
语言模型监督式微调(SFT)概述
监督式微调(SFT)是将通用语言模型转化为特定任务模型的关键方法。其核心流程包括:预训练模型准备、任务相关数据集构建、模型微调训练和效果评估。SFT通过最小化响应交叉熵损失,使模型学会模仿预期行为。最佳应用场景包括激发新行为、提升推理能力和工具使用能力。高质量数据是SFT成功的关键,需采用蒸馏、拒绝采样和过滤等策略。微调方式可选择全参数更新或参数高效方法(LoRA等),需在性能和资源间权衡。SFT
一、SFT流程简述
监督式微调是一种把通用语言模型转化为特定类型模型的方法,其旨在使用提示-响应对数据,对语言模型进行再次训练,以达到我们预期的效果。其流程简述为以下四步:
1. 预先训练语言模型
先在庞大数据集上训练出一个泛用型的语言模型,也可以从模型网站Hugging Face上下载已训练好的模型。
2. 准备数据集
从模型需要完成的任务或者做出的行为出发,寻找相关领域的提示-响应对或者助手回复的提示-响应对。
3. 进行SFT训练
将模型在数据集上进行监督式微调处理,即通过最小化响应的交叉熵损失来进行训练。
4. 进行模型评估
将训练好的模型进行系统评估,以判断是否达到期望标准。
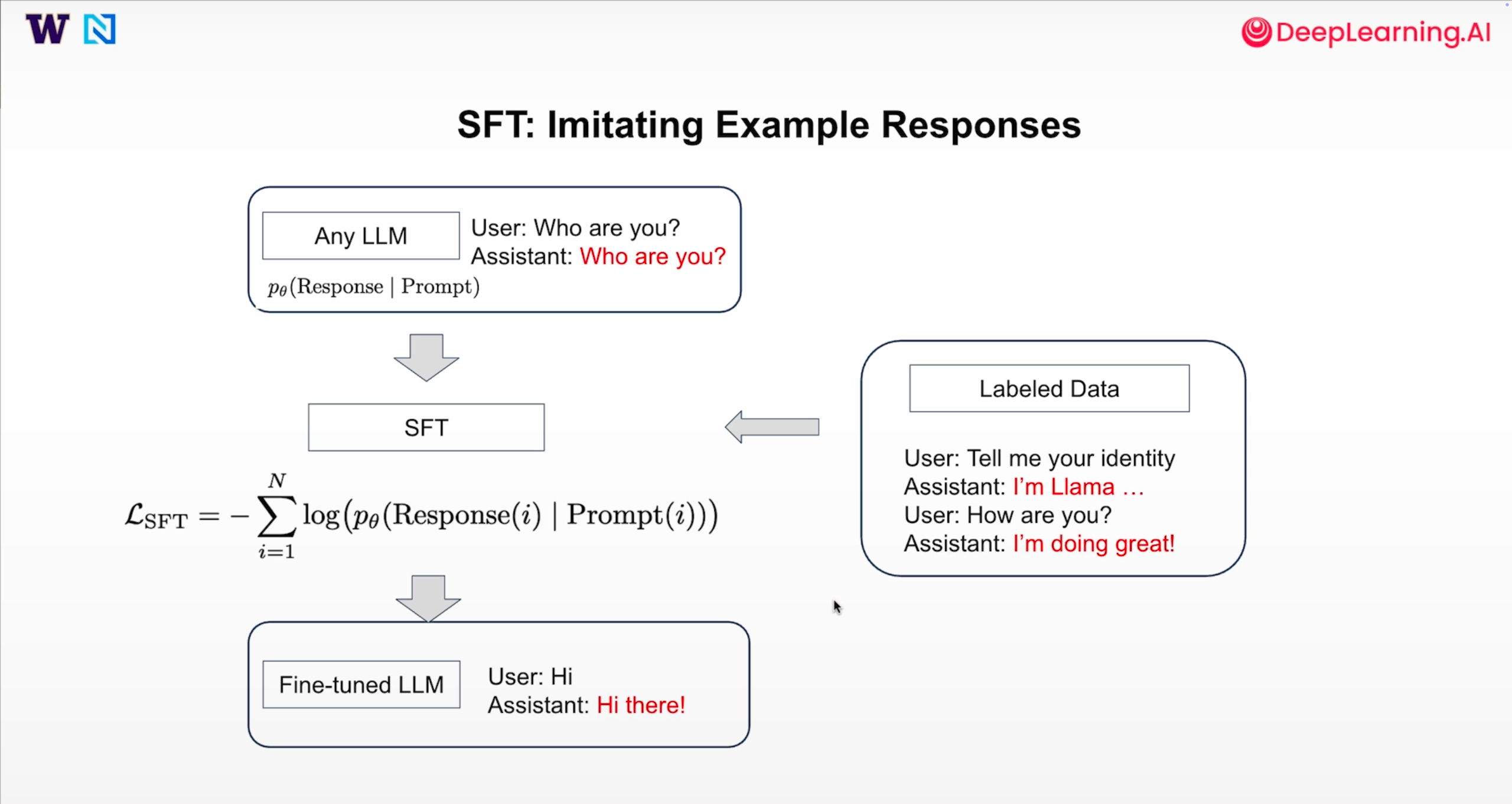
以上的损失函数公式本质上是在最大化给定提示i下所有响应token的联合概率分布,如果模型输出偏离响应标签会增大熵,因此SFT实际上是在教会模型“模仿”,这好比一个在大学学习的学生,学的东西泛而浅,他出来工作时需要学习公司的办事方式和沟通表达等等。
二、SFT的最佳使用场景
1. 激发模型新的行为
- 将预训练的没有固定格式的模型变为能遵守指令的模型
- 让不具备推理能力的模型具备基本的推理能力
- 让模型在没有明说的情况下默认使用某个工具
2. 提示模型能力
- 通过大模型生成高质量数据,通过“模型蒸馏”方式转移到我们的模型中

三、SFT 数据策划原则
在 SFT(监督微调)过程中,数据质量是决定最终效果的核心变量,其影响力远超数据数量。高质量、多场景的训练样本能引导模型学习合规且高效的输出模式,而低质量样本则会导致模型习得错误逻辑或不当表达,形成 “坏习惯”。
主流 SFT 数据构建策略
- 蒸馏策略:借助性能更优的指令模型生成高质量回复,再以这些回复为目标,训练参数规模更小的模型。该方法可有效将大模型的核心能力迁移至轻量模型,降低部署成本。
- Best-of-K / 拒绝采样:针对同一条输入提示,生成 K 个不同的候选回复。通过预设的奖励函数对这些候选进行打分,筛选出评分最高的回复作为训练样本,确保数据的优质性。
- 过滤策略:从大规模原始 SFT 数据集中,依据 “回复质量高” 和 “提示场景多样” 两个核心标准进行筛选,最终形成规模精简但质量过硬的训练数据集。
核心原则:质量优先于数量
SFT 的本质是让模型 “模仿所见数据”,这种模仿具有无差别性 —— 模型会同时学习数据中的优点与缺陷。因此,1000 条经过精心筛选、覆盖多类场景的优质样本,其训练效果通常优于 100 万条质量参差不齐的样本,前者能精准塑造模型行为,后者则可能引入大量噪声,拖累模型性能。

全参数微调与参数高效微调的对比
在进行 SFT(或其他模型对齐方法)时,核心决策之一是确定模型权重的更新方式:
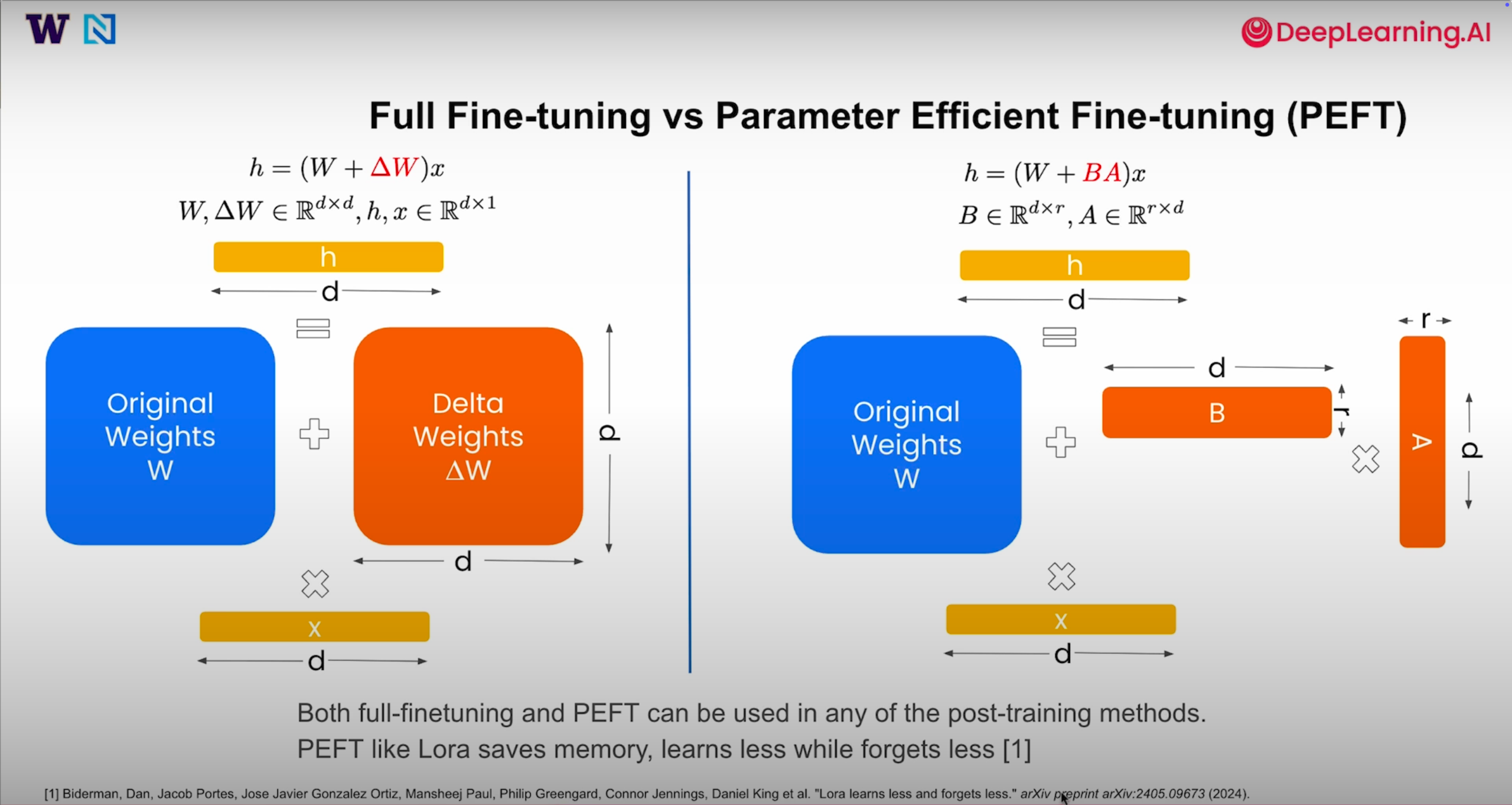
-
全参数微调:为模型每一层都配置完整的权重更新矩阵\(\Delta W\),即对所有参数进行调整。这种方式能带来显著的性能提升,但相应地需要庞大的存储资源和计算能力支持。
-
参数高效微调:以 LoRA(低秩适配)为例,其通过在每一层引入小型低秩矩阵 A 和 B 来实现参数调整。这种方法大幅减少了可训练参数的数量,有效节省显存空间,但存在局限性 —— 由于更新的参数规模较小,模型的学习能力和遗忘能力都会受到一定限制。
这两种微调策略可与任何训练方法结合使用。实际应用中,可根据资源约束和性能需求选择:追求极致性能且资源充足时可选全参数微调;硬件条件有限时,参数高效微调则成为更受欢迎的选择。
总结
监督式微调是语言模型对齐过程中的基础且重要的方法。其核心原理是通过最小化目标回复的负对数似然,使模型学会模仿预期行为,并能针对提示做出恰当回应。
SFT 的优势在于:特别适合启动新行为,以及实现从大模型向小模型的能力 "蒸馏"。
但需重点注意:数据质量对 SFT 效果起决定性作用 —— 采用蒸馏、拒绝采样、过滤等策略处理的数据,其训练效果远胜于简单堆砌大量普通数据。
而全参数微调与参数高效微调的选择,本质上是在性能表现与资源消耗之间寻找平衡。
以上来源DataWhale的打卡学习活动,学习内容来自:https://github.com/datawhalechina/Post-training-of-LLMs/tree/main/docs/chapter1
更多推荐


 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)