
LangGraph Supervisor架构详解:构建可扩展的多智能体系统(含完整代码)
文章介绍了LangGraph框架中的Supervisor机制,这是一种用于多智能体系统的中央调度架构。通过微软Magentic-One案例,展示了Supervisor如何实现分工明确、中央协调和动态路由的工作模式。文章提供了详细的代码实现,包括系统状态定义、Supervisor节点行为、子代理节点创建等,并展示了数据库与分析能力多代理系统的实战案例。这种架构实现了结构化任务调度、可扩展代理体系和自
在多智能体系统(Multi-Agent System)的发展历程中,LangGraph 正逐渐成为最具代表性的编排框架之一。它不仅能让多个智能体协同工作,还能通过图结构管理复杂的工作流。而在众多特性中,最值得关注的,莫过于它所引入的“Supervisor(代理主管)”机制——一个能够像项目经理一样,统筹规划、任务分派、结果整合的核心控制单元。
这篇文章,我们将从微软的最新多智能体系统 Magentic-One 入手,深入理解 Supervisor 架构的思想来源与实现逻辑,最后带你一步步在 LangGraph 中构建一个真正可运行的多智能体系统。
一、从 Magentic-One 说起:多智能体系统的协作样本
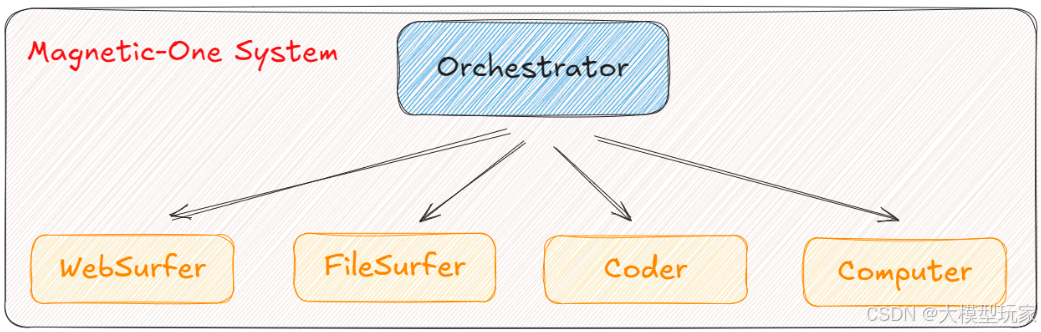
微软在 2024 年推出的 Magentic-One,可以说是当前多智能体系统的“教科书级”范例。它允许多个 AI 代理协同工作,每个代理都是某一领域的专家,彼此之间通过中心控制器(Orchestrator)进行通信与协调。
举个例子,在一个软件开发场景中:
- WebSurfer 代理负责网页搜索;
- FileSurfer 负责文件管理;
- Coder 负责编写代码;
- ComputerTerminal 负责执行程序;
- 而 Orchestrator 则作为“大脑”,调度上述所有代理。
这种设计让整个系统具备了像人类团队一样的协作模式:一个主管带领多个执行者,实时分工、汇报、反馈、调整。
如下图所示,Magentic-One 的架构逻辑清晰分层:
在实际任务中,比如提取图片中的 Python 代码、运行后生成 C++ 源码,再执行得到计算结果,系统的任务流是这样运转的:
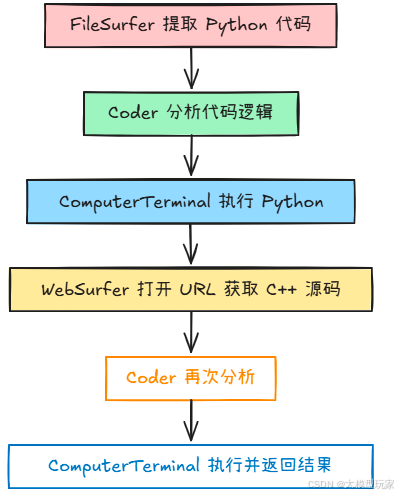
FileSurfer提取 Python 代码;Coder分析代码逻辑;ComputerTerminal执行 Python;WebSurfer打开 URL 获取 C++ 源码;Coder再次分析;- 最终由
ComputerTerminal执行并返回结果。
整个过程由 Orchestrator 全程监督调度。
这套体系的关键优势在于:
- 各代理功能独立但可协作;
- 流程具备弹性和可恢复性;
- 具备“动态自适应”的能力,能根据环境变化实时调整。
这正是 LangGraph 的 Supervisor 架构 所要实现的目标。
二、LangGraph的Supervisor架构是什么?
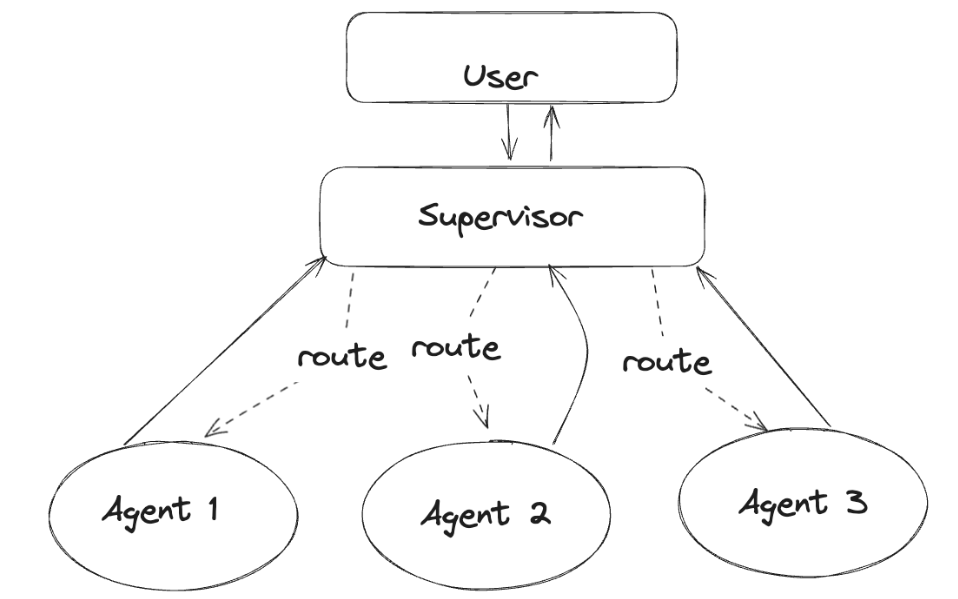
它的核心思想就是:分工明确 + 中央协调 + 动态路由。
LangGraph 的 Supervisor 就是把这种思想“图化”,把调度逻辑用状态图(StateGraph)表达出来,便于可视化、调试与扩展。它作为中央调度中心,负责协调多个子代理(Worker Agents)的工作流。简单说,它就是图中的一个特殊节点,充当多代理工作流中的中央控制器。
整个流程是这样的:
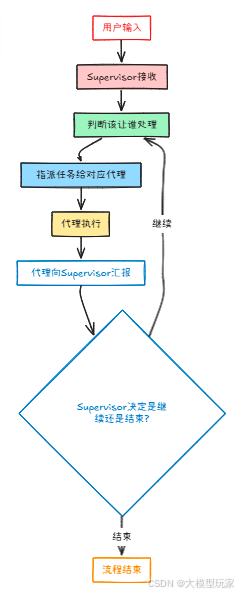
用户输入 → Supervisor接收 → 判断该让谁处理 → 指派任务给对应代理 → 代理执行完后向Supervisor汇报 → Supervisor决定是继续还是结束。
这种架构有个巨大的优势:灵活性。随着需求变化或新代理的加入,系统可以动态调整工作流程。特别是在客户服务这类动态环境中,查询和需求不断变化,这种架构就显得特别有用。
三、如何用代码实现?
我们来看一个实际的例子。假设要搭建一个包含三个功能的系统:
- Chat代理:处理常规对话
- Coder代理:处理代码生成和执行
- SQLer代理:处理数据库相关操作
首先要定义系统的状态。在LangGraph中,通过StateGraph来实现:
class AgentState(MessagesState):
next: str
然后定义Supervisor节点的行为。这个节点需要读取当前的消息,分析用户需求,然后决定下一步该调用哪个代理。关键技术是利用结构化输出强制LLM返回特定格式:
class Router(TypedDict):
next: Literal["chat", "coder", "sqler", "FINISH"]
next 字段就是Supervisor的决策结果。
然后分别定义三个子代理节点。这里有个很重要的细节——每个代理在返回结果时,都要标上自己的名字。这样Supervisor才能知道这条消息是谁产生的:
def chat(state: AgentState):
messages = state["messages"][-1]
model_response = llm.invoke(messages.content)
final_response = [HumanMessage(content=model_response.content, name="chat")]
return {"messages": final_response}
最后把所有节点和边连接起来:
builder = StateGraph(AgentState)
builder.add_node("supervisor", supervisor)
builder.add_node("chat", chat)
builder.add_node("coder", coder)
builder.add_node("sqler", sqler)
# 所有代理完成任务后都向主管汇报
for member in members:
builder.add_edge(member, "supervisor")
# 根据Supervisor的决策进行路由
builder.add_conditional_edges("supervisor", lambda state: state["next"])
# 从开始就连接到Supervisor
builder.add_edge(START, "supervisor")
graph = builder.compile()
这样就搭好了基本框架。测试时问它"帮我生成一个二分查找的Python代码",系统会自动判断该用Coder代理;问"我想查询数据库中的数据",它就会调用SQLer代理。
四、实战案例:构建具备数据库与分析能力的多代理系统
我们可以把这个思路用到一个真实场景:搭建一个包含数据库管理员和数据分析师的多代理系统。
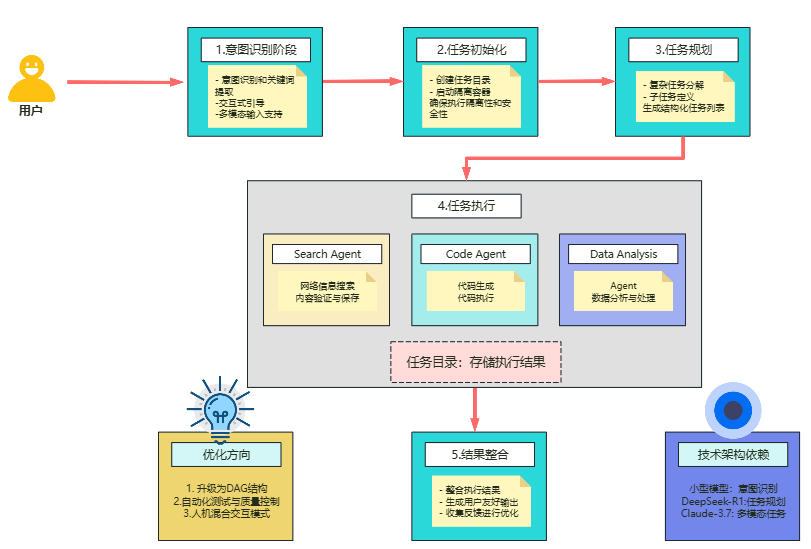
数据库管理员(db_agent)负责对接数据库,提取数据。数据分析师(code_agent)拿到数据后用Python进行分析,生成可视化图表。Supervisor在其中扮演协调者的角色,判断用户需求,然后分别指派任务。
用户说"帮我生成前10名销售记录的柱状图",流程就是:
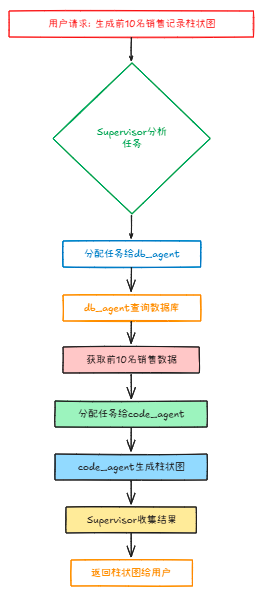
- Supervisor分析,这需要数据库代理和代码代理
- 先让db_agent查询数据库拿出前10名的销售记录
- 再让code_agent根据这些数据生成柱状图
- 最后Supervisor收集结果,返回给用户
整个过程对用户来说是无感知的,但背后的协调工作很复杂。
下面是一份完整的 Python 脚本,基于 SQLite,包含三个子代理(chat、sqler、coder)和一个 Supervisor。
# 文件名:langgraph_supervisor.py
#LangGraph
Supervisor 多代理示例(SQLite 后端 + Python 执行工具)
import os
import getpass
import random
from typing import Literal
from typing_extensions import TypedDict
# 数据库
from sqlalchemy import create_engine, Column, Integer, String, Float
from sqlalchemy.orm import sessionmaker, declarative_base
# 生成假数据
from faker import Faker
# Pydantic
from pydantic import BaseModel
# LLM/工具和 LangGraph(按本地版本调整导入)
try:
from langchain_openai import ChatOpenAI
except Exception:
from langchain import OpenAI as ChatOpenAI # 兼容方案
try:
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
except Exception:
from langchain.tools import tool
from langchain.schema import HumanMessage
try:
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.prebuilt import create_react_agent
except Exception as e:
raise RuntimeError("请确认已安装并可导入 langgraph。按需调整导入路径。")
# 可选的 PythonREPL
try:
from langchain_experimental.utilities import PythonREPL
except Exception:
PythonREPL = None
# -------------------------
# 1. 配置 LLM
# -------------------------
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("请输入你的 OPENAI_API_KEY: ")
# 这里示例用 gpt-4o-mini;如无此模型请替换为本地或小模型
llm = ChatOpenAI(model="gpt-4o-mini")
# -------------------------
# 2. 本地 SQLite 数据库与 ORM
# -------------------------
Base = declarative_base()
class SalesData(Base):
__tablename__ = 'sales_data'
sales_id = Column(Integer, primary_key=True, autoincrement=True)
product_id = Column(Integer)
employee_id = Column(Integer)
customer_id = Column(Integer)
sale_date = Column(String(50))
quantity = Column(Integer)
amount = Column(Float)
discount = Column(Float)
DB_FILE = "sales_demo_cn.sqlite"
DB_URI = f"sqlite:///{DB_FILE}"
engine = create_engine(DB_URI, echo=False)
Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)
def seed_data_if_empty(n=100):
session = Session()
if session.query(SalesData).count() > 0:
session.close()
return
fake = Faker()
for _ in range(n):
s = SalesData(
product_id=random.randint(1, 10),
employee_id=random.randint(1, 8),
customer_id=random.randint(1, 40),
sale_date=fake.date_between(start_date="-120d", end_date="today").isoformat(),
quantity=random.randint(1, 20),
amount=round(random.uniform(10, 1200), 2),
discount=round(random.uniform(0, 0.3), 2)
)
session.add(s)
session.commit()
session.close()
print(f"已初始化并插入 {n} 条示例数据到 {DB_FILE}")
seed_data_if_empty(120)
# -------------------------
# 3. 定义工具
# -------------------------
class AddSaleSchema(BaseModel):
product_id: int
employee_id: int
customer_id: int
sale_date: str
quantity: int
amount: float
discount: float
class DeleteSaleSchema(BaseModel):
sales_id: int
class UpdateSaleSchema(BaseModel):
sales_id: int
quantity: int
amount: float
class QuerySalesSchema(BaseModel):
sales_id: int
@tool(args_schema=AddSaleSchema)
def add_sale(product_id, employee_id, customer_id, sale_date, quantity, amount, discount):
"""添加销售记录"""
session = Session()
try:
rec = SalesData(
product_id=product_id,
employee_id=employee_id,
customer_id=customer_id,
sale_date=sale_date,
quantity=quantity,
amount=amount,
discount=discount
)
session.add(rec)
session.commit()
return {"messages": ["添加成功。"], "sales_id": rec.sales_id}
except Exception as e:
return {"messages": [f"添加失败,错误:{e}"]}
finally:
session.close()
@tool(args_schema=DeleteSaleSchema)
def delete_sale(sales_id):
"""删除销售记录"""
session = Session()
try:
rec = session.query(SalesData).filter(SalesData.sales_id == sales_id).first()
if not rec:
return {"messages": [f"未找到 sales_id={sales_id} 的记录。"]}
session.delete(rec)
session.commit()
return {"messages": [f"删除成功:{sales_id}"]}
except Exception as e:
return {"messages": [f"删除失败,错误:{e}"]}
finally:
session.close()
@tool(args_schema=UpdateSaleSchema)
def update_sale(sales_id, quantity, amount):
"""更新销售记录"""
session = Session()
try:
rec = session.query(SalesData).filter(SalesData.sales_id == sales_id).first()
if not rec:
return {"messages": [f"未找到 sales_id={sales_id} 的记录。"]}
rec.quantity = quantity
rec.amount = amount
session.commit()
return {"messages": [f"更新成功:{sales_id}"]}
except Exception as e:
return {"messages": [f"更新失败,错误:{e}"]}
finally:
session.close()
@tool(args_schema=QuerySalesSchema)
def query_sales(sales_id):
"""查询销售记录"""
session = Session()
try:
rec = session.query(SalesData).filter(SalesData.sales_id == sales_id).first()
if not rec:
return {"messages": [f"未找到 sales_id={sales_id} 的记录。"]}
return {
"sales_id": rec.sales_id,
"product_id": rec.product_id,
"employee_id": rec.employee_id,
"customer_id": rec.customer_id,
"sale_date": rec.sale_date,
"quantity": rec.quantity,
"amount": rec.amount,
"discount": rec.discount
}
except Exception as e:
return {"messages": [f"查询失败,错误:{e}"]}
finally:
session.close()
# Python REPL:用于 code_agent 执行生成的 Python(请勿在非受控环境执行任意代码)
if PythonREPL is not None:
repl = PythonREPL()
@tool
def python_repl(code: str):
"""执行 python 代码并返回 stdout"""
try:
result = repl.run(code)
return f"执行成功,输出:{result}"
except Exception as e:
return f"执行失败,错误:{repr(e)}"
else:
@tool
def python_repl(code: str):
"""简易执行器(仅用于本地演示,禁止危险模块)"""
banned = ["os", "sys", "subprocess", "socket", "shutil"]
if any(b in code for b in banned):
return "拒绝执行包含危险模块的代码。"
local_vars = {}
try:
exec(code, {"__builtins__": __builtins__}, local_vars)
return f"执行结束,本地变量:{list(local_vars.keys())}"
except Exception as e:
return f"执行失败,错误:{repr(e)}"
# -------------------------
# 4. 创建 ReAct 风格的 Agents
# -------------------------
db_agent = create_react_agent(
llm,
tools=[add_sale, delete_sale, update_sale, query_sales],
state_modifier="你是数据库代理。接收用户请求并调用数据库工具(增删改查)。返回结果需清晰、结构化,必要时返回 sales_id。"
)
code_agent = create_react_agent(
llm,
tools=[python_repl],
state_modifier="你是代码代理。根据输入的数据生成可运行的 Python 代码来分析或绘图,并执行后返回结果或文件路径。若生成代码,请在最后用 print() 输出关键结果。"
)
# -------------------------
# 5. 将 agents 封装为图节点(回报时包含 name 字段)
# -------------------------
def db_node(state):
res = db_agent.invoke(state)
content = res["messages"][-1].content if res["messages"] else "无返回"
# 把 name 设置为 sqler 便于 supervisor 识别
return {"messages": [HumanMessage(content=content, name="sqler")]}
def code_node(state):
res = code_agent.invoke(state)
content = res["messages"][-1].content if res["messages"] else "无返回"
return {"messages": [HumanMessage(content=content, name="coder")]}
def chat_node(state):
# chat 用 LLM 直接回答
msg = state["messages"][-1]
resp = llm.invoke(msg.content)
return {"messages": [HumanMessage(content=resp.content, name="chat")]}
# -------------------------
# 6. Supervisor
# -------------------------
members = ["chat", "coder", "sqler"]
options = members + ["FINISH"]
class Router(TypedDict):
next: Literal["chat", "coder", "sqler", "FINISH"]
class AgentState(MessagesState):
next: str
def supervisor(state: AgentState):
system_prompt = (
"你是一个监督者(Supervisor),负责在以下代理之间分配任务:chat, coder, sqler。\n\n"
"每个代理的职责:\n"
"- chat:使用自然语言直接回应用户问题,做一般性解释与对话。\n"
"- coder:生成并(在安全沙箱中)执行 Python 代码,用于数据分析或绘图,返回执行结果或图像路径。\n"
"- sqler:执行数据库相关操作(增删改查),并返回结构化数据或操作状态。\n\n"
"请根据下列对话上下文判断接下来应该由哪个代理执行任务,并以 JSON 格式仅返回一个字段 next,值必须是以下之一:"
f"{options}。如果任务已经完成,请返回 FINISH。\n\n"
"注意:输出必须是严格的 JSON,例如:{\"next\":\"sqler\"}。不要返回其他任何多余文本。"
)
messages = [{"role": "system", "content": system_prompt}] + state["messages"]
try:
# 优先使用结构化输出能力(若 LLM wrapper 支持)
response = llm.with_structured_output(Router).invoke(messages)
next_ = response["next"]
except Exception:
# 作为后备方案:解析模型的文本回答寻找关键字
raw = llm.invoke(messages).content
nxt = None
for m in options:
if m in raw:
nxt = m
break
next_ = nxt or "FINISH"
if next_ == "FINISH":
next_ = END
return {"next": next_}
# -------------------------
# 7. 构建 StateGraph
# -------------------------
builder = StateGraph(AgentState)
builder.add_node("supervisor", supervisor)
builder.add_node("chat", chat_node)
builder.add_node("coder", code_node)
builder.add_node("sqler", db_node)
# 子代理执行后回到 supervisor
for mem in members:
builder.add_edge(mem, "supervisor")
# conditional edge:由 state["next"] 指定
builder.add_conditional_edges("supervisor", lambda state: state["next"])
builder.add_edge(START, "supervisor")
graph = builder.compile()
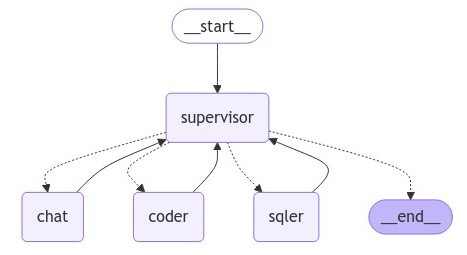
# 显示图(可选)
try:
from IPython.display import Image, display
display(Image(graph.get_graph(xray=True).draw_mermaid_png()))
except Exception:
pass
# -------------------------
# 8. 测试与演示
# -------------------------
def demo_queries():
qs = [
"你好,请用简单介绍你自己。",
"请帮我查询 sales_data 表中 sales_id=1 的记录。",
"请帮我删除 sales_id=5 的记录。",
"请根据最近 10 条销售记录绘制销售额柱状图,并返回结果(你可以生成并执行 Python 代码)。",
"请添加一条销售记录:product_id=3, employee_id=2, customer_id=7, sale_date=2025-10-10, quantity=5, amount=299.9, discount=0.05"
]
for q in qs:
print("\n\n====== 用户请求:", q)
all_chunks = []
for chunk in graph.stream({"messages": q}, stream_mode="values"):
all_chunks.append(chunk)
if "messages" in chunk and chunk["messages"]:
print("-> 步骤返回:", chunk["messages"][-1].content)
if all_chunks:
last = all_chunks[-1]
if "messages" in last and last["messages"]:
print("最终返回:", last["messages"][-1].content)
if __name__ == "__main__":
print("启动 LangGraph Supervisor")
demo_queries()
print("示例运行结束。")
五、需要注意的坑
用LangGraph构建Supervisor系统虽然很高效,但也有些问题值得关注。
比较常见的一个现象是:Supervisor会陷入"自言自语"的循环。它不断地把一个代理的输出再发给自己,来回折腾,导致Token消耗暴增,响应速度也变慢。
还有一个问题是决策的准确性。有时候Supervisor可能会做出不太合理的选择,导致系统走错方向。
这些问题都需要根据具体的业务逻辑和所用LLM的特性来针对性调整。比如优化system prompt、调整温度参数、或者给Supervisor加上额外的决策规则。
六、总结
Supervisor 把多代理系统从“各自为政”提升为“有序协作”。它的价值体现在三点:
- 结构化的任务调度:Supervisor 通过状态控制图,实现了任务的动态编排。
- 可扩展的代理体系:可以随时接入新的专业代理而无需重构流程。
- 自适应的智能决策:通过大模型理解上下文并实时规划下一步。
未来,多智能体系统的发展方向,就是让这些“主管”和“员工”之间的协作更加自然,最终演化为一个可以自动理解目标、动态规划路径、自主执行任务的“智能组织”。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
更多推荐
 22
22 0
0- 0



 已为社区贡献307条内容
已为社区贡献307条内容

所有评论(0)