AI产品经理学习之算法评估指标
分类任务指标包括准确率(评估总体正确率)、精确率(减少误报)、召回率(减少漏报)、F1分数(平衡精确率和召回率)、混淆矩阵(全面展示预测结果)以及ROC曲线与AUC(评估分类效果)。回归任务指标包含MSE(对异常值敏感)、RMSE(数值直观)、MAE(抗异常值)和R²(解释变异能力)。聚类任务指标有轮廓系数(评估聚类结构)和调整兰德指数(与真实标签一致性比较)
算法评估指标用于量化模型的性能,常见的分类及对应指标,按任务类型整理。
一、分类任务常见指标
准确率、精确率、召回率、F1分数、混淆矩阵、ROC 曲线与 AUC
1、准确率(Accuracy)
定义:正确预测的样本占总样本的比例
公式:Accuracy = (TP + TN) / (TP + TN + FP + FN)
真正例(TP):真实为正,预测为正
假正例(FP):真实为负,预测为正(误报)
真负例(TN):真实为负,预测为负
假负例(FN):真实为正,预测为负(漏报)
100 个样本中,80 个预测正确,则准确率为 80%
适用:适用于类别平衡的数据集
局限:不适用于不平衡数据(如 99% 样本为负,模型全预测为负也能达到 99% 准确率)
2、精确率(Precision)—预测为正的可靠性
定义:是预测为正的样本中实际为正的比例,衡量模型在预测为正例的样本中的准确性。
公式:Precision = TP / (TP + FP)
如:90封垃圾邮件被正确识别,10封正常邮件被误判为垃圾邮件
精确率 = TP / (TP + FP) = 90 / (90 + 10) = 90%
应用场景:减少误报的场景,提高精确率可以有效降低误报数量
如欺诈检测中误判:将正常交易误判为欺诈,可能导致严重的后果
3、召回率(Recall/Sensitivity)也叫查全率
定义:实际为正的样本中,被正确预测为正的比例
公式:Recall = TP / (TP + FN)
如:10 个实际癌症患者中,模型检测出 7 个,则召回率为 70%
应用场景:需减少漏报的场景,关注 “不漏掉正例”,即尽可能多地找出所有真正的正类样本(如癌症诊断避免漏诊)。
4、F1 分数(F1-Score)
定义:精确率和召回率的调和平均数,平衡两者的矛盾
公式:F1 = 2 * (Precision * Recall) / (Precision + Recall)
示例:精确率 80%,召回率 70%,则 F1 = 2*(0.8*0.7)/(0.8+0.7) ≈ 74.7%。
适用场景:希望精确率和召回率都较高的场景(如推荐系统)
电商推荐系统中,精确率和召回率都需要较高,保证推荐的商品既能满足用户的兴趣,又能覆盖到尽可能多的相关商品。
5、混淆矩阵(Confusion Matrix)
• 定义:以矩阵形式展示模型预测结果与真实标签的分布。
通过展示模型在每个类别上的预测结果,包括正确预测(真阳性、真阴性)和错误预测(假阳性、假阴性),帮助全面了解模型的表现。
6、ROC 曲线与 AUC
ROC 曲线:横轴表示假阳性率(FPR),即所有实际为负的样本中被错误预测为正的比例;
纵轴表示真阳性率(TPR),即所有实际为正的样本中被正确预测为正的比例。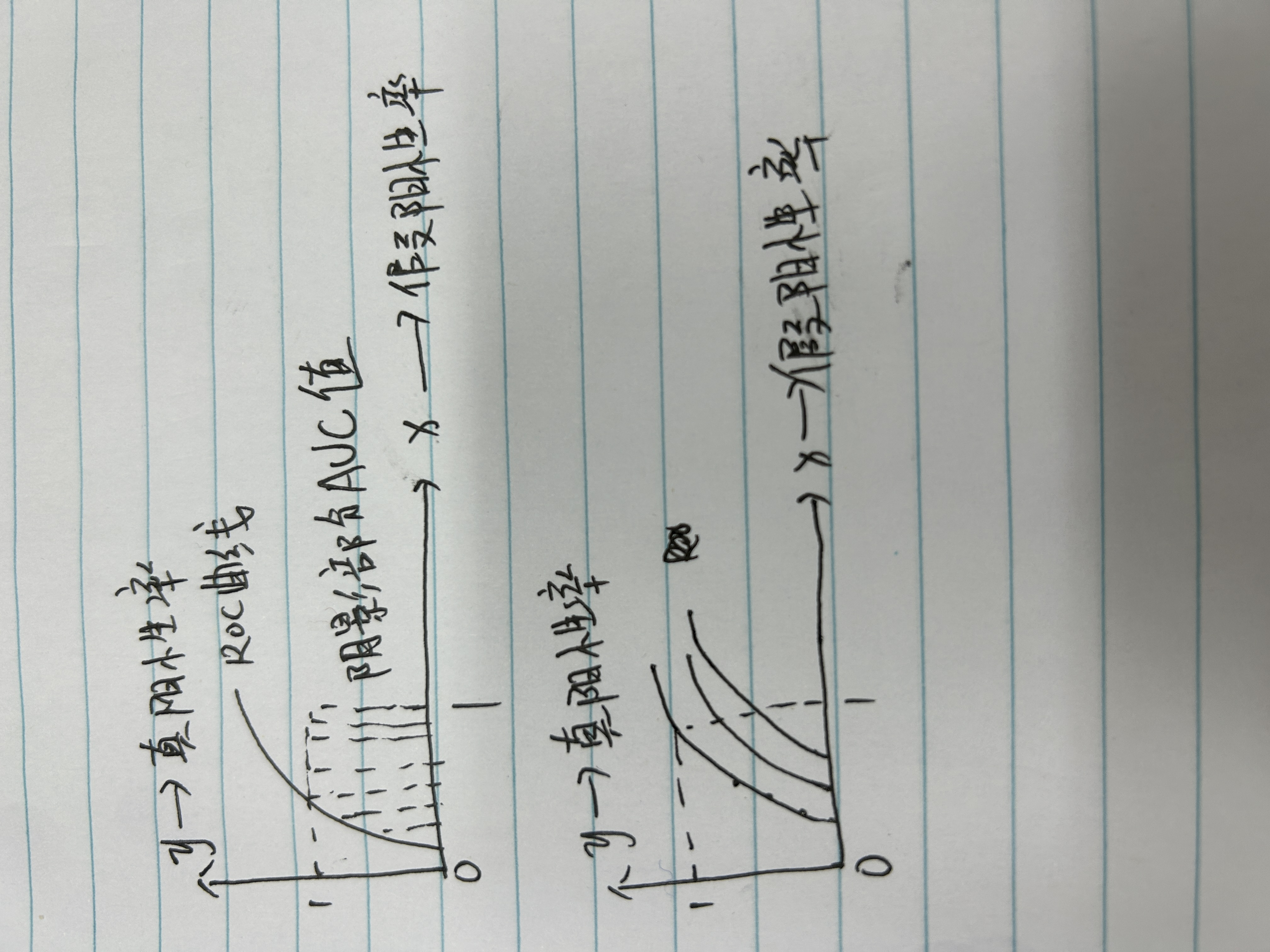
• AUC为ROC 曲线下的面积,取值范围 [0,1],值越大模型性能越好,AUC值为1表示完美分类,AUC值为0.5表示随机猜测,理想的ROC曲线应该尽可能靠近左上角,表明模型具有高召回率和低误报率
分类任务指标选择:
怎么提高精确率
减少误报
优化模型的决策边界;
提升数据质量和特征工程;
选择合适的模型和评估指标
怎么提高召回率:
减少漏报
提高模型对正类样本的识别能力;
调整分类阈值和损失函数;
优化数据质量和特征工程;
选择合适的模型和评估指标
特征工程指的是从原始数据中提取、构造和选择对模型预测目标最有用的特征(变量或属性)的过程;包括:特征提取、特征构造、特征选择、特征转换、特征缩放;
二、回归任务评估指标
1、均方误差(MSE)
定义:预测值与真实值差值的平方的平均值。
特点:对异常值非常敏感,进而影响模型的鲁棒性
2、均方根误差(RMSE)
定义:MSE 的平方根,衍生指标
特点:单位与原始数据单位一致,在数值上更直观,可以直接反映预测值与真实值之间的平均偏差大小,更容易解释模型的误差水平
3、平均绝对误差(MAE)
特点:对异常值不敏感,具有一定鲁棒性,单位与原始数据一致。
缺点:优化时可能收敛较慢,逐步接近最优解的速度较慢
4、R² 决定系数(R-squared)
定义:衡量模型解释数据变异的能力,取值范围 (-∞,1]
特点:R²=0.8 表示模型能解释 80% 的数据变异,接近 1 说明拟合效果好
回归任务指标选择: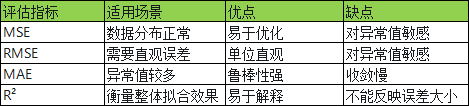
三、聚类任务评估指标
1、轮廓系数(Silhouette Score)
定义:结合簇内距离和簇间距离,取值范围 [-1,1],值越大聚类效果越好。
• 示例:轮廓系数 = 0.7 表示聚类结构合理;接近 - 1 表示样本可能分到错误的簇。
优点:直观,适用于任意聚类算法。
缺点:计算复杂度较高,不适合大数据集。
2. 调整兰德指数(ARI)
• 定义:当有真实标签时,用于衡量聚类结果与真实标签的一致性
值范围为 [-1, 1],值越接近 1 表示聚类结果与真实标签越一致。
优点:考虑了随机聚类的影响,对噪声和异常值具有一定的鲁棒性;
适用于监督和无监督学习的对比;
缺点:需要真实标签,不适用于完全无监督的场景。
聚类任务指标选择建议:无监督时用轮廓系数,有标签时用ARI
四、生成任务评估指标
1、BLEU 分数(文本)
一种用于评估机器生成的文本与参考文本之间相似度的指标,常用于机器翻译和文本生成任务。分数范围在0到1之间,数值越高表示生成文本与参考文本越接近,质量越高
优势:
与人类判断密切相关
计算速度快,计算成本低
容易理解,与具体语言无关
局限:
无法捕捉翻译结果的语法、流畅度、连贯性等方面的问题
只能评估 n-gram 的匹配情况,不考虑可理解性和语法正确性
2、Inception Score(图像)
用于评估生成图像质量的指标,尤其常见于生成对抗网络(GANs)的评估中。该分数基于图像的清晰度和多样性,数值越高表示生成的图像质量更高且更具多样性

分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)