
LangChain版Claude Skills实战教程(非常详细),智能体开发从入门到精通,收藏这一篇就够了!
对于大模型而言,其如何理解并使用工具,通常主要依赖以下三个方面:* **大模型自身在预训练阶段所获得的通用知识与能力*** **工具本身的描述信息**,例如工具的功能、参数及调用方式* **开发者编写的系统提示词与用户提示词**,用于引导模型的整体行为
简介
对于大模型而言,其如何理解并使用工具,通常主要依赖以下三个方面:
- 大模型自身在预训练阶段所获得的通用知识与能力
- 工具本身的描述信息,例如工具的功能、参数及调用方式
- 开发者编写的系统提示词与用户提示词,用于引导模型的整体行为
在一些通用任务场景下,上述三点往往已经能够满足需求。然而,当智能体需要完成专业性较强、流程较复杂或规则较多的任务时,仅依赖大模型自身的能力显然是不够的;而工具描述本身通常只关注“如何使用该工具”,对“如何完整、正确地完成一类任务”提供的指导也十分有限。
因此,在实际应用中,我们往往会将对整体任务目标、执行原则以及流程约束的说明写入系统提示词中,以此来引导智能体的行为。
但随着任务复杂度的不断提升,这种做法会逐渐暴露出明显的问题。那就是系统提示词会变得越来越长、越来越复杂,不仅增加了上下文开销,也会使模型在推理过程中难以抓住重点,反而更容易出现理解偏差和幻觉,从而错误地执行任务。
为了解决这一问题,我们可以换一种思路——不再将所有任务规则一次性写入系统提示词,而是将复杂任务进行拆分。
具体来说,我们可以先将一个复杂任务拆分为若干相对独立、职责清晰的子任务,并分别为这些子任务设计对应的执行流程、规则说明和注意事项。随后,我们将这些“针对某一类任务的完整执行说明”封装为一个个技能(Skill)。
在系统提示词中,我们只需要简要地列出当前智能体可用的技能及其功能概述。当智能体接收到用户请求后,只有在判断该请求与某个 Skill 相关时,才会按需加载该 Skill 的详细内容;若暂时无关,则保持其不被使用,从而避免不必要的上下文占用。通过这种方式,我们可以在显著降低上下文复杂度与长度的同时,依然为智能体提供足够专业、结构化的任务指导,从而提升系统的稳定性与执行准确性。
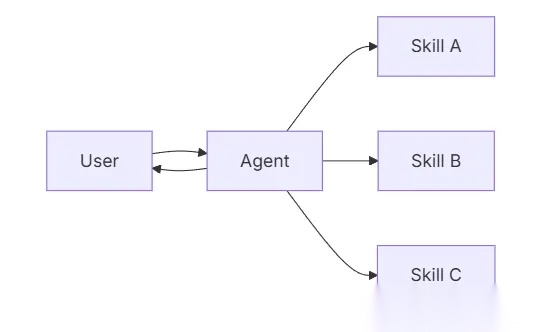
从本质上来看,这种将信息按需加载、逐步暴露的设计思路,正是当前大模型应用中所强调的上下文工程(Context Engineering)的重要组成部分。其核心目标并不是“提供尽可能多的信息”,而是在合适的时间,向模型提供恰当且必要的信息。这一思想最早由 Anthropic 在 Claude Code 中系统性地提出,并以 Skill 的形式加以实践。将复杂的任务知识与执行规范封装为可独立加载的技能模块,由模型在推理过程中自主选择和使用。
从我个人的理解来看,Skills 其实更像是让智能体变得专业化的重要路径,以往在没有 skills 的情况下,一个智能体使用工具,通常是这样被引导的:
- system prompt 里写:
- 什么时候该用工具
- 先用哪个工具
- 用完工具后要注意什么
- tool 描述里写:
- 参数
- 返回值
- 用法示例
结果是工具“怎么用”是清楚的,但在什么业务语境下、按什么流程去用”是模糊的。而 skills 正好补的是这一层。其主要关注的是在完成某一类任务时,工具应该如何被组合、约束和使用。
skills 通常包含的内容你已经见过了:
- 任务目标(比如“写一条符合业务规则的 SQL”)
- 业务约束(哪些状态有效,哪些要排除)
- 使用工具的原则(什么时候该查 schema,什么时候不该)
- 示例(“正确的工具使用范式”)
所以我们就可以把 Skill 当作是对工具的“调度说明书”,用一个更高的维度指导智能体完成特定的任务。
那下面我们就来基于 LangChain 来尝试复现一下 Skills 的使用吧!
前期准备
环境准备
我们需要安装配套的库来进行任务的完成:
pip install langchain langchain-community dashscope langgraph
密钥准备
然后我们还需要获取百炼大模型的 api_key 来进行 qwen 大模型的调用:
os.environ["DASHSCOPE_API_KEY"] = "sk-YOUR-API-KEY"
代码准备
然后我们需要测试一下是否能够调用大模型:
from langchain_community.chat_models import ChatTongyiimport osmodel = ChatTongyi(api_key=os.environ.get("DASHSCOPE_API_KEY"), model="qwen-turbo")
准备好以上内容后我们就可以正式开始进行代码的实战了!
代码实战
任务简介
在下面的任务中,我希望做的是一个 SQL 助手智能体,用来帮助在大型企业中编写跨不同业务垂直领域的 SQL 查询。在这样的企业环境里,可能存在以下两种情况之一:
- 每个业务垂直领域(vertical)都有各自独立的数据存储系统;
- 或者整个企业使用的是一个单体数据库,其中包含成千上万张表。
但它和“直接把所有数据库 schema 塞进系统提示词”不一样,Skills 用的是 Progressive Disclosure(渐进披露/按需加载上下文) 的思路:
- 智能体一开始只知道“有哪些技能(skills)”,每个技能只有一句话描述(很轻量)。
- 当用户的问题涉及某个业务域(比如销售分析、库存管理),智能体会通过 工具调用(tool call) 去加载对应技能的完整内容(包括 schema、业务规则、示例 SQL)。
- 加载后再写 SQL,这样就避免了:一开始把成千上万张表、规则都塞进上下文导致爆窗、幻觉、成本高。
因此我们需要制作以下四个核心组件:
- 根据任务内容创建 Skill
- **制造 load_skill 工具:**输入 skill_name,返回对应 skill 的
content(拼上“Loaded skill: …”)。 - **SkillMiddleware(关键点):**它做一件事:在每次模型调用前,把“技能目录”追加到 system prompt,让模型知道“我现在有哪些技能可用”。
- **Agent:**用
create_agent(...)把模型 + system_prompt + middleware + checkpointer 组起来。
创建 Skill
首先我们需要先定义 Skill 的格式,这里我们将 Skill 拆分成 name,description 和 content 三部分内容。这里的 name 和 description 就是名称和一句话的描述,这两部分就会放到系统提示词里让智能体像选择工具一样进行选用。而 content 就是当智能体决定调用工具来获取到具体内容信息,这部分信息就会在调用后以工具结果的形式展示在上下文中:
from typing import TypedDictclass Skill(TypedDict): """A skill that can be progressively disclosed to the agent.""" name: str description: str content: str
在设置好了格式后,我们就可以来定义 Skills 了:
SKILLS: list[Skill] = [ { "name": "sales_analytics", "description": "Database schema and business logic for sales data analysis including customers, orders, and revenue.", "content": """# Sales Analytics Schema## Tables### customers- customer_id (PRIMARY KEY)- name- email- signup_date- status (active/inactive)- customer_tier (bronze/silver/gold/platinum)### orders- order_id (PRIMARY KEY)- customer_id (FOREIGN KEY -> customers)- order_date- status (pending/completed/cancelled/refunded)- total_amount- sales_region (north/south/east/west)### order_items- item_id (PRIMARY KEY)- order_id (FOREIGN KEY -> orders)- product_id- quantity- unit_price- discount_percent## Business Logic**Active customers**: status = 'active' AND signup_date <= CURRENT_DATE - INTERVAL '90 days'**Revenue calculation**: Only count orders with status = 'completed'. Use total_amount from orders table, which already accounts for discounts.**Customer lifetime value (CLV)**: Sum of all completed order amounts for a customer.**High-value orders**: Orders with total_amount > 1000## Example Query-- Get top 10 customers by revenue in the last quarterSELECT c.customer_id, c.name, c.customer_tier, SUM(o.total_amount) as total_revenueFROM customers cJOIN orders o ON c.customer_id = o.customer_idWHERE o.status = 'completed' AND o.order_date >= CURRENT_DATE - INTERVAL '3 months'GROUP BY c.customer_id, c.name, c.customer_tierORDER BY total_revenue DESCLIMIT 10;""", }, { "name": "inventory_management", "description": "Database schema and business logic for inventory tracking including products, warehouses, and stock levels.", "content": """# Inventory Management Schema## Tables### products- product_id (PRIMARY KEY)- product_name- sku- category- unit_cost- reorder_point (minimum stock level before reordering)- discontinued (boolean)### warehouses- warehouse_id (PRIMARY KEY)- warehouse_name- location- capacity### inventory- inventory_id (PRIMARY KEY)- product_id (FOREIGN KEY -> products)- warehouse_id (FOREIGN KEY -> warehouses)- quantity_on_hand- last_updated### stock_movements- movement_id (PRIMARY KEY)- product_id (FOREIGN KEY -> products)- warehouse_id (FOREIGN KEY -> warehouses)- movement_type (inbound/outbound/transfer/adjustment)- quantity (positive for inbound, negative for outbound)- movement_date- reference_number## Business Logic**Available stock**: quantity_on_hand from inventory table where quantity_on_hand > 0**Products needing reorder**: Products where total quantity_on_hand across all warehouses is less than or equal to the product's reorder_point**Active products only**: Exclude products where discontinued = true unless specifically analyzing discontinued items**Stock valuation**: quantity_on_hand * unit_cost for each product## Example Query-- Find products below reorder point across all warehousesSELECT p.product_id, p.product_name, p.reorder_point, SUM(i.quantity_on_hand) as total_stock, p.unit_cost, (p.reorder_point - SUM(i.quantity_on_hand)) as units_to_reorderFROM products pJOIN inventory i ON p.product_id = i.product_idWHERE p.discontinued = falseGROUP BY p.product_id, p.product_name, p.reorder_point, p.unit_costHAVING SUM(i.quantity_on_hand) <= p.reorder_pointORDER BY units_to_reorder DESC;""", },]
这里总共有两个 skill,一个是 sales_analytics,用于销售数据分析的数据库结构与业务逻辑,包括客户、订单和收入相关内容。另一个是 inventory_management,用于库存管理的数据库结构与业务逻辑,包括商品、仓库和库存数量。
这两个里面都是介绍对应数据库表的结构信息(Tables),然后介绍完表信息后也会介绍一下具体的**业务规则(Business Logic)是如何的,最后还会给出一些查询的示例信息(Example Query)**来让其能够对该任务有更深入的理解。
在之前我们在讲 SQL Agent 的时候都是给出一些 SQL 工具让工具自己来查这些个数据库里的表结构,而现在我们直接在 Skills 里给出的话明显效率会高很多。当然两者还是要结合着来使用的,因为最后执行的话还是要靠 SQLDatabaseToolkit 来实现查询的。
创建 skill 载入工具
在创建完 skill 以后,我们还需要设置一个工具让智能体能够在合适的时候获取合适的 skill 以及内部对应的 content 内容:
from langchain.tools import tool@tooldef load_skill(skill_name: str) -> str: """将某个技能(skill)的完整内容加载到智能体的上下文中。 当你需要了解如何处理某一类特定请求的详细信息时,请使用该工具。 该工具会为你提供该技能领域内的完整说明、策略规则以及操作指导。 参数说明: skill_name:要加载的技能名称 (例如:"expense_reporting"、"travel_booking") """ # 查找并返回请求的技能内容 for skill in SKILLS: if skill["name"] == skill_name: returnf"已加载技能:{skill_name}\n\n{skill['content']}" # 未找到对应技能 available = ", ".join(s["name"] for s in SKILLS) returnf"未找到技能 '{skill_name}'。可用技能包括:{available}"
所以这里传入的就是可能的 skill 名称,然后先看看里面有没有,有的话就将对应的 content 内容进行返回。假如没有找到的话,那就把有的 skills 名称都提取出来,然后返回说没有找到制定的技能,然后我们有的技能是什么。
构建 skill 中间件
设置完工具以后,我们还需要设置对应的中间件来动态更新系统提示词的内容:
from langchain.agents.middleware import ModelRequest, ModelResponse, AgentMiddlewarefrom langchain.messages import SystemMessagefrom typing import Callableclass SkillMiddleware(AgentMiddleware): """一个用于将技能(skill)描述注入到系统提示词(system prompt)中的中间件。""" # 将 load_skill 工具注册为该中间件可用的工具 tools = [load_skill] def __init__(self): """初始化中间件,并基于 SKILLS 生成技能说明提示内容。""" # 从 SKILLS 列表中构建技能说明文本 skills_list = [] for skill in SKILLS: skills_list.append( f"- **{skill['name']}**:{skill['description']}" ) # 将所有技能说明拼接成一段文本 self.skills_prompt = "\n".join(skills_list) def wrap_model_call( self, request: ModelRequest, handler: Callable[[ModelRequest], ModelResponse], ) -> ModelResponse: """同步执行:在模型调用前,将技能描述注入到 system prompt 中。""" # 构建技能说明的补充内容 skills_addendum = ( f"\n\n## 可用技能(Available Skills)\n\n{self.skills_prompt}\n\n" "当你需要处理某一类具体请求的详细信息时," "请使用 load_skill 工具来加载对应技能的完整内容。" ) # 将技能说明追加到系统消息的内容块中 new_content = list(request.system_message.content_blocks) + [ {"type": "text", "text": skills_addendum} ] # 构造新的系统消息 new_system_message = SystemMessage(content=new_content) # 用新的 system message 覆盖原有请求中的 system message modified_request = request.override(system_message=new_system_message) # 将修改后的请求继续交给下一个处理器(模型)执行 return handler(modified_request)
- 这里我们首先将 load_skill 作为全局变量载入到该中间件中,因此每次当模型发出指令时,其都能够看见这一个工具的存在。假如我们放到 agent 的 tools 参数里面,反而有可能被其他一些中间件给影响,所以这里就选择放在了中间件的类里面,保证其能够正常运行。
- 接下来我们设置了一些初始化的信息,比如通过解包的方式将 skills 的名称和描述提取出来放到 skills_list 里,并且将 skills_list 的内容组合起来形成 skills_prompt 信息。
- 然后将 skills_prompt 信息与一些提示词进行组合,形成 skills_addendum 说明信息。最后将这部分信息添加到系统提示词的最后,并且通过 .override 的方式进行更新。更新完后再用 handler 对最新的 modified_request 进行调用。
所以总的来说,这个中间件本质上就是在把 Skills 里的 name 和 description 提取出来并且放入到系统提示词中,从而让智能体知道有哪些 Skills 以及如何进行使用它们。
创建并调用智能体
当我们将Skills、工具、中间件都打造好以后,我们就可以来将其组合在一起了,这里我们就还需要写入短期记忆内容 InMemorySaver() 和一段简短的系统提示词即可:
from langchain.agents import create_agentfrom langgraph.checkpoint.memory import InMemorySaver# 创建一个支持技能(skill)机制的智能体agent = create_agent( model, system_prompt=( "你是一个 SQL 查询助手," "负责帮助用户针对企业级业务数据库编写 SQL 查询。" ), middleware=[SkillMiddleware()], checkpointer=InMemorySaver(),)
此时我们就可以对该智能体进行调用了,首先我们还是要先创建一个线程 ID:
import uuid# 为当前这次对话生成一个唯一的线程 IDthread_id = str(uuid.uuid4())# 构造本次调用的配置参数# configurable.thread_id 用于让 agent / checkpointer# 识别并区分不同的对话线程config = {"configurable": {"thread_id": thread_id}}
然后我们就可以发出一个查询的请求,了解一下一个月内超过 1000 美元订单的客户有哪些:
# 向智能体提出一个 SQL 查询请求result = agent.invoke( { "messages": [ { "role": "user", "content": ( "请编写一条 SQL 查询,用于找出在最近一个月内," "下过金额超过 1000 美元订单的所有客户" ), } ] }, config)
最后遍历本次调用中产生的所有消息,包括:
- 用户消息(Human Message)
- 模型消息(AI Message)
- 工具调用消息(Tool Message)
如果消息对象支持 pretty_print():
- 使用 LangChain 提供的格式化输出(更清晰)
否则:
- 以「消息类型 + 内容」的方式直接打印
# 打印整个对话过程中的所有消息for message in result["messages"]: if hasattr(message, 'pretty_print'): message.pretty_print() else: print(f"{message.type}: {message.content}")
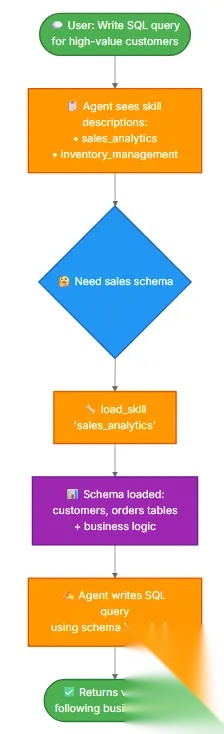
可以看到当我们提问了问题以后,模型第一时间发出了 skills 调用的请求,然后将对应的 content 进行了返回。模型在阅读完 skills 内容后就给出了 SQL 调用的代码。可以看出这种方式其实是非常高效且有用的!
================================[1m Human Message [0m=================================请编写一条 SQL 查询,用于找出在最近一个月内,下过金额超过 1000 美元订单的所有客户==================================[1m Ai Message [0m==================================Tool Calls: load_skill (call_b7c5415bd69841eea6f4bc) Call ID: call_b7c5415bd69841eea6f4bc Args: skill_name: sales_analytics=================================[1m Tool Message [0m=================================Name: load_skill已加载技能:sales_analytics# Sales Analytics Schema## Tables### customers- customer_id (PRIMARY KEY)- name- email- signup_date- status (active/inactive)- customer_tier (bronze/silver/gold/platinum)### orders- order_id (PRIMARY KEY)- customer_id (FOREIGN KEY -> customers)- order_date- status (pending/completed/cancelled/refunded)- total_amount- sales_region (north/south/east/west)### order_items- item_id (PRIMARY KEY)- order_id (FOREIGN KEY -> orders)- product_id- quantity- unit_price- discount_percent## Business Logic**Active customers**: status = 'active' AND signup_date <= CURRENT_DATE - INTERVAL '90 days'**Revenue calculation**: Only count orders with status = 'completed'. Use total_amount from orders table, which already accounts for discounts.**Customer lifetime value (CLV)**: Sum of all completed order amounts for a customer.**High-value orders**: Orders with total_amount > 1000## Example Query-- Get top 10 customers by revenue in the last quarterSELECT c.customer_id, c.name, c.customer_tier, SUM(o.total_amount) as total_revenueFROM customers cJOIN orders o ON c.customer_id = o.customer_idWHERE o.status = 'completed' AND o.order_date >= CURRENT_DATE - INTERVAL '3 months'GROUP BY c.customer_id, c.name, c.customer_tierORDER BY total_revenue DESCLIMIT 10;==================================[1m Ai Message [0m==================================以下是用于查找在最近一个月内下过金额超过 1000 美元订单的所有客户的 SQL 查询: ```sql SELECT DISTINCT c.customer_id, c.name, c.email, c.signup_date, c.status, c.customer_tier FROM customers c JOIN orders o ON c.customer_id = o.customer_id WHERE o.status = 'completed' AND o.total_amount > 1000 AND o.order_date >= CURRENT_DATE - INTERVAL '1 month'; ```### 说明:- `DISTINCT`:确保每个客户只出现一次,即使他们有多个符合条件的订单。- `JOIN orders o ON c.customer_id = o.customer_id`:将客户表和订单表连接起来。- `o.status = 'completed'`:只考虑完成的订单。- `o.total_amount > 1000`:筛选出金额超过 1000 美元的订单。- `o.order_date >= CURRENT_DATE - INTERVAL '1 month'`:筛选出最近一个月内的订单。如果你需要进一步筛选或扩展这个查询,请告诉我!
进阶应用
在前面的版本里,其实存在一个隐患:
❗ 模型理论上可以:
- 还没加载
sales_analytics- 就开始写 sales 的 SQL
- 或者乱用 schema
也就是说:
- 我们只是“引导”模型
- 但没有强制约束
而这一节做的事是:
把“先加载 skill → 再使用相关工具” 从一种提示习惯,升级为系统级规则
添加 AgentState 确保查询时已加载 Skills
本质上来说,我们这里要做的就是把“已加载了哪些 skills”记录到 agent 的 state 里,然后让后续工具基于 state 决定“能不能用”。首先我们先定义一个 AgentState 的字段 skills_loaded,用列表的形式将已经载入的 Skills 进行记录:
from langchain.agents.middleware import AgentStatefrom typing import NotRequiredclass CustomState(AgentState): skills_loaded: NotRequired[list[str]]
这个 AgentState 在前面自定义中间件时已经进行了讲解,本质上就是在智能体流动过程中不断改变的状态信息。我们可以在中间件、工具等地方进行获取并对其进行修改。
更新 load_skill 工具以修改 state 信息
有了这个 state 信息后,那我们还需要更新一下 load_skill 工具,使其能够在获取完 skills 里的内容后顺便把 skill_loaded 信息通过 Command 进行更新:
from langgraph.types import Commandfrom langchain.tools import tool, ToolRuntimefrom langchain.messages import ToolMessage@tooldef load_skill(skill_name: str, runtime: ToolRuntime) -> Command: """ 将指定技能(skill)的完整内容加载到智能体的上下文中。 当需要处理某一类特定请求、并且必须了解该业务领域的 详细说明、业务规则或操作规范时,使用此工具。 参数: skill_name:要加载的技能名称 """ # 查找并返回对应的技能 for skill in SKILLS: if skill["name"] == skill_name: skill_content = f"已加载技能:{skill_name}\n\n{skill['content']}" # 更新系统状态,用于记录已加载的技能 return Command( update={ "messages": [ ToolMessage( content=skill_content, tool_call_id=runtime.tool_call_id, ) ], # 在 agent 的 state 中记录已加载的技能名称 "skills_loaded": [skill_name], } ) # 未找到对应技能 available = ", ".join(s["name"] for s in SKILLS) return Command( update={ "messages": [ ToolMessage( content=f"未找到技能“{skill_name}”。可用技能包括:{available}", tool_call_id=runtime.tool_call_id, ) ] } )
假如能够找到对应的 skill 的话,那就通过 update 的方法将 skills_load 的信息进行更新。假如没找到的话也还是通过 Command 将未找到的信息进行传回。
创建业务检验工具
那拥有了 state 以后,我们也可以更进一步去实现只有在“对应 skill 已加载”的前提下,才能查询对应业务领域的内容。这里我们定义了一个 write_sql_query 的工具来进行实现:
from langchain.tools import tool, ToolRuntime@tooldef write_sql_query( query: str, vertical: str, runtime: ToolRuntime,) -> str: """ 为指定的业务领域编写并校验一条 SQL 查询。 该工具用于对 SQL 查询进行格式化与校验。 在使用该工具之前,必须先加载对应的 skill, 以确保已经理解该业务领域的数据库结构(schema)。 参数说明: query:要编写/校验的 SQL 查询语句 vertical:业务领域名称(sales_analytics 或 inventory_management) """ # 从运行时状态中读取已经加载过的技能列表 skills_loaded = runtime.state.get("skills_loaded", []) # 如果所需的业务领域 skill 尚未加载,则返回错误提示 if vertical notin skills_loaded: return ( f"错误:在编写 SQL 查询之前,必须先加载 '{vertical}' 技能," f"以便理解对应的数据库结构。" f"请先使用 load_skill('{vertical}') 来加载该 schema。" ) # 校验并格式化 SQL 查询(此处为示例实现) return ( f"{vertical} 业务领域的 SQL 查询如下:\n\n" f"```sql\n{query}\n```\n\n" f"✓ 查询已通过 {vertical} schema 校验\n" f"可以安全地在数据库中执行。" )
这里首先我们就是从 runtime.state 中获取 skills_loaded 信息,假如找不到就是空列表。找到以后呢就检查一下业务领域 vertical 是否存在于 skills_loaded 中。假如不存在的话就返回错误信息。假如存在就通过校验。
更新中间件和 agent
接下来有了这个 state 和新的 write_sql_query 工具后,我们还需要将其加载到中间件 SkillMiddleware 中(其他地方都没变):
from langchain.agents.middleware import ModelRequest, ModelResponse, AgentMiddlewarefrom langchain.messages import SystemMessagefrom typing import Callableclass SkillMiddleware(AgentMiddleware): """一个用于将技能(skill)描述注入到系统提示词(system prompt)中的中间件。""" **state_schema = CustomState tools = [load_skill, write_sql_query]** def __init__(self): """初始化中间件,并基于 SKILLS 生成技能说明提示内容。""" # 从 SKILLS 列表中构建技能说明文本 skills_list = [] for skill in SKILLS: skills_list.append( f"- **{skill['name']}**:{skill['description']}" ) # 将所有技能说明拼接成一段文本 self.skills_prompt = "\n".join(skills_list) def wrap_model_call( self, request: ModelRequest, handler: Callable[[ModelRequest], ModelResponse], ) -> ModelResponse: """同步执行:在模型调用前,将技能描述注入到 system prompt 中。""" # 构建技能说明的补充内容 skills_addendum = ( f"\n\n## 可用技能(Available Skills)\n\n{self.skills_prompt}\n\n" "当你需要处理某一类具体请求的详细信息时," "请使用 load_skill 工具来加载对应技能的完整内容。" ) # 将技能说明追加到系统消息的内容块中 new_content = list(request.system_message.content_blocks) + [ {"type": "text", "text": skills_addendum} ] # 构造新的系统消息 new_system_message = SystemMessage(content=new_content) # 用新的 system message 覆盖原有请求中的 system message modified_request = request.override(system_message=new_system_message) # 将修改后的请求继续交给下一个处理器(模型)执行 return handler(modified_request)
然后我们就能够再次构建 agent 并进行调用:
from langchain.agents import create_agentfrom langgraph.checkpoint.memory import InMemorySaver# 创建一个支持技能(skill)机制的智能体agent = create_agent( model, system_prompt=( "你是一个 SQL 查询助手," "负责帮助用户针对企业级业务数据库编写 SQL 查询。" ), middleware=[SkillMiddleware()], checkpointer=InMemorySaver(),)
此时返回的结果为就不再是前面简单的查询了,而是加上了一步检验的过程,从而确保是已经加载 Skills 后才能进行搜索结果的产出:
================================[1m Human Message [0m=================================请编写一条 SQL 查询,用于找出在最近一个月内,下过金额超过 1000 美元订单的所有客户==================================[1m Ai Message [0m==================================Tool Calls: load_skill (call_ff0c133db2994271a61b4d) Call ID: call_ff0c133db2994271a61b4d Args: skill_name: sales_analytics=================================[1m Tool Message [0m=================================Name: load_skill已加载技能:sales_analytics# Sales Analytics Schema## Tables### customers- customer_id (PRIMARY KEY)- name- email- signup_date- status (active/inactive)- customer_tier (bronze/silver/gold/platinum)### orders- order_id (PRIMARY KEY)- customer_id (FOREIGN KEY -> customers)- order_date- status (pending/completed/cancelled/refunded)- total_amount- sales_region (north/south/east/west)### order_items- item_id (PRIMARY KEY)- order_id (FOREIGN KEY -> orders)- product_id- quantity- unit_price- discount_percent## Business Logic**Active customers**: status = 'active' AND signup_date <= CURRENT_DATE - INTERVAL '90 days'**Revenue calculation**: Only count orders with status = 'completed'. Use total_amount from orders table, which already accounts for discounts.**Customer lifetime value (CLV)**: Sum of all completed order amounts for a customer.**High-value orders**: Orders with total_amount > 1000## Example Query-- Get top 10 customers by revenue in the last quarterSELECT c.customer_id, c.name, c.customer_tier, SUM(o.total_amount) as total_revenueFROM customers cJOIN orders o ON c.customer_id = o.customer_idWHERE o.status = 'completed' AND o.order_date >= CURRENT_DATE - INTERVAL '3 months'GROUP BY c.customer_id, c.name, c.customer_tierORDER BY total_revenue DESCLIMIT 10;==================================[1m Ai Message [0m==================================Tool Calls: write_sql_query (call_440d901500244c668fe219) Call ID: call_440d901500244c668fe219 Args: query: SELECT DISTINCT c.customer_id, c.name FROM customers c JOIN orders o ON c.customer_id = o.customer_id WHERE o.status = 'completed' AND o.order_date >= CURRENT_DATE - INTERVAL '1 month' AND o.total_amount > 1000; vertical: sales_analytics=================================[1m Tool Message [0m=================================Name: write_sql_querysales_analytics 业务领域的 SQL 查询如下:sqlSELECT DISTINCT c.customer_id, c.name FROM customers c JOIN orders o ON c.customer_id = o.customer_id WHERE o.status = 'completed' AND o.order_date >= CURRENT_DATE - INTERVAL '1 month' AND o.total_amount > 1000;✓ 查询已通过 sales_analytics schema 校验可以安全地在数据库中执行。==================================[1m Ai Message [0m==================================以下是针对最近一个月内下过金额超过 1000 美元订单的所有客户的 SQL 查询:```sqlSELECT DISTINCT c.customer_id, c.name FROM customers c JOIN orders o ON c.customer_id = o.customer_id WHERE o.status = 'completed' AND o.order_date >= CURRENT_DATE - INTERVAL '1 month' AND o.total_amount > 1000;
此查询将返回满足条件的客户 ID 和姓名。如果需要进一步分析这些客户,可以在此基础上扩展查询。
实现方式的变体
本教程中,将 skills(技能) 实现为内存中的 Python 字典,并通过工具调用的方式按需加载。不过,实际上还有多种方式可以实现基于 skills 的渐进式披露(progressive disclosure)机制。
Skills 的存储方式(Storage backends)
- 内存方式(本教程采用)
- 将 skills 定义为 Python 数据结构
- 访问速度快
- 没有 I/O 开销
- 但更新技能内容需要重新部署代码
- 文件系统方式(Claude Code 的做法)
- 将 skills 组织为目录和文件
- 通过文件操作(如
read_file)进行发现和加载 - 适合技能内容频繁变更的场景
- 远程存储方式
- 将 skills 存储在 S3、数据库、Notion 或 API 中
- 在需要时按需拉取
- 适合大规模、多团队协作的企业级系统
Skills 发现机制(Agent 是如何知道有哪些 skills 存在的)
- 系统提示词列举(本教程采用)
- 在 system prompt 中列出所有技能的简要描述
- 实现简单、直观
- 基于文件的发现
- 通过扫描目录结构来发现可用技能
- Claude Code 采用的方式
- 注册中心方式(Registry-based)
- 通过技能注册服务或 API 查询可用技能列表
- 适合分布式系统
- 动态查询方式
- 通过工具调用,动态返回当前可用的技能列表
渐进式披露策略(技能内容是如何被加载的)
- 一次性加载(Single load)
- 通过一次工具调用加载整个 skill 内容
- 本教程采用的方式
- 实现简单,适合中小规模技能
- 分页加载(Paginated)
- 将技能内容拆分成多个页面或片段
- 适合内容较大的技能
- 基于搜索的加载(Search-based)
- 在技能内容中按需搜索相关部分
- 例如对技能文件使用
grep/read操作 - 避免加载无关内容
- 分层加载(Hierarchical)
- 先加载技能概览
- 再逐步深入加载具体子模块或子章节
Skills 规模的经验性划分(非严格标准)
- 小型技能
- 少于 1K tokens(约 750 字)
- 可直接放入 system prompt
- 可结合 prompt caching 提升响应速度、降低成本
- 中型技能
- 1K–10K tokens(约 750–7500 字)
- 适合按需加载(本教程的典型场景)
- 能显著减少上下文占用
- 大型技能
- 超过 10K tokens
- 或占用上下文窗口的 5%–10% 以上
- 必须采用分页、搜索或分层加载等渐进式披露策略
- 否则会严重挤占上下文空间
实现选择的权衡总结
- 内存方式:
- 速度最快
- 实现最简单
- 但技能更新需要重新部署
- 文件或远程存储方式:
- 技能可动态更新
- 无需改代码
- 但会带来 I/O 或网络延迟
最终选择取决于你对性能、灵活性、维护成本的需求。
总结
总的来说,本文围绕复杂专业任务中大模型上下文失控的问题,引入并系统讲解了 Skills + Progressive Disclosure(渐进式披露) 的设计思想。核心在于不再将所有业务规则、流程约束和知识一次性写入 system prompt,而是将其拆分为职责清晰、可独立加载的技能模块。智能体在初始阶段仅感知“有哪些技能可用”,只有在任务真正涉及某一业务领域时,才通过工具调用按需加载对应 Skill 的完整内容,从而在显著降低上下文长度与复杂度的同时,依然保持对专业任务的充分理解与执行能力。这本质上体现了上下文工程“在合适的时间提供恰当信息”的核心原则。
在具体实现上,文章基于 LangChain 复现了 Skills 的完整工程形态:通过定义 Skill 结构、构建 load_skill 工具、利用 Middleware 将技能目录动态注入 system prompt,并结合 AgentState 记录已加载技能,从而实现对智能体行为的系统级约束。相比单纯依赖提示词引导的方式,这种设计将“先加载知识、再执行任务”的隐性约定,升级为可被程序强制执行的规则,使智能体的行为更加稳定、可控且可调试,也为后续引入校验、审计和复杂流程控制奠定了基础。
从更高层次看,Skills 并不仅是 SQL 场景下的技巧,而是一种可泛化的上下文工程范式,适用于多业务域、多团队协作和大规模知识体系下的智能体系统。无论是采用内存、文件系统还是远程存储来管理技能内容,或进一步结合 few-shot 示例加载、搜索式披露、多智能体协作等模式,Skills 都可以作为“任务级知识与执行规范的封装单元”,帮助大模型应用从“能回答问题”走向“可工程化、可扩展、可长期维护的智能系统”。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 10
10 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)