
写文章




- @qq_52176723
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
直接偏好优化 (DPO) 基础理论
DPO(直接偏好优化)是一种基于对比学习的大模型微调技术,通过在正负样本对中学习人类偏好来优化模型表现。其核心是使用特殊设计的损失函数,最大化正样本优势并最小化负样本优势。相比传统监督微调,DPO更适合模型行为微调(如身份标识修改、多语言优化等)和能力提升。高质量数据构建可通过校正法或策略内生成法实现,需注意保持样本多样性避免过拟合。DPO能有效提升模型对齐人类偏好的能力,是微调领域的重要方法。
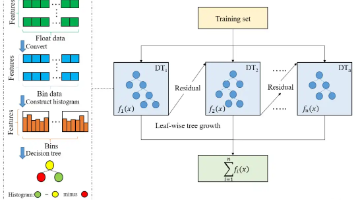
LightGBM时序预测详解:从原理到 PSO 参数优化
本文介绍了利用LightGBM和粒子群优化(PSO)算法进行时间序列预测的方法。LightGBM作为一种高效的梯度提升决策树框架,通过直方图算法和Leaf-wise生长策略,特别适合处理大规模时序数据。PSO算法则通过模拟群体智能,高效搜索LightGBM的最优参数组合。文章详细阐述了LightGBM的原理、优势及在时序预测中的应用,并提供了完整的PSO优化LightGBM的实战代码,包括参数定义
自动寻最优参的ARIMA模型--pmdarima
网格搜索理论相对简单,确定好模型取值参数,使用遍历循环带入,获取每个模型的评估指标值(ARIMA采用AIC或者BIC值,越小代表模型越好)。这里采用模拟数据集来作为演示。"""自动选择最优ARIMA参数"""# 生成所有可能的(p,d,q)组合# 网格搜索try:continueprint(f"最优参数: {best_order}, AIC: {best_aic}")# 对2090年后的数据进行预
一维搜索--牛顿法与割线法原理推导和MatLab实验收敛速度对比
本文从数学推导加matlab实验验证的角度,对牛顿法,拟牛顿法中的双割线法和单割线法进行了优劣比较。

到底了