
人工智能三Deep:三大“Deep”力量如何共塑AI黄金时代
从长远来看,这将被证明是一个高明的选择,它不仅立刻提高了深度学习的研究关注度,而且未来以此为基础的AI研究更是促进了整个AI技术的突破和行业的广泛应用。DeepMind 的技术路径一直偏爱强化学习,就像一位痴迷于“闯关学习法”的学霸,它最爱的练功房是各种游戏世界—从围棋棋盘到电子游戏,在这里不断试错、总结,练就了一套强大的“强化学习”本领。在谷歌这一代号“谷歌猫”的项目中,计算机系统通过自主学习1
自21世纪起,以神经网络为基础的连接主义便彻底主导了人工智能的发展方向。 本文将以三个“Deep”开头的标志性公司和技术——DeepLearning(深度学习技术)、DeepMind(谷歌旗下AI公司)与DeepSeek(中国大模型企业)——为线索,追溯它们如何实现理论突破并走向产业繁荣,最终共同推动人工智能从实验室落地于千行百业。
一、DeepLearning:
为神经网络正名的“术语定义”

在“深度学习”这个词被提出之前,人工智能正经历着上世纪90年代以来的第二次“寒冬”。那时候,神经网络不被主流学术圈认可,连杨立昆(Yann LeCun)这样的大佬,都只能把“卷积神经网络”简称为“卷积网络”——因为直接提“神经网络”,论文大概率会被拒稿。
转折出现在2006年。杰弗里·辛顿(Geoffrey Hinton)发表了两篇关键论文:一篇是发表在《科学》杂志上的《通过神经网络进行数据降维处理》(Reducing the Dimensionality of Data with Neural Network),这篇论文重振了神经网络的理论价值;另一篇是《一种基于深度信念网络的快速学习算法》(A Fast Learning Algorithm for Deelp Belief Nets),论文里首次提出“深度”概念,为多层神经网络技术贴上了全新标签。
2007年,在温哥华NIPS年度大会上,时值60岁生日的辛顿发表演讲,“深度学习”这个词第一次出现在标题中。这是一次巧妙的品牌重塑,当他在台上调侃其他研究者都在做‘浅薄研究’时,听众的笑声印证了这个术语的感染力。从长远来看,这将被证明是一个高明的选择,它不仅立刻提高了深度学习的研究关注度,而且未来以此为基础的AI研究更是促进了整个AI技术的突破和行业的广泛应用。
“DeepLearning”这一命名不仅让一度沉寂的神经网络重获新生,更恰逢互联网大数据时代的兴起与GPU在计算领域的意外优势。三者结合,正式确立了“数据+算法+算力”这一AI发展的三大支柱,为后续大模型的技术爆发埋下了火种。
受其推动的里程碑事件
-
2009年:语音识别的“破冰时刻”
微软率先将深度学习应用于语音识别领域。实验结果显示,深度学习展现出的海量数据处理能力远超传统混合高斯模型,直接将错误率降低了20%——这一降幅相当于该领域过去十年的累积进步。 随后,苹果Siri、谷歌语音搜索等产品相继应用此技术,首次实现了人类与机器较为自然的对话交互。
-
2011年:谷歌大脑的“猫脸觉醒”
在谷歌这一代号“谷歌猫”的项目中,计算机系统通过自主学习1000万张未标注的YouTube图片,首次在没有人工干预的情况下识别出了“猫脸”这一概念。 这是全球首个利用无标注数据进行训练的成功案例,它证明了机器能像婴儿一样“自学”理解世界特征,也验证了深度学习在无监督学习范式上的巨大潜力。
-
2012年:AlexNet点燃“视觉革命”
由辛顿带领的三人小队(Hitton、Llya、Alex)凭借AlexNet进入ImageNet决赛, 该模型通过改进的卷积神经网络架构结合GPU加速计算,最终以领先第二名十几个百分点的巨大优势获胜。这一突破性成果,从此将计算机视觉的研究方向几乎完全转向了深度学习,同时也奠定了GPU作为AI算力基础设施的核心地位。 多年后,辛顿曾幽默地调侃道:“是Ilya提议了这个思路,Alex实现了突破,而我则获得了诺贝尔奖。”

二、DeepMind:
用“理想主义”为通用AI锚定方向

2010年,国际象棋神童、神经科学家戴密斯·哈萨比斯(Demis Hassabis)以“通用人工智能造福人类”为使命在伦敦创立DeepMind,公司名致敬《银河系漫游指南》中求解宇宙终极答案的超级计算机“DeepThought”。在资本追逐短期回报的AI赛道,DeepMind显得“格格不入”——它执着于通过游戏(如《打砖块》《太空入侵者》)验证强化学习,探索机器“试错-反思-进化”的通用智能路径。
2024年1月,谷歌宣布收购DeepMind。面对谷歌,DeepMind在保持独立研发体系的前提下,仍提出两个条件以维护其最初的理想:1)禁止将DeepMind技术用于军事目的;2)要求谷歌设立独立道德委员会,监督其通用人工智能技术的使用(无论何时实现)。我们经常谈及的理想主义在这里体现的淋漓尽致。
DeepMind 的技术路径一直偏爱强化学习,就像一位痴迷于“闯关学习法”的学霸,它最爱的练功房是各种游戏世界—从围棋棋盘到电子游戏,在这里不断试错、总结,练就了一套强大的“强化学习”本领。但它的目光始终锁定在终极目标:打造像人类一样能思考、能适应万千变化的“通用人工智能”。这条路,它走得既专注又充满野心。
受其推动的里程碑事件
-
2015年:促使马斯克的“反垄断宣言”
2015年,马斯克(Elon Musk)在考察DeepMind后深受震动——既惊叹其技术潜力,又警惕谷歌垄断AI的风险。仅3个月后便联合硅谷精英创立一家以通用人工智能为研究目标的开放机构。他宣称:“这是为对抗巨头而生的AI‘守护者’!”机构以开源、透明为原则,承诺“让AI造福全人类”,首轮募资即达10亿美元,这就是后来被大家所熟知的OpenAI。
-
2016年:AlphaGo上演“AI成人礼”
2016年,DeepMind打造的AlphaGo以4:1的比分击败韩国围棋冠军李世石。围棋这项曾被视作人类智慧最后堡垒的古老技艺,轰然被AI攻克。这不仅是棋盘上的胜负,更是一个震撼的宣告:人工智能不再是科幻概念,它已强悍地闯入现实,向全世界展示了其深不可测的潜力。

-
2020年:AlphaFold破解生命的“折叠密码”
2020年DeepMind正式推出了AlphaFold,凭借其在蛋白质结构预测领域的突破性贡献,2024年,DeepMind创始人哈萨比斯和DeepMind工程师乔普连同科学家戴维·贝克共同荣获诺贝尔化学奖。
三、DeepSeek:中国AI的"普惠之光"

2022年,OpenAI发布ChatGPT,大模型的浪潮将AI推向下一个巅峰。但当全球科技巨头沉迷于"参数竞赛"与"闭源壁垒"时,一群来自中国量化投资巨头幻方量化的工程师,正悄悄做着另一件事——他们要打造"性能接近国际顶尖模型,成本却低一个数量级"的大语言模型,让AI真正"飞入寻常百姓家"。
2023年7月,脱胎于幻方量化的DeepSeek正式成立。"纯血国产""技术普惠"是这家公司的双重标签。不同于行业巨头动辄投入数十亿美元的"暴力训练"模式,DeepSeek团队另辟蹊径:通过模型架构优化来提升计算效率,采用开源策略吸引全球开发者共建生态。
这种"拼多多式"的AI突围,很快在2024年底迎来爆发:其发布的DeepSeek V3基础模型与2025年1月的DeepSeek R1推理模型,性能直逼OpenAI o1正式版,支持复杂问题分解、模块化处理等高阶能力,却将单次调用成本压缩至行业水平的1/10。紧接着在国内的产业界也引发了一场DeepSeek的应用浪潮。
受其推动的里程碑事件
-
2025年1月:AI领域的“斯普特尼克时刻”
2025年1月27日,DeepSeek应用如黑马般同时登顶苹果中美应用商店免费榜榜首,将ChatGPT挤至次席。日活用户突破3000万,服务器一度因流量洪峰“闪崩”——这场由中国团队主导的AI狂欢,被《华尔街日报》称为“AI领域的斯普特尼克时刻”(开启人类航天史上大国军备竞赛的时刻)
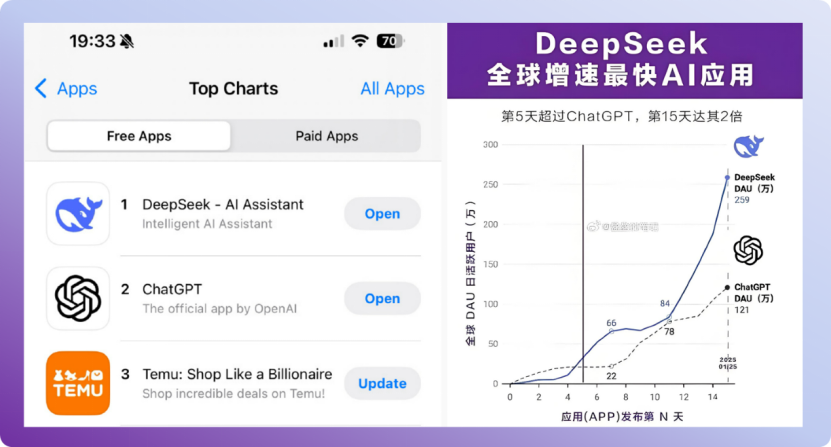
-
2025年2月:全球云厂商的“DeepSeek联盟日”
短短十天内,中国四大互联网云巨头——百度、阿里、华为、腾讯——集体官宣上线DeepSeek模型服务,打响“AI接入战”。百度智能云推出“限时免费体验”,腾讯云实现“3分钟极速部署”,华为昇腾云完成国产芯片适配。更戏剧性的是海外巨头的罕见支持:微软Azure将OpenAI竞品DeepSeek-R1纳入企业级平台;亚马逊CEO安迪·贾西亲自喊话“尽管用”;英伟达官网高调展示其为“最先进开源模型”。
-
2025年3月:算力采购狂欢与“一体机泡沫”
DeepSeek热潮在国内引爆了GPU采购热潮。硬件厂商纷纷推出“DeepSeek一体机”,其中满血版搭载8颗GPU芯片,售价普遍超百万;华强北商家甚至通过“现场攒机”牟利。企业跟风抢购,却未算清经济账——据某券商测算,私有部署的硬件利用率往往不足30%。相比之下,九章云极等智算云平台通过动态调度大幅提升了闲置资源利用率,证明具备高效调度能力、能灵活适配多场景的弹性算力租用,才是企业最具性价比的算力投入方式。 在算力应用方面,对大多数企业而言,“开箱即用是伪命题,云端协同才是最优解”
结语
2024年的诺贝尔奖同时颁给了DeepLearning的提出者辛顿和DeepMind的创始人哈萨比斯,这也是诺贝尔奖第一次颁发给AI从业者。对很多行业来说诺贝尔奖是他们追逐的终点和终极目标,但对于人工智能而言,或许这仅仅是它迈向下一次辉煌的起点。

三大“Deep”力量不止有两个“Deep”的主导者获得了诺贝尔奖,更推动了大模型时代的加速降临。它们所带来的“影响力”毋庸置疑,而“深度”背后的“含金量”同样惊人:
- 2013年,为了竞拍而临时组建的DNNresearch三人公司(提出AlexNet的三人小队)被谷歌以4400万美元收购。辛顿主动终止竞拍,拒绝了更高报价。
- 2014年,谷歌以6.5亿美元收购50人团队DeepMind。传闻Facebook出价翻倍,但因拒绝承诺DeepMind坚持的AI伦理独立条款而错失交易。
- 2025年,当OpenAI估值冲上3000亿美元,作为中国代表性大模型企业,DeepSeek被业内预测估值或达1500亿美元。
由此可见“Deep”不止很深度,而且很值钱—“Deep”之名,既象征技术之深,亦暗藏价值之厚。

精彩内容

欢迎加入北京社区
更多推荐


 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)