【Big Data】实时数仓的全能选手:Hologres 的湖仓一体与向量计算如何适配 AI 时代
Hologres是阿里巴巴自主研发的一站式实时数仓引擎(Real-Time Data Warehouse),支持海量数据实时写入、实时更新、实时加工、实时分析,支持标准SQL(兼容PostgreSQL协议和语法,支持大部分PostgreSQL函数),支持PB级数据多维分析(OLAP)与即席分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),支持多种负载的细粒度隔离与企业级安全能
目录
Hologres是阿里巴巴自主研发的一站式实时数仓引擎,基于HSAP(Hybrid Serving & Analytical Processing)架构,融合了实时服务与分析能力,支持海量数据的实时写入、实时更新、实时加工与实时分析 。作为阿里云的核心产品,Hologres已从集团内部核心业务场景走向云上商业化,成为企业构建实时数据中台、支持精细化分析、自助式分析、营销画像、人群圈选、实时风控等场景的理想选择。在2021年双11大促中,Hologres以每秒11.2亿条的高速写入和每秒1.1亿次的查询峰值,成功支撑了阿里巴巴核心业务的实时数据处理需求 ,展现了其在极端流量场景下的卓越性能。

1. 什么是阿里巴巴的Hologres?
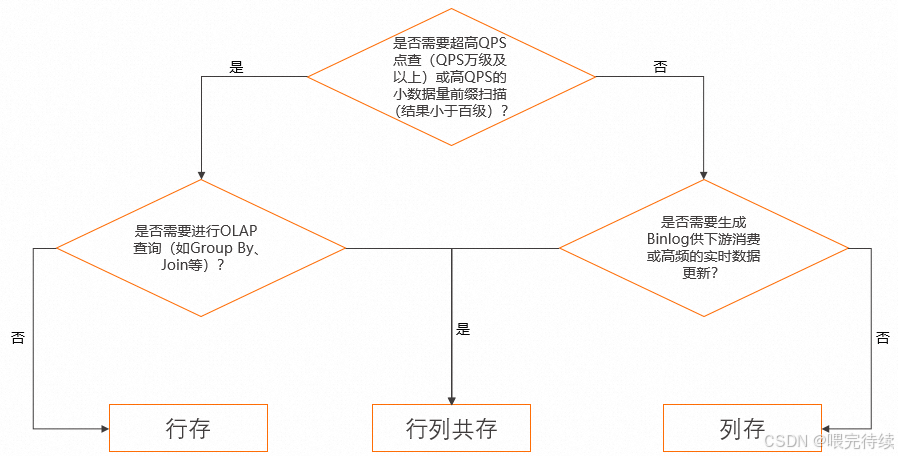
Hologres是阿里云推出的一款云原生实时数仓引擎,专为处理大规模数据的实时分析和查询而设计 。它基于HSAP架构,能够同时处理高并发点查和复杂分析查询,满足企业对实时数据服务与分析的混合负载需求。Hologres支持标准SQL(兼容PostgreSQL协议和语法),并提供了丰富的存储模式(行存、列存、行列共存)和索引类型,使开发人员能够根据不同的查询场景选择最适合的存储方式 。
Hologres的核心优势在于简化了传统大数据架构中的数据孤岛问题,通过存储计算分离和联邦查询能力,实现了离线与实时数据的一体化分析。它不仅能够支持PB级数据的亚秒级交互式分析,还能够提供每秒数十万QPS的高性能在线点查能力,适用于实时维表关联、ID-Mapping等场景。此外,Hologres还集成了向量检索和AI Function能力,支持企业构建智能化的数据分析应用。
2. Hologres的诞生背景
2.1 阿里巴巴内部需求驱动
Hologres的诞生源于阿里巴巴集团内部对实时数据处理的迫切需求。在电商、金融、物流等业务场景中,实时分析能力已成为业务决策的关键支撑 。例如,在淘宝搜索推荐场景中,用户标签和商品属性需要实时更新和查询,以支持精准的推荐策略调整。2021年双11大促期间,Hologres需要支撑每秒11.2亿条的高速写入和每秒1.1亿次的查询峰值 ,传统Lambda架构(离线分析与实时分析分离)难以满足这种极端流量场景下的实时性要求。
2.2 市场需求与技术趋势
随着企业数字化转型的深入,实时数仓市场呈现出快速增长态势。根据IDC发布的《2024年下半年中国数据仓库软件市场跟踪报告》,中国数据仓库软件市场规模已达5.5亿美元,预计到2029年将达到20.9亿美元,年复合增长率(CAGR)为15.5% 。在这一背景下,企业对数据仓库的需求已从单纯的离线分析扩展到实时服务与分析的混合负载场景。
同时,存储计算分离架构、实时分析能力以及湖仓一体技术已成为数据仓库产品应具备的基础能力。传统架构中,企业需要为不同类型的查询(简单点查、复杂分析)部署不同的系统(如HBase、Redis用于点查,Greenplum、ClickHouse用于分析),导致架构复杂度高、数据孤岛多、运维成本高。Hologres正是针对这一行业痛点,提出了一站式实时数仓解决方案。
2.3 技术演进与架构创新
Hologres的诞生也反映了数据库技术的演进方向。在传统数据库架构中,OLAP(联机分析处理)和OLTP(联机事务处理)是分离的 。随着HTAP(混合事务/分析处理)概念的兴起,一些数据库开始尝试整合这两种能力,但主要面向交易型数据。
Hologres提出的HSAP(混合服务/分析处理)架构,则更侧重于解决非交易型大数据(如日志、用户行为数据)的实时服务与分析需求 。相比HTAP,HSAP牺牲了分布式事务的强一致性保证,但在吞吐量、简单查询性能和复杂分析性能上取得了更好的平衡,更适合互联网大数据场景。
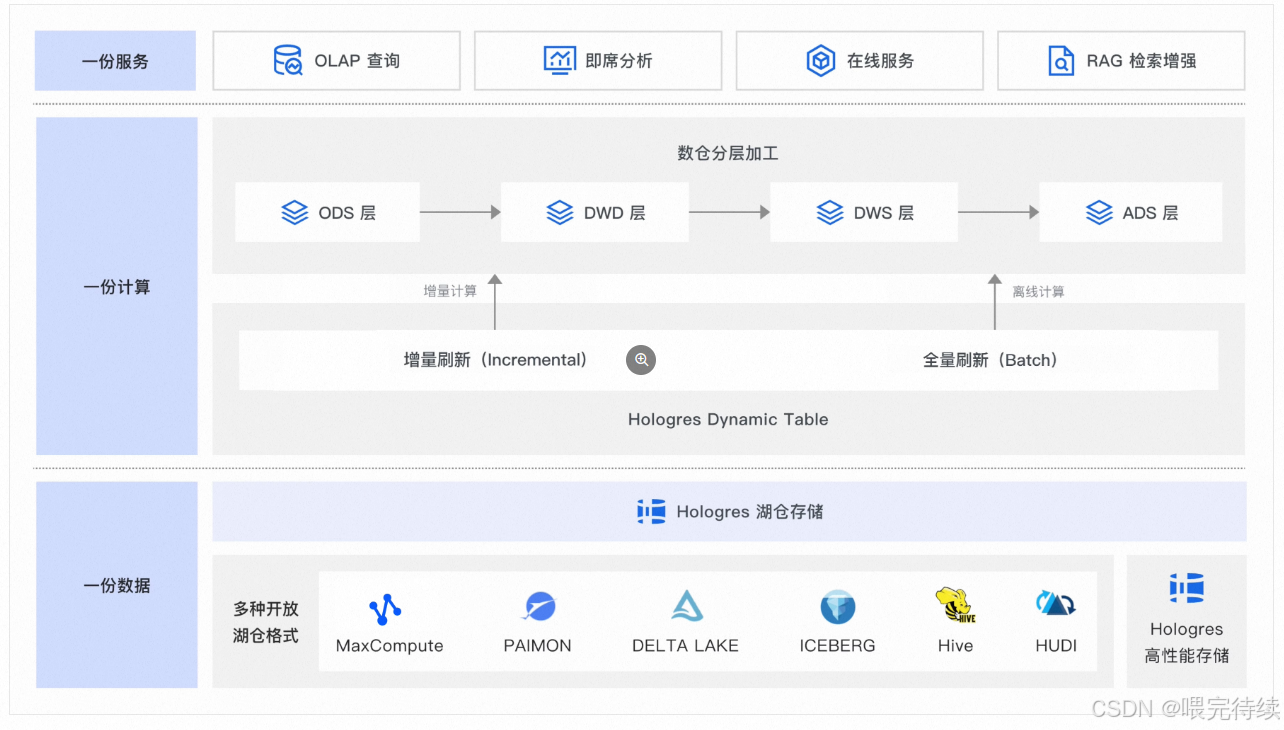
3. Hologres的技术架构
3.1 整体架构设计
Hologres采用存储计算分离架构,计算节点无状态,依赖阿里云自研的Pangu分布式文件系统进行数据存储 。这种架构设计使得计算层可以灵活扩展,无需像传统Shared Nothing架构那样进行耗时的数据rebalance操作。Hologres的架构从上到下分为接入层、计算层和存储层,整体采用MPP(Massively Parallel Processing)并行计算架构,支持大规模数据的高效处理。
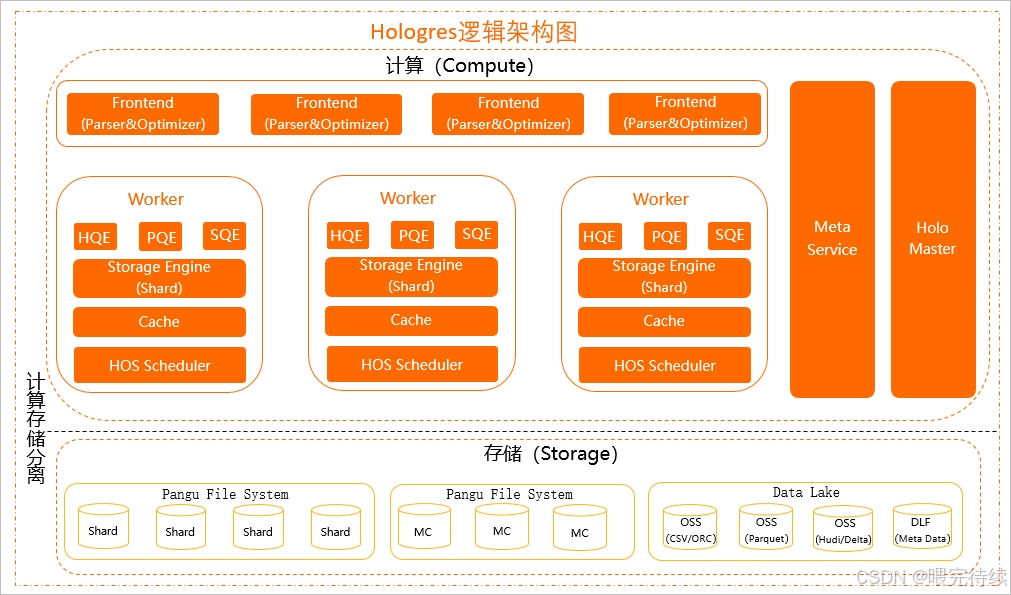
3.2 存储引擎
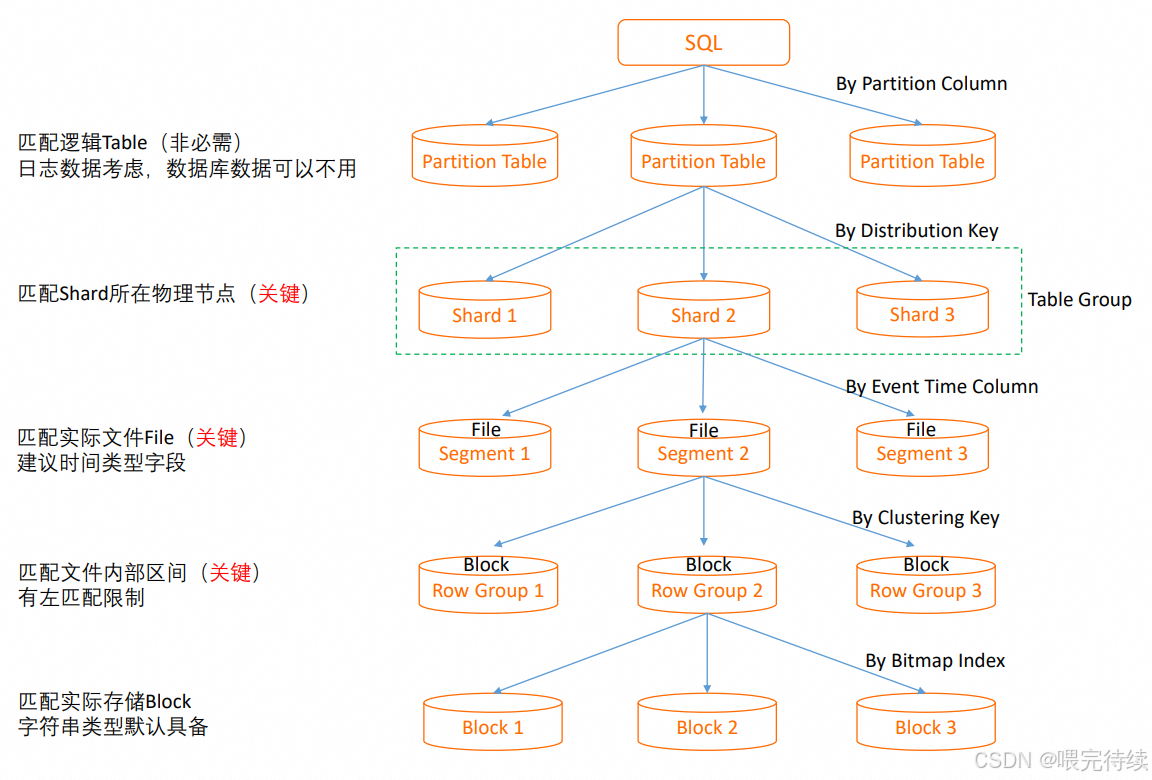
Hologres的存储引擎是其技术核心,支持三种存储格式:行存(SST)、列存(ORC)和行列共存。行存采用主键索引和短路径查询优化,适合高并发点查场景;列存采用AliORC格式,结合RLE、字典编码等压缩算法,适合复杂分析场景;行列共存模式则允许同一张表同时支持点查与分析,但会带来更多的存储开销。
在存储方式上,Hologres支持水平分区(时间/业务键)和分布式存储,数据分片策略确保了查询的高效性。Hologres的存储引擎还实现了读写隔离和数据最终一致性保证 ,使得系统在高并发写入场景下仍能保持稳定的查询性能。
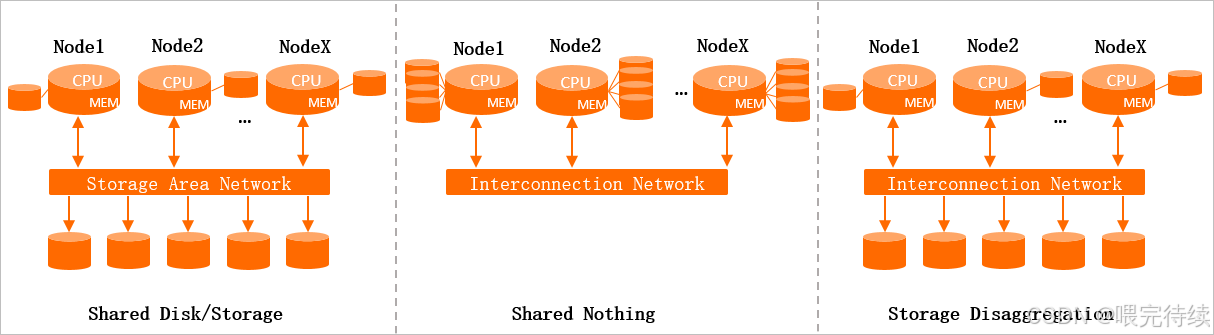
3.3 计算引擎
Hologres的计算层采用了MPP架构,包括三个主要执行引擎:
- HQE(Hologres Query Engine):自研MPP执行引擎,通过向量化算子和数据局部性优化实现亚秒级查询性能 。
- PQE(PostgreSQL Query Engine):用于兼容PostgreSQL提供扩展能力,支持PG生态的各种扩展组件 。
- SQE(Seahawks Query Engine):无缝对接MaxCompute的执行引擎,实现对MaxCompute的本地访问,无需数据迁移 。
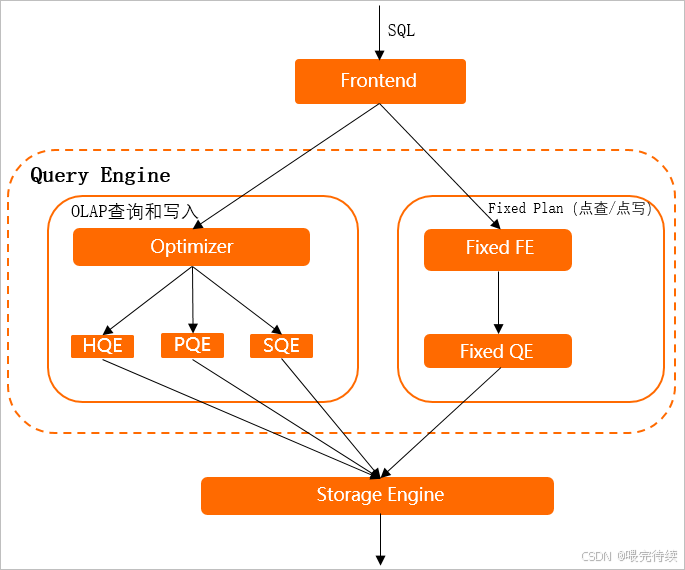
在计算资源管理上,Hologres支持资源组隔离和计算组模式,通过独立的资源配额和调度队列实现不同负载(如OLAP查询、点查、写入)之间的隔离,避免资源抢占 。Hologres还采用了轻量级调度单元EC(Execution Context),解决了线程切换开销大的问题,提高了资源利用率。
3.4 联邦查询与数据湖加速
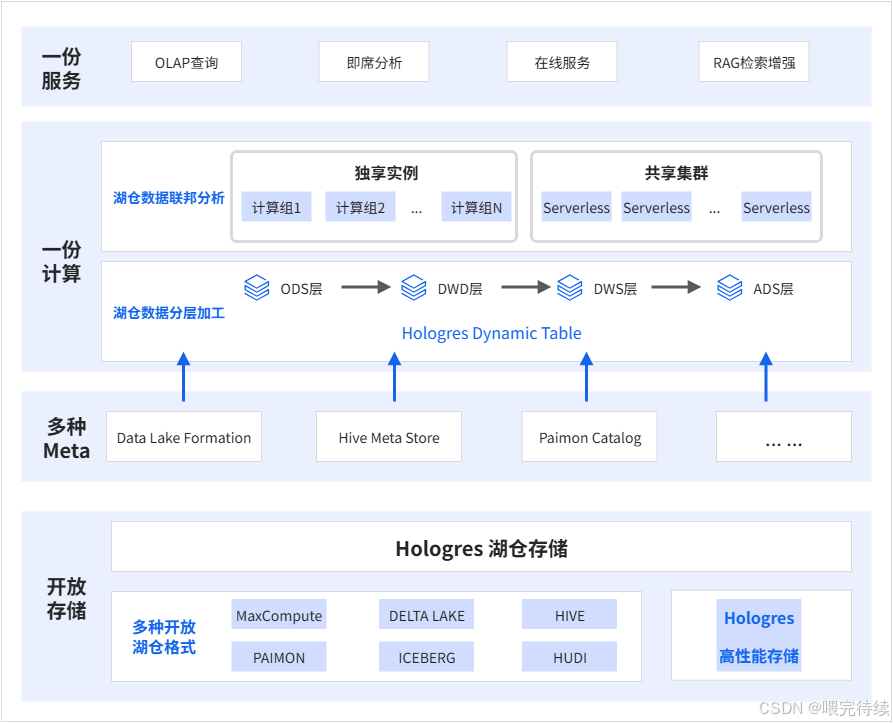
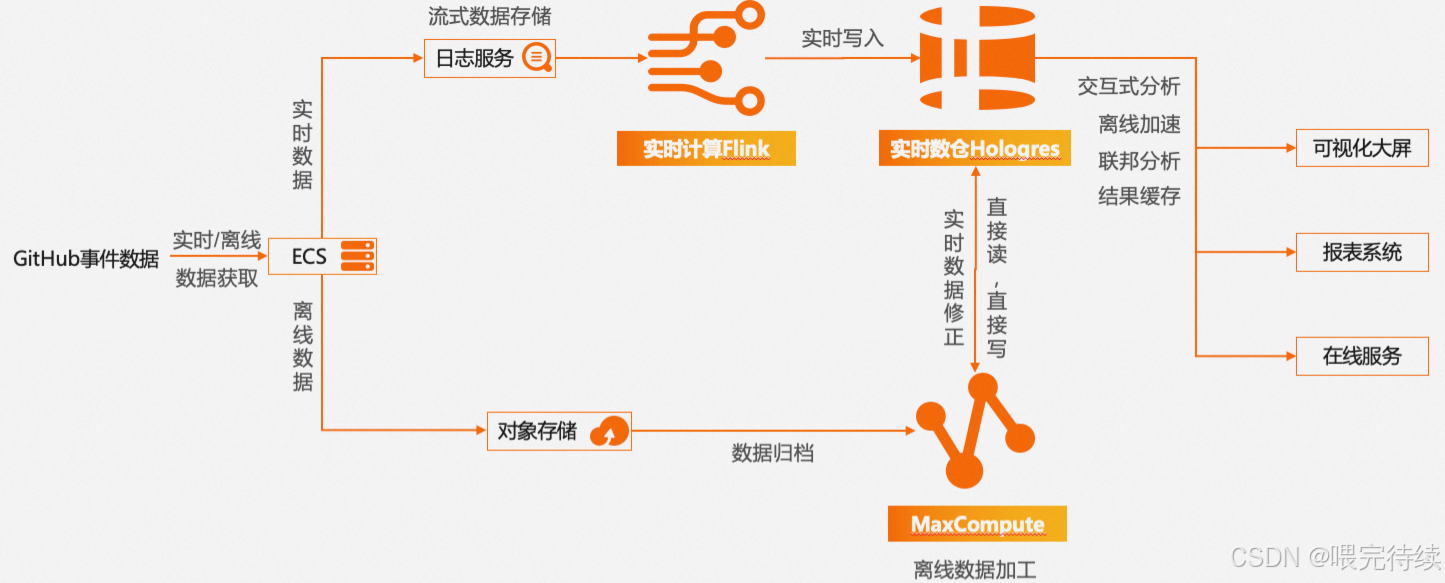
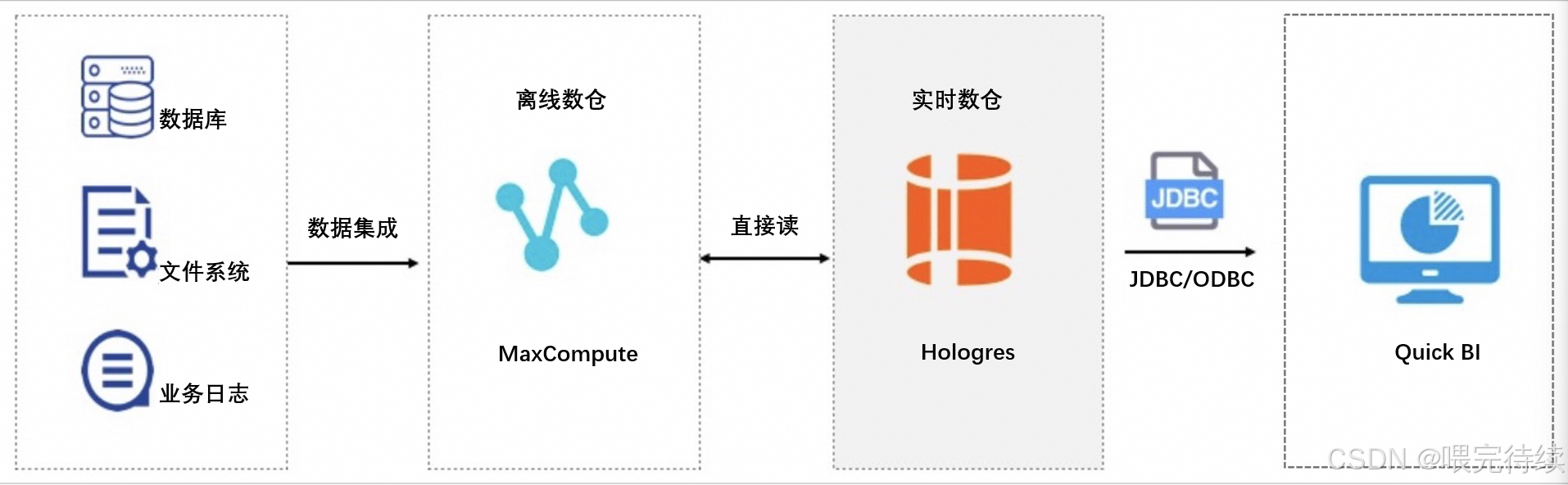
Hologres通过SQE引擎实现了与MaxCompute的直连,直接读取MaxCompute的Pangu存储,无需数据迁移,即可实现对PB级离线数据的毫秒级交互式分析 。这种联邦查询能力使Hologres能够无缝连接企业现有的离线数据仓库,降低数据架构复杂度。
此外,Hologres还支持OSS数据湖格式读写,简化了数据入湖入仓流程,实现了湖仓一体化 。通过外部表透明加速查询和元数据自动导入,Hologres相比原生MaxCompute访问加速了5-10倍。
4. Hologres解决的关键问题
4.1 数据孤岛与冗余问题
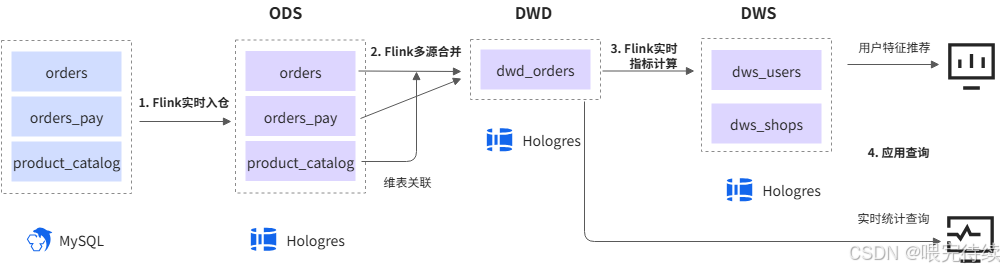
传统Lambda架构中,实时数据和离线数据需要分别存储在不同的系统中,导致数据冗余和同步延迟 。Hologres通过联邦查询与MaxCompute直连,解决了这一问题,无需数据迁移即可实现冷热数据关联分析。在淘宝搜索推荐场景中,通过Hologres将Text Array升级为JSONB格式,不仅提升了查询性能400%+,还节约了数千core资源,实现了降本增效。
4.2 实时性不足问题
传统数仓架构下,数据从采集到可用存在明显的延迟,难以满足实时决策需求。Hologres支持数据写入即可查(ACID事务),实现了亚秒级的实时分析体验 。在双11场景中,Hologres的实时写入与查询能力,使业务能够实时监控交易数据,及时调整运营策略,为大促活动的成功提供了技术保障 。
4.3 多负载冲突问题
在混合负载场景下,高并发点查和复杂分析查询往往相互影响,导致系统性能波动 。Hologres通过计算组实例和资源组隔离技术,实现了不同负载之间的物理隔离 ,例如可以将256Core作为写入和加工实例,512Core作为OLAP只读实例,128Core作为在线Serving实例,确保各业务场景的SLA得到保障。
4.4 半结构化数据处理低效问题
随着数据采集方式的多样化,JSON等半结构化数据在企业中广泛应用。Hologres原生支持JSONB列式存储压缩,使半结构化数据的存储和分析效率接近原生列存效率 。在游戏行业长周期留存计算场景中,Hologres的JSON函数优化使开发人员能够将ndays(天数)和指标值转换为JSON格式数据,然后在外层使用JSONB处理函数进行展开和计算,显著提升了数据处理效率。
4.5 AI与分析融合困难问题
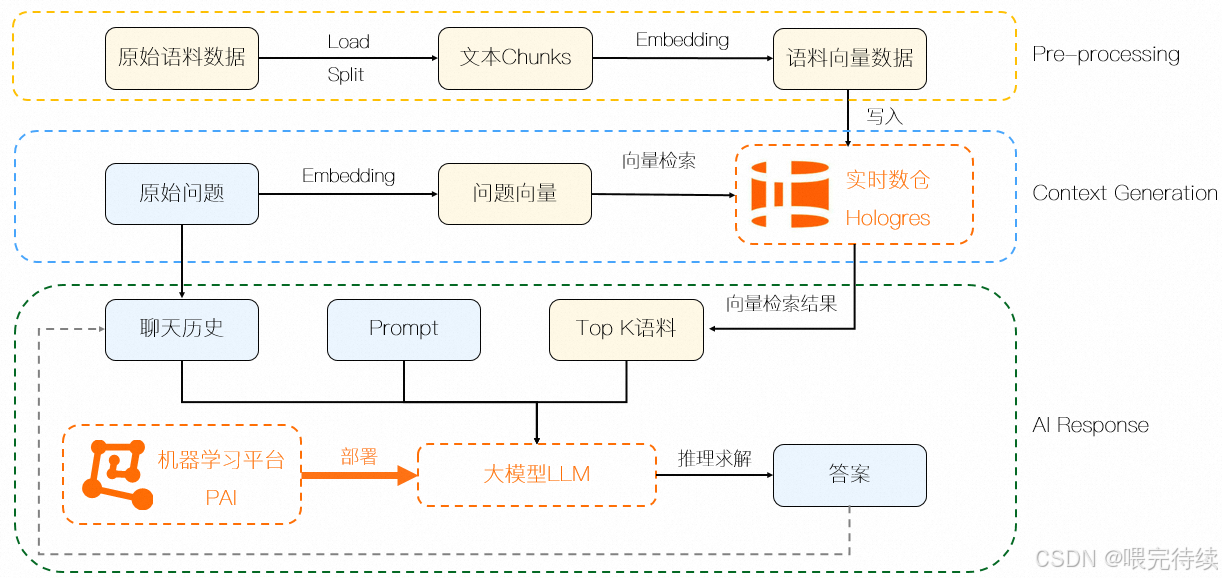
传统架构中,AI应用需要将数据导出到专门的AI系统中进行处理,增加了数据流转的复杂性。Hologres通过内置Pro厦门市向量检索库和AI Function能力,实现了数据存储、检索、推理的一体化。在企业知识库、ChatBI等应用场景中,无需额外数据导出,即可通过SQL方式完成全流程闭环,释放数据价值,促进业务精细化增长。
5. Hologres的关键特性
5.1 行列混合存储引擎
Hologres的存储引擎是其最核心的创新点,支持行存、列存和行列共存三种存储模式,能够根据不同的查询场景自动优化存储和查询路径。行存模式采用主键索引和短路径查询优化,适合高并发点查场景;列存模式采用AliORC格式,结合多种编码和压缩算法,适合复杂分析场景;行列共存模式则允许同一张表同时支持点查与分析,简化了数据架构。
在行存实现上,Hologres采用了LSM-Tree结构,通过WAL(Write-Ahead Log)日志保证数据的Exactly Once写入,支持高吞吐实时更新。列存的AliORC格式压缩率显著高于Parquet,例如在天气数据集上Zlib压缩比达7:1,结合向量化算子和AliORC优化,查询性能大幅提升。
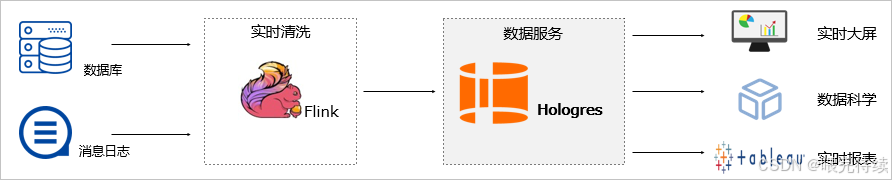
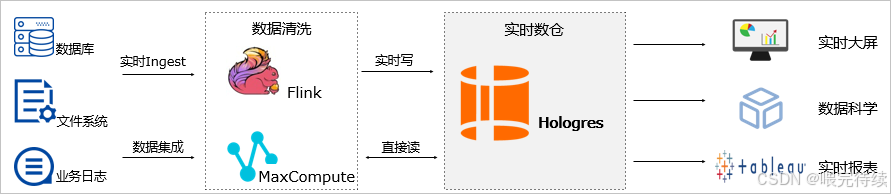
5.2 实时分析与服务一体化(HSAP)
Hologres的核心架构理念是HSAP,将分析(OLAP)与服务(Serving)能力统一在一个系统中。相比传统的HTAP架构(混合事务/分析处理),HSAP更专注于非交易型大数据的实时服务与分析,通过行列混合存储和资源组隔离技术,实现了高并发点查与复杂分析的高效协同 。
在HSAP架构下,Hologres能够同时替换OLAP系统(如Greenplum、Presto)和Serving系统(如HBase、Redis),1份数据即可满足OLAP查询、即席分析、在线服务、向量计算多个场景,显著降低了架构复杂度和数据维护成本 。
5.3 高吞吐实时写入与更新
Hologres支持高并发实时写入与更新,每秒可处理数千万甚至上亿条数据 。在128C实例上,Hologres的Fixed Plan模式实现了高效的数据写入,盲写(append only模式)每秒可达230万RPS,写入包含主键且采用insert or ignore模式每秒可达200万RPS,按主键进行upsert操作每秒可达80万RPS。
Hologres还支持Exactly Once写入语义,确保数据在高并发写入场景下的准确性和一致性。在淘宝搜索推荐场景中,Hologres通过JSONB列式存储优化,支持每秒上千万的流量峰值,满足了实时A/B实验看板等应用场景的需求。
5.4 联邦查询与数据湖加速
Hologres的联邦查询能力是其另一大创新,通过SQE(Seahawks Query Engine)引擎直接读取MaxCompute的Pangu存储 ,实现了冷热数据的无缝关联分析。相比原生MaxCompute访问,Hologres联邦查询加速了5-10倍,同时支持MaxCompute与Hologres之间百万行每秒的高速同步。
在数据湖场景中,Hologres支持OSS数据湖格式读写,简化了数据入湖入仓流程,实现了湖仓一体化,0 ETL导入离线MaxCompute数据。通过外部表透明加速查询和元数据自动导入,Hologres为BI分析提供了便捷的入口。
5.5 向量检索与AI Function
Hologres与阿里达摩院的Pro厦门市向量检索库深度集成,支持高效的应用场景如相似度搜索、图像检索以及场景识别等。相比开源的Faiss等同类产品,Pro厦门市在稳定性、性能等方面更具优势。
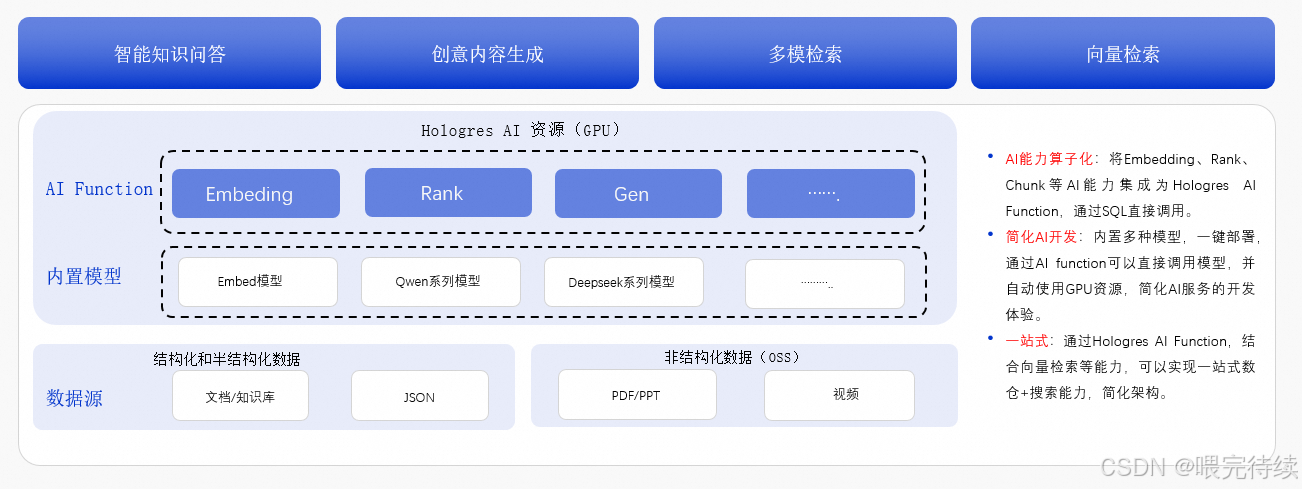
自V3.2版本开始,Hologres提供GPU资源售卖和AI Function能力,通过SQL方式即可调用AI模型进行推理。Hologres的MCP协议实现了Hologres MCP Server,为AI Agent与Hologres数据库之间的通信提供了通用接口,提升了AI与Hologres数据库的交互效率。
5.6 企业级运维能力
Hologres提供了丰富的企业级运维能力,支持计算负载、访问权限等细粒度管控要求,提供丰富的监控和告警指标 。在资源管理上,Hologres支持计算资源弹性扩展和系统热升级,满足企业级安全可靠的运维需求 。
Hologres还支持多计算组实例共享存储 ,实例间数据异步实时同步,延迟在毫秒级别。这种部署方案实现了完整的读写分离功能,保障不同业务场景的SLA。
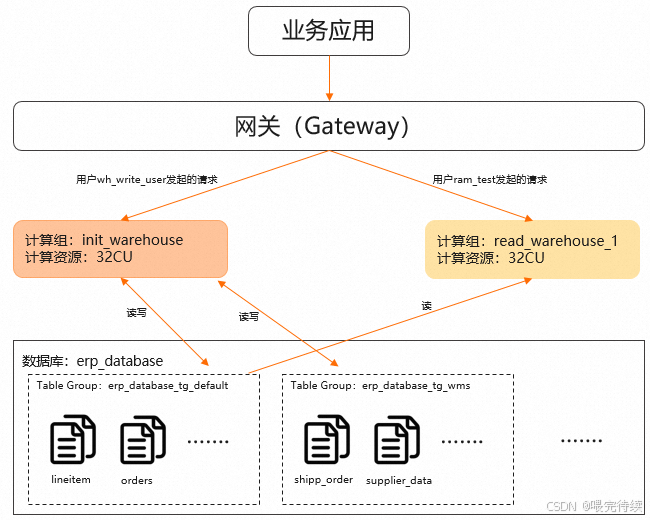
在安全方面,Hologres支持BYOK数据存储加密、数据脱敏、IP白名单等企业级安全能力,通过PCI-DSS安全认证,满足金融等高安全要求行业的使用需求 。
6. Hologres与同类产品的对比
6.1 与Greenplum对比
| 特性 | Hologres | Greenplum |
|---|---|---|
| 存储模式 | 行存、列存、行列共存 | 主要列存,支持行存但优化不足 |
| 实时写入能力 | 每秒数千万至亿级写入 | 实时写入能力较弱,适合批量导入 |
| 查询延迟 | 亚秒级交互式分析 | 秒级查询,复杂查询延迟更高 |
| 扩展性 | 存储计算分离,弹性扩展 | Shared Nothing架构,扩展需rebalance |
| 资源隔离 | 支持资源组和计算组隔离 | 资源隔离能力有限 |
| 生态集成 | 深度集成MaxCompute、Flink、DataWorks | 生态集成相对简单 |
Greenplum是基于PostgreSQL开发的MPP数据库,专为大规模数据分析而设计,但在实时写入和高并发点查方面存在明显不足。Hologres通过HSAP架构和存储计算分离设计,在实时性、扩展性和资源隔离方面具有显著优势 ,特别适合需要同时处理实时服务与复杂分析的混合负载场景。
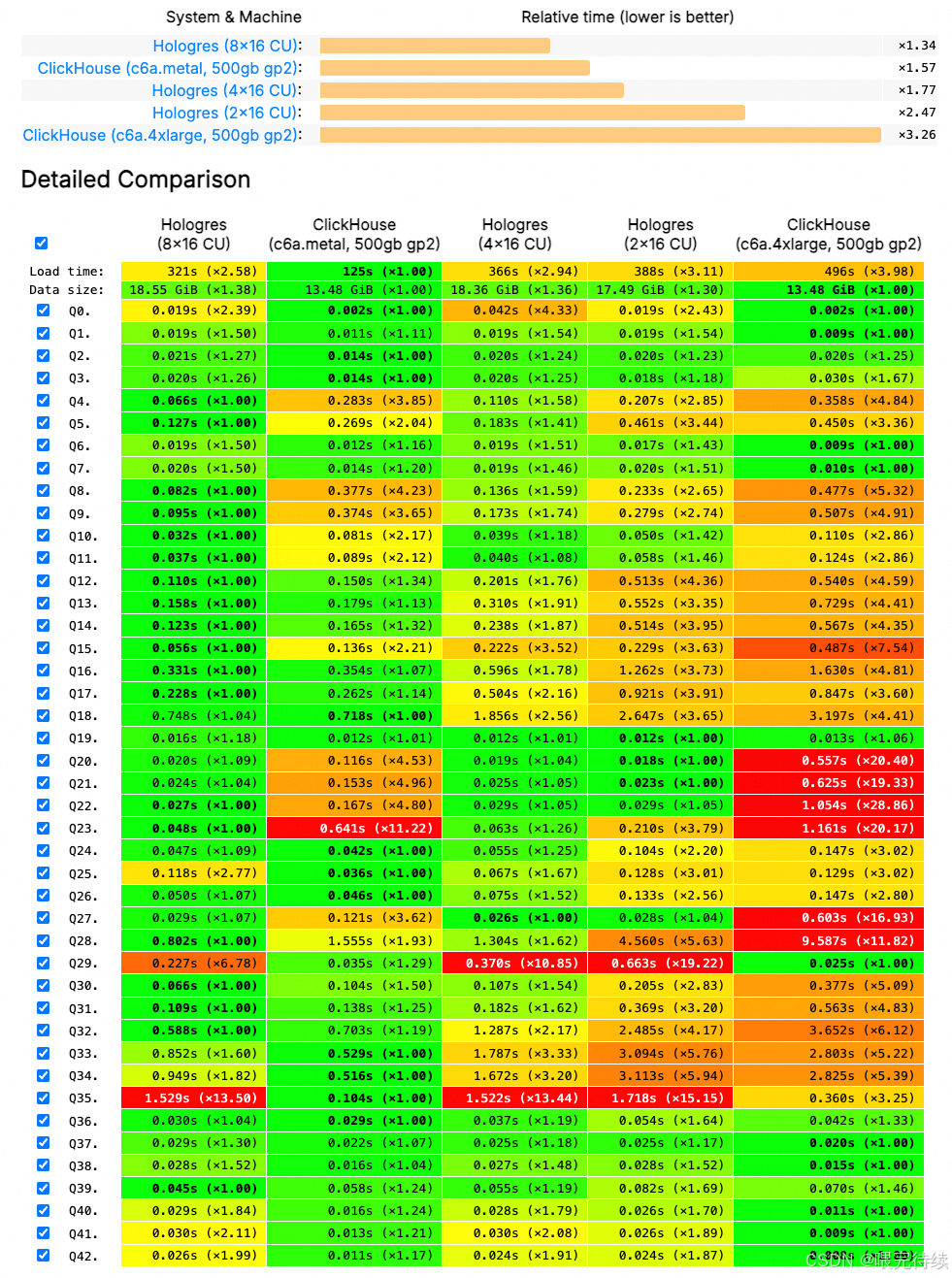
6.2 与ClickHouse对比
| 特性 | Hologres | ClickHouse |
|---|---|---|
| 事务支持 | 支持ACID事务,支持Update/delete | 仅支持INSERT,无事务支持 |
| 多负载隔离 | 支持资源组和计算组隔离 | 多表JOIN性能差,无负载隔离 |
| 存储模式 | 行存、列存、行列共存 | 主要列存,存储模式单一 |
| 扩展性 | 弹性扩展,支持Serverless | 扩展性有限,依赖分片策略 |
| 生态集成 | 深度集成MaxCompute、Flink、DataWorks | 生态集成相对简单 |
| SQL兼容性 | 兼容PostgreSQL | 自有SQL语法,兼容性较差 |
ClickHouse是目前开源MPP计算框架中计算速度最快的之一,特别擅长单表查询。但在多表JOIN、事务支持和资源隔离方面存在明显不足,难以满足混合负载场景的需求。Hologres通过HSAP架构和资源组隔离技术,在混合负载场景下性能表现更佳 ,同时保持了与PostgreSQL生态的兼容性,降低了开发和运维成本。
6.3 与Milvus对比
| 特性 | Hologres(Pro厦门市) | Milvus |
|---|---|---|
| 集成度 | 内置向量检索,无需独立部署 | 需要独立部署向量数据库 |
| 稳定性 | 企业级稳定性,支持高并发 | 开源版本稳定性有限 |
| 性能优化 | 与Hologres存储引擎深度集成 | 需要额外开发分布式能力 |
| 数据安全 | 支持BYOK加密、数据脱敏等企业级安全能力 | 安全能力相对简单 |
Milvus是由国内团队主导的开源云原生向量数据库,支持多种高效的向量索引和距离度量。但相比Hologres内置的Pro厦门市向量检索库,Milvus在企业级稳定性、与存储引擎的集成度以及数据安全方面存在差距。Hologres通过将向量检索能力内置到实时数仓引擎中,简化了AI与数据分析的融合流程,使企业能够更便捷地构建智能化的数据分析应用。
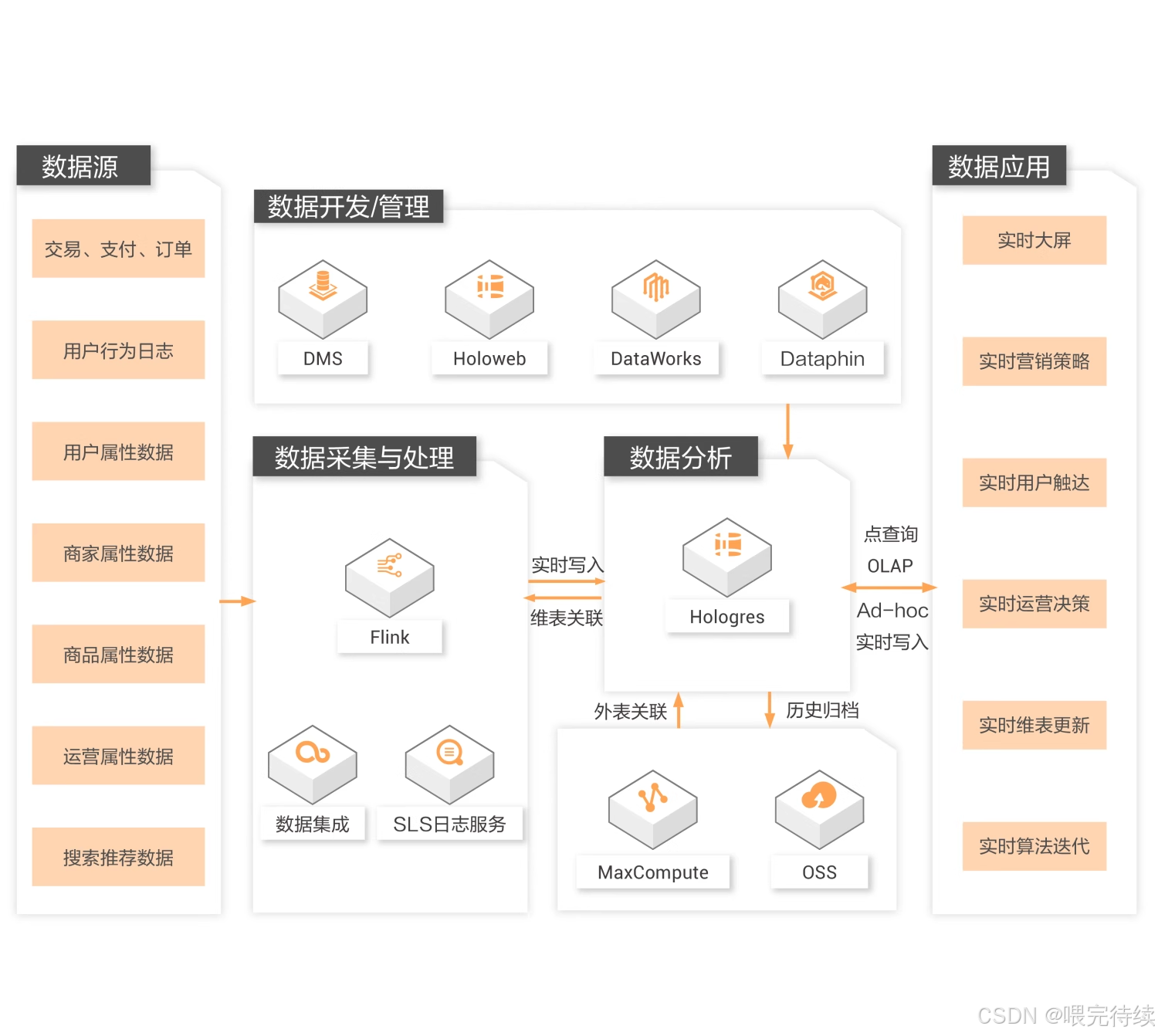
7. Hologres的实际使用方法
7.1 连接与基础操作
Hologres兼容PostgreSQL协议,可以通过多种方式连接和操作:
Java连接示例:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql Statement;
public class HologresExample {
public static void main(String[] args) {
// JDBC连接信息
String url = "jdbc:hologres://hostname:port/database";
String username = "your_username";
String password = "your_password";
try {
// 加载Hologres JDBC驱动
Class.forName("com.aliyun.hologres.jdbc.HologresDriver");
// 建立连接
Connection conn = DriverManager.getConnection(url, username, password);
Statement stmt = conn.createStatement();
// 执行SQL查询
String sql = "SELECT * FROM table_name";
ResultSet rs = stmt.executeQuery(sql);
// 处理查询结果
while (rs.next()) {
// 读取数据示例
int id = rs.getInt("id");
String name = rs.getString("name");
System.out.println("ID: " + id + ", Name: " + name);
}
// 关闭资源
rs.close();
stmt.close();
conn.close();
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
}
}
}Python连接示例:
import holostore
import langchain
import langchain_openai
import langchain_text_splitters
import langchain_community
import langchain_community vectorstores
import os
# 设置环境变量以连接Hologres
os.environ['PG_HOST'] = 'your_host'
os.environ['PG_USER'] = 'your_user'
os.environ['PG_PASSWORD'] = 'your_password'
# 创建连接字符串
connection_string = holostore connection_string_from_db_params(
host/os.environ.get("PGHOST", "localhost"),
port/int(os.environ.get("PGPORT", "80")),
database/os.environ.get("PGDATABASE", "postgres"),
username/os.environ.get("PGUSER", "postgres"),
password/os.environ.get("PGPASSWORD", "postgres"),
)
# 使用连接字符串创建Hologres客户端
client = holostore Client(connection_string)7.2 实时写入与更新
Hologres支持多种实时写入方式,包括Flink CDC、Kafka Connect等。在Flink实时写入场景中,推荐使用Fixed Plan模式,通过预生成执行计划减少优化器开销,实现高吞吐。
Flink写入配置示例:
source:
type: mysql
name: MySQL Source
hostname: localhost
port: 3306
username: username
password: password
tables: holo_test.\*
server-id: 8601-8604
include-comments.enabled: true
scan.incremental.snapshot.unbounded-chunk-first.enabled: true
scan-only deserialize captured tables changelog.enabled: true
sink:
type: hologres
name: Hologres Sink
endpoint: ****.hologres.aliyuncs.com:80
dbname: cdcyaml_test
username: ${secret_values.holo-username}
password: ${secret_values.holo-password}
sink.type-normalize-strategy: BROADEN在配置Flink CDC作业时,建议设置include-comments.enabled同步表注释和字段注释,以及scan.incremental.snapshot.unbounded-chunk-first.enabled避免可能出现的TaskManager OutOfMemory问题。
7.3 存储模式选择与优化
Hologres支持三种存储模式,选择合适的存储模式对性能至关重要:
行存模式:适合基于主键的高并发点查场景,建议不超过3000列。
CREATE TABLE orders_row (...) WITH (orientation = 'row');列存模式:适合复杂分析场景,建议不超过300列。
CREATE TABLE lineitem (...) WITH (orientation = 'column');行列共存模式:适合需要同时支持点查和分析的场景,但会带来额外存储开销。
CREATE TABLE orders (...) WITH (orientation = 'row(column)');在表设计上,建议根据实例规格设置合适的Shard数,例如64Core实例可设置40-64个Shard。Distribution Key应选择均匀分布的字段(如用户ID),避免使用年龄、性别等可能使数据分布不均的字段。
-- 设置Shard数和Distribution Key
CREATE TABLE public.tbl_col (
id TEXT NOT NULL,
name TEXT NOT NULL,
class TEXT NOT NULL,
in_time TIMESTAMPTZ NOT NULL,
PRIMARY KEY (id)
) WITH (
orientation = 'column',
clustering_key = 'class',
bitmap_columns = 'name',
event_time_column = 'in_time',
shard_count = 64
);7.4 资源组隔离配置
Hologres支持资源组隔离,可以为不同业务场景分配独立的资源配额,避免资源抢占。以下是HoloWeb中资源组管理的步骤:
- 登录HoloWeb开发页面,进入顶部菜单栏的"安全中心"。
- 在左侧导航栏选择"资源组管理"。
- 选择目标实例名称,单击"新增资源组"。
- 输入资源组名称并设置资源组配额(总和不能超过1)。
- 绑定用户到资源组,一个用户仅能被绑定到一个资源组 。
资源组配置示例:
资源组名称 | 资源组配额 | 绑定用户
----------|-----------|---------|
olap_query | 0.5 | user1, user2
point_check | 0.3 | user3, user4
realtime_write | 0.2 | user5, user67.5 向量检索实战
Hologres与Pro厦门市的深度集成,使向量检索变得简单高效。以下是使用Python SDK实现向量搜索的完整流程:
安装依赖库:
pip install hologres-vector langchain langchain-openai langchain-text-splitters langchain-community加载文档并创建向量库:
from langchain_community vectorstores import Hologres
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community document_loaders import TextLoader
import os
# 加载文档
loader = TextLoader ("../../how_to/state_of_the_union.txt")
documents = loader.load()
# 文档分割
text_splitter = CharacterTextSplitter (chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
# 创建嵌入
embeddings = OpenAIEmbeddings()
# 设置环境变量以连接Hologres
os.environ ['PG_HOST'] = 'your_host'
os.environ ['PG_USER'] = 'your_user'
os.environ ['PG_PASSWORD'] = 'your_password'
# 创建连接字符串
connection_string = Hologres connection_string_from_db_params(
host/os.environ.get("PGHOST", "localhost"),
port/int(os.environ.get("PGPORT", "80")),
database/os.environ.get("PGDATABASE", "postgres"),
username/os.environ.get("PGUSER", "postgres"),
password/os.environ.get("PG_PASSWORD", "postgres"),
)
# 将嵌入和文档存储到Hologres
vector_db = Hologres.from_documents(
docs,
embeddings,
connection_string=connection_string,
table_name="langchain_example_embeddings"
)
# 执行相似性搜索
query = "What did the president say about Ketanji Brown Jackson"
docs = vector_db similarity_search(query)
print(docs[0].page_content)向量检索优化建议:
- 文档分块大小建议500-1000字符,平衡语义完整性和检索效率
- 使用阿里云API确保国内访问速度与稳定性
- 对于高维向量,考虑使用Pro厦门市的HNSW索引算法
7.6 联邦查询与数据湖加速
Hologres支持联邦查询与MaxCompute直连,无需数据迁移即可查询MaxCompute表。以下是联邦查询的配置步骤:
- 设置GUC参数(Session级别开启):
SET hg_experimental_external_catalog_routing = 'odps:common_table';- 创建外部数据库或表:
-- 整库映射
CREATE EXTERNAL DATABASE maxcompute_project
FROM odps.'project_name';
-- 批量创建外部表
IMPORT FOREIGN SCHEMA maxcompute_schema
FROM odps.'project_name'.'schema_name'
INTO hologres_schema;
-- 创建单个外部表
CREATE FOREIGN TABLE hologres_table
(LIKE hologres_table)
FROM odps.'project_name'.'schema_name'.'table_name'
WITH (
orientation='column',
distribution_key='column_name'
);联邦查询优化建议:
- 对于大查询,做好资源隔离,可使用Serverless模式
- 设置合适的分布键,提高查询效率
- 对于频繁查询的字段,考虑在Hologres中创建物化视图
7.7 AI Function使用方法
Hologres的AI Function能力允许通过SQL方式使用GPU资源执行AI模型。以下是AI Function的基本使用流程:
- 部署AI模型到Hologres:
CREATE AI FUNCTION ai_model_name
( input_column TEXT ) RETURNS TEXT
USING 'model_path'
WITH (
model_type = 'text-generation',
input_format = 'text',
output_format = 'text',
max Concurrency = 10
);- 在SQL中调用AI Function:
SELECT ai_model_name(text_column) AS ai_result
FROM table_name
WHERE id = 'doc1';AI Function优化建议:
- 根据模型复杂度设置合适的max Concurrency参数
- 对于高频调用的模型,考虑使用热缓存策略
- 结合实时物化视图,预计算常用AI分析结果
8. 总结与展望
Hologres作为阿里巴巴自主研发的一站式实时数仓引擎,通过HSAP架构和存储计算分离设计,成功解决了传统大数据架构中的数据孤岛、实时性不足、多负载冲突等问题,为企业提供了高性能、高可靠、低成本、可扩展的实时数据仓库解决方案 。
在实际应用中,Hologres已广泛应用于实时数据中台建设、精细化分析、自助式分析、营销画像、人群圈选、实时风控等场景。特别是在2021年双11大促期间,Hologres以每秒11.2亿条的高速写入和每秒1.1亿次的查询峰值,成功支撑了阿里巴巴核心业务的实时数据处理需求 ,展现了其在极端流量场景下的卓越性能。
未来,随着AI技术的不断发展和企业对实时分析需求的进一步提升,Hologres将继续演进,深化其在AI与数据分析融合方面的优势。Hologres已开始支持MCP协议,为AI Agent与数据库之间的通信提供了通用接口;同时,Hologres也在积极扩展其在多模态数据分析、实时预测等领域的应用能力。
对于技术开发人员而言,Hologres提供了一个统一的数据处理与分析平台,能够通过标准SQL接口实现从数据写入、存储到分析、服务的全流程,显著降低了开发和运维复杂度。同时,Hologres与阿里云生态的深度集成,也为企业提供了更加便捷的数据管理与分析解决方案。
随着Hologres的持续迭代和阿里云生态的不断完善,Hologres有望成为企业构建实时数据中台的首选技术,为企业数字化转型提供强大支撑。
参考资料:
本博客专注于分享开源技术、微服务架构、职场晋升以及个人生活随笔,这里有:
📌 技术决策深度文(从选型到落地的全链路分析)
💭 开发者成长思考(职业规划/团队管理/认知升级)
🎯 行业趋势观察(AI对开发的影响/云原生下一站)
关注我,每周日与你聊“技术内外的那些事”,让你的代码之外,更有“技术眼光”。
日更专刊:
🥇 《Thinking in Java》 🌀 java、spring、微服务的序列晋升之路!
🏆 《Technology and Architecture》 🌀 大数据相关技术原理与架构,帮你构建完整知识体系!关于博主:

一座年轻的奋斗人之城,一个温馨的开发者之家。在这里,代码改变人生,开发创造未来!
更多推荐

 37
37 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)