
小白从零开始勇闯人工智能:机器学习初级篇(pandas库)
在上一篇文章中,我们学习了Python科学计算的核心库Numpy,在本章中我们将学习机器学习中负责数据处理和分析的Pandas库。Pandas是一个用Python编写的数据分析库,可以轻松处理数百万行数据,是AI工程师最常用的工具。
引言
在上一篇文章中,我们学习了Python科学计算的核心库Numpy,在本章中我们将学习机器学习中负责数据处理和分析的Pandas库。Pandas是一个用Python编写的数据分析库,可以轻松处理数百万行数据,是AI工程师最常用的工具。
一、Pandas基础数据类型
1、Series:一维数据的"智能列表"
Pandas Series是一个带有索引的一维数据结构。它可以通过 pd.Series() 创建,既支持默认的数字索引,也允许自定义标签索引。Series 具有 index、values、dtype、shape 等关键属性,并可通过 describe() 获取统计摘要,或使用 head()、tail() 查看数据片段。在操作上,它支持通过标签或位置访问元素,可方便地通过条件筛选数据,并允许直接修改或添加新值。
1)、基本创建
mport pandas as pd
#1、基本创建
# 创建第一个Series
s1 = pd.Series([1, 2, 3, 4, 5])
print(s1)
print(f"类型:{type(s1)}")
print(f"形状:{s1.shape}")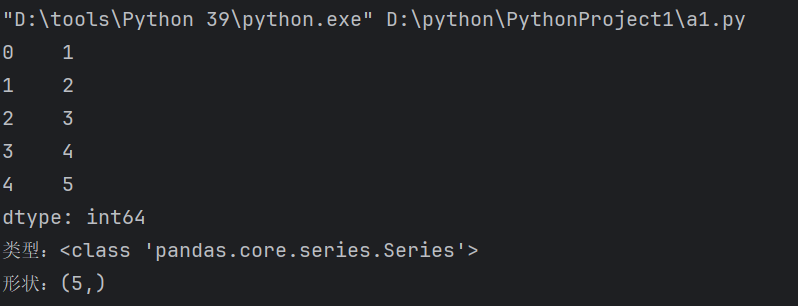
2)、自定义索引
#2、自定义索引
# 创建带自定义索引的Series(就像给数据贴标签)
s2 = pd.Series([1, 2, 3],
index=['小王', '小红', '小李'])
print("\n带自定义索引的Series:")
print(s2)
# 创建字符串类型的Series
s3 = pd.Series(['xaiowang', 'xiaohong', 'xiaoli'])
print("\n字符串Series:")
print(s3)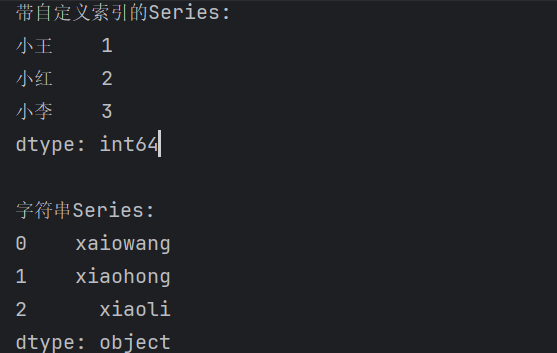
3)、Series的属性
#3、Series的属性
# 查看Series的各种属性
# 查看索引
print(f"s1的索引:{s1.index}")
print(f"s2的索引:{s2.index}")
# 查看值
print(f"s1的值:{s1.values}")
print(f"s2的值:{s2.values}")
# 查看数据类型
print(f"s1的数据类型:{s1.dtype}")
print(f"s3的数据类型:{s3.dtype}")
# 查看大小
print(f"s1的长度:{len(s1)}")
print(f"s1的形状:{s1.shape}")
# 查看统计信息
print(f"s1的描述统计:")
print(s1.describe())
# 查看前几个/后几个值
print(f"s1的前3个值:")
print(s1.head(3))
print(f"s1的后2个值:")
print(s1.tail(2))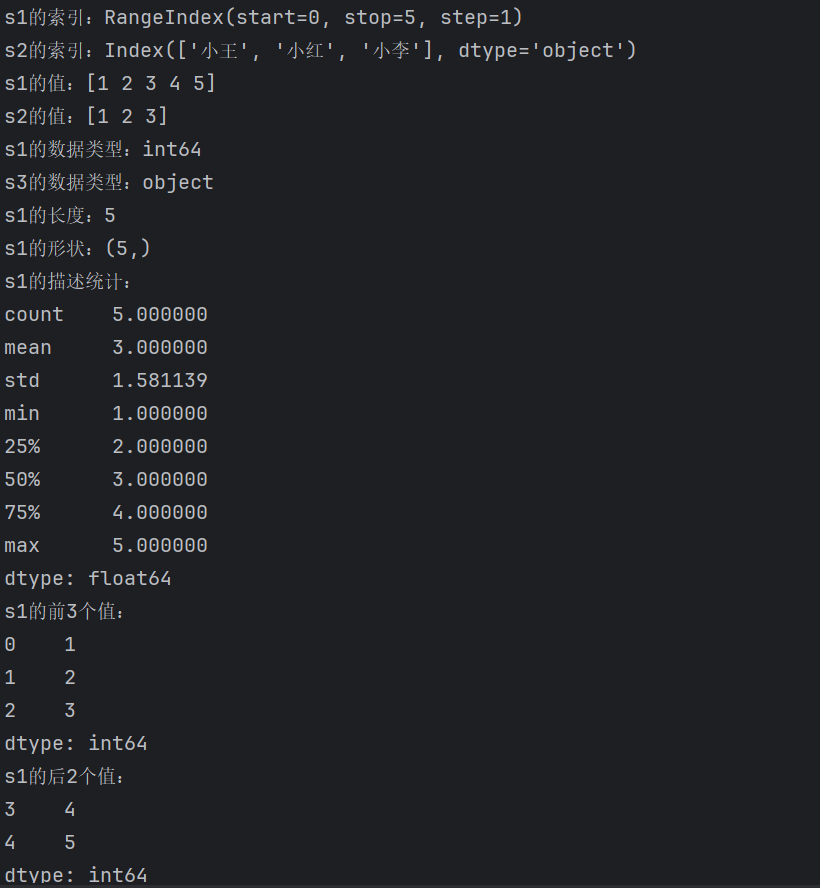
2、DataFrame:二维数据的"智能表格"
Pandas DataFrame是一个二维的、带行列标签的表格型数据结构。它通常通过字典创建,其中键为列名,值为列数据,并可自定义行索引(index 参数)。DataFrame 具有 index(行索引)、columns(列名)、values(底层 NumPy 数组)、shape(形状)、dtypes(各列数据类型)等核心属性,并可通过 describe() 获取统计摘要、info() 查看基本信息、head()/tail() 浏览数据片段。在数据访问上,可以通过列名直接获取单列(df['列名'] 或 df.列名),通过列表获取多列(df[['列1','列2']]),通过切片获取连续行(df[0:2]),以及使用 loc(基于标签)和 iloc(基于位置)精确访问行列交叉点的数据。
1)基本创建
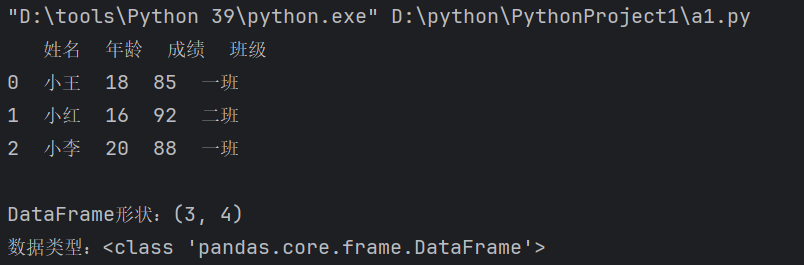
#1、基本创建
import pandas as pd
# 创建第一个DataFrame(学生信息表)
df1 = pd.DataFrame({
'姓名': ['小王', '小红', '小李'],
'年龄': [18, 16, 20],
'成绩': [85, 92, 88],
'班级': ['一班', '二班', '一班']
})
print(df1)
print(f"\nDataFrame形状:{df1.shape}")
print(f"数据类型:{type(df1)}")
2)、自定义索引
#2、自定义索引
# 创建带自定义行索引的DataFrame
df2 = pd.DataFrame({
'年龄': [18, 23, 22],
'姓名': ['小明', '小崔', '小刚'],
'收入': [100, 200, 300]
}, index=['学生1', '学生2', '学生3'])
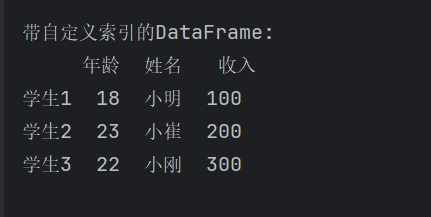
print("\n带自定义索引的DataFrame:")
print(df2)
3)、DataFrame的属性
#3、DataFrame的属性
# 查看行索引
print(f"行索引:{df1.index}")
print(f"行索引类型:{type(df1.index)}")
# 查看列名
print(f"列名:{df1.columns}")
print(f"列名类型:{type(df1.columns)}")
# 查看值
print(f"所有值:\n{df1.values}")
print(f"值类型:{type(df1.values)}") # 其实是numpy数组
# 查看形状
print(f"形状(行×列):{df1.shape}")
# 查看数据类型
print(f"各列数据类型:\n{df1.dtypes}")
# 查看统计信息
print(f"\n数值列统计信息:")
print(df1.describe())
# 查看基本信息
print(f"\nDataFrame基本信息:")
print(df1.info())
# 查看前几行/后几行
print(f"\n前2行:\n{df1.head(2)}")
print(f"\n后1行:\n{df1.tail(1)}")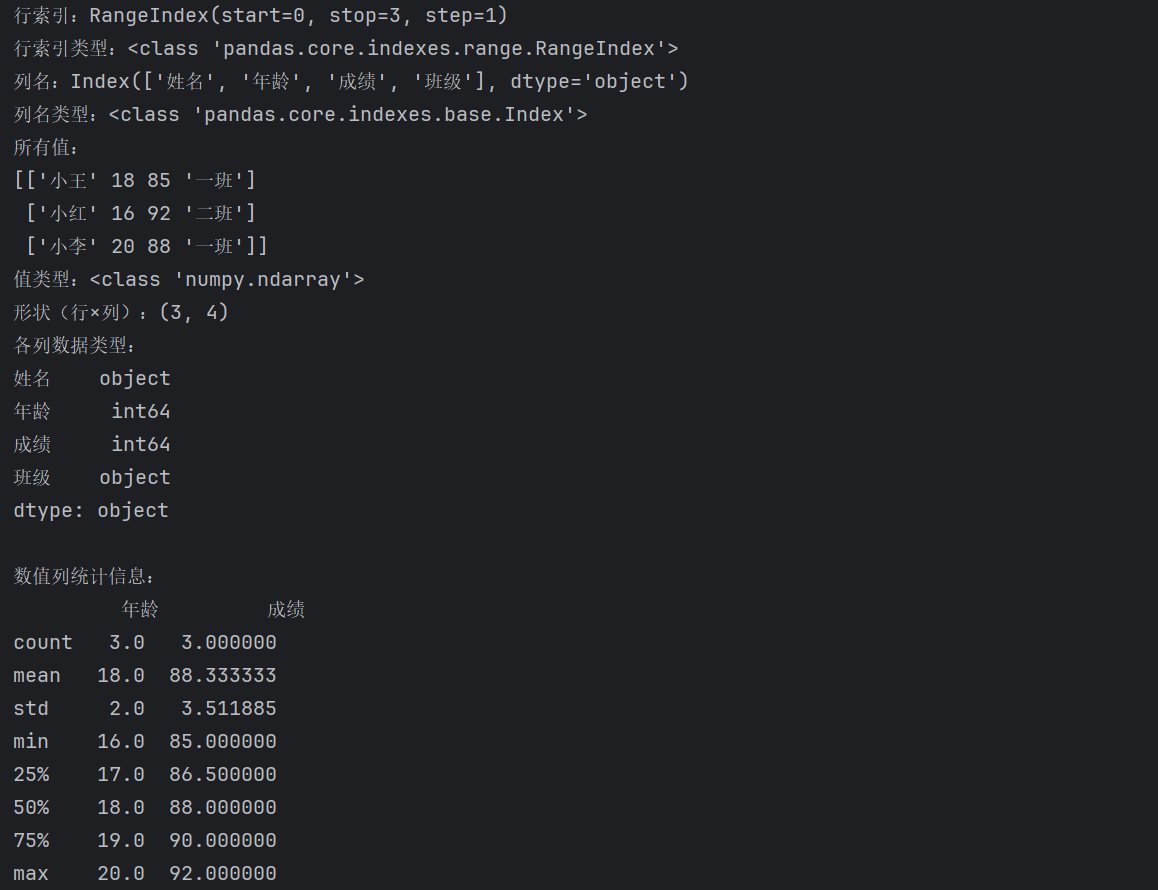
4)、访问DataFrame的数据
# 方法1:使用点符号(
print(f"姓名列:\n{df1.姓名}")
# 方法2:使用方括号
print(f"\n年龄列:\n{df1['年龄']}")
# 访问多列
print(f"\n姓名和成绩列:\n{df1[['姓名', '成绩']]}")
# 访问行(通过位置切片)
print(f"\n前2行:\n{df1[0:2]}")
# 访问单个单元格
print(f"\n第一个学生的姓名:{df1.loc[0, '姓名']}")
print(f"第二个学生的年龄:{df1.iloc[1, 1]}")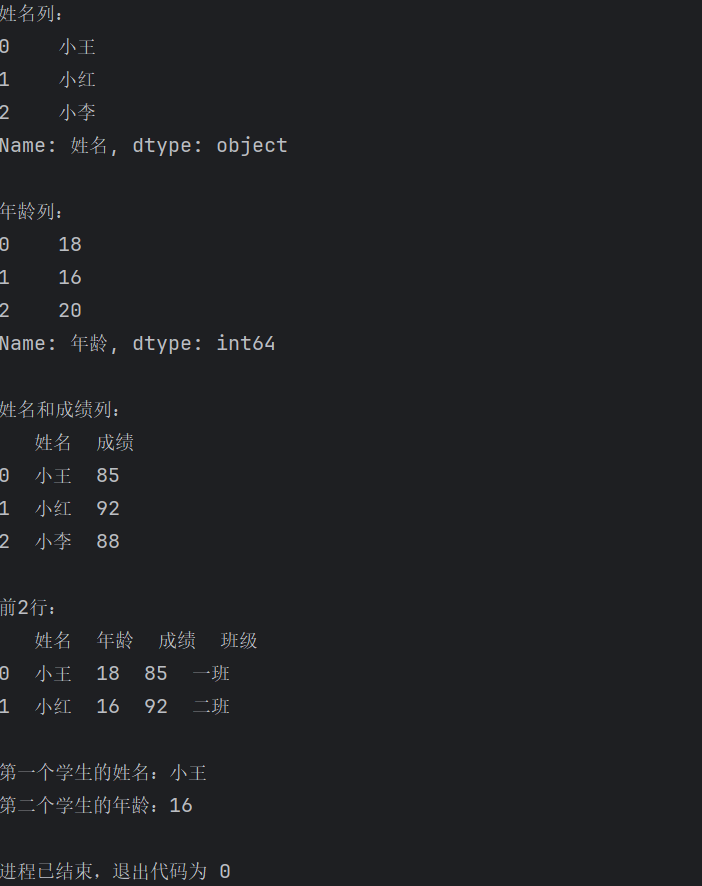
二、DataFrame常见操作
1、排序数据
DataFrame的sort_values() 方法用于对数据进行排序,通过 by 参数指定排序依据的列名,ascending 参数控制升降序(默认为 True 即升序)。它可以进行单列排序,也可通过设置 ascending=False 进行降序排列。需要注意的是,该操作默认返回排序后的新 DataFrame,而不改变原始数据。
import pandas as pd
# 创建示例数据
data = {
'姓名': ['小明', '小红', '小王', '小李'],
'年龄': [20, 16, 18, 21],
'性别': ['男', '女', '男', '女']
}
df = pd.DataFrame(data)
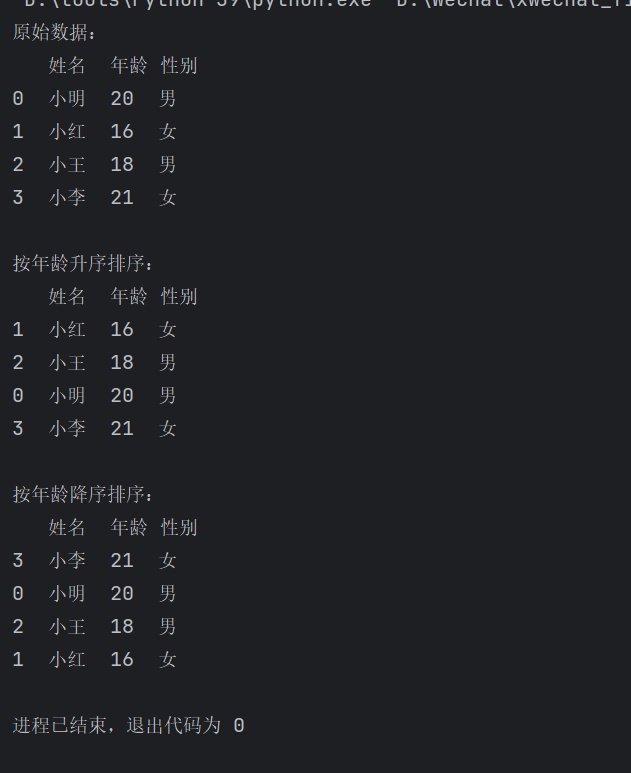
print("原始数据:")
print(df)
# 按年龄升序排序
df_sorted_asc = df.sort_values(by=['年龄'])
print("\n按年龄升序排序:")
print(df_sorted_asc)
# 按年龄降序排序
df_sorted_desc = df.sort_values(by=['年龄'], ascending=False)
print("\n按年龄降序排序:")
print(df_sorted_desc)
2、值替换
通过使用DataFrame的replace()方法,可以轻松替换指定列中的特定值。
df['性别'] = df['性别'].replace(['男', '女'], ['male', 'female'])
print("替换后的数据:")
print(df)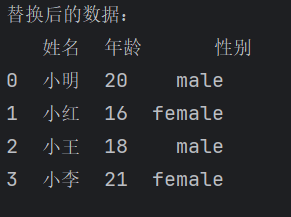
三、数据查询的两种方法:loc和iloc
Pandas提供了 loc 和 iloc 两种核心方法来查询 DataFrame 的数据,两者的根本区别在于索引方式:loc 基于标签(行索引名和列名)进行查询,而 iloc 则基于整数位置(从0开始的行列序号)。尽管索引依据不同,但两者均可获取单个值、整行或整列、多行或多列。总之当使用行/列的名称时选择 loc,使用数字序号时选择 iloc。
import pandas as pd
import numpy as np
a = pd.DataFrame({
'成绩': [85, 92, 78, 95],
'姓名': ['小明', '小红', '小李', '小王']
}, index=['stu1', 'stu2', 'stu3', 'stu4'])
print(a)
# 使用loc(基于标签)
print("\n使用loc:")
print(f"stu2的成绩:{a.loc['stu2', '成绩']}")
print(f"stu2到stu3:\n{a.loc['stu2':'stu3']}")
# 使用iloc(基于位置)
print("\n使用iloc:")
print(f"第2个学生(索引1)的成绩:{a.iloc[1, 0]}")
print(f"第2到第3个学生(索引1:3):\n{a.iloc[1:3]}")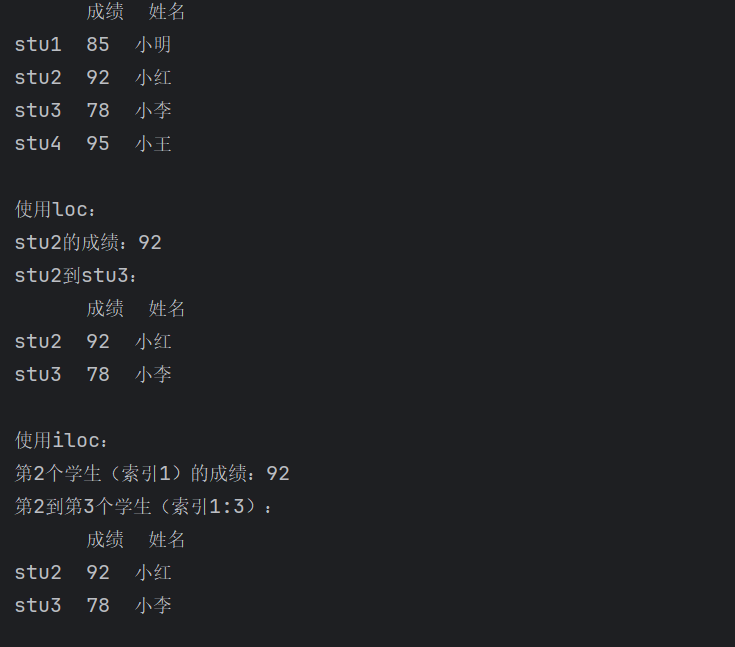
四、简单操作DataFrame
1、修改列名和行索引
要修改DataFrame的列名和行索引,可以直接对其 columns 和 index 属性进行赋值。这种方法会直接修改原始DataFrame的结构,使用时需确保新列名数量与列数一致、新行索引数量与行数一致。
import pandas as pd
df = pd.DataFrame({
'年龄': [10, 11, 12],
'姓名': ['小王', '小红', '小李'],
'收入': [100, 200, 300]
}, index=['person1', 'person2', 'person3'])
print("原始DataFrame:")
print(df)
# 修改列名
df.columns = ['age', 'name', 'income']
print(f"修改后列名:{df.columns}")
print("修改后的DataFrame:")
print(df)
# 修改行索引
df.index = ['学生1', '学生2', '学生3']
print(f"修改后行索引:{df.index}")
print("修改后的DataFrame:")
print(df)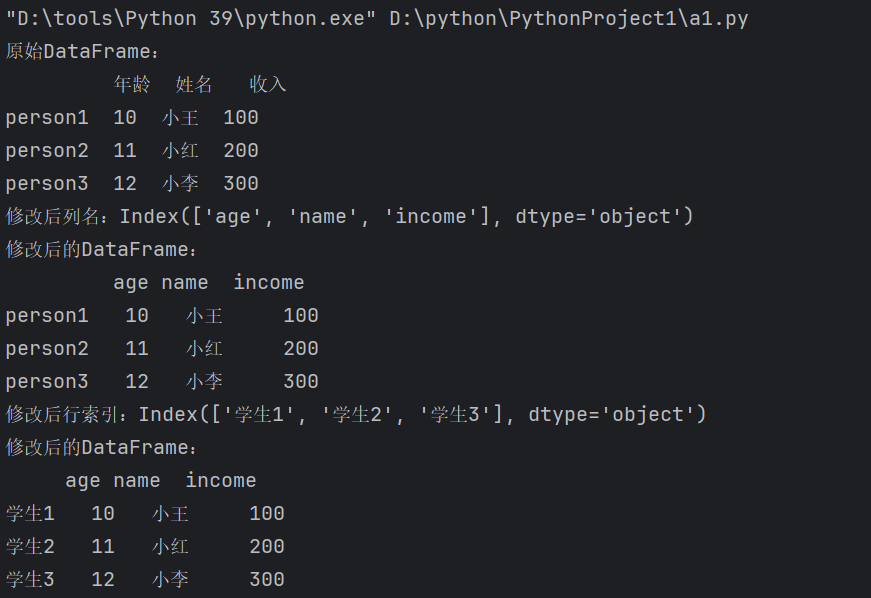
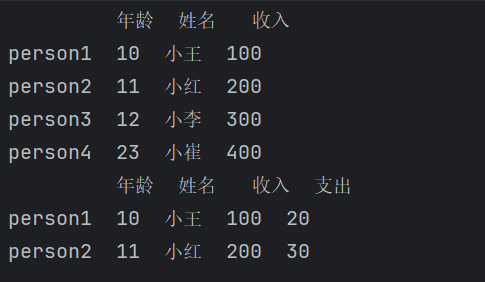
2、增加行或列
在Pandas中,向DataFrame添加新列可以直接通过赋值实现,要求列表长度与行数一致。而添加新行则通常通过loc索引器完成,这会在指定行索引位置插入一行数据,若该索引已存在则覆盖原行。这两种方法均会直接修改原DataFrame,添加时需注意数据对齐。
#增加列
df['支出'] = [20, 30, 40]
print(df)
#增加行
df.loc['学生4'] = [23,'小崔', 400, 50]
print(df)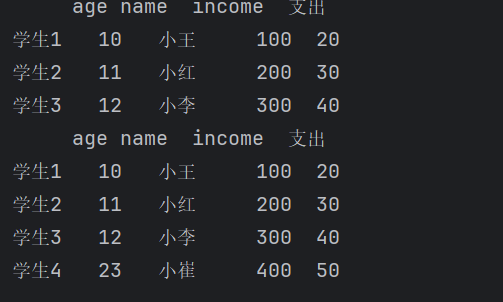
3、访问DataFrame数据
在 Pandas DataFrame中,访问数据有多种方式:通过点符号或方括号加列名字符串可以访问单个列,此时返回一个 Series;通过包含多个列名的列表可以访问多个列,此时返回一个 DataFrame。通过切片可以访问连续的行,返回一个DataFrame;通过 loc 索引器并传入行索引标签的列表可以访问指定的多行;而通过同时指定行标签和列标签可以访问特定的单个值。
# 访问列
print(df['姓名'])
print(f"类型:{type(df['姓名'])}")
# 访问多列
print(df[['姓名', '年龄']])
print(f"类型:{type(df[['姓名', '年龄']])}")
# 访问行
print("\n3. 访问前3行:")
print(df[0:3])
# 访问行
print("\n4. 访问person1和person3:")
print(df.loc[['person1', 'person3']])
# 访问单个值
print("\n5. 访问person1的姓名:")
print(df.loc['person1', '姓名'])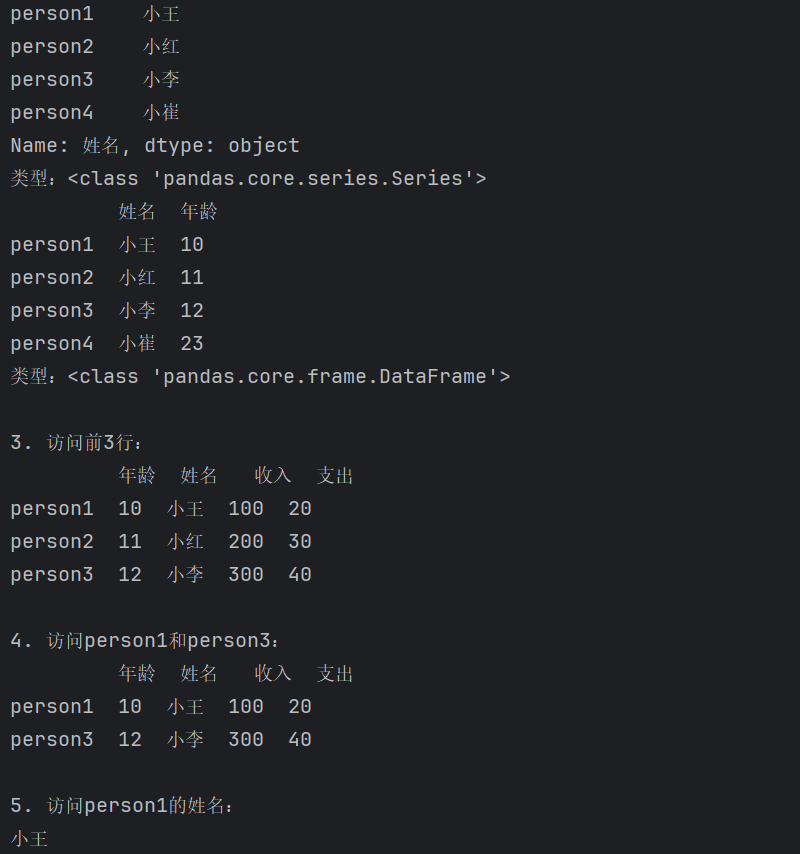
4、删除数据
在Pandas中,删除数据可以通过多种方式实现。使用del语句可以直接在原始DataFrame上删除指定的列,而使用drop()方法提供了更灵活的删除选项:通过指定axis=1可以删除列,指定axis=0可以删除行。inplace参数控制删除操作是否在原始数据上执行:当inplace=False(默认)时返回删除后的新DataFrame而不改变原数据;当inplace=True时直接在原DataFrame上修改且不返回新对象。
# 删除列
del df_copy['支出']
print(df_copy)
# 删除行
df_copy = df.copy()
df_copy.drop(['person3', 'person4'], axis=0, inplace=True)
print(df_copy)
五、数据的导入导出
1、读取文件
Pandas提供了多种读取文件的函数:pd.read_csv() 用于读取 CSV 格式文件,可通过 encoding 参数指定编码(如 'utf8'),通过 header=None 指定文件无表头;pd.read_excel() 用于读取 Excel 文件;pd.read_table() 常用于读取以特定分隔符分隔的文本文件,需通过 sep 参数明确分隔符(例如 sep=',' 表示逗号分隔)。
#读取csv文件
import pandas as pd
df_1 =pd.read_csv("data1.csv",encoding='utf8',header=None)
#读取excel文件
df_3 = pd.read_excel("data2.xlsx")
#读取txt文件
df_4 = pd.read_table("data.txt",sep=',',header=None)
2、导出文件
Pandas提供了将DataFrame导出为多种文件格式的方法。使用 df.to_csv("文件名.csv", index=True, header=True) 可以将数据导出为 CSV 格式,其中 index 参数控制是否写入行索引,header 参数控制是否写入列名。同样,使用 df.to_excel("文件名.xlsx", index=True, header=True) 可以将数据导出为 Excel 格式。
import pandas as pd
df_1.to_csv("导出.csv",index=True, header=True)
df_1.to_excel("导出.xlsx",index=True, header=True)六、缺失值处理
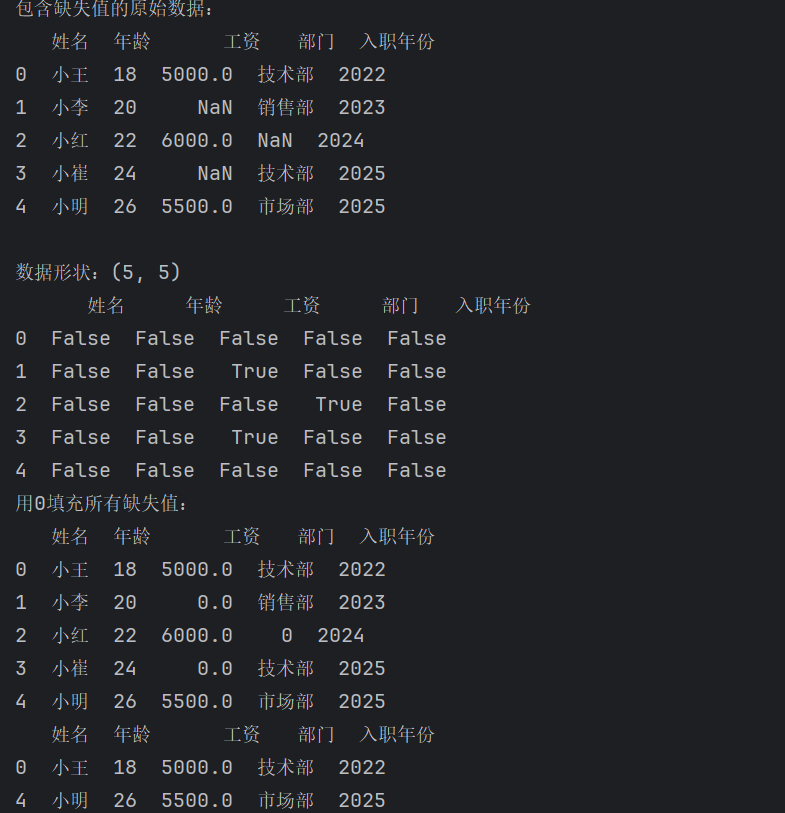
在使用Pandas处理数据时,缺失值的处理通常有三种方法:数据补齐、删除对应数据行和不处理。首先,可以通过pd.read_csv()函数读取CSV文件。随后,使用df.isnull()进行逻辑判断,生成一个布尔类型的DataFrame来标识缺失值的位置。对于数据补齐,可以使用df.fillna('1')方法,将缺失值统一填充为指定值。对于删除对应数据行,则可以使用df.dropna()方法,直接删除包含缺失值的整行数据,从而得到一个完整的子集。
import pandas as pd
import numpy as np
data_with_nan = {
'姓名': ['小王', '小李', '小红', '小崔', '小明'],
'年龄': [18, 20, 22, 24, 26],
'工资': [5000, np.nan, 6000, np.nan, 5500],
'部门': ['技术部', '销售部', np.nan, '技术部', '市场部'],
'入职年份': [2022, 2023, 2024, 2025, 2025]
}
df = pd.DataFrame(data_with_nan)
print("包含缺失值的原始数据:")
print(df)
print(f"\n数据形状:{df.shape}")
# 检查缺失值
print(df.isnull())
# 处理缺失值
# 用固定值填充
df_fill_fixed = df.fillna(0)
print("用0填充所有缺失值:")
print(df_fill_fixed)
# 删除缺失值
df_drop_any = df.dropna()
print(df_drop_any)
七、重复值处理
pandas 处理数据中的重复值,首先通过 df.duplicated() 可以检测整行的重复,也可指定单列或列组合来判断部分重复,并返回布尔序列标记重复项位置。随后可以利用该布尔序列进行条件筛选,提取出所有重复行。最后通过 df.drop_duplicates() 删除重复行,默认基于所有列进行去重,也可指定列的子集进行部分去重。
import pandas as pd
data_with_duplicates = {
'姓名': ['小红', '小王', '小李', '小红', '小王'],
'年龄': [18, 20, 22, 22, 20],
'城市': ['合肥', '杭州', '宁波', '合肥', '杭州'],
'工资': [5000, 6000, 5000, 5500, 6000]
}
df = pd.DataFrame(data_with_duplicates)
print(df)
# 检查整行重复
duplicated_rows = df.duplicated()
print(duplicated_rows)
# 查看重复的行
print("\n重复的行:")
print(df[duplicated_rows])
# 删除所有完全重复的行
df_no_duplicates = df.drop_duplicates()
print(df_no_duplicates)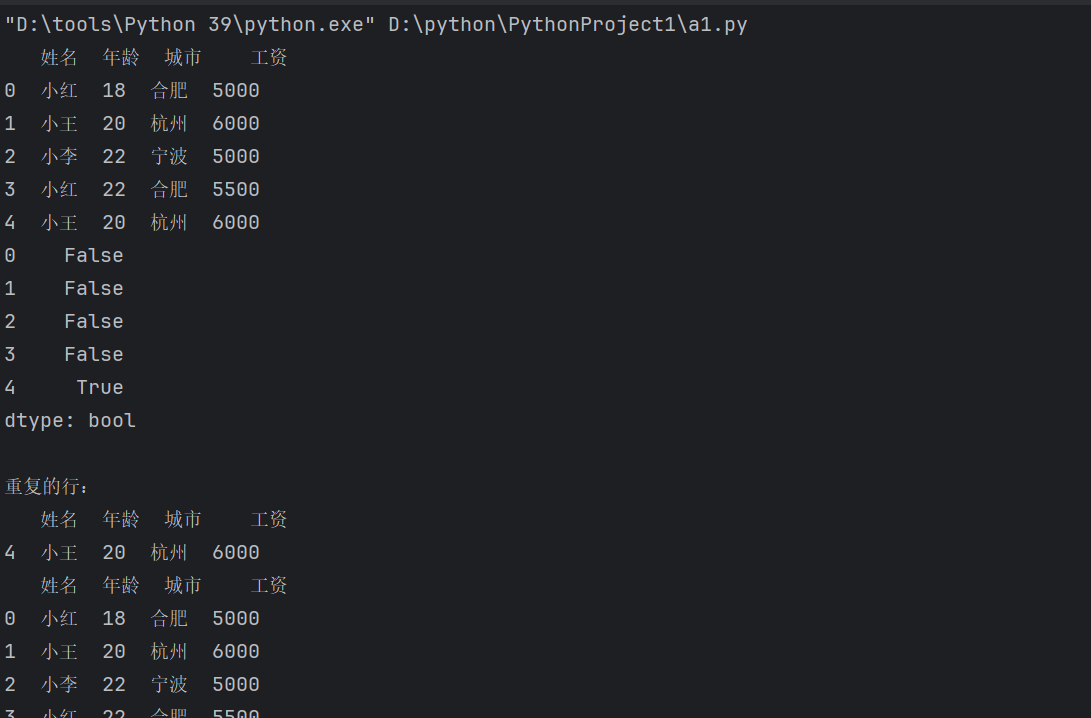
到这里我们就学完了机器学习所需要掌握的两个核心库了,在下一章中将会真正的步入机器学习中。
更多推荐


 24
24 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)