AI 测试技术全解析:框架、检测与优化实践
本文探讨了AI技术在软件测试领域的创新应用与发展趋势。首先,文章介绍了智能自动化测试框架的架构设计,包括四层核心结构和AI增强组件,对比了传统与AI测试框架的差异。其次,详细阐述了智能缺陷检测技术路径,提供了基于CNN的UI缺陷检测和缺陷分析修复的代码实现。第三部分分析了AI优化A/B测试的方法,包括多臂老虎机算法和贝叶斯统计分析。随后展示了电商平台全链路AI测试的综合应用案例及成效评估。最后,文
一、自动化测试框架与 AI 融合
1.1 智能自动化测试框架架构设计
现代自动化测试框架已从传统的线性执行模式演进为融合 AI 能力的智能生态系统,其核心架构包含数据层、AI 引擎层、执行层和应用层四个维度。
graph TD
A[数据层] -->|测试数据/日志/结果| B[AI引擎层]
B -->|预测/决策| C[执行层]
C -->|执行结果| D[应用层]
D -->|反馈数据| A
B -->|模型训练| B1[机器学习模块]
B -->|自然语言处理| B2[NLP模块]
B -->|视觉识别| B3[CV模块]
C --> C1[智能用例生成器]
C --> C2[自适应执行引擎]
C --> C3[动态断言生成器]
D --> D1[Web测试]
D --> D2[移动应用测试]
D --> D3[API测试]
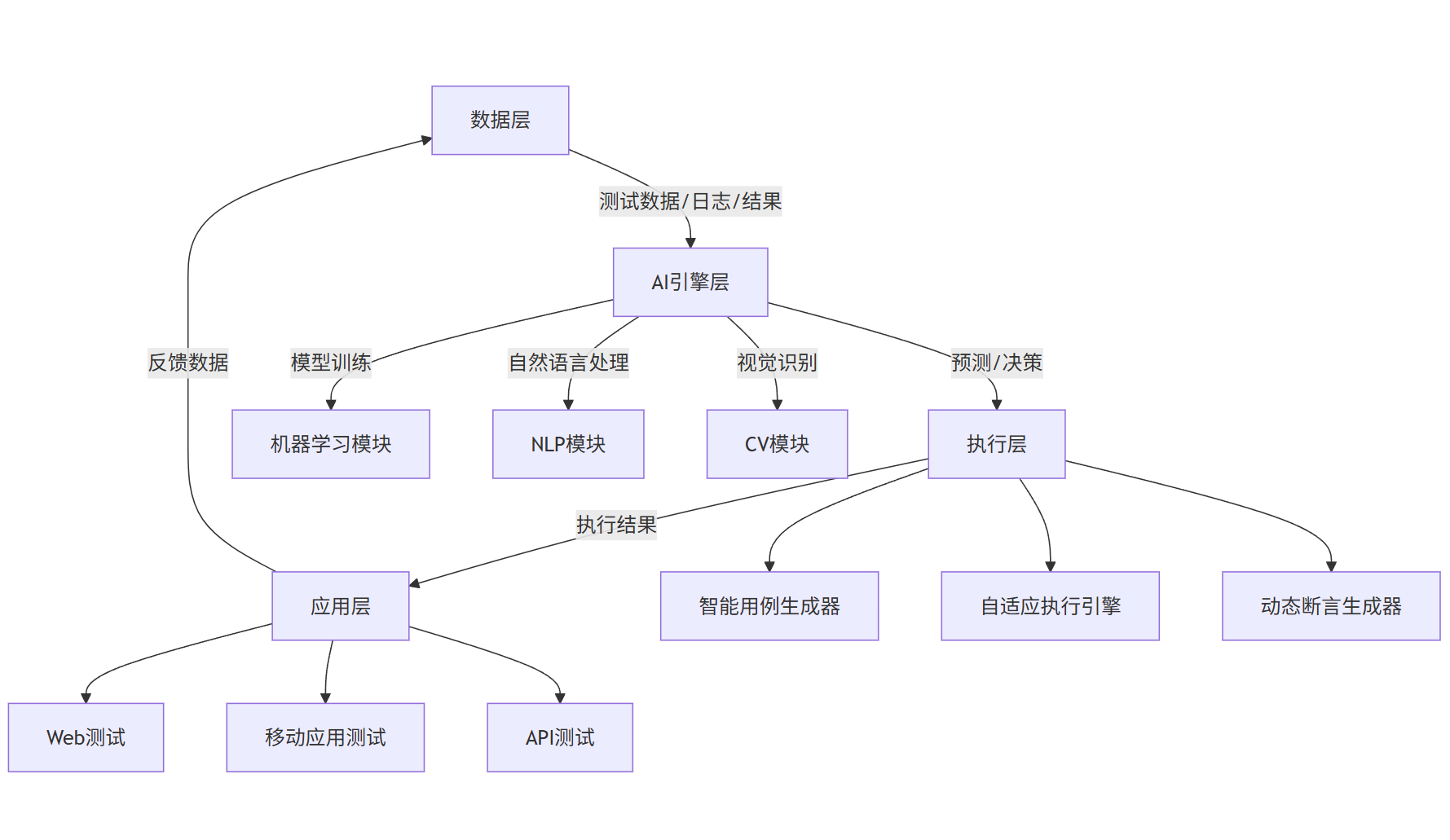
核心组件说明:
- 智能用例生成器:基于历史测试数据和需求文档自动生成测试用例
- 自适应执行引擎:根据系统负载和用例优先级动态调整执行顺序
- 动态断言生成器:通过 NLP 解析需求文档自动生成断言条件
- 机器学习模块:实现用例优先级排序、失败预测和自我修复
1.2 基于 AI 的自动化测试框架实现
以下是一个融合了强化学习的 Python 自动化测试框架核心代码:
python
运行
import unittest
import numpy as np
from sklearn.ensemble import RandomForestClassifier
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
class AITestFramework:
def __init__(self):
# 初始化测试用例库
self.test_cases = []
# 初始化强化学习模型
self.rl_model = self.build_rl_model()
# 初始化测试结果分析器
self.result_analyzer = RandomForestClassifier()
def build_rl_model(self):
"""构建用于测试用例优先级排序的强化学习模型"""
model = Sequential([
Dense(64, activation='relu', input_shape=(10,)), # 10个特征输入
Dense(32, activation='relu'),
Dense(1, activation='linear') # 输出预期收益值
])
model.compile(optimizer='adam', loss='mse')
return model
def add_test_case(self, test_case, features):
"""添加测试用例及特征"""
self.test_cases.append({
'test_case': test_case,
'features': features,
'priority': 0
})
def prioritize_test_cases(self):
"""使用RL模型计算用例优先级"""
for tc in self.test_cases:
features = np.array(tc['features']).reshape(1, -1)
priority = self.rl_model.predict(features)[0][0]
tc['priority'] = priority
# 按优先级排序
self.test_cases.sort(key=lambda x: x['priority'], reverse=True)
def execute_test_suite(self, max_executions=None):
"""按优先级执行测试套件"""
results = []
executed = 0
for tc in self.test_cases:
if max_executions and executed >= max_executions:
break
try:
# 执行测试用例
result = tc['test_case']()
results.append({
'test_case': tc['test_case'].__name__,
'status': 'passed',
'result': result
})
except Exception as e:
results.append({
'test_case': tc['test_case'].__name__,
'status': 'failed',
'error': str(e)
})
executed += 1
# 用执行结果更新模型
self.update_model(results)
return results
def update_model(self, results):
"""根据测试结果更新强化学习模型"""
# 准备训练数据
X = []
y = []
for res in results:
# 找到对应的测试用例
tc = next(tc for tc in self.test_cases
if tc['test_case'].__name__ == res['test_case'])
# 构建奖励:失败用例奖励更高(发现缺陷)
reward = 10 if res['status'] == 'failed' else 1
X.append(tc['features'])
y.append(reward)
if X and y:
# 训练模型
self.rl_model.fit(np.array(X), np.array(y), epochs=5, verbose=0)
# 示例使用
if __name__ == "__main__":
# 创建测试框架实例
ai_test = AITestFramework()
# 定义测试用例
def test_login():
# 实际测试逻辑
assert "success" in "login_success"
return "Login test passed"
def test_payment():
# 实际测试逻辑
assert 1 + 1 == 2
return "Payment test passed"
# 添加测试用例及特征(复杂度、历史失败率等)
ai_test.add_test_case(test_login, [0.8, 0.3, 0.5, 0.9, 0.2, 0.1, 0.6, 0.7, 0.4, 0.2])
ai_test.add_test_case(test_payment, [0.9, 0.7, 0.8, 0.6, 0.5, 0.9, 0.7, 0.8, 0.6, 0.5])
# 计算优先级
ai_test.prioritize_test_cases()
# 执行测试
results = ai_test.execute_test_suite()
print(results)
1.3 智能测试框架的优势分析
| 传统自动化测试框架 | AI 增强型自动化测试框架 |
|---|---|
| 固定执行顺序 | 基于预测动态调整执行顺序 |
| 人工设计断言 | 自动生成智能断言 |
| 静态测试用例 | 用例自我进化与修复 |
| 事后分析 | 实时异常预测与预防 |
| 覆盖率导向 | 风险导向的测试策略 |
| 被动反馈 | 主动学习与优化 |
二、智能缺陷检测技术与实践
2.1 缺陷检测的 AI 技术路径
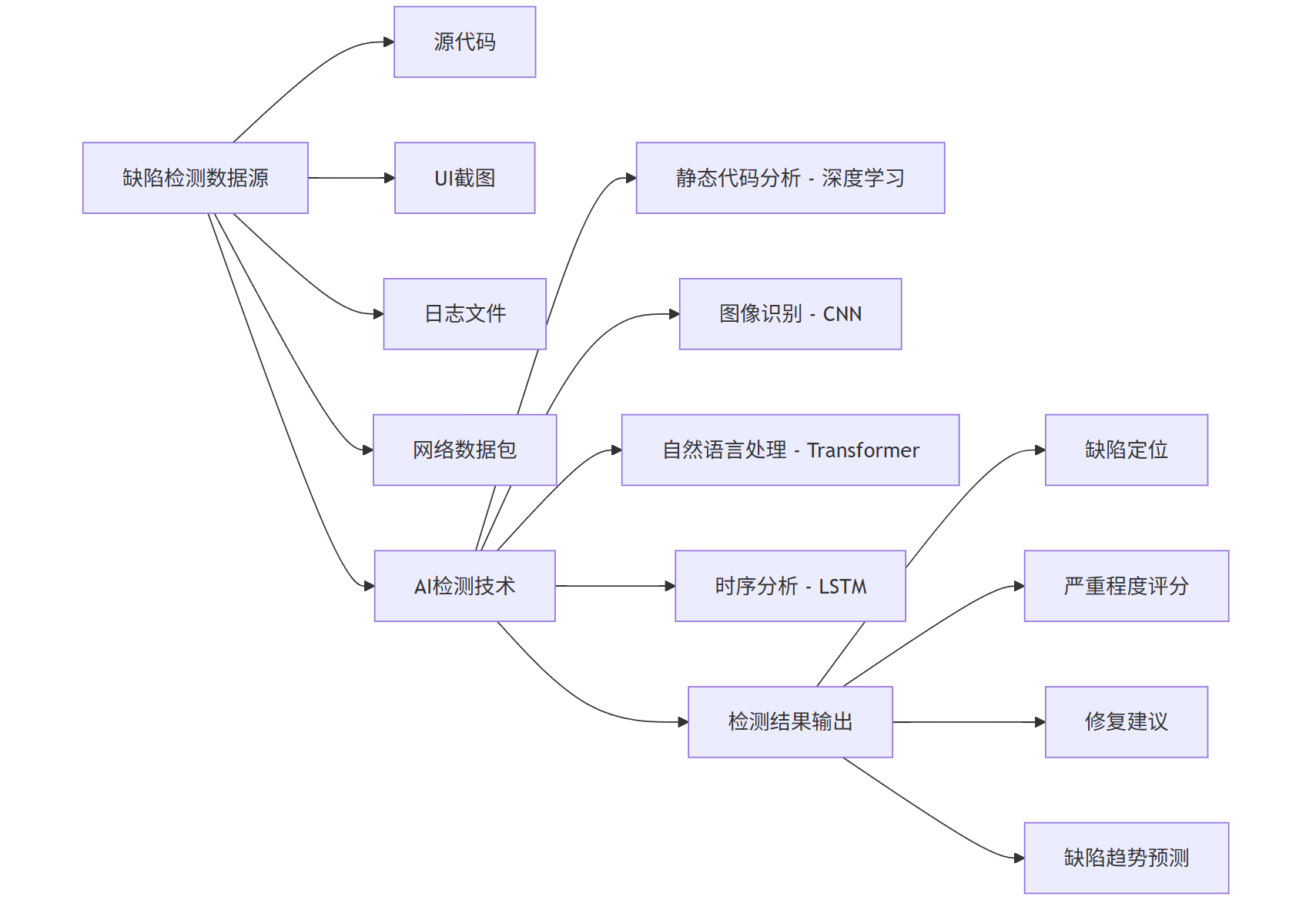
智能缺陷检测通过机器学习和深度学习技术,实现从代码、图像到用户行为数据中的异常模式识别,其技术路径如下:
graph LR
A[缺陷检测数据源] --> A1[源代码]
A --> A2[UI截图]
A --> A3[日志文件]
A --> A4[网络数据包]
B[AI检测技术] --> B1[静态代码分析 - 深度学习]
B --> B2[图像识别 - CNN]
B --> B3[自然语言处理 - Transformer]
B --> B4[时序分析 - LSTM]
C[检测结果输出] --> C1[缺陷定位]
C --> C2[严重程度评分]
C --> C3[修复建议]
C --> C4[缺陷趋势预测]
A --> B
B --> C
2.2 基于 CNN 的 UI 缺陷检测实现
以下是一个使用卷积神经网络检测 UI 界面缺陷的代码实现:
python
运行
import tensorflow as tf
from tensorflow.keras import layers, models
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
import os
from PIL import Image
# 1. 数据准备与预处理
class UIDefectDataset:
def __init__(self, dataset_dir, img_size=(224, 224)):
self.dataset_dir = dataset_dir
self.img_size = img_size
self.images = []
self.labels = []
self._load_data()
def _load_data(self):
"""加载数据集:正常UI和有缺陷的UI"""
# 加载正常样本
normal_dir = os.path.join(self.dataset_dir, 'normal')
for img_file in os.listdir(normal_dir):
img_path = os.path.join(normal_dir, img_file)
img = Image.open(img_path).resize(self.img_size)
img_array = np.array(img) / 255.0 # 归一化
self.images.append(img_array)
self.labels.append(0) # 0表示正常
# 加载缺陷样本
defect_dir = os.path.join(self.dataset_dir, 'defective')
for img_file in os.listdir(defect_dir):
img_path = os.path.join(defect_dir, img_file)
img = Image.open(img_path).resize(self.img_size)
img_array = np.array(img) / 255.0
self.images.append(img_array)
self.labels.append(1) # 1表示有缺陷
def get_train_test_split(self, test_size=0.2):
"""获取训练集和测试集"""
return train_test_split(
np.array(self.images),
np.array(self.labels),
test_size=test_size,
random_state=42
)
# 2. 构建缺陷检测模型
def build_ui_defect_model(input_shape=(224, 224, 3)):
"""构建基于CNN的UI缺陷检测模型"""
model = models.Sequential([
# 特征提取层
layers.Conv2D(32, (3, 3), activation='relu', input_shape=input_shape),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(128, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(128, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
# 分类层
layers.Flatten(),
layers.Dropout(0.5), # 防止过拟合
layers.Dense(512, activation='relu'),
layers.Dense(1, activation='sigmoid') # 二分类:正常/缺陷
])
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', tf.keras.metrics.Precision(name='precision'),
tf.keras.metrics.Recall(name='recall')]
)
return model
# 3. 模型训练与评估
def train_ui_defect_model(dataset_dir, epochs=30, batch_size=32):
"""训练UI缺陷检测模型"""
# 加载数据
dataset = UIDefectDataset(dataset_dir)
X_train, X_test, y_train, y_test = dataset.get_train_test_split()
# 构建模型
model = build_ui_defect_model(input_shape=(*dataset.img_size, 3))
# 训练模型
history = model.fit(
X_train, y_train,
epochs=epochs,
batch_size=batch_size,
validation_split=0.1
)
# 评估模型
test_loss, test_acc, test_precision, test_recall = model.evaluate(X_test, y_test)
print(f"Test accuracy: {test_acc:.4f}")
print(f"Test precision: {test_precision:.4f}")
print(f"Test recall: {test_recall:.4f}")
# 保存模型
model.save('ui_defect_detector.h5')
# 绘制训练曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.tight_layout()
plt.savefig('training_curves.png')
return model
# 4. 缺陷检测与定位
class UIDefectDetector:
def __init__(self, model_path='ui_defect_detector.h5', img_size=(224, 224)):
self.model = tf.keras.models.load_model(model_path)
self.img_size = img_size
def detect_defect(self, img_path):
"""检测单张图片中的UI缺陷"""
# 预处理图像
img = Image.open(img_path).resize(self.img_size)
img_array = np.array(img) / 255.0
img_array = np.expand_dims(img_array, axis=0)
# 预测
prediction = self.model.predict(img_array)[0][0]
is_defective = prediction > 0.5
# 如果有缺陷,尝试定位缺陷区域
defect_regions = []
if is_defective:
defect_regions = self._localize_defects(img)
return {
'is_defective': is_defective,
'confidence': float(prediction),
'defect_regions': defect_regions
}
def _localize_defects(self, img):
"""定位图像中的缺陷区域(滑动窗口方法)"""
img_array = np.array(img)
h, w, _ = img_array.shape
window_size = (64, 64)
step = 32
defect_regions = []
# 滑动窗口检测
for y in range(0, h - window_size[1], step):
for x in range(0, w - window_size[0], step):
# 提取窗口区域
window = img_array[y:y+window_size[1], x:x+window_size[0]]
window = Image.fromarray(window).resize(self.img_size)
window_array = np.array(window) / 255.0
window_array = np.expand_dims(window_array, axis=0)
# 预测窗口是否包含缺陷
pred = self.model.predict(window_array)[0][0]
if pred > 0.7: # 更高的置信度阈值
defect_regions.append({
'x1': x, 'y1': y,
'x2': x + window_size[0],
'y2': y + window_size[1],
'confidence': float(pred)
})
return defect_regions
# 示例使用
if __name__ == "__main__":
# 训练模型(实际使用时只需执行一次)
# model = train_ui_defect_model('ui_dataset')
# 加载检测器并进行预测
detector = UIDefectDetector()
result = detector.detect_defect('test_ui.png')
print(result)
2.3 智能缺陷分类与修复建议生成
python
运行
import spacy
from transformers import pipeline, AutoTokenizer, AutoModelForSeq2SeqLM
import json
class DefectAnalyzer:
def __init__(self):
# 加载NLP模型
self.nlp = spacy.load("en_core_web_lg")
self.classifier = pipeline("text-classification", model="distilbert-base-uncased-finetuned-sst-2-english")
# 加载缺陷修复建议生成模型
self.tokenizer = AutoTokenizer.from_pretrained("t5-small")
self.repair_model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
# 缺陷类型与修复策略映射
self.defect_strategies = self._load_defect_strategies()
def _load_defect_strategies(self):
"""加载缺陷类型与修复策略的映射关系"""
return {
"NullPointerException": {
"severity": "high",
"common_causes": ["未初始化对象", "对象被意外置空", "错误的类型转换"],
"fix_templates": [
"在使用{variable}前添加非空检查: if ({variable} != null) {{ ... }}",
"确保{variable}在声明时被正确初始化"
]
},
"IndexOutOfBoundsException": {
"severity": "medium",
"common_causes": ["数组访问越界", "错误的循环条件", "集合大小计算错误"],
"fix_templates": [
"添加索引范围检查: if (index >= 0 && index < {array}.length) {{ ... }}",
"修正循环条件为: for (int i = 0; i < {array}.length; i++)"
]
},
# 更多缺陷类型...
}
def analyze_stack_trace(self, stack_trace):
"""分析堆栈跟踪信息,识别缺陷类型和位置"""
doc = self.nlp(stack_trace)
# 提取缺陷类型(通常是第一个大写开头的异常类名)
defect_type = None
for ent in doc.ents:
if ent.text.endswith("Exception") or ent.text.endswith("Error"):
defect_type = ent.text
break
# 提取受影响的文件和行号
file_path = None
line_number = None
for token in doc:
if ".java" in token.text or ".py" in token.text or ".js" in token.text:
file_path = token.text
# 查找行号(通常在文件名后面)
next_token = doc[token.i + 1] if token.i + 1 < len(doc) else None
if next_token and next_token.text.isdigit():
line_number = int(next_token.text)
return {
"defect_type": defect_type,
"file_path": file_path,
"line_number": line_number,
"full_stack": stack_trace
}
def classify_defect_severity(self, defect_info, code_context):
"""分类缺陷的严重程度"""
# 结合缺陷类型和代码上下文判断严重程度
if defect_info["defect_type"] in self.defect_strategies:
base_severity = self.defect_strategies[defect_info["defect_type"]]["severity"]
else:
base_severity = "medium"
# 分析代码上下文,调整严重程度
context_analysis = self.classifier(code_context[:512])
sentiment = context_analysis[0]["label"]
# 如果涉及核心功能代码,提高严重程度
if "core" in code_context or "main" in code_context:
if base_severity == "medium":
base_severity = "high"
elif base_severity == "low":
base_severity = "medium"
return base_severity
def generate_fix_suggestions(self, defect_info, code_snippet):
"""生成缺陷修复建议"""
defect_type = defect_info["defect_type"]
# 如果是已知缺陷类型,使用模板生成建议
if defect_type in self.defect_strategies:
strategies = self.defect_strategies[defect_type]
suggestions = []
# 提取代码中的变量名
doc = self.nlp(code_snippet)
variables = [ent.text for ent in doc.ents if ent.label_ == "VAR"]
# 生成具体修复建议
for template in strategies["fix_templates"]:
for var in variables:
suggestion = template.format(variable=var)
suggestions.append(suggestion)
return list(set(suggestions)) # 去重
else:
# 使用T5模型生成修复建议
input_text = f"Fix the following {defect_type} in code: {code_snippet}"
inputs = self.tokenizer.encode(input_text, return_tensors="pt", max_length=512, truncation=True)
outputs = self.repair_model.generate(inputs, max_length=512, num_return_sequences=3)
suggestions = []
for output in outputs:
suggestion = self.tokenizer.decode(output, skip_special_tokens=True)
suggestions.append(suggestion)
return suggestions
def analyze_defect(self, stack_trace, code_snippet):
"""完整的缺陷分析流程"""
# 1. 解析堆栈跟踪
defect_info = self.analyze_stack_trace(stack_trace)
# 2. 分类缺陷严重程度
severity = self.classify_defect_severity(defect_info, code_snippet)
defect_info["severity"] = severity
# 3. 生成修复建议
suggestions = self.generate_fix_suggestions(defect_info, code_snippet)
defect_info["fix_suggestions"] = suggestions
# 4. 生成缺陷摘要
defect_info["summary"] = self._generate_summary(defect_info, code_snippet)
return defect_info
def _generate_summary(self, defect_info, code_snippet):
"""生成缺陷摘要"""
summary = f"发现{defect_info['defect_type']},位于{defect_info['file_path']}第{defect_info['line_number']}行,"
summary += f"严重程度为{defect_info['severity']}。"
# 添加简短原因分析
if defect_info["defect_type"] in self.defect_strategies:
summary += f"常见原因包括:{', '.join(self.defect_strategies[defect_info['defect_type']]['common_causes'][:2])}。"
return summary
# 示例使用
if __name__ == "__main__":
analyzer = DefectAnalyzer()
# 示例堆栈跟踪
stack_trace = """
Exception in thread "main" java.lang.NullPointerException
at com.example.UserService.getUserName(UserService.java:45)
at com.example.MainController.displayUser(MainController.java:23)
at com.example.Application.main(Application.java:10)
"""
# 示例代码片段
code_snippet = """
public String getUserName(User user) {
return user.getName();
}
"""
# 分析缺陷
result = analyzer.analyze_defect(stack_trace, code_snippet)
print(json.dumps(result, indent=2))
2.4 智能缺陷检测 Prompt 工程示例
Prompt 1: 代码缺陷分析
plaintext
作为一名高级软件测试工程师,请分析以下Python代码中的潜在缺陷:
def calculate_average(numbers):
total = 0
for num in numbers:
total += num
return total / len(numbers)
请提供:
1. 至少3种可能导致错误的输入场景
2. 每种场景的具体错误类型
3. 修复这些缺陷的代码建议
4. 针对这段代码的测试用例设计
Prompt 2: 日志异常检测
plaintext
作为一名AI驱动的日志分析专家,请分析以下应用日志,识别异常模式并判断可能的系统问题:
[2023-10-05 14:32:15] INFO: User login successful - user_id=12345
[2023-10-05 14:32:22] INFO: Database query executed - time=0.23s
[2023-10-05 14:32:30] WARNING: Memory usage above 80%
[2023-10-05 14:32:45] ERROR: Connection timeout to payment gateway
[2023-10-05 14:32:50] ERROR: Connection timeout to payment gateway
[2023-10-05 14:33:01] WARNING: Memory usage above 90%
[2023-10-05 14:33:10] ERROR: Database connection failed
[2023-10-05 14:33:15] CRITICAL: System unresponsive
请提供:
1. 异常事件的时间线和关联分析
2. 可能的根本原因(按可能性排序)
3. 建议的即时排查步骤
4. 预防类似问题的长期措施
三、A/B 测试的 AI 优化方法
3.1 智能 A/B 测试框架设计
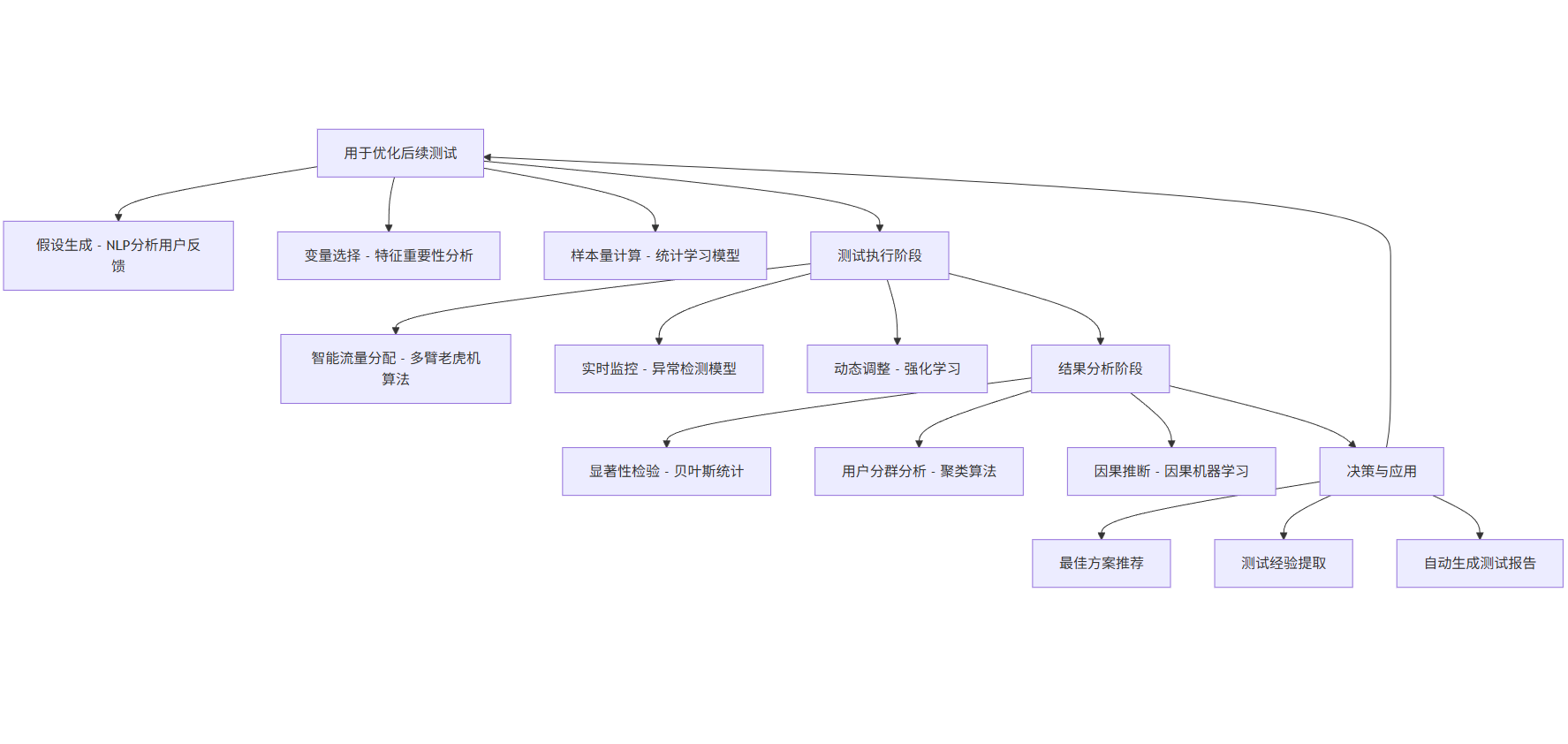
AI 驱动的 A/B 测试框架通过预测用户行为、动态调整流量分配和智能分析结果,显著提升测试效率和准确性。
graph TD
A[测试准备阶段] --> A1[假设生成 - NLP分析用户反馈]
A --> A2[变量选择 - 特征重要性分析]
A --> A3[样本量计算 - 统计学习模型]
B[测试执行阶段] --> B1[智能流量分配 - 多臂老虎机算法]
B --> B2[实时监控 - 异常检测模型]
B --> B3[动态调整 - 强化学习]
C[结果分析阶段] --> C1[显著性检验 - 贝叶斯统计]
C --> C2[用户分群分析 - 聚类算法]
C --> C3[因果推断 - 因果机器学习]
D[决策与应用] --> D1[最佳方案推荐]
D --> D2[测试经验提取]
D --> D3[自动生成测试报告]
A --> B
B --> C
C --> D
D --> A[用于优化后续测试]
3.2 基于多臂老虎机算法的智能流量分配
传统 A/B 测试采用固定流量分配(如 50/50),而 AI 优化的方案通过多臂老虎机算法动态调整流量,在减少损失的同时加速找到最优方案。
python
运行
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import beta
class AIBasedABTester:
def __init__(self, variants, exploration_rate=0.2, strategy='thompson'):
"""
初始化AI驱动的A/B测试器
:param variants: 测试变体列表
:param exploration_rate: 探索率(仅用于epsilon-greedy策略)
:param strategy: 流量分配策略:thompson(汤普森采样)或epsilon_greedy
"""
self.variants = variants
self.strategy = strategy
self.exploration_rate = exploration_rate
# 初始化每个变体的成功和尝试次数
self.stats = {v: {'successes': 0, 'attempts': 0} for v in variants}
# 记录每个步骤的选择和结果
self.history = []
def select_variant(self):
"""基于所选策略选择变体"""
if self.strategy == 'thompson':
return self._thompson_sampling()
elif self.strategy == 'epsilon_greedy':
return self._epsilon_greedy()
else:
raise ValueError("不支持的策略,选择'thompson'或'epsilon_greedy'")
def _thompson_sampling(self):
"""汤普森采样算法:基于Beta分布选择变体"""
samples = {}
for variant in self.variants:
# 为每个变体生成Beta分布样本
# 使用Beta(alpha, beta),其中alpha = successes + 1, beta = (attempts - successes) + 1
alpha = self.stats[variant]['successes'] + 1
beta_param = (self.stats[variant]['attempts'] - self.stats[variant]['successes']) + 1
samples[variant] = beta.rvs(alpha, beta_param)
# 选择具有最高样本值的变体
return max(samples, key=samples.get)
def _epsilon_greedy(self):
"""Epsilon-Greedy算法:大概率选择当前最优,小概率随机探索"""
# 随机探索
if np.random.random() < self.exploration_rate:
return np.random.choice(self.variants)
# 选择当前最优变体(成功率最高)
best_variant = None
best_success_rate = -1
for variant in self.variants:
if self.stats[variant]['attempts'] == 0:
# 尚未尝试的变体,优先选择
return variant
success_rate = self.stats[variant]['successes'] / self.stats[variant]['attempts']
if success_rate > best_success_rate:
best_success_rate = success_rate
best_variant = variant
return best_variant
def record_result(self, variant, success):
"""记录测试结果"""
self.stats[variant]['attempts'] += 1
if success:
self.stats[variant]['successes'] += 1
# 记录历史
self.history.append({
'variant': variant,
'success': success,
'stats': {v: dict(s) for v, s in self.stats.items()}
})
def run_test(self, num_trials):
"""运行A/B测试"""
for _ in range(num_trials):
# 选择变体
variant = self.select_variant()
# 模拟用户交互结果(实际应用中应替换为真实数据)
# 这里假设每个变体有不同的真实成功率
true_rates = {'A': 0.15, 'B': 0.20, 'C': 0.18} # 实际应用中未知
success = np.random.random() < true_rates[variant]
# 记录结果
self.record_result(variant, success)
def get_results(self):
"""获取测试结果"""
results = {}
for variant in self.variants:
attempts = self.stats[variant]['attempts']
if attempts == 0:
rate = 0
else:
rate = self.stats[variant]['successes'] / attempts
results[variant] = {
'success_rate': rate,
'successes': self.stats[variant]['successes'],
'attempts': attempts
}
return results
def plot_results(self):
"""可视化测试结果"""
# 绘制每个变体的选择次数
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
attempts = [self.stats[v]['attempts'] for v in self.variants]
plt.bar(self.variants, attempts)
plt.title('每个变体的尝试次数')
plt.ylabel('次数')
# 绘制成功率曲线
plt.subplot(1, 2, 2)
for variant in self.variants:
rates = []
attempts = 0
successes = 0
for entry in self.history:
if entry['variant'] == variant:
attempts += 1
if entry['success']:
successes += 1
rates.append(successes / attempts if attempts > 0 else 0)
plt.plot(rates, label=f'变体 {variant}')
plt.title('各变体成功率随时间变化')
plt.xlabel('尝试次数')
plt.ylabel('成功率')
plt.legend()
plt.tight_layout()
plt.show()
# 绘制Beta分布
if self.strategy == 'thompson':
plt.figure(figsize=(10, 6))
x = np.linspace(0, 1, 100)
for variant in self.variants:
alpha = self.stats[variant]['successes'] + 1
beta_param = (self.stats[variant]['attempts'] - self.stats[variant]['successes']) + 1
y = beta.pdf(x, alpha, beta_param)
plt.plot(x, y, label=f'变体 {variant} (α={alpha}, β={beta_param})')
plt.title('各变体的Beta分布')
plt.xlabel('成功率')
plt.ylabel('概率密度')
plt.legend()
plt.show()
# 示例使用
if __name__ == "__main__":
# 创建A/B测试器,测试3个变体
ab_tester = AIBasedABTester(['A', 'B', 'C'], strategy='thompson')
# 运行1000次测试
ab_tester.run_test(1000)
# 获取并打印结果
results = ab_tester.get_results()
print("测试结果:")
for variant, data in results.items():
print(f"变体 {variant}: 成功率 = {data['success_rate']:.4f}, "
f"成功次数 = {data['successes']}, 总尝试 = {data['attempts']}")
# 可视化结果
ab_tester.plot_results()
3.3 基于贝叶斯统计的 A/B 测试分析
传统 A/B 测试依赖于频率学派的假设检验,而贝叶斯方法能提供更直观的结果解释和更早的决策点。
python
运行
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import beta
import pandas as pd
from bayes_testing import TwoSampleBayesianTTest
class BayesianABAnalyzer:
def __init__(self):
"""初始化贝叶斯A/B测试分析器"""
self.tests = {}
def analyze_two_samples(self, variant_a, variant_b, alpha_prior=1, beta_prior=1):
"""
分析两个变体的A/B测试结果
:param variant_a: 变体A的数据 {'successes': int, 'trials': int}
:param variant_b: 变体B的数据 {'successes': int, 'trials': int}
:param alpha_prior: 先验Beta分布的alpha参数
:param beta_prior: 先验Beta分布的beta参数
"""
# 计算后验分布参数
a_successes, a_trials = variant_a['successes'], variant_a['trials']
b_successes, b_trials = variant_b['successes'], variant_b['trials']
a_alpha = a_successes + alpha_prior
a_beta = (a_trials - a_successes) + beta_prior
b_alpha = b_successes + alpha_prior
b_beta = (b_trials - b_successes) + beta_prior
# 生成后验分布样本
samples = 10000
a_samples = beta.rvs(a_alpha, a_beta, size=samples)
b_samples = beta.rvs(b_alpha, b_beta, size=samples)
# 计算B优于A的概率
b_better_prob = np.mean(b_samples > a_samples)
a_better_prob = np.mean(a_samples > b_samples)
difference = b_samples - a_samples
avg_lift = np.mean(difference)
lift_interval = np.percentile(difference, [2.5, 97.5]) # 95%置信区间
# 可视化后验分布
self._plot_posteriors(a_samples, b_samples, 'A', 'B')
return {
'variant_a': {
'success_rate': a_successes / a_trials if a_trials > 0 else 0,
'alpha': a_alpha,
'beta': a_beta
},
'variant_b': {
'success_rate': b_successes / b_trials if b_trials > 0 else 0,
'alpha': b_alpha,
'beta': b_beta
},
'probabilities': {
'b_better_than_a': b_better_prob,
'a_better_than_b': a_better_prob,
'equivalent': 1 - b_better_prob - a_better_prob
},
'lift': {
'average': avg_lift,
'95%_interval': lift_interval,
'positive_lift_prob': np.mean(difference > 0)
}
}
def _plot_posteriors(self, a_samples, b_samples, a_name, b_name):
"""绘制两个变体的后验分布"""
plt.figure(figsize=(12, 6))
# 绘制后验分布直方图
plt.hist(a_samples, bins=50, alpha=0.5, label=a_name, density=True)
plt.hist(b_samples, bins=50, alpha=0.5, label=b_name, density=True)
# 添加均值线
plt.axvline(np.mean(a_samples), color='blue', linestyle='dashed', linewidth=1)
plt.axvline(np.mean(b_samples), color='orange', linestyle='dashed', linewidth=1)
plt.title(f'{a_name} 和 {b_name} 的成功率后验分布')
plt.xlabel('成功率')
plt.ylabel('密度')
plt.legend()
plt.show()
def sequential_testing(self, results, min_samples=100, stopping_threshold=0.95):
"""
序贯测试:允许在达到预设样本量前停止测试
:param results: 测试结果字典,包含每个变体的成功和尝试次数
:param min_samples: 最小样本量,低于此值不考虑停止
:param stopping_threshold: 停止阈值,当某变体优于其他变体的概率超过此时停止
"""
variants = list(results.keys())
total_samples = sum(results[v]['trials'] for v in variants)
# 检查是否达到最小样本量
if total_samples < min_samples:
return {
'stop': False,
'reason': f'样本量不足(当前: {total_samples}, 最小: {min_samples})',
'leader': None,
'confidence': 0
}
# 比较所有变体对
leader = None
max_confidence = 0
for i in range(len(variants)):
current = variants[i]
# 计算当前变体优于所有其他变体的概率
better_than_all = 1.0
for j in range(len(variants)):
if i == j:
continue
other = variants[j]
# 计算当前变体优于其他变体的概率
test = TwoSampleBayesianTTest(
successes_a=results[current]['successes'],
trials_a=results[current]['trials'],
successes_b=results[other]['successes'],
trials_b=results[other]['trials']
)
prob = test.prob_a_better_than_b()
better_than_all *= prob
if better_than_all > max_confidence:
max_confidence = better_than_all
leader = current
# 判断是否应该停止测试
if max_confidence >= stopping_threshold:
return {
'stop': True,
'reason': f'{leader} 优于所有其他变体的概率达到 {max_confidence:.4f} ≥ {stopping_threshold}',
'leader': leader,
'confidence': max_confidence
}
else:
return {
'stop': False,
'reason': f'没有变体达到足够高的置信度(最高: {max_confidence:.4f} < {stopping_threshold})',
'leader': leader,
'confidence': max_confidence
}
def power_analysis(self, baseline_rate, min_effect, significance=0.05, power=0.8):
"""
计算所需样本量
:param baseline_rate: 基准转化率
:param min_effect: 最小可检测效果(相对提升)
:param significance: 显著性水平
:param power: 检验功效
"""
# 计算实验组的预期转化率
treatment_rate = baseline_rate * (1 + min_effect)
# 使用正态近似计算样本量
# 基于公式: n = (Zα/2*sqrt(2*p*q) + Zβ*sqrt(p1*q1 + p2*q2))^2 / (p1-p2)^2
from scipy.stats import norm
# 计算Z值
z_alpha = norm.ppf(1 - significance/2)
z_beta = norm.ppf(power)
p1 = baseline_rate
p2 = treatment_rate
q1 = 1 - p1
q2 = 1 - p2
p_avg = (p1 + p2) / 2
q_avg = 1 - p_avg
# 计算每组所需样本量
n = (z_alpha * np.sqrt(2 * p_avg * q_avg) +
z_beta * np.sqrt(p1 * q1 + p2 * q2)) **2 / (p2 - p1)** 2
return {
'baseline_rate': baseline_rate,
'treatment_rate': treatment_rate,
'min_effect': min_effect,
'per_group_sample_size': int(np.ceil(n)),
'total_sample_size': int(np.ceil(n * 2)),
'significance': significance,
'power': power
}
# 示例使用
if __name__ == "__main__":
analyzer = BayesianABAnalyzer()
# 示例数据:两个变体的A/B测试结果
variant_a = {'successes': 120, 'trials': 1000} # 12% 转化率
variant_b = {'successes': 150, 'trials': 1000} # 15% 转化率
# 分析结果
result = analyzer.analyze_two_samples(variant_a, variant_b)
print("贝叶斯A/B测试分析结果:")
print(f"B优于A的概率: {result['probabilities']['b_better_than_a']:.2%}")
print(f"平均提升: {result['lift']['average']:.2%}")
print(f"95%置信区间: [{result['lift']['95%_interval'][0]:.2%}, {result['lift']['95%_interval'][1]:.2%}]")
# 序贯测试示例
sequential_result = analyzer.sequential_testing({
'A': variant_a,
'B': variant_b
})
print("\n序贯测试结果:")
print(f"是否停止测试: {'是' if sequential_result['stop'] else '否'}")
print(f"原因: {sequential_result['reason']}")
# 样本量计算示例
power_result = analyzer.power_analysis(
baseline_rate=0.12, # 基准12%
min_effect=0.2, # 最小检测20%的提升
significance=0.05, # 5%显著性水平
power=0.8 # 80%检验功效
)
print("\n样本量计算结果:")
print(f"每组所需样本量: {power_result['per_group_sample_size']}")
print(f"总样本量: {power_result['total_sample_size']}")
3.4 A/B 测试优化 Prompt 示例
Prompt 1: 测试假设生成
plaintext
作为一名产品优化专家,我需要为电商网站的产品详情页设计A/B测试假设。
网站背景:
- 中等规模电商平台,主营电子产品
- 当前产品详情页转化率约为3%
- 用户反馈主要集中在"价格不明确"和"配送信息难找"
请基于以上信息,生成:
1. 5个具体可测试的假设(遵循"If...then...because..."格式)
2. 每个假设对应的测试变体设计
3. 每个测试的关键成功指标(KSIs)
4. 测试的优先级排序及理由
Prompt 2: 异常结果分析
plaintext
作为一名数据科学家,请分析以下A/B测试结果中的异常模式并提供解释:
测试背景:
- 测试目标:优化注册表单转化率
- 变体A:原始表单(5个字段)
- 变体B:简化表单(3个字段)
- 测试时长:2周,总样本量10,000
结果数据:
- 变体A:转化率12.5%,跳出率45%
- 变体B:转化率14.2%,跳出率38%
- 但在移动端,变体B转化率(8.3%)低于变体A(9.1%)
请提供:
1. 可能导致移动端结果异常的3个原因
2. 验证这些假设的后续测试建议
3. 基于当前结果的决策建议
4. 从这个测试中可提取的产品洞察
四、AI 测试技术综合应用案例
4.1 电商平台全链路 AI 测试方案
某大型电商平台构建了端到端 AI 测试体系,实现了从功能测试到用户体验优化的全流程智能化,其架构如下:
graph TD
A[用户行为数据采集] --> B[智能测试用例生成]
B --> C[自动化执行引擎]
C --> D[AI缺陷检测系统]
D --> E[缺陷修复建议模块]
E --> F[A/B测试验证系统]
F --> G[产品优化决策支持]
G --> H[测试知识图谱更新]
subgraph 实时监控
I[性能异常检测] --> C
J[用户体验指标监控] --> F
end
subgraph 持续优化
H --> B
F --> H
end
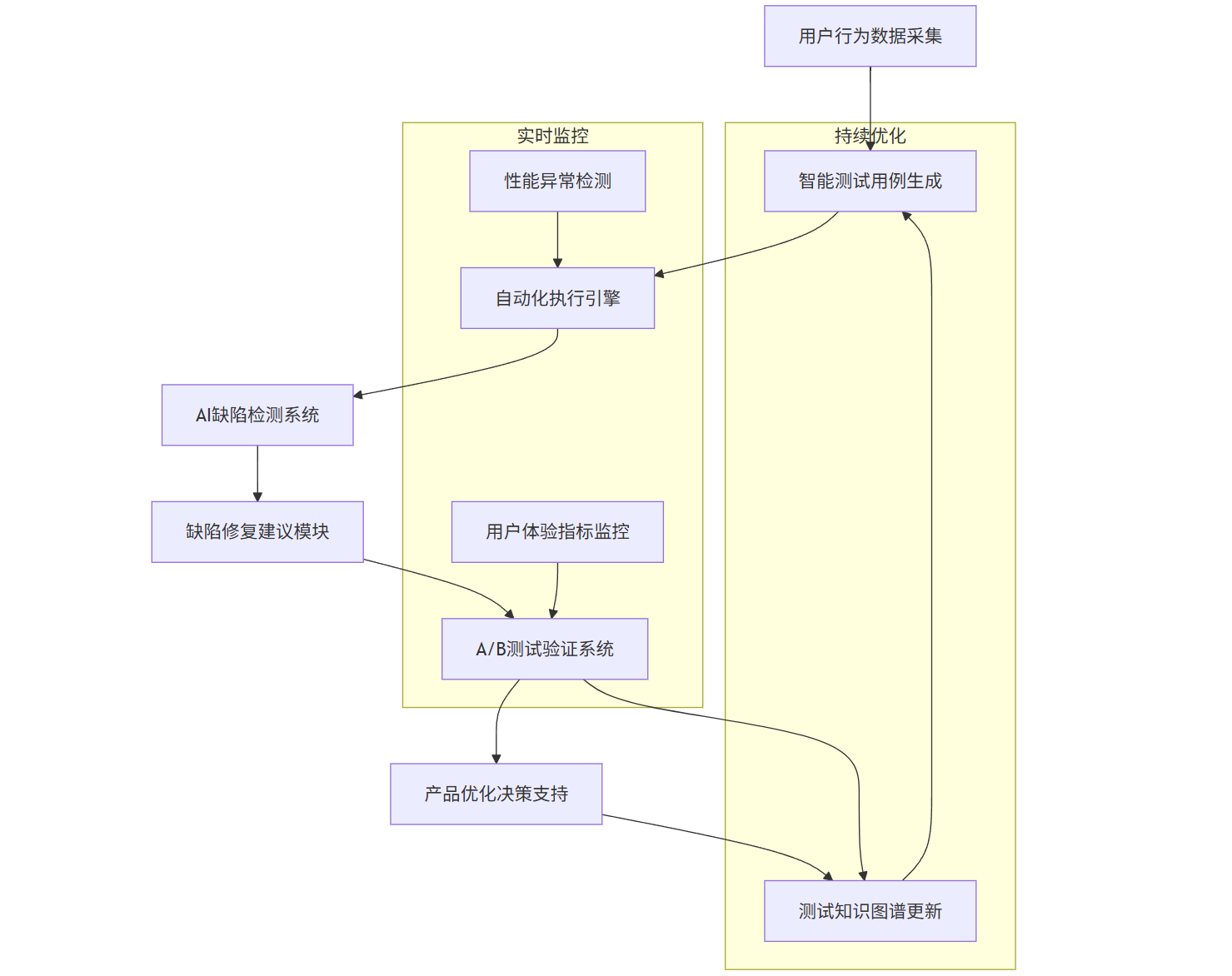
该方案的核心成效包括:
- 测试用例生成效率提升 65%
- 缺陷检测覆盖率从 72% 提升至 94%
- 线上问题平均修复时间从 4.2 小时缩短至 1.8 小时
- 关键业务指标(如转化率)通过 A/B 测试优化提升 8-15%
4.2 AI 测试成熟度评估模型
| 成熟度级别 | 自动化测试 | 智能缺陷检测 | A/B 测试能力 | 典型特征 |
|---|---|---|---|---|
| Level 1 | 脚本化自动化,覆盖核心功能 | 人工主导,基于规则的静态分析 | 手动设计,固定流量分配 | 效率低,覆盖率有限,依赖专家经验 |
| Level 2 | 模块化框架,支持数据驱动 | 引入 ML 模型辅助缺陷分类 | 半自动化设计,基础统计分析 | 部分流程自动化,开始应用 AI 辅助 |
| Level 3 | 自适应执行,用例自动修复 | 端到端智能检测与定位 | 多变量测试,动态流量分配 | AI 深度集成,显著提升效率 |
| Level 4 | 自我学习框架,预测性测试 | 缺陷根因分析与自动修复 | 全流程自动化,因果推断 | 高度智能化,自主决策能力 |
| Level 5 | 自主进化系统 | 缺陷预防与系统自愈 | 实时个性化测试,全局优化 | 完全自治,持续自我优化 |
五、AI 测试技术发展趋势
-
多模态测试融合:结合文本、图像、语音等多种数据类型的统一测试框架将成为主流,能够更全面地模拟真实用户场景。
-
因果推断增强:超越相关性分析,AI 测试将能更准确地识别产品变更与用户行为变化之间的因果关系,提升决策质量。
-
数字孪生测试环境:构建与生产环境高度一致的虚拟测试环境,通过 AI 模拟各种极端条件和边缘情况,大幅提升测试覆盖率。
-
自主测试代理:具备自我学习能力的智能代理将能够独立设计、执行和分析测试,实现真正意义上的 "零干预" 测试流程。
-
隐私保护与测试平衡:在严格的数据隐私法规下,联邦学习等技术将被广泛应用于 AI 测试,实现数据安全与测试效果的平衡。
AI 测试正从简单的工具辅助向自主智能系统演进,未来将成为产品开发流程中不可或缺的核心能力,帮助企业在快速迭代的市场环境中保持竞争力。

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)