
NeurIPS 2025 超越认知的物理挑战:PhyBlock 3D积木基准撬动大模型空间推理极限
研究团队提出PhyBlock基准,系统性评估21种视觉语言模型在3D积木搭建任务中的物理理解和规划能力。该基准包含400个分层搭建场景和2200道物理理解VQA问题,涵盖从简单堆叠到22块积木的复杂结构。实验发现主流模型在简单任务表现尚可,但在复杂空间依赖和高层推理上性能急剧下降,尤其存在姿态误估和支撑依赖两大核心缺陷。值得注意的是,开源模型显著落后于闭源模型,而思考模式提示对空间任务几乎无效。结
前言
无界智慧(Spatialtemporal AI)联合MBZUAI、中山大学、清华大学的研究员们重磅提出PhyBlock——一个针对机器人 3D 积木搭建的全新基准,用以衡量视觉语言模型(VLM)在理解物理世界、制定长序列计划方面的能力。这一基准结合了分层搭建任务和物理理解 VQA,共计 2600 个任务,系统评测了 21 个流行的 VLM,让大家熟知的 GPT、Claude 、Gemini 等模型接受了一次“空间智商测验”。
项目主页:https://phyblock.github.io/
论文地址:https://arxiv.org/abs/2506.08708
开源项目:https://github.com/PhyBlock/PhyBlock
为什么要在 3D 积木上考验大模型?
新一代 VLM 能够对图像进行描述甚至指导机器人完成动作,但它们对物理规律、结构稳定性的理解仍然有限。作者指出,传统基准多聚焦于单步感知或简单动作,忽视了重心、支撑、顺序依赖等真实世界约束。例如,在 3D 积木任务中,模型不仅要识别形状、颜色,还必须懂得“上面的积木要有支撑”“放错顺序整体会倒”等基本常识。正是这种对重力、支撑关系和几何约束的考察,才能检验模型是否具备真正的“物理直觉”。
PhyBlock 基准怎么设计?
论文设计了两个分支:
1. 分层积木搭建任务(Hierarchical Assembly Planning)
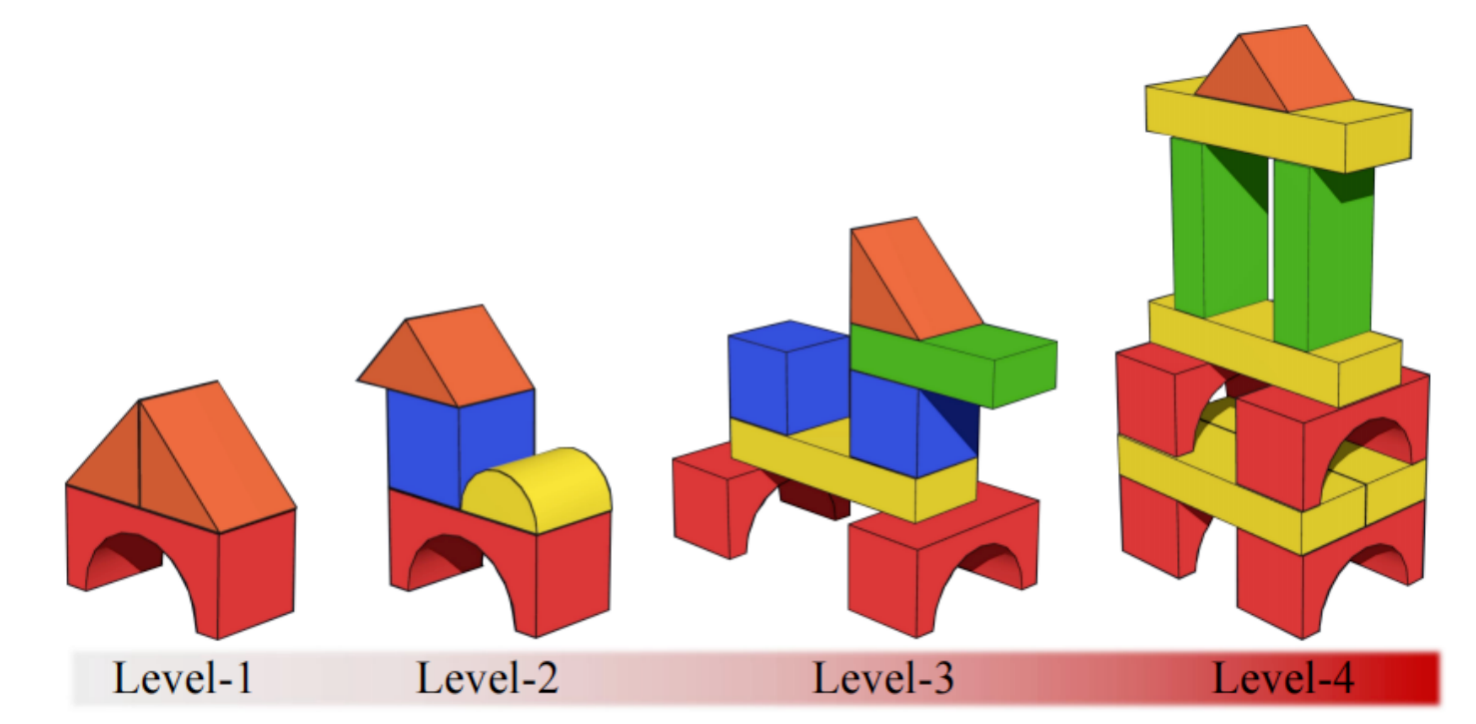
借助高保真物理模拟器 Genesis,研究者构建了 400 个积木搭建场景,划分为四个难度等级:
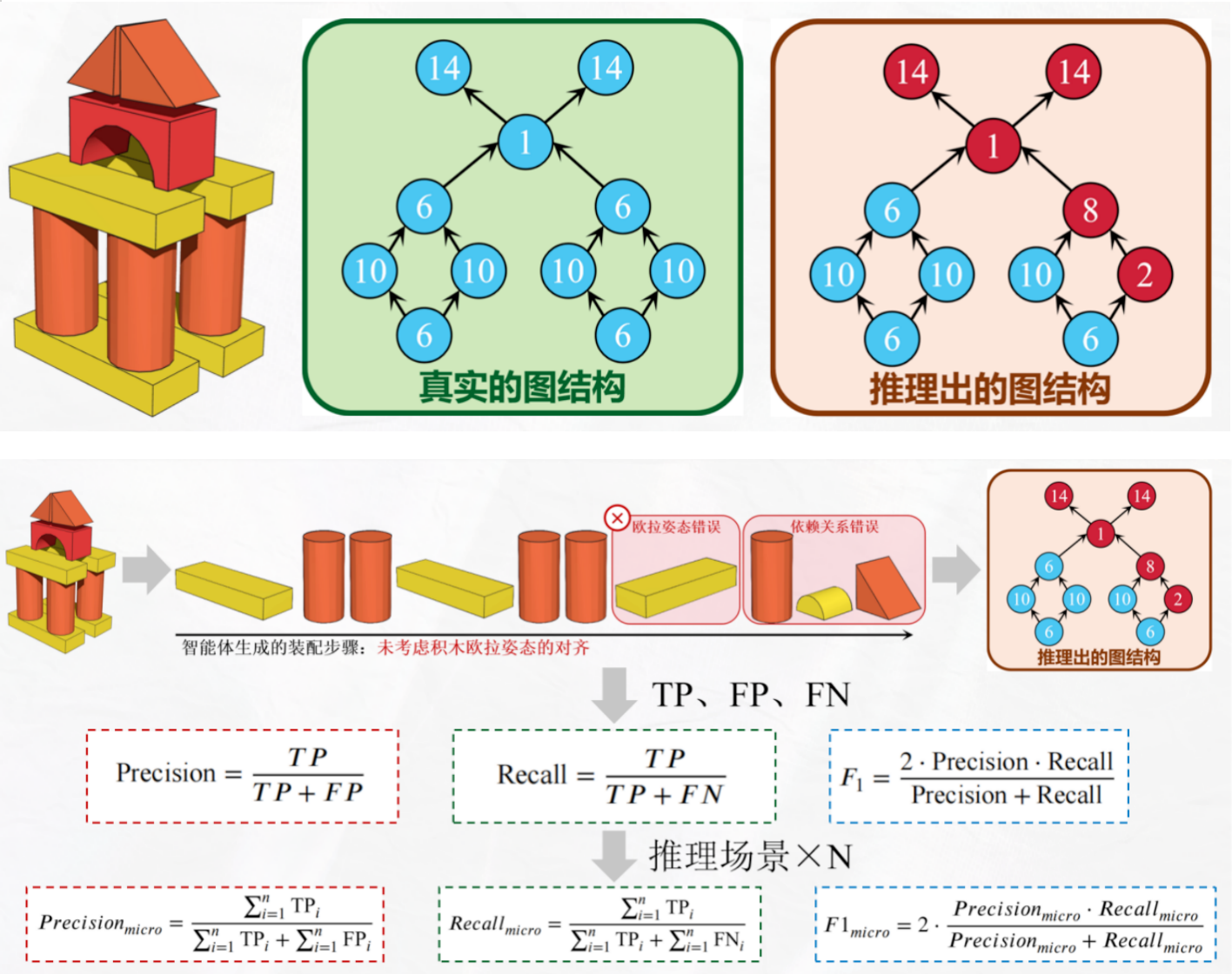
在评估方面,作者用活动顶点图(AOV)网络描述积木搭建的目标样式,利用积木之间形成的拓扑依赖关系,判断模型推理出的每个步骤是否合理。我们将正确的步骤视作TP、不合理的步骤视作FP、未考虑到的步骤视作FN,对于每个需要搭建的场景,可以得到准确率、召回率和F1分数,对于N个场景我们使用micro-F1作为量化指标。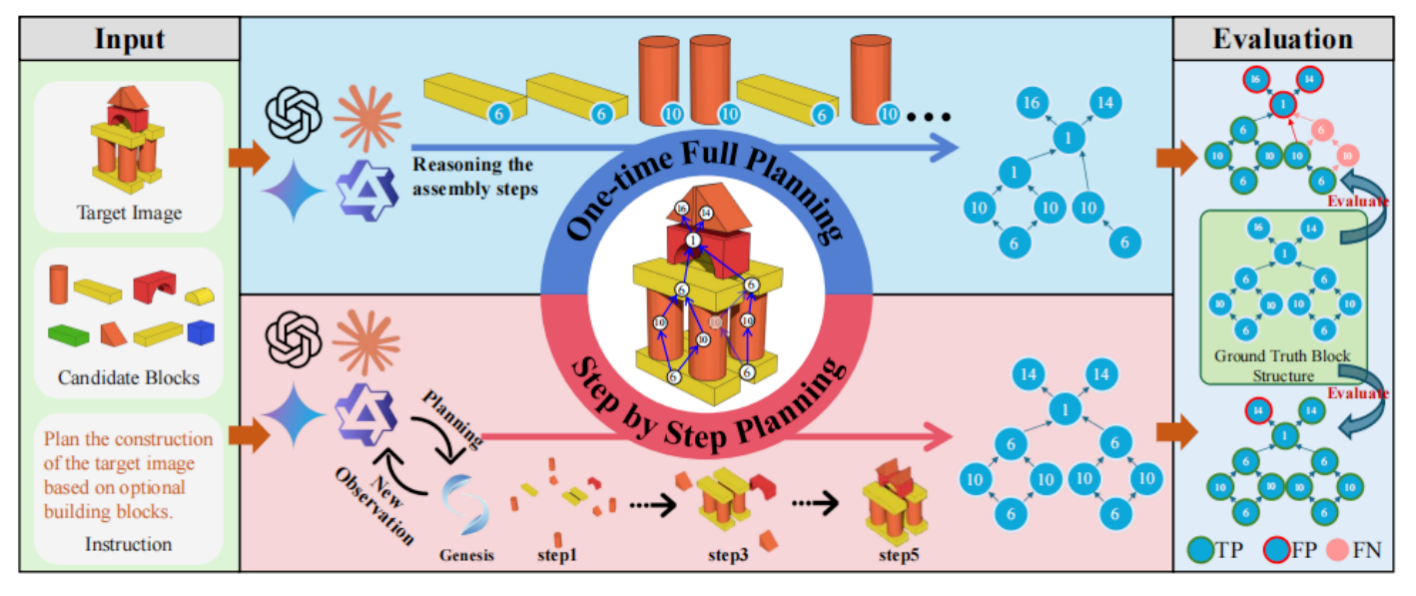
作者评测了 21 个 VLM(13 个闭源模型和 8 个开源模型),覆盖 GPT‑4o、Claude、Gemini、Qwen、LLaVA 等热门系列。基准支持两种推理模式:
- 一次性全局规划(One‑time Full Planning):模型在看到初始场景和目标图后,一次性输出完整的搭建顺序,无法修正错误。
- 逐步规划(Step‑by‑Step Planning):模型在模拟器中边观察、边行动,生成下一个操作。这更接近现实机器人任务,但也更考验闭环决策能力。



2. 物理理解 VQA(Physics Understanding VQA)
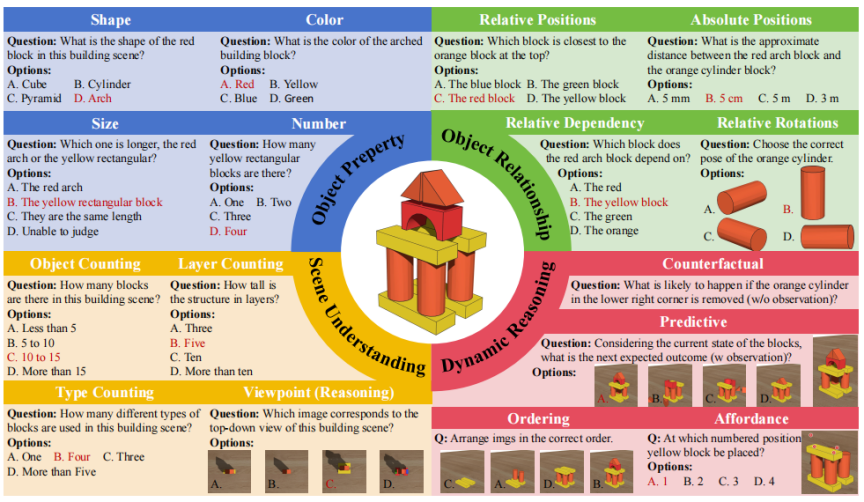
为了更细致地评估模型在积木搭建任务中所涉及的多维能力,研究者设计了 2200 道多项选择题,涵盖从静态感知到动态推理的完整认知链条。这些问题被划分为四大类别:物体属性、物体关系、场景理解与动态推理四大类,例如:
- 形状、颜色、尺寸、数量的识别;
- 相对/绝对位置、支撑依赖、相对旋转;
- 场景层数、对象数量、视角匹配;
- 反事实推测、未来预测、步骤排序与摆放可行性。
这些问题同时检验模型对静态属性和动态后果的理解,例如“移除支撑块会发生什么”“下一步应该放哪里”,构成了一个层层递进的评测框架,既能验证模型的视觉感知精度,也能揭示其在真实物理世界中进行因果推理与结构规划的能力缺陷。
实验发现:从感知到规划,性能急剧下滑

论文的实验给出了令人警醒的结果:
-
难度提升导致 F1 分数大幅下降
所有模型在简单任务上表现尚可,但一旦难度上升,F1 和召回率几乎减半。以表现最好的闭源模型 Claude 3.7 Sonnet 为例,其在 Level‑1 任务上的 F1 高达 76.78%,而在 Level‑4 任务时仅剩 41.82%。这表明当前模型无法有效处理复杂空间依赖。 -
低层问题擅长,高层推理困难
在物理理解 VQA 任务上,模型普遍能正确回答颜色、形状等低层属性问题,但在反事实、因果推理、结构稳定性等动态推理上表现惨淡。例如,GPT‑o3 在颜色识别(Color)子任务上准确率达 90%;然而在需要推测移除支撑块后会发生什么的反事实问题上,其准确率则大幅下降。 -
开源模型明显落后于闭源模型
闭源模型(如 Claude、GPT)在整体性能上领先开源模型,尤其是在复杂任务上。例如,Claude 3.7 Sonnet 的总体 F1 分数约为 47.4%,而多数开源模型仅为 20% 左右。这反映了当前开源 VLM 在物理推理方面仍有明显差距。 -
Orientation判断和支撑依赖是主要错误来源
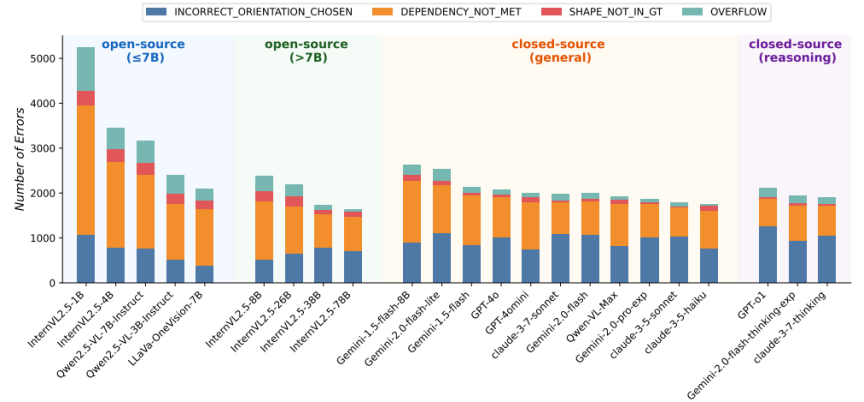
在对模型的失败案例进行系统性拆解后,作者将 3D 积木搭建过程中推理出的错误归纳统计为四大类:
1)姿态误估(Euler Error);
2)支撑/依赖关系错误(Dependency Not Met);
3)形状识别或选型错误(Shape Not in Ground Truth);
4)溢出式放置(Overflow Placement)。
错误分析结果显示,姿态误估与支撑依赖错误几乎贯穿所有模型,是最主要的失败来源。其中,姿态误估(Euler Error) 尤为突出:模型往往无法准确判断方块的旋转角度或空间方向,导致其生成的摆放姿态与真实解严重偏差。例如,某些模型会将拱形块倒置、将圆柱块旋转到不稳定角度,或在水平/垂直朝向上出现明显误判。这些错误会在序列规划中持续放大,最终使后续操作无法保持结构稳定。
与之并列的另一个核心问题是 忽视支撑依赖(Dependency Not Met)。由于 3D 搭建具有严格的“先放下层,再放上层”的物理约束,模型需要理解哪些积木承担结构支撑、哪些步骤存在必然的前后依赖。然而实验表明,大部分模型即使能够识别方块,也常常忽略基础构件的承重与先后关系,导致上层结构被“悬空”或直接放置在缺乏支撑的位置上。
相比之下,形状误选 与 溢出放置 的发生频率相对较低,更多属于“注意力不集中”式的小型错误。然而姿态误估与支撑依赖两类错误具有本质上的物理推理缺陷,且在所有模型(无论开源/闭源、小模型/大模型)中均普遍存在,呈现出 跨架构的共性弱点。 -
思考模式并未显著提升表现
令人意外的是,当启用思考模式(Thinking Mode)提示时,模型表现几乎没有提升。这表明对于空间任务,长文本推理并不能弥补物理直觉的缺失,模型仍会在最初的姿态估计阶段犯错并贯穿后续步骤。
比如,即便对某些模型启用 reasoning-tuned 版本(如 Claude 3.7 Sonnet-Thinking),其 Euler Error 的数量几乎 没有下降,说明 链式思考(CoT)并不能帮助模型弥补物理直觉的缺乏。模型在空间方向、旋转角度、稳定性判断等问题上更多依赖“预训练中是否看过类似结构”,而不是依靠语言链条进行逻辑推理。
- 增强的空间推理能力可能是最关键的突破点
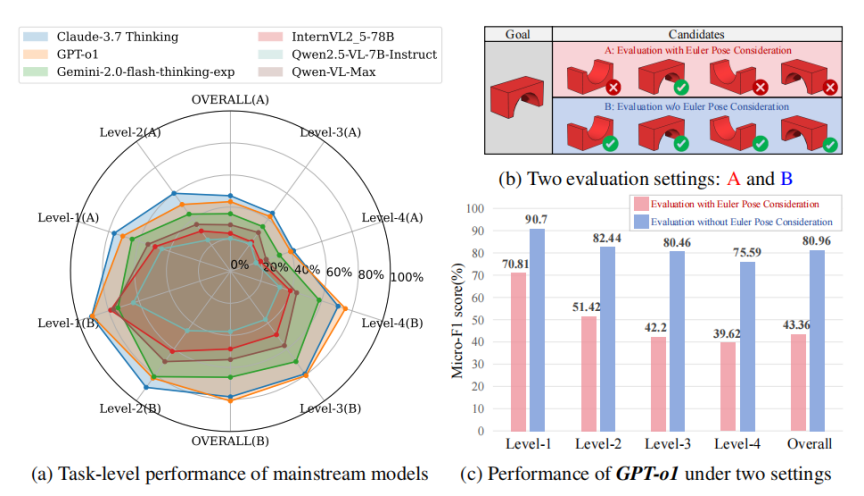
为了更系统地揭示模型的性能瓶颈,我们在基准中引入了 两种不同的评估范式,分别从“严格物理一致性”与“任务意图一致性”两个维度检验模型的真实能力。
·Setting A(严格姿态一致)
要求模型在每个步骤中不仅要选择正确的积木,还必须预测出与目标完全一致的三维姿态(Euler Pose)。也就是说,只要角度或方向稍有偏差,即便积木选对了也会被判断为错误。
·Setting B(放宽姿态要求)
在该设定下,只要模型选择了正确的积木样式或结构组件,即视为推理正确,而不会对旋转角度、摆放朝向等空间姿态做严格要求。
通过对 GPT-O1 模型的对比分析,我们发现一个非常关键的现象:当评估从 Setting A → Setting B 过渡时,GPT-O1 的整体得分出现大幅跃升。换句话说,在姿态约束被放宽后,模型的推理链条不再被姿态错误反复拖累,表现显著提升。
这一结果与错误类型分析完全一致,也为我们带来了清晰的启示:在三维结构搭建类任务中,“空间姿态对齐” 是当前 VLM 的最大短板,也是影响长程规划性能的首要瓶颈。
目前的大模型在识别积木类型、推断依赖关系、甚至制定基本序列策略方面表现尚可,但一旦要求其进行精确的三维姿态预测,性能便会急剧下滑。姿态误估不仅导致单步失败,还会在多步规划中呈现“级联效应”,使后续操作全部偏离正确轨迹。
因此,在未来的具身智能与 3D 规划模型中,提升三维姿态理解与空间对齐能力 ——而不仅是增强语言链式推理或扩展感知模态——可能是最关键的突破点。
小结:为具身智能铺路的新基准
PhyBlock 的出现,为研究者提供了一个可以定量评估空间理解与规划能力的统一平台。作者的贡献包括:
统一的测试平台:基于物理模拟的 3D 积木任务,既考察视觉感知又兼顾长序列规划;
渐进式数据集:从简单堆叠到 22 块积木的复杂结构,配套 2200 条经过人工验证的 VQA 问答,覆盖 16 种语义类别;
全面基准分析:评测 21 种 VLM,揭示在复杂空间任务上的共性缺陷,如高层推理能力不足、姿态估计误差大等。
论文指出,要让 VLM 在现实机器人场景中担当高阶规划者,仅靠视觉对齐和语言模型远远不够。未来模型需要在视觉嵌入中融入物理先验,并通过互动学习强化空间推理能力。此外,该基准代码与数据集已开源,研究者可以利用现有场景生成更多样的任务,推动具身智能迈向真正理解物理世界的下一阶段。
作者介绍

共同一作 马梁 现为 MBZUAI 硕士研究生,师从 Prof. Xiaodan Liang,本科毕业于 中山大学智能工程学院。
研究方向主要聚焦于具身智能与机器人,涵盖具身任务规划、机械臂物体操作(Manipulation)以及视觉语言导航(VLN)。他尤其关注如何通过提升多模态大模型的具身能力来应对具身智能中的核心挑战,从而实现基于感知的规划与真实物理世界中的执行。
当前研究重点包括:大型视觉语言模型的物理世界理解与具身推理能力,以及长序列操作任务的规划与评测。其长期研究目标是让机器人能够在多模态指令输入下,高效地理解并执行人类意图,以在复杂的物理环境中协助人类完成多样化任务。
共同一作温嘉俊是清华大学深圳国际研究生院硕士研究生,本科毕业于中山大学智能工程学院。研究方向为具身智能与人类动作理解,主要聚焦多模态大模型在三维感知、物理推理与人机交互中的应用。目前已在 NeurIPS、IROS、ICMEW 等国际会议发表多篇论文。曾获国家奖学金、中山大学郭谢碧蓉特等奖学金、校级优秀毕业生等荣誉。
共同一作林敏是中山大学智能工程学院电子信息专业硕士研究生(研二),导师是Prof. Xiaodan Liang。本科期间同样就读于中山大学智能工程学院,连续获得多次校级优秀奖学金及创新实践荣誉。目前为中山大学具身智能中心成员,参与多个与机器人自主感知与智能决策相关的研究项目。
研究方向主要聚焦于具身智能(Embodied Intelligence)与多模态学习(Multimodal Learning),尤其关注如何通过视觉、语言与动作等模态的深度融合,使机器人能够在真实环境中实现理解、规划与执行的闭环智能行为。目前的研究重点包括:基于视觉语义的长视距任务规划与控制;结合记忆机制(如工作记忆与场景记忆)的策略学习与任务分解;面向移动操作任务的具身智能体训练与评测方法。
其研究目标是让机器人能够在复杂、动态和非结构化环境中具备更强的感知理解与自主决策能力,从而在多阶段任务中实现高效的移动与操作协同。
共同一作许镕涛是 无界智慧联创兼CTO,Rongtao-Xu.github.io。MBZUAI研究员,前中科院自动化所助研、多模态人工智能国重博士, 曾获中科院院长奖、两次IEEE旗舰会议最佳论文提名奖、国奖、北京市和中科院优秀毕业生。华中科技大学数学与计算机双学位。研究方向为具身智能与机器人,提出全球首个基于空间可供性操作大模型A0,曾在银河通用共同主导全球首个具身导航大模型NaVid。在相关领域学术期刊和会议上共发表论文70余篇,其中以一作或通讯发表论文30余篇,含ESI高被引论文3篇。曾在NeurIPS、AAAI、ICRA、IROS等会议上发表多篇Oral论文。拥有多项发明专利,研究成果应用于YOLO系列,以及无界智慧、银河通用、华为、Momenta等多款产品。
共同一作梁曦文是中山大学的博士生,导师为 Prof. Xiaodan Liang 。研究聚焦于具身智能(Embodied AI),涵盖具身任务规划、视觉语言导航(VLN)以及视觉-语言-动作模型(VLA)。目标是打造能够真正理解人类意图、具备稳健推理能力并能在真实环境中自主执行复杂任务的机器人,使智能体在未来能够以更高的可靠性和泛化能力服务于人类的日常生活与多样化应用场景。
更多推荐
 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)