
提示词工程指南(一):提示介绍 —— 兼论如何与AI愉快地“鸡同鸭讲”,大模型入门到精通,收藏这篇就足够了!
本指南是系列文章的第一篇,我们将从最基础的概念开始,带你一步步揭开提示词的神秘面纱。准备好了吗?让我们一起学习如何“调教”……啊不,是“引导”我们强大的AI伙伴吧!🚀
各位未来的“AI耳语者”(Prompt Engineer)们,大家好!欢迎来到这篇可能是你职业生涯中最不正经但绝对有用的技术文章。在2025年的今天,如果你还以为和AI(人工智能)对话,就像和楼下大爷聊天一样随性,那你就“out”啦!🤖
与大型语言模型(LLM)打交道,更像是在跟一个博学多才但偶尔有点“一根筋”的“灯神”许愿。你说得越精准,它实现的愿望就越靠谱;你说得含糊不清,它可能就会给你一头“会飞的猪”而不是一辆“会飞的汽车”。而“提示词工程”(Prompt Engineering),就是那本教你如何正确许愿的“神灯使用手册”。
这门学科的目标,就是通过精心设计和优化我们输入的“提示”(Prompt),让LLM这位超级大脑能够更高效、更准确地为我们服务,无论是在解答问题、写代码,还是进行文学创作等各种任务上。
本指南是系列文章的第一篇,我们将从最基础的概念开始,带你一步步揭开提示词的神秘面纱。准备好了吗?让我们一起学习如何“调教”……啊不,是“引导”我们强大的AI伙伴吧!🚀
第一章:基础提示概念与示例 —— “你好,AI,在吗?”
想象一下,你第一次见到一个功能强大的机器人,你对它说的第一句话是什么?“你好”?“你会干啥”?这些就是最原始、最基础的提示。
1.1 什么是提示(Prompt)?
从本质上讲,提示就是你向大型语言模型(LLM)发出的任何文本输入。它可以是一个问题、一段指令、一句未完的话,甚至只是一堆关键词。LLM会根据这个输入,动用它那庞大的“知识库”和“推理能力”,生成它认为最合适的后续文本。
一个基础的提示通常包含了你希望模型执行的任务或回答的问题。你可以把它看作是与AI沟通的“开场白”。
一个简单的提示示例:
提示:
天空为什么是蓝色的?
在这个例子里,我们直接提出了一个问题。对于一个训练有素的LLM来说,它会立刻理解你的意图,并开始解释瑞利散射等物理现象。
但问题来了,如果我们想让它扮演一个角色来回答呢?或者我们想让它用五岁小孩能听懂的语言来解释?这时候,简单的提问就不够了。一个更有效的提示需要包含更多信息。
一个稍微复杂点的提示示例:
提示:
作为一个拥有天体物理学博士学位的诗人,请用一首短诗来解释天空为什么是蓝色的。
看到区别了吗?我们不仅提出了问题,还给了AI一个 角色(诗人博士) 和 输出格式(短诗) 的要求。这就是提示工程的魅力所在——通过增加细节,精确地引导AI的输出方向。
1.2 提示的“威力”取决于信息量
记住一个核心原则:你给AI的信息越多、越具体,得到的结果就越接近你的预期 。只说“写个故事”,你可能会得到一个关于小猫咪的童话;但如果你说“写一个赛博朋克风格的短篇故事,主角是一个失去记忆的仿生人侦探,故事发生在新东京的雨夜”,那么结果的质量和方向性将截然不同。
这就像点菜,你只说“来个菜”,厨师可能会随便给你炒个青菜;但如果你说“来一份宫保鸡丁,多放花生,少放辣”,厨师才能精准地做出你想要的美味。提示词工程,就是教你如何成为一个懂得“点菜”的顶级吃货。😉
第二章:LLM 参数设置 —— AI 的“情绪”调节器
如果你以为只要写好提示词就万事大吉了,那可就太天真了!与LLM互动时,我们还能调整一些“旋钮”,来控制它的“创作风格”和“性格”。其中最重要、也最有趣的两个参数就是 temperature(温度)和 top_p。
2.1 Temperature (温度):AI的“创意兴奋剂”
Temperature参数控制着LLM输出的随机性。你可以把它想象成AI的“创意兴奋剂”或“胆量值” 。它的取值范围通常在0到1之间。
低 temperature (例如 0.1 - 0.3):
效果: AI会变得非常“冷静”和“保守”。它会倾向于选择最常见、最合乎逻辑的词语来构建句子。输出结果会非常确定、重复性高,适合需要事实、精准和逻辑的任务。
适用场景:
事实性问答(“法国的首都是哪里?”)
代码生成(需要精确无误的语法)
文本分类、信息提取等严谨任务。
像一个严谨的会计师,每一分钱都算得清清楚楚,绝不即兴发挥。
高 temperature (例如 0.7 - 0.9):
效果: AI会变得“热情奔放”、“脑洞大开”。它会敢于尝试不那么常见、更有创意的词汇组合,输出结果更多样、更有趣,甚至可能出人意料。
适用场景:
创意写作(写诗、写故事、想广告语)
头脑风暴(“给我10个关于环保APP的新点子”)
角色扮演或对话生成,让对话更自然、不刻板。
像一个喝了假酒的诗人,灵感如泉涌,佳句与“胡话”齐飞。
2.2 Top_p (核采样):AI的“专注力过滤器”
Top_p 参数,也叫核采样(Nucleus Sampling),它从另一个维度控制输出的多样性。它决定了AI在生成下一个词时,从多大的“候选词库”里进行选择 。top_p 的值是一个0到1之间的概率。
工作原理: 假设 top_p 设置为0.9。AI会计算出所有可能成为下一个词的概率,然后从高到低排序,并累加它们的概率。当累加概率达到0.9时,它就划定一个“核心词库”(Nucleus),并只在这个词库里进行随机选择。
低 top_p (例如 0.1):
效果: 核心词库非常小,只包含那几个概率最高的词。这使得AI的输出非常集中和确定,类似于低 temperature 的效果。
高 top_p (例如 0.95):
效果: 核心词库很大,包含了大量可能性,AI的选择范围更广,输出更多样化。
2.3 Temperature vs. Top_p:鱼与熊掌如何兼得?
这两者功能相似,但机制不同。一个常见的最佳实践是:通常只调整其中一个,而不是两个都调!因为同时调整它们,就像一边踩油门一边踩刹车,很难预测最终效果。
官方推荐: OpenAI等机构通常建议优先调整 temperature。
经验法则:
追求创意与多样性: 设置较高的 temperature (如 0.7-0.9),top_p 保持默认值1。
追求稳定与精确: 设置较低的 temperature (如 0.2),top_p 保持默认值1。或者将 temperature 设为1,然后降低 top_p 的值。
场景化参数推荐表 (仅供参考,最佳值需实验):
代码生成/数学计算 0.0 - 0.2 1.0 (或不设置) 需要绝对的精确性和逻辑性,杜绝“创意”发挥。
创意写作/头脑风暴 0.7 - 0.9 1.0 (或不设置) 鼓励AI打破常规,生成新颖、有趣的内容。
事实问答/文本摘要 0.2 - 0.5 1.0 (或不设置) 在保证事实准确性的前提下,增加一点语言的流畅性。
角色扮演/聊天机器人 0.7 - 0.9 1.0 (或不设置) 模仿人类对话的自然性和不确定性,让对话不死板。
记住,没有绝对的“最佳参数”,只有最适合你当前任务的参数。多尝试、多实验,你就能找到与你的AI伙伴最合拍的“情绪频道”。
第三章:提示元素及设计要点 —— “米其林级”AI大餐的秘方
一个强大的提示,就像一道米其林星级菜肴,由多种“食材”精心搭配而成。理解这些基本元素,是成为提示词大厨的第一步。一个结构良好的提示通常包含以下几个核心要素:
3.1 提示的四大核心元素
指令 (Instruction):
定义: 你希望模型执行的具体任务。这是提示中最核心的部分。
示例: “总结以下文章”、“将这段英文翻译成中文”、“写一首关于秋天的五言绝句”。
厨师比喻: 这是菜谱的“主标题”,比如“清蒸鲈鱼”。
上下文 (Context):
定义: 为模型提供背景信息或约束条件,帮助它更好地理解任务。
示例: “在下面的对话中,我是用户,你是客服”、“背景:这是一个面向儿童的科普读物”。
厨师比喻: 这是“烹饪环境”,比如“使用蒸锅,时间控制在8分钟”。
输入数据 (Input Data):
定义: 你希望模型处理的具体信息或问题。
示例: 需要被总结的文章全文、需要被翻译的英文句子。
厨师比喻: 这是“主要食材”,比如那条新鲜的鲈鱼。
输出指示符 (Output Indicator):
定义: 指定输出的格式、结构或类型。
示例: “以JSON格式输出”、“请用无序列表回答”、“生成的摘要不要超过100字”。
厨师比喻: 这是“摆盘要求”,比如“装在白色长盘中,撒上葱丝”。
一个“四项全能”的提示示例:
提示:
[指令] 请总结以下客户评论。
[上下文] 你是一名专业的电商产品分析师,需要从评论中提炼出优点和缺点。
[输入数据] “这款吸尘器吸力很强,噪音也小,但是电池续航太短了,用了半小时就没电了,而且充电要很久。”
[输出指示符] 请以JSON格式输出,包含’pros’和’cons’两个键,值为字符串数组。
这样的提示,就像给AI大厨一份详尽无比的SOP(标准作业程序),它想做错都难!
3.2 提示设计的黄金法则
设计提示词是一门艺术,更是一门科学。遵循以下几条“黄金法则”,能让你的提示效果提升一个数量级:
清晰具体,拒绝模糊:
坏例子: “写点关于狗的东西。”
好例子: “写一篇500字左右的短文,描述一只金毛寻回犬在一个阳光明媚的下午,在公园里追逐飞盘的快乐场景。”
要点: 永远假设AI是个“直肠子”,你必须把需求描述得像法律条文一样清晰。
多用“你应该做什么”,少用“你不要做什么”:
坏例子: “写一段描述,不要出现陈词滥调。” (AI可能反而会因为“陈词滥调”这个词而联想到它们)
好例子: “写一段描述,请使用新颖、独特的比喻。”
要点: 正向引导远比反向禁止更有效。
赋予角色,入境三分:
给AI一个明确的身份,能极大地提升输出的专业性和风格一致性。
示例: “扮演一位资深投资银行家,分析一下当前的市场趋势。” vs “分析一下当前的市场趋势。” 前者的回答会更专业、术语更地道。
使用分隔符,结构清晰:
当提示词内容复杂,包含多段文本时,使用 ###、“”" 或 XML 标签等分隔符来区分指令、上下文和输入数据。这能帮助AI更好地解析你的意图。
示例:
指令
总结以下文本。
文本
“”"
[此处放入长长的文本]
“”"
明确输出格式,省去后处理的烦恼:
如果你需要程序直接处理AI的输出,那么在一开始就规定好格式(如JSON、Markdown、CSV)至关重要。
示例: “提取文本中的人名、地名和组织名,并以JSON对象数组的形式返回,每个对象包含’entity’和’type’两个字段。”
掌握了这些设计要点,你就从一个只会说“你好”的门外汉,晋升为懂得排兵布阵的“提示词策略师”了。
第四章:标准提示与 Few-shot Prompting —— 从“授人以鱼”到“授人以渔”
现在,我们来聊聊两种最核心的提示策略:标准提示(通常指零样本提示)和少样本提示(Few-shot Prompting)。
4.1 标准提示 (Zero-shot Prompting)
零样本提示(Zero-shot Prompting),顾名思义,就是不给AI任何具体的执行范例,直接让它根据指令去完成任务 。我们前面见到的大部分例子都属于零样本提示。
示例(情感分类):
提示:
将以下文本分类为“积极”、“消极”或“中性”。
文本:“这部电影的结局真是太棒了!”
分类:
这种方式的优点是简单直接,对于那些LLM在训练中已经见过无数次的常见任务(如翻译、总结、简单问答),效果非常好。
但是,当你面对一个新颖的、或者格式要求特殊的任务时,只靠零样本提示,AI可能会“蒙圈”。这时候,就需要更高级的玩法了。
4.2 少样本提示 (Few-shot Prompting)
少样本提示(Few-shot Prompting)是一种极其强大的技术。它的核心思想是,在提出正式任务之前,先给AI提供几个“输入-输出”的范例 。这就像老师在教学生新知识时,会先举几个例子一样。
通过这些例子,AI能够“在上下文中学习”(In-context Learning),快速理解你想要的模式和格式,而无需重新训练模型。
示例(创造新词并解释):
提示:
范例1:
输入:一种早上醒来后不想上班的强烈情绪。
输出:晨间倦怠 (Morning-nertia)
范例2:
输入:因为害怕剧透而不敢上社交媒体的状态。
输出:剧透恐惧症 (Spoiler-phobia)
正式任务:
输入:打开冰箱门,盯着里面看了半天,然后忘记自己要拿什么的现象。
输出:
看到这个提示,AI会迅速领悟到你的模式:将一种现代生活现象,创造一个复合词来描述。它很可能会生成类似“冰箱失忆症 (Fridge-amnesia)”或“开门茫然 (Door-mnesia)”这样有趣的答案。
在实际应用中,我们甚至可以结合代码模板来动态构建少样本提示,例如使用Python的 LangChain 库中的 FewShotPromptTemplate。
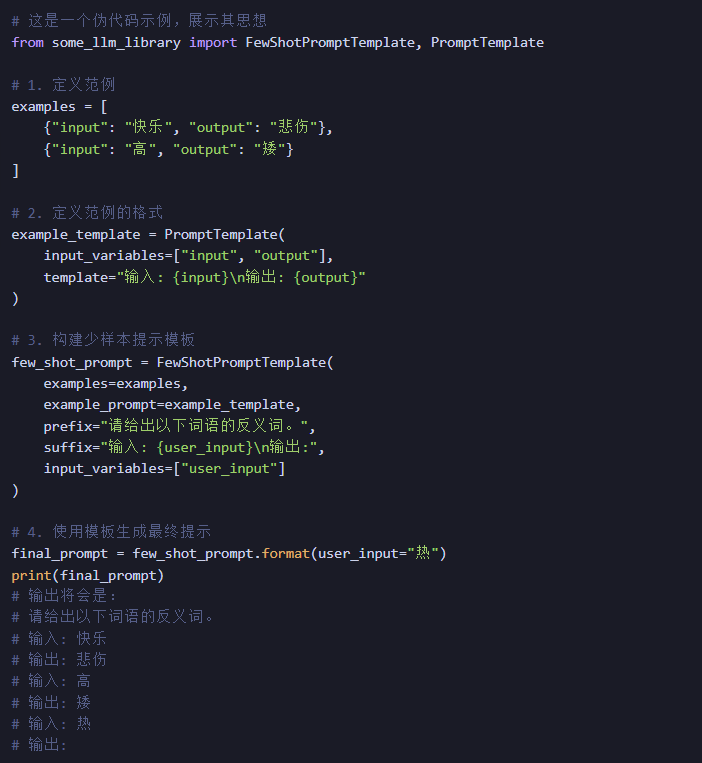
通过这种方式,我们可以动态地、结构化地构建强大的少样本提示,让AI能够处理各种复杂和定制化的任务。
One-shot Prompting: 只给一个范例。
Few-shot Prompting: 给出多个(通常是2-5个)范例。
少样本提示是提示工程中从入门到精通的“分水岭”,掌握它,你就真正拥有了“调教”AI的能力。
第五章:实际案例分析与常见错误 —— “翻车现场”与“拯救指南”
理论说了这么多,是时候上点“干货”,看看在真实世界中,这些技巧是如何应用的,以及新手们最容易在哪些地方“翻车” 。
5.1 案例:智能客服邮件摘要机器人
**业务场景:**一家电商公司希望开发一个工具,能自动将用户的投诉邮件总结成结构化的摘要,方便客服快速跟进。
数据来源: 真实的用户投诉邮件。
初始尝试(一个糟糕的提示):
提示 (版本1.0):
总结这封邮件。
邮件内容:
“你好,我上周买的那个型号为X-2025的咖啡机,昨天第一次用就坏了!开机没反应,屏幕也不亮。我查了订单号是#12345,希望能尽快给我换一个新的,或者退款也行。你们的质量太让人失望了!”
AI可能的输出:
“一位顾客的咖啡机坏了,他想要换货或退款。”
这个输出虽然没错,但信息量太低,对客服来说价值不大。它缺少了关键信息,比如产品型号、订单号和具体故障。
5.2 常见错误分析
这个“翻车”的提示犯了以下几个典型错误:
指令过于模糊: “总结”是一个很宽泛的词。什么样的总结?需要包含哪些关键信息?完全没说。
缺少输出格式要求:AI以自然语言的形式返回,不方便程序进行后续的自动化处理。
未提供上下文或角色:AI不知道它是为“客服快速跟进”这个特定目的服务的,因此没有主动提取那些关键信息。
5.3 优化与迭代(一个优秀的提示)
现在,让我们用前面学到的知识来“拯救”这个提示。

[输入数据 - 邮件]
“”"
你好,我上周买的那个型号为X-2025的咖啡机,昨天第一次用就坏了!开机没反应,屏幕也不亮。我查了订单号是#12345,希望能尽快给我换一个新的,或者退款也行。你们的质量太让人失望了!
“”"
[输出]
AI理想的输出:

分析这次成功的原因:
清晰的指令和角色:明确了AI的身份和任务。
具体的上下文和要求:详细列出了需要提取的“关键信息”。
严格的输出格式:使用JSON格式,并定义了键名,甚至考虑了信息缺失的情况。
清晰的结构:使用分隔符 — 和 “”" 将不同部分隔开,让AI一目了然。
通过这样的迭代优化,我们把一个几乎无用的摘要,变成了一个可以直接被系统集成的、高价值的结构化数据。这就是提示工程的真正力量所在——它不仅仅是“和AI聊天”,而是在设计一种高效的人机协作流程。
你的“耳语者”之旅刚刚开始
恭喜你!读到这里,你已经成功完成了“提示词工程”的新手村任务。你了解了什么是提示,学会了如何调节AI的“情绪”(temperature 和 top_p),掌握了构建提示的“食材”和“菜谱”,甚至还亲眼见证了一个“翻车现场”是如何被力挽狂澜的。
但这仅仅是个开始。提示词工程的世界远比这更广阔,还有诸如思维链(Chain-of-Thought)、自洽性(Self-Consistency)等更高级的魔法等着你去探索。
记住,与AI合作的未来,属于那些懂得如何巧妙提问、精准引导的“AI耳语者”。现在,关上这份指南,去打开你的AI工具,开始你的第一次“许愿”吧!祝你好运,未来的大师!👋✨
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!
更多推荐
 20
20 0
0- 0



 已为社区贡献151条内容
已为社区贡献151条内容

所有评论(0)