
TensorFlow集群搭建与编程
文本手把手教会你利用docker搭建TensorFlow集群环境,然后利用该环境进行深度学习模型的训练,比较单机版本和集群版本的性能差异。
TensorFlow集群搭建与编程
深度学习那超强学习能力的背后,是巨大的计算负担,因此分布式集群计算势在必行,据说AlphaGo需要同时使用1202个CPU和176个GPU来进行并行计算。
集群功能早在Tensorflow0.8版本就已推出,本文将一步步地展示搭建集群框架并在上面编程分配计算任务的全过程。
考虑到不少人条件有限,很难实现真实的多机环境,因此下面将利用docker来实现一个虚拟的多机集群网络通信环境。整体架构如下:
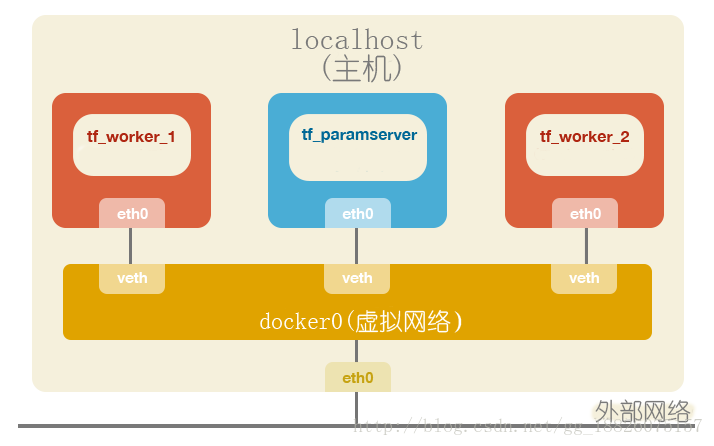
1.搭建环境
首先是搭建支撑TensorFlow集群运行的Docker环境,然后把TensorFlow镜像导入运行。
1.1安装Docker并启动Daemon
Red Hat系列的操作系统(比如:CentOS7):
[root@localhost ~]# yum install docker
[root@localhost ~]# systemctl start docker
[root@localhost ~]# systemctl status docker #确认Docker Daemon的启动状态Debian系列的操作系统(比如:Ubuntu16.04LTS):
root@localhost:~$ sudo apt-get update
root@localhost:~$ sudo apt-get install docker.io
root@localhost:~$ sudo service docker start
root@localhost:~$ sudo service docker status #确认Docker Daemon的启动状态注意:接下来我们假定操作系统是Ubuntu16.04LTS。
1.2下载TensorFlow镜像
TensorFlow官方提供了Docker镜像,可以省去繁杂的环境搭建流程
root@localhost:~$ sudo docker pull tensorflow/tensorflow:latest
root@localhost:~$ sudo docker images # 确认镜像是否下载成功2.启动各个Docker容器
因为我们要实现集群中各个服务器实例在各自的Python交互环境中运行,所以考虑启动相同数量的Docker容器,然后分别在它们之上运行终端程序。
2.1定制化镜像
root@localhost:~$ sudo docker run -it --name init_server --cpuset-cpus 0 -h init_server tensorflow/tensorflow:latest /bin/bash
root@init_server:/notebooks# # 自动切换到刚创建的容器环境
root@init_server:/notebooks# apt-get update # 为接下来安装ifconfig和vim做好准备
root@init_server:/notebooks# apt-get install vim
root@init_server:/notebooks# apt-get install net-tools # 安装ifconfig
root@init_server:/notebooks# exit
exit
root@localhost:~$ sudo docker ps -a # 查找刚退出容器的ID,假设为c4d51e8fbbbe
root@localhost:~$ sudo docker commit c4d51e8fbbbe my_images/tensorflow # 使用容器来创建镜像
root@localhost:~$ sudo docker stop c4d51e8fbbbe # 停止容器
root@localhost:~$ sudo docker rm c4d51e8fbbbe # 删除容器解释一下我们上面docker run命令中各参数的含义:
- -i:以交互模式运行容器,通常与 -t 同时使用;
- -t:为容器重新分配一个伪输入终端,通常与 -i 同时使用;
- –name “nginx-lb”:为容器指定一个名称;
- –-cpuset-cpus 0-2:创建的容器只能用0、1、2这三个内核
- -h “mars”:指定容器的hostname;
- tensorflow/tensorflow:latest:指定镜像名
- /bin/bash:容器启动完成后,在容器内执行/bin/bash命令
2.2启动ParamServer
root@localhost:~$ sudo docker run -it --name tf_paramserver --rm --cpuset-cpus 0 -h tf_paramserver -v ~/tensorflow-cluster-cifar-10-annotated:/tmp/tensorflow-cluster-cifar-10-annotated my_images/tensorflow /bin/bash
root@tf_paramserver:/notebooks# # 自动切换到刚创建的容器环境
root@tf_paramserver:/notebooks# ifconfig # 确认容器的IP地址
eth0 Link encap:Ethernet HWaddr 02:42:ac:11:00:02
inet addr:172.17.0.2 Bcast:0.0.0.0 Mask:255.255.0.0
……
……这样,我们就得到了ParamServer的IP地址——172.17.0.2
值得留意的是上面的docker run命令中又新增了一些选项。
- –rm选项,这样在退出该容器时会自动对它进行docker rm操作。
- -v /path/to/hostdir:/mnt:表示将宿主机器上的/path/to/hostdir挂载到容器上的/mnt目录(上面的tensorflow-cluster-cifar-10-annotated是存放待会要运行的python代码的目录)
2.3启动WorkerServer1
root@localhost:~$ sudo docker run -it --name tf_worker_1 --rm --cpuset-cpus 0 -h tf_worker_1 -v ~/tensorflow-cluster-cifar-10-annotated:/tmp/tensorflow-cluster-cifar-10-annotated my_images/tensorflow /bin/bash
root@tf_worker_1:/notebooks# # 自动切换到刚创建的容器环境
root@tf_worker_1:/notebooks# ifconfig # 确认容器的IP地址
eth0 Link encap:Ethernet HWaddr 02:42:ac:11:00:03
inet addr:172.17.0.3 Bcast:0.0.0.0 Mask:255.255.0.0
……
……这样,我们就得到了WorkerServer1的IP地址——172.17.0.3
2.4启动WorkerServer2
root@localhost:~$ sudo docker run -it --name tf_worker_2 --rm --cpuset-cpus 0 -h tf_worker_2 -v ~/tensorflow-cluster-cifar-10-annotated:/tmp/tensorflow-cluster-cifar-10-annotated my_images/tensorflow /bin/bash
root@tf_worker_2:/notebooks# # 自动切换到刚创建的容器环境
root@tf_worker_2:/notebooks# ifconfig # 确认容器的IP地址
eth0 Link encap:Ethernet HWaddr 02:42:ac:11:00:04
inet addr:172.17.0.4 Bcast:0.0.0.0 Mask:255.255.0.0
……
……这样,我们就得到了WorkerServer2的IP地址——172.17.0.4
3.编程实现
下面我们对官方的示例代码——cifar-10图像分类进行改写,从而得到我们的分布式集群实现版本。cifar-10数据集分为10个类别,训练集共5万张图片,测试集共1万张图片。

整个分布式系统的数据流大致如下:
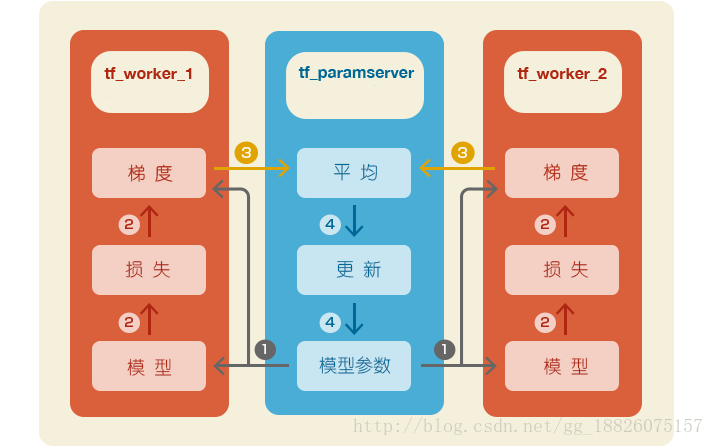
即使现在TensorFlow官网上的教程还有这份代码的说明文档(卷积神经网络部分),但是源码链接已经失效,主要原因是由于TensorFlow1.0的升级带来了许许多多API接口的变化,这份代码官方也不再维护了。
不过经过本人认真的修改,已经把代码修改为最新版本也可以使用了,github地址如下:https://github.com/gh877916059/tensorflow-cluster-cifar-10-annotated
我们修改的目标就是cifar10_multi_gpu_train.py这个单机多GPU版本的代码文件。
为了节省文章的篇幅,下面仅列出代码修改前后的差异。diff工具就是专门用来干这事情的,它也是代码版本管理的基石。
比如,我们把下面的命令的执行结果保存为”差异.patch”
$ diff <变动前的文件> <变动后的文件>然后我们就可以通过patch <变动前的文件> 差异.patch来还原得到<变动后的文件>。
关于如何读懂diff的输出结果,可以参考这篇文章:
http://www.ruanyifeng.com/blog/2012/08/how_to_read_diff
3.1 cifar10_standalone_train.patch
51c51
51c51
< tf.app.flags.DEFINE_integer('max_steps', 1000000,
---
> tf.app.flags.DEFINE_integer('max_steps', 1000,
3.2 cifar10_cluster_train.patch
46a47
> PS_NODE = "172.17.0.2"
51c52
< tf.app.flags.DEFINE_integer('max_steps', 1000000,
---
> tf.app.flags.DEFINE_integer('max_steps', 1000,
53,54c54,55
< tf.app.flags.DEFINE_integer('num_gpus', 1,
< """How many GPUs to use.""")
---
> tf.app.flags.DEFINE_integer('num_workers', 2,
> """How many WorkerServers to use.""")
124c125
< with tf.Graph().as_default(), tf.device('/cpu:0'):
---
> with tf.Graph().as_default(), tf.device('/job:ps/task:0/cpu:0'):
145,146c146,147
< for i in xrange(FLAGS.num_gpus):
< with tf.device('/gpu:%d' % i):
---
> for i in xrange(FLAGS.num_workers):
> with tf.device('/job:worker/task:%d/cpu:0' % i):
190,192c191
< sess = tf.Session(config=tf.ConfigProto(
< allow_soft_placement=True,
< log_device_placement=FLAGS.log_device_placement))
---
> sess = tf.Session("grpc://%s:2222" % PS_NODE)
204c203
< num_examples_per_step = FLAGS.batch_size * FLAGS.num_gpus
---
> num_examples_per_step = FLAGS.batch_size * FLAGS.num_workers
206c205
< sec_per_batch = duration / FLAGS.num_gpus
---
> sec_per_batch = duration / FLAGS.num_workers
记得,把上面的PS_NODE = “172.17.0.2”替换为你自己查到的ParamServer的IP地址。
3.3代码修改说明
51c51
< tf.app.flags.DEFINE_integer('max_steps', 1000000,
---
> tf.app.flags.DEFINE_integer('max_steps', 1000,修改前模型的默认训练步数为100万,如果不引入大量并行化处理,将会耗费大量的时间。而我们本次实验的目的并非真的要训练出一个准确率极高的模型,只是想验证下集群模式与单机模式的处理速度的差异而已。因此,我们把训练步数减少为1000。
46a47
> PS_NODE = "172.17.0.2"由于我们的两个WorkerServer都是只与ParamServer进行直接通信,因此需要而且只需要知道ParamServer的IP地址即可。
53,54c54,55
< tf.app.flags.DEFINE_integer('num_gpus', 1,
< """How many GPUs to use.""")
---
> tf.app.flags.DEFINE_integer('num_workers', 2,
> """How many WorkerServers to use.""")修改前的代码是用于多GPU协同计算的,需要指定GPU的数量;
修改前的代码是用于多WorkerServer协同计算的,需要指定WorkerServer的数量;
124c125
< with tf.Graph().as_default(), tf.device('/cpu:0'):
---
> with tf.Graph().as_default(), tf.device('/job:ps/task:0/cpu:0'):修改前的单机CPU和修改后的ParamServer的0号CPU实际上负责同样的事情。
145,146c146,147
< for i in xrange(FLAGS.num_gpus):
< with tf.device('/gpu:%d' % i):
---
> for i in xrange(FLAGS.num_workers):
> with tf.device('/job:worker/task:%d/cpu:0' % i):修改前的单机各个GPU和修改后的各个WorkerServer的0号CPU实际上负责同样的事情。
190,192c191
< sess = tf.Session(config=tf.ConfigProto(
< allow_soft_placement=True,
< log_device_placement=FLAGS.log_device_placement))
---
> sess = tf.Session("grpc://%s:2222" % PS_NODE)取消allow_soft_placemet,禁止自动分配设备;
取消log_device_placement,不自动输出计算结果和设备分配情况;
指定会话的执行主体为ParamServer,端口号为2222,通信协议为grpc
4.运行结果对比
4.1单机版
root@localhost:~$ sudo docker run -it --name tf_paramserver --rm --cpuset-cpus 0 -h tf_paramserver -v ~/tensorflow-cluster-cifar-10-annotated:/tmp/tensorflow-cluster-cifar-10-annotated my_images/tensorflow /bin/bash
root@tf_paramserver:/notebooks# cd /tmp/tensorflow-cluster-cifar-10-annotated/
root@tf_paramserver:/notebooks# python cifar10_standalone_train.py
>> Downloading cifar-10-binary.tar.gz 100.0%
Successfully downloaded cifar-10-binary.tar.gz 170052171 bytes.
Filling queue with 20000 CIFAR images before starting to train. This will take a few minutes.
2017-10-10 14:43:30.635849: step 0, loss = 4.68 (12.8 examples/sec; 9.998 sec/batch)
2016-05-08 14:43:45.431379: step 10, loss = 4.66 (98.7 examples/sec; 1.297 sec/batch)
2016-05-08 14:43:58.407859: step 20, loss = 4.64 (98.5 examples/sec; 1.299 sec/batch)
2016-05-08 14:44:11.413918: step 30, loss = 4.62 (98.4 examples/sec; 1.301 sec/batch)
2016-05-08 14:44:24.434746: step 40, loss = 4.60 (98.3 examples/sec; 1.302 sec/batch)
2016-05-08 14:44:37.489811: step 50, loss = 4.59 (98.0 examples/sec; 1.306 sec/batch)单机版本大概每秒只能处理大约98张图片。
4.2集群版
启动ParamServer:
root@tf_paramserver:/notebooks# python
>>> import tensorflow as tf
cluster = tf.train.ClusterSpec({
"ps": [
"172.17.0.2:2222"
],
"worker": [
"172.17.0.3:2222",
"172.17.0.4:2222"
]})
server = tf.train.Server(cluster, job_name="ps", task_index=0)启动WorkerServer1:
root@tf_worker_1:/notebooks# python
>>> import tensorflow as tf
cluster = tf.train.ClusterSpec({
"ps": [
"172.17.0.2:2222"
],
"worker": [
"172.17.0.3:2222",
"172.17.0.4:2222"
]})
server = tf.train.Server(cluster, job_name="worker", task_index=0)启动WorkerServer2:
root@tf_worker_2:/notebooks# python
>>> import tensorflow as tf
cluster = tf.train.ClusterSpec({
"ps": [
"172.17.0.2:2222"
],
"worker": [
"172.17.0.3:2222",
"172.17.0.4:2222"
]})
server = tf.train.Server(cluster, job_name="worker", task_index=1)启动客户端:
root@localhost:~$ sudo docker run -it --name tf_client --rm --cpuset-cpus 0 -h tf_client -v ~/tensorflow-cluster-cifar-10-annotated:/tmp/tensorflow-cluster-cifar-10-annotated my_images/tensorflow /bin/bash
Filling queue with 20000 CIFAR images before starting to train. This will take a few minutes.
Filling queue with 20000 CIFAR images before starting to train. This will take a few minutes.
2017-10-10 20:21:33.712485: step 0, loss = 4.67 (11.7 examples/sec; 10.936 sec/batch)
2017-10-10 20:21:50.442159: step 10, loss = 4.65 (171.5 examples/sec; 0.746 sec/batch)
2017-10-10 20:22:04.883423: step 20, loss = 4.63 (172.6 examples/sec; 0.742 sec/batch)
2017-10-10 20:22:19.511816: step 30, loss = 4.62 (170.4 examples/sec; 0.751 sec/batch)
2017-10-10 20:22:33.988097: step 40, loss = 4.60 (170.8 examples/sec; 0.749 sec/batch)
2017-10-10 20:22:48.366351: step 50, loss = 4.58 (168.9 examples/sec; 0.758 sec/batch)性能明显提高了,现在每秒能处理大约170张图片,接近单机版本的两倍。

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)