
Embedding模型微调:基于对比学习的训练与优化实践,大模型入门到精通,收藏这篇就足够了!
本文将以一个基于PyTorch的训练脚本为核心,结合对比学习中的InfoNCE损失,详细解析如何实现Embedding模型的微调。
🎯 文章目标
本文作为《Embedding模型微调:基于已有数据快速构建训练与评估数据集》的续篇,旨在从理论到实践,详细讲解如何基于对比学习实现Embedding模型的微调训练。上一篇文章深入探讨了如何构建高质量的微调数据集,本文则聚焦于实际的训练流程与性能优化,帮助读者:
- 理解对比学习的核心原理,特别是以DPR和GTR为代表的现代训练框架。
- 掌握基于批内负样本(In-batch Negatives)的InfoNCE损失计算与训练流程。
- 学习如何通过PyTorch代码实现数据预处理、模型训练与优化。
- 获取从基础到前沿的实践优化建议,包括BM25难负样本挖掘、模型规模扩展(Scaling),以及利用套娃表示学习(MRL)提升推理效率。
本文适合希望在信息检索、语义匹配等任务中优化Embedding模型的初学者与实践者。
完整的配套代码在: https://github.com/li-xiu-qi/XiaokeAILabs/blob/main/datas/test_train_embedding/train_embedding.py
🚀 前言
在上一篇文章中,我们详细探讨了如何构建高质量的Embedding模型微调数据集。坚实的数据基础是模型优化的前提,而科学的训练方法则是将数据潜力转化为模型性能的关键。
本文将以一个基于PyTorch的训练脚本为核心,结合对比学习中的InfoNCE损失,详细解析如何实现Embedding模型的微调。我们将首先深入剖析以DPR和GTR为代表的核心训练原理,理解它们如何通过巧妙的负采样和模型扩展策略提升模型性能。随后,我们将逐行解读训练代码,最终提供一系列从基础到前沿的优化策略,助您打造更强、更快、更泛化的检索模型。
📒 核心原理:从DPR到GTR
对比学习的目标是让模型学会区分相似与不相似的样本。在密集检索领域,其核心思想是拉近“查询(Query)”与其“相关文档(Positive Passage)”的Embedding距离,同时推远其与“不相关文档(Negative Passages)”的距离。
2.1 密集段落检索(DPR:奠定基础)
DPR (Dense Passage Retrieval) 是密集检索领域的开创性工作,它证明了无需复杂的预训练任务,仅通过一个设计精良的双塔模型和对比学习,就能在检索任务上超越经典的BM25算法。
-
双塔结构与相似度函数
DPR采用双塔结构,即一个查询编码器()和一个文档编码器()分别将查询和文档映射到同一维度的向量空间。两个编码器可以共享权重,也可以独立。其相似度通常使用点积(Dot Product)计算: -
核心训练策略:批内负样本 (In-batch Negatives)
DPR的成功关键在于其高效的负采样策略。假设一个训练批次(batch)包含 个独立的{查询, 正样本}对。对于批次中的任何一个查询 ,其对应的 是正样本,而批次内所有其他的 个文档 () 都被视为它的负样本。
这种“批内负样本”机制极大地提高了训练效率,每个样本都能利用批内其他样本,瞬间将负样本数量扩大至 个,而无需额外计算它们的Embedding。
- 损失函数:InfoNCE
DPR采用负对数似然(Negative Log-Likelihood)损失,这在后续研究中通常被称为InfoNCE损失。对于查询 ,其损失函数为:
这个公式的本质是,将查询 与批内所有 个文档的相似度得分看作是一个分类问题,模型的目标是正确地将 分类为正样本。
-
结合BM25难负样本
DPR论文强调,在批内负样本的基础上,为每个查询额外增加一个由BM25检索到的、排名靠前但不包含答案的难负样本,可以显著提升模型的判别能力和最终的检索准确率。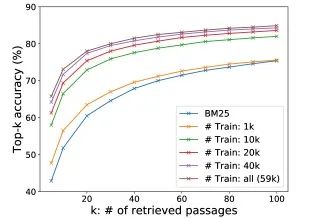
2.2 可泛化T5检索器(GTR:规模化的力量)
DPR证明了双编码器模型的有效性,但一个普遍的担忧是,简单的点积瓶颈是否会限制其泛化能力。GTR (Generalizable T5-based dense Retrievers) 通过实验有力地回应了这一问题:扩大模型规模是通往更强泛化能力的有效途径。
- 模型规模 vs. 泛化能力
GTR研究发现,即使保持Embedding维度(如768维)不变,仅仅将双塔编码器的骨干模型从Base(1.1亿参数)扩展到XXL(48亿参数),模型在跨领域检索基准(BEIR)上的性能也会持续、显著地提升。这表明,更大的模型容量能够学习到更鲁棒和可迁移的语义表示。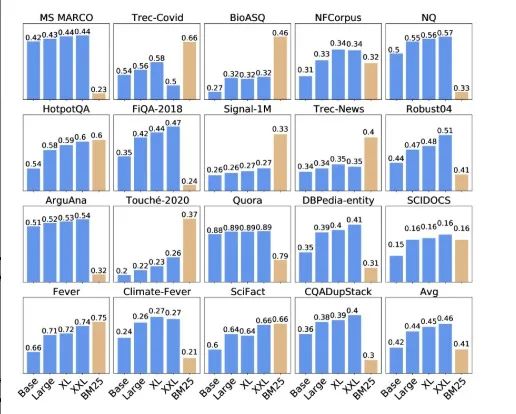
- 两阶段训练范式
为了充分释放大模型的潜力,GTR提出了一种高效的两阶段训练范式:
- 预训练 (Pre-training):在海量的、领域广泛但可能嘈杂的数据上进行训练(如从社区问答网站收集的20亿问答对)。这个阶段让模型学习通用的语义知识。
- 微调 (Fine-tuning):在高质量、人工标注的领域数据上(如MS MARCO)进行微调。这个阶段让模型适应特定任务的需求。
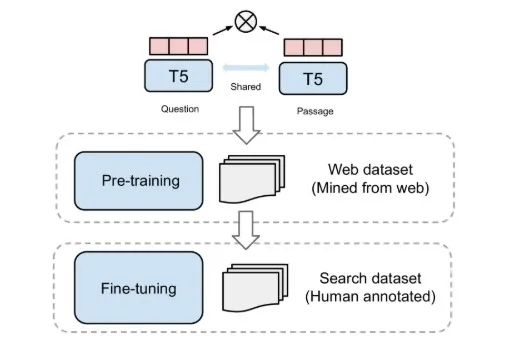
通用 T5 双编码器的多阶段训练。
- 数据效率
一个惊人的发现是,经过大规模预训练后,GTR模型在微调阶段表现出极高的数据效率。实验表明,仅使用10%的MS MARCO数据进行微调,GTR大模型就能达到甚至超过使用全部数据训练时的跨领域性能。
核心启示:从DPR到GTR的发展告诉我们,一个成功的Embedding模型微调实践,不仅依赖于像DPR那样高效的对比学习框架(特别是批内负样本),还受益于GTR所揭示的模型规模化和多阶段训练的策略。
🛠️ 代码解析:从数据到训练的完整流程
以下我们将基于一个典型的PyTorch训练脚本,逐段解析实现细节。
3.1 数据预处理与加载
import json
from torch.utils.data import Dataset, DataLoader
classTextDataset(Dataset):
def__init__(self, data_path):
super().__init__()
self.samples = []
with open(data_path, 'r', encoding='utf-8') as f:
for line in f:
self.samples.append(json.loads(line.strip()))
def__len__(self):
return len(self.samples)
def__getitem__(self, idx):
return self.samples[idx]
defcollate_fn(batch, tokenizer, query_max_len, passage_max_len):
queries = [item["query"] for item in batch]
pos_docs = [item["pos_doc"] for item in batch]
# 如果数据中包含BM25或其他难负样本,也应在此处一并处理
# neg_docs = [item["neg_doc"] for item in batch]
query_tokens = tokenizer(queries, padding=True, truncation=True, max_length=query_max_len, return_tensors="pt")
pos_doc_tokens = tokenizer(pos_docs, padding=True, truncation=True, max_length=passage_max_len, return_tensors="pt")
return {
"query_input_ids": query_tokens["input_ids"],
"query_attention_mask": query_tokens["attention_mask"],
"pos_doc_input_ids": pos_doc_tokens["input_ids"],
"pos_doc_attention_mask": pos_doc_tokens["attention_mask"],
}
这段代码主要是把原始的文本数据批量转换为模型可以直接输入的张量,具体流程如下:
1. 分离文本
从 batch 中提取所有 query 和正样本文档(pos_doc)。2. 分词与编码
用 tokenizer 对 queries 和 pos_docs 分别进行分词、截断、填充,并转为 PyTorch 张量(input_ids 和 attention_mask)。3. 组织输出
返回一个字典,包含模型 forward 所需的所有输入张量。
作用总结:
把一批原始文本(query、pos_doc)转成模型可用的张量格式,方便后续送入模型进行训练或推理。
tokenizer 函数解析:
query_tokens = tokenizer(queries, padding=True, truncation=True, max_length=query_max_len, return_tensors="pt")
pos_doc_tokens = tokenizer(pos_docs, padding=True, truncation=True, max_length=passage_max_len, return_tensors="pt")
这两行代码用于对批量文本进行分词和编码,参数含义如下:
- queries / pos_docs:待分词的文本列表(查询/正样本文档)。
- padding=True:自动将批次内的序列填充到当前批次中最长序列的长度。
- truncation=True:当序列长度超过 max_length 时,进行截断。
- max_length=…:指定序列的最大长度。
- return_tensors=“pt”:返回 PyTorch 张量格式,便于后续模型输入。
这样可以保证每个 batch 的输入张量形状一致,方便模型进行批处理运算。
TextDataset:一个标准的PyTorch Dataset,用于加载JSONL格式的数据。每行是一个JSON对象,至少包含一个"query"和一个正样本"pos_doc"。
collate_fn:这是数据加载的核心。它将一个批次的样本(list of dict)处理成模型所需的张量格式。
它从批次中分别提取所有query和pos_doc。
使用tokenizer(如来自HuggingFace Transformers)将文本批量转换为input_ids和attention_mask。设定最大长度(query_max_len, passage_max_len)以进行截断和填充,确保批内张量形状一致。
数据加载器与并发优化:
# 在主脚本中
import os
from functools import partial
# 使用partial来固定collate_fn的其他参数
collate_with_tokenizer = partial(collate_fn, tokenizer=tokenizer, query_max_len=64, passage_max_len=256)
partial 的作用:
functools.partial 用于“冻结”函数的一部分参数,生成一个新的、更简单的函数。
场景说明:
PyTorch 的 DataLoader 需要的 collate_fn 参数是一个只接受 batch 作为输入的函数,即 collate_fn(batch)。但我们自己定义的 collate_fn 还需要 tokenizer 等额外参数。
使用 partial 可以提前把 tokenizer、query_max_len 等参数固定住,生成一个符合 DataLoader 要求的新函数 collate_with_tokenizer。
如果不使用 partial,则需要使用 lambda 函数或者将参数定义为全局变量,代码不够优雅。partial 是更专业的做法。
train_dataloader = DataLoader(
train_dataset,
batch_size=args.batch_size, # batch_size越大, 批内负样本越多
shuffle=True,
collate_fn=collate_with_tokenizer,
num_workers=4# 开启多进程加速数据加载
)
# 禁用HuggingFace Tokenizer的并行处理,避免与DataLoader的num_workers冲突
os.environ["TOKENIZERS_PARALLELISM"] = "false"
TOKENIZERS_PARALLELISM 的作用:
HuggingFace 的 Tokenizer 为了提升速度,内部实现了自己的并行处理机制(通常基于Rust的多线程)。而 PyTorch 的 DataLoader 在设置 num_workers > 0 时,也会启动多个子进程来并行加载数据。
当这两个并行机制同时工作时,可能会发生资源竞争或死锁,导致程序卡住或报错。
通过设置 os.environ[“TOKENIZERS_PARALLELISM”] = “false”,我们强制关闭了Tokenizer的内部并行,让它在每个DataLoader的子进程中以单线程模式运行,从而避免了冲突,保证了训练的稳定性。
DataLoader:****batch_size是一个关键超参数,它直接决定了批内负样本的数量。更大的batch_size通常会带来更好的性能,但受限于GPU显存。
num_workers: 启用多个子进程来预加载数据,避免GPU等待。
TOKENIZERS_PARALLELISM: 设置为"false"是常见的实践,以防止HuggingFace Tokenizer的内部并行与DataLoader的多进程机制发生冲突,导致死锁。
3.2 模型定义与前向传播
import torch.nn as nn
from sentence_transformers import SentenceTransformer
classEmbeddingModel(nn.Module):
def__init__(self, model_name_or_path, temperature=0.05):
super().__init__()
# 加载预训练的双塔模型或单个BERT模型
self.model = SentenceTransformer(model_name_or_path, trust_remote_code=True)
self.temperature = temperature
defforward(self, query_input_ids, query_attention_mask, pos_doc_input_ids, pos_doc_attention_mask):
# 分别编码查询和文档
query_embeddings = self.model({'input_ids': query_input_ids, 'attention_mask': query_attention_mask})['sentence_embedding']
pos_doc_embeddings = self.model({'input_ids': pos_doc_input_ids, 'attention_mask': pos_doc_attention_mask})['sentence_embedding']
# 计算对比损失
loss, accuracy = self.calculate_contrastive_loss(query_embeddings, pos_doc_embeddings)
return {'loss': loss, 'accuracy': accuracy}
EmbeddingModel: 封装了SentenceTransformer模型。SentenceTransformer库极大地简化了获取句子嵌入的过程。
forward:
接收collate_fn准备好的input_ids和attention_mask。
分别将查询和正样本文档的批次输入模型,得到它们的嵌入向量。
调用损失计算函数,并返回包含损失和准确率的字典。
3.3 对比学习损失计算(InfoNCE)
这是模型训练的核心,实现了DPR中描述的批内负采样和InfoNCE损失。
import torch
import torch.nn.functional as F
# 这是EmbeddingModel类的一个方法
defcalculate_contrastive_loss(self, query_embeddings, pos_doc_embeddings):
# 步骤1: (可选但推荐) L2归一化,使得点积等价于余弦相似度
query_embeddings = F.normalize(query_embeddings, p=2, dim=-1)
pos_doc_embeddings = F.normalize(pos_doc_embeddings, p=2, dim=-1)
# 步骤2: 计算相似度矩阵 (scores)
# query_embeddings: [batch_size, hidden_size]
# pos_doc_embeddings: [batch_size, hidden_size]
# scores: [batch_size, batch_size]
scores = query_embeddings @ pos_doc_embeddings.transpose(-1, -2)
计算相似度矩阵:
query_embeddings 是形状为 [batch_size, embedding_dim] 的张量,表示每个 query 的嵌入向量。
pos_doc_embeddings 也是 [batch_size, embedding_dim],表示每个正样本文档的嵌入。
pos_doc_embeddings.transpose(-1, -2) 把文档嵌入转置为 [embedding_dim, batch_size],方便进行矩阵乘法。
@ 是矩阵乘法运算符。结果 scores 的形状为 [batch_size, batch_size]。
由于向量在第一步已经进行了L2归一化,这里的点积结果等价于余弦相似度。
含义:
scores 矩阵的第 (i, j) 个元素表示第 i 个 query 和第 j 个 doc 的相似度。
对角线上的元素 scores[i, i] 是 query 与其正样本文档的相似度。
非对角线上的元素 scores[i, j] (其中 i ≠ j) 是 query 与其批内负样本的相似度。
这一步高效地计算出批内所有可能的 query-doc 对的相似度,为后续的对比学习损失计算奠定了基础。
# 步骤3: 温度系数缩放
scores = scores / self.temperature
# 步骤4: 创建标签
# 对角线元素是正样本 (query_i, pos_doc_i),所以标签是 [0, 1, 2, ...]
batch_size = query_embeddings.size(0)
labels = torch.arange(batch_size, device=scores.device, dtype=torch.long)
创建标签 labels:
query_embeddings.size(0): 获取批处理大小(batch_size),例如 4。
torch.arange(batch_size): 创建一个从 0 到 batch_size - 1 的整数序列,例如 [0, 1, 2, 3]。
device=scores.device: 确保新创建的 labels 张量与 scores 张量在同一设备上(如CPU或同一块GPU),这是PyTorch运算的前提。
dtype=torch.long: 指定 labels 的数据类型为长整型,这是 F.cross_entropy 函数对标签类型的要求。
为何需要 [0, 1, …, N-1] 作为标签?
这与 scores 矩阵的结构密切相关。我们的目标是,对于第 i 行的相似度分数(即第 i 个查询与批内所有文档的相似度),模型应该预测出第 i 个文档是正样本。
因此,F.cross_entropy 接收到 scores 和 labels 后,就会执行以下任务:
对于第 0 行,目标是让索引 0 处的概率最大。
对于第 1 行,目标是让索引 1 处的概率最大。
这恰好对应了我们期望模型学习的目标:让 scores 矩阵对角线上的值(正样本对的相似度)远大于其他位置的值。
# 步骤5: 计算交叉熵损失 (InfoNCE Loss)
# F.cross_entropy内部会自动计算softmax
loss = F.cross_entropy(scores, labels)
InfoNCE 损失计算:
计算公式(以 batch size 为 ):
其中 是 矩阵的第 行第 列元素, 是温度系数。
F.cross_entropy 函数是一个高度集成的操作,它内部自动完成了两件事:
- 对输入的 scores 矩阵的每一行进行 Softmax 操作,将其转换为概率分布。
- 根据这个概率分布和 labels 计算负对数似然损失 (Negative Log-Likelihood Loss)。
这个过程的目标是最大化每个查询对其正确正样本的预测概率,即让对角线上的值在经过Softmax后尽可能接近1。
# 步骤6: 计算准确率
# 找出每个查询得分最高的文档索引
_, predicted_indices = torch.max(scores, 1)
torch.max 查找预测索引:
torch.max(scores, 1): 这个函数会沿着 scores 矩阵的第二个维度(dim=1,即每一行)查找最大值。
它返回一个元组 (values, indices),其中 values 包含了每一行的最大值,indices 包含了这些最大值对应的索引。
_: 我们用下划线 _ 忽略了最大值本身,因为我们只关心最大值出现的位置。
predicted_indices: 这是一个长度为 batch_size 的张量,其中第 i 个元素的值,就是第 i 行(第i个查询)中相似度得分最高的文档的索引。
示例 (batch_size=3):
# scores 矩阵 (行为query, 列为doc)
scores = torch.tensor([
[2.1, 0.5, -1.2], # 第0个query,最相似的是索引0
[0.3, 1.8, 0.2], # 第1个query,最相似的是索引1
[-0.7, 0.4, 2.5] # 第2个query,最相似的是索引2
])
_, predicted_indices = torch.max(scores, 1)
# predicted_indices 的结果会是: tensor([0, 1, 2])
在这个理想的例子中,模型为每个查询都正确找到了其对应的正样本(都在对角线上)。
correct_predictions = (predicted_indices == labels).sum().item()
accuracy = correct_predictions / batch_size
return loss, accuracy
准确率计算:
公式:
其中:
是 batch_size。
是第 个查询预测的最相似文档的索引(来自 predicted_indices)。
是第 个查询的正确文档索引(来自 labels,即索引 本身)。
是指示函数,当预测正确时值为1,否则为0。
作用:
predicted_indices == labels: 逐元素比较预测索引和真实标签,生成一个布尔张量(True / False)。
.sum(): 计算 True 的数量,即预测正确的样本数。
.item(): 将只有一个元素的张量转换为Python的数值。
/ batch_size: 计算出正确率。
这个指标直观地反映了在当前的批次中,模型将查询与其正样本配对的成功率。
3.4 训练流程
from tqdm import tqdm
classTrainer:
# (省略__init__部分,其中包含模型、优化器、调度器、数据加载器等)
deftrain_epoch(self, epoch):
self.model.train()
total_loss = 0
progress_bar = tqdm(self.train_dataloader, desc=f"Epoch {epoch}/{self.epochs}", unit="batch")
tqdm 进度条:
tqdm(self.train_dataloader, …): tqdm 是一个非常流行的Python库,它可以将任何可迭代对象(如DataLoader)包装起来,在循环执行时自动显示一个智能的进度条。
desc=f"Epoch {epoch}/{self.epochs}": 设置进度条的静态前缀描述,例如 “Epoch 1/10”。
unit=“batch”: 设置进度条的单位,表示每次迭代代表一个 “batch”。
这行代码的核心作用是可视化训练进度,让我们可以在命令行界面直观地看到训练进行到哪个批次,以及预计剩余时间。
for step, batch in enumerate(progress_bar):
# 将数据移动到指定设备 (GPU)
batch = {k: v.to(self.device) for k, v in batch.items()}
数据移动到设备:
batch 是一个字典,键是 “query_input_ids” 等,值是对应的PyTorch张量。
.to(self.device) 是PyTorch张量的一个方法,用于将其数据和计算图移动到指定的设备(self.device 通常是 ‘cuda:0’ 或 ‘cpu’)。
这行代码使用字典推导式,遍历 batch 字典中的所有项,并将值为张量的项都移动到目标设备上。
这是在GPU上进行训练的标准操作,确保模型和数据在同一个设备上,以利用GPU进行高速并行计算。
# 前向传播与优化
outputs = self.model(**batch)
loss = outputs['loss']
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.lr_scheduler.step()
单步训练核心流程:
- outputs = self.model(batch): 前向传播。将准备好的数据批次 batch 输入模型,batch 将字典解包为关键字参数(如 query_input_ids=…),模型计算后返回包含损失 loss 和准确率 accuracy 的字典。
- self.optimizer.zero_grad(): 梯度清零。由于PyTorch的梯度是累加的,所以在进行新一轮的反向传播之前,必须手动将上一步的梯度清零。
- loss.backward(): 反向传播。根据当前的损失 loss,自动计算模型中所有可学习参数的梯度。
- self.optimizer.step(): 参数更新。优化器(如AdamW)根据 loss.backward() 计算出的梯度来更新模型的权重。
- self.lr_scheduler.step(): 学习率更新。学习率调度器根据预设的策略(如余弦退火)更新学习率。
# 更新进度条
total_loss += loss.item()
progress_bar.set_postfix({'loss': f"{loss.item():.4f}", 'acc': f"{outputs['accuracy']:.2%}"})
avg_loss = total_loss / len(self.train_dataloader)
print(f"Epoch {epoch} finished. Average Loss: {avg_loss:.4f}")
统计与显示指标:
loss.item(): 在PyTorch中,loss 是一个包含单个值的张量(标量张量),例如 tensor(0.1234, device=‘cuda:0’)。它仍然附带计算图信息。
.item() 方法可以将这个标量张量提取成一个标准的Python浮点数(float),如 0.1234。这样做有两个好处:一是方便进行常规的Python数学运算(如累加),二是可以释放计算图占用的内存。
total_loss += loss.item(): 将当前批次的损失值累加到 total_loss 变量中,用于在整个epoch结束后计算平均损失。
progress_bar.set_postfix({…}): 这是tqdm库的功能,用于在进度条的末尾动态显示一个信息字典。
这里我们实时更新了当前批次的loss(格式化为4位小数的浮点数)和acc(格式化为百分比),方便实时监控训练状态。
# 优化器与学习率调度器
from transformers import get_cosine_schedule_with_warmup
# total_steps = len(train_dataloader) * args.epochs
# optimizer = torch.optim.AdamW(model.parameters(), lr=args.lr)
# lr_scheduler = get_cosine_schedule_with_warmup(
# optimizer=optimizer,
# num_warmup_steps=int(0.1 * total_steps), # 前10%步数预热
# num_training_steps=total_steps,
# )
学习率预热 (Warmup):
作用:
在深度学习训练初期,模型参数是随机初始化的,非常不稳定。如果此时直接使用一个较大的学习率,可能会导致梯度剧烈震荡,使得训练过程不稳定甚至发散。
Warmup 策略通过在训练开始的一小段时间内(num_warmup_steps),将学习率从一个很小的值(通常是0)线性地增加到预设的初始学习率,来解决这个问题。这个“热身”过程让模型参数先平稳地调整到一个合理的范围,再开始以正常的学习率进行训练。
get_cosine_schedule_with_warmup 的流程:
- Warmup阶段: 在前 num_warmup_steps 步,学习率从 0 线性增长到设定的 lr。
- Cosine Decay阶段: 在后续的步骤中,学习率会按照余弦函数的形状平滑地从 lr 下降到 0。
这种“先慢后快再慢”的策略被证明在许多任务上都非常有效,能帮助模型更好地收敛到最优解。
3.5 模型保存与检查点管理
defsave_checkpoint(self, epoch):
save_dir = os.path.join(self.output_dir, f"checkpoint-epoch-{epoch}")
os.makedirs(save_dir, exist_ok=True)
print(f"Saving model checkpoint to {save_dir}")
# SentenceTransformer提供了便捷的保存方法
self.model.model.save(save_dir)
# self.tokenizer.save_pretrained(save_dir) # 分词器也应一同保存
# 在训练循环结束后
final_save_dir = os.path.join(args.output_dir, "final_model")
model.model.save(final_save_dir)
tokenizer.save_pretrained(final_save_dir)
定期保存检查点(checkpoint)可以在训练中断后恢复,或用于选择验证集上表现最佳的模型。
训练完成后,保存最终的模型和分词器,以便于后续的推理和部署。SentenceTransformer的.save()方法会保存模型配置和权重。
💡 实践优化建议:从效果到效率
4.1 效果优化:提升模型准确率
- 高质量的负样本
- BM25难负样本:如DPR论文所强调,在每个训练样本中加入一个通过BM25检索到的高分负样本是提升性能最有效的方法之一。你需要一个大规模的文档语料库,用BM25为每个查询检索,并选取排名靠前但不含答案的文档作为难负例。
- 使用LLM生成难负样本:可以利用大型语言模型(LLM)生成与查询主题相关但语义细节不同的“迷惑性”负样本。例如,对于查询“这只鸟正在水槽里洗澡”,可以提示LLM生成“这只鸟站在水槽边喝水”。这种方法能有效提升模型对细微语义差异的辨别力。
- 采用GTR的规模化策略
- 扩大模型尺寸:如果计算资源允许,尝试使用更大规模的预训练模型作为骨干(如从bge-base升级到bge-large,或从T5-base到T5-large)。GTR的实验证明,模型规模的提升能直接带来泛化能力的增强。
- 两阶段训练:对于追求极致性能的场景,可以借鉴GTR的思路。先在海量的通用语料(如社区问答、网页文本)上进行第一阶段的对比学习预训练,然后在你的目标领域数据上进行第二阶段的微调。
- 数据增强:对查询或文档进行同义词替换、回译等操作,增加数据多样性,提高模型鲁棒性。
- 超参数调优
- 学习率 (Learning Rate):通常从2e-5开始尝试,可以在1e-5到5e-5的范围内搜索。
- 批大小 (Batch Size):在显存允许的情况下越大越好,因为它直接增加了批内负样本的数量。
- 温度 (Temperature):通常在0.01到0.1之间。较低的温度有助于模型学习区分更难的负样本。
4.2 效率优化:套娃表示学习(MRL)
这是一个高级优化技巧,旨在提升模型的推理效率。
核心思想:
套娃表示学习 (Matryoshka Representation Learning, MRL) 是一种训练方法,它使单个高维Embedding向量的不同前缀(prefix)本身就是高质量的低维Embedding。例如,一个通过MRL训练的768维向量,其前128维就是一个高质量的128维向量,其前256维就是一个高质量的256维向量,以此类推,像套娃一样层层嵌套。
实现方式:
在训练时,修改损失函数,使其不仅在最终的 维上计算损失,还在一系列预设的更小维度上(如 )都计算对比损失,并将这些损失加权求和。
其中 表示Embedding向量的前 维, 是在这 维上计算的InfoNCE损失。
**应用场景:自适应检索 (Adaptive Retrieval)**MRL的最大优势在于推理时可以实现两阶段检索,大幅提升大规模检索的速度:
- 筛选 (Filtering):面对一个包含数百万甚至数十亿文档的数据库,首先使用所有文档的短Embedding(如128维)进行快速的近似最近邻(ANN)搜索。由于向量维度低,这个过程非常快,可以迅速筛选出几百个候选文档。
- 重排 (Re-ranking):然后,仅对这几百个候选文档,使用其完整的高维Embedding(如768维)与查询的完整Embedding计算精确相似度,进行最终排序,返回top-K结果。
通过这种“粗筛->精排”的方式,MRL可以在几乎不损失检索精度的情况下,将检索速度提升10倍以上,极大地降低了大规模部署的计算和内存成本。
🙋♂️ 入群交流公众号菜单点击「社群」,扫码直接入群回复关键词「入群」,添加作者微信人工邀请,注意备注:入群
📊 总结与展望
本文系统梳理了Embedding模型微调的理论基础与实践方法,从DPR的双塔结构和批内负样本,到GTR的规模化策略和MRL的高效推理技术。我们不仅掌握了对比学习的核心训练流程,还介绍了提升模型效果和推理效率的多种实用技巧。
- 基础:DPR的双塔结构、批内负样本和InfoNCE损失是现代密集检索模型的核心。
- 进阶:结合BM25难负样本、扩大模型规模(GTR策略)可有效提升准确率和泛化能力。
- 前沿:MRL训练让模型具备自适应检索能力,实现推理速度数量级提升,助力大规模工业应用。
感兴趣的小伙伴可以进一步融合这些技术,比如在大模型上应用MRL训练,并结合LLM生成的高质量负样本,持续提升模型的效果与效率。当前如 jina-embedding v4 等主流模型已支持MRL,相关技术正不断演进,值得持续关注和实践。
附录:项目代码实战指南 (README)
为了将前文的理论付诸实践,以下提供一个基于 train_embedding_model.py 脚本的完整项目代码实战指南,我们可以直接上手运行和修改。
项目原理简介
本项目基于 PyTorch,提供了完整的文本嵌入(Embedding)模型微调代码,核心目标是通过对比学习提升模型对语义相似度的捕捉能力,适用于向量检索、文本匹配等下游任务。
本项目采用主流的 In-batch Negatives 对比学习策略,原理已在正文中详细阐述:
- 每个 Query 的正样本为其对应的 Document。
- 同一批次内其他所有 Document 均视为该 Query 的负样本。
- 优化目标是 InfoNCE 损失,旨在拉近正样本对的相似度,推远负样本对的相似度。
环境依赖
请使用 pip 安装项目所需库:
pip install torch transformers sentence-transformers tqdm
快速开始
-
下载代码:保存 train_embedding_model.py 脚本到本地。
-
执行训练:在终端中直接运行以下命令,脚本会自动创建并使用一个包含少量样本的演示数据集 demo_data.jsonl。
python train_embedding_model.py训练完成后,模型检查点和最终版本将保存在 ./models/bge-finetuned 目录下。
-
运行输出示例(本项目示例在 NVIDIA A6000 显卡上运行):
硬件与时间参考:使用默认配置训练时,显卡显存占用约为 6767MiB(约 7GB)。在A6000上,完成3个epoch的训练大约需要 1分钟。
Using device: cuda --- Training Started --- Epoch 1/3: 100%|██████████| 1/1 [00:02<00:00, 2.56s/batch, loss=0.0000, acc=100.00%] Epoch 1 finished. Average Loss: 0.0000 Saving model checkpoint to ./models/bge-finetuned/checkpoint-epoch-1 Epoch 2/3: 100%|██████████| 1/1 [00:00<00:00, 1.55batch/s, loss=0.0000, acc=100.00%] Epoch 2 finished. Average Loss: 0.0000 Saving model checkpoint to ./models/bge-finetuned/checkpoint-epoch-2 Epoch 3/3: 100%|██████████| 1/1 [00:00<00:00, 1.49batch/s, loss=0.0000, acc=100.00%] Epoch 3 finished. Average Loss: 0.0000 Saving model checkpoint to ./models/bge-finetuned/checkpoint-epoch-3 --- Training Finished --- Final model saved to: ./models/bge-finetuned/final_model每个 epoch 会显示进度条、当前 batch 的实时损失和准确率。训练结束后,最终的模型和分词器会保存在指定目录。
自定义数据训练
-
数据格式要求:
数据文件必须是 .jsonl 格式(每行一个JSON对象)。
每个JSON对象必须包含 “query” 和 “pos_doc” 两个字段。示例 my_dataset.jsonl:
{"query": "什么是大语言模型?", "pos_doc": "大语言模型(LLM)是指在一个极大规模的文本语料库上训练的,参数数量巨大的语言模型。"} {"query": "如何预防感冒?", "pos_doc": "预防感冒需要注意保暖、勤洗手、保持室内空气流通并加强体育锻炼。"} -
启动训练:
通过 –train_dataset 参数指定你的数据文件路径,并可按需调整其他命令行参数。
python train_embedding_model.py \ --model_name_or_path "BAAI/bge-base-zh-v1.5" \ --train_dataset "path/to/your/my_dataset.jsonl" \ --output_dir "./models/my-custom-model" \ --epochs 5 \ --batch_size 16 \ --lr 1e-5
命令行参数说明
| 参数 | 默认值 | 说明 |
|---|---|---|
--model_name_or_path |
BAAI/bge-base-zh-v1.5 |
Hugging Face上的预训练模型名称或本地路径 |
--train_dataset |
demo_data.jsonl |
训练数据集的文件路径 |
--output_dir |
./models/bge-finetuned |
模型检查点和输出的保存目录 |
--epochs |
3 |
训练的总轮次 |
--lr |
2e-5 |
学习率 |
--batch_size |
4 |
训练批次大小 |
--query_max_len |
64 |
查询文本的最大Token长度 |
--passage_max_len |
256 |
文档段落的最大Token长度 |
代码结构概览
EmbeddingModel类:核心模型,封装SentenceTransformer并实现对比学习损失计算。TextDataset类:数据集加载器,负责从.jsonl文件读取数据。collate_fn函数:数据批处理函数,将文本批量转换为模型所需的张量格式。Trainer类:训练流程的执行者,包含完整的训练循环、日志记录和模型保存逻辑。main()函数:程序主入口,负责解析命令行参数、初始化所有对象并启动训练流程。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!
更多推荐

 17
17 0
0- 0



 已为社区贡献230条内容
已为社区贡献230条内容

所有评论(0)