
智能Agent+MCP打造前端开发新范式,值得收藏!
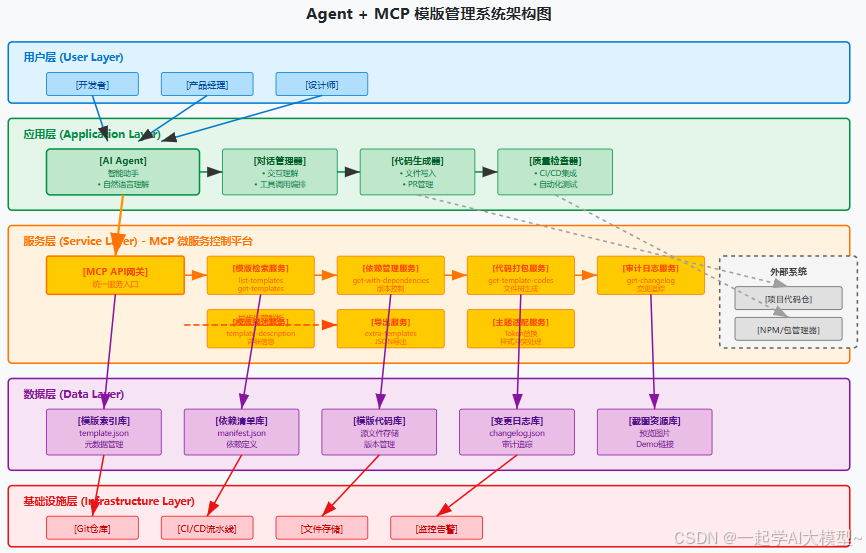
本文介绍如何将前端模版库封装为MCP平台并配合智能Agent,实现从需求到代码的自动生成闭环。通过将系统拆分为Agent(交互理解层)和MCP(服务层),解决了模版选择、落地和维护成本高的问题。文章详细介绍了工具设计、交互流程、数据结构和工程实现要点,帮助团队实现可审计、可回滚的模版复用流程,从根本上提升开发效率和协作质量。
在实际项目里,UI 风格和模版库一度是“既是利器又是绊脚石”。模版越多,团队越容易通过复用加速开发;但当模版数量和复杂度上来后,找到合适模版、处理模版内部依赖、把模版快速落地到代码仓,就成了一件耗时又易错的事。我们团队把现有前端模版库封装为一个 MCP(微服务/模版控制平台)并配合智能 Agent,目标不是单纯“智能推荐模版”,而是做到:用户说出需求,Agent 找到最合适的模版并把代码写到项目里.
一、为什么把模版库“服务化”比你想的更值钱
很多团队的模版库厌倦地躺在 git 里或共享盘上,大家认为“复用”是美德,结果却是“人找模版,模版找人、代码找依赖”。出现的典型痛点有三类:
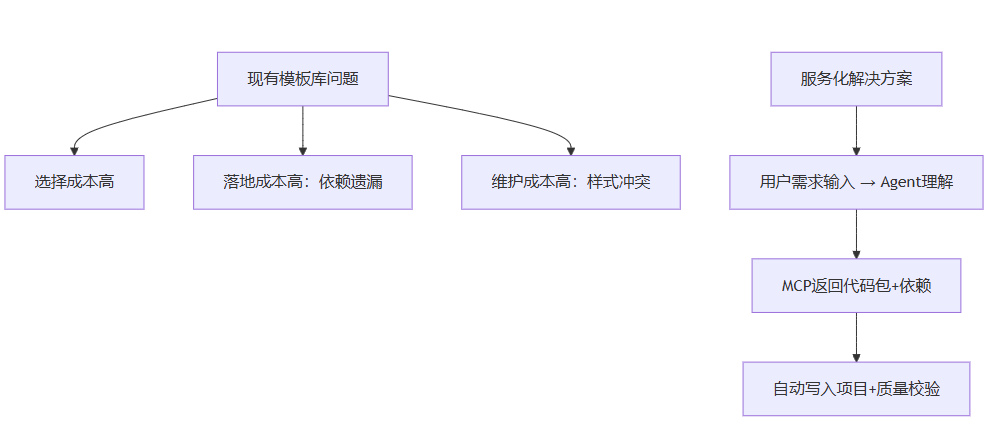
- 选择成本高:模版多时,开发要花时间筛选最合适的那一个;
- 落地成本高:模版往往不是孤立的,会引用子组件、样式、工具函数,复制时容易遗漏;
- 维护成本高:不同项目对主题、样式、变量的细微差异会导致“复用”变成“改造”。
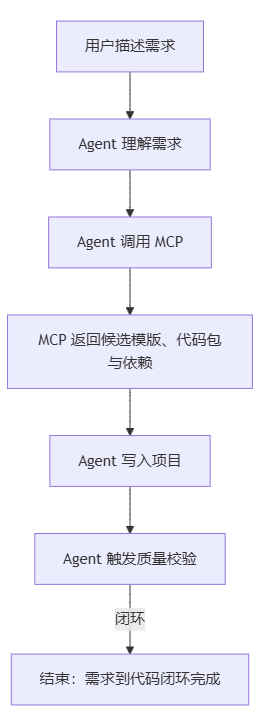
把模版库“服务化”并不是为了解决“找不到模版”的问题,而是为了实现“从需求到代码”的闭环:用户用自然语言或简单表单描述需求 → Agent 理解并调用 MCP → MCP 返回候选模版、代码包与依赖 → Agent 写入项目并触发质量校验。这样,每次复用都像调用一次可靠的生产线,而不是手工装配。
如果你的团队开始感到“模版复用”变成了负担,那就到了把模版库做成可编程服务的时刻。
接下来我们进入设计思路与能力拆分:Agent 做什么,MCP 做什么。
二、能力拆分 —— Agent 与 MCP 的角色边界(为什么要这样分?)
要把“模版复用”做好,核心不是 AI 会不会推荐,而是职责划分清晰。我们把系统拆成两层:
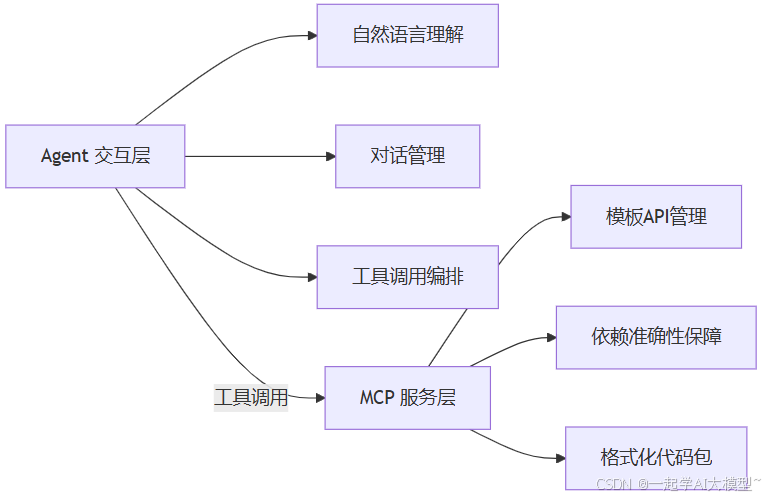
- Agent(交互理解层):它和人对话,理解场景(例如“列表页,带筛选、分页、批量”),负责确认细节(列字段、数据来源、本地 state 还是服务端分页),并把“意图”转成一系列可执行的工具调用。Agent 的强处是语言理解 + 对话管理 + 工具调用编排。
- MCP(模版/代码服务层):把模版库抽象成一组 API(列模版、按标签筛选、拉取代码包、一次性拉取依赖、导出模版快照、查看变更日志等),负责数据管理、版本与依赖的准确性、以及把模版按规则格式化成“可写入项目”的文件包。MCP 的强处是数据与格式化的可靠性。
为什么要这样?因为交互和数据处理是两种完全不同的能力:交互需要模糊理解和确认,数据处理需要严格的规范和可回溯性。把它们分开,你能既保证沟通顺畅,又保证代码落地可控、安全。
理解了角色分工,下面我会列出我们实现的 MCP 工具清单,并说明每个工具的使用场景与输出格式,便于开发者复制落地。
三、MCP 工具清单(全方位接口,用一句话概括每个工具为什么必须存在)
在实践中,我们把 MCP 暴露成若干“工具函数”,Agent 可以直接调用。下面是清单,后面我会用真实场景把它们串联起来:
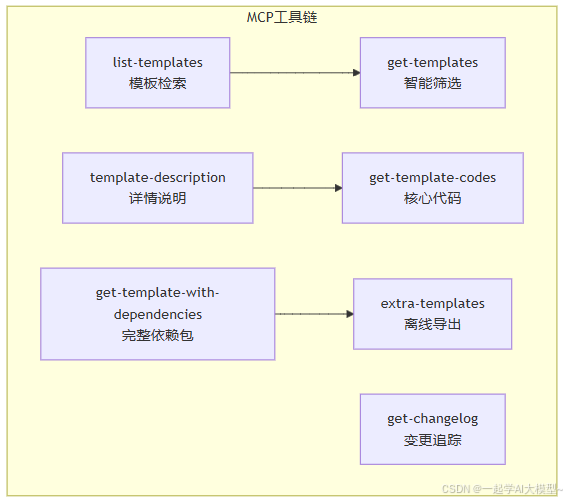
- list-templates —— 返回当前所有可用模版(带 id、title、tags、brief) 场景:当用户只说“我要一个列表页”,Agent 先用这个接口列出候选项。
- template-description —— 返回单个模版的详细描述(功能点、适配场景、注意事项、示例截图/代码片段) 场景:帮助用户在多个候选间作出决策,避免选择不匹配的模版。
- get-template-codes —— 获取模版的核心代码文件(组件/页面) 场景:用户预览或想把核心文件单独拿出来看时使用。
- get-template-with-dependencies —— 一次性把模版及其所有依赖(子组件、样式、工具函数)返回成完整文件树 场景:自动写入项目时必用,解决“忘带依赖”的痛。
- extra-templates —— 将当前可用的模版信息导出为 json(便于离线审计或做版本快照) 场景:设计或产品要审查当前模版池时,直接导出给非开发人员查看。
- get-templates(聚合/过滤查询)—— 一个更强的查询引擎,可以按 tag、复杂度、适用端、维护活跃度过滤 场景:当 Agent 要自动推荐最优模版时,用它做排序打分。
- get-changelog(或 changelog.json) —— 查询模版变更历史 场景:用户或审核者想知道某个模版是否近期改动或有 bug 修复记录时使用。
- template.json + src 路径 —— 数据存储与代码物理位置(用于检索与写入) 场景:文件写入、回滚、版本管理都依赖这一块的准确性。
每个接口都有明确场景,Agent 只需要把“需求”转成这些接口的参数即可。
下面把这些工具放到一个真实的对话和执行流程里,看整个链条如何运行。
四、从“我要一个列表页”到“代码已推 PR”——完整交互与执行流程(逐步演示)
下面以用户一句话为起点,演示 Agent + MCP 的真实执行流程,同时说明每步背后的设计考量。

用户:我要一个列表页,支持搜索、服务端分页和批量删除,样式要跟当前项目一致。
Agent 执行步骤(详解):
- 意图解析(Agent)
-
Agent 把自然语言解析成结构化请求:
{pageType: "list", features: ["search","server-pagination","batch-delete"], theme: "project-default"} -
设计要点:把“feature”标准化成 tags(search、pagination-server、batch)以便于 MCP 过滤。
- 候选检索(Agent → list-templates/get-templates)
- Agent 调用
get-templates?tags=[list,search,pagination-server]得到 3 个候选:tpl-list-v1、tpl-advanced-table、tpl-light-list。每个包含 brief 与 score(usageCount、lastUpdated、match度)。 - 交互策略:Agent 按得分降序展示 3 个简要信息和截图,避免给用户 50 个选项造成选择疲劳。
- 候选说明(Agent → template-description)
- 用户选中两个候选仍犹豫,Agent 进一步请求
template-description返回每个的适配细节(例如:tpl-list-v1 更倾向服务端分页,tpl-advanced-table 内置复杂筛选插件但样式偏企业蓝)。 - 设计要点:描述中包含“是否破坏现有项目依赖”的字段,以便判断写入风险。
- 获取代码包(Agent → get-template-with-dependencies)
- 用户确认
tpl-list-v1,Agent 请求完整包,得到文件树:/templates/list/standard/{index.jsx, table.jsx, styles.module.css, utils/fetcher.js, components/BatchActions/index.jsx}。 - 可靠性设计:每个文件都有 hash 与 manifest 中列出的依赖声明(比如依赖
@company/table),Agent 同时得到依赖安装建议。
- 写入策略选择(Agent 与用户确认)
- Agent 提示:你要“创建新目录”还是“合并到 existing/path/list.jsx”?默认给出安全选项:
create new folder并自动生成分支feat/agent/tpl-list-v1并发起 MR(PR)。这一步强制二次确认,避免覆盖。
- 自动化质量门(Agent → CI)
- Agent 在写入并开 PR 后触发 lint、单测、样式检查。若失败,Agent 将错误日志回传给用户并建议修复方案(例如:样式变量冲突 → 建议替换 theme token)。
- 记录与变更历史(MCP → changelog.json 更新)
- 写入成功后,MCP 更新
changelog.json,记录此次落地(谁、何时、哪个模版、写入路径、PR 链接)。
- 最终反馈(Agent)
- Agent 给用户一句话结论:
已在 repo 创建分支 feat/agent/tpl-list-v1 并提交 PR #123;CI 全绿;演示地址:...。并可直接打开 Demo 页面或生成预览截图给产品验收。
每一步都离不开前一步的数据与决策(意图→候选→描述→完整包→写入策略→质量门→记录),这是闭环的关键。
接下来展示我们项目里实际使用的数据结构与 manifest 样例,便于复制。
五、数据结构与 manifest 示例
要把上面流程变成可执行的工程实现,最关键的两个文件是 template.json(模版目录索引)和每个模版目录下的 manifest.json。下面给出可直接拷贝的示例,并解释每个字段为什么必须存在。

template.json(核心索引,片段示例)
{
"templates": [
{
"id": "tpl-list-v1",
"fatherTitle": "列表页模版",
"title": "标准列表页(搜索+分页+批量)",
"description": "支持服务端分页和本地筛选,集成通用表格组件,含批量操作按钮和多列配置。",
"tags": ["list","search","pagination-server","batch"],
"path": "templates/list/standard",
"screenshot": "https://assets.company.com/templates/list/standard/snap.png",
"usageCount": 42,
"lastUpdated": "2025-07-10T10:00:00Z"
}
]
}
字段说明:tags 用来快速匹配,screenshot 提升可视化选择体验,usageCount 用于打分推荐。
templates/list/standard/manifest.json(模版自述与依赖)
{
"id": "tpl-list-v1",
"version": "1.2.0",
"files": [
"index.jsx",
"table.jsx",
"styles.module.css",
"components/BatchActions/index.jsx",
"utils/fetcher.js"
],
"dependencies": {
"npm": ["@company/table@^2.0.0"],
"peer": ["react@>=17.0.0"]
},
"themeTokens": ["--primary-color","--font-size-base"],
"notes": "需要项目提供通用 Table 组件,若无则可替换为内置 table.jsx"
}
字段说明:dependencies 明确外部依赖,Agent 可以在写入前注入安装建议或自动在 CI 中安装;themeTokens 用来做主题替换,避免样式冲突。
把 manifest.json 做成必须项并在模版提交流程里做校验,可以显著减少运行时依赖错误。
六、工程实现要点与场景策略(十条实战建议)
这一章直接给你团队能立即落地的工程建议,每条都来自我们在内部试点的经历。
- 模版必须有版本号:任何模版变更都记录为新版本,Agent 可选择旧版回滚。
- 强制 manifest.json:模版不合格不入库,依赖缺失一律拒绝上线。
- 预览优先:template.json 必须包含截图或 demoUrl,减少误选。
- 默认安全写入策略:Agent 写入默认创建新分支并开 MR,除非得到明确覆盖同意。
- CI 集成:写入触发 lint/test,失败回滚或阻塞合并。
- 主题变量替换器:项目主题 token 化,Agent 写入前做 token 替换,避免样式冲突。
- 权限与审计:写入权限分级,敏感项目需要审批。
- 打分策略:推荐模版时考虑匹配度、使用频次、最近修改时间、维护者活跃度。
- 灰度推广:先在内部 team 项目试点,再推广到全公司,收集反馈迭代模版质量。
10.异常回退机制:写入出错时,Agent 能自动关闭 PR 并恢复原状态,同时把错误原因写入 changelog。
这些建议与前文的接口设计、交互流程高度耦合——例如 “默认创建分支并开 MR” 必须由 Agent 的写入策略和 MCP 的写入 API 协同实现。
七、常见问题与对策(落地中必会遇到的坑)
实战里遇到的问题种类很多,我把最常见的列出来并给出可执行对策。
- 依赖丢失或版本冲突
- 症状:写入后运行报
Cannot find module或组件行为异常。 - 对策:强制 manifest、由 MCP 在拉取包前做依赖树校验;必要时生成自动 MR 安装依赖或在 CI 中安装并跑 smoke test。
- 样式/主题冲突
- 症状:颜色、间距与当前项目不一致,影响整体 UI。
- 对策:模版使用 theme token;Agent 写入前做 token 替换;必要时生成样式适配层(small shim)替换变量。
- 覆盖本地改动导致冲突
- 症状:Agent 直接覆盖导致开发历史丢失或功能被覆盖。
- 对策:默认生成新分支与 MR,由开发者 reviews;提供“smart merge”建议(仅合入不冲突的改动)。
- 模版过时、维护差
- 症状:老模版被大量使用但质量低,导致重复返工。
- 对策:增加模版评分与健康度指标(test coverage、lastUpdated、openIssues)并在 list 时排序提醒。
八、总结
把模版库做成服务,看起来像是“多一道工程”,其实是给团队减少每天的重复劳动,把时间留给真正有价值的事情——设计更好的交互、实现更复杂的业务逻辑。我们用 Agent + MCP 把“找模版、复制代码、补依赖”这类琐事变成了可审计、可回滚、可量化的工程流程。效果不仅是效率提升,还是复用质量与团队协作方式的根本改善。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
更多推荐


 8
8 0
0- 0



 已为社区贡献201条内容
已为社区贡献201条内容

所有评论(0)