
收藏!从零开始掌握7种主流Agent设计模式:Anthropic最新Agent实践指南
文章介绍了Anthropic发布的Agent系统设计模式,区分了Workflow与Agents概念,详细阐述了7种常见模式:增强LLM、链式调用、路由模式、并行化、编排器-Worker、评估-优化模式和Agents。指出当前落地应用以Workflow为主,因其上手快、门槛低且试错成本低。这些模式可灵活组合,成功关键是在实际场景中衡量效果,仅在能明显改善结果时才增加复杂性。
在2024年底,Anthropic发布了文章Building effective agents,从实际落地的角度,梳理了目前主流的一些Agent设计模式。
从严格意义上来讲,我们所介绍的Agent,更贴近Agent的概念,但正如我们在Agent:基础概念中所介绍的,Agent本身的定义也不是绝对的,从LLM到最高等级的Agent,中间是有大量灰度地带的,在Anthropic看来,Agent可以以多种方式定义,有些人将完全自主系统定义为Agent,而另一些团队则将预定义的工作流程定义为Agent。在Anthropic,所有这些变种都定义为Agent系统(Agentic System)。
Workflow和Agents的区别:
- Workflow:LLMs和工具通过预定义的代码路径编排的系统,也就是用户输入后,它的执行路径,是能够提前预料的,是有人工构建的,像基于Coze、Dify、n8n等平台搭建的应用,绝大多数属于这一类
- Agents:LLMs动态指导自己的流程和工具使用,典型的,比如Cursor、Windsur、Claude Code这种编程智能体,你发送指令后,后续它会先向你做一些澄清、帮你开始编写一份技术文档还是调用MCP工具来获取一些API使用说明等,没人能确切地知道其执行路径
为什么上一篇介绍完“正统”的Agent设计模式后,这一篇还要介绍一些Workflow呢?这是因为当前落地的绝大多数Agent仍以Workflow形式为主,它有三大显著的优势:
- 上手很快,门槛比较低,即使没有学过编程,也能拖拽出一个可以用的应用
- 不同场景有自己固定的成熟流程,使用Workflow是将这些流程融入AI非常低成本的方式
- 试错成本低,熟悉基本概念后,对于一个不太复杂的场景,一两天就能用Coze、Dify之类的搭建出看起来像样的应用,而构建高度自主化的Agent,则周期长、成本高
Anthropic在原文的多个地方强调寻找尽可能简单的解决方案,这也确实是一个非常务实的建议,毕竟,在没有清晰实现路径的情况下,小步快跑才是更优选择。
1 何时该使用与不该使用Agents
使用LLMs构建应用程序时,建议尽可能找简单的解决方案,仅在需要时增加复杂性。这意味着可能根本不需要构建Agent。Agent系统通常以高延迟和高成本为代价来获得更好的任务性能。
当需要更高的复杂性时,Workflow为定义明确的任务提供可预测性和一致性,当需要大规模的灵活性和模型驱动的决策时,Agents是更好的选择。但是,对于大多数应用,使用检索和In-Context样例优化单个LLM就足够了。
2 代理系统的常见模式
这部分从基础构建块——增强LLM开始,逐步增加复杂性,从简单组合的工作流到自主代理。
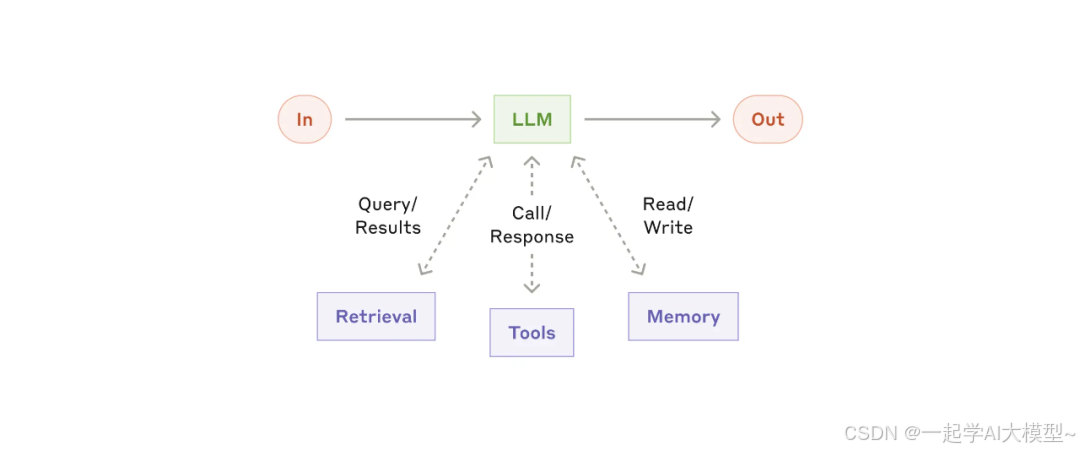
2.1 增强LLM
通过检索、工具、记忆等模块来增强LLM
2.2 链式调用
这种模式由一系列Prompt + LLM串联成链式结构组成,链可以将任务分解为一系列步骤,每个LLM调用都会处理前一个调用的输出,可以对任何中间步骤添加检查(下图中的Gate)
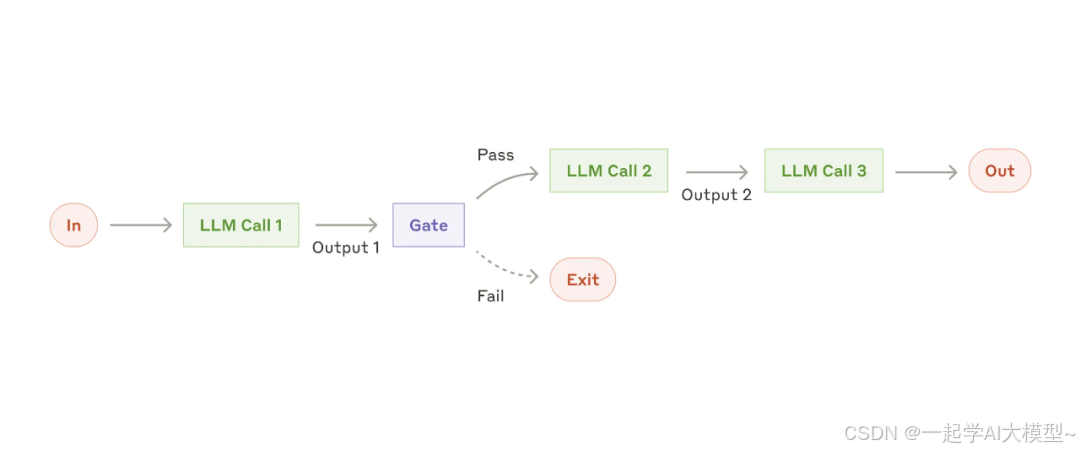
)
适用模式的样例:
- 生成营销副本,然后将其翻译为不同的语言
- 编写文档的大纲,检查大纲是否满足特定条件,然后根据大纲编写文档
2.3 路由模式
将输入分类,然后将其定向到后续的任务。
对于有些输入,优化一种类型的输入可能会损害其他输入的性能(跷跷板),这种情况适合使用这种模式。
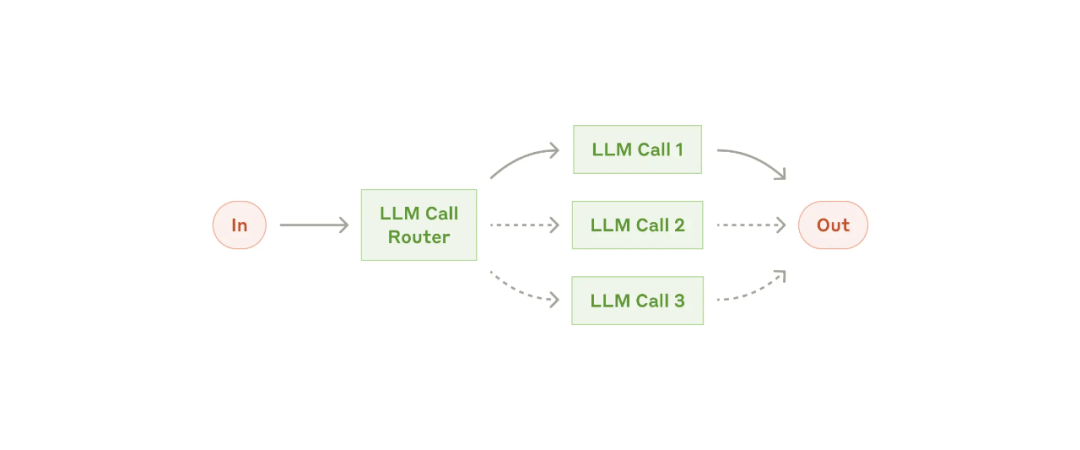
适用这种模式的样例:
- 将不同类型的客户服务查询(一般问题、退款请求、技术支持)引导到不同的下游流程、提示和工具中
- 将简单/常见问题路由到较小的模型,将困难/不寻常的问题路由到更强大的模型,以优化成本和速度
2.4 并行化
这种模式适合同时处理多个任务,并以编程方式聚合其输出。
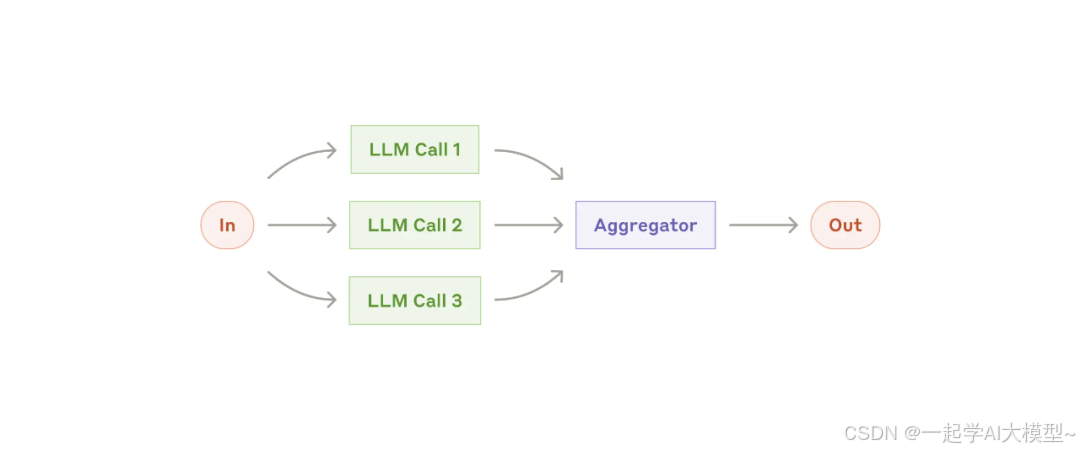
当任务可以并行以提高速度时,或者需要多个视角或尝试以更高的置信度结果时,这种方式比较有效。
对于有多个考虑因素的复杂任务,将每个考虑因素都由单独的LLM处理时,通常效果会更好。
适用这种模式的样例:
- 聚合
- 实施查询护栏,其中一个模型实例处理用户查询,另一个检查用户输入是否存在不当内容
- 自动化评估,每个LLM调用评估模型在给定Prompt下性能的区别
- 投票
- 使用不同的Prompt检查代码是否存在漏洞
- 评估给定的内容是否不合适,不同的Prompt评估不同的方面或者要求不同的投票阈值来平衡误报和漏报
2.5 编排器-Worker
在这种模式下,中央LLM会动态分解任务,然后将其委派给worker LLMs,并合并结果。
这种Workflow适合无法预测所需子任务的复杂任务(例如,在编码过程中,需要修改的文件数量和每个文件要修改的内容很可能依赖于任务)。
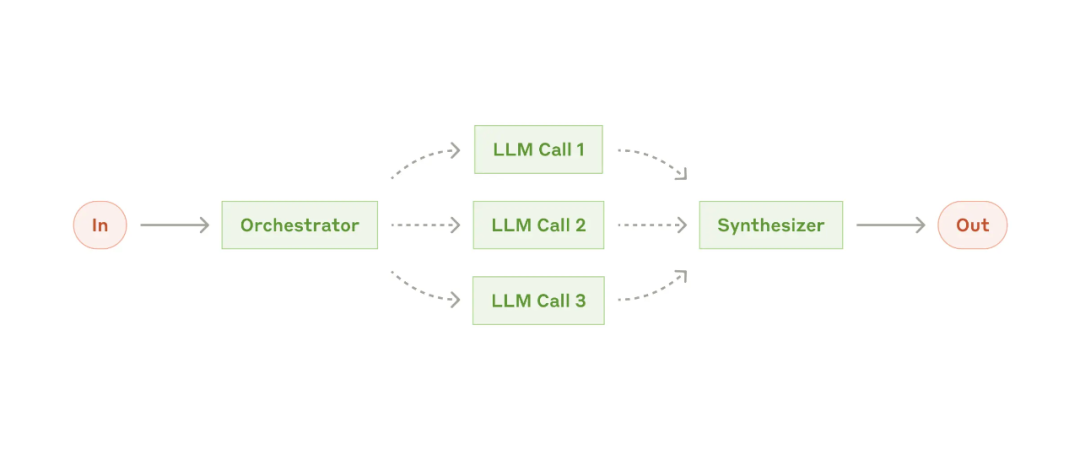
它和并行模式虽然在拓扑结构上类似,但主要的区别是灵活性——子任务不是预定义的,而是编排模块根据特定输入确定的。
适用这种模式的样例:
- 每次对多个文件进行复杂更改的编码产品
- 涉及从多个来源收集和分析信息以查找可能的相关信息的搜索任务
2.6 评估-优化模式
在这种工作流中,一个LLM调用负责生成,而另一个LLM调用在循环中提供评估和反馈。
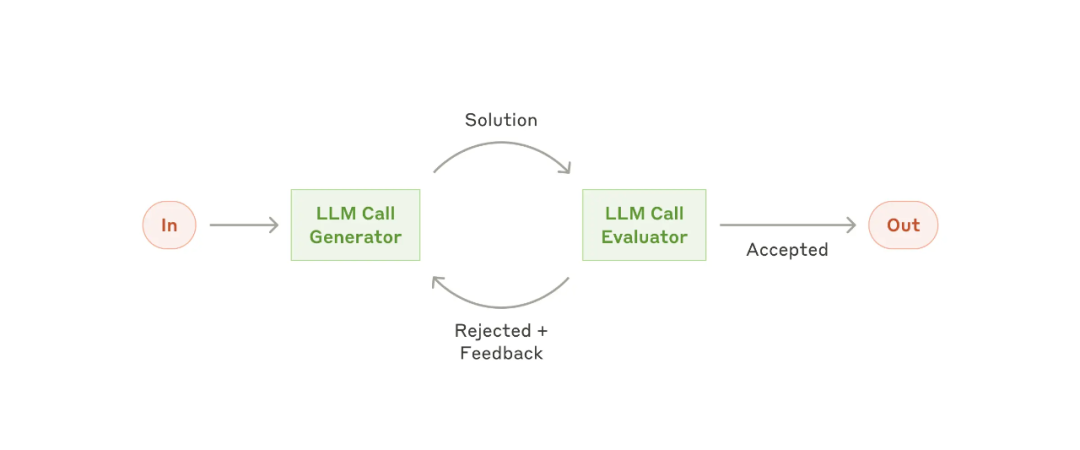
当有明确的评估标准,并且迭代优化提供可衡量的价值时,此工作流特别有效,这种模式已经有自主Agent的雏形了,把Evaluator部分加上环境反馈,这基本上就跟上篇文章介绍的ReAct很像了。
适用这种模式有两个判断标准:
- 反馈可以由人类清晰表述时,LLM的输出根据反馈可以明显得到改善
- LLM可以提供这样的反馈
这类似人类作家在制作精美的文档时可能经历的迭代协作过程。
适用这种模式的样例:
- 文学翻译,其中有细微的差别,翻译LLM最初可能无法捕获到,但评估LLM可以提供有用的批评
- 复杂的搜索任务,需要多轮搜索和分析以收集全面的信息,评估LLM可以决定是否需要进一步搜索
下面是使用Dify搭建的一个反思翻译的流程,也就是吴恩达之前开源的反思翻译项目的Dify实现:

下面是实际翻译效果,从翻译结果来看,反思翻译质量明显是高于初始翻译的。
| 原文 | 初始翻译 | 反思翻译 |
|---|---|---|
| 皮之不存,毛将焉附? | If the skin does not exist, where will the hair attach itself? | When the root is gone, how can the branches survive? |
| 我命由我不由天。 | My fate is controlled by me, not determined by heaven. | My fate is in my own hands. |
2.7 Agents
随着 LLM 在关键能力(理解复杂输入、参与推理和规划、可靠地使用工具以及从错误中恢复)方面的成熟,人工智能正在生产中崭露头角。Agents通过人类用户的命令或与人类用户的互动讨论开始工作。一旦任务明确,Agents就会独立进行规划和操作,并有可能返回人类获取进一步的信息或判断。在执行过程中,Agents从环境中获取每一步的 “基本事实”(如工具调用结果或代码执行情况)以评估其进度至关重要。然后,代理可以在检查点或遇到阻碍时暂停,以获得人工反馈。任务通常会在完成后终止,但通常也会包含停止条件(如迭代的最大次数)以保持控制。
代理可以处理复杂的任务,但它们的实现通常很简单。它们通常只是基于环境反馈循环使用工具的 LLM。因此,清晰周到地设计工具集及其文档至关重要。
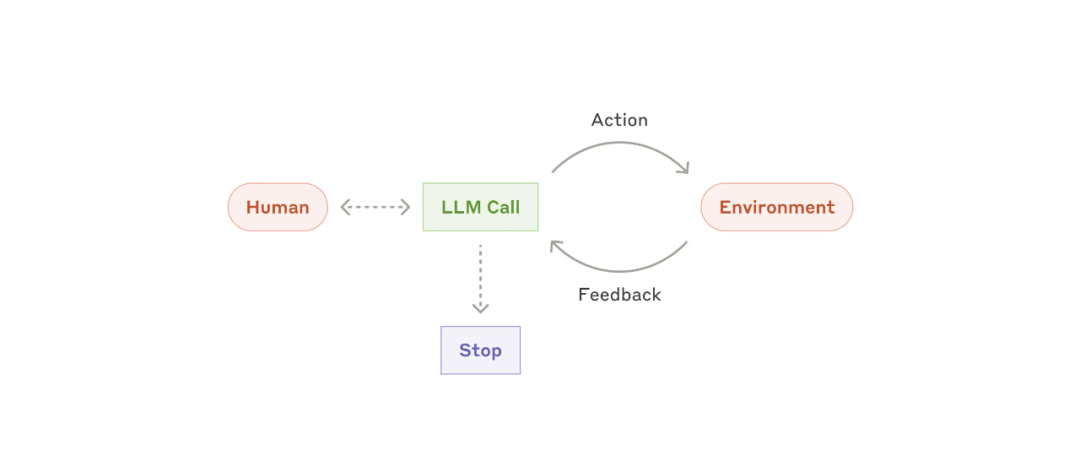
何时使用Agents:agents通常用于难以或不可能预测所需步骤以及无法固定路径进行硬编码的开放问题。LLM可能会运行多个回合,并且用户需要对其决策有一定程度的信任。Agents的自主性使得它成为可信环境中扩展任务的理想选择。
agents的自主性意味着更高的成本,并且可能会使错误复杂化。建议在沙盒环境中进行广泛测试,并使用适当的防护机制。
适用这种模式的样例:
(例来自Anthropic)
- 解决SWE-bench任务,该任务涉及根据任务描述对许多文件进行编辑
- computer use参考实现,其中Claude使用计算机完成任务
3 模式的组合
上面这7种模式可以看作是原子模块,可以根据实际情况修改和组合以适应不同场景。
和任何LLM功能一样,成功的关键是衡量在实际场景中的效果,并要切记:只有在能够明显改善结果时才应考虑增加复杂性。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
更多推荐


 14
14 0
0- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)