
ZeRO3 技术原理
摘要: DeepSpeed ZeRO3通过全面切分模型参数、梯度与优化器状态,显著降低单卡显存占用。每张GPU仅保留本地数据分片,通过all_gather临时聚合参数进行前向计算,反向传播使用reduce_scatter同步梯度。以4卡为例,显存占用从17GB降至5GB。通信操作(如all_gather、reduce_scatter)伴随短暂全量数据缓存,结合Offload策略可进一步优化显存。该
DeepSpeed ZeRO3 训练过程细节
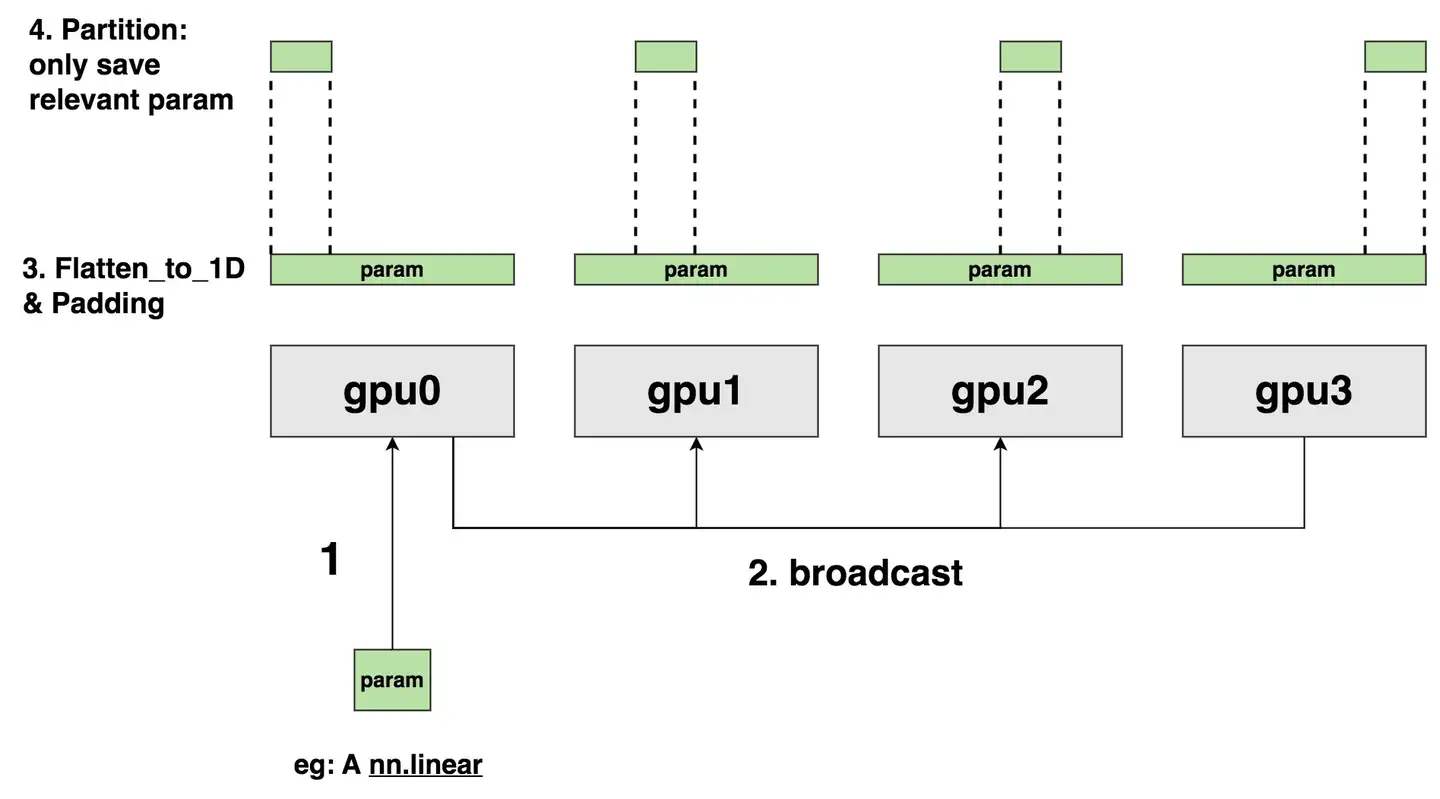
1. ZeRO3 概述
ZeRO(Zero Redundancy Optimizer)是 DeepSpeed 推出的分布式优化器。ZeRO Stage 3 实现了模型参数、优化器状态、梯度的全面切分(shard),每个进程(GPU)仅保存自己负责的一部分数据。这种方式极大地降低了显存占用,使得训练更大规模的模型成为可能。
2. 训练过程中的数据与参数流动
2.1 参数(Model Parameters)
- 切分方式:每张 GPU 只存储部分参数(即参数分片)。
- 前向传播:需要时,通过 all_gather 操作临时收集当前 layer 所需的全部参数,计算完成后立即释放,仅保留本地分片。
- 反向传播:只需本地参数分片进行梯度计算。
- 参数更新:每张 GPU 仅更新自己负责的参数分片。
2.2 梯度(Gradients)
- 切分方式:梯度同样被切分,每张 GPU 只保存本地参数的梯度分片。
- 反向传播:本地参数分片产生本地梯度。
- 梯度聚合:通过 reduce_scatter 操作,将全局梯度同步到各自负责的 GPU,避免每张卡都保存全部梯度。
2.3 优化器状态(Optimizer States)
- 切分方式:如 Adam 优化器的动量、二阶矩阵等状态,也被切分分配到各 GPU。
- 更新:每张 GPU 仅更新本地分片的优化器状态。
2.4 输入数据(Batches)
- 数据并行:每张 GPU 处理不同的数据 batch,与常规数据并行一致。
- 流水线处理:每个 batch 的前向、反向和参数更新均严格按照切分与同步逻辑执行。
3. 关键通信操作
- all_gather:在需要完整参数时,所有 GPU 之间收集参数分片,拼成完整参数进行前向/反向计算,计算完毕后释放。
- reduce_scatter:反向传播后,将各自的梯度分片同步到对应的 GPU,每张卡仅保留本地分片。
- broadcast:参数初始化或更新后,可能需要将参数广播到所有进程。
4. 显存占用对比与数据流动
假设有 4 张 GPU,模型参数 4GB(float32),梯度 4GB,Adam 优化器状态 8GB,激活值 1GB。
- 未分片时:每张 GPU 需占用显存
4 GB(参数)+4 GB(梯度)+8 GB(优化器状态)+1 GB(激活值)=17 GB 4\,\text{GB}(\text{参数}) + 4\,\text{GB}(\text{梯度}) + 8\,\text{GB}(\text{优化器状态}) + 1\,\text{GB}(\text{激活值}) = 17\,\text{GB} 4GB(参数)+4GB(梯度)+8GB(优化器状态)+1GB(激活值)=17GB - 使用 ZeRO3 后:参数、梯度、优化器状态均分为四份,每卡仅存储 1/4
1 GB(参数)+1 GB(梯度)+2 GB(优化器状态)+1 GB(激活值)=5 GB 1\,\text{GB}(\text{参数}) + 1\,\text{GB}(\text{梯度}) + 2\,\text{GB}(\text{优化器状态}) + 1\,\text{GB}(\text{激活值}) = 5\,\text{GB} 1GB(参数)+1GB(梯度)+2GB(优化器状态)+1GB(激活值)=5GB
5. ZeRO3 训练过程中的数据流动详解
-
参数分片
所有参数分片,每张卡仅保存自己负责的参数分片。 -
前向传播
对于每个 layer,仅在需要时通过 all_gather 临时获得该 layer 的全部参数,计算完成后立即释放,只保留本地分片。例如,Layer0 参数为 400MB,4 张卡 all_gather 后临时各自获得 400MB,计算完释放。 -
反向传播
仅计算本地参数分片的梯度。需要全局同步时,通过 reduce_scatter 将梯度分发到各自负责的 GPU,每卡保留 1GB。 -
优化器状态
Adam 优化器状态(8GB)被切分,每卡仅保存 2GB,并只更新本地分片。 -
参数更新
每张卡只负责本地参数分片的更新,更新后释放临时变量。 -
通信时的临时显存占用
在 all_gather 和 reduce_scatter 操作时,会临时出现全量参数或梯度的显存占用,但这些数据很快被释放,通常不会与激活值、常驻参数和梯度的显存峰值重叠。
6. Offload 策略
可以将前向传播中的中间结果(激活值)保存到内存或硬盘(如 NVMe),需要时再加载或重新计算,以进一步降低显存占用。
更多推荐


 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)