
通过动态群体感知网络进行多智能体轨迹预测
文章指出智能体的决策由三个因素决定,自我动力,瞬时意图和社会交互,而社会交互则是当前的重点,近年主要通过空间中心机制,注意力机制,图来进行建模但仍然存在局限性:首先,没有考虑群体行为,如海洋鱼群躲避捕食者,NBA团队合作其次,交互关系会随时间变化,如群体内部的关系最后,目前大多只推理交互类别,没有交互强度在过去的轨迹预测中(GroupNet)主要考虑多智能体间静态的交互关系,因此提出DynGrou
论文:2024年Dynamic-Group-Aware Networks for Multi-Agent Trajectory Prediction with Relational Reasoning
1、介绍
文章指出智能体的决策由三个因素决定,自我动力,瞬时意图和社会交互,而社会交互则是当前的重点,近年主要通过空间中心机制,注意力机制,图来进行建模
但仍然存在局限性:
首先,没有考虑群体行为,如海洋鱼群躲避捕食者,NBA团队合作
其次,交互关系会随时间变化,如群体内部的关系
最后,目前大多只推理交互类别,没有交互强度
在过去的轨迹预测中(GroupNet)主要考虑多智能体间静态的交互关系,因此提出DynGroupNet这样一个动态群感知网络
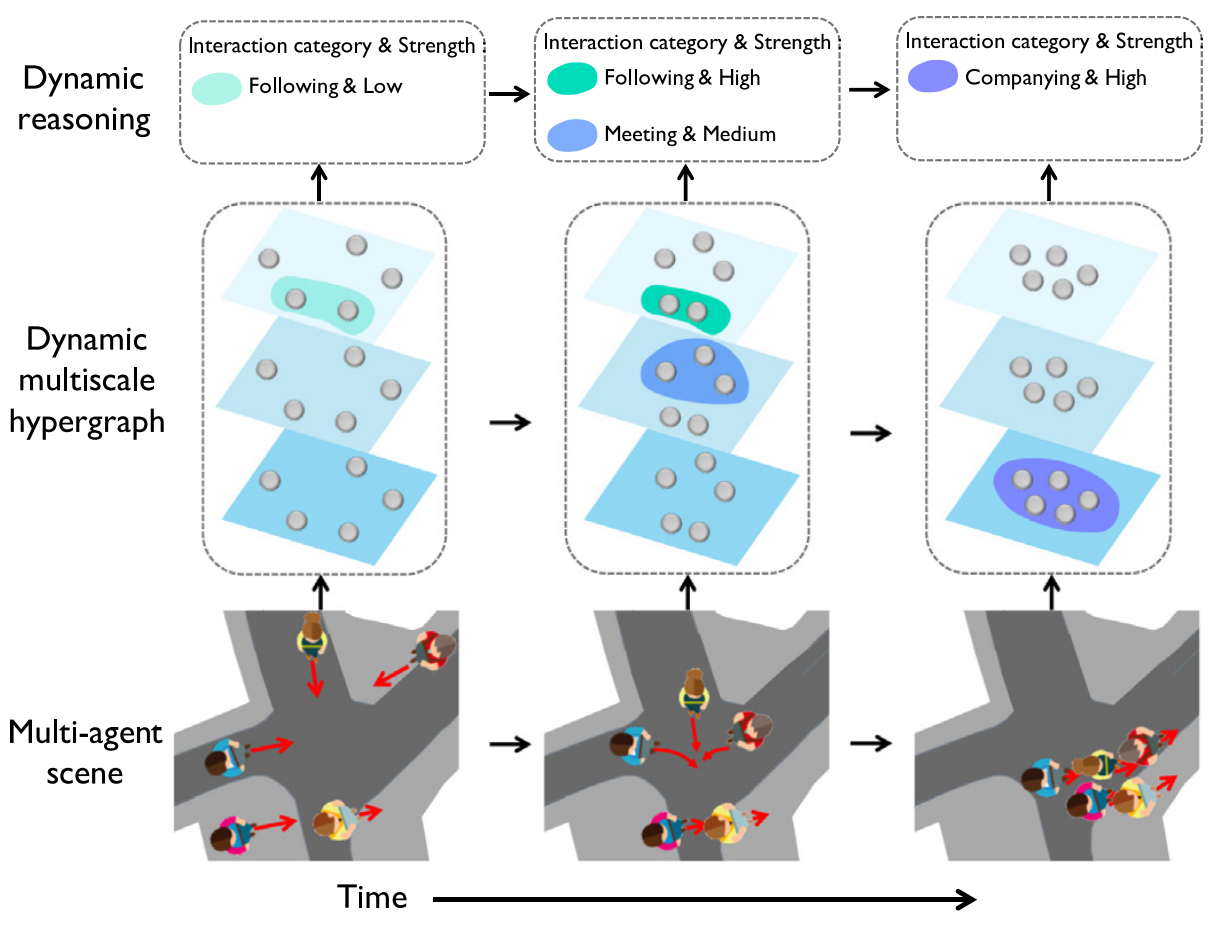
1)考虑成对的和群体的交互,提出了一个多尺度的超图,用一系列的超图来建模不同大小的群体交互
2)在动态环境中考虑时空交互,在拓扑和表示上将多尺度超图进化为动态的多尺度超图,建模群体的动态和群体内部的交互。主要通过一个循环编码和关联矩阵来拓扑,还有一个基于transformer的动态嵌入进化,结合先前的交互信息来进行当前的交互建模
3)无监督推理交互强度和类别,通过提出一种三元素表示格式:神经交互强度、神经交互类别和per-category函数,它可以反映交互群体的交互强度和类别,通过在动态多尺度超图传递神经消息,将这种三元素交互嵌入合并到表示学习过程中,以推理动态关系
基于提出一个预测系统,以DyGroupNet为编码过程的核心组件,通过将预测轨迹设置为下一个编码输入,对未来轨迹进行递归预测。
由于未来轨迹的多样性和不确定性,采用基于双变量GMM模型的一个CVAE构建未来轨迹的分布,而不是回归(类似于与LSSTA的最后一步)
为了减少不同预测轨迹不准确部分所带来的输入噪声,稳定系统训练,进一步提出一种多采样训练策略。
为了增强从GMM中单独抽样的每个时间戳的预测结果之间的相关性,提出了一种预测细化,以实现更平滑和可行的未来预测。
主要贡献:
提出的DynGroupNet可以提取不同规模的时变群体的交互信息,并推理得到相应的交互强度和类别
提出的基于DynGroupNet的预测系统将高斯混合模型、多重采样和预测细化紧密结合,实现了预测的多样性,训练的稳定性和轨迹的平滑性
建立物理模型设计了广泛的合成模拟,证明了动态交互的推理能力
在4种真实数据集中展示了优越性能
2、流程
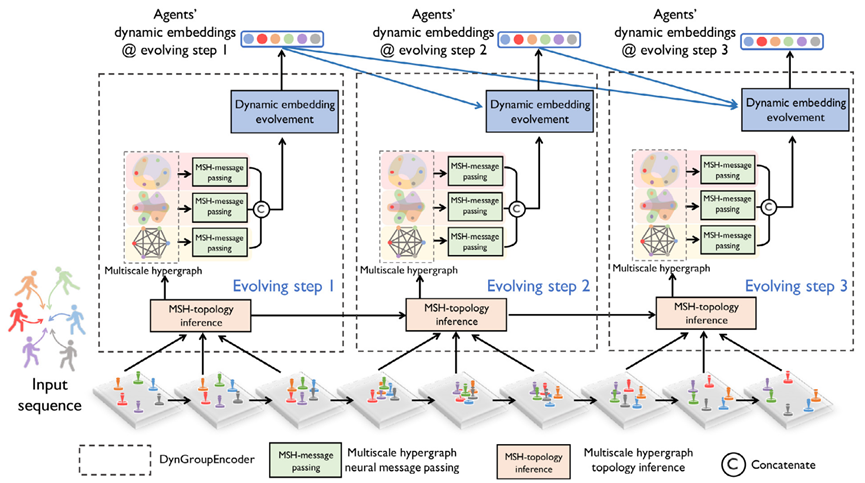
通过k次evolving steps编码来提取动态交互特征,每一次输入是一个时间段的轨迹,输出是相应智能体的embeddings
每一个evolving step,使用一个DynGroupNetEncoder,主要由三个操作构成:
多尺度超图拓扑推断,在给定输入子轨迹时,推断多尺度超图的拓扑结构
多尺度超图神经网络信息传递,学习智能体和多尺度超图推断得到的交互关系的模式
动态嵌入进化,接收沿时间学习得到的模式,并根据时间依赖性合并,输出智能体的动态embeddings
在该流程图中,有3次evolving step,第k个步骤输入的子轨迹为k*tao:k*tao+TE-1,这里TE=tao=3
3、多尺度拓扑推断
3.1、相关矩阵
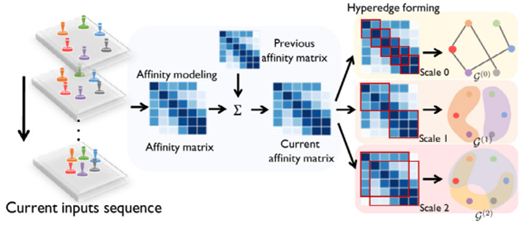
在第evolving step下首先对输入轨迹通过一个MLP进行初始化,然后计算相关矩阵,反映两个智能体之间的相关度,为了平滑智能体相关性的变化,通过对上一个evolving step的相关矩阵的加权求和来调整当前的相关矩阵
![]()
![]()
3.2、形成超边
形成不同尺度下的超边,超边区别于普通的图论中的边(两点相连,只能表达两两智能体之间的关系),超边是任意数量节点相连的边,也就是一组节点的小集合,如下图0尺度下的超边在文中表述为最精细的成对的智能体的联系,每个节点连接与其具有最大相关度分数的节点。
![]()
一个群体中的智能体之间应该有很高的相关度,因此在相关矩阵A中找到高密度的子矩阵来构建其他尺度的超边,每个节点 vi 对应一个超边 ei(s,k) ,表示一个包含 M(s) 个节点的群体,所以最后有多少节点就有多少超边,实际上是一个优化问题,优化令群体内部相关度总和最大(如下图即为优化目标),最后将同一尺度下的超边构成一个超边集
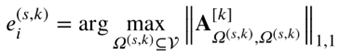
![]()
3.3、形成超图
![]()
然后由当前输入序列的智能体集合和当前evolving step的一个s尺度的超边集构成一个超图,即
![]()
再将不同尺度的超图构成一个超图集
而集合中的每一个超图则可以转化为一个关联矩阵,当第i个节点,在第j个超边中,则Hij为1,否则为0
4、多尺度超图神经网络信息传递
通过节点到超边和超边到节点的迭代来获取智能体和交互的embeddings
4.1、节点到超边阶段
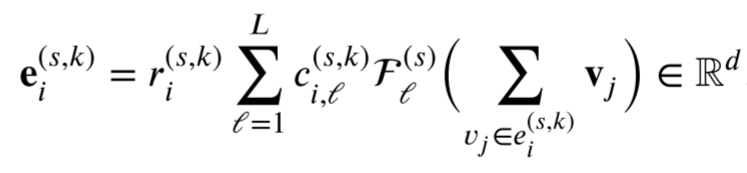 在每个尺度上,通过将同一群体中的智能体embeddings聚合来获取交互embeddings,构造一种包含三个元素的嵌入格式:神经交互的强度,表示交互的强度,神经交互的类别,反映智能体的交互类别,以及per-category函数,表示该类别的交互过程所起的作用
在每个尺度上,通过将同一群体中的智能体embeddings聚合来获取交互embeddings,构造一种包含三个元素的嵌入格式:神经交互的强度,表示交互的强度,神经交互的类别,反映智能体的交互类别,以及per-category函数,表示该类别的交互过程所起的作用
r 为神经交互强度,c表示某一神经类别交互的概率,利用一个MLP构造一个该类别的函数F。首先通过MLP(考虑每一个节点对群体的贡献)得到一个反映群智能体整体信息的共同embeddings(隐藏状态)z,然后分别利用MLP得到r和c。
4.2、超边到节点阶段
根据群智能体的交互embeddings来更新每个智能体的embeddings,如图将某一节点embedding和该节点的超边的embeddings之和合并后,通过一个MLP来更新该节点的embedding
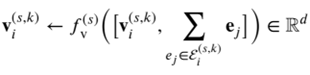
最后,通过聚合所有尺度的节点embeddings来获得智能体的表示
![]()
5、动态嵌入进化
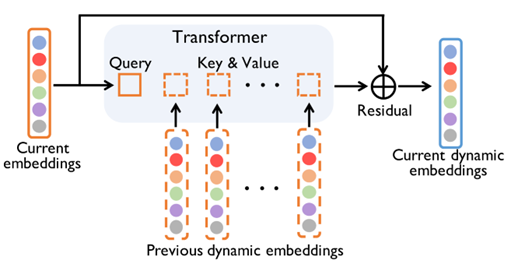
将最后聚合得到的Embedding升级为动态的,通过一个transformer提取全局时态,其中Q为当前的embedding,而K和V是过去的动态embedding,将k次进化以前的每一次
![]()
进化的动态embedding和和其位置向量(通过MLP得到)相加,然后再多次串联,得到k次以前的动态embeddings,而当前动态embedding通过transformer结构得到
![]()
6、预测系统
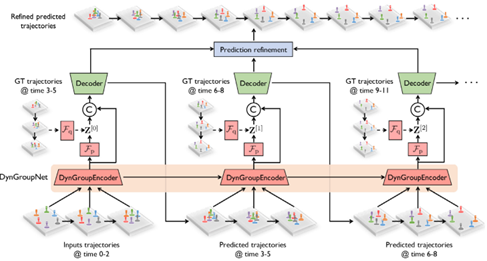
主要基于DynGroupNet结构,和CVAE,来预测出智能体的多可能的轨迹。
首先通过DynGroupNet对历史轨迹进行编码,通过计算智能体的embeddings来得到潜变量z, 通过对潜变量z和智能体的动态embeddings解码得到预测轨迹,再将预测轨迹作为下一输入,重复编码-解码,最后将多次的预测轨迹一起细化得到最后的输出轨迹
编码过程首先利用DGN生成智能体的动态embeddings,MLP或LSTM将GT生成GT的embeddings,再分别利用线性层生成先验分布参数和后验分布参数,在训练阶段,通过从后验分布中采样得到潜变量z,测试阶段没有GT,从先验分布中采样,最后将潜变量z和动态embeddings合并作为编码的输出(这一步类似于LSSTA的最后一步处理)
解码器由GRU和GMM(二元高斯分布模型)构成,每一个GRU逐步生成GMM的参数,而GMM采样得到智能体的下一个速度,下一步再将速度添加得到位移,最后得到预测轨迹,进行多次采样,选择最接近GT的一个去作为下一步的输入。
将编码-解码过程不断重复,得到轨迹,但由于预测轨迹是分段预测的,缺乏相关性,利用一个类似MLP的函数进行细化最后得到一个预测轨迹。
损失函数为每一轮编码-解码的负对数损失,KL散度损失,细化损失之和。
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)