测。无监督学习则使用没有标签的数据集,其目标是挖掘数据的内在结构。无监督学习的主要方法有聚类和降维,其中聚类是将数据分组,例如在客户分析中对不同类型客户进行分群;降维则是通过降低数据维度的方式进行特征提取或数据可视化,如主成分分析(PCA)常用于这种场景。半监督学习结合了监督学习和无监督学习的优势,通过少量有标签的数据和大量无标签的数据来训练模型,适用于获取标签数据成本较高的情况。强化学习通过与环境的交互不断优化策略,其关键在于通过奖励和惩罚信号来学习最优的行为策略,常见的应用包括游戏AI和机器人控制。自监督学习是一种近年来备受关注的技术,利用数据本身生成伪标签,从而在无标签数据上进行预训练,广泛应用于自然语言处理和计算机视觉任务。
在具体方法上,机器学习包含从基础到先进的一系列技术。在线性回归中,模型通过拟合输入特征和目标变量之间的线性关系来进行预测,通常使用最小二乘法来优化参数。逻辑回归则是用于分类任务的一种技术,它通过Sigmoid函数将输入特征映射到概率空间,从而实现二分类问题的解决。支持向量机是一种既可以用于分类也可以用于回归的技术,通过寻找最优超平面将数据分类,并最大化不同类别之间的间隔,其核心是对数据点进行映射以使非线性问题变得线性可分。决策树方法通过递归地划分特征空间来构建树形结构,从而完成分类或回归任务;然而,由于决策树容易过拟合,因此随机森林通过组合多棵决策树进行集成,从而提高了模型的稳定性和准确性。梯度提升方法如XGBoost和LightGBM在建模时通过逐步修正残差来优化模型,成为许多比赛和生产环境中的首选算法。
神经网络是机器学习中的一类重要技术,特别是深度学习的兴起使其成为研究的热点。神经网络的基本单元是神经元,多个神经元通过层的形式组合成网络结构。卷积神经网络(CNN)专注于提取图像中的局部特征,适合图像分类、目标检测等任务;循环神经网络(RNN)则专注于处理时间序列数据,通过其隐状态捕获序列中的上下文关系,用于自然语言处理和语音识别。然而,传统的RNN存在梯度消失问题,因此改进的长短期记忆网络(LSTM)和门控循环单元(GRU)得以广泛应用。近年来,Transformer架构由于其并行计算能力和对长距离依赖建模的优势,取代了RNN在许多任务中的地位,成为自然语言处理和其他领域的主流技术,例如BERT和GPT模型的成功就基于这种架构。此外,图神经网络(GNN)是处理图结构数据的一种强大工具,它通过节点间的消息传递机制学习图中节点的特征表示,被应用于社交网络分析、推荐系统和生物信息学等领域。
机器学习方法的成功还依赖于优化算法和特征工程。优化算法是模型训练的关键,通过不断调整参数以最小化损失函数。例如,梯度下降法及其变种如Adam优化器在现代机器学习中被广泛使用。特征工程则包括特征选择和特征提取,前者通过统计方法或算法选择最具信息量的特征,后者通过方法如PCA或自动编码器将数据转换为更易于学习的形式。
机器学习在许多实际场景中发挥着重要作用。在自然语言处理领域,文本分类技术被用于垃圾邮件过滤和情感分析,机器翻译技术支撑了多语言交流,聊天机器人则改进了客户服务效率。在计算机视觉领域,图像分类和目标检测已经应用于人脸识别、自动驾驶和医疗影像分析等任务。推荐系统结合协同过滤和基于内容的推荐模型,能够在电商、视频和音乐平台上提供个性化推荐。在金融科技中,机器学习被用于信用评分、欺诈检测和市场预测,显著提高了金融服务的效率与安全性。在医疗健康领域,机器学习通过电子病历分析和医学影像处理帮助医生进行疾病诊断和预测。工业与物联网应用中,机器学习被用于设备的故障预测和优化控制,例如通过预测性维护延长机器寿命。强化学习也在游戏AI、机器人路径规划和自动化系统中展现了强大的能力。此外,在科学研究中,机器学习加速了新药开发、基因分析和天文学研究的进展。
通过技术的不断演进,机器学习的应用范围还在持续扩展,其对各行业的深刻影响仍在进一步深化。
清除./ragtest下的生成文件,只保留input,prompt,.env和settings.yaml,防止之前英文示例缓存对中文示例产生影响。
4.2 中文提示词变更
GraphRAG支持中文文本,但默认提示词针对英文,所以首先需要调整提示词。
这里使用graphrag提供的自动化prompt调整,示例如下。
graphrag prompt-tune --root ./ragtest --domain 计算机 --language 中文 --chunk-size 500 --output ./prompt-cs
以上命令在./prompt-cs下生成针对计算机领域、中文文本的提示词。
graphrag prompt-tune其他参数可以通过graphrag prompt-tune --help查看。
使用新生成提示词覆盖./ragtest/prompt下默认提示词,剩余运行步骤与英文版类似,即为构建索引、进行全局搜索和局部搜索。
附录
1 Invalid value for '--reporter'
Invalid value for '--reporter' (env var: 'None'): <ReporterType.RICH: 'rich'> is not one of 'rich', 'print', 'none'. │
补全输出参数"none"/"print"/"rich",比如 --reporter "rich"
2 其他测试数据
如下小1000行的文本,获取命令如下。
https://www.gutenberg.org/cache/epub/7785/pg7785.txt
wget https://www.gutenberg.org/cache/epub/7785/pg7785.txt -O ragtest/input/Transformers_intro.txt
reference
---
GraphRAG
https://github.com/msolhab/graphrag
Project Gutenberg
Global Search Notebook
https://microsoft.github.io/graphrag/examples_notebooks/global_search/
GraphRAG-知识图谱与检索增强的融合探索
https://blog.csdn.net/liliang199/article/details/151189579
GraphTest - 直接使用阿里API,总体费用相对可控。
https://github.com/NanGePlus/GraphragTest
GraphRAG(最新版)+Ollama本地部署,以及中英文示例
https://juejin.cn/post/7439046849883226146
傻瓜操作:GraphRAG、Ollama 本地部署及踩坑记录
https://blog.csdn.net/weixin_42107217/article/details/141649920
graphrag-local-ollama
https://github.com/TheAiSingularity/graphrag-local-ollama
深度解读 GraphRAG:如何通过知识图谱提升 RAG 系统
https://xie.infoq.cn/article/18ca7cd7702fc0f03baa02b01
OneAPI-通过OpenAI API访问所有大模型
https://blog.csdn.net/liliang199/article/details/151393128
微软开源GraphRAG的安装+示例教程

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐


 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)