
一文搞懂Transformer里的QKV,大模型底层逻辑不再神秘!
摘要 本文深入解析了Transformer架构中的核心机制QKV(Query-Key-Value)。QKV是自注意力机制的关键组成部分:Query代表当前元素的查询需求,Key作为被查询的索引,Value包含实际信息内容。通过线性变换将输入数据转换为Q、K、V三个不同视角的表示,使模型能有效捕捉长距离依赖关系。QKV机制不仅增强了模型表达能力,还为多头注意力提供了基础。文章以机器翻译为例,展示了Q
一文搞懂Transformer里的QKV,大模型底层逻辑不再神秘!
Transformer 爆火,QKV 是关键?
在大模型席卷而来的当下,Transformer 架构无疑是其中的中流砥柱,支撑起了诸如 GPT、BERT 等一系列大名鼎鼎的模型。要是把 Transformer 架构看作一座摩天大楼,那 QKV(Query、Key、Value,即查询、键、值)机制就是构建这座大楼的基石,它对于 Transformer 架构来说至关重要,是理解 Transformer 工作原理的核心所在。但对于很多刚接触大模型和 Transformer 架构的朋友而言,QKV 却像是一团迷雾,充满了神秘色彩,让人摸不着头脑 。那么,QKV 究竟是什么?它们在 Transformer 中又扮演着怎样不可或缺的角色?接下来,就让我们一起深入探索 QKV 的奥秘。
本文较长,建议点赞收藏,以免遗失。更多AI大模型开发 学习视频/籽料/面试题 都在这>>Github<< >>Gitee<<
什么是 Q、K、V
Query(查询)、Key(键)和 Value(值)是 Transformer 架构中自注意力机制(Self-Attention Mechanism)的核心概念 ,它们本质上是由输入数据经过特定的线性变换得到的向量。
Query 的作用就像是你向模型提出的一个问题,它代表了当前需要关注或处理的元素想要获取信息的 “意愿”,用来查询其他元素与自身的相关性 。例如在处理文本 “我喜欢吃苹果,苹果很美味” 时,当模型在处理 “美味” 这个词时,“美味” 对应的 Query 向量就会去询问其他词(像 “苹果”)与它的关联程度。
Key 可以理解为是被查询的 “索引” 信息,它包含了输入序列中每个元素的特征表示,用于与 Query 进行匹配,以此来衡量不同元素之间的相似程度。简单来说,每个输入元素都有对应的 Key,通过 Query 与 Key 的对比,模型就能知道哪些元素之间关系密切。回到刚才的文本例子,“苹果” 的 Key 向量就会和 “美味” 的 Query 向量进行匹配,以此来确定 “苹果” 和 “美味” 的相关程度。
Value 则包含了输入序列中每个元素的实际信息内容,是真正要被提取和利用的信息。在注意力计算过程中,根据 Query 和 Key 的匹配结果(也就是相似度),模型会对 Value 进行加权求和,从而得到融合了相关信息的输出。在上述文本中,“苹果” 对应 Value 向量里就包含了有关苹果的具体信息,当确定了 “苹果” 和 “美味” 高度相关后,“苹果” Value 里的信息就会被提取出来参与到对 “美味” 这个词理解和处理中 。
为了更直观地理解,我们可以把 Q、K、V 的关系类比成搜索引擎的工作过程。当你在搜索引擎(如百度、谷歌)中输入一个查询词(Query),比如 “人工智能发展现状”,搜索引擎会在它庞大的网页数据库里,根据每个网页所包含的关键信息(Key,例如网页标题、关键词、正文内容等)与你的查询词进行匹配,找到那些和你查询内容最相关的网页。然后,从这些相关网页中提取出具体的文本、图片、链接等实际内容(Value)展示给你。这里,搜索引擎通过 Query 和 Key 的匹配,从 Value 中获取到了你需要的信息,就如同 Transformer 中通过 Q 和 K 的计算,从 V 中提取出关键信息一样 。
Q、K、V 的计算过程详解
了解了 Q、K、V 的基本概念后,我们再深入到它们的计算过程中去一探究竟 。在 Transformer 中,Q、K、V 是通过对输入数据进行线性变换得到的 。
假设输入序列为 X X X,它的形状通常是 [ b a t c h _ s i z e , s e q u e n c e _ l e n g t h , d _ m o d e l ] [batch\_size, sequence\_length, d\_model] [batch_size,sequence_length,d_model],其中 b a t c h _ s i z e batch\_size batch_size表示一次处理的样本数量, s e q u e n c e _ l e n g t h sequence\_length sequence_length是序列的长度(比如文本中的单词数量), d _ m o d e l d\_model d_model是每个元素(token)的特征向量维度 。以一个简单的文本处理场景为例,假设有一个包含 3 个单词的句子 “我 喜欢 苹果”,经过词嵌入(Word Embedding)和位置编码(Positional Encoding)后得到输入 X X X,此时 b a t c h _ s i z e = 1 batch\_size = 1 batch_size=1(因为只有一个句子), s e q u e n c e _ l e n g t h = 3 sequence\_length = 3 sequence_length=3(3 个单词), d _ m o d e l d\_model d_model假设为 512(实际中常见的维度值) 。
接下来,通过三个不同的权重矩阵 W Q W_Q WQ、 W K W_K WK、 W V W_V WV对输入 X X X进行线性变换,从而生成 Q、K、V 。这三个权重矩阵都是模型在训练过程中需要学习的参数,它们的形状通常是 [ d _ m o d e l , d _ k ] [d\_model, d\_k] [d_model,d_k](对于 W Q W_Q WQ和 W K W_K WK)和 [ d _ m o d e l , d _ v ] [d\_model, d\_v] [d_model,d_v](对于 W V W_V WV),这里 d _ k d\_k d_k和 d _ v d\_v d_v分别是 Query 和 Key 向量的维度、Value 向量的维度,通常 d _ k = d _ v d\_k = d\_v d_k=d_v 。在实际应用中,为了计算的高效性和模型性能, d _ k d\_k d_k和 d _ v d\_v d_v的值会小于 d _ m o d e l d\_model d_model,比如 d _ m o d e l = 512 d\_model = 512 d_model=512时, d _ k = d _ v = 64 d\_k = d\_v = 64 d_k=d_v=64 。
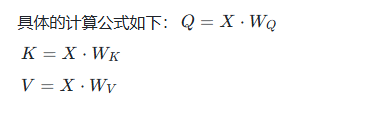
我们再结合上面 “我 喜欢 苹果” 的例子,对于输入 X X X中的第一个单词 “我” 对应的特征向量 x 1 x_1 x1(形状为 [ 1 , 512 ] [1, 512] [1,512],因为 b a t c h _ s i z e = 1 batch\_size = 1 batch_size=1),与 W Q W_Q WQ(形状为 [ 512 , 64 ] [512, 64] [512,64])进行矩阵乘法运算,得到 “我” 对应的 Query 向量 q 1 q_1 q1(形状为 [ 1 , 64 ] [1, 64] [1,64]) 。同理, x 1 x_1 x1与 W K W_K WK相乘得到 Key 向量 k 1 k_1 k1,与 W V W_V WV相乘得到 Value 向量 v 1 v_1 v1 。对句子中的每个单词都进行这样的操作,最终得到整个输入序列对应的 Q、K、V 矩阵 。
通过这样的线性变换,输入序列 X X X被转化为了三个不同的表示形式 Q、K、V,它们携带了不同角度的信息,为后续自注意力机制中计算注意力分数和加权求和做好了准备 。
为什么 Transformer 需要 QKV
你可能会好奇,为什么 Transformer 要大费周章地将输入拆分为 Q、K、V 三个向量呢?其实,这背后有着深刻的设计考量,QKV 机制对于 Transformer 的强大能力起着至关重要的作用 。
从根本上来说,QKV 机制是为了增强模型对输入序列中复杂依赖关系的捕捉能力 。在自然语言处理(NLP)任务中,一个单词的含义往往不仅仅取决于它自身,还与句子中其他单词密切相关 。比如在句子 “苹果从树上掉下来,小明把它捡起来了”,“它” 指代的就是 “苹果”,模型要理解 “它” 的含义,就必须建立起 “它” 和 “苹果” 之间的关联 。在处理图像时,一个像素点的特征也可能与图像中其他区域的像素点相关 。Transformer 引入 QKV 机制,通过 Query 与 Key 的匹配计算,能够找到输入序列中与当前元素(token)最相关的部分,再结合 Value 向量提取出这些相关部分的信息,从而更好地捕捉长距离依赖关系 。这就好比在茫茫人海中,你要找到与自己兴趣爱好最相似的人,Query 就是你的兴趣标签,Key 是其他人的兴趣标签,通过对比 Query 和 Key,你就能找到那些和你兴趣相投的人(Value),并与他们交流互动,获取有价值的信息 。
从模型表达能力的角度来看,QKV 机制为模型提供了多个不同的视角来处理输入数据 。通过不同的权重矩阵 W Q W_Q WQ、 W K W_K WK、 W V W_V WV对输入进行线性变换,得到的 Q、K、V 向量在不同的特征空间中,携带了输入数据不同方面的信息 。这就像从不同的角度观察一个物体,你会看到它不同的特征 。模型在计算注意力分数和加权求和时,综合考虑了这些不同视角的信息,使得模型能够学习到更丰富、更复杂的模式,大大增强了模型的表达能力 。在处理文本情感分析任务时,Q 向量可以关注单词本身的语义,K 向量可以捕捉单词之间的语法结构关系,V 向量则包含了单词的上下文信息,通过 QKV 的协同作用,模型能够更准确地判断文本的情感倾向 。
此外,QKV 机制还为 Transformer 实现多头注意力机制(Multi-Head Attention)奠定了基础 。多头注意力机制是 Transformer 的一个重要创新点,它通过并行地使用多个不同的注意力头(head),每个头都有自己独立的 Q、K、V 计算,能够同时关注输入序列的不同部分,捕捉到不同类型的依赖关系 。就好像有多个不同的探测器,每个探测器都专注于探测输入数据的某一个特定方面,最后将这些探测器的结果综合起来,得到更全面、更准确的信息 。在处理一篇新闻报道时,一个注意力头可能专注于人物关系,另一个注意力头关注事件发生的时间顺序,还有的注意力头聚焦于事件发生的地点等信息,多头注意力机制将这些不同头的结果融合,使得模型对新闻内容的理解更加深入和全面 。
QKV 在 Transformer 中的应用实例
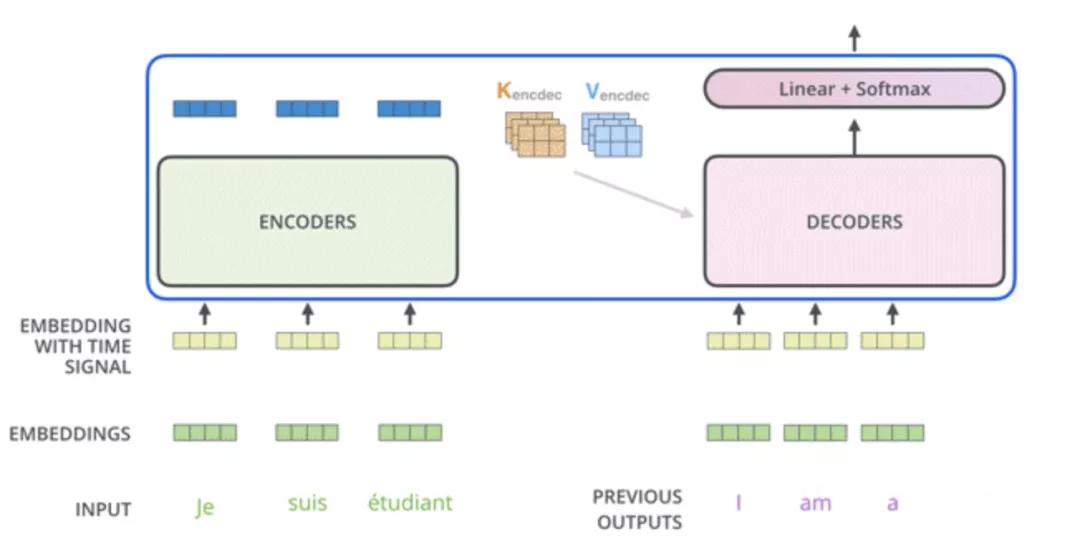
为了让大家更清楚地了解 QKV 在 Transformer 中的实际运作,我们以机器翻译任务为例来详细说明 。假设我们要将英文句子 “Hello, how are you?” 翻译成中文 “你好,你怎么样?” 。
编码器中的 QKV
首先,输入的英文句子 “Hello, how are you?” 会经过词嵌入层和位置编码层,将每个单词转化为包含语义和位置信息的向量,形成输入序列 X X X 。然后, X X X会分别与 W Q W_Q WQ、 W K W_K WK、 W V W_V WV进行线性变换,生成 Q、K、V 矩阵 。
在编码器的多头自注意力机制中,以其中一个注意力头为例,当计算单词 “you” 对应的输出时,“you” 对应的 Query 向量 q y o u q_{you} qyou会与句子中其他所有单词(包括 “Hello”、“how”、“are”、“you” 自身)对应的 Key 向量进行点积运算,得到一系列注意力分数 。这些分数表示 “you” 与其他单词之间的相关性程度,比如 q y o u q_{you} qyou与 k a r e k_{are} kare的点积结果表明了 “you” 和 “are” 的相关程度 。然后,通过对这些注意力分数进行缩放(除以 d k \sqrt{d_k} dk, d k d_k dk是 Key 向量的维度)和 Softmax 归一化处理,得到每个单词相对于 “you” 的注意力权重 。最后,根据这些注意力权重对所有单词对应的 Value 向量进行加权求和,得到 “you” 这个位置经过自注意力机制处理后的输出 。这个输出不再仅仅包含 “you” 自身的信息,还融合了句子中其他相关单词的信息,比如 “are” 的信息,因为在自然语言中 “are you” 经常一起出现,它们的相关性很强 。
编码器通过多层这样的多头自注意力机制和前馈神经网络,对输入序列进行层层编码,最终输出一个包含了整个输入句子丰富语义信息的上下文向量序列,这个序列会作为解码器的输入之一 。
解码器中的 QKV
解码器在生成翻译结果时,同样依赖 QKV 机制 。解码器以起始标记(如 “”)作为初始输入,结合编码器的输出,生成目标语言(中文)的第一个单词 。在这个过程中,解码器的第一个多头自注意力机制是掩码自注意力(Masked Self-Attention),它会防止当前位置关注后续位置的信息,保证翻译过程是从左到右依次生成的 。比如在生成第一个中文单词 “你” 时,掩码自注意力机制会确保 “你” 只能关注之前生成的起始标记 “”,而不会提前看到后续要生成的单词 。
接着,解码器的第二个多头自注意力机制是编码器 - 解码器注意力(Encoder-Decoder Attention),也叫交叉注意力(Cross Attention) 。在这里,编码器的输出作为 Key 和 Value,解码器中掩码自注意力机制的输出作为 Query 。以生成中文单词 “好” 为例,“好” 对应的 Query 向量会与编码器输出中所有单词对应的 Key 向量进行匹配计算,得到注意力分数,再经过缩放和 Softmax 处理得到注意力权重 。根据这些权重对编码器输出中对应的 Value 向量进行加权求和,这样就可以从编码器的输出中提取与生成 “好” 这个单词最相关的信息 。比如,通过这种方式,模型可以从编码器对英文 “Hello” 的编码信息中获取与 “好” 相关的语义,因为 “Hello” 和 “你好” 在语义上是对应的 。
然后,经过前馈神经网络和一系列的处理,最终通过线性层和 Softmax 函数计算出词汇表中每个单词作为下一个输出的概率,选择概率最高的单词作为当前位置的输出 。如此循环往复,直到生成结束标记(如 “”),完成整个翻译过程 。
通过这个机器翻译的实例可以看出,QKV 机制贯穿了 Transformer 编码器和解码器的整个工作流程,在捕捉输入序列内部依赖关系、融合相关信息以及生成目标序列等方面都发挥着关键作用,是 Transformer 能够在机器翻译等自然语言处理任务中取得卓越性能的重要保障 。
写在最后
通过上面的介绍,相信大家对 Transformer 里的 QKV 有了较为深入的理解。QKV 作为 Transformer 自注意力机制的核心,通过独特的设计和计算方式,让 Transformer 拥有了强大的长距离依赖捕捉能力和卓越的模型表达能力,在自然语言处理、计算机视觉等众多领域都取得了令人瞩目的成果 。
如果你对 Transformer 和注意力机制感兴趣,不妨进一步深入学习相关的理论知识,尝试阅读经典论文《Attention Is All You Need》,并动手实践一些 Transformer 相关的代码,相信你会有更多的收获 。随着技术的不断发展,Transformer 架构也在持续演进,新的变体和应用不断涌现,深入理解 QKV 将为你探索这些前沿技术奠定坚实的基础 。
更多推荐

 34
34 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)