知识图谱构建新路径:LLM 图转换器的使用方法详解
本文介绍了如何利用大语言模型(LLMs)从非结构化文本构建知识图谱,重点分析了LLM图转换器的两种工作模式及其应用场景。文章首先阐述了知识图谱在支持检索增强生成(RAG)应用中的重要性,特别是处理多跳推理和结构化操作任务时的优势。随后详细说明了LLM图转换器的两种工作模式:工具驱动模式(利用结构化输出)和提示驱动模式(依赖少样本提示),并比较了它们的优缺点。文章还介绍了如何定义图谱模式(graph
从文本到知识图谱
从文本中构建知识图谱,是一件既令人兴奋又充满挑战的技术实践 —— 其核心在于将非结构化文本精准转化为结构化数据,为后续的知识检索、分析与应用打下基础。
事实上,“文本转结构化数据” 的方法早有探索,但直到大语言模型(LLMs) 兴起后,这一过程的效率与准确性大幅提升,不仅突破了传统方法的局限,更让文本构建知识图谱的技术迅速进入主流视野,在企业知识库、智能问答等场景中得到广泛应用。
在下图中:
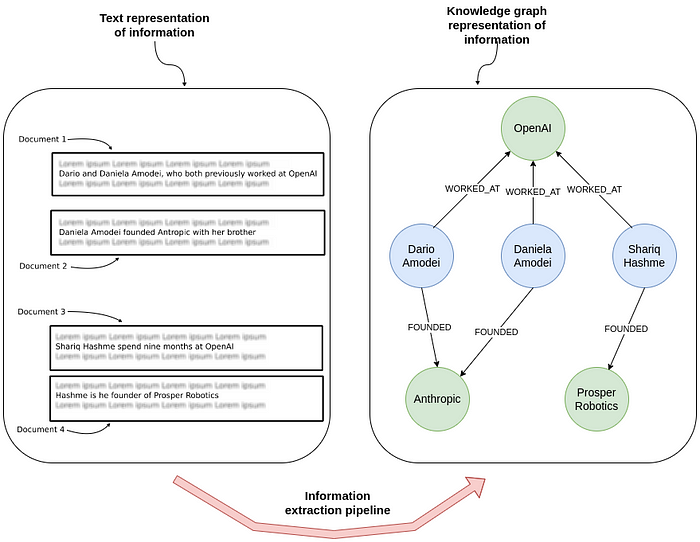
•左侧 展示了若干包含人物与公司关系的非结构化句子。•右侧 则将这些信息抽取为知识图谱,展示了谁在哪些公司工作或创建了哪些组织。
为什么要构建知识图谱?
一个关键原因是为了支持 检索增强生成(RAG, Retrieval-Augmented Generation) 应用。
•仅仅依靠文本嵌入模型处理非结构化文本,虽然有用,但在以下情况下会受限:•复杂的 多跳推理问题[1](需要跨多个实体进行推理)。•需要 结构化操作(如过滤、排序、聚合)[2]的任务。•通过从文本中抽取结构化信息并构建知识图谱:•可以更有效地组织数据;•可以建立强大的框架来理解复杂关系。
这种 结构化方法 不仅让检索和利用特定信息更加容易,还能显著提升准确性,并扩展可回答的问题范围。
LLM 图转换器的出现
大约一年前,我开始尝试用 LLM 构建图谱。随着兴趣日益增长,我们决定将这一功能集成到 LangChain 中,推出了 LLM Graph Transformer。
过去一年,我们积累了宝贵经验,并新增了多项功能。本文将逐步展示这些成果。
相关代码已在 GitHub[3] 开源。
搭建 Neo4j 环境
我们选择 Neo4j 作为底层图数据库,它内置图形可视化能力。
快速入门方式有两种:
1.使用 Neo4j Aura 免费云实例[4](官方提供,开箱即用)。2.下载 Neo4j Desktop 应用[5],在本地创建数据库实例。
示例代码:
from langchain_community.graphs importNeo4jGraph
LLM 图转换器
LLM Graph Transformer 的设计目标,是提供一个灵活的框架,让我们可以利用任意大语言模型(LLM)来构建知识图谱。 由于当下有众多不同的模型和服务提供商,这项任务远非简单。
幸运的是,LangChain在标准化处理方面承担了大量工作。 至于 LLM 图转换器 本身,它就像是“两只猫套在风衣里” —— 具备两种完全独立的工作模式。
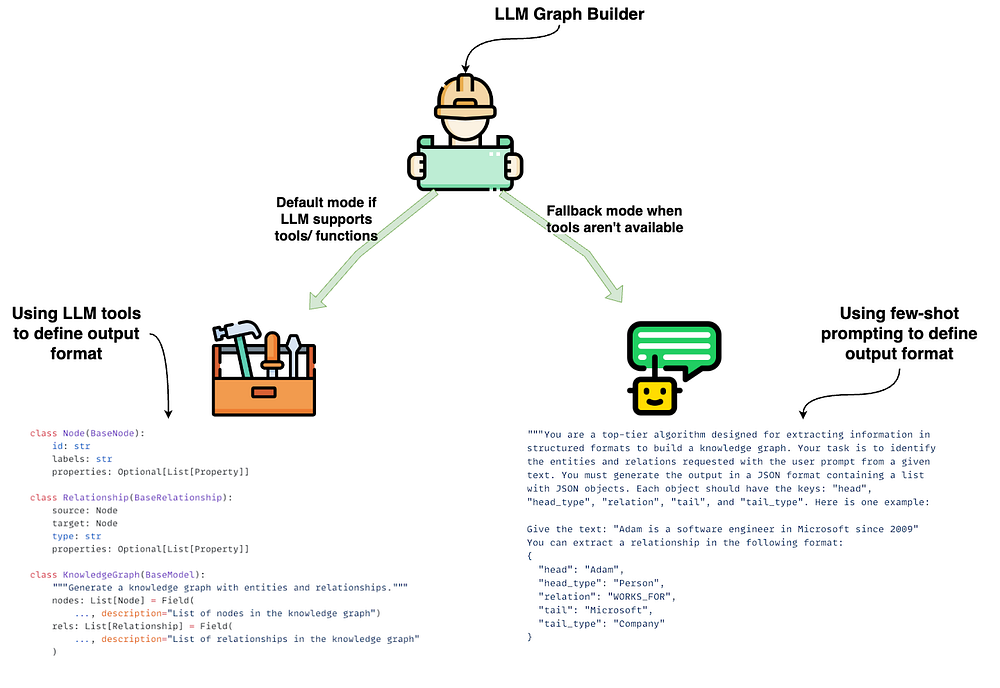
两种工作模式
LLM 图转换器 提供了两种模式,用于在不同场景下从文档中生成知识图谱:
1. 工具驱动模式(默认模式)
•适用于 LLM 支持 结构化输出 或 函数调用 的情况。•此模式依赖 LLM 内置的 with_structured_output 方法[6],结合工具规范来定义输出格式。•这样,实体与关系就能以 结构化、预定义的形式 被准确提取。•在原文插图的左侧,可以看到 Node 和 Relationship 类的代码示例。
2. 提示驱动模式(回退模式)
•当 LLM 不支持工具或函数调用时,系统会退回到纯 Prompt 驱动 的方式。•使用 少样本提示(few-shot prompting) 来定义输出格式,引导 LLM 以文本形式抽取实体和关系。•随后,结果会经过一个自定义函数解析,转化为 JSON 格式,用于填充节点和关系。•本质上,与工具模式生成的结构一致,只是这里完全依赖 Prompt 进行引导。•在原文插图的右侧,可以看到提示示例及其对应的 JSON 输出。
灵活性与兼容性
•这两种模式保证了 LLM 图转换器 能够适配不同的 LLM:•可以直接使用工具提取;•也可以通过解析 Prompt 输出的文本来构建图谱。•即使模型本身支持工具/函数调用,你也可以通过设置 ignore_tools_usage=True 来强制启用 Prompt 模式。
为什么选择工具驱动提取?
我们最初选择 工具驱动模式 作为默认方案,原因在于它可以:
•减少复杂的 Prompt 设计工作;•避免编写过多自定义解析函数。
在 LangChain 中,with_structured_output 方法允许通过 工具 或 函数 来提取信息:
•输出可以定义为 JSON 结构;•或者定义为 Pydantic 对象。
就个人而言,我认为 Pydantic 对象 更加直观清晰,因此我们选择了这种方式。
以下是一个 Node 类的示例,用于描述知识图谱中的节点:
classNode(BaseNode):
Node 类说明
每个 节点(Node) 都包含以下部分:
•id:节点唯一标识符(要求是 人类可读的唯一名称)。•说明:有些 LLM 会将 ID 理解为随机字符串或自增整数,但我们更希望 ID 能直接表示实体的名称。•label:节点标签(通过描述中列出可选项来限制标签类型)。•properties:可选的属性(用于存放节点的额外信息)。
此外,像 OpenAI 这样的模型支持 enum 参数,我们也利用这一特性来限制可用的标签范围。
Relationship 类定义
接下来是 关系(Relationship) 的定义:
classRelationship(BaseRelationship):
Relationship 类的改进(第二版)
这是 Relationship 类 的第二个迭代版本。
在最初的实现中,我们为关系的 起始节点(source) 和 目标节点(target) 使用了嵌套的 Node 对象。
但实验发现:嵌套对象会降低提取的准确性和质量。
因此,我们将其 扁平化,改为独立字段:
•source_node_id 与 source_node_label•target_node_id 与 target_node_label
另外,我们在 节点标签(label) 和 关系类型(type) 的描述中,明确限定了可选值,确保 LLM 严格遵守既定的图谱模式(schema)。
定义属性类(Property)
在 工具驱动提取 模式下,我们可以为节点和关系都定义属性。
以下是用于定义属性的 Property 类:
classProperty(BaseModel):
属性(Property)的局限性
每个 Property 都是以 键值对(key-value pair) 的形式定义。
这种方式虽然灵活,但也存在一些局限:
•无法为每个属性单独提供唯一的描述。•无法区分哪些属性是 必填,哪些是 可选 —— 因此所有属性都被统一定义为可选。•属性并不是针对每种节点或关系类型分别定义的,而是 在所有节点和关系之间共享。
系统提示(System Prompt)的作用
为了引导信息抽取,我们实现了一个详细的 系统提示[7]。 不过根据经验,函数及参数的描述 往往比系统提示对结果的影响更大。
遗憾的是,目前在 LLM Graph Transformer 中,还没有简便的方法去定制函数或参数的描述。
提示驱动模式(Prompt-based Extraction)
由于只有少数商用 LLM 和 LLaMA 3 支持原生工具,我们实现了一个 回退方案 —— 在模型不支持工具时,采用 Prompt 驱动模式。
即便使用支持工具的模型,也可以通过设置
ignore_tool_usage=True来强制使用 Prompt 模式。
提示驱动模式的大部分 Prompt 工程 和示例由 Geraldus Wilsen[8] 提供。
在这种模式下,输出结构必须直接在 Prompt 中定义。完整的 Prompt[9] 可以在原始代码中找到,这里只展示概要。
系统 Prompt 示例
You are a top-tier algorithm designed for extracting information in structured formats to build a knowledge graph.
提示驱动模式的关键差异
在 提示驱动模式(Prompt-based approach) 中,有一个重要区别:
•我们只要求 LLM 抽取关系(relationships),而不是单独抽取节点(nodes)。•这意味着输出中不会存在“孤立节点”,与 工具驱动模式 不同。•另外,由于缺乏原生工具支持的模型性能往往较差,我们在该模式下 不允许抽取任何属性(无论是节点属性还是关系属性),以保持结果输出的简洁性。
少样本示例(Few-shot Examples)
在 Prompt 中,我们会加入若干 少样本示例,用来引导 LLM 学习所需的抽取格式。
下面是部分示例代码:
examples =[
自定义 Few-shot 示例的限制
在 提示驱动模式 下,目前还 不支持添加自定义的 few-shot 示例 或额外的说明指令。
唯一的定制方式是通过 prompt 属性,直接修改整个 Prompt。
扩展自定义选项是我们正在积极考虑的方向。
定义图谱模式(Graph Schema)
在使用 LLM Graph Transformer 进行信息抽取时,定义图谱模式(schema) 至关重要。
它可以:
•指定需要抽取的 节点类型 与 关系类型;•明确每个节点或关系所关联的属性;•为模型提供一个蓝图(blueprint),确保 LLM 输出的内容始终与目标知识图谱的结构保持一致。
一个良好的图谱模式,能帮助模型稳定地抽取有意义的结构化信息,从而构建出清晰、可用的知识图谱。
示例:Marie Curie + Robin Williams
在本篇博客的示例中,我们选取了 玛丽·居里(Marie Curie)[10] 的维基百科开头段落,并在结尾加了一句关于 罗宾·威廉姆斯(Robin Williams) 的描述。
from langchain_core.documents importDocument
使用 GPT-4o 作为 LLM
在所有示例中,我们都使用 GPT-4o 作为底层 LLM:
from langchain_openai importChatOpenAI
下面先看看在未定义任何图谱 schema 的情况下,抽取流程是如何工作的。
from langchain_experimental.graph_transformers importLLMGraphTransformer
接下来使用异步的 aconvert_to_graph_documents 来处理文档。 推荐在 LLM 抽取中使用 async:它可以并行处理多个文档,显著缩短等待时间、提升吞吐量,尤其适合批量场景。
data = await no_schema.aconvert_to_graph_documents(documents)
LLM Graph Transformer 的返回结果是一个图文档(graph document),其结构大致如下:
[
图文档与可视化
图文档(graph document)中不仅描述了抽取出的 节点(nodes) 与 关系(relationships), 还会在 source 字段下附上 抽取所依据的源文档,便于溯源与校验。
我们可以使用 Neo4j Browser 对结果进行可视化,从而获得更清晰、直观的理解。
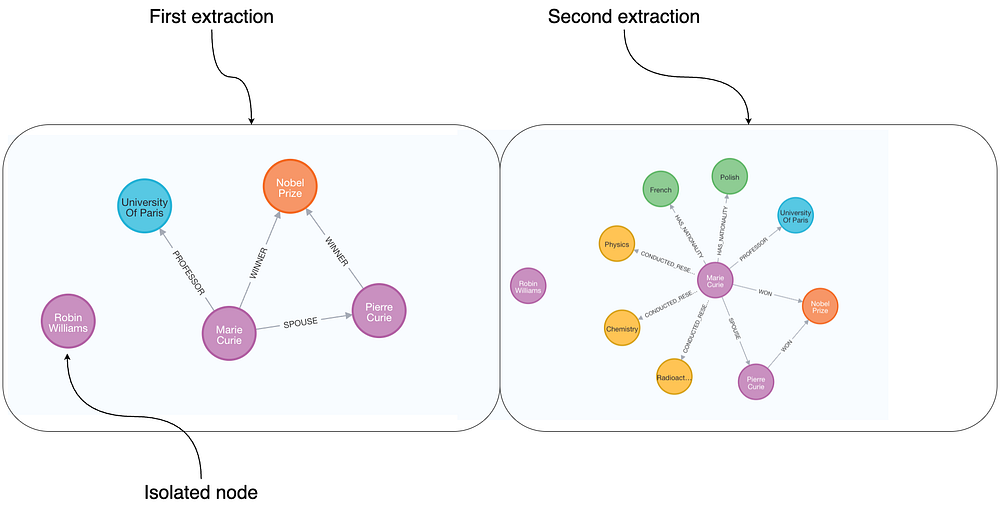
下图(原文示意)展示了**在未定义图谱模式(schema)**的情况下,对同一段玛丽·居里(Marie Curie)文本进行两次抽取的可视化对比。
本例使用 GPT-4 的工具驱动抽取,因此可能出现“孤立节点”。
由于没有预先定义 schema,LLM 会在运行时自行决定抽取哪些信息:
•即便是同一段文本,不同次的输出也可能存在差异;•有的结果更详细,有的在结构上也会有所不同。
例如:左图把 Marie 表达为 Nobel Prize 的 WINNER,右图则表达为 Marie WON 了 Nobel Prize —— 语义相近,但关系类型与表述结构不同。
使用提示驱动模式(Prompt-based)进行同样的抽取
对于 支持工具 的模型,也可以通过设置 ignore_tool_usage 参数来启用 提示驱动模式:
no_schema_prompt =LLMGraphTransformer(llm=llm, ignore_tool_usage=True)
使用提示驱动模式的效果与局限
在 提示驱动模式(prompt-based approach) 下,不会出现“孤立节点”。
不过,与之前的抽取一样,由于未定义 schema,同一输入在不同运行之间的结构仍可能变化,从而得到不同的输出。
通过定义图谱模式获得更一致的结果
接下来看看:定义图谱 schema 如何帮助产出更一致的结果。
限定允许的节点类型(Defining allowed nodes)
对抽取到的图结构进行约束非常有帮助,它能引导模型聚焦于特定且相关的实体与关系。 通过定义清晰的 schema,你可以显著提升多次抽取之间的一致性,让结果更可预测、更符合实际需求。
这将降低不同运行之间的波动,确保抽取数据遵循标准化结构,并捕获预期中的信息。
在一个良好定义的 schema 下,模型更不容易遗漏关键细节,也更不容易引入意外元素,最终得到更干净、可用性更强的图。
我们先用 allowed_nodes 参数定义期望抽取的节点类型:
allowed_nodes =["Person","Organization","Location","Award","ResearchField"]
在这里,我们规定 LLM 只能抽取五类节点,如 Person、Organization、Location 等。 随后,可以在 Neo4j Browser 中对两次独立执行的结果进行可视化对比。
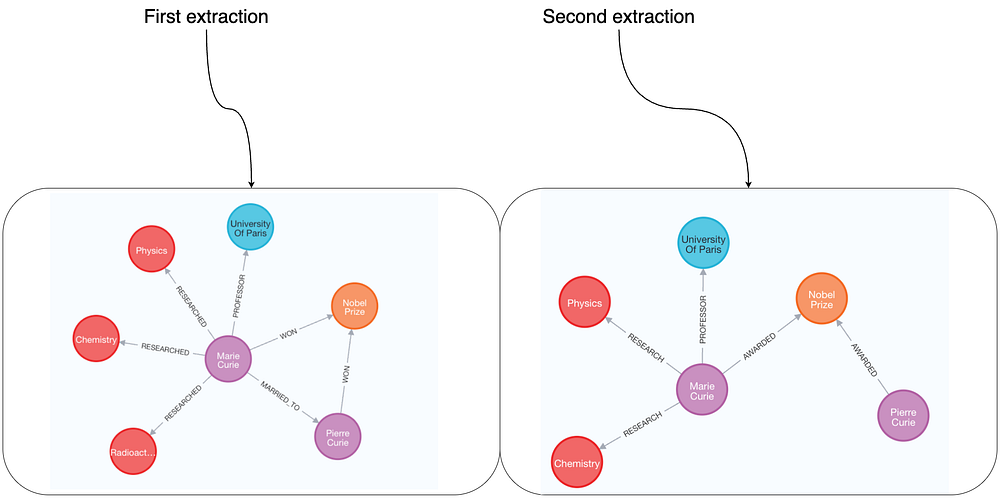
通过明确期望的节点类型,节点抽取的确会更一致;但仍可能出现差异。
例如:第一次运行中将 “radioactivity(放射性)” 抽取为 ResearchField,而第二次运行则未抽取到。
由于我们尚未限定关系类型,不同运行间的关系抽取也会不一致;且有的结果信息更丰富。
比如:MARRIED_TO(已婚/配偶)这一关系(Marie 与 Pierre 之间)并非在两次抽取中都出现。
仅限定节点类型,关系抽取仍会波动。接下来我们同时限定关系类型,以进一步提升一致性。
定义允许的关系类型(Defining allowed relationships)
第一种做法是以枚举列表的方式,指定允许的关系类型:
allowed_nodes =["Person","Organization","Location","Award","ResearchField"]
随后,可以再次对两次独立抽取进行对比可视化,观察在限定了节点与关系之后,输出在结构与语义上的一致性是否显著提升。
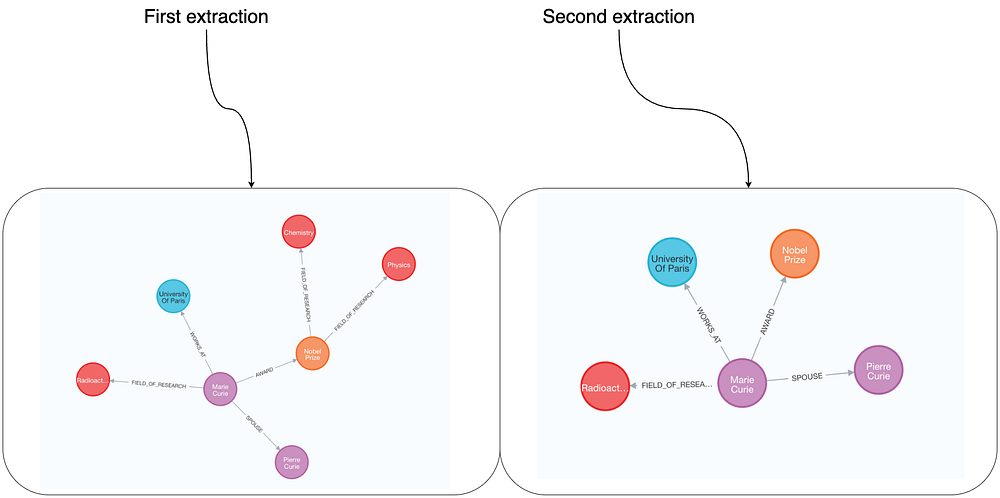
同时限定节点与关系后的效果
当节点类型与关系类型都被限定后,输出的一致性显著提升。
例如:关于 Marie 的信息会稳定地包含:
•获得奖项(如诺贝尔奖);•与 Pierre 为配偶关系;•就职/任教于巴黎大学。
不过,由于关系仅以通用列表的方式定义,且未限制可连接的节点类型,仍会出现一些差异:
•FIELD_OF_RESEARCH(研究领域)有时会在 Person ↔ ResearchField 之间建立,
但也可能错误地出现在 Award ↔ ResearchField 之间。•此外,我们没有定义关系方向,因此方向一致性也可能不稳定。
新增:关系的三元组约束(限定端点与方向)
为了解决无法指定关系可连接的节点类型以及无法强制方向的问题,我们引入了新的关系定义方式,如下所示:
allowed_nodes =["Person","Organization","Location","Award","ResearchField"]
使用三元组格式定义关系
与之前用 字符串列表 定义关系不同,现在我们采用 三元组(tuple) 的格式来描述关系:
•第 1 个元素:源节点类型(Source Node)•第 2 个元素:关系类型(Relationship Type)•第 3 个元素:目标节点类型(Target Node)
这种方式的优势在于:
•明确规定了 关系必须连接的节点类型;•保证了 关系的方向性;•大幅提升了抽取结果的 一致性与准确性。
可视化结果
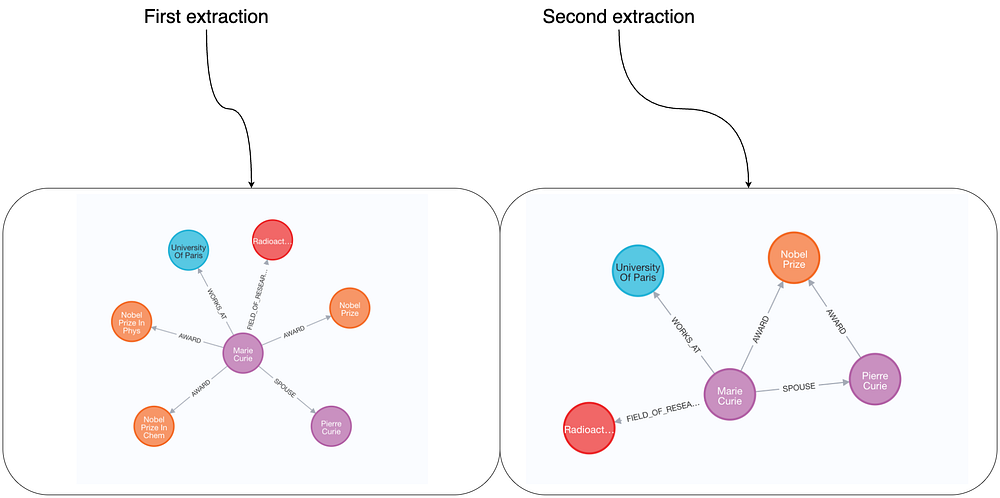
通过在 Neo4j Browser 中再次进行可视化,可以直观对比:
•使用 字符串列表 定义关系时的不确定性;•采用 三元组格式 后,关系结构更加稳定、语义更加清晰的效果。
三元组关系的稳定性与剩余差异
采用 三元组(source, relation, target) 的关系定义后,多次执行间的 schema 一致性 显著提升。
不过,由于 LLM 的固有特性,细节层面的差异 仍可能存在:
•例如右侧结果中显示 Pierre 获得了诺贝尔奖,而左侧结果则缺少这一信息。
定义属性(Properties)
改进图谱 schema 的最后一步,是为 节点 与 关系 定义属性。这里有两种思路:
方案一:让模型自主决定提取哪些属性
将 node_properties 或 relationship_properties 设为 True,允许 LLM 自主判定要抽取的属性键值对。
优点是简便、能快速捕获更多细节;缺点是不够可控、不同运行间可能存在差异。
示例代码:
allowed_nodes =["Person","Organization","Location","Award","ResearchField"]
接下来即可查看结果,评估在属性启用后,节点与关系是否携带了更丰富的上下文信息(如时间、职位、地点、获奖年份等)。
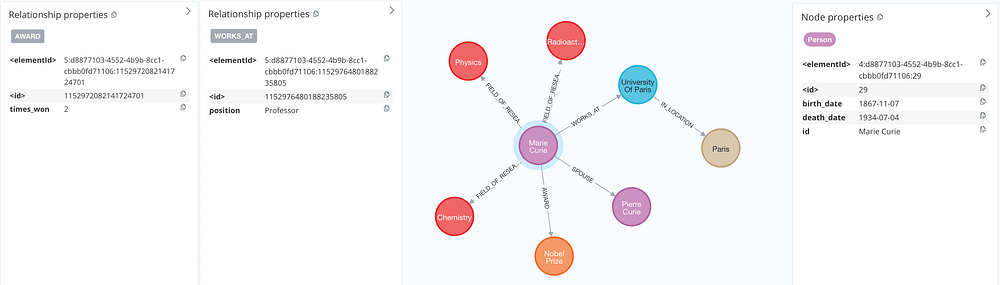
注:方案二通常是显式列举允许的属性键并限制类型与必选/可选,但本文段落暂仅介绍“让模型自主决定”的做法。
在该方案中,我们允许 LLM 自主决定为节点或关系添加它认为相关的属性。
例如,模型会补充:
•玛丽·居里(Marie Curie) 的 出生/逝世日期;•她在 巴黎大学任教(Professor at the University of Paris) 的角色信息;•她 两次获得诺贝尔奖 的事实。
这些附加属性显著丰富了抽取的信息密度,让图谱更具语义价值。
第二种做法是明确列出我们希望抽取的节点属性与关系属性,从而让输出更可控、更一致。
allowed_nodes =["Person","Organization","Location","Award","ResearchField"]
接下来即可查看 LLM 的抽取结果,验证是否正确填充了:
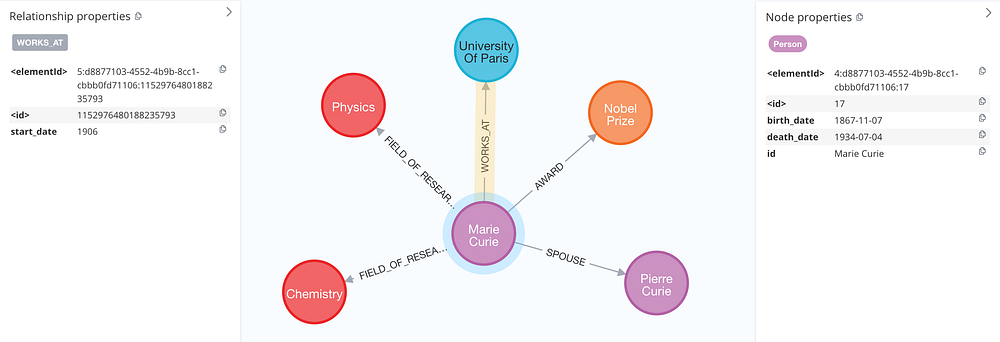
与前一次抽取相比,出生日期与逝世日期保持一致。
此外,这一次模型还抽取出了 玛丽在巴黎大学任教的起始日期(教授任期的开始时间)。
引入 属性(Properties) 的确能显著提升信息的深度与可用性,但当前实现仍存在一些限制:
1.只能在工具驱动模式下 抽取属性(prompt 驱动模式不支持)。2.所有属性都以字符串(string)形式 返回(缺少类型化,如日期/数字/布尔等)。3.属性只能 全局定义,而不能按节点标签或关系类型分别指定。4.无法自定义属性的描述 来进一步约束或引导 LLM 提取得更精确。
严格模式(Strict Mode)
如果你以为我们已经找到了让 LLM 完美遵循 schema 的方法,那我需要澄清一下:
即便投入了大量的 Prompt 设计工作,要让 LLM(尤其是性能较弱的模型)百分之百 严格遵循指令仍然很难。
为此,我们引入了一个后处理步骤——strict_mode:
•它会 移除 所有 不符合已定义图谱 schema 的信息,•以获得更干净、更一致的输出。
默认情况下,strict_mode=True。你也可以手动关闭:
LLMGraphTransformer(
关闭严格模式后,LLM 可能会输出 超出 schema 定义的节点或关系类型, 因为模型有时会“发挥创意”,产生不在约束内的结构。
将图文档导入图数据库
从 LLM Graph Transformer 抽取出的图文档,可以导入到图数据库(如 Neo4j)中,
以便进行后续的分析与应用。
导入时可使用 add_graph_documents 方法,根据不同场景选择不同的导入策略。
默认导入(Default Import)
最简单的方式是直接将节点与关系导入 Neo4j,示例代码如下:
graph.add_graph_documents(graph_documents)
此方法会直接导入传入的图文档中的所有节点与关系。 在本文的实验与演示中,我们一直采用这种方式来验证不同 LLM 与 schema 配置下的结果。
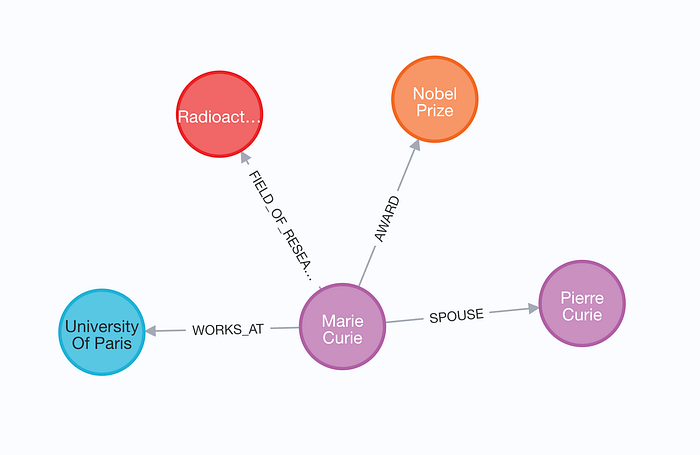
基础实体标签(Base Entity Label)
大多数图数据库都支持 索引(indexes) 来优化数据的导入与检索。
在 Neo4j 中,索引只能设置在特定的 节点标签(node labels) 上。
然而,我们可能事先并不知道所有的节点标签。
为了解决这个问题,可以通过 baseEntityLabel 参数,
为每个节点添加一个 次级的基础标签,以便统一建立索引。
示例代码:
graph.add_graph_documents(graph_documents, baseEntityLabel=True)
启用 baseEntityLabel 后,每个节点都会额外拥有一个__Entity__标签。 这样我们就能基于 __Entity__ 建立索引,从而提升 导入效率 和 查询性能, 而无需为图中每个可能出现的节点标签单独设置索引。
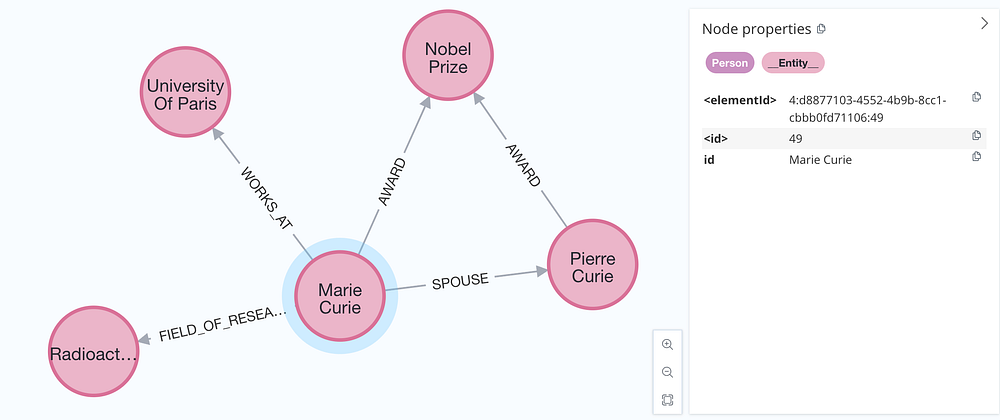
导入源文档(Include Source Documents)
最后一个可选项是 同时导入源文档,以记录节点与关系的出处。
这种方式可以帮助我们追踪:某个实体或关系来源于哪些文档, 便于后续的溯源与分析。
启用方法:在导入时设置 include_source=True。
graph.add_graph_documents(graph_documents, include_source=True)
在可视化结果中,源文档(source document) 会以蓝色高亮显示,
并通过 MENTIONS 关系与从该文档中抽取出的所有实体相连。
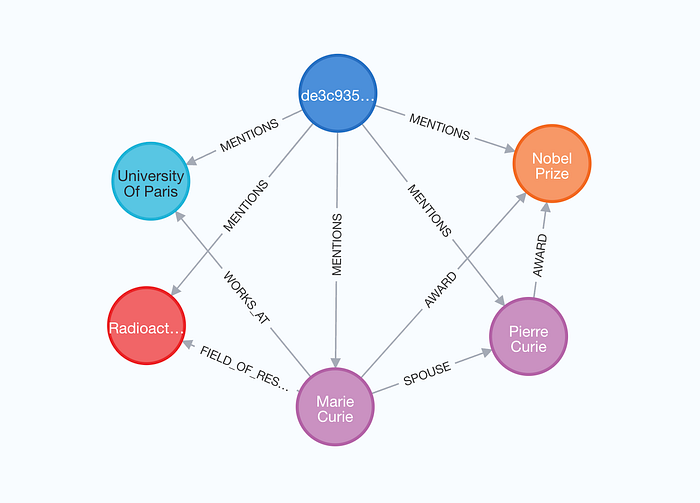
这种模式不仅能展示信息来源,还可以构建同时利用
结构化搜索 与 非结构化搜索 的检索器(retrievers)[11], 从而提升检索增强生成(RAG)的能力。
总结
在这篇文章中,我们探索了 LangChain 的 LLM Graph Transformer
以及它的两种构建知识图谱的模式:
•工具驱动模式(Tool-based mode)•我们的主要方法。•借助结构化输出与函数调用,减少了 Prompt 设计的复杂性。•支持属性(Properties)的抽取。•提示驱动模式(Prompt-based mode)•当工具不可用时的替代方案。•依赖少样本示例(few-shot examples)来引导 LLM 输出。•不支持属性抽取,且不会生成孤立节点。
图谱 Schema 的重要性
实验表明,清晰的图谱 Schema 定义(包括允许的节点类型与关系类型):
•能显著提升抽取结果的一致性与性能;•确保输出严格遵循目标结构;•让结果更可预测、更可靠,并便于应用在下游任务中。
应用价值
无论是工具驱动还是提示驱动,
LLM Graph Transformer 都能将非结构化文本转化为更有组织、更结构化的表示。
这对于:
•RAG 应用•多跳推理查询(multi-hop queries)
都具有重要价值。
获取与尝试
•代码已在 GitHub[12] 开源。•你也可以在 Neo4j 提供的托管 LLM Graph Builder 应用 中,
通过 零代码环境(no-code environment) 来尝试 LLM Graph Transformer。
https://medium.com/data-science/building-knowledge-graphs-with-llm-graph-transformer-a91045c49b59
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)