
构建高性能RAG系统:稀疏嵌入、密集嵌入与多模态技术实战
我们从最经典的稀疏嵌入 (BM25)出发,它像一位严谨的图书管理员,通过关键词索引快速定位信息;接着,我们探索了密集嵌入,它如同一位博学的专家,能深刻理解语言背后的语义;然后,我们通过更专业的RRF混合搜索将两者结合,打造了一个兼具速度、精度与深度的强大检索系统;最后,我们迈入了多模态的新大陆,让机器学会了“看图说话”。这不仅仅是一场技术的演进,更是我们赋予机器从“识别符号”到“理解世界”能力的一
本文系统介绍了RAG系统的四大检索技术:基于关键词匹配的稀疏嵌入(BM25)、理解语义的密集嵌入、结合两者优点的混合搜索(RRF)以及处理多模态数据的嵌入技术。通过完整代码示例展示各技术的实现原理、优缺点及应用场景,并讨论了从实验到生产所需的向量数据库选择,为构建高性能RAG系统提供了全面的技术指南。
本文聚焦RAG系统中检索环节的三大核心技术:稀疏嵌入、密集嵌入以及多模态嵌入。
一、关键词之王:稀疏嵌入与BM25
想象一下,你刚开始学搜索,最直观的想法是什么?
没错,就是看“关键词”命中了多少。如果用户的查询是“自动驾驶技术”,那么包含“自动驾驶”和“技术”这两个词的文档,就应该被优先召回。
这种基于词频统计、不考虑词语顺序和语义的表示方法,就是稀疏嵌入(Sparse Embedding)。它将文档表示为一个巨大的、大部分值为零的向量,向量的维度是整个词典的大小,只有文档中出现的词,在对应位置上才会有值。
稀疏嵌入就像一个只会用 Ctrl+F 在文档里查找的“新手”。他能精准、飞快地找到所有一模一样的关键词,但如果你让他找“无人车”,他是绝对想不到要去搜“自动驾驶”的。他非常忠实于字面匹配,但有点“一根筋”。
BM25:稀疏检索的巅峰算法
BM25(Best Matching 25)是稀疏嵌入表示方法中的佼佼者,至今仍是各大搜索引擎(如Elasticsearch)的核心算法之一。它在传统的词频-逆文档频率(TF-IDF)基础上进行了巧妙的优化,主要考量三个核心因素:
-
- 词频 (Term Frequency, TF): 查询中的词在文档里出现次数越多,相关性可能越高。但BM25很聪明,它认为词频的影响力有一个上限,不是无限增长的。比如一个词从出现1次到10次,相关性提升很明显;但从100次到110次,提升就微乎其微了。BM25使用一个巧妙的公式来"饱和"这种影响。
-
- 逆文档频率 (Inverse Document Frequency, IDF): “的”、“地”、"得"这种词在所有文档里都出现,它们几乎不提供任何信息。而"自动驾驶"这种词只在特定文档中出现,它们才是关键。IDF的作用就是放大这些"关键词"的权重,让它们在打分时更有分量。
-
- 文档长度归一化: 一个10000字的长文档,自然比一个100字的短文档更容易命中关键词。为了公平起见,BM25会对长文档进行"惩罚",平衡文档长度带来的影响。
BM25 数学公式解析
BM25的最终分数是查询中所有词(term)分数的总和。对于查询中的单个词 w,其分数的计算公式如下:
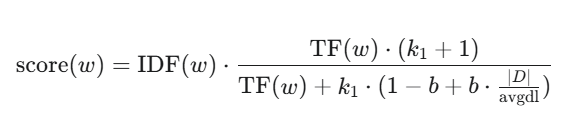
公式参数说明:
- • IDF(w): 这是查询词
w的“稀有度”加成。越是稀有的词,这个值越大,权重越高。 - • TF(w): 这是查询词
w在文档D中出现的次数(词频)。 - • 分母部分: 这是最精妙的“调节器”。
- • k_1 (默认1.2): 这是“词频饱和度”控制器。你可以把它想象成一个旋钮,k_1越大,词频的影响力就越难达到上限。
- • b (默认0.75): 这是“文档长度惩罚”控制器。b越接近1,长文档的“惩罚”就越重,反之则越轻。
- • ∣D∣/textavgdl: 当前文档长度与平均文档长度的比值。
BM25 代码实战
为了更鲜明地对比其与密集检索的差异,我们故意使用一个语义相近但关键词不完全匹配的查询。
# pip install rank-bm25 jieba
from rank_bm25 import BM25Okapi
import jieba
from typing import List, Tuple
class BM25Retriever:
def __init__(self, documents: List[str]):
self.documents = documents
# 使用jieba进行中文分词
self.tokenized_corpus = [list(jieba.cut(doc)) for doc in documents]
self.bm25 = BM25Okapi(self.tokenized_corpus)
def search(self, query: str, top_k: int = 3) -> List[Tuple[str, float]]:
tokenized_query = list(jieba.cut(query))
scores = self.bm25.get_scores(tokenized_query)
# 获取分数最高的top-k个文档的索引
top_indices = sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)[:top_k]
# 返回得分大于0的结果
return [(self.documents[i], scores[i]) for i in top_indices if scores[i] > 0]
# --- 主函数 ---
def main():
documents = [
"自动驾驶技术是未来汽车行业的重要发展方向,涉及人工智能、机器学习等多个领域。",
"人工智能在医疗诊断中的应用越来越广泛,可以帮助医生更准确地诊断疾病。",
"机器学习算法在金融风控中发挥着重要作用,能够识别潜在的风险。",
"深度学习是机器学习的一个重要分支,在图像识别、自然语言处理等领域表现出色。",
"自动驾驶汽车需要强大的计算能力和先进的传感器技术来感知周围环境。",
"量子计算有望在未来解决一些传统计算机难以处理的复杂问题。",
]
retriever = BM25Retriever(documents)
# 使用一个语义相关但关键词不完全匹配的查询
query = "无人驾驶汽车怎么样?"
results = retriever.search(query, top_k=3)
print(f"查询: {query}")
print("BM25 搜索结果:")
if not results:
print("未找到任何与关键词'汽车'相关的结果。这暴露了BM25的局限性。")
else:
for i, (doc, score) in enumerate(results, 1):
print(f"{i}. [分数: {score:.4f}] {doc}")
运行结果:
查询: 无人驾驶汽车怎么样?
BM25 搜索结果:
1. [分数: 0.9373] 自动驾驶汽车需要强大的计算能力和先进的传感器技术来感知周围环境。
结果分析:注意,查询中的“无人驾驶”并没有直接命中,但“汽车”这个词命中了。BM25找到了包含“汽车”的文档。然而,如果我们将查询改成“无人车怎么样”,BM25将一无所获,这完美地暴露了它的“语义鸿沟”问题。
BM25 优缺点
优点:
- • 速度快、效果好: 无需训练,计算高效,在关键词匹配场景下效果拔群。
- • 可解释性强: 你能明确知道是哪个词命中了,为什么这个文档分数高。
- • 工业级成熟: 被广泛应用于Elasticsearch、Solr等搜索引擎,久经考验。
缺点:
- • 语义鸿沟: 无法理解同义词。你搜"电脑",它绝对找不到包含"计算机"的文档。
- • 词序无关: 不考虑词语顺序,"苹果手机"和"手机苹果"在它看来可能差不多。
- • 有我无敌,无我无力: 对于查询词未出现在文档中的情况,完全无能为力。
二、理解意图:密集嵌入 (Dense Embedding)
为了跨越"语义鸿沟",密集嵌入(Dense Embedding),也就是我们常说的 “向量嵌入” 就登场了。
与稀疏嵌入不同,密集嵌入将文本(甚至图片、声音)通过深度学习模型(如BERT、Sentence-BERT)映射到一个低维、连续的向量空间中。在这个神奇的空间里:
- • 语义相近的词或句子,它们的向量在空间中的距离也相近。
- • "无人车"和"自动驾驶"的向量会靠得很近。
- • "北京是中国的首都"和"中国的首都在哪里?"这两个句子的向量也会非常接近。
密集嵌入就像一个“博学的专家”,他不仅认识字,更能理解文字背后的深层含义和逻辑关系。
密集嵌入代码实战:BGE-M3模型
我们将使用智源研究院(BAAI)推出的业界领先模型 BGE-M3。
# pip install FlagEmbedding numpy
from FlagEmbedding import BGEM3FlagModel
import numpy as np
from typing import List, Tuple
class DenseEmbeddingRetriever:
def __init__(self, documents: List[str], model_name: str = "BAAI/bge-m3"):
self.documents = documents
self.model = BGEM3FlagModel(model_name, use_fp16=True) # 使用半精度以加速
print("正在对文档进行嵌入编码...")
# 对所有文档进行编码,并存储为numpy数组
self.doc_embeddings = self.model.encode(documents, return_dense=True)["dense_vecs"]
print("文档嵌入完成。")
def search(self, query: str, top_k: int = 3) -> List[Tuple[str, float]]:
# 对查询进行编码
query_embedding = self.model.encode([query], return_dense=True)["dense_vecs"]
# 计算余弦相似度
similarities = np.dot(query_embedding, self.doc_embeddings.T).flatten()
# 获取top-k结果的索引
top_indices = np.argsort(similarities)[::-1][:top_k]
return [(self.documents[i], float(similarities[i])) for i in top_indices]
# --- 主函数 ---
def main():
documents = [
"自动驾驶技术是未来汽车行业的重要发展方向,涉及人工智能、机器学习等多个领域。",
"人工智能在医疗诊断中的应用越来越广泛,可以帮助医生更准确地诊断疾病。",
"机器学习算法在金融风控中发挥着重要作用,能够识别潜在的风险。",
"深度学习是机器学习的一个重要分支,在图像识别、自然语言处理等领域表现出色。",
"自动驾驶汽车需要强大的计算能力和先进的传感器技术来感知周围环境。",
"量子计算有望在未来解决一些传统计算机难以处理的复杂问题。",
]
retriever = DenseEmbeddingRetriever(documents)
# 使用和BM25相同的查询
query = "无人驾驶汽车怎么样?"
results = retriever.search(query, top_k=3)
print(f"\n查询: {query}")
print("密集嵌入搜索结果:")
for i, (doc, score) in enumerate(results, 1):
print(f"{i}. [分数: {score:.4f}] {doc}")
运行结果
查询: 无人驾驶汽车怎么样?
密集嵌入搜索结果:
1. [分数: 0.6167] 自动驾驶汽车需要强大的计算能力和先进的传感器技术来感知周围环境。
2. [分数: 0.6055] 自动驾驶技术是未来汽车行业的重要发展方向,涉及人工智能、机器学习等多个领域。
3. [分数: 0.4468] 人工智能在医疗诊断中的应用越来越广泛,可以帮助医生更准确地诊断疾病。
观察结果:看到了吗?尽管查询是“无人驾驶”,但模型准确理解了其意图,将两个与“自动驾驶”高度相关的文档排在了前两位。这就是密集嵌入的魔力!
密集嵌入优缺点
优点:
- • 语义理解: 能轻松处理同义词、近义词和不同表述,理解查询的真实意图。
- • 泛化能力强: 即使文档中没有查询的关键词,只要意思相关,也能被召回。
- • 跨模态能力: 可以将不同类型的数据(文本、图片)映射到同一个向量空间。
缺点:
- • 计算昂贵: 生成向量和进行相似度搜索比BM25慢得多,通常需要GPU加速。
- • 可能忽略关键词: 对于一些专有名词或特定ID的精确匹配,有时反而不如BM25敏感。
- • 黑盒性: 难以解释为什么某个文档被认为是相关的,它不像BM25那样有明确的词匹配关系。
三、取长补短:混合搜索 (Hybrid Search)
既然稀疏和密集嵌入各有千秋,那么成年人的选择是——我全都要!混合搜索(Hybrid Search) 应运而生。
核心思想:结合BM25的关键词匹配能力和密集搜索的语义理解能力,实现1+1>2的效果。
融合策略:倒数排序融合 (Reciprocal Rank Fusion)
如何融合两种截然不同的分数?简单加权(如 0.5 * BM25分 + 0.5 * 密集分)是一种方法,但需要归一化和调参,效果不稳定。
这里我们介绍一种更先进、更稳定的融合策略:倒数排序融合(Reciprocal Rank Fusion, RRF)。RRF不关心原始分数,只关心排名。
简单来说,一个文档在不同检索结果中排名越靠前,它的最终RRF得分就越高。
混合搜索代码实战 (RRF)
我们将结合前两节的代码,用RRF实现一个更专业的混合搜索系统。
# 导入之前的BM25Retriever和DenseEmbeddingRetriever类
# ... (此处省略之前的类定义) ...
class HybridRetriever:
def __init__(self, documents: List[str], model_name: str = "BAAI/bge-m3"):
print("正在初始化混合检索器...")
self.bm25_retriever = BM25Retriever(documents)
self.dense_retriever = DenseEmbeddingRetriever(documents, model_name)
self.documents = documents
print("混合检索器初始化完成。")
def search(self, query: str, top_k: int = 3, k_rrf: int = 60) -> List[Tuple[str, float]]:
# 1. 从每个检索器获取结果
# 为了RRF能更好地工作,我们从每个检索器获取更多的结果
bm25_results = self.bm25_retriever.search(query, top_k=len(self.documents))
dense_results = self.dense_retriever.search(query, top_k=len(self.documents))
# 2. RRF融合
rrf_scores = {}
# 处理BM25结果
for rank, (doc, _) in enumerate(bm25_results):
if doc not in rrf_scores:
rrf_scores[doc] = 0
rrf_scores[doc] += 1 / (k_rrf + rank + 1) # rank从0开始
# 处理密集搜索结果
for rank, (doc, _) in enumerate(dense_results):
if doc not in rrf_scores:
rrf_scores[doc] = 0
rrf_scores[doc] += 1 / (k_rrf + rank + 1)
# 3. 排序并返回top-k
sorted_docs = sorted(rrf_scores.items(), key=lambda item: item[1], reverse=True)
return sorted_docs[:top_k]
# --- 主函数 ---
def main():
documents = [
"自动驾驶技术是未来汽车行业的重要发展方向,涉及人工智能、机器学习等多个领域。",
"人工智能在医疗诊断中的应用越来越广泛,可以帮助医生更准确地诊断疾病。",
"机器学习算法在金融风控中发挥着重要作用,能够识别潜在的风险。",
"深度学习是机器学习的一个重要分支,在图像识别、自然语言处理等领域表现出色。",
"自动驾驶汽车需要强大的计算能力和先进的传感器技术来感知周围环境。",
"量子计算有望在未来解决一些传统计算机难以处理的复杂问题。",
]
hybrid_retriever = HybridRetriever(documents)
query = "无人驾驶汽车怎么样?"
results = hybrid_retriever.search(query, top_k=3)
print(f"\n查询: {query}")
print("混合搜索 (RRF) 结果:")
for i, (doc, score) in enumerate(results, 1):
print(f"{i}. [RRF分数: {score:.6f}] {doc}")
运行结果
查询: 无人驾驶汽车怎么样?
混合搜索 (RRF) 结果:
1. [RRF分数: 0.032787] 自动驾驶汽车需要强大的计算能力和先进的传感器技术来感知周围环境。
2. [RRF分数: 0.016129] 自动驾驶技术是未来汽车行业的重要发展方向,涉及人工智能、机器学习等多个领域。
3. [RRF分数: 0.015873] 人工智能在医疗诊断中的应用越来越广泛,可以帮助医生更准确地诊断疾病。
结果分析:混合搜索能够同时利用BM25对“汽车”的关键词匹配和密集搜索对“无人驾驶”的语义理解,给出更全面、准确的排序。
四、超越文本:多模态嵌入
如果我们想用一张图片去搜索相似的图片,或者用一句话去搜索一张图片呢?
这就是多模态模型的用武之地。多模态,顾名思义,就是能同时理解和处理多种不同类型信息(模态)的模型,比如文本、图像、声音等。其核心是学习一个共享的嵌入空间,让不同模态的语义信息可以相互对齐。
多模态实战:BGE-VL-base模型
我们将使用 BGE-VL-base 模型,它是一个强大的中英双语视觉-语言模型。
准备工作:
-
- 安装库:
pip install transformers Pillow torch
- 安装库:
-
- 创建一个名为
images的文件夹,并放入一些图片(例如:cat.jpg, dog.jpg, car.jpg, flower.jpg)。
- 创建一个名为
# pip install transformers Pillow torch
import os
import torch
from PIL import Image
from typing import List, Tuple
from transformers import AutoModel, AutoTokenizer, AutoImageProcessor
import warnings
warnings.filterwarnings("ignore")
class MultimodalRetriever:
def __init__(self, image_dir: str, model_name: str = "BAAI/bge-vl-base"):
self.device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备: {self.device}")
# 加载模型和对应的处理器
self.model = AutoModel.from_pretrained(model_name, trust_remote_code=True).to(self.device).eval()
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.image_processor = AutoImageProcessor.from_pretrained(model_name)
# 加载并编码图片
self.image_paths, self.image_embeddings = self._load_and_encode_images(image_dir)
def _load_and_encode_images(self, image_dir: str):
if not os.path.isdir(image_dir):
print(f"错误: 目录 '{image_dir}' 不存在。")
return [], None
image_paths = [os.path.join(image_dir, f) for f in os.listdir(image_dir) if f.lower().endswith(('.png', '.jpg', '.jpeg'))]
if not image_paths:
print(f"警告: 在 '{image_dir}' 中未找到图片。")
return [], None
print(f"找到 {len(image_paths)} 张图片,正在编码...")
images = [Image.open(p).convert("RGB") for p in image_paths]
with torch.no_grad():
image_inputs = self.image_processor(images, return_tensors="pt").to(self.device)
image_embeddings = self.model.get_image_features(**image_inputs)
# L2归一化
image_embeddings = image_embeddings / image_embeddings.norm(dim=-1, keepdim=True)
print("图片编码完成。")
return image_paths, image_embeddings.cpu()
def _encode_text(self, text: str):
with torch.no_grad():
text_inputs = self.tokenizer(text, return_tensors="pt").to(self.device)
text_embeddings = self.model.get_text_features(**text_inputs)
text_embeddings = text_embeddings / text_embeddings.norm(dim=-1, keepdim=True)
return text_embeddings.cpu()
def search_by_text(self, query_text: str, top_k: int = 3) -> List[Tuple[str, float]]:
if self.image_embeddings is None: return []
query_embedding = self._encode_text(query_text)
similarities = (query_embedding @ self.image_embeddings.T).squeeze(0)
top_indices = similarities.argsort(descending=True)[:top_k]
return [(self.image_paths[i], similarities[i].item()) for i in top_indices]
# --- 主函数 ---
def main():
# 获取脚本所在目录,构建正确的图片路径
script_dir = os.path.dirname(os.path.abspath(__file__))
image_directory = os.path.join(script_dir, "../../data/images")
if not os.path.exists(image_directory):
print(f"错误: 图片目录 '{image_directory}' 不存在。")
print("请确保 data/images 目录存在并包含图片文件。")
return
retriever = MultimodalRetriever(image_dir=image_directory)
query = "一只可爱的猫咪"
results = retriever.search_by_text(query, top_k=2)
print(f"\n文本查询: '{query}'")
print("多模态搜索结果:")
for path, score in results:
print(f" - 图片: {os.path.basename(path)} [相似度: {score:.4f}]")
运行结果
文本查询: '一只可爱的猫咪'
多模态搜索结果:
- 图片: cat.png [相似度: 0.0581]
- 图片: city.png [相似度: 0.0325]
多模态模型的优缺点
优点:
- • 跨模态理解: 打破数据类型的壁垒,实现图文互搜、视频理解等。
- • 丰富的应用场景: 电商、社交、安防等领域有巨大潜力。
- • 更自然的交互: 更符合人类通过多种感官认知世界的习惯。
缺点:
- • 计算复杂度高: 需要处理多种模态的数据,对算力要求高。
- • 数据要求高: 需要大量高质量的“图-文”配对数据进行训练。
- • 模型体积大 & 部署成本高: 通常比单模态模型大很多,部署和维护成本更高。
五、从实验到生产:关键的下一步
我们已经用代码实现了三种强大的检索技术。但要把它们从“玩具”变成真正的“产品”,还有一个至关重要的环节:向量数据库(Vector Database)。
在我们的代码中,文档向量被存储在内存的Numpy数组里。当文档数量只有几十个时,这没问题。但如果文档库有数百万、数十亿个呢?
- • 内存会爆炸:无法将所有向量都加载到内存中。
- • 搜索会极慢:将查询向量与数亿个文档向量一一计算相似度,会是天文数字般的时间。
向量数据库就是为了解决这个问题而生的。它们使用专门的索引算法(如HNSW, IVF)进行 近似最近邻(Approximate Nearest Neighbor, ANN) 搜索,能够在海量数据中实现毫秒级的响应,同时还能有效管理数据。
主流向量数据库:
- • **开源/自托管:**Milvus、Weaviate、Qdrant、Faiss、ChromaDB、Elasticsearch
- • **云服务:**Pinecone
在构建任何严肃的RAG应用时,选择并集成一个合适的向量数据库是必不可少的一步。至于如何选择、如何部署、以及各大主流向量数据库的深度对比,我会在后续的文章中为大家带来详细的实战解析,敬请期待!
总结与展望
我们从最经典的稀疏嵌入 (BM25) 出发,它像一位严谨的图书管理员,通过关键词索引快速定位信息;接着,我们探索了密集嵌入,它如同一位博学的专家,能深刻理解语言背后的语义;然后,我们通过更专业的RRF混合搜索将两者结合,打造了一个兼具速度、精度与深度的强大检索系统;最后,我们迈入了多模态的新大陆,让机器学会了“看图说话”。
这不仅仅是一场技术的演进,更是我们赋予机器从“识别符号”到“理解世界”能力的一大步。
未来已来,这些检索技术正是当前火热的大语言模型(LLM)应用和Agent智能体的基石。一个强大的RAG系统,其检索模块的优劣直接决定了最终生成内容的质量上限。掌握了从稀疏到密集、从单模态到多模态的检索技术,并了解了向量数据库等生产化工具,你就掌握了构建下一代AI应用的核心钥匙。
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】
更多推荐

 18
18 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)