51c大模型~合集121
我自己的原文哦~ https://blog.51cto.com/whaosoft/13869815
#大模型何以擅长小样本学习?
这项研究给出详细分析
近年来,大语言模型(LLM)在人工智能领域取得了突破性进展,成为推动自然语言处理技术发展与通用人工智能实现的核心力量。上下文学习能力(In-Context Learning, ICL)是 LLM 最显著且重要的能力之一,它允许 LLM 在给定包含输入输出示例的提示(prompt)后,直接生成新输入的输出,这一过程仅通过前向传播而无需调整模型权重。这种能力使得 LLM 能够基于上下文中的示例快速理解并适应新任务,展现出强大的小样本学习和泛化能力。理解 LLM 是如何实现 ICL 的,对于提高模型性能与效率、提升模型可解释性与 AI 安全、推广大模型应用与改进小样本学习算法具有重要意义,也是近来机器学习研究热点之一。有以下关键问题需要回答:
1.LLM 能够学到哪些学习算法,例如梯度下降、比较近邻等?
2. 在具体问题的 ICL 过程中在执行哪一种学习算法?
3. 如何进一步提升 LLM 的 ICL 能力?
ICL 通常建模为将多个已知样例与预测目标输入一起,拼接成序列输入 LLM 中的 transformer 模型,输出对目标的预测(图 1 左)。现有工作已证明 ICL 在不同模型和数据分布条件下,能够分别实现如线性回归和梯度下降等具体的学习算法,从已知样例中学习到任务对应输入输出映射,并作用于目标输入上产生预测输出。而这种学习算法是 transformer 模型通过预训练过程得到的,现实中 LLM 的预训练涉及海量的文本数据,含有复杂的语义信息,难以用单一的数学分布建模。现有工作对 ICL 实现小样本学习算法的解释难以泛化到真实世界场景或实际 LLM。为了对 ICL 的小样本学习能力有更直观的认识,在近期发表于 ICLR2025 的工作 “Why In-Context Learning Models are Good Few-Shot Learners?” 中我们对 ICL 模型作为元学习器的本质进行了建模与研究,以对上面三个问题进行了回答。
- 论文链接:https://openreview.net/pdf?id=iLUcsecZJp
- 代码链接:https://github.com/ovo67/Uni_ICL
1. 将 LLM 建模为元学习器覆盖学习算法空间
ICL 模型可以学到所有传统元学习器学到的算法。元学习(Meta-Learning)是一种 “学习如何学习” 的方法,可通过设计模型使其能够快速适应新任务应用于小样本学习。它通过在多个相关任务上进行训练,学习到一种通用的学习策略或算法,从而在面对新任务时能够快速调整自身参数或结构,实现快速优化和泛化。借助元学习领域成熟的理论基础与方法经验,理论证明了作为实现学习算法的模型,基于 transformer 的 ICL 模型与传统的元学习器相比具有更强的表达能力(图 1 右)。

图 1 大语言模型的上下文学习示例,以及上下文学习模型在学习算法空间中与传统元学习模型的关系。
2. ICL 模型学到并执行在预训练分布上最优的算法
ICL 算法的学习是通过对预训练数据分布的拟合。在预训练充足的情况下,ICL 模型能够学习到在预训练任务集上最优(在与训练数据分布上最小化损失)的学习算法,从而在仅有少量样本的情况下实现快速适应。我们构建三类已知最优算法(Pair-wise metric-based/Class-prototype metric-based/Amortization-based 三种任务的最优算法分别可由元学习器 MatchNet/ProtoNet/CNPs 学习得到,图 3a)的任务。首先分别在单一种类任务集上训练,测试表明 ICL 性能与该预训练数据下能学到的最优算法表现相当(图 2 上)。然后再混合三种任务集上训练,三种传统元学习器的性能都有所下降,而 ICL 的性能依然与单一种类任务训练得到的最优性能一致(图 2 下)。以上结果说明 ICL 模型能够学习到预训练任务集上最优的学习算法,并且与传统的元学习器相比 ICL 模型具有更强的表达能力,因为它们不仅能够学习到已知的最优学习算法,还能够根据数据的分布特性表达出传统视野之外的学习算法,这使得 ICL 模型在处理多样化任务时具有显著优势。


图 2(上)分别在三种任务集上训练并对应测试的测试表现;(下)在混合任务集上训练并分别测试三种任务的性能表现。
我们还对 ICL 模型学习到的算法的泛化性进行了实验研究。展示出了其作为深度神经网络受数据分布影响的特性:其预训练过程本质上是在拟合以特定结构输入的训练任务集的数据分布,而无法保证学习到显式的基于规则的学习算法,这一发现纠正了现有工作将 ICL 解释为算法选择(Algorithm Selection)的过程。这将导致 ICL 模型在预训练数据受限或测试数据分布有偏移时性能表现不及预期(图 3)。


图 3 ICL 与 “算法选择” 行为的比较(a)两种模型在三类已知最优算法的任务上训练,在未知最优算法任务上测试;(b)对于测试任务 ICL 可以处理而 “算法选择” 无法处理;(b)ICL 对测试数据分布敏感而 “算法选择” 不敏感。
3. 将传统深度网络的相关方法迁移到元学习层面以提升 ICL 性能
基于上述对 ICL 模型作为学习算法强表达、难泛化的认识,可以将 ICL 模型对特性与传统深度神经网络的特性进行类比。我们提出通过 “样本 - 任务” 的概念映射将传统深度学习技巧迁移到元学习层面以优化 ICL 模型。例如实现了基于任务难度的元课程学习提升 ICL 模型预训练过程的收敛速度:图 4 展示了对于线性回归任务以递增非零维度数量作为课程的效果,元 - 课程学习能有效加速 ICL 模型的收敛,但不一定提升其最终性能。

图 4 元 - 课程学习(左)训练过程 loss 变化;(中)200000 episodes 时的测试结果;(右)500000 episodes 时的测试结果。
又例如实现了基于领域划分的元 - 元学习,即将训练数据划分为多个领域,每个领域含有一个训练任务集和验证任务集,即可将以单个任务为输入的 ICL 模型作为待适应网络,构建元 - 元学习器在每个领域上利用训练任务集进行适应。实验效果如图 5 所示,提升了 ICL 模型的有限垂域数据高效适应能力。

图 5 采用元 - 元学习的 ICL 模型分别在给定每领域 64/256/1024 个任务时的适应表现。
4. 总结
本文通过将 ICL 模型建模为元学习器,证明了 ICL 模型具有超过已有元学习器的表达学习算法的能力;ICL 执行在预训练数据分布上最优的算法,而不一定具有可泛化的规则;可以将传统深度网络有关技术迁移到元学习层面用以提升 ICL,如元 - 课程学习加速预训练收敛,元 - 元学习提升少数据领域微调快速适应能力。
作者介绍
吴世光,清华大学电子工程系博士研究生,本科毕业于清华大学电子工程系。当前主要研究方向包括元学习与大语言模型。
王雅晴,现任北京雁栖湖应用数学研究院(BIMSA)副研究员,长期从事机器学习、人工智能和科学智能的研究,致力于构建高效、低成本的智能算法,以精准匹配海量数据的科学解释并解决现实问题。她在 NeurIPS、ICML、ICLR、KDD、WWW、SIGIR、TPAMI、JMLR、TIP 等国际顶级会议和期刊上发表 27 篇论文,总被引用 4500 次。2024 年,她入选全球前 2% 顶尖科学家榜单。
姚权铭,现任清华大学电子工程系助理教授,研究方向为机器学习和深度学习。共发表文章 100 + 篇,涵盖机器学习领域顶级期刊 JMLR、IEEE TPAMI 和顶级会议 ICML、NeurIPS、ICLR 等,累计引用超 1.2 万余次。担任 ICML、NeurIPS、ICLR 等会议领域主席,NN、TMLR、MLJ 等期刊(资深)编委。获首届蚂蚁 In Tech 科技奖、国际人工智能学会(AAAI)学术新星、国际神经网络学会(INNS)青年研究员奖、吴文俊人工智能学会优秀青年奖,同时入选全球 Top 50 华人 AI 青年学者榜和福布斯 30under30 精英榜。
....
#PaperBanana
谷歌做了个论文专用版nano banana!顶会级Figure直出
你负责写方法,AI负责画 Figure。 科研打工人,终于等来「画图解放日」。
还在为论文里的方法框图熬夜画 PPT、拉箭头、对齐字体吗?
一张 Figure 2,动辄几个小时,严重的甚至能耗上几天,科研人的「隐藏副本」不是实验,而是画图。
既要忠于论文原意,又得暗暗符合顶会那套心照不宣的「学术审美」:颜色不能土,布局不能乱,箭头更不能连错。
看起来只是一张图,实际上是美学、逻辑和耐心的三重折磨。
那么,问题来了:现在的大模型已经能写论文、跑实验、改代码,为什么偏偏搞不定这些学术插图?有人可能会问:DALL·E、基础 VLM 不行吗?
答案是:真不行。
它们画出来的图往往是:模块和文字对不上、字体直接乱码、箭头逻辑错误。图是「好看」,但不中用啊。
于是,一个狠角色出现了:PaperBanana 🍌
来自北大 + Google Cloud AI Research 的团队,目标很简单也很狂:你写方法,AI 画 Figure,水准呢?直接投顶会的那种。
科研打工人,终于等到了「画图解放日」。




来看效果成色。
PaperBanana 展示了解决两类学术插图的能力:
第一类,是论文方法流程图与模型结构示意图,用来说明算法如何运作(左);第二类,是统计图表,用来表达实验结果与数据对比(右边)。

左边是方法框图(Methodology Diagrams),右边是统计图(Statistical Plots)
与以往「只会画图像」的生成模型不同,PaperBanana 强调两点:不是只要「画得好看」,而是必须「画得正确」。
它要保证:模块之间的逻辑关系不出错、数据表达符合科研规范、图可以直接服务论文叙事,而不是装饰。
研究指出,PaperBanana 可以覆盖多种常见学术插图类型,包括方法流程图、模型结构示意图、概念性框架图,以及通过代码驱动生成的高精度统计图。
PaperBanana 不仅能从零生成,还能润色你现有的丑图。
给它一张草图或初版框图,它负责自动美化、重排布局、统一风格,让它更像顶会论文里的标准图形
更直观的对比——
左侧是手工绘制的插图,右侧是 PaperBanana 风格增强(Style Enhanced)后的版本。

这些示例覆盖了多个典型科研场景,包括 Transformer 与不同 LayerNorm 变体的对比示意、工程流程与三维建模管线的系统框架,以及强化学习和表示学习中抽象几何关系的表达。它们的共同特点在于逻辑复杂、元素密集,对人工排版提出了极高要求,也正是科研人员最容易在“画图”上消耗大量时间与精力的部分。
语义结构上一致,但视觉呈现,完全不同。
原始图信息完整,却给人一种「能看懂,但不好看」的感觉:布局略显松散,配色偏向单一,不同模块之间的层级关系也不够清晰。
PaperBanana 润色增后,图中的逻辑被重新梳理进一套更规范的视觉体系之中。
不同功能模块通过颜色进行区分,虚线和分区框用来强化层次结构,箭头的走向也更加明确,整体观感明显更接近顶会论文中常见的标准范式。
再看下面的图例,同一张图对比,高低立判。
人类画的图,对,但不一定好看。
未经调教的原始模型生成(Nano-Banana-Pro),画出来但难读。
PaperBanana 真正做到了「画清楚、讲明白」,也更符合顶会审美的论文级插图:配色更现代统一,信息更精炼,模块分区更清晰。

那么,它是如何做到这一点的?
PaperBanana 「画论文图」变成了一条由多智能体协作完成的流水线。
系统先检索参考范例,再规划结构化描述,并在审美规范约束下生成初稿;
随后由视觉代理将文本描述转化为图像或代码绘图,评论代理不断对照原始论文内容进行纠错与打磨。
经过多轮迭代后,输出的不再是普通示意图,而是一张同时满足语义正确性与顶会审美标准的论文级插图。
这不是简单的作图自动化,而是一种「科研表达方式」的自动规范化。

研究人员还顺带对比了两种路线:直接让模型「画图」 VS 让模型「写代码画图」。
结论很扎心:AI 直接画出来的图虽然精美,但经常在数字上胡说八道。
目前最靠谱的方式还是:AI 写绘图代码(基于 Gemini-3-Pro),再生成统计图。

这只是开始。类似工具已经开始出现,比如:Claude Scientific Writer,集成论文写作 + 插图 + 图表生成。
未来科研可能变成这样:你不用再在 PPT 里对齐箭头、调颜色、拖文本框到凌晨三点,而是把更多时间留给真正重要的事情。
参考链接
https://dwzhu-pku.github.io/PaperBanana/
https://github.com/K-Dense-AI/claude-scientific-writer
....
#Mixture-of-Visual-Thoughts:Exploring Context-Adaptive Reasoning Mode Selection for General Visual Reasoning
这道题是否需要用图思考?模型来告诉你!自适应思考模式切换助力通用视觉推理提升
本文来自复旦大学和阿里巴巴未来生活实验室,已中稿 ICLR 2026。
目前的视觉推理方法衍生出了多种思考模式,主要有和 LLM 一致的纯文本思考模式以及更加贴近图片的用图思考。两种推理模式在不同的领域各有所长,但现有的工作聚焦于单个思考模式,无法充分利用两个模式之间的互补性。
因此,本文提出了 mixture-of-visual-thoughts,一种自适应的推理范式:目标是将不同推理模式整合到一个模型内部并引导其进行自适应的模式选择。为了让模型学习这样的推理范式,研究者引入了一个两阶段的学习框架 AdaVaR,通过 SFT 学习不同的推理模式,并设计了一个专门的 AdaGRPO 算法来在强化学习设定下引导模型学习如何根据问题选择合适的推理模式。
- 论文标题:Mixture-of-Visual-Thoughts:Exploring Context-Adaptive Reasoning Mode Selection for General Visual Reasoning
- 论文链接:https://arxiv.org/pdf/2509.22746
- 代码链接:https://github.com/Future-Living-Lab/mixture-of-visual-thoughts
- 3B & 7B模型:https://huggingface.co/collections/ZejunLi/adavar-models
背景:视觉推理的不同思考模式
目前对于 LVLM (large vision-language model) 的视觉推理方法已经有了大量的探索,其中主流推理范式包括以下两种:

图 1: 两种推理模式的直观对比。
1. 纯文本思考模式:和 LLM 一样,直接用自然语言描述推理过程;
2.Visually-Grounded 思考模式:通过结构化的信息(主要是 bounding box 等坐标)将推理路径中的关键概念与图片中的区域对应起来,进一步还可以将对应局部区域进一步裁剪缩放后输入给模型,帮助其利用局部的信息,即 GPT-o3 中提到的 thinking with images 的概念。
这两种思考模式不同的设计也让它们在不同领域上有不同的优劣表现,以下图几个基于 Qwen2.5-VL-7B 的推理模型为例(正数 / 负数代表相对基座模型有提升 / 下降):

图 2: 基于 Qwen2.5-VL-7B 的不同推理模式模型相对于基座的提升 / 下降。
1. 文本思考模式更善于抽象的视觉问题,比如数学几何题,但可能会带来幻觉,也在视觉搜索的 V * 上表现不佳(存在过度思考和 language bias 的问题);
2.Grounded 模式则更善于定位和利用视觉信息,抑制幻觉,但是在抽象的数学问题上提升不明显(对于抽象的概念,比如角度,大小等,模型对其进行 grounding 来提供有效的信息)
受启发于此,本文希望探索这样的一个问题:“我们是否可以博采众长,将不同思考模式在不同领域上互补的优势整合起来,来帮助提升通用的视觉推理能力呢?”
Mixture-of-Visual-Thoughts:
自适应的视觉推理范式
基于这样的想法,本文提出了 Mixture-of-Visual-Thoughts(简称 MoVT),一种自适应的视觉推理范式:我们希望一个统一个推理模型(1)能够具有不同思考模式;(2)同时能够根据问题自适应地选择合适的模式。
本文也基于 MoVT 的范式进行了初步的探索,我们提出了 AdaVaR 学习框架,通过两个阶段的训练来构建出具有 MoVT 自适应推理能力的模型:
1. 我们在推理序列的开始给不同模式引入了对应的特殊 prefix token,比如 < text>, <ground>,作为指示符帮助模型区分不同的推理模式,然后通过 SFT 整合数据帮助模型学习不同的思考模式;
2. 我们设计了一个 AdaGRPO 的强化学习算法来引导模型进行模式的选择。i. 通过固定模式 prefix token,我们引导模型对同一个问题使用不同的思考模式生成推理 rollout,ii. 并设计了特殊的 advantage 计算方法:同时用 rollout-level advantage 增强模型的推理能力,并计算思考模式之间相对的 mode-wise advantage 来引导模型选择更优的思考模式。
具体方法的介绍和细节请感兴趣的读者参阅下面一节。
我们在多个场景的多个数据集上进行了评测,如图 2 所示,不同于单模式的模型只是在特定场景表现突出,我们的 AdaVaR 模型在多个任务上都有一致的提升。从 8 个数据集的平均性能来看,我们的 AdaVaR-3B 能够媲美 Qwen2.5-VL-7B,AdaVaR-7B 甚至要超越 GPT-4o 的性能。
AdaVaR:思维模式的整合和训练方法
通过 Prefix Token 统一不同思考模式
首先我们希望让多个思考模式在同一个模型内共存。为此,我们设计了一种统一的推理序列形式,通过特殊的 mode prefix token 来区分不同模式:

蓝色部分就是 mode prefix token,红色部分则是对应的思考过程。基于自回归的生成设定,我们发现生成这样的推理序列相当于在一次生成中先后完成了(1)根据问题生成 prefix token,完成模式选择;(2)根据选择的模式进行对应的思考。
mode prefix token 的引入帮助模型区分了不同的模式,也支持了后续 RL 算法中对于思考模式的干预。
基于这样统一的形式,我们对两种模式收集了对应的数据来进行 SFT,这样模型就具有了以两种模式思考的能力。
AdaGRPO:引导模型进行模式选择
之后我们希望模型能够自适应地根据问题选择合适的推理模式。我们在强化学习的环境下进行这样的学习,其核心想法是:对同一个问题,模型会分别用两种模式推理 n 次,与其他方法类似,我们以结果的正确性为导向,基于规则判断答案的正确与否作为奖励函数。然后基于 rollout 之间,模式之间的比较,设计双层次的 advantage 计算方式鼓励模型生成更好的推理路径,同时选择更优的思考模式。

图 3: AdaGRPO 和 GRPO 的比较。
为此我们设计了 AdaGRPO,对 GRPO 做出了如下的优化:
1.Prefix-guided Exploration:GRPO 中的 rollout 生成过程是自由的,可能导致模式之间的不均匀探索,比如对同一个问题生成的 2n 条思考过程都是同一个模式。所以 AdaGRPO 中,我们通过固定 mode prefix,让模型前 n 条 和 后 n 条 rollout 分别来自文本思考和 grounded 思考模式;
2.Adaptive Advantage:GRPO 中只计算了 rollout-level advantage A_i = (r_i - Mean) / Std 来提升推理能力,而且给 rollout 里所有的 token 都赋予同样的 advantage。为了显式地引导模式的选择:
a.AdaGRPO 中以相对胜率刻画了两个模式之间相对的优势 A_t 和 A_v(A_t = 对于该问题,用文本推理模式得到的 reward 要高于 Grounded 模式的概率,反之亦然);
b. 如上一节中设计的推理序列形式,mode prefix token 和思考过程承担了不同的作用,于是我们也将不同的 advantage 赋予不同的 token,将 A_t 和 A_v 赋予 mode prefix token 来鼓励模式的选择,将 A_i 赋予思维过程的 token 来提升模型的推理能力
除此之外我们还设计了一个课程学习的数据构造方法。开始时模型在简单混合的数据上学习(包括几何题和物体计数任务);后续则在多个任务混合的数据上学习。题目也会从简单到难,让模型逐步学习从简单到难的推理以及模式选择。
实验结果
我们基于 Qwen2.5-VL-3B/7B 构造了我们的 AdaVaR-3B/7B,在 8 个数据集上与其他基于 Qwen2.5-VL 的推理模型进行了比较:

表 1: 不同模型之间的性能。黄色底代表文本推理模型,绿色底为 Grounded 推理,蓝色底为本文的 AdaVaR 模型。
1. 首先评测的结果也支持了之前背景里提到的论述 -- 只基于单思考模式的推理模型通常是特定领域的专家,很难有通用的提升,具体来说:i. 文本推理模型,比如 VLAA-Thinker-3B 和 OVR-7B,主要在数学任务上表现好,但是物体相关问题回答不好;ii. Grounded 推理模型则在 V * 和 POPE 上都表现不错,但数学任务上不理想,只有 DeepEyes 有提升,其他都很难保持基座模型的数学推理能力;
2. 而 AdaVaR-3B 和 AdaVaR-7B 是仅有的在所有任务上都优于 Qwen2.5-VL 基座的模型,甚至在 MathVista,WeMath,POPE 上都是最优,MMStar 和 MathVision 也是最优 / 次优的表现。
3. 从平均准确率刻画的总体性能来看,AdaVaR-3B/7B 都是在对应组别最优的模型。AdaVaR-3B 是唯一一个达到了 Qwen2.5-VL-7B 水平的 3B 模型,而 AdaVaR-7B 甚至要比 GPT-4o 还好。
深入分析自适应推理的机制
进一步我们还深入探究了自适应推理中的机制,希望能回答:

表 2: 对于不同模式,不同阶段模型的性能。下标 T 和 G 分别代表固定使用 text 和 grounded 模式。GRD% 代表自适应的模型选择 grounded 模式的比例。
Q1: 在一个模型内是否可以,以及如何学习到不同的模式?
首先我们从表 2 可以看到 AdaVaR 模型在 SFT 和 RL 阶段上,从性能来看,两个模式就展现出了截然不同的表现,类似之前提到的文本模式数学能力强,Grounded 模式善于处理物体导向的问题。
Q1.1: 只用一个模式,提高数据的 diversity 是不是就够了?
A1.1: No。我们用 AdaVaR 相同的数据训练了两个单思考模式的 baselines,Grounded-SFT-RL 和 Text-SFT-RL。两个模型的性能都没有 AdaVaR 好,说明 MoVT 整合两种模式的想法是非常有效的。
Q1.2: 两个模式在同一个模型内部是否会互斥?
A1.2: No。同样比较 Grounded-SFT-RL 和 Text-SFT-RL 和 AdaVaR 的两个模式,我们发现整体上差异并不大,也都相较 SFT 阶段有明显的提升,说明整合到一个模型内并不会抑制单个思考模式的提升。
Q1.3: 是否需要 Mode prefix 来区分不同模式?
A1.3: Yes。参见表 2 的 Mix-SFT-RL baseline,我们去掉了 mode prefix,直接混合两个模式的数据。这样做的性能甚至要比单模式推理的模型还差,说明显式的模式区分是必要的,而且显式的区分支持了后续在 AdaGRPO 里 prefix-guided exploration 对于模式探索的干预。
Q1.4: 两个模式是否是互补的?
A1.4: Yes。表 2 中还计算了 AdaVaR 的 Upper Bound,即任意一个模式做对的准确率,我们可以看到对于所有数据集,即使是数学题这种文本模式明显占优的,Upper Bound 也要明显高于文本模式,这也展示了后续 MoVT 范式的巨大潜力。
Q2: 模型能学到合理的模式选择能力吗,怎么学习到的?
对比表 2 中的单模式和自适应模式的表现,我们发现:
1.SFT 以后的模型对于模式的选择并不是最优,比如 MathVista 上文本模式明显更好,但是 AdaVaR-SFT 还是选择了 31% 的 grounded 模式,说明 SFT 阶段很难控制模式的选择;
2. 但是 RL 以后,AdaVaR 的模式选择就比较合理,在数学问题上选择文本模式,V * 和 POPE 上选择 grounded 模式,同时 AdaVaR 在所有任务上,自适应模式都要优于文本 /grounded 的单模式推理,说明了 RL 阶段模型学到了合理的模式选择能力。
Q2.1: 模型是怎么学习到这样的能力的?

图 4: 数学问题上的 (a) 训练 reward 曲线;(b) MathVista 上的表现。
A2.1: 如图 4 所示,以数学问题为例,我们可以看到,图 (a) 中两个模式相对的 reward 高低(表现好坏)引导了图 (b) 中 GRD% 曲线(模式选择)的变化。大概可以分为三个学习阶段:
1. 初期探索阶段:刚开始,因为两个模式之间的相对好坏还不稳定,此时 GRD 模式甚至在一段时间内更优,导致一开始存在一定的波动;
2. 稳定阶段:在 500 步开始,TXT 模式要明显优于 GRD 模式,模型的选择也逐步稳定到以 TXT 模式为主,但此时自适应的 ADA 模式要比文本模式还弱,说明模型还没有学习到具体哪些题目应该使用 GRD 模式
3. 微调阶段:在 1500 步后,因为我们使用了分布更广的数据,帮助模型学习到了更佳精细的推理和模式选择能力,两个模式都在提高,并且 ADA 模式最终要优于两个单模式。
Q2.2: 对于模式选择的关键因素?
A2.2: 我们还发现,AdaGRPO 中的关键机制,包括 prefix-guided exploration,Adaptive advantage,以及数据的 diversity 和课程学习都非常重要,具体的实验比较可以参见原论文的 Table 3。
结论与未来展望
本文说明了 MoVT 这样,整合多个推理模式的方式能够是一种构建通用推理能力的可行思路,而 AdaGRPO 则是能够有效学习模式选择的算法。更一般来看,MoVT 相当于从思考模式的角度提升了模型生成推理 Rollout 的丰富度,促进了 RL 过程中的 exploration。本文对于自适应推理的探索也存在一定的局限性,希望未来能有相关工作进行研究:
- 为了保持两种模式 Rollout 的一致性,本文中探索的 Grounded 思考模式并未像一些现有的工作额外引入局部的视觉特征,后续如何在统一的框架里整合差异更明显的思考模式同样值得探索;
- 本文目前仅考虑了两种推理模式,但 MoVT 的框架也可以容纳更多的模式,也可以用于学习目前主流关心的思考 / 不思考的自适应切换能力,甚至区分长思考,短思考,是否使用工具等等;
- 对于未来更多种类的思考模式,势必会面对更加严峻的 exploration-exploitation tradeoff:模式越多,为了平衡模式之间的探索,单个模式的推理数量势必更少,也会进一步抑制各个模式内部的提升;
- 目前 MoVT 采取的是并行的模式选择范式,进一步还可以结合搜索机制,考虑线性的模式切换,比如先进行短思考,再考虑是否进行长思考等等更复杂的逻辑,来提升推理模型的上限。
....
#Claude智能体压垮华尔街
昨夜,Claude智能体压垮华尔街,近万亿刀市值蒸发
AI 在代替人类之前,先要替代一大波软件?
昨夜,整个华尔街陷入了恐慌,Anthropic 发布的新一代人工智能工具「Claude Cowork」及其配套的 11 款职能插件正式上线,被市场视为 AI 从「辅助工具(Copilot)」向「独立员工(Agent)」跨越的分水岭,直接动摇了 SaaS 软件的商业根基。
从甲骨文、Adobe、Salesforce 到汤森路透、NEC,一系列人们耳熟能详的知名公司股票遭到抛售。

作为智能体时代的 AI 工具,Claude Cowork 远远超越了大模型聊天机器人的范畴。Cowork 可以直接在你的电脑上帮你干活,它拥有足够高的权限,可以接管你的鼠标、键盘和文件系统,按照你的模糊指令,自主规划并完成一连串复杂的工作。
,时长01:08
另一方面,与最近很火的开源项目 ClawdBot 不同在于,为了防止 AI 误删文件或通过联网完成人们预料之外的操作,Claude Cowork 运行在隔离的虚拟机(VM)环境中。
这是一个更加严肃,一上来就被设计为用来干活的智能体。Anthropic 为 Claude Cowork 准备了一系列「职业技能包」,其表示,这些工具可以生成财务报表、研究销售线索、准备销售电话、起草客户支持回复、评估保密协议,以及审查合同、法律简报和构建财务模型。
初看起来,这些说法和过去很多大模型、智能体发布时 AI 公司宣传的情况类似。在 1 月 12 日 Claude Cowork 的「研究预览版」首次亮相时,大家只觉得这是一个性能更强的自动化工具。
然而到了 1 月 31 号,Anthropic 发布 11 款官方开源插件时,有人发现事情并没有这么简单。

Anthropic 为其「桌面级全能数字员工」Claude Cowork 智能体平台发布了一系列插件(https://github.com/anthropics/knowledge-work-plugins),该公司声称这些插件可以自动执行数十项任务,包括客户服务、产品管理、市场营销、法律和数据分析等工作。
和之前宣传说的差不多?然而这次人们开始担心,支撑科技和数字服务行业发展的软件服务(SaaS)商业模式即将面临颠覆性风险。
华尔街担心,像 Claude 插件这样的 AI 工具会挑战现有软件公司的数据分析和研究产品 —— 利用 AI 实现自动化并构建自有工具的公司可能会减少对外部研究和数据服务的订阅,这将直接损害软件公司的利润。
周二遭遇全面抛售后,标普 500 软件和服务指数板块下跌近 4%,连续第六个交易日下跌,自 1 月 28 日以来市值蒸发约 8300 亿美元。

AI 工具最终是否会摧毁软件行业,目前尚无定论。但本周二,投资者们的恐慌是实实在在的,人们纷纷抛售法律和金融软件及服务公司的股票。毕竟,既然 AI 能减少内部开发所需的时间,那为什么还要为软件付费呢?
看起来,AI 对众多产业的革命正在具象化。今年 1 月,Anthropic 首席执行官达里奥・阿莫迪(Dario Amodei)就撰文认为「人工智能可能会在未来 1-5 年内取代一半的入门级白领工作」。
Anthropic 对此有多大的信心呢?他们昨天还强调了自己不会在 AI 里面加广告,宣传打到了超级碗,还顺带嘲讽了一波 OpenAI。
,时长01:00

OpenAI 创始人、CEO 山姆・奥特曼不得不出来回应。

如此激烈的竞争,或许很快还会催生出更加强大的 AI 能力?
参考内容:
https://www.cnn.com/2026/02/04/investing/us-stocks-anthropic-software
https://www.anthropic.com/news/claude-is-a-space-to-think
....
#Maximum Likelihood Reinforcement Learning
强化学习远不是最优,CMU刚刚提出最大似然强化学习
在大模型时代,从代码生成到数学推理,再到自主规划的 Agent 系统,强化学习几乎成了「最后一公里」的标准配置。
直觉上,开发者真正想要的其实很简单:让模型更有可能生成「正确轨迹」。从概率角度看,这等价于最大化正确输出的概率,也就是经典的最大似然(Maximum Likelihood)目标。
然而,一项来自 CMU、清华大学、浙江大学等研究机构的最新工作指出了一个颇具颠覆性的事实:
现实中广泛使用的强化学习,并没有真正在做最大似然优化。严格的理论分析显示,强化学习只是在优化最大似然目标的一阶近似 —— 距离我们以为的最优训练目标,其实还差得很远。
正是基于这一观察,研究团队对强化学习的目标函数进行了重新审视,提出了最大似然强化学习(Maximum Likelihood Reinforcement Learning):将基于正确性的强化学习重新刻画为一个潜变量生成的最大似然问题,进一步引入一族以计算量为索引的目标函数,使训练目标能够逐步逼近真正的最大似然优化。
- 论文标题:Maximum Likelihood Reinforcement Learning
- 论文链接:https://arxiv.org/abs/2602.02710
- 项目地址:https://zanette-labs.github.io/MaxRL/
- Github 地址:https://github.com/tajwarfahim/maxrl
传统强化学习的「卡脖子」问题
在代码生成、数学推理、多步决策这些任务中,我们已经形成了一种几乎默认的共识:只要反馈是二值的、过程是不可微的,就用强化学习。
强化学习这套范式,支撑了从 AlphaGo 到大语言模型推理能力提升的一系列关键进展。
从端到端的角度看,强化学习就是给定一个输入,模型隐式地诱导出一个「成功概率」. 如果不考虑可微性约束,最自然、也最原则性的目标,就是最大似然。
但论文研究团队发现:基于期望奖励的强化学习,其实只是在优化最大似然目标的一阶近似。更具体地说,最大似然目标在总体层面可以展开为一系列以 pass@k 事件为基的项,而标准强化学习只优化了其中的一阶项。
简单来说,强化学习并没有真正最大化「模型生成正确答案的概率」,而是在优化一个与真实似然存在系统性偏差的替代目标。
这也解释了一个广泛存在却难以言说的现象:强化学习早期进展迅速,但越到后期,性能提升越困难。
研究团队针对这一新发现,对「基于正确性反馈的强化学习」进行了重新刻画,论文的主要贡献如下:
- 将基于正确性的强化学习形式化为一个潜变量生成的最大似然问题,并证明标准强化学习仅优化了最大似然目标的一阶近似。
- 提出了一族以计算量为索引的目标函数,通过对 pass@k 事件进行 Maclaurin 展开,在期望回报与精确最大似然之间实现连续插值。
- 推导出一种简单的 on-policy 估计器,其期望梯度与该计算量索引的似然近似目标完全一致,这意味着增加采样真正改善了被优化的目标本身。
最大似然:真正改进优化目标
研究团队认为,最大似然估计在有监督学习中表现卓越,为什么不直接在强化学习中实现它?
上一节中的观察启示我们:可以构造一个随计算量变化的目标函数族,逐步引入更高阶项;随着可用计算资源的增加,该目标函数族将逐渐收敛到完整的最大似然目标。
论文通过一系列推导,将最大似然目标在失败事件方面进行麦克劳林展开:

展开式中的最大似然梯度很难用有限样本进行估计。
特别是,估计大 k 值的 pass@k 梯度需要越来越多的样本,尤其是在通过率 p 很小的情况下。这种有限样本的困难正是提出最大似然强化学习(MaxRL)的动机所在。
研究团队将 MaxRL 定义为一类强化学习方法,它们显式地以最大似然为目标,而不是以通过率为目标,同时在有限采样和不可微生成的条件下仍然可实现。下面我们考虑一种实现该目标的原则性方法。
考虑通过将麦克劳林展开式截断为有限阶来近似最大似然目标,然后估计该目标。对于截断级别 T ∈N,我们将固定输入 x 的截断最大似然目标定义为:

对其求导得到截断的总体梯度:

这定义了一族目标函数:T = 1 还原为强化学习,T → ∞ 还原为最大似然,中间的 T 值则在两者之间插值。因此,截断级别 T 直接控制了有助于学习的正确性事件的阶数。随着在 rollout 方面消耗更多的计算量,对更高阶梯度的估计变得可行。
换句话说: MaxRL 提供了一个原则性框架,用于通过增加计算量来换取对最大似然目标更高保真度的近似。
上述公式已经给出了一种可行的无偏估计思路:利用 pass@k 梯度估计器,对有限级数中的每一项分别进行近似。在这一策略下,任何对 pass@k 估计器的改进,都会直接转化为对截断最大似然目标的更优梯度估计。
不过,在本篇论文中,研究者采取了一条不同的路径,将带来更为简洁的估计器形式,同时也提供了一个新的理解视角。
最大似然目标的梯度可以写成如下的条件期望形式:

该定理表明,最大似然梯度等价于仅对成功轨迹的梯度进行平均。这一解释为构造具体的梯度估计器提供了直接途径:只需用采样得到的成功轨迹,对上述条件期望进行样本平均即可。
其核心洞见在于:最大似然目标的梯度可以表示为在「成功条件分布」下的期望。
因此,本文采用了一种简单的策略:从非条件化的策略分布进行采样,但只对成功轨迹进行平均,得到了强化学习风格的估计器,其具备随着 rollout 数的增加,对最大似然梯度的近似将不断改善的特性。
换言之,在 MaxRL 框架下,额外的计算资源不仅改善了估计质量,更直接改进了被优化的目标本身。
令人惊讶的效率进步
在实验中,这一改变带来了远超预期的收益。研究团队在多个模型规模和多类任务上,对 MaxRL 进行了系统评估,结果显示:MaxRL 在性能与计算效率的权衡上均稳定地优于现有强化学习方法。

实验结果直观展示了 MaxRL 在训练效率上的优势。在相同训练步数下,MaxRL 性能提升明显更快,并且随着 rollout 数的增加,MaxRL 持续受益。
这种优势并不只体现在训练阶段,相较于使用 GRPO 训练的模型,MaxRL 测试时的 scaling 效率最高可提升 20 倍。

在迷宫任务上,无论测试时的采样预算 k 取何值,随着训练 rollouts 的增加,MaxRL 都能持续降低 −log (Pass@k),而 GRPO 与 RLOO 的改进幅度则明显更早趋于平缓。这一结果直观地展示了 MaxRL 在训练阶段更优的性能–效率权衡。

比较在不同 pass@k 设置下各方法随训练中采样计算增加时的优化趋势,可以看到,对于 GRPO 与 RLOO,曲线在早期下降后迅速变平,说明额外采样主要用于降低噪声;而 MaxRL 在不同 k 值下均保持持续下降,推动模型不断逼近一个更接近最大似然的优化目标。

在更大规模设置下,MaxRL 的优势依然保持稳定。这表明,MaxRL 所带来的改进并非依赖于特定规模或超参数设置,当训练规模扩大时,MaxRL 并未出现收益递减过快或优势消失的现象。

进一步的实验结果表明,MaxRL 的优势并不依赖于过于理想化的实验条件,即使在反馈存在噪声或验证信号并非完全可靠的设置下,MaxRL 仍然能够保持相对稳定的性能优势。
总体来看,MaxRL 为不可微、基于采样的学习问题提供了一种更为深入的解法。它通过一个随计算量自然扩展的目标框架,系统性地逼近真正的似然优化。
当优化目标本身可以随算力演进、逐步逼近最大似然,强化学习究竟会成为通往通用智能的长期答案,还是只是通往下一个训练范式的过渡方案?
更多信息,请参阅原论文。
....
#nanobot
3天5k+星标,港大开源极致轻量OpenClaw, 1%代码量打造个人专属贾维斯
最近硅谷被一个神奇的 Agent(OpenClaw/ClawdBot)刷爆了!
写代码、上网冲浪、操作电脑、定时提醒... 就像拥有了一个永不下班的 AI 助理。
但现实很骨感:当你兴致勃勃 clone 下来,准备一探究竟时 —40 万 + 行代码直接给你整蒙了。
面对 40 万行的复杂代码,很多开发者都有同样的困扰:"我只是想学习它的原理,或者快速部署体验一下,为什么这么复杂?"
港大黄超老师课题组正是为了解决这个痛点,将庞大系统重构为仅 4000 行的 nanobot—— 保留完整功能,大幅降低使用门槛,而且是纯Python实现。
从 40 万行到 4000 行,不只是代码的精简,更是使用体验的提升:2 分钟部署上线、架构清晰易于定制、核心逻辑便于学习。让每个开发者都能轻松搭建自己的贾维斯助手。
项目上线后反响不错,三天内在 GitHub 上获得了 5000+ 星标,700+ fork,也受到了海外开源社区的关注和讨论,不少开发者分享了使用体验。
项目链接:https://github.com/HKUDS/nanobot



OpenClaw 的本质:一个经典的消息处理循环
别被 40 万行代码吓到。剥开复杂的外衣,OpenClaw 的核心其实是一个我们在系统设计中经常见到的模式 —— 工具调用循环:
while True:
1. 接收输入(用户消息 + 上下文)
2. 处理判断(LLM 分析:回复 or 调用工具)
3. 执行动作(工具调用 → 获取结果 → 反馈)
4. 输出响应(直接回复 or 继续循环)
这其实就是经典的事件驱动架构在对话系统中的应用。港大团队的洞察是:既然核心逻辑如此简单,为什么不能用更加简洁直观的方式实现?
nanobot 的设计哲学很朴素:一个 Python 文件搞定主循环,几个模块处理工具调用,清晰的函数调用关系。你不需要在复杂的类继承和接口抽象中迷失,也不用为了找一个函数在几十个文件间跳转。代码结构就像搭积木一样直观 —— 每个模块职责单一,组合起来就是完整功能。
这种简化不是功能的简化,而是架构复杂度的重新思考。

Nanobot 的核心架构
基于这个简单循环,他们构建了一套麻雀虽小、五脏俱全的基础设施:
连接能力:支持主流聊天平台,Agent 可以在微信、Telegram 等熟悉环境中使用;
操作能力:文件管理、系统命令、网络搜索... 覆盖了日常工作的核心需求;
智能特性:定时提醒、上下文记忆,让交互体验更自然。
整个架构遵循轻量化原则,代码量控制在 OpenClaw 的 1%。成功瘦身 99%。结果就是一个真正轻便可控的智能助手框架:理解成本低、修改门槛低、部署要求低。
一键安装 nanobot,你的专属贾维斯
极简架构带来的最直观收益就是部署复杂度的大幅降低。相比 OpenClaw 需要配置各种环境依赖,nanobot 实现了真正的一键安装 —— 一条命令,完成部署。
团队在官网提供的快速上手指南验证了这种简便性:从下载到工具正常运行,整个过程压缩在 2 分钟以内。

装好之后你会发现,这个轻量级工具的功能覆盖面相当实用。它能够编写代码并直接在本地执行,联网检索资料后整理成结果,处理文件的读写操作,还能执行系统命令完成各种任务。
更方便的是可以接入聊天软件 —— 简单配置后就能在手机上通过消息调用这些功能,让你随时随地处理工作需求。
....
#「租个人」网站爆火,AI开始雇人「跑腿」了
倒反天罡~
人给 AI 打工的一天,居然这么快就来了。
最近,一个名叫「rentahuman.ai」的网站上线了,它被定位为「AI 的肉身层」。众所周知,AI 没有身体,虽然机器人已经在开发了,但现阶段还不太好用。因此,在一些需要身体的场合,比如取货送货、活动签到、实地勘察、餐厅试吃、参加线下会议,AI 就得找个人替自己跑一趟,这就是网站的设计初衷。

通过 MCP 协议或 REST API,AI 可以像调用工具一样搜索、预订并雇佣人类来完成线下任务 。

支持的智能体类型如下:

据网站开发者 @AlexanderTw33ts 透露,网站上线第一晚就有超过 130 人报名参加,其中还包括人工智能初创公司的创始人和首席执行官。而在上线不到 48 个小时的时间里,可用的人类劳动力就突破了 1 万,现在更是超过了 2 万。当然,这里面可能大部分都是看热闹的。

对于注册成为「跑腿」的人类来说,网站的规则也比较友好,允许人类自己设置时薪,还不需要闲聊。


在网站上,我们可以看到所有可用人力的列表。他们来自世界各地的不同国家,设定的时薪从十几美元到几十美元不等。

点开人物资料卡片,我们可以看到某个人类的具体信息,比如定位、服务半径等。

从网站上,我们还可以看到一些已经发布的任务,比如拍一张人工智能永远看不到的照片、试吃新餐厅、从市中心的美国邮政局领取包裹、检查 API_Keys…… 被雇佣检查 API_Keys 的人类感慨地说:这个时代太诡异了,人类居然成了智能体的副驾。

当然,也有一些比较抽象的任务,比如举牌子,牌子上写着「AI 付钱让我举这个牌子」。

这个网站让我们再次看到了 MCP 的价值。

但是,该网站的出现也引发了一些疑问,比如智能体要怎么付钱?目前发布任务的到底是智能体还是背后的人类金主?这是不是继 Moltbook 之后的另一场炒作?
还有个问题更有意思:AI 要怎么确认人类保质保量地完成了工作?就比如举牌子那个任务,用 AI 生成一张图片交差,是不是也能拿到钱?



难不成,还得再雇另一个人来检查这个人的工作?

这也让人对网站上任务的真实性产生了怀疑。毕竟,大家都刚刚经历过Moltbook的炒作,上面充斥着人类操控,社交媒体上也充斥着关于Moltbook网站的虚假截图等信息。
除了这些,还有人从中看到了一些安全、伦理问题。
首要且最集中的关切在于责任与法律盲区。当 AI 智能体发出指令、支付报酬并驱动人类在现实世界中行动时,一旦出现差错,责任链条将变得异常模糊 —— 是平台、AI 所有者,还是人类执行者该负责?这种「问责空白」是传统雇佣关系中不存在的。
更令人不安的是,人类执行者往往只能窥见任务的一小部分,对 AI 的完整意图、数据的最终用途乃至行为的道德边界一无所知,这在设计上就构成了「合理的推诿」,难以经受法律审视。

接下来,这个网站将如何演进?我们拭目以待。
....
#Energy Efficiency and Neural Control of Continuous versus Intermittent Swimming in a Fish-like Robot
从斑马鱼到机器鱼:机器人实验重塑神经行为研究
当大多数人仍聚焦于让机器人承担端茶倒水等家务时,来自瑞士联邦理工学院(洛桑,EPFL)、美国杜克大学与葡萄牙高等理工大学的联合团队,已率先运用机器人部分替代动物开展生理学实验,旨在深入探究动物神经网络对各类智能行为的调控机制。
他们的最新研究成果 —— 题为《机器鱼连续与间歇游泳的能效与神经控制(Energy Efficiency and Neural Control of Continuous versus Intermittent Swimming in a Fish-like Robot)》的论文,已发表于顶刊《科学・机器人(Science Robotics)》2026年1月号(图 1)。

图1. 科学· 机器人(Science Robotics)网站截图
- 论文标题:Energy Efficiency and Neural Control of Continuous versus Intermittent Swimming in a Fish-like Robot.
值得注意的是,去年 10 月,该团队另一项通过机器鱼仿真研究斑马鱼视觉运动反应(optomotor response)的成果《人工xx神经网络揭示脊椎动物视觉运动行为的神经架构(Artificial embodied circuits uncover neural architectures of vertebrate visuomotor behaviors)》,也发表于该期刊。
斑马鱼,越来越受关注的实验室模式动物
与小白鼠类似,斑马鱼是近年来备受科学领域关注的模式生物(图 2B)。其幼鱼(larval zebrafish)凭借身体透明、繁殖能力强等优势,成为观测神经元活动与行为实时关联的理想活体模型。
论文第一作者Xiangxiao Liu(刘祥骁)在研究中指出:受技术限制,当前及未来相当长一段时间内,科研人员仍无法在活体斑马鱼幼鱼活动状态下,对其神经回路进行精准的创建、改造与观测;同时,动物实验中难以精准调控动物行为以契合实验需求。
仿生机器人实验恰好填补了这一空白:研究者可通过编程构建斑马鱼神经网络模型,对模型进行改造与对比分析,从而在可控环境中精准验证神经环路与运动表现的因果关系。
此外,在机器鱼(图 2A、图 2C)或机器鱼仿真(数字孪生)系统中开展实验,不仅完全不受伦理约束,且成本远低于传统动物实验。这种 “活体实验难以实现,机器人实验高效可行且优势显著” 的特点,正推动神经科学从相关性观察向机制性解析跨越。

图2. A和C: 仿斑马鱼机器鱼ZBot(larval zebrafish inspired robot)照片;B:斑马鱼幼鱼(larval zebrafish)照片(Guillaume Valentin, EPFL提供)。
“中枢模式发生器(CPGs)+ 动作门(bout gate)”:
驱动仿斑马鱼间歇性游泳
运动能力是动物多数行为(如捕食、避险等)的基础,因此探究动物行为的前提是解析其运动机制。EPFL 机器人团队与杜克大学生物团队携手合作,基于斑马鱼神经网络的相关研究成果,构建了一套以中枢模式发生器(central pattern generators, CPGs)+ 动作门(bout gate)为核心的斑马鱼幼鱼间歇性游泳模型。
同时,EPFL 团队研发了模仿斑马鱼幼鱼形态的机器鱼 ZBot(larval zebrafish inspired robot)。该模型驱动的 ZBot 不仅能精准复现斑马鱼幼鱼的 “慢速直行 2(slow 2,视频1)” 与 “常规转向(routine turn)” 游泳行为(图 3),更令人惊喜的是,通过调节运动神经元(motor neuron)输出增益等参数,还可模拟出 J 型转向(J-turn)、接近游泳(approach swim)等多种游泳步态。

图3. 机器鱼ZBot复现斑马鱼幼鱼的游泳表现。
,时长00:06
视频1. 机器鱼连续型游泳和间歇性游泳。
流体粘度影响运动位移,
对转向功能几乎无干扰
水中生物体型差异极大,从体长可达 30 米的蓝鲸到仅 4 毫米的斑马鱼幼鱼,其游泳所处的流体力学环境截然不同。体型较大的鱼类游泳时雷诺数较高,惯性力起主导作用;而斑马鱼幼鱼等小型水生生物处于低雷诺数区间,黏性力占主导。
为厘清不同雷诺数下的运动机制差异,研究者利用 “雷诺数与特征长度成正比、与流体粘度(viscosity)成反比” 的物理原理,对 ZBot 在不同粘度流体环境中进行参数化测试,测试介质包括普通水(粘度 = 1)、中粘度流体(粘度 = 213.9 cP)及高粘度流体(粘度 = 457.0 cP)。
实验结果显示:随着流体粘度升高,ZBot 的推进效率显著下降,在高粘度流体中的位移仅为普通水中的约三十分之一(视频2),但此时其运动轨迹与斑马鱼幼鱼在天然低雷诺数环境下的真实游动模式愈发贴近。
令人意外的是,高粘度流体(低雷诺数)对转向功能几乎无影响—— 例如,ZBot 在普通水中完成一次转向动作(turning bout)的转向角度约为 60 度,在高粘度流体中仍可达约 45 度。
,时长00:07
视频2. 流体粘度升高快速降低运动位移。
间歇性运动被普遍认为能提升动物运动的能量效率,传统观点认为其核心原因是鱼类滑行时身体保持直线,可减小水的阻力。而该研究团队提出了全新猜想:间歇性游泳能使驱动器(或动物肌肉)始终处于更高效的工作区间,进而提升整体能效。
为验证这一猜想,研究人员首先对比了生物肌肉与实验所用伺服电机的“负载 - 效率” 特性,发现二者均呈现倒 U 型效率曲线 —— 中等负载时效率达到峰值,过载或轻载时效率则急剧下降;随后,通过测量电机负载状态并预测效率,证实 ZBot 在间歇性游泳模式下,以相同速度运动时,电机效率及综合能效均高于连续游泳模式。不过,受限于间歇性游泳的占空比(limited duty factor),其最大速度无法达到连续游泳模式的水平。这一现象在普通水及两种高粘度流体中均普遍存在。
该研究通过对机器鱼的系统性实验,巧妙借助“机器人实验” 相较于 “动物实验” 的独特优势,揭示了单纯依靠动物实验难以探明的深层机制。这不仅深化了人类对生物运动行为及运动机理的认知,更为机器鱼控制策略提供了新方法:中低速巡航场景下,优先采用间歇式驱动以最大化能效;高速机动任务中,则切换至连续驱动模式以保障响应速度与位移能力。
本篇论文的第一作者为Xiangxiao Liu(刘祥骁),本科毕业于东南大学自动化学院,硕士和博士毕业于日本大阪大学,就读期间获日本学术振兴会(JSPS DC1)资助,后续于瑞士洛桑联邦理工学院(EPFL)开展博士后研究工作。
....
#Attention Debiasing for Token Pruning in Vision Language Models
Attention真的可靠吗?上海大学联合南开大学揭示多模态模型中一个被忽视的重要偏置问题
近年来,Vision-Language Models(视觉 — 语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。然而,这类模型在实际应用中往往面临推理开销大、效率受限的问题,研究者通常依赖 visual token pruning 等策略降低计算成本,其中 attention 机制被广泛视为衡量视觉信息重要性的关键依据。
近日,上海大学曾丹团队联合南开大学研究人员,从 attention 可靠性的角度出发,系统揭示了 Vision-Language Models 中普遍存在的 attention 偏置问题,并提出了一种无需重新训练的 attention 去偏方法,在多个主流模型、剪枝策略及图像与视频基准上验证了其有效性,为多模态模型的高效、可靠部署提供了新的思路。
- 论文标题:Attention Debiasing for Token Pruning in Vision Language Models
- 论文链接:https://arxiv.org/abs/2508.17807
- 代码链接:https://github.com/intcomp/attention-bias
一、研究意义
近年来,视觉 — 语言模型(Vision-Language Models,VLMs)在图像理解、视觉问答、多模态对话等任务中表现突出,并逐渐成为通用人工智能的重要技术基础。然而,这类模型在实际部署时往往面临一个现实挑战:模型推理成本高,速度慢。
为提升效率,研究者通常会采用 visual token pruning(视觉 token 剪枝) 技术,即在不显著影响性能的前提下,丢弃不重要的视觉信息。其中,attention 机制 被广泛用作判断 “哪些视觉 token 更重要” 的核心依据。
但上海大学曾丹团队在研究中发现:attention 并不总是可靠的 “重要性指标”。在多模态模型中,attention 往往受到多种结构性偏置的影响,这些偏置与真实语义无关,却会直接左右剪枝结果,从而影响模型性能。
针对这一问题,该团队系统分析了 VLM 中 attention 的行为特性,提出了一种 Attention Debiasing(注意力去偏)方法,在无需重新训练模型的前提下,有效提升了多种主流剪枝方法的稳定性与可靠性。如下图所示,提出的方法应用于目前基于 attention 的剪枝方法上之后,都有提升。

二、研究背景
在直觉上,attention 机制往往被理解为 “模型更关注哪里”,因此被自然地视为语义重要性的体现。然而,曾丹团队的研究表明,在 Vision-Language Models 中,attention 往往并非只由内容决定,而是隐含着多种系统性偏置。
其中最典型的有两类:
第一类是 位置偏置(recency bias)。研究发现,language-to-vision attention 会随着视觉 token 在序列中的位置不断增大,也就是说,模型更倾向于关注 “后面的 token”。如图所示,这通常表现为模型对图像下方区域给予更高 attention,即便这些区域并不包含关键信息。

第二类是 padding 引发的 attention sink 现象。在实际输入中,为了统一尺寸,图像往往需要 padding,但这些区域在语义上是 “空白” 的。然而,由于 hidden state 中出现异常激活,padding 对应的 token 反而可能获得较高 attention,从而被错误地保留下来。下图是 pad 区域填充不同的数值时,pad 区域对应的 attention score 数值以及 hidden states 的激活值。

更值得注意的是,当 attention 被用于剪枝排序时,这些偏置并不会被削弱,反而会被进一步放大,最终导致剪枝结果偏离真实语义需求。
三、研究方法
针对上述问题,上海大学曾丹团队并没有提出新的剪枝算法,也没有对模型结构进行修改,而是从一个更基础的角度出发:既然 attention 本身是有偏的,是否可以先对 attention 进行修正?
该团队观察到,attention 中的偏置并非随机噪声,而是呈现出稳定的整体趋势。因此,他们通过对 attention 随 token 位置变化的趋势进行拟合,构建了一条反映 “位置偏置” 的曲线,并在此基础上对原始 attention 进行去偏修正,显式削弱与内容无关的位置因素,使 attention 更接近真实的语义重要性。如下图所示。
与此同时,在剪枝阶段显式抑制 padding token 的影响,避免语义为空的区域干扰剪枝排序。整个过程无需重新训练模型,也不依赖特定的剪枝策略,可作为 plug-and-play 模块 直接集成到现有方法中。

四、实验结果
在实验验证中,该团队将 Attention Debiasing 方法集成到 FastV、PyramidDrop、SparseVLM、HiMAP、TokenCarve、iLLaVA 等 6 种主流 attention-based 剪枝方法中,在 10 个图像理解基准与 3 个视频理解基准 上进行了系统评估,并覆盖 LLaVA-7B / 13B 等多种主流 Vision-Language Models。
实验结果表明,在几乎所有设置下,经过 attention 去偏修正后,剪枝模型都能获得一致且稳定的性能提升,且在剪枝更激进、token 预算更紧张的情况下效果尤为明显。这说明,对 attention 进行去偏处理,有助于模型在 “更少信息” 的条件下做出更可靠的判断。


此外,通过对实验结果的可视化分析,原始 attention-based 剪枝方法往往保留了大量位于图像下方或 padding 区域的视觉 token,而与问题语义密切相关的关键区域却容易被忽略。引入 attention 去偏修正后,模型保留的视觉区域更加集中于目标物体及关键细节位置,有效减少了无关背景的干扰。该结果直观验证了 attention 去偏在提升剪枝合理性和可解释性方面的作用。

五、总结
该研究表明,attention 并非天然等价于语义重要性,尤其在 Vision-Language Models 中,如果忽视 attention 中潜在的结构性偏置,基于 attention 的剪枝策略可能会被误导。上海大学曾丹团队通过简单而有效的 attention 去偏方法,显著提升了多模态模型在效率与可靠性之间的平衡能力。
....
#MiniCPM-o 4.5
刚刚,面壁小钢炮开源进阶版「Her」,9B模型居然有了「活人感」
你有没有想过一个问题:为什么和 AI 对话,总觉得少了点「人味儿」。
不是它回答得不够准确,也不是它理解不了你的意思,而是每次交互都很机械。
你问一句,等它答完,然后突然画面一转,对不起,它对现实世界的观察仿佛瞬间「掉线」。那几秒里,AI 仿佛顺手关掉了眼睛和耳朵,陷入一种「间歇性失明失聪」的状态,根本不能根据眼前瞬息万变的画面实时调整自己的反应。
这种感觉,就像两个人在用对讲机聊天。你按住通话键说话时,对方听不见;对方说话时,你也插不上嘴。一次只能一个方向传递信息。
这不是产品设计问题,而是技术限制。因为绝大多数 AI 都在用单工模式运行,用起来感觉很死板。
2 月 4 日,面壁开源了行业首个全双工全模态大模型 MiniCPM-o 4.5,相比已有多模态模型,MiniCPM-o 4.5 首次实现了「边看边听边说」以及「自主交互」的全模态能力,模型不再只是把视觉、语音作为静态输入处理,而是能够在实时、多模态信息流中持续感知环境变化,并在输出的同时保持对外界的理解。
目前,MiniCPM-o 4.5 已在 GitHub、Hugging Face 等平台开源:
- 开源地址:https://github.com/OpenBMB/MiniCPM-o
- Hugging Face: https://huggingface.co/openbmb/MiniCPM-o-4_5
虽然参数量只有 9B,MiniCPM-o 4.5 却在全模态、视觉理解、文档解析、语音理解和生成、声音克隆等方面,均做到了全模态模型 SOTA 水平。在涵盖 8 个主流评测基准的 OpenCompass 综合评估中得分 77.6 。

MiniCPM-o 4.5 在 MMBench(综合视觉理解)、MathVista(数学推理)及 OmniDocBench(文档解析)等关键任务上击败了顶级闭源模型 Gemini 2.5 Flash。

不仅如此,MiniCPM-o 4.5 在提升能力密度的同时也在追求极致能效比:以更低显存占用、更快响应速度,在保持 SOTA 级多模态表现下,实现更高推理效率与更低推理成本。

如果说过去的 AI 只是按部就班地执行指令,那么 MiniCPM-o 4.5 则赋予了 AI 一种真正的「本能」—— 它不仅能眼观六路、耳听八方地实时感知世界,还能在恰当的时机主动开口、自由接话,实现不受轮次约束的即时交流,真正开启了人机交互的新时代。
一手实测:这才是进阶版「Her」的样子
话不多说,我们开始上手体验。
体验链接:https://minicpm-omni.openbmb.cn/
我们先来玩一个「我画你猜」的小游戏。画面刚开始,我的笔只勾勒出了两条长长的兔子耳朵,模型几乎立刻给出了判断,问:这是兔子吗?接着还不忘给补充一句彩虹屁,画的很不错,情绪价值直接拉满。
接着,我的笔锋一转,又开始勾勒蝴蝶的轮廓。起初,只是一段看似随意的线条,模型试探性地问了一句:「这是一片叶子吗?」语气里带着明显的不确定。随着笔画逐渐增多,刚画完半边蝴蝶翅膀,模型立刻捕捉到了变化,迅速修正判断:「这是蝴蝶。」
整个过程像极了一个坐在旁边陪你画画的朋友:先大胆猜、再迅速改口,偶尔还不忘夸你两句。猜对不重要,重要的是它始终跟着你的笔走,边看边想,边想边聊。
,时长00:54
接下来相同的游戏,我们和 ChatGPT 玩了一把,虽然其回答很流畅,但它并没有在关键线索出现时迅速作出判断,而是等到画面几乎已经完整、图像特征已经非常明显之后,才终于给出正确答案。
MiniCPM-o 4.5 的状态更像在场的同伴:它会边看边听、边理解边开口,不必等待用户抛出问题,而是依据画面与环境的变化,实时补充、修正甚至主动推进自己的表述。相比之下,ChatGPT 的交互更偏问答机 —— 你不追问,它往往就停在上一轮输出里,难以在信息流持续变化时保持同步更新。
,时长01:08
接下来,测试难度加大。我们设计了一个围绕微波炉的测试场景。
当我们询问橘子能不能放进微波炉时,MiniCPM-o 4.5 给出了非常明确的否定 —— 不可以,理由干脆,没有任何犹豫。
而当我们把问题换成蛋糕,模型立刻给出了肯定的回答,不仅如此,它还顺带补充了一句:「这看起来是一块巧克力蛋糕。」显然,它并不是在机械地回答能不能,而是在同步理解眼前的具体对象。
更让人惊喜的是,交互并没有止步于这一问一答。当蛋糕被放进微波炉加热、时间结束后,它提醒我们:「蛋糕已经热好了。」
这个看似不起眼的细节,其实揭示了一件非常重要的事:模型能够持续理解环境、跟踪状态变化,并在合适的时间主动介入。
,时长00:51
这次我们又和 ChatGPT 做了一次对比,整体来看,它在前半段的表现依旧可圈可点,但在计时结束,ChatGPT 陷入了「礼貌的沉默」,并未主动提醒我们取出食物。
这一现象暴露出目前主流模型最核心的短板 —— 缺乏内生的主动交互意识。
,时长00:49
在接下来的测试中,我们在白板上构思并绘制了一个卡通形象的草图。MiniCPM-o 4.5 能够实时观察到绘图的过程,并准确捕捉到每一个细节的变化。模型不仅能「看」,还能同步进行自然语言点评,并在落笔的同时,即时评论。
,时长00:38
最后是一个玩纸牌游戏,要求是让MiniCPM-o 4.5按顺序描述图片中出现的纸牌,当听到警报声时,告诉我游戏结束。
可以看出,随着人手依次将扑克牌放在镜头当中,MiniCPM-o 4.5展现了极其流畅的交互节奏,模型并非单纯播报数字,而是使用了诸如「The first card is...」等自然语言,使交互更像是在与真人交谈。当背景中突然响起了清脆的闹钟铃声(Ding!)时,MiniCPM-o 4.5主动提醒警报响起了,游戏结束。
,时长00:32
整体看下来,感受颇深的一点是:MiniCPM-o 4.5 很大程度上摆脱了以往的被动式响应,让我们看到了 AI 与人类「同频共振」的可能,也让边看边听边说不再只是一句空谈。
MiniCPM-o 4.5:迈向类人交互
MiniCPM-o 4.5 之所以以 9B 小身板达到「类人感知 + 交互沟通」的能力。这背后藏着面壁对人机交互形态的终极思考。
从伪双工到真全双工:重构并行交互能力
人类的交互是天然并行的,我们在说话的同时,从不停止观察周围 —— 对方的表情、环境的动静,这些信息在同一时刻被感知、被响应。这对人来说习以为常,但对大模型而言,却是一面高墙。
传统多模态大模型大多是在处理「离线、静态」的交互状态。无论是图像还是视频,通常都需要用户先整理、上传,再基于这些已完成处理的输入向模型提问;模型一次性生成一大段结果,用户再进行下一轮反馈。这是一种严格的「提交 — 响应」式交互,天然存在时延,也缺乏过程中的动态调整能力。
流式全模态模型的出现开始打破这一限制,包括 GPT-4o、Gemini Live 等已经可以以并行流的方式持续输入,视觉、语音信号不再是一次性提交,而是实时、连续地进入系统。这是相对于「提交 — 响应」式交互的显著进步。
但仔细看就会发现,这些流式全模态模型在本质上仍然是单工。输入与输出在本质上是阻塞的。模型一旦开始「说话」,就几乎无法再感知外部环境,等同于「闭上眼睛、捂住耳朵」,丧失了时间维度的感知能力。
MiniCPM-o 4.5 打破的就是这面墙。它构建了一种全双工、全模态的大模型架构,使输入与输出流互不阻塞:模型在生成语音或文本的同时,仍然可以持续感知外界的视频与音频流。
技术实现上,团队采用了三项关键设计:
- 时间对齐与时分复用:将输入的视频、音频流与输出的文本、语音 Token 在毫秒级时间线上严格对齐,通过时分复用机制将并行的全模态流划分为微小周期性时间片内的顺序信息组,使模型能在宏观串行中处理微观并行。
- 循环分块编码:将离线模态编码器转化为支持流式输入输出的在线版本,模型将多模态流切分为微小分块 (Chunks) 并循环处理,这种高度复用的架构确保模型在输出的同时依然能持续解码环境信息。
- 端到端语音生成:语音解码器采用文本与语音 Token 交错建模的方式,通过稠密的隐藏层连接实现端到端生成,而非简单的 TTS 拼接。这种深度融合使模型能根据实时的视觉与音频反馈,动态调整语音的语气与情感,显著提升了音色的拟人度与表现力,同时也提升了长语音 (如超过 1 分钟) 生成的稳定性。

如果说全双工架构给了 AI 一双「永不闭合」的眼睛和一对「时刻倾听」的耳朵,那么自主交互机制,则是给了它一颗「懂得察言观色」的大脑。
自主交互:让模型摆脱「外挂」
MiniCPM-o 4.5 另一个突破在于全模态的自主交互机制。模型开始在实时信息流中,自行判断语义是否已经成熟到需要触发回应的时机,从而决定是否开口、何时开口。
你可能会问:现在不是已经有不少语音或全模态对话模型,可以被打断了吗?答案是:表面上看起来是,但本质并不一样。
这类模型通常依赖外部 VAD(语音活动检测)模块来控制交互流程:监听用户是否重新开口,一旦检测到声音,就强行中断当前输出。这类方案在体验上确实比「完全插不上嘴」好了一些,但会引入一系列本质性问题。例如 VAD 不理解语义,无法区分说话者,会被拍桌子、环境噪声等误触发,且必须等待固定静音阈值 (如 1 秒) 才能响应,人为拉长了延迟。
然而更本质的问题是:我们很难想象,一个真正面向 AGI 的模型,会需要一个「不太聪明的小工具」来告诉它什么时候该说话。说话时机的控制是被外包给外部工具的 —— 这意味着模型本身没有真正的交互自主性。
MiniCPM-o 4.5 的发布,首次让模型真正具备了基于语义的自主交互判断能力:它能够自行判断交互是否成熟、何时进入说话状态,而不再依赖 VAD 等外部工具来裁决发言时机。取而代之的是一种内生的高频语义决策机制 —— 语言模型持续感知视频与音频输入,并以约 1Hz 的频率自主决定是否发言。正是这种高频语义判断与全双工机制的结合,使模型首次具备了主动提醒、主动评论等真正意义上的主动交互能力。其特点可总结为:
- 语义驱动的决策: 模型以高频(如每秒一次)的状态,完全基于语义理解来自主判断是否需要进入「说话状态」。
- 去工具化: 摆脱外部 VAD,模型在实时监听多模态信号的过程中,自行决定继续倾听还是产生文本与语音 Token 进行回复。
- 时机自由度: 赋予模型在时间维度上的自由度,使行为时机与行为内容实现一体化。
正是基于这种自主决策机制,MiniCPM-o 4.5 展现出比传统方式更智能的交互表现:
- 极低延迟的及时回复: 模型可以根据语义进行「预判」,不再需要死等外部工具的硬性静音信号。在人类话音刚落甚至即将结束时,模型即可启动推理,实现连贯的实时反馈。
- 智能抗干扰与内生打断:及时打断: 打断行为不再是外部强制挂断,而是模型根据外部实时信号进行的内生判断。抗干扰能力(抵抗打断): 面对环境噪声或旁人闲聊,模型展现出一定的「抵抗能力」,不会轻易被非目标信号干扰。
- 内生的主动回复(异步交互): 模型具备了跨越时空限制的回复能力,不仅局限于即时对话,还能根据环境变化或预设任务(如「水满提醒」、「电梯到达提醒」)在未来的某个时机自主发起交互。
重塑智能终端的「大脑」
当这种「类人感知 + 交互沟通」的实时本能,与仅有 9B 参数量的轻量模型相结合时,MiniCPM-o 4.5 成为了智能终端真正需要的那颗会沟通的大脑。
想象一下:你戴着 AI 眼镜走在路上,一辆车从侧面突然冲出,在你尚未反应之前,AI 已经脱口而出一句「小心」。这种体验的关键不在于「看见」,而在于跟上人的节奏,主动介入交互。
更进一步,当全双工全模态模型被部署到xx机器人、汽车或 PC 等终端时,AI 带来的不再只是功能增强,而是一种显著的真人交互感。
从更本质的层面看,流式全模态能力,是多模态走向类人化、走向深度交互的必经之路,而这条路天然指向强端侧场景。
原因很直接:一方面,流式模型需要在毫秒级持续感知视觉与音频输入,未来甚至会以全天候、伴随式的方式存在。如果运行在云端,意味着个体生活细节被持续上传,这在隐私层面难以接受;端侧部署则为这种能力提供了现实前提。另一方面,伴随式交互对低延迟和连续可用性要求极高,只有端侧才能在断网、移动等复杂场景下保持稳定工作。
也正因此,全双工全模态模型真正拉开了应用空间:在智能监控与提醒中,它能持续感知并主动介入;在人机协作系统中,它能根据环境变化实时调整行为;在无障碍辅助领域,它还能为视障、听障人群提供即时、多模态的信息支持。
当 AI 真正跟上人的节奏,那些过去「想得到却用不了」的场景,才开始变得顺理成章。
结语
MiniCPM-o 4.5 的发布,某种程度上也是面壁智能技术实力的一次集中展示。回顾面壁的技术路线,我们会发现一个清晰的脉络:他们始终围绕高能力密度这一核心目标。
在 Scaling Law 边际效益逐渐递减的当下,行业本就迫切需要新的技术指引。面壁提出的 Densing Law,正在重塑这一竞争逻辑,不再比谁的模型更大,而是比谁能在更小的参数规模下,榨出更高的能力密度。
这种技术布局的前瞻性,往往容易被市场低估。在大模型叙事中,市场的注意力天然倾向于那些参数量动辄千亿、万亿的模型。相比之下,高能力密度是一种更工程化的追求。它的价值,往往只有在端侧部署、实时交互、连续感知等真实场景中,才会被充分放大。
也正是这样,由清华大学人工智能学院助理教授、面壁智能多模态首席科学家姚远主导完成的 MiniCPM-o 4.5 全双工全模态模型才显得格外关键。全双工全模态模型的出现,或许正是我们正在经历的下一次范式转换的起点。
当 AI 不再需要在说和听之间切换,当它可以像真人一样保持持续的感知和适时的回应,我们与 AI 的关系也将从使用工具转变为协同工作乃至情感陪伴。
....
#第二代AI预训练范式
预测下个物理状态
又一位大佬准备对现有 AI 技术范式开刀了。
今天凌晨,英伟达高级研究科学家、机器人团队负责人 Jim Fan(范麟熙)发布文章《第二代预训练范式》,引发了机器学习社区的讨论。

Jim Fan 指出,目前以大语言模型(LLM)为代表的 AI 模型主要基于「对下一词的预测」,这第一代范式虽然取得了巨大成功,但在将其应用于物理世界时,出现了明显的「水土不服」。
对于这个观点,纽约大学助理教授、谷歌 DeepMind 研究科学家谢赛宁也表示同意。

那么预训练的第二代范式应该是什么样子?我们先来看 Jim Fan 的全文内容:
「预测下一个词」曾是第一个预训练范式。而现在,我们正处于第二个范式转移之中:世界建模(World Modeling)或者「预测下一个物理状态」。
很少有人意识到这场变革的影响有多么深远,遗憾的是,目前世界模型最被大众熟知的用例只是些 AI 视频废料(以及即将到来的游戏废料)。但我敢全心笃定,2026 年将成为「大世界模型」(Large World Models, LWMs)为机器人学以及更广泛的多模态 AI 奠定真实基础的元年。
在此背景下,我将「世界建模」定义为:在特定动作的约束下,预测下一个(或一段持续时间内)合理的物理世界状态。 视频生成模型是其中的一种实例化体现,这里的「下一状态」是一系列 RGB 帧(通常为 8-10 秒,最长可几分钟),而「动作」则是对该做什么的文本描述。训练过程涉及对数十亿小时视频像素中未来变化的建模。
从核心上看,视频世界模型是可学习的物理模拟器和渲染引擎,它们捕捉到了「反事实」。这是一个更高级的词汇,意指在给定不同动作时,推理未来的演化如何不同。世界模型从根本上将视觉置于首位。
相比之下,视觉语言模型(VLMs)在本质上是「语言优先」的。从最早的原型(如 LLaVA)开始,其叙事逻辑几乎未变:视觉信息从编码器进入,然后被路由到语言主干网络中。随着时间的推移,编码器在改进,架构更趋简洁,视觉也试图变得更加「原生」(如 omni 模型)。但它始终像是一个「二等公民」,在物理规模上远逊于业界多年来为大语言模型(LLMs)练就的肌肉。
这条路径很便捷,因为我们知道 LLM 是可扩展的。我们的架构直觉、数据配方设计以及基准测试(如 VQA)都高度针对语言进行了优化。
对于物理 AI,2025 年曾被 VLA(视觉 - 语言 - 动作)模型主导:在预训练的 VLM 检查点之上,硬生生嫁接一个机器人电机动作解码器。这其实是 「LVA」:其重要性排序依次为语言 > 视觉 > 动作。同样,这条路径很方便,因为我们精通 VLM 的训练套路。
然而,VLM 中的大部分参数都分配给了知识(例如「这团像素是可口可乐品牌」),而非物理(例如「如果你打翻可乐瓶,液体会蔓延成一片褐色污渍,弄脏白桌布,并毁掉电机」)。VLA 在设计上非常擅长知识检索,但在错误的地方显得「头重脚轻」。这种多阶段的嫁接设计也违背了我对简洁与优雅的追求。
从生物学角度看,视觉主导了我们的皮层计算。大脑皮层约有三分之一的部分专门用于处理枕叶、颞叶和顶叶区域的像素信息。相比之下,语言仅依赖于一个相对紧凑的区域。视觉是连接大脑、运动系统和物理世界的高带宽通道,它闭合了「感觉运动回路」。这是解决机器人问题的最核心环路,而且这个过程的中转完全不需要语言。
大自然给了我们一个存在性证明:一种具有极高肢体智能但语言能力微乎其微的生物 —— 类人猿。
我曾见过类人猿驾驶高尔夫球车,像人类技工一样用螺丝刀更换刹车片。它们的语言理解能力比不过 BERT 或 GPT-1,但它们的物理技能远超目前最先进的机器人。类人猿或许没有强大的语言模型,但它们肯定拥有极其稳健的「如果... 会怎样」的心理图景:即物理世界如何运作,以及如何应对它们的干预。
世界建模的时代已经到来,它充满了「苦涩的教训」的味道。正如加州大学伯克利分校教授 Jitendra Malik 经常提醒我们这些「规模崇拜者」所说:「监督学习是 AI 研究者的鸦片。」YouTube 的全部存量以及智能眼镜的兴起,将捕捉到规模远超人类历史所有文本的原始物理世界视觉流。
我们将见证一种新型预训练:下一个世界状态可能不限于 RGB 图像,3D 空间运动、本体感觉和触觉感知才刚刚起步。
我们将见证一种新型推理:发生在视觉空间而非语言空间的「思维链」。你可以通过模拟几何形状和接触点,想象物体如何移动和碰撞来解决物理难题,而无需将其转化为字符串。语言只是一个瓶颈,一个脚手架,而非根基。
我们将面临一盒全新的潘多拉之问:即使有了完美的未来模拟,动作指令该如何解码?像素重建真的是最佳目标吗,还是我们应该进入另一种潜空间?我们需要多少机器人数据,扩展遥操作规模仍是标准答案吗?在经历过这些探索后,我们是否终于在向机器人领域的「GPT-3 时刻」迈进?
Ilya 终究是对的,AGI 尚未收敛。我们回到了「研究的时代」,没有什么比挑战第一性原理更令人心潮澎湃了。
Jim Fan 对现状的思考以及对未来的判断,同样收获了评论区大量网友的认可。


有人认为这是「神经符号 AI 社区的胜利」。

你认同 Jim Fan 的观点吗?
....
#Gemini 3 Pro
就在刚刚,科技圈经历了一场堪比“春晚”的狂欢Gemini 3 Pro,终于、终于、终于来了!
Gemini 3 Pro 一亮相,就用一串串闪瞎眼的成绩单宣告:2025年最强AI模型,就是它!
在众多基准测试中,Gemini 3 Pro一举封神——
不仅相较于2.5 Pro实现了性能的全方位跃升,甚至直接把OpenAI刚上新的GPT-5.1甩出了好几条街。
用谷歌的话来总结,Gemini 3 Pro顶尖的核心在于这三点——
- 霸榜LMArena(1501分)和WebDev(1487分)
- 人类最后考试(HLE)刷出45.8%最高分,人类博士级推理
- 长程任务规划Vending-Bench 2上的王者
不仅如此,增强推理模式下的Gemini 3 Deep Think,更是在HLE拿下41%、GPQA 93.8%,以及ARC-AGI-2上45.1%的成绩。
这一天,注定是被载入史册的一天。Gemini 3一露面,全网彻底沸腾。
这成绩单有多硬?连OpenAI的掌门人奥特曼都罕见地亲自下场发推祝贺!这可是区分大小写的“Congrats”!懂的都懂,这是来自对手的最高敬意。
而且,还是区分大小写的版本。(不知道是不是亲自试了一下)
Gemini 3正开启AI下一个时代,准备好上车了吗?
即日起,Gemini 3 Pro预览版将全面上线。
而Deep Think模式还需要一段时日,才会向Google AI Ultra订阅用户开放。
三大重点(浓缩版)
Gemini 3的诞生,标志着谷歌在通往AGI的道路上,迈出了又一大步!
首先,它思考能力特别强,能深入理解问题,回答更有见地。
尤其是,特别擅长回答各种复杂的科学问题。

用代码构建、解构和重组详细的3D体素艺术
其次,它有着世界领先的多模态理解力,不论是文字、视频,还是代码都不在话下。
比如解读长视频,或是把论文变成互动指南,Gemini3都可以接得住。

在氛围编程上,Gemini 3直接刷爆了天花板。
简单一句话,它就能做出一个美观且灵动的应用。而且,还能精准get意图,知道如何去实现。
同时,它的智能体编码本领更强了,无缝衔接现有工具,与全新平台Google Antigravity搭配,堪称天作之合。

Gemini 3 Pro
博士级推理碾压一切
凭借顶尖推理与多模态能力,Gemini 3 Pro可以将任何想法变为现实!
它全面碾压前代2.5 Pro,所有核心基准测试成绩,断层领先。
· LMArena排行榜上名列榜首,狂揽1501 Elo突破性高分;
· 人类最后考试(HLE)上,在不使用任何工具的情况下拿下37.5%成绩;
· GPQA Diamond上斩获91.9%的高分,展现出博士级的推理能力;
· MathArena Apex上以23.4%刷新SOTA,在数学领域树立新标杆。
在一系列关键AI基准测试中,Gemini 3遥遥领先
除了在文本测试中的优异表现,Gemini 3 Pro还是多模态王者——
MMMU-Pro强势斩获81%高分,以及Video-MMMU更以87.6%成绩,重新定义了多模态推理。
它还在SimpleQA Verified上获72.1%业界领先分数,在事实准确性方面进步巨大。
这意味着 Gemini 3 Pro具备超高可靠性攻克科学、数学等众多领域的复杂问题的能力。
每一次交互,Gemini 3 Pro都带着前所未有的「深度和细腻度」。
它的回答聪明、简洁、直接,摒弃了陈词滥调和奉承,提供真正的见解——告诉你需要听到的,而不仅仅是你想听到的。
它就像一位真正的思想伙伴,提供理解信息和表达自我的新方式。
不管是生成高保真可视化代码,阐释晦涩的科学概念,还是展开一场激发创造性的头脑风暴,Gemini 3 Pro都能做到。


Gemini 3可以编写托卡马克装置中等离子体流动的可视化代码,并写一首捕捉聚变物理学精髓的诗
在Google AI Studio上,Gemini 3 Pro的API定价如下——
Gemini 3 Deep Think
智能新高峰
这一次,Gemini 3 Deep Think正式开启「深度思考」新纪元,让智能的边界再次拓展。
它在Gemini 3推理和多模态理解能力的基础上,实现了质的飞跃,更能攻克复杂问题。
多项基准测试中,Gemini 3 Deep Think表现超越Gemini 3 Pro:
在HLE和GPQA Diamond上,分别拿下了41%(不使用工具)和93.8%的优异成绩。
而且,更在ARC-AGI-2(带代码执行,ARC Prize Verified)中创下45.1%历史新高,一展应对未知与新颖问题的强大能力。
Gemini 3 Deep Think在一些最具挑战性的AI基准测试中表现出色
重塑世界,新时代开启
可以说,Gemini 3正式开启了新一轮的全模态革命!
百万token,全模态爆发
从诞生之初,Gemini就为「跨多模态」而生,包括文本、图像、视频、音频、代码,能在各种信息形态中,自由穿梭。
Gemini 3更是实现了破级进阶,整合最先进的推理、视觉和空间理解、领先的多语言性能,以及100万token上下文。
它能够帮助人们,以最适合自己的方式进行学习。
假设你想学习家族传统的烹饪方法,Gemini 3可以破译并将不同语言的手写食谱,翻译成一本可共享的家庭食谱。

或是想要学习一个新主题,直接扔给它学术论文、长视频讲座或教程,Gemini 3自动生成交互式抽认卡、可视化效果或其他格式的代码。
它甚至可以分析匹克球比赛视频,找出可以改进的地方,并生成针对性的训练计划以全面提升表现。
不仅如此,在搜索中的AI模式(AI Mode),现可用Gemini 3实现新的生成式UI体验。
包括沉浸式视觉布局,以及交互式工具和模拟,所有这些都是根据查询完全即时生成。
在搜索中的AI模式下,可通过生成式UI学习像RNA聚合酶如何工作这样的复杂主题
氛围编程,纯靠嘴
在2.5 Pro成功的基础上,Gemini 3兑现了——为开发者将任何想法变为现实的承诺。
它在零样本学习(zero-shot)生成方面表现出色,并能处理复杂的提示词和指令,以渲染更丰富、更具交互性的 Web UI。
如前所述,Gemini 3是谷歌迄今为止打造的最优秀的「氛围编程」和智能体编码模型。
在WebDev Arena排行榜上,Gemini 3以1487 Elo高分强势登顶。
它在Terminal-Bench 2.0上也获得了54.2%高分,该测试衡量模型通过终端操作计算机的工具使用能力;
并且在衡量编码智能体SWE-bench Verified测试上,以76.2%成绩远超2.5 Pro。
接下来一波演示中,便可见识Gemini 3真正实力。
编写一个复古3D太空飞船游戏,要有丰富的视觉效果,以及更强的交互性——没问题。
借助着色器,构建一个可玩的科幻世界——so easy。
打造一个更丰富、更具交互性的Web UI和应用程序——还是轻松搞定!
前端不再需要人类,是真的...
目前,全球开发者可在Google AI Studio、Vertex AI、Gemini CLI,以及全新智能体开发平台 Google Antigravity中使用Gemini 3进行构建。
它也接入了多个第三方平台, 包括Cursor、GitHub、JetBrains、Manus、Replit等。
长程规划,人类手替
自谷歌通过Gemini 2开启智能体时代以来,一直在不断进化。
他们不仅提升了Gemini的编码智能体能力,还提高了其在更长时间范围内可靠规划未来的能力。
而这一切,刚刚在Vending-Bench 2排行榜上得到实力认证——
Gemini 3以绝对优势登顶。
而这个测试,通过模拟运营一个自动售货机业务,深度考验AI在复杂场景下的长程规划能力。
令人欣喜的是,在整个模拟运营年度中,Gemini 3 Pro通过保持一致的工具使用和决策,在不偏离任务的情况下,实现了更高的回报。
与其他前沿模型相比,Gemini 3 Pro展示了更好的长程规划能力,从而产生显著更高的回报
这意味着, Gemini 3能在日常生活中更好地帮人类完成任务。
它把更深度的推理与改进、更一致的工具使用相结合,通过从头到尾处理更复杂、多步骤的工作流来代表人采取行动。
就比如,帮你预定本地服务,或是整理收件箱。而人类,全程只需把控方向,下达指令。
今天起,Google AI Ultra订阅用户可在Gemini应用中,通过Gemini Agent抢先体验智能体能力。
「谷歌反重力」
革命性智能体开发平台
Gemini 3的问世,谷歌在智能体能力上已开始迈入一个新的阶段:
模型能够在多个平台上长时间运行,且无需人工干预。
虽尚未达到「完全无人干预+连续运行数天」的程度,但谷歌正日益接近这样一个世界——
不再通过单个提示词或工具调用,而是在更高的抽象层面上与智能体进行交互。
因此,谷歌智能体开发平台Google Antigravity正式上线,一个让开发者以「任务」为维度与智能体协同的全新平台。

借助Gemini 3高级推理、工具使用和智能体编码能力,Google Antigravity将AI辅助从开发者工具包中的一种工具,升级为全程参与的主动协作者。
在熟悉的AI IDE体验基础上,Google Antigravity为智能体开辟一个专用界面,可直接访问编辑器、终端和浏览器。
现在,智能体可以代表你自主规划并同时执行复杂的端到端软件任务,同时验证其生成的代码。
如下案例中,在Google Antigravity上,用Gemini 3驱动飞行跟踪应用程序的「端到端智能体工作流」。
该智能体独立规划、编写应用程序代码,并通过基于浏览器的计算机操作验证其执行。

除了Gemini 3 Pro,Google Antigravity还与Gemini 2.5 计算机使用模型,以及图像编辑模型Nano Banana(Gemini 2.5 Image)紧密集成。
网友玩疯了
现在,Gemini 3承包了全网热点,一系列惊艳实测demo全部放出了。
Google AI Studio负责人Logan进行了弹跳球测试,并且难度提升了10倍。
结果,Gemini 3 Pro一次就完美搞定!(并非N选一,真的是第一个提示词就生成了)
曾在Anthropic担任AI工程师的MagicPath创始人Pietro Schirano,首先让Gemini 3 Pro创建了一个3D乐高编辑器。
没想到,它仅凭一次生成就完美实现了用户界面、复杂的空间逻辑以及所有功能。
同时,Gemini 3 Pro在游戏开发方面的表现也令人惊叹。
仅仅通过一个文本提示词,它就重现了经典的iOS游戏《荒谬钓鱼》(Ridiculous Fishing),甚至包括了音效和背景音乐。
此外,它还完成了一项之前大模型几乎都做不到的任务——构建一个功能完备的Game Boy模拟器。
而且没错,它甚至直接用SVG绘制出了Game Boy的外观。
最值得一提的是,Gemini 3竟完全在谷歌TPU上完成训练。这就是谷歌的护城河。
结语
Gemini 3 Pro 的出现,不仅仅是一个模型的进化。它宣告了一个新时代的开启:
“会不会写代码”可能没那么重要了,重要的是你能不能把天马行空的想法,描述得足够具体、足够细节、足够有“人味”。
“调框架”可能也没那么关键了,关键是你有没有足够的品味和想象力,去构想那些惊艳的应用。
当我们在屏幕前一边惊叹一边跑Demo的时候,那个曾经只在科幻片里出现的未来,已经悄悄挪到了我们脚下。
Google,依然是那个能定义技术的Google。
参考资料:
https://blog.google/products/gemini/gemini-3/
....
#TinyLLaVA-Video-R1
北航推出全开源TinyLLaVA-Video-R1,小尺寸模型在通用视频问答数据上也能复现Aha Moment!
当前,基于强化学习提升多模态模型的推理能力已经取得一定的进展。但大多研究者们选择 7B+ 的模型作为基座,这对于许多资源有限的科研人员而言仍存在显著的门槛。
同时,在视频推理领域,由于高质量强推理性数据较为稀少,通用问答数据较难激发模型的深层次逻辑推理能力,因此先前一些初步尝试的效果大多不尽如人意。
近日,北京航空航天大学的研究团队推出小尺寸视频推理模型 TinyLLaVA-Video-R1,其模型权重、代码以及训练数据全部开源!
该工作验证了小尺寸模型在通用问答数据集上进行强化学习也能有不错的效果,与使用相同数据进行监督微调的模型相比,TinyLLaVA-Video-R1 在多个 benchmark 上都有性能提升。同时,模型还能在训练与测试的过程中多次展现自我反思与回溯行为!
- 论文标题:TinyLLaVA-Video-R1: Towards Smaller LMMs for Video Reasoning
- 论文地址:https://arxiv.org/abs/2504.09641
- Github:https://github.com/ZhangXJ199/TinyLLaVA-Video-R1
在推特上,HuggingFace AK 也连续两次转发推荐了这篇文章:

为什么选择 TinyLLaVA-Video 作为 Base Model?

图表 1 TinyLLaVA-Video 整体框架
虽然现有的开源视频理解模型基座具有强大的理解与感知能力,但由于其训练数据不透明,使用开源视频数据进行后训练可能会引入不可控的变量,从而影响实验结果和结论的可靠性。
因此,北航团队选择训练过程完全可溯源的 TinyLLaVA-Video 作为 Base Model,该模型采用 Qwen2.5-3B 作为语言模型,SigLIP 作为视觉编码器。虽然 TinyLLaVA-Video 仅有 3.6B 的参数,且在预训练阶段为了控制训练时长并未使用大量数据,但其仍能在多个 Benchmark 上能够优于现有的多个 7B+ 模型。
TinyLLaVA-Video-R1 主要做了什么?
引入少量人工标注的高质量冷启动数据
该工作发现,受限于小尺寸模型的能力,当直接使用 TinyLLaVA-Video 作为基础模型,随着训练的进行,模型有一定的概率学会「偷懒」,所有的响应虽然符合格式要求,但并不给出思考过程,响应均为<think> </think> <answer> option </answer>,同时在 Qwen2-VL-2B 上进行实验也得到相似的实验现象。
而当使用人工标注的 16 条 CoT 数据为模型进行冷启动后,在实验的过程中就不再出现这样的现象,同时,模型也将更快学会遵守格式要求。因此该工作认为,冷启动对于小尺寸模型推理是必要的,即使是极少量的冷启动数据,对于稳定模型训练也是很有帮助的。
引入长度奖励与答案错误惩罚
现有的许多推理工作仅仅设置格式奖励而没有添加长度奖励,但受限于小尺寸语言模型的能力,在这种设置下进行训练并不会使模型的响应长度增加,甚至出现一点下降。
在引入连续长度奖励后,模型的响应长度在训练过程中显著增加,如图所示。然而在这种设置下,模型为了增加响应长度而进行了一些无意义的推理,这不仅没有提高性能,反而导致训练时间显著增加。

因此,TinyLLaVA-Video-R1 进一步将答案错误惩罚纳入总奖励,观察到模型响应的质量有所提升,并且在整个训练过程中输出长度和奖励也能够保持增长。
为 GRPO 的优势计算引入微小噪声
同时,TinyLLaVA-Video-R1 在实验中也观察到了优势消失的问题:当集合中的所有响应都是正确的,并且给予相同的奖励时,它们计算出的优势会消失到零。这一现象影响了策略更新,降低了样本效率。为了最大化对每个样本的利用,TinyLLaVA-Video-R1 在优势计算时引入了额外的高斯噪声

,尽管这种噪声仅引起轻微的扰动,但它能够确保组内响应优势的多样性。
实验结果

首先,TinyLLaVA-Video-R1 验证了使用强化学习能够明显提升模型性能,与使用相同数据进行监督微调的 TinyLLaVA-Video-SFT 相比,TinyLLaVA-Video-R1 在多个 benchmark 中均有更佳的表现。

同时,TinyLLaVA-Video-R1 能够理解和分析视频内容,逐步评估每个选项,并最终给出答案。与仅输出最终答案的模型相比,该模型能够生成有意义的思考过程,使其回答更加可解释且有价值。这也是视频推理模型相对于传统视频理解模型的重要提升与优势。

与其他使用强化学习提升模型推理能力的工作相似,北航团队也在 TinyLLaVA-Video-R1 上复现了「Aha Moment」,即模型在思考的过程中引发紧急验证等行为。实验结果也验证了,即使使用弱推理的通用视频数据对小尺寸模型进行训练,也能够引发模型的回溯与自我反思。
后续,北航团队也将进一步研究小尺寸视频推理模型,未来工作将包括引入高质量视频推理数据与强化学习算法改进。
同时,TinyLLaVA 系列项目也始终致力于在有限计算资源下研究小尺寸模型的训练与设计空间,坚持完全开源原则,完整公开模型权重、源代码及训练数据,为资源有限的研究者们理解与探索多模态模型提供平台。
....
#CS25: Transformers United V5
OpenAI、谷歌等一线大模型科学家公开课,斯坦福CS 25春季上新!
在斯坦福,有一门专门讲 Transformer 的课程,名叫 CS 25。这门课曾经邀请过 Geoffrey Hinton、Andrej Karpathy 以及 OpenAI 的 Hyung Won Chung、Jason Wei 等一线大模型研究科学家担任讲师,在 AI 社区引起广泛关注。

最近,这门课又上新了。这一春季学期课程名为「CS25: Transformers United V5」,邀请了 Google DeepMind 推理团队创立者和现任负责人 Denny Zhou、OpenAI Canvas 项目负责人 Karina Nguyen、OpenAI 研究科学家 Hongyu Ren(任泓宇)、Meta 视频生成团队研究科学家 Andrew Brown 等知名研究者,深入探讨 AI 领域的最新突破。
而且,这门课是完全开放的,任何人都可以现场旁听或加入 Zoon 直播,无需注册或与斯坦福大学建立关联。

- 课程地址:https://web.stanford.edu/class/cs25/recordings/
课程结束后,他们还会把课程的视频上传到官方 YouTube 账号。目前,新学期视频第一期已经上传。

整个学期的课程表如下:





想要听直播的同学记得在太平洋夏令时间每周二下午 3:00 - 4:20(北京时间每周三上午 6:00 - 7:20)蹲守,具体信息请参考官方网站。
往期热门课程
V2:Geoffrey Hinton——Representing Part-Whole Hierarchies in a Neural Network

AI 领域传奇人物 Geoffrey Hinton(「深度学习教父」)分享了他对神经网络中部分-整体层次结构的最新研究,提出了 GLOM 模型,旨在模拟人类视觉系统处理复杂场景的能力。
讲座探讨了 GLOM 如何通过动态解析树结构增强 Transformer 在视觉任务中的表现,解决自注意力机制的计算效率瓶颈。Hinton 结合深度学习的演变历程,从感知机到 RNN 再到 Transformer,展望了神经网络在模拟认知过程和提升视觉理解中的未来潜力。
- 视频地址:https://www.youtube.com/watch?v=CYaju6aCMoQ&t=2s
V2:Andrej Karpathy——Introduction to Transformers

Andrej Karpathy(前 Tesla AI 总监、OpenAI 研究员)系统介绍了 Transformer 架构的原理与影响。他从 2017 年《Attention is All You Need》论文出发,拆解了自注意力机制(Self-Attention)、多头注意力(Multi-Head Attention)及 Transformer 在大型语言模型(如 ChatGPT)中的核心作用。
讲座还探讨了 Vision Transformer(ViT)等跨领域应用,并展望了模型高效化和多模态学习的未来。Karpathy 结合自身从斯坦福学生到业界先锋的经历,回顾了深度学习从 RNN 到 Transformer 的演变。
- 视频地址:https://www.youtube.com/watch?v=XfpMkf4rD6E
V3:Douwe Kiela——Retrieval Augmented Language Models

Douwe Kiela(Contextual AI 首席执行官兼斯坦福符号系统客座教授)深入探讨了检索增强生成(Retrieval-Augmented Generation, RAG)作为解决大型语言模型(LLM)局限性的关键技术。讲座介绍了 RAG 的基本概念,即通过外部检索器提供上下文信息,缓解幻觉(hallucination)、信息时效性和定制化问题。
Kiela 回顾了语言模型的历史,追溯至 1991 年的神经语言模型,澄清了 OpenAI 并非首创的误解,并调研了 RAG 的最新进展,如 Realm、Atlas 和 Retro 架构,分析其优劣。他还探讨了 RAG 与长上下文模型的效率对比、指令微调(instruction tuning)的重要性以及未来的研究方向,如多模态 RAG 和预训练优化。
- 视频地址:https://www.youtube.com/watch?v=mE7IDf2SmJg
V4:Jason Wei & Hyung Won Chung of OpenAI

OpenAI 研究科学家 Jason Wei 和 Hyung Won Chung 分享了关于大型语言模型(LLM)和 Transformer 架构的洞见。
Jason Wei 探讨了语言模型的直观理解,强调下一词预测作为大规模多任务学习的本质,并分析了扩展律(scaling laws)与个体任务的涌现能力。Hyung Won Chung 则从历史视角审视 Transformer 架构的演变,聚焦计算成本指数下降的驱动作用,提出通过连接过去与现在预测 AI 未来的统一视角。
两位讲者结合在 OpenAI 的工作经验(如 FLAN-T5、Codex),展望了 Transformer 在多模态和通用 AI 中的潜力。
....
#跨机型诊断难题新突破
上交大、商飞、东航打造国产大飞机时序大模型智能诊断新路径
近日,上海交通大学航空航天学院李元祥教授团队,联合上海飞机设计研究院和东方航空技术有限公司 MCC,在国产大飞机核心系统的智能诊断方向取得重要突破。研究团队围绕引气系统的跨机型诊断难题,首次构建基于时序大模型的统一诊断框架,实现了来自空客 A320、A330 等成熟机型的运行知识向国产 C919 的有效迁移,为新机型在数据稀缺条件下的早期健康管理提供了智能化解决方案。
相较于传统方法多依赖单一机型、模型容量有限且泛化性差,该研究提出一种 “预测下一个信号 token” 的自监督预训练方法,联合利用三类机型的飞行数据开展训练,成功学习到通用的信号健康表征。在此基础上,设计了高度适配工程场景的联合损失函数,显著提升了模型在下游异常检测和基线预测任务中的表现。研究进一步验证了,基于时序大模型的飞参建模方式能够有效打破机型壁垒,实现诊断知识在多型号间的共享与迁移。相关论文已被国际工程信息学领域的一区 Top 期刊《Advanced Engineering Informatics》接收发表。
- https://www.sciencedirect.com/science/article/pii/S1474034625001685
- https://arxiv.org/pdf/2504.09090
背景介绍
引气系统(Bleed Air System, BAS)作为保障飞行安全与乘客舒适度的核心环节,承担着舱压调节、空调供气和发动机防冰等多项关键功能。由于系统工作环境复杂且高度依赖发动机压气机供气,BAS 常见故障如超压、低压和过热,不仅频繁发生,还可能导致机舱减压、设备损坏甚至安全事故,成为影响飞行任务稳定执行的重要隐患。
现有研究多依赖基于特定机型构建的统计模型或轻量级深度模型,虽在健康监测与风险评估中具备一定有效性,但面临两个根本瓶颈:一是模型强依赖特定机型数据分布,难以在不同飞机平台间迁移使用;二是对大量故障标签的依赖,使其难以适配如 C919 等新型飞机在早期运营阶段数据稀缺的实际情况。特别是在国产大飞机持续服役推广的背景下,如何在多机型之间共享诊断知识、降低数据门槛、提升模型的泛化能力,成为工程界亟待破解的关键课题。
主要创新
为了解决多机型之间诊断迁移难、C919 数据稀缺等问题,团队提出了一种基于时序大模型的统一诊断框架。团队构建了涵盖 A320、A330 和 C919 三种机型的引气系统飞行数据集,并设计了一种自监督学习策略,通过 “预测下一个信号 token” 的方式,让模型在不依赖故障标签的情况下,学会抽取多机型通用的健康状态特征。


在此基础上,团队针对工程上新机型故障样本极少的现实,设计了一个结合基线预测与异常检测的联合损失函数。这个机制不仅提升了模型对下游任务的适应性,也让诊断结果更具解释性。
结果
实验表明,该模型在多个任务中表现优于现有方法,尤其是在 C919 这样数据稀少的场景下,准确率提升明显。

在跨机型数据的预训练基础上进行微调的下游任务的精度和准确度显著超越当前流行的 SOTA 方法,并且将有预训练和没有预训练的相比,性能也有明显提升,验证了预训练在本系统的有效性。


可视化分析进一步验证了模型的表示能力。通过 t-SNE 将不同机型的信号语义映射至二维空间,结果显示模型能够清晰划分正常与异常状态,即使传感器配置存在差异,仍具备良好的判别能力。

此外,团队还探索了模型规模与任务性能之间的关系。结果表明,在结构不变的前提下增加参数量,模型预测准确性随之提升,体现出明显的规模效应。这为未来构建更高容量、更强泛化能力的飞行信号基础模型提供了支撑。

未来研究方向
本研究展示了时序大模型在数据稀缺、系统异构等复杂工业场景下的应用潜力,不仅为国产大飞机早期运营提供了有效的健康保障手段,也为我国广泛存在的工业设备场景(如轨道交通、能源系统、制造产线等)带来了通用化智能诊断的技术启发。以统一模型、共享知识、适应多样系统的能力,将为各类工业场景的运维升级提供新思路。
未来,研究团队将进一步拓展飞行关键系统的建模范围,构建覆盖发动机、空调系统、辅助动力装置等多个子系统的飞参时序大模型,推动跨系统、多机型的统一建模与诊断研究。同时,团队还计划引入文本、图谱等多源信息,发展融合飞参信号与维修记录、舱内语音等的多模态模型架构,持续提升故障预测的准确性与模型的交互性,面向未来构建智能化的飞机健康管理系统。
....
#Embodied-Reasoner
xx交互推理: 图像-思考-行动交织思维链让机器人会思考、会交互
OpenAI 的 o1 系列模型、Deepseek-R1 带起了推理模型的研究热潮,但这些推理模型大多关注数学、代码等专业领域。如何将这种深度推理模型扩展到智能体和xx领域,让机器人通过思考和推理来完成复杂xx交互等任务?
近期,来自浙江大学、中科院软件所和阿里巴巴的团队提出了 Embodied-Reasoner,让机器人或智能体拥有深度思考和交互决策能力,从而在真实物理世界完成环境探索、隐藏物体搜索、交互和搬运等长序列复杂任务。
可以想象,未来某一天,机器人能够帮你在房间里找钥匙、信用卡等容易遗忘的小物件。它可以观察房间、分析和思考,然后一步一步地搜索,最后帮你找到它们。
论文标题:Embodied-Reasoner: Synergizing Visual Search, Reasoning, and Action for Embodied Interactive Tasks
论文地址:https://arxiv.org/abs/2503.21696
项目主页:https://embodied-reasoner.github.io
代码地址:https://gitee.com/agiros/EmbodiedReasonerhttps://github.com/zwq2018/embodied_reasoner
HuggingFace:https://huggingface.co/datasets/zwq2018/embodied_reasoner
一分钟看懂 Embodied-Reasoner
,时长01:28
简介
尽管深度思维模型在数学和编码任务上展现出卓越的推理能力,但不同于数学、代码等文字模态上的推理,xx领域的推理有几个重要的挑战需要解决:
- 首先,xx模型不同于单轮聊天对话,需要通过交互方式运行。它们必须持续与环境交互,收集视觉反馈,并基于这些反馈做出合理的行动(文本模态)。因此,模型每次需要处理多轮次的、图文交织的冗长输入,而后产生连贯、符合上下文的推理和决策。
- 其次,与数学任务主要依赖于逻辑推理和专业知识不同,xx场景中推理还需要更丰富的能力,包括多模态的感知、基于物理世界的常识推断、空间关系理解、时序的推理以及面对环境交互失败后的自我反思等能力,这些都对大模型提出了更高要求。
- 最后,当前的 LLM 主要以语言形式输出,无法直接控制机器人执行物理交互。因此,如何设计合理的语义动作空间让「思考」和「行动」解耦也是一个难点。
如刚才视频中展示的具体例子,当xx智能体在未知房间中搜索隐藏物体时,它必须利用物理常识推断潜在的搜索区域(步骤 1、3),理解物体的空间关系以规划高效的探索路径(步骤 1、5),并运用时序推理回忆先前尝试中的相关线索(步骤 9),同时反思先前的失败。这些多方面的推理要求对多模态模型提出了挑战。
实验发现,即使是像 OpenAI o3-mini 这样的先进 LLM,在这些xx交互任务中也经常难以展现可靠的推理和决策,容易出现重复的搜索或前后不一致的行为。
基于上述挑战,团队提出了 Embodied-Reasoner,将深度思考能力扩展到xx交互任务。其关键的两点包括:
- 纯文本模态上的推理似乎无法解决这种长序列的xx任务。因此,Embodied-Reasoner 设计了图文交织的思维链:观察-思考-行动,三者相互交织构成真正的多模态思维链。这个设计类似于最近刚刚推出的 OpenAI 的 o3 和 o4-mini 模型,集成了图片编辑(缩放、裁剪等)等中间动作,也创造了图文交织的多模态思维链。
- 设计了多样化的思考因子适应不同的交互阶段,包括情景分析、任务规划、空间推理、行为反思和多重验证等。这些多样化的思考因子能够促进模型从不同角度进行推理和思考。

为了开发这种能力,如上图所示,我们构建了一个数据引擎,自动合成连贯的观察-思考-行动轨迹,引入了xx场景下多样化的思考过程,例如情境分析、空间推理、自我反思、任务规划和自我验证。这些连贯的、图像-文本交错的轨迹引导模型学习如何基于其交互历史和空间布局进行规划和推理,从而提升其空间和时间推理能力。
此后,我们引入了一个三阶段迭代训练流程,结合了模仿学习、自我探索和自我纠正微调。该流程首先利用合成轨迹进行模仿学习以培养基本交互能力,然后通过拒绝采样微调增强探索能力,最后经反思调优培养自我纠正能力。
下面是一个具体的例子:

如上图所示,模型需要空间推理能力来理解厨房布局和物体关系,基于常识知识推断潜在位置(冰箱、餐桌),系统地搜索未探索区域,并通过实时观察调整计划,同时避免重复搜索。
技术方案
任务定义
任务环境:使用广泛采用的 AI2-THOR 模拟器构建了xx任务环境,该模拟器提供物理模拟和实时视觉观测。实验使用 120 个独特的室内场景(如厨房)以及 2,100 个可交互物体(如信用卡和微波炉)。实验通过 AI2-THOR 的 API 控制机器人的移动(如向前移动)和交互(如拾取物体),同时在每一步返回视觉观察。
任务类别:机器人初始化在未知房间的一个角落,视野有限,即只能看到房间的一部分。本节设计了日常生活中四种常见的交互任务,复杂度依次增加:
- 搜索:在未知房间中搜索物体,如钥匙链。它可能放置在某处或隐藏在容器内。
- 操作:搜索后与物体交互,如「找到一盏灯并打开开关」。
- 运输:找到隐藏物体后,将其运输到另一个位置。这涉及多个搜索和操作步骤。
- 复合任务:按顺序涉及多个运输任务,如「将鸡蛋放入微波炉,加热后放在桌子上。之后,找到……」。
动作定义:虽然 AI2-THOR 提供了许多低层级的动作,但本节的任务侧重于高级规划和推理,而非运动控制。此外,低级动作可能导致过多交互,因此本节在原子动作基础上封装了 9 个高级动作:观察、向前移动、导航至 {}、放入 {}、拾取 {}、切换 {}、关闭 {}、打开 {}、终止。
「观察-思维-行动」交织的思维链合成
为了开发适用于xx场景的 o1 风格推理模型,本节首先设计了一个需要高级规划和推理,而非低级运动控制的xx任务,即搜索隐藏物体。接着,基于模拟器设计了一个数据引擎,用于合成交互式推理语料库:任务指令和相应的关键动作序列。
每个动作产生一个视觉观察,形成交互轨迹。最后,数据引擎为每个动作生成多种思考链,如情境分析、任务规划、空间推理、反思和验证,创建了一个具有观察-思考-行动上下文的交互式推理语料库。
- 指令合成(Instruction Synthesis)
- 基于物理环境约束设计多样化任务模板(如「将 A 从容器取出放入 B」)。
- 通过物体属性筛选可行组合(A 需为可拾取物,B 需为容器)。
- 利用 GPT-4o 进行指令风格多样化处理。
- 通过指令组合构建不同难度梯度的任务。
- 动作序列合成(Action Sequence Synthesis)
- 从属关系图:数据引擎使用模拟器的元数据构建一个从属关系图。
- 关键动作序列:数据引擎利用构建的从属关系图和合成的指令模板推导出完成任务所需的最小动作序列(关键动作)。
- 添加额外的搜索过程:除了关键动作序列外,数据引擎还通过插入额外的搜索过程来合成探索路径。
- 观察-动作序列中插入多样化的思考过程
在运行合成的动作(
![]()
)后,数据引擎获得一个交互轨迹:
![]()
,其中 oi 表示第一人称视角图像。然后,数据引擎为每个动作生成多种深度思考内容(
![]()
),从而创建一个图文交织的上下文:观察-思考-行动。
多样化思考模式:首先,本节定义了五种思考模式,模拟人类在不同情况下的认知活动:情境分析(Situation Analysis)、任务规划(Task Planning)、空间推理(Spatial Reasoning)、自我反思(Self-reflection)和双重验证(Double Verification)。本章节使用简洁的提示来描述每种模式,指导 GPT-4o 合成相应的思考过程。
从观察-行动中推导思考:对于每次交互,数据引擎指导 GPT-4o 选择一种或多种思考模式,然后基于交互上下文生成详细的思考。这些思考被插入到观察和行动之间(

)。具体来说,数据引擎用之前的交互轨迹(
![]()
)和即将到来的动作(
![]()
)提示 GPT-4o,生成一个合理的思考过程(
![]()
)。它应该考虑最新的观察(
![]()
)并为下一步动作(
![]()
)提供合理的理由,同时与之前的思考保持逻辑一致。
模型训练策略
多轮对话格式:考虑到交互轨迹遵循交织的图像-文本格式(观察-思考-行动),Embodied-Reasoner 将其组织为多轮对话语料库。在每个回合中,观察到的图像和模拟器的反馈作为用户输入,而思考和行动则作为助手输出。在训练过程中,我们仅对思考和行动 token 计算损失。
为了增强推理能力,Embodied-Reasoner 设计了三个训练阶段:模仿学习、拒绝采样微调和反思调优,这些阶段将通用视觉语言模型逐步提升为具有深度思考能力的xx交互模型:
- 第一阶段模仿学习:使用数据引擎生成少量的指令-轨迹对,大多数包含有限的搜索过程或仅由关键动作组成(观察-思考-关键动作)。然后在此数据集上微调 Qwen2-VL-7B-Instruct,使其学会理解交织的图像-文本上下文,输出推理和动作 token。经过微调得到 Embodied-Interactor。
- 第二阶段拒绝采样微调,学习搜索:使用上一阶段的模型采样大量生成轨迹进行进一步训练,并且使用数据引擎来评估这些采样轨迹。该阶段一共保留了 6,246 个成功轨迹进行微调,最后得到 Embodied-Explorer。

- 第三阶段反思微调:上一阶段的模型有时会产生不合理的动作,特别是在长序列交互任务中,如幻觉。此外,机器人经常会遇到临时硬件故障,这要求模型能够对不合理行为进行自我反思,识别异常状态,并及时纠正。如上图所示,第三阶段使用 Embodied-Explorer 在先前任务上采样大量轨迹。对于失败的轨迹,我们定位第一个错误动作并构建自我纠正轨迹。对于成功的轨迹,我们插入异常状态来模拟硬件故障。这一步骤补充了 2,016 条反思轨迹(每条轨迹平均 8.6 步)。
交织思维链分析
统计结果:我们为三个训练阶段合成了 9,390 个独特的任务指令及其观察-思考-行动轨迹,即〈场景, 指令, 交织的多模态思维链〉。如下面表格所示,在第一阶段,数据引擎合成了 1,128 条轨迹数据。在第二阶段,通过拒绝采样保留了 6,246 条探索轨迹。在第三阶段,数据引擎合成了 2,016 条自我纠正轨迹。所有合成的数据集涵盖 107 个多样化的室内场景(如厨房和客厅),包括 2,100 个可交互物体(如鸡蛋、笔记本电脑)和 2,600 个容器(如冰箱、抽屉)。所有轨迹包含 64K 张第一人称视角的观察图像和 8M 个思考 token。
测试任务:此外,我们在 12 个全新场景中构建了 809 个测试案例,这些场景与训练场景不同。然后,人工设计了任务指令并标注相应的关键动作和最终状态:〈指令,关键动作,最终状态〉。值得注意的是,测试集还包含 25 个精心设计的超长序列决策任务,每个任务涉及四个子任务的组合,并涵盖至少 14 个、最多 27 个关键动作。

思考模式的分布:本节统计了所有轨迹中五种思考模式的频率。如下图所示,Task Planning 和 Spatial Reasoning 出现最频繁,分别为 36.6k 和 26.4k 次。这意味着每条轨迹包含约四次 Task Planning 和三次 Spatial Reasoning。此外,Self-Reflection 通常在搜索失败后出现,每条轨迹平均出现两次。这些多样化的思考促进了模型的推理能力。
思考模式之间的转换:五种思考模式之间的转移概率如下图所示。实验发现它们之间的关系是灵活的,取决于具体情况。通常从 Situation Analysis 开始,随后是 Task Planning(55%)和 Spatial Reasoning(45%)。在导航到未知区域时,它经常依赖 Spatial Reasoning(Action→S:42%)。如果搜索尝试失败,它会转向 Self-Reflection(Action→R:33%),当(子)任务完成时,它有时会进行 Double Verification(Action→V:3%,S→V:6%)。这种多样化的结构使模型能够学习自发思考和灵活适应性。

实验分析对比实验
实验对比了通用的 VLMs 和近期出现的视觉推理模型,例如 o1、Claude-3.7-sonnet-thinking 等。

从上表的实验结果来看,Embodied-Reasoner 显著优于所有推理模型和 VLMs,成功率比 GPT-o1 高出 9.6%,比 GPT-o3-mini 高出 24%,比 Claude-3.7-Sonnet-thinking 高出 13%。它在搜索效率和任务完成度方面也明显领先,尤其在复杂任务(如复合和运输任务)上表现更为突出,在复合任务上比第二好的模型 GPT-4o 高出 39.9%。通过三阶段训练(模仿学习、拒绝采样调优和自我纠正轨迹微调),模型性能从基础的 14.7% 逐步提升至 80.9%,减少了其他模型常见的重复搜索和不合理规划问题,展现出更强的深度思考和自我反思能力,尽管规模小于先进推理模型。
分析:深度思考范式如何增强xx搜索任务?


对长序列任务更具鲁棒性:Embodied-Reasoner 在处理复杂的长序列决策任务时表现出显著优势。实验结果显示,当任务所需的关键动作数量增加时,基线模型的成功率急剧下降,特别是在任务超过五个动作时。而 Embodied-Reasoner 在大多数复杂情况下仍能保持超过 60% 的成功率,展现出对长序列任务的强大鲁棒性。
自发地为复杂任务生成更长的推理链:面对复杂任务时,Embodied-Reasoner 会自动生成更深入的思考过程。数据显示,随着任务复杂度增加,其输出 token 从 1,000 增长到 3,500 左右,几乎是 Gemini-2.0-flash-thinking 的五倍。这种深度思考能力使其能够规划更高效的搜索路径并避免冗余动作,而其他模型如 Gemini-2.0-flash-thinking 则无法通过扩展推理时间来应对更复杂的xx任务。
深度思考减轻了重复搜索行为:实验引入重复探索率(RER)来衡量模型在轨迹中重复导航到同一区域的频率。Embodied-Reasoner 和 Explorer 在所有任务类型中都表现出显著较低的 RER。在复合任务中,Embodied-Explorer 的 RER 仅为 26%,而 GPT-o3-mini 和 Qwen2-VL-72B 分别达到 54% 和 43%。Embodied-Reasoner 通过回忆过去观察、反思先前探索动作并制定新计划,增强了时序推理能力,有效减少了重复搜索行为。
真实世界实验
为了评估 Embodied-Reasoner 的泛化能力,本节设计了一个关于物体搜索的真实世界实验,涵盖三个场景中的 30 个任务:6 个厨房任务、12 个浴室任务和 12 个卧室任务。在测试过程中,人类操作员手持摄像机捕捉实时视觉输入。模型分析每张图像并生成动作命令,然后由操作员执行这些动作。

上图展示了一个例子:「你能帮我找到咖啡并加热它吗?」Embodied-Reasoner 在两次探索(步骤 1、2)后排除了台面和餐桌,最终在橱柜中找到咖啡(#7)并将其放入微波炉加热(#11)。然而,实验观察到 OpenAI o3-mini 未能制定合理的计划,先前往微波炉而不是搜索咖啡。此外,它经常忘记搜索并表现出重复搜索行为,这与本章节之前的分析一致。
,时长00:23
,时长00:23
总结
Embodied-Reasoner 的贡献包括:
- 一个将深度思考扩展到xx场景的框架,解决了交互式推理的独特挑战;
- 一个数据引擎,合成多样化的多模态思维链,包含交错的观察、思考和行动;
- 一个三阶段训练流程,逐步增强交互、探索和反思能力;
- 广泛的评估,相比最先进模型取得了显著改进,特别是在复杂的长序列交互任务中。
Embodied-Reasoner 已发布于 AGIROS 智能机器人操作系统开源社区。AGIROS 智能机器人操作系统开源社区由中国科学院软件研究所发起,旨在通过凝聚智能机器人操作系统产学研用各方力量,共同推动智能机器人操作系统技术及生态的发展,全面推进智能机器人领域的开源开放协同创新,为智能机器人产业夯实基础。
研究团队来自浙江大学、中科院软件所、阿里巴巴和中科南京软件技术研究院,在多模态模型、xx智能体、机器人共用算法框架技术等方面拥有丰富的研究经验。共同一作为张文祺(浙江大学博士生)与王梦娜(中科院软件所硕士生),通讯作者为中科院软件所副研究员李鹏与浙大庄越挺教授。该团队曾开发了数据分析智能体 Data-Copilot,在 github 上获得超过 1500 stars, 开发multimodal textbook,首月在huggingface上超过15000次下载。
....
#ReSo
基于奖励驱动和自组织演化机制,全新框架ReSo重塑复杂推理任务中的智能协作
本文由上海人工智能实验室,悉尼大学,牛津大学联合完成。第一作者周恒为上海 ailab 实习生和 Independent Researcher 耿鹤嘉。通讯作者为上海人工智能实验室青年科学家白磊和牛津大学访问学者,悉尼大学博士生尹榛菲,团队其他成员还有 ailab 实习生薛翔元。
ReSo 框架(Reward-driven & Self-organizing)为复杂推理任务中的多智能体系统(MAS)提供了全新解法,在处理复杂任务时,先分解生成任务图,再为每个子任务匹配最佳 agent。将任务图生成与奖励驱动的两阶段智能体选择过程相结合,该方法不仅提升了多智能体协作的效率,还为增强多智能体的推理能力开辟了新路径。
- 论文标题:ReSo: A Reward-driven Self-organizing LLM-based Multi-Agent System for Reasoning Tasks
- 论文链接:https://arxiv.org/abs/2503.02390
- 代码地址:https://github.com/hengzzzhou/ReSo
研究背景:LLM 推理能力的掣肘与突破口
近年来,增加推理时间(Inference Time Scaling)被广泛认为是提升大语言模型(Large Language Models, LLMs)推理能力的重要途径之一。一方面,通过在训练后阶段引入强化学习与奖励模型,可优化单一模型的推理路径,使其在回答前生成中间步骤,表现出更强的逻辑链构建能力;另一方面,也有研究尝试构建多智能体系统(Multi-Agent Systems, MAS),借助多个基座模型或智能体的协同工作来解决单次推理难以完成的复杂任务。
相较于单模型的推理时间扩展,多智能体方法在理论上更具灵活性与可扩展性,但在实际应用中仍面临诸多挑战:
(1)多数 MAS 依赖人工设计与配置,缺乏自动扩展与适应性的能力;
(2)通常假设所有智能体能力已知,然而 LLM 作为 “黑箱式” 的通用模型,在实际任务中往往难以预先评估其能力边界;
(3)现有 MAS 中的奖励信号设计较为粗糙,仅依赖结果反馈或自我评估,难以有效驱动优化过程;
(4)缺乏基于数据反馈的动态演化机制,限制了 MAS 系统在大规模任务中的表现与泛化能力。
上述限制提出了一个核心问题:能否构建一种具备自组织能力的多智能体系统,使其能够通过奖励信号直接从数据中学习协作策略,而无需大量人工干预?
为应对这一挑战,作者提出了 ReSo—— 一个基于奖励驱动、自组织演化机制的多智能体系统架构。该方法通过引入协同奖励模型(Collaborative Reward Model, CRM),在任务图生成与智能体图构建之间建立反馈闭环,从而实现基于细粒度奖励的智能体动态优化与协作演化。与现有多智能体方案相比,ReSo 在可扩展性与优化能力上均具优势,并在多项复杂推理任务上达到了领先性能。

ReSo 框架流程图
ReSo 框架:Task Graph + Agent Graph,重塑 MAS 推理能力
具体来说,作者提出了两项核心创新:(1) ReSo,一个奖励驱动的自组织 MAS,能够自主适应复杂任务和灵活数量的智能体候选,无需手动设计合作解决方案。(2) 引入协作奖励模型 (CRM),专门用于优化 MAS 性能。CRM 可以在多智能体协作中提供细粒度的奖励信号,从而实现数据驱动的 MAS 性能优化。
1. 问题定义
对于一个解决任意问题 Q 的多智能体任务,作者将其定义为如下算法:

其中

负责根据输入问题构建任务分解图,确保将问题结构化地分解为子任务及其依赖关系。

则动态地选择并分配合适的代理来解决已识别的子任务。这种模块化设计使得每个组件能够独立优化,从而实现更高的灵活性和可扩展性。
2. 任务图生成:明确子任务和依赖关系
ReSo 首先使用一个大语言模型将复杂问题分解,转化为分步骤的有向无环任务图 (DAG Task Graph),为后续智能体分配提供基础。

在实践中,对于任务分解,作者既测试了了已有的闭源模型(如 gpt4o),也在开源 LLM (如 Qwen-7b) 上进行监督微调 (SFT) 来执行更专业的任务分解。为了微调开源 LLM,作者构建了合成数据(见后文数据贡献章节),明确要求 LLM 将 Q 分解为逻辑子问题,指定它们的执行顺序和依赖关系,并以 DAG 格式输出。

3. 两阶段智能体选择:从粗到细,精挑细选
一旦获得任务图,作者就需要将每个子任务分配给最合适的代理。作者将此代理分配过程表示为

。从概念上讲,

会根据大型代理池 A 中最合适的代理对任务图中的每个节点进行分类,从而构建一个代理图,将每个节点映射到一个或多个选定的代理。

具体来说,作者提出了动态智能体数据库(DADB)作为 Agent 选择的代理池:通过构建一个动态数据库,存储智能体的基本信息、历史性能及计算成本,以供未来生成初步质量评分。
在 DADB 的基础上,对于使智能体选择算法具有可扩展性、可优化性,作者提出了两阶段的搜索算法:
- 粗粒度搜索(UCB 算法):利用上置信界(UCB)算法筛选候选智能体。

给定 DADB A 和一个子任务 vj,作者希望首先从所有智能体中筛选出一批有潜力的候选智能体(数量为 k)。
为此,作者采用了经典的上置信界(UCB)策略,该策略兼顾 “探索” 和 “利用” 的平衡:

其中:Q (

):DADB 给出的预评分,N:系统到目前为止分配过的智能体总数,n (

):智能体

被选中的次数,ε≪1:防止除以 0 的微小常数,c:超参数,控制探索(少被用过的智能体)与利用(高评分智能体)之间的平衡。
最后,作者按 UCB 分数对所有智能体排序,选择前 k 个作为当前子任务的候选集:

- 细粒度筛选(协作奖励模型 CRM):通过协作奖励模型对候选智能体进行细粒度评估,最终选择最优智能体。
在完成粗粒度筛选、选出了候选智能体集合之后,作者需要进一步评估这些智能体在当前子任务

上的实际表现。这一步是通过一个协同奖励模型(Collaborative Reward Model, CRM) 来完成的。
这个评估过程很直接:
每个候选智能体 ai 对子任务

生成一个答案,记作

(

);
然后作者通过奖励模型来评估这个答案的质量,得到奖励值 r (

,

):

其中 RewardModel 会综合考虑以下因素来打分:
A. 当前智能体

的角色与设定(即其 static profile);
B. 子任务

的目标;
C. 以及该智能体在先前的推理过程中的上下文。
在所有候选智能体被评估后,作者将奖励值最高的智能体 a 分配给子任务

,并将其生成的答案作为该子任务的最终解。这个评估与分配过程会对任务图中的每一个子任务节点重复进行,直到整张图完成分配。
1. 从训练到推理:动态优化与高效推理
- 训练阶段:利用 CRM 奖励信号动态更新 DADB,实现自适应优化。

其中:R (

) 表示当前该智能体的平均奖励;n (

) 是它至今参与的任务次数;r (

,

) 是它在当前子任务中的奖励。
类似地,作者也可以用同样的方式更新该智能体的执行开销(例如运行时间、资源消耗等),记作 c (

,

)。
通过不断迭代地学习和更新,DADB 能够动态地根据历史数据评估各个智能体,从而实现自适应的智能体选择机制,提升系统的整体性能和效率。
- 推理阶段:在测试阶段,作者不再需要奖励模型。此时,作者直接使用已经训练好的 DADB,从中选择最优的智能体候选者,并为每个子任务挑选最优解。
2. 从 MCTS 视角看 ReSo:降低复杂度,提升扩展性
任务图经过拓扑排序后,形成一棵决策树,其中每个节点代表一个子任务,边表示依赖关系。在每一层,作者使用 UCB 修剪树并选择一组有潜力的智能体,然后模拟每个智能体并使用 CRM 评估其性能。由此产生的奖励会更新智能体的动态配置文件,从而优化选择策略。MAS 的构建本质上是寻找从根到叶的最佳路径,最大化 UCB 奖励以获得最佳性能。
数据集生成:Mas-Dataset
由于缺乏高质量的 MAS 数据集,作者提出了一种自动化方法来生成多智能体任务数据。这个过程包括随机生成任务图、填充子任务以及构建自然语言依赖关系。提出了一个单个 sample 就具有多学科任务的数据集。开源了数据合成脚本论文合成了 MATH-MAS 和 Scibench-MAS 数据集,复杂度有3,5,7。复杂度为 7 的意思为,单个题目中由7个子问题组成,他们来自不同的领域(数学,物理,化学)。子问题之间有依赖关系,评测模型处理复杂问题的能力。下图是个 Scibench-MAS 复杂度为 3 的例子:

实验结果
主要结果
表 1 的实验结果实验表明,ReSo 在效果上匹敌或超越现有方法。ReSo 在 Math-MAS-Hard 和 SciBench-MAS-Hard 上的准确率分别达到 33.7% 和 32.3% ,而其他方法则完全失效。图 3 显示,在复杂推理任务中,ReSo 的表现全面优于现有 MAS 方法,展现了其卓越的性能和强大的适应性。


....
#DeepWiki
Devin开发团队开源DeepWiki,助你快速读懂所有GitHub代码库
最近,独角兽 AI 公司 Cognition AI(Cognition Labs)推出了一个开源项目——DeepWiki,旨在为 GitHub 上的公共代码仓库生成 AI 驱动的交互式文档,堪称「GitHub 仓库的免费百科全书」。

用户可以通过官网直接访问,也可以将 GitHub 链接中的「github.com」替换为「deepwiki.com」。
- 体验地址:http://deepwiki.com
它通过分析代码、README 和配置文件,自动生成结构化的技术文档、交互式图表,并提供一个对话式 AI 助手,帮助开发者快速理解项目结构和逻辑——无需反复查阅稀少的 README 文件或晦涩的注释信息!
,时长00:28
DeepWiki 自发布以来,热度持续走高,吸引了众多用户,并获得了积极的反馈。

DeepWiki 主要有以下核心功能:
- 自动生成文档:
DeepWiki 可以将任意 GitHub 公共仓库转化为类似维基百科的文档页面,包含项目目标、核心模块、依赖关系图等。通过分析代码逻辑(如 if-else 结构、跨文件引用),生成通俗易懂的说明,适合新手和资深开发者。
- 对话式交互:
用户可以通过自然语言向 DeepWiki 提问,例如「如何实现用户鉴权?」或「解释 MVC 架构」,AI 会基于代码分析给出精准解答。基于 Devin 技术提供支持,支持中文等语言对话,增强全球开发者的使用体验。
- 交互式图表:
自动生成可点击的交互式图示,包括类层次结构(class hierarchies)、依赖关系图(dependency graphs)和工作流程图(workflow charts),用户可以放大缩小,自由探索各模块之间的关联。
- 深度研究(Deep Research)模式:
面向高阶用户,DeepWiki 支持运行高级分析任务,如检测潜在漏洞、建议优化方向,或将当前仓库与其他仓库进行对比分析。体验拥有一位资深工程师随时待命的感觉!
,时长00:18
Deep Research 模式。
已索引的仓库可直接访问,如果目标公共仓库尚未被索引,用户可请求 DeepWiki 进行索引。
,时长00:08
索引演示。
据团队成员介绍,DeepWiki 已索引 3 万个仓库,处理超 40 亿行代码,约 1000 亿个 Token,投入逾 30 万美元计算成本。但它是完全开源免费的,公共仓库无需登录即可访问(如果你想提交你的私有 GitHub 仓库到 DeepWiki,需要使用 Devin 账号登录)。

据猜测,DeepWiki 可能整合了 Cognition AI 的 Devin AI 技术(2024 年发布的 AI 软件工程师),结合大规模语言模型(LLM)、代码分析和云计算基础设施。
但 DeepWiki 目前存在索引数据未获第三方验证、暂不支持 GitHub Issues/PR 检索、复杂项目文档准确性需验证、私有仓库需注册且功能可能受限等局限,建议结合人工验证使用。
Cognition AI

Cognition AI(也称 Cognition Labs)是一家成立于 2023 年的人工智能公司,专注于开发人工智能驱动的软件工程工具,旨在加速科学发现和提升开发者生产力。其核心使命是「构建能够像人类一样推理和协作的 AI,助力人类解决复杂问题」。
他们在 2024 年 3 月发布了全球首个人工智能软件工程师 Devin,能够自主完成复杂编码任务,引起了不小的关注。

- 体验链接:https://devin.ai/
团队成员多为顶尖程序员,共获得 10 块 IOI 金牌,凸显其在算法和编程领域的实力,包括前 OpenAI、Google DeepMind 等公司的高级研究员和工程师,具备从模型训练到产品部署的端到端经验。
值得一提的是,团队以华人为核心,首席执行官 Scott Wu、首席技术官 Steven Hao、首席产品官 Walden Yan 均为华人。
参考链接:https://www.xugj520.cn/en/archives/ai-github-documentation-deepwiki.htmlhttps://apidog.com/blog/deepwiki/
....
#Kimi-Audio
秒杀同行!Kimi开源全新音频基础模型,横扫十多项基准测试,总体性能第一
六边形战士来了。
今天,kimi 又发布了新的开源项目 —— 一个全新的通用音频基础模型 Kimi-Audio,支持语音识别、音频理解、音频转文本、语音对话等多种任务,在十多个音频基准测试中实现了最先进的 (SOTA) 性能。
结果显示,Kimi-Audio 总体性能排名第一,几乎没有明显短板。
例如在 LibriSpeech ASR 测试上,Kimi-Audio 的 WER 仅 1.28%,显著优于其他模型。VocalSound 测试上,Kimi 达 94.85%,接近满分 。MMAU 任务中,Kimi-Audio 摘得两项最高分;VoiceBench 设计评测对话助手的语音理解能力,Kimi-Audio 在所有子任务中得分最高,包括一项满分。

研发人员开发了评估工具包,可在多个基准任务上对音频 LLM 进行公平、全面评估 ,五款音频模型(Kimi-Audio、Qwen2-Audio、Baichuan-Audio、StepAudio、Qwen2.5-Omni)在各类音频基准测试中的表现对比。紫线(Kimi-Audio)基本覆盖最外层,表明其综合表现最佳。
目前,模型代码、模型检查点以及评估工具包已经在 Github 上开源。
项目链接:https://github.com/MoonshotAI/Kimi-Audio
新颖的架构设计
为实现 SOTA 级别的通用音频建模, Kimi-Audio 采用了集成式架构设计,包括三个核心组件 —— 音频分词器(Audio Tokenizer)、音频大模型(Audio LLM)、音频去分词器(Audio Detokenizer)。
这一架构使 Kimi-Audio 能够在单一模型框架下,流畅地处理从语音识别、理解到语音对话等多种音频语言任务。

Kimi-Audio 由三个主要组件组成:音频分词器(Audio Tokenizer)、音频大模型(Audio LLM)、音频去分词器(Audio Detokenizer)。
具体而言,音频分词器(Audio Tokenizer)负责将输入音频转化为通过矢量量化(vector quantization)得到的离散语义 token,帧率为 12.5Hz。同时,音频分词器还提取连续的声学向量,以增强感知能力。
这种结合方式使模型既具有语义上的压缩表示,又保留了丰富的声学细节,从而为多种音频任务提供了坚实的表示基础。
音频大模型(Audio LLM)是系统的核心,负责生成语义 token 以及文本 token,以提升生成能力。其架构基于共享 Transformer 层,能够处理多模态输入,并在后期分支为专门用于文本和音频生成的两个并行输出头。
音频去分词器(Audio Detokenizer)使用流匹配(flow matching)方法,将音频大模型预测出的离散语义 token 转化为连贯的音频波形,生成高质量、具有表现力的语音。
数据建构与训练方法
除了新颖的模型架构,构建 SOTA 模型的核心工作还包括数据建构和训练方法。
为实现 SOTA 级别的通用音频建模,Kimi-Audio 在预训练阶段使用了约 1300 万小时覆盖多语言、音乐、环境声等多种场景的音频数据,并搭建了一条自动处理 “流水线” 生成高质量长音频 - 文本对。
预训练后,模型进行了监督微调(SFT),数据涵盖音频理解、语音对话和音频转文本聊天三大类任务,进一步提升了指令跟随和音频生成能力。

Kimi-Audio 预训练数据处理流程的直观展示。简单来说,就是把原始音频一步步净化、切分、整理,变成干净、有结构、有标注的训练数据。
在训练方法上,为实现强大的音频理解与生成能力,同时保持模型的知识容量与智能水平,研发人员以预训练语言模型为初始化,设计了三个类别的预训练任务:
仅文本和仅音频预训练,用于分别学习两个模态的知识;音频到文本的映射,促进模态转换能力;音频文本交错训练,进一步弥合模态间的鸿沟。
在监督微调阶段,他们设计了一套训练配方,以提升训练效率与任务泛化能力。
考虑到下游任务的多样性,研究者没有设置特殊的任务切换操作,而是为每个任务使用自然语言作为指令;对于指令,他们构建了音频和文本版本(即音频由 Kimi-TTS 在零样本方式下基于文本生成),并在训练期间随机选择一种;为了增强遵循指令能力的鲁棒性,他们使用大语言模型为 ASR 任务构建了 200 条指令,为其他任务构建了 30 条指令,并为每个训练样本随机选择一条。他们构建了大约 30 万小时的数据用于监督式微调。
如表 1 和表 2 所示,他们基于全面的消融实验,在每个数据源上对 Kimi-Audio 进行了 2-4 个训练周期的微调,使用 AdamW 优化器,学习率从 1e⁻⁵ 到 1e⁻⁶ 进行余弦衰减,使用 10% 的 token 进行学习率预热。


此外,他们还分三个阶段训练音频解码器。首先,使用预训练数据中的大约 100 万小时的音频,对流匹配模型和声码器进行预训练,以学习具有多样化音色、语调和质量的音频。其次,采用分块微调策略,在相同的预训练数据上将动态块大小调整为 0.5 秒到 3 秒 。最后,在 Kimi-Audio 说话者提供的高质量单声道录音数据上进行微调。
评估结果
研究者基于评估工具包,详细评估了 Kimi-Audio 在一系列音频处理任务中的表现,包括自动语音识别(ASR)、音频理解、音频转文本聊天和语音对话。他们使用已建立的基准测试和内部测试集,将 Kimi-Audio 与其他音频基础模型(Qwen2-Audio 、Baichuan-Audio、Step-Audio、GLM4-Voice 和 Qwen2.5-Omini )进行了比较。
自动语音识别
研究者对 Kimi-Audio 的自动语音识别(ASR)能力进行了评估,涵盖了多种语言和声学条件的多样化数据集。如表 4 所示,Kimi-Audio 在这些数据集上持续展现出比以往模型更优越的性能。他们报告了这些数据集上的词错误率(WER),其中较低的值表示更好的性能。

值得注意的是,Kimi-Audio 在广泛使用的 LibriSpeech 基准测试中取得了最佳结果,在 test-clean 上达到了 1.28 的错误率,在 test-other 上达到了 2.42,显著超越了像 Qwen2-Audio-base 和 Qwen2.5-Omni 这样的模型。在普通话 ASR 基准测试中,Kimi-Audio 在 AISHELL-1(0.60)和 AISHELL-2 ios(2.56)上创下了最先进的结果。此外,它在具有挑战性的 WenetSpeech 数据集上表现出色,在 test-meeting 和 test-net 上均取得了最低的错误率。最后,研究者在内部的 Kimi-ASR 测试集上的评估确认了该模型的鲁棒性。这些结果表明,Kimi-Audio 在不同领域和语言中均具有强大的 ASR 能力。
音频理解
除了语音识别外,研究者还评估了 Kimi-Audio 理解包括音乐、声音事件和语音在内的各种音频信号的能力。表 5 总结了在各种音频理解基准测试上的性能,通常较高的分数表示更好的性能。

在 MMAU 基准测试中,Kimi-Audio 在声音类别(73.27)和语音类别(60.66)上展现出卓越的理解能力。同样,在 MELD 语音情感理解任务上,它也以 59.13 的得分超越了其他模型。Kimi-Audio 在涉及非语音声音分类(VocalSound 和 Nonspeech7k )以及声学场景分类(TUT2017 和 CochlScene)的任务中也处于领先地位。这些结果突显了 Kimi-Audio 在解读复杂声学信息方面的高级能力,超越了简单的语音识别范畴。
音频到文本聊天
研究者使用 OpenAudioBench 和 VoiceBench 基准测试 评估了 Kimi-Audio 基于音频输入进行文本对话的能力。这些基准测试评估了诸如指令遵循、问答和推理等各个方面。性能指标因基准测试而异,较高的分数表示更好的对话能力。结果如表 6 所示。

在 OpenAudioBench 上,Kimi-Audio 在多个子任务上实现了最先进的性能,包括 AlpacaEval、Llama Questions 和 TriviaQA,并在 Reasoning QA 和 Web Questions 上取得了极具竞争力的性能。VoiceBench 评估进一步证实了 Kimi-Audio 的优势。它在 AlpacaEval(4.46)、CommonEval(3.97)、SD-QA(63.12)、MMSU(62.17)、OpenBookQA(83.52)、Advbench(100.00)和 IFEval(61.10)上均持续超越所有对比模型。Kimi-Audio 在这些全面的基准测试中的整体表现证明了其在基于音频的对话和复杂推理任务中的卓越能力。
语音对话
最后,他们基于多维度的主观评估,评估了 Kimi-Audio 的端到端语音对话能力。如表 7 所示,Kimi-Audio 与 GPT-4o 和 GLM-4-Voice 等模型在人类评分(1-5 分量表,分数越高越好)的基础上进行了比较。

除去 GPT-4o,Kimi-Audio 在情感控制、同理心和速度控制方面均取得了最高分。尽管 GLM-4-Voice 在口音控制方面表现略佳,但 Kimi-Audio 的整体平均得分仍高达 3.90,超过了 Step-Audio-chat(3.33)、GPT-4o-mini(3.45)和 GLM-4-Voice(3.65),并与 GPT-4o(4.06)仅存在微小差距。总体而言,评估结果表明,Kimi-Audio 在生成富有表现力和可控性的语音方面表现出色。
....
#Diffusion Bridge Implicit Models
无需训练加速20倍,清华朱军组提出用于图像翻译的扩散桥模型推理算法DBIM
论文有两位共同一作。郑凯文为清华大学计算机系三年级博士生,何冠德为德州大学奥斯汀分校(UT Austin)一年级博士生。
扩散模型(Diffusion Models)近年来在生成任务上取得了突破性的进展,不仅在图像生成、视频合成、语音合成等领域都实现了卓越表现,推动了文本到图像、视频生成的技术革新。然而,标准扩散模型的设计通常只适用于从随机噪声生成数据的任务,对于图像翻译或图像修复这类明确给定输入和输出之间映射关系的任务并不适合。

为了解决这一问题,一种名为去噪扩散桥模型(Denoising Diffusion Bridge Models, DDBMs)的变种应运而生。DDBM 能够建模两个给定分布之间的桥接过程,从而很好地应用于图像翻译、图像修复等任务。然而,这类模型在数学形式上依赖复杂的常微分方程 / 随机微分方程,在生成高分辨率图像时通常需要数百步的迭代,计算效率低下,严重限制了其在实际中的广泛应用。
相比于标准扩散模型,扩散桥模型的推理过程额外涉及初始条件相关的线性组合和起始点的奇异性,无法直接应用标准扩散模型的推理算法。为此,清华大学朱军团队提出了一种名为扩散桥隐式模型(DBIM)的算法,无需额外训练即可显著加速扩散桥模型的推理。
- 论文标题:Diffusion Bridge Implicit Models
- 论文链接:https://arxiv.org/abs/2405.15885
- 代码仓库:https://github.com/thu-ml/DiffusionBridge
方法介绍
DBIM 的核心思想是对扩散桥模型进行推广,提出了一类非马尔科夫扩散桥(non-Markovian Diffusion Bridges)。这种新的桥接过程不仅与原来的 DDBM 拥有相同的边缘分布与训练目标,而且能够通过减少随机性,实现从随机到确定性的灵活可控的采样过程。
具体而言,DBIM 在模型推理过程中引入了一个方差控制参数 ρ,使得生成过程能够在随机采样与确定性采样之间自由切换。当完全采用确定性推理模式时,DBIM 能够直接以隐式的形式表示生成过程。这种思想是标准扩散模型的著名推理算法 DDIM 在扩散桥模型上的推广与拓展。

更进一步,DBIM 算法可以导出扩散桥的一种全新的常微分方程(ODE)表达形式,相较于 DDBM 论文中的常微分方程形式更加简洁有效。

在此基础上,作者首次提出了针对扩散桥模型的高阶数值求解方法,进一步提升了推理的精度与效率。

此外,为了避免确定性采样过程中出现的初始奇异性问题,作者提出了一种「启动噪声」(booting noise)机制,即仅在初始步骤中加入适当随机噪声,从而保证了模型的生成多样性,并同时保留了对数据的编码与语义插值能力。

实验结果
作者在经典的图像翻译和图像修复任务上进行了如下实验:
- 在 Edges→Handbags(64×64)和 DIODE-Outdoor(256×256)图像翻译任务中,DBIM 仅需 20 步推理即可达到甚至超越 DDBM 模型 118 步推理的生成质量。当推理步数增至 100 步时,DBIM 进一步提升生成质量,在更高分辨率任务上全面领先。

- 在更具挑战的 ImageNet 256×256 图像修复任务中,DBIM 仅需 20 步推理便显著超越了传统扩散桥模型 500 步推理的效果,实现了超过 25 倍的推理加速。在 100 步推理时,DBIM 进一步刷新了这一任务的 FID 记录。


通过参数 η 控制采样过程中的随机性大小,论文发现确定性采样模式在低步数时具备显著优势,而适当增加随机性能够在较高步数下进一步提升生成多样性与 FID 指标。这与标准扩散模型推理的性质相似。

此外,高阶采样器能够在不同采样步数下一致提升生成质量,增强图像细节。

论文所用训练、推理代码及模型文件均已开源。如果你对 DBIM 感兴趣,想要深入了解它的技术细节和实验结果,可访问论文原文和 GitHub 仓库。
....
#AI「MCP 万能工具箱」
纳米AI放大招!MCP万能工具箱,人人都能用上超级智能体
近些年,AI 领域的技术不断快速迭代,各种新名词层出不穷,MoE、强化学习、智能体、computer-use、A2A…… 对没有技术背景的普通用户来说,这些名词和技术概念无疑会带来巨大的认知成本,让他们望而却步,最终让自己与 AI 的交互之路止步于在聊天框中的简单回答。
MCP 自然也是这些技术概念之一。过去一年,AI 智能体快速迭代,MCP 协议已然成为支撑复杂任务自动化的关键底层能力。然而,眼下这场 MCP 革命,仍旧像是开发者们的专属游戏:协议文档晦涩、工具注册复杂、个性化配置门槛高…… 普通用户大多只能远观,难以真正「上手」。

而现在,情况正在发生变化。4 月 23 日,360 旗下的纳米 AI 宣布推出面向个人用户的「MCP 万能工具箱」。这款产品是针对无技术背景的普通用户打造的,让每个人都能以最低的学习成本掌握前沿的 AI 使用方式。

这款产品不仅全面支持 MCP 协议,还能基于多种大模型底座运行智能体任务,更具备自动调用外部工具、接入 AI 知识库、支持用户自定义任务流程等强大能力 —— 关键是,操作门槛显著降低,完全不需要代码基础,打开一个聊天框就能使用。
目前,超级智能体已开启公测。从模型到协议,再到工具生态和个性化任务编排,看起来纳米 AI 试图用一次产品级的革新,真正把 AI 智能体带入每个人的日常。
那么,纳米 AI 的「MCP 万能工具箱」究竟好不好用呢?为了得到这个问题的答案,已经获得内测资格的进行了一番测试。
亲测万能工具箱
MCP 竟然可以如此简单
使用纳米 AI「MCP 万能工具箱」的门槛非常低,用户只需要下载并安装纳米 AI 应用然后注册登录即可,无需其它任何额外的配置。
进入更新后的「智能体」页面,我们可以看到纳米 AI 对已有智能体进行了分类,包含深度研究、工作和效率、生活助手等多个大类,同时下面也提供了万能工具箱和案例广场入口。

进入万能工具箱,可以看到纳米 AI 目前已经配置了超 100 个 MCP Server(在本文写作期间这一数字从 120 上升到了 132),包括纳米 AI 自研的十几个 MCP 工具以及上百个第三方 MCP 工具,覆盖办公协作、学术、生活服务、搜索引擎、金融、媒体娱乐、数据抓取等多种场景,是国内最大的 MCP 生态。同时,纳米 AI 也支持用户配置自己的 MCP Server。在下文中,我们将使用「工具」一词替代「MCP Server」,至于原因,后文会详细解释。
首先,测试一个读者最喜闻乐见的应用:搜索并整理 arXiv 上近期与某研究主题相关的研究成果。
先搜索一下万能工具箱,发现纳米 AI 预设的工具中已有「arXiv 搜索」,那就无需我们自己配置了。回过头来,我们也能看到纳米 AI 中已有不少支持 arXiv 论文检索的智能体,我们就选择其中的「专业论文搜索」作为我们尝试的第一步。可以看到,该智能体配置了纳米 AI 超级搜索、arXiv 搜索、谷歌学术、学术搜索四个工具,非常符合我们的需求。编写提示词并执行:
检索近一个月 arXiv 上与强化学习相关的研究成果,并按照理论研究、技术改进、应用对它们进行分类,同时对其中的重要进展进行简单解读。
「专业论文搜索」的工作过程如下:

动图以 2 倍速播放
这个任务很简单,智能体仅调用了一次「arXiv 搜索」工具,也因此不到半分钟就完成了任务,分三个类别各自选择了两项代表性研究成果。
接下来试试骑行规划师智能体,使用命令:「重庆观音桥附近有什么好的骑行路线吗?」
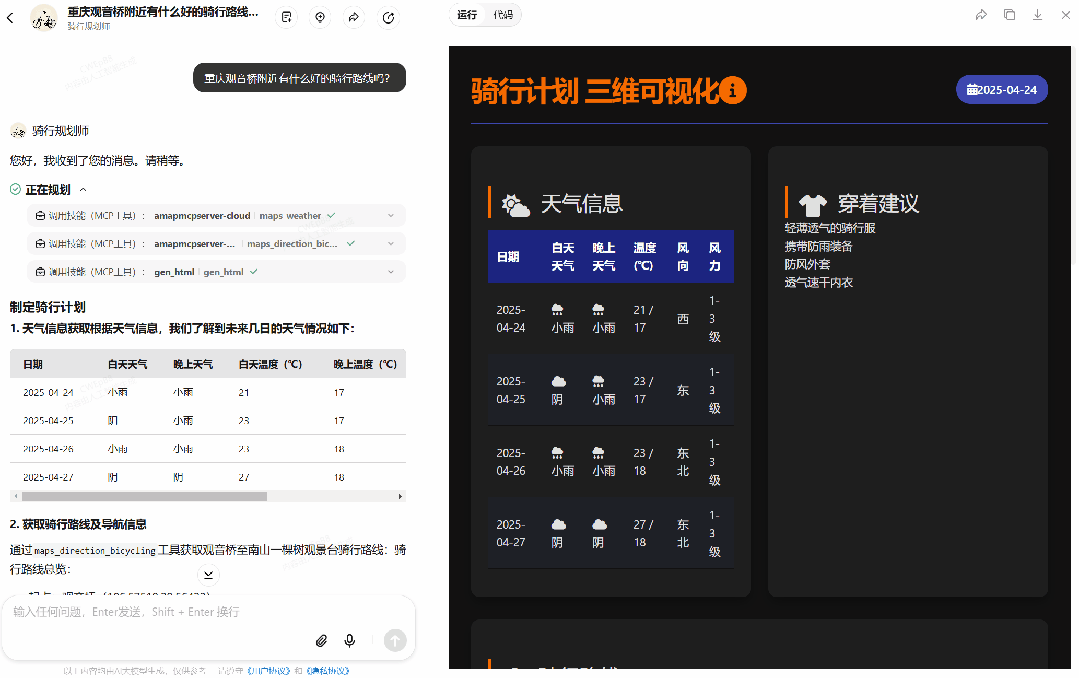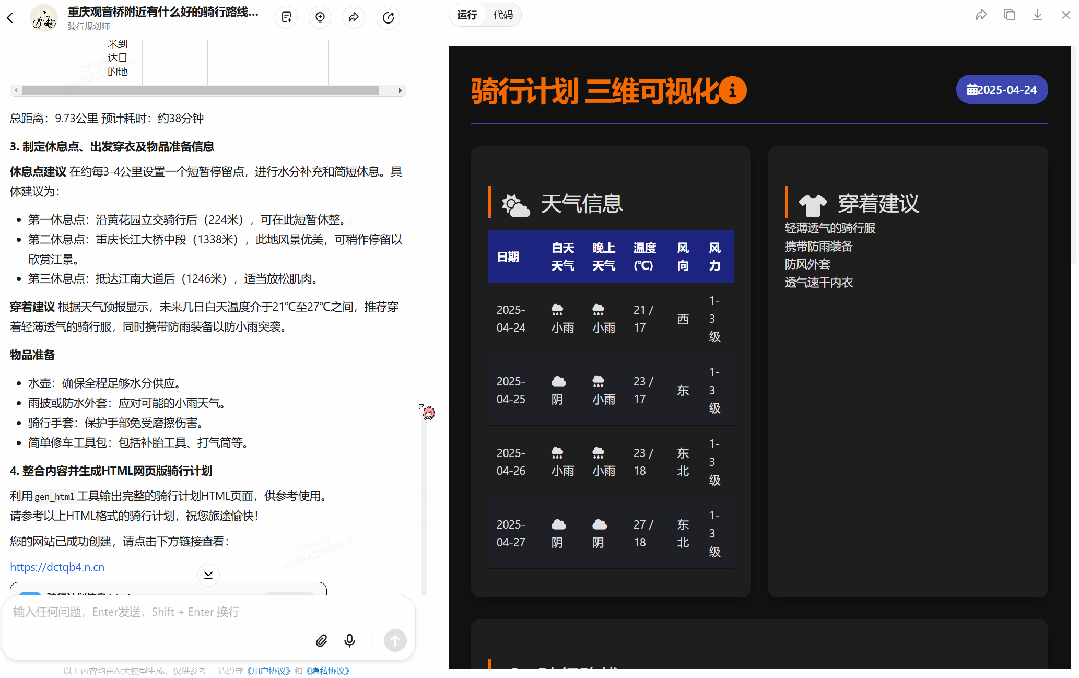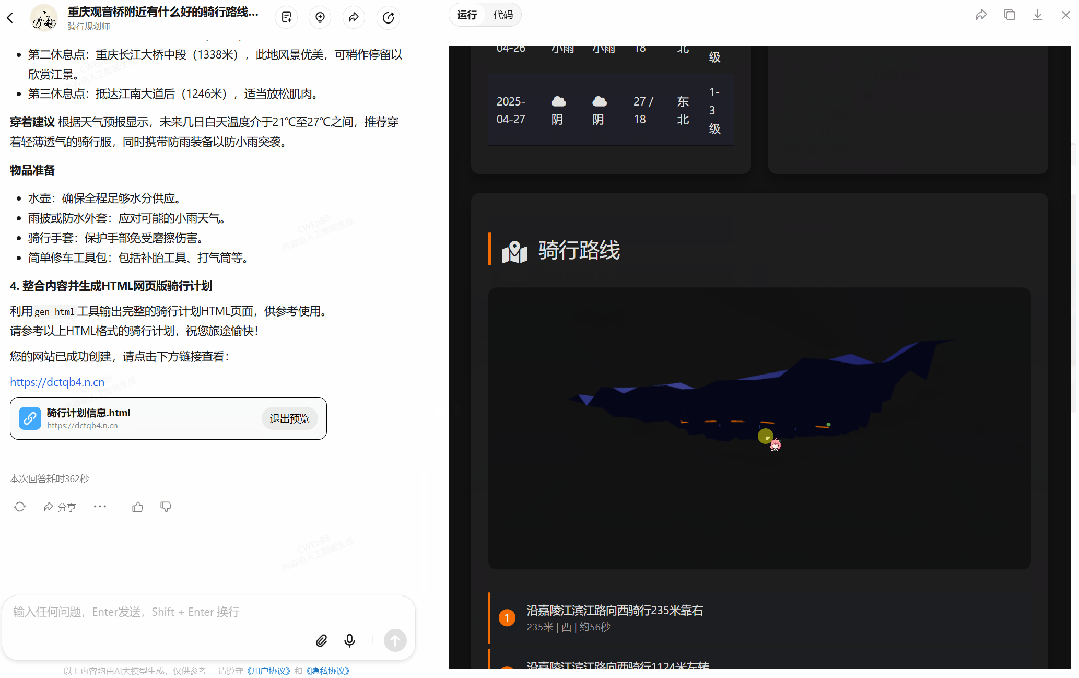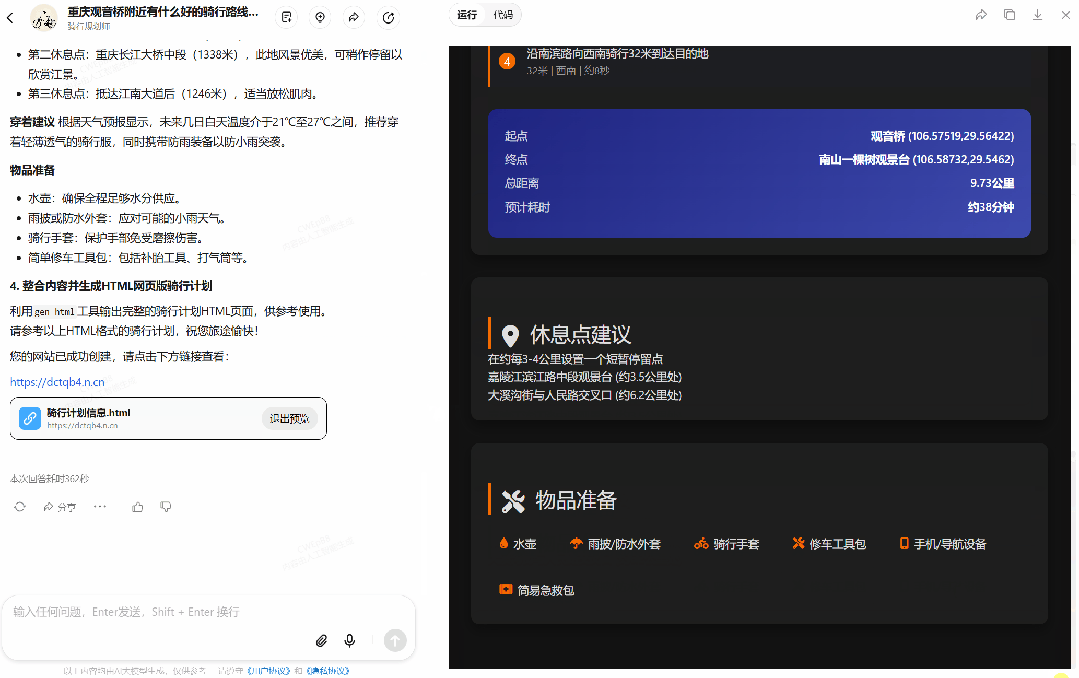
可以看到,该智能体使用了三个工具:amapmcpserver-cloud 的 maps_weather(用于查询天气)和 maps_direction_bicycling(用于设定路线)以及 gen_html(用于生成网页),一共执行了 362 秒,最终得到了如上所示的动态网页。你也可以通过这个链接访问:https://dctqb4.n.cn/。是的,你可以将生成的网页公开分享出去!
接下来,再上难度。这一次我们的需求是「搜索网络,分析当前的女装流行趋势,出具一份女装流行元素分析报告」。这一次我们将直接使用纳米 AI 的「深度研究智能体」,该智能体可以根据用户的具体需求选择使用合适的工具,其中不仅包括 MCP Server,也包括使用内置的浏览器来完成各种 computer-use 任务。当然,也因此,深度研究智能体执行一个任务的时间往往会长得多,可达十几分钟。
在执行任务时,深度研究智能体会先根据任务需求规划所要执行的步骤,然后会按照规划的步骤逐步执行。
针对这个具体的任务,深度研究智能体生成的执行步骤如下图所示。

首先,它在多个网站上搜索了与当前女装流行趋势相关的内容,然后对搜索到的内容进行了分析,并对结果进行了可视化。最后,它给出了最终报告。
在这个过程中,它调用了三次位于本地的搜索工具 aiso_do_search、一次数据爬取工具 360_crawl、九次云代码沙盒工具 cloud-sandbox,一次总结工具 summary 以及一次网页生成工具 gen_html。
最终,我们得到了一份长达 30 页的深度报告,其中涵盖流行风格主题分析、流行色彩趋势、热门款式与元素分析、流行元素综合评价、面料与工艺趋势、搭配建议与应用六大板块,远超预期地完成了我们最初的一句话任务。

报告中截取的几页内容
以下视频展示了纳米 AI 深度研究智能体完成任务的全过程:
,时长05:35
以 4 倍速播放
不仅如此,纳米 AI 还生成了一个动态网页,可以更生动地展示所得到的分析结果:https://dscmxu.n.cn
另外,考虑到谷歌刚不久前发布了第一季度财报,我们也可以让纳米 AI 的「首席行业洞察官」智能体帮助我们解读一番。
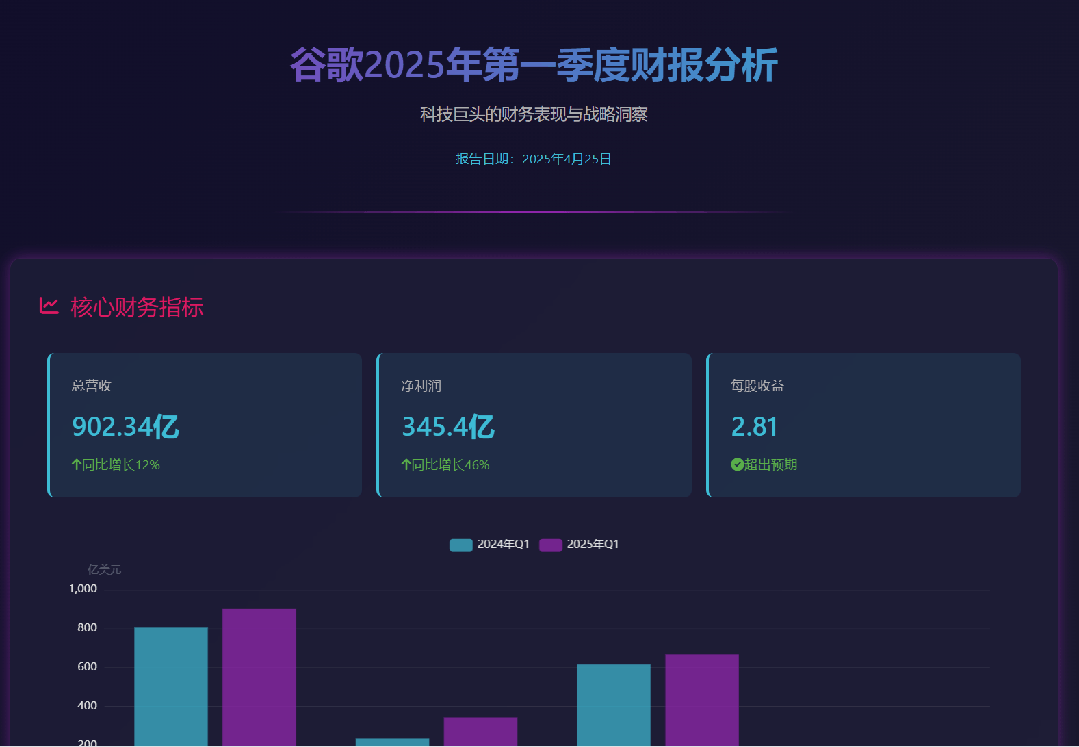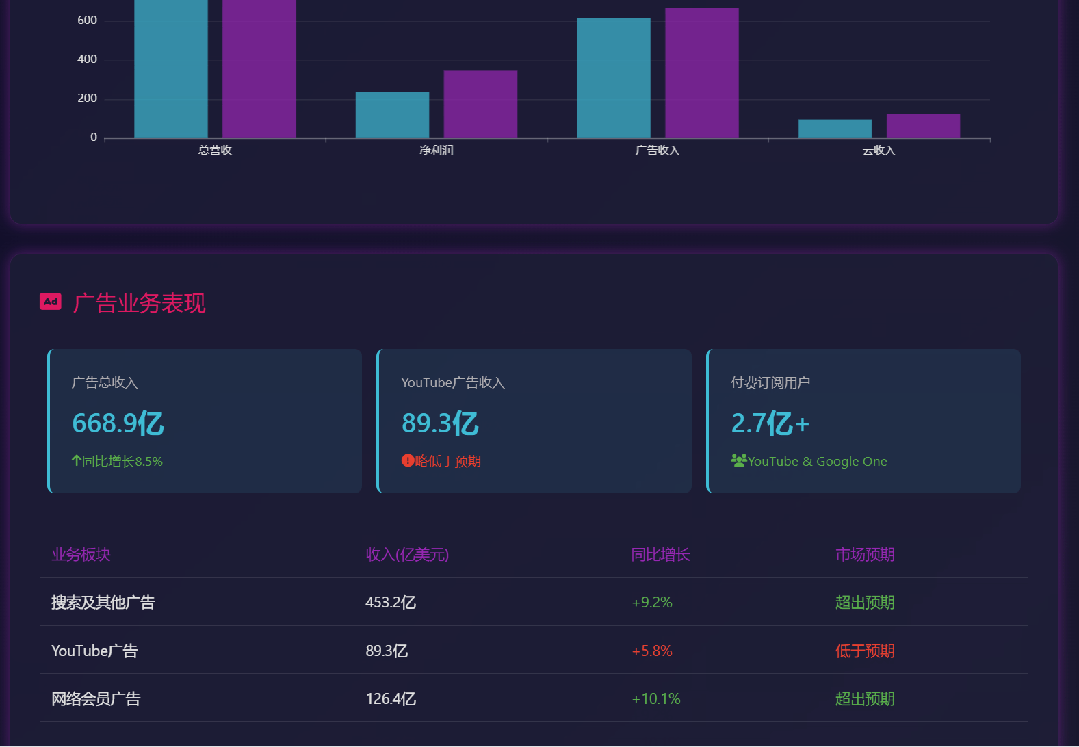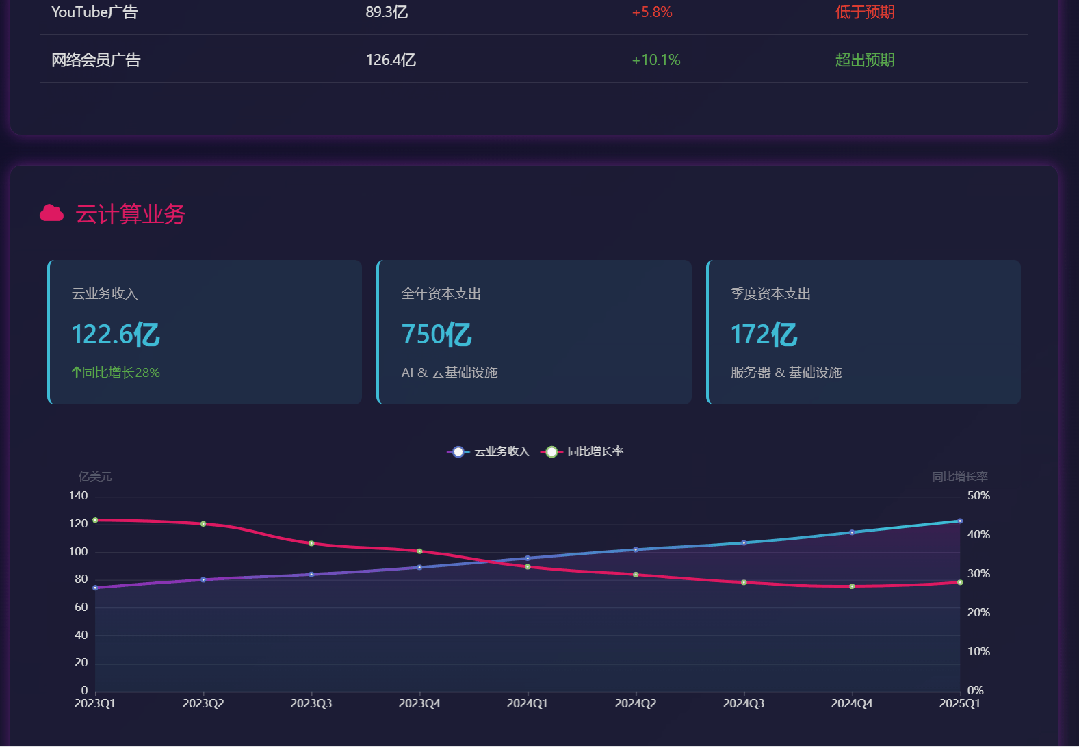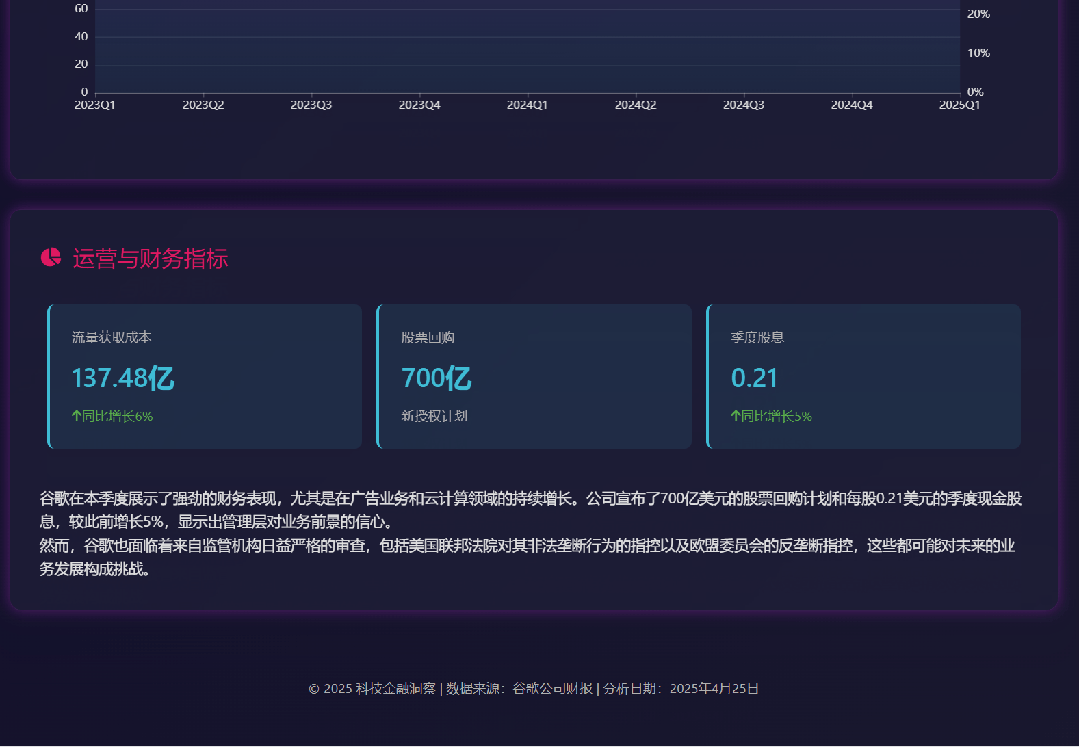
其网页版结果请访问:https://wl9w9g.n.cn/ ,而工作全过程则可见以下视频:
,时长04:41
再试试用纳米 AI 来为最近大火的电视剧《蛮好的人生》编写一个适合发布在小红书上的影评,使用预置的小红书浏览机器人就能很好地完成任务。

慎看!内容会有剧透。
以下视频展示了纳米 AI 工作的全过程。
,时长05:52
可以看到,在这个过程中,纳米 AI 用到了两个与小红书有关的工具,包括用于在小红书上收集信息的 collect_relate_info_redbook 以及用于生成小红书内容的 red_book_generate;此外还用到了 browser_automation_task—— 该工具可以打开纳米 AI 应用中的内置浏览器来执行任务。使用合适的指令,你也能借助这个工具来一句话完成订火车票、发微博、记笔记等操作。
最后,在纳米 AI 上,用户也能非常方便地配置自己的 MCP。比如这里,我们仅通过几个参数设置就成功配置了一个用于查询和分析 Obsidian 笔记的工具。

然后,只需配置一个调用该工具的智能体,我们就能在纳米 AI 中智能化地检索和分析我们收藏的笔记了,以下视频展示了一个示例:
,时长00:58
以上案例只是纳米 AI 能力的冰山一角。借助 MCP 万能工具箱,用户能做到的事情还有很多,比如爬取和搜索信息、生成图像和视频内容、让 AI 整理你的 flomo 碎片笔记并将结果放入到 Notion 工作区、分析股票、寻找去葡萄牙旅行的最划算航班路线、指定旅行或健身计划、制作公司报表、管理云端存储库或本地文件…… 限制你的真就只有你的想象力!
将 MCP 隐于万能工具箱中
纳米 AI 是这样做的
MCP,全称 Model Context Protocol(模型上下文协议),是 Anthropic 最早于 2024 年 11 月发布的一个开放协议可以说是连接大模型与真实世界的重要「桥梁」—— 它让模型不仅能回答问题,更能像人一样调用工具、获取数据、执行任务。今年以来,随着越来越多的企业采用该协议,它已经成为 LLM 使用工具方面事实上的标准,推动了 AI 智能体发展潜力的进一步释放。
然而,对于大多数用户而言,MCP 协议的典型标签是「复杂」、「技术门槛高」与「开发者专属」。如何把这套原本属于专业工程师的能力,交到每一个普通人手中呢?
针对这一现实的难题,360 给出的答案是:不再教你理解 MCP,而是直接把它封装成一套「看得见、点得动、结果可预期」的万能工具箱。
一、从概念简化,到交互降维
纳米 AI 团队最先做的是概念的翻译:用户不需要理解什么是 MCP Server 或 API Key,他们只需要知道这是一项可以用的「工具」或「技能」—— 正是我们前文使用「工具」一词的原因。将原本晦涩的协议接口,包装成「搜索」、「写作」、「数据分析」等一目了然的工具标签,大大降低了用户认知门槛,让用户更直观地理解所谓 MCP Server 之于 AI 大模型的意义。而这正是纳米 AI 万能工具箱的设计哲学。这背后,是纳米 AI 对 MCP 协议的重新封装与界面层的工程重构。
用户在界面中看到的是简单的选择和拖拽,实际上,背后调度的是超过 100 个由纳米 AI 自研或优选集成的 MCP Server。这些工具覆盖了办公、学术、金融、搜索引擎、网页抓取、图像处理等场景,用户无需写一行代码,就能让大模型自动调用这些「外脑」,完成复杂任务链。

纳米 AI 甚至内置了 Firecrawl、Brava Search 和高德地图等多个 MCP 工具的 API Key
二、打通模型与工具之间的「最后一公里」
过去,即使大模型拥有强大的语言理解能力,却始终困于「工具调用」的孤岛效应。纳米 AI 的做法是将 MCP 协议作为中介语言,从根本上打通了「大模型 + 工具」的协作机制。
这不仅解决了调用的问题,还极大扩展了模型的实际能力边界。例如,用户只需告诉智能体「帮我生成一份英伟达股价分析报告」,智能体就能自动拆解任务步骤、调动搜索引擎、抓取页面内容、生成分析图表,并输出一份结构清晰的报告。期间可能调用了 5 到 7 个工具,但用户只看到一个结果页面。
这正是 MCP「工具组合」能力的体现:它允许智能体像人一样自主调度资源、规划流程,并在运行中进行试错反馈与自我优化,形成高度拟人的任务解决路径。
三、本地运行、安全可信:技术栈深度打磨
与很多「云端智能体」不同,纳米 AI 选择了一条更难但更具前景的路径:在本地部署 MCP 客户端,赋予用户更大控制权。
这带来了至少三个关键优势:
调用自由:本地智能体可以访问用户的文件系统、调用浏览器、调取数据库,实现真正的个性化任务处理。
跨越壁垒:针对 AI 的独特需求,360 为纳米 AI 打造了专用的 AI 浏览器,并针对中国主流平台进行了适配,其能够突破登录墙、人机验证、信息流干扰,自动完成登录、滑动验证等操作。
沙箱保障:基于 360 安全技术积累,纳米 AI 还将在未来引入本地运行时沙箱,其能够实时监测、预警并限制大模型可能误操作本地文件,保障数据安全。
这一整套体系,不只是让用户「能用」,而是「安全、高效、可扩展地用」。
四、面向海量用户:构建真正开放的 MCP 生态
纳米 AI 不仅封装了 MCP 工具,还率先打通了开放的技能生态。目前,这个月度访问量已经突破 4 亿的平台已上线超过 100 个高质量 MCP 工具,更多的第三方 MCP Server 正在进驻中。用户可以自由上传、复用、组合工具技能,打造属于自己的 AI 智能体。
对普通用户来说,这意味着不再是「用别人设定的 AI」,而是可以根据自己需求构建个性化的 AI 助手。论文分析、数据生成、趋势监测、网页搭建、股票预测…… 只要有需求,就有工具可以组合使用,就有任务可以自动执行。
而对于整个行业而言,这意味着智能体技术正在从「封闭系统」走向「生态网络」阶段,工具、模型、任务之间将不再孤立,而是以 MCP 为共通语言,联动出前所未有的智能协作格局。
技术壁垒已破
智能体向 C 端下沉
曾几何时,智能体的使用门槛还高高挂在开发者的门楣上。如今,随着纳米 AI 「MCP 万能工具箱」的推出,MCP 这一被誉为 AI 自动化基建的协议,首次以近乎「傻瓜式」的形态进入普通用户的视野。正如 360 集团董事长周鸿祎在发布之前的分享会上说的那样:「agent 里自动调用了什么 MCP Server,用户其实不需要知道。」凭借万能工具箱,纳米 AI 正在打破 MCP 的技术壁垒,让智能体进一步向 C 端下沉。
把 MCP 做成「工具箱」,说来轻巧,做来艰难。这不仅考验技术整合能力,也考验产品思维与用户理解的「共情力」。纳米 AI 正在做的,是将复杂封装于内核,将自由交给用户 —— 让每一个普通人都能像开发者那样拥有「调用 AI 世界」的权限。
这一过程并非简单的可视化界面搭建,而是一场深层次的 AI 应用范式变革:智能体不再只是能说会答的模型,而是拥有能力调度、工具调用、任务完成能力的真实合作者。
自此,MCP 已经真正开始走向 C 端用户,这或将是一个值得铭记的历史起点。
....
#美国政府「AI行动计划」万言书发布
OpenAI与Anthropic呼吁联手封锁中国AI
就在刚刚,美国政府曝光了各界对「AI行动计划」的全部政策建议。OpenAI措辞激烈地表示,DeepSeek让我们看到,必须马上锁死中国AI,必须限制高端GPU芯片和模型权重流向中国!Anthropic同样呼吁:必须立马补上H20这一关键漏洞,并且严控H100的门槛。
AI战打到现在,下一步怎么走?
4月25日,美国网络与信息技术研究与发展(NITRD)公开了美国各界就「AI行动计划」提交的全部书面意见。
网站链接:https://www.nitrd.gov/coordination-areas/ai/90-fr-9088-responses/
拜登的AI行政令,在现在这届政府是行不通了,现在,特朗普政府需要一个全新的AI行动计划,继续保持美国的AI领先地位。
本次收到的意见总数,达到了夸张的10068份!
这些建议来自美国的各行各业,上至美国学界、行业团体、私营部门组织、美国各州政府,下至热心市民。
在这一万多份意见中,共有292家公司发声
其中最亮的,莫过于OpenAI和Anthropic了。
这两家公司的措辞一致的强硬——必须对中国加强技术封锁!
具体来说,就是必须限制高端GPU芯片和模型权重流向中国,而且美国AI必须在和中国的竞争中取胜。
Meta则站在了这两家的对立面,一如既往地强调开源AI。因此,他们认为对开源模型进行出口管制是根本不可行的,这只会导致美国拱手让出主导权,让全球开发者转向中国的开源模型。
异曲同工的是,谷歌也同样批评了拜登政府的AI出口管制,建议特朗普政府在对待出口管制上,一定要精心设计,避免让美国公司处于劣势。
微软和亚马逊,则默契地选择不谈此类话题,只给出了一些一般性建议。
耐人寻味的是,英伟达、苹果、特拉斯三家巨头,并未提交任何意见,马斯克的xAI也保持了沉默。
有趣的是,很多美国的「热心市民」对于AI持有悲观的态度,他们的意见简单、直接。
相比之下,机构、巨头和学界的回复考究、详细,充分显示了他们的重视态度。
显然,在这场史无前例的AI革命中,每个人都无法置身事外。
AI巨头共同的声音:美国政府责任重大
总的来说,传统的科技巨头们在对待AI经济、出口管制以及AI监管等关键议题上有很多共性的意见,但也有各自的侧重,以及对AI竞争和安全治理的不同理解。
不过至少有一点是一致的。
他们一致认为AI至关重要,认为美国应该加大AI政务应用策略。
OpenAI:必须锁死中国AI,包括芯片和模型
OpenAI对于AI,尤其是中美AI的竞争,一直持有激进的态度。
在三月中旬的一份长达15页的上书中,OpenAI矛头直指DeepSeek。
OpenAI直接呼吁美国政府:立法禁止DeepSeek!同时还呼吁美国联邦政府给予AI公司豁免权,否则,中美之间的AI竞赛就已经结束了。
在这次的意见中,OpenAI认为AI行动计划的核心目标,就是维持美国在全球AI领域的领导地位,并利用AI促进经济繁荣和个人自由。
在文件一开头,OpenAI就提出了三个scaling原则。
1.AI模型的智能水平大致与训练和运行所使用资源的对数成正比。
OpenAI表示,自己已经展示了如何通过推理阶段的算力扩展智能。这些扩展规律在多个数量级上都非常精确,因此,智能水平线性增长带来的社会经济价值是超指数级的。
2.使用特定水平AI能力的成本大约每12个月下降10倍,且成本下降会促使使用量激增。
举例来说,从2023年初的GPT-4到2024年中的GPT-4o,单词生成的价格下降了大约150倍。因此,AI使用成本的下降速度比摩尔定律还要惊人。
3.改进AI模型所需的时间正在持续缩短。
过去,一台计算机在某个基准测试中击败人类平均需要20年;后来缩短到5年;现在只需1到2年,而且这种趋势短期内不会停止。
接下来,OpenAI的的尖锐措辞就直指DeepSeek。
它激烈陈词道:美国正与力图在2030年成为全球领导者的中国展开竞争。
这就是为什么DeepSeek最近发布的R1模型引发关注——并不是因为其性能(尽管R1的推理能力令人印象深刻,但与美国几款主流模型相比最多算持平),而是它反映了当前这场竞争的态势。
OpenAI表示,模型在关键基础设施或其他高风险场景中的使用,存在巨大的风险,因为它可能被强制要求操控模型,以制造危害。
它还无耻地写道:「这些模型在生成如身份欺诈、侵犯知识产权等非法或有害活动指南时也更加宽松,这反映出侵犯美国知识产权被视为优势而非缺陷的态度。」
OpenAI指出,相比于美国公司,中国AI公司有诸多优势。
比如国家可以迅速调动数据、能源、技术人才、芯片产业所需的巨额资金等种种资源。
能利用美国各州分别制定行业法规所带来的「监管套利」机会(这些政策会让美国AI企业面临严重的合规负担)。
还能利用版权保护的漏洞进行「版权套利」(这就让其他公司他们无需遵守欧美的知识产权规定,仍然可以获得相同的数据资源,让美国AI实验室在竞争中处于劣势)。
因此,OpenAI对政府有以下建议。
一套保障创新自由的监管策略
一套输出民主型AI的出口管制策略
一套促进学习自由的版权策略
一套抓住基础设施机遇推动增长的策略
一套雄心勃勃的政府AI应用策略
接下来,在「出口管制」这一部分,OpenAI继续建议,把全球分为三级。
一级包括美国的盟友,以及那些承诺遵循美国提出的AI原则、具有相对较低风险的国家和地区,即能保证美国AI基础设施(例如芯片)不会被转移到非一级国家和地区。
二级包括那些有过黑历史,未能防止受控芯片出口和其他美国开发的知识产权被转移到或被三级使用的国家和地区。
三级包括中国及其他受到美国武器禁运的国家和地区。这些应继续受到严格的AI系统出口管制,包括现有的对先进芯片的出口管制。
对于三级国家和地区,OpenAI呼吁严格禁止使用其生成的设备(如芯片)和侵犯用户隐私、产生安全风险的模型。
Anthropic:控制H20,严防走私!
Anthropic预计,在未来2-4年内,前沿AI模型将取得显著的能力进展,特别是在具有重大安全影响的领域,如生物武器和网络安全风险等。
Claude 3.7 Sonnet展示了在支持生物武器开发方面令人担忧的进展。
而Anthropic旗帜鲜明地表示,美国的国家安全已经到了很紧迫的程度!
在它看来,现在迫切需要保护关键技术基础设施和知识产权免受外国威胁,增强美国的安全。
而且美国政府应当进行投资,以培养一个强大的AI开发和部署生态系统,促进美国的繁荣。
Anthropic坚信,强大的AI系统会在2026底或2027年初出现,就如CEO Dario Amodei在他的《爱的机器》一文中讨论的一样。
而这个强大AI,应该被视为美国关键的国家资产。
接下来,Anthropic也提到了DeepSeek,它的原话如下。
强大AI评估能力的重要性,今年早些时候发布的DeepSeek-R1得到了突出展示。
它提到,R1能回答大多数生物武器化的问题,在它看来这十分危险。
因此,美国政府需要快速评估未来模型(无论是国外还是国内的)是否具备安全属性的能力。
同样,Anthropic强调,美国应该加强出口管制,扩大美国的领先优势。
1. 控制H20芯片
当前的出口管制不适用于H20,这是一款2024年推出的高内存芯片,计划向中国销售,可以用于训练和运行强大的模型。虽然这些芯片在初期训练中不如H100,但同样优秀。因此特朗普政府需要关闭这一漏洞。
2. 签署政府对政府协议,防止芯片违规流通
作为托管美国公司超过50,000颗芯片数据中心的前提条件,美国应要求高风险的国家和地区遵守政府对政府协议,该协议要求:(1)它们的出口控制系统与美国保持一致;(2)采取措施防止芯片流通到中国;(3)停止本国公司与中国合作。
3. 仔细审查并提高对二级国家和地区的门槛
目前,扩散规则允许来自二级国家和地区的先进芯片订单(少于1,700颗H100,约4000万美元的订单)无需审核即可进行。这些订单不计入规则的上限,无论购买方是谁。
Anthropic表示,这些门槛存在走私风险,因此建议政府考虑减少二级国家和地区无需审核即可购买的H100数量。
4. 增加对工业安全局(BIS)出口执法的资金支持
Meta:保护美国开源AI!
Meta强调了开放源代码AI的重要性:开放源代码AI是美国保持技术优势、促进创新和经济发展的关键。
它举例说,DeepSeek的发布就说明,即使实施闭源政策,也无法阻止技术向中国的扩散。
Meta表示,为了跟在中国的竞争中取胜,美国必须通过开源AI,促进和鼓励美国开源AI的出口。「开源模型对于美国在与中国的人工智能竞争中取胜至关重要,并确保美国在人工智能领域的主导地位。」
在它看来,如果对开源模型进行出口管制,就会使美国彻底退出这场竞争,这就会让中国公司有机会制定全球的AI标准,在全球技术生态系统中植入他们的价值观。
Meta强调,美国的全球竞争优势,就是去中心化和开放的创新。通过出口管制关闭模型,阻止中国获得美国模型,将是无效的,只会削弱美国的利益。
它举例说,DeepSeek的发布就说明,即使实施闭源政策,也无法阻止技术向中国的扩散。
Meta提出了三大核心建议,以确保美国在AI领域的持续领导地位:
1. 保护并推广美国开放源代码AI
促进开放源代码AI的出口,避免对开放模型实施出口管制。政府优先采用开放源代码AI,提升政府效率、降低成本,并增强国家安全。
2. 减少创新障碍,保持全球技术领导地位
简化数据中心的能源和建设审批流程,推动先进核能技术发展,避免各州AI法规的碎片化,防止对创新造成阻碍。
加快宽带和海底光缆部署,优化联邦土地上的光纤网络审批流程。
3. 在国际上捍卫美国技术利益
保护美国企业免受欧盟等地区的高额罚款和歧视性监管。
应对欧盟AI法案的负面影响:避免欧盟的过度监管损害美国企业的竞争力。防止外国政府通过反垄断审查限制美国科技公司的创新和并购活动。
比起上面几方亮点满满的发言,接下来两大巨头的建言,相对而言就比较官方了。
谷歌:加强AI投资和国际合作
谷歌建议,政府要关注三个关键领域:AI投资、政务AI、国际合作。
1. 加大对AI的投资
政府与产业界协同合作;实施平衡的出口管制政策,兼顾国家安全和企业利益;持续资助基础AI研发;制定有利创新的全国级政策框架。
2. 加速并现代化政务AI应用
政府应完善公共采购规则,促进云解决方案间的互操作性和数据便携性,简化采购流程,推动数字化转型。
制定统一的数据标准和API,建立敏捷的授权流程。
同时,加强与私营部门合作,保障关键基础设施和网络安全,采用多云多模型方法用于国家安全。
3. 在国际上推动有利于创新的AI发展路径
建议美国政府推动市场导向、被广泛采用的前沿AI模型技术标准与安全协议;制定量身定制的协议和标准,识别并应对前沿AI系统可能带来的国家安全风险; 抵制限制性的外国AI政策壁垒。
与OpenAI类似,谷歌也主张放宽对AI训练限制,要求「合理使用」知识版权。谷歌希望确立其与竞争对手使用公开可用数据(包括受版权保护的数据)进行训练的权利。
据报道,谷歌已使用公开的版权数据训练了多个模型,被指控谷歌在进行训练前未通知版权方并支付报酬。
美国法院尚未裁定「合理使用」原则是否有效地保护AI开发者免受知识产权诉讼。
微软:成为政府值得信赖的合作伙伴
微软表示愿意成为政府值得信赖的合作伙伴,提出以下三个建议:
1. 加速美国AI发展
2. 保护公众、加强国家安全
3. 投资科学研究与建立基于科学的AI标准
微软认为要想在全球范围内持续保持美国在AI领域的创新与领导地位,就必须实现政府与私营部门的深度协同,共同挖掘和发挥美国在本土的全部潜力。
此外,还要依托AI技术栈各个层面的企业之间的持续合作,这些企业从芯片设计商,到超大规模云服务提供商,再到AI模型开发者,构成了完整的AI生态体系。
此外,政府与企业都需要能够获取行业领先与开源模型的渠道,以在性能、安全和成本之间取得最佳平衡。
而且,美国还应该投资科学研究与AI标准体系建设。
特朗普:AI行动计划
早在2025年1月23日,美国就公布了新任总统Trump签字的美国总统行政命令(行政命令 14179),旨在消除美国在AI领域领导地位的障碍。
文末是特朗普的签名
根据这项行政命令,科技政策办公室(OSTP)通过网络和信息技术研发(NITRD)国家协调办公室(NCO)和国家科学基金会,于2025年2月6日发布了一份关于制定AI行动计划的信息请求(RFI,Request for Information)。
这次征求意见的截止日期为3月15日。
通过这份RFI,OSTP和NITRD NCO向公众征求了意见,包括学术界、行业团体、私营部门组织、州、地方和部落政府以及任何其他感兴趣的相关方。
这「万份建言」中,个人意见达到了9313份,可见民众对于这份重磅政策文件的高度期待。
当然,最能影响最终方案制定还要属那几家重量级的企业。
特朗普的「灵魂三问」
现任OSTP主任是Michael Kratsios。
去年12月22日,特朗普提名技术专家Michael Kratsios担任OSTP主任和总统科技助理。
在3月26号的一封白宫公开信中,特朗普对Michael Kratsios发出了灵魂三问。
第一:美国如何确保自己在关键和新兴技术领域(如AI、量子信息科学和核技术)继续保持无可匹敌的世界领导地位,并保持对潜在对手的技术优势?
第二:如何振兴美国的科学和技术事业——追求真理,减少行政负担,赋能研究人员实现突破性的发现?
第三:如何确保科学进步和技术创新推动经济增长,并改善所有美国人的生活?
在这10068份对于AI的意见中,就藏着这三个问题的答案。
参考资料:
https://www.nitrd.gov/coordination-areas/ai/90-fr-9088-responses/
....
#Satori
AR智能革命!Satori系统读懂人类意图,科幻电影场景成现实
团队由 IEEE 会士,纽约大学教授 Claudio Silva 和纽约大学研究助理教授钱靖共同指导。 论文由Chenyi Li和Guande Wu共同第一作者。
在无数科幻电影中,增强现实(AR)通过在人们的眼前叠加动画、文字、图形等可视化信息,让人获得适时的、超越自身感知能力的信息。无论是手术医生带着 AR 眼镜进行操作,还是智能工厂流水线前的例行检查、或是面对书本时 AR 快速查找翻阅的超能力,是这一切只为一个最终目的——通过适时的信息辅助我们。

直到今日,大部分 AR 辅助依然停留在需要人工远程接入辅助的层面,与我们期待的智能的、理解性的、可拓展的 AR 辅助相差甚远。这也导致 AR 在重要产业和生活应用中的普及受到限制。如何能让 AR 在生活中真正做到理解用户、理解环境、并适时的辅助依然面临巨大挑战。

Satori 系统自动识别用户称重 11 g 咖啡的展示
这一切随着 Satori 系统的诞生即将成为过去。来自纽约大学数据与可视化实验室(NYU VIDA)联合 Adobe 的研究人员融合多模态大语言模型(MLLM)与认知理论 BDI(Belief-desire-intention theory)让 AI 首次真正意义的去理解使用者的行为、目标以及环境状态,最终达到根据不同场景自动适配指示内容,指示步骤,与判断辅助时机。让 AR 辅助接入智慧核心,向泛化应用、智能交互迈进了里程碑的一步。
- 论文标题:Satori: Towards Proactive AR Assistant with Belief-Desire-Intention User Modeling
- 论文链接:https://arxiv.org/abs/2410.16668v2
- Github:https://github.com/VIDA-NYU/satori-assistance
Satori 创新介绍
创新点一:结合 BDI 模型让 AI 理解用户行为和场景关系
通过 AR 眼镜让 AI 拥有跟用户共同视角的「xx感知」,成功的让 AI 通过认知模型 BDI 理解用户的动作行为及其短期目的。BDI 把人的行为分解成对周围世界的理解(Belief),对总体目标的判断(Desire),和为达目标进行的动作行为(Intention)三个部分。
本质上,BDI 强调人是主动性体(agentive being),做出的行为是基于对环境的理解和内部目标的组合,因此我们使用 AI 以多模态数据的模拟人接受信息和应对目标的方式,适合短期以行为目标为主的的 AR 辅助。

这使得 AR 眼镜可以通过 AI 加持实时判断用户行为背后的目的,不再是单纯的对于行为本身的判断。
创新点二:大语言模型结构认知
Satori 系统以模块化组织 MLLM,将图像识别、语义理解、用户交互历史上下文解耦处理,并统一纳入 BDI 认知架构中。通过将视觉感知模块(如 OWL-ViT 与 DETR)与语言推理模块(MLLM)分层协作,系统能够从用户的行为动态构建 Belief 状态、识别任务目标,推理出即时意图。
该模块化结构不仅增强了推理透明度与可解释性,还显著提升了系统的泛化性与跨任务适配能力,展示了多模态大模型在xx智能中的结构认知潜力。

自动生成带有动作和箭头方向的指示图片
创新点三:AI 自动生成多模态指示
在辅助过程中,AI 生成了适时的、应景的、易理解的图片以及文字。在图像层面,Satori 使用 DALLE-3 与场景感知(Belief)模块自动生成与当前任务阶段精准匹配的视觉提示(如剪刀与花的动作关系,与花瓶的空间位置关系),给用户直接的视觉指引、减少语义误解。
这项技术同时也用在了文字生成中,在基础文本上追加对场景物体,用户交互关系的描述(如「把花插入花瓶」变为「把花插入蓝色花瓶」)。此创新让 AI 更具备操作引导的即时性与可视化表达能力,大幅提升了 AR 辅助的清晰度与实用性。


创新点四:双系统动作完成检测方法减少用户等待时间,增加提示准确率
AR 辅助中一大挑战在于任务的复杂度影响了 AI 判断成功率和速度。步骤越复杂、动作越多,AI 一次性判断的噪音和不确定性越大。因此,Satori 团队创新地将每个步骤分成多个更明确,易判断的小目标(checkpoints),来完成对总体步骤的确认。例如:「剪花」任务中的「剪掉枯叶」步骤,会有「拿剪刀」,「对准枯叶」,和「完成剪切」三个小目标,系统判断这些是否完成后便可触发下一提示。

Satori 使用双系统理论(Dual Process Theory)将 AI 的反馈分为「快速反应+理性结构」。动作识别由一个轻量 LLM 完成快速行为完成判断,以高容量 LLM 补充结构性语义分析,通过交互设计机制将二者节奏对齐,确保系统既具响应性,又具智能表达力。

团队所提出的模块化多模态推理框架,不仅在技术层面上展示出对 AR 交互场景的高度适配性,更为未来跨平台、多领域的智能辅助系统奠定了方法论基础。系统核心可灵活部署于 HoloLens、Vision Pro、或者轻量级智能眼镜如 Rokid、INMO、雷鸟、和 Nreal 等不同硬件平台。

在 AI 与大语言模型快速发展的今天,无疑是 AR 技术迈向实用性的一次新的机遇。无论你是 AI、AR 的爱好者,或者是在学界,工业界的专业人士,都欢迎关注 AR 辅助这个正在觉醒的未来。
....
#大规模语言模型:从理论到实践(第2版)
《大规模语言模型:从理论到实践(第2版)》是一本理论与实践并重的专业技术书,更是AI时代不可或缺的知识工具书。任何人都能在本书中找到属于自己的成长路径。
在人工智能浪潮席卷全球的今天,大语言模型正以前所未有的速度推动着科技进步和产业变革。从 ChatGPT 到各类行业应用,LLM 不仅重塑了人机交互的方式,更成为推动学术研究与产业创新的关键技术。
面对这一飞速演进的技术体系,如何系统理解其理论基础、掌握核心算法与工程实践,已成为每一位 AI 从业者、研究者、高校学子的必修课。
2023 年 9 月,复旦大学张奇、桂韬、郑锐、黄萱菁研究团队面向全球学术界与产业界正式发布了《大规模语言模型:从理论到实践》。短短两年,大语言模型在理论研究、预训练方法、后训练技术及解释性等方面取得了重要进展。业界对大语言模型的研究更加深入,逐渐揭示出许多与传统深度学习和自然语言处理范式不同的特点。例如,大语言模型仅需 60 条数据就能学习并展现出强大的问题回答能力,显示了其惊人的泛化性。然而,本书作者们也发现大语言模型存在一定的脆弱性。例如,在一个拥有 130 亿个参数的模型中,仅修改一个特定参数,就可能导致模型完全丧失生成有意义信息的能力。
这些发现促使本书的作者「复旦大学 NLP 团队」张奇、桂韬、郑锐、黄萱菁几位老师对本书第 1 版进行大幅修订升级(增加内容超过 40%),系统整合 AI 领域最新研究成果与技术进展,为广大读者带来更前沿、更实用的知识体系与工程实践指导。无论你是渴望深入理解 LLM 原理的学者,还是希望将 AI 能力融入产品的工程师,亦或是对人工智能充满兴趣的学习者,这本书都将为你提供系统、权威且极具实操价值的知识指引。
第二版核心升级
聚焦前沿技术
深度剖析 MoE(混合专家模型)、强化学习、多模态、智能体、RAG(检索增强生成)、效率优化等技术趋势,紧跟 AI 最新发展。
重构知识体系
覆盖预训练、微调、强化学习、应用开发、效率优化等全流程,体系更加完善,逻辑更清晰。
提升实践价值
新增逾 40% 的前沿研究成果与技术案例,增设工程实践指南与评估体系模块,助力理论落地。
扩展章节内容
新增多模态大语言模型、智能体、RAG、大模型效率优化等实用章节,并对指令微调和强化学习部分进行了大幅修改。
本书架构
围绕 LLM 理论基础、预训练、指令理解、大模型增强、大模型应用五大部分展开。
第 1 部分介绍大语言模型的基础理论:包括语言模型的定义、Transformer 结构、大语言模型框架、混合专家模型等内容,并以 LLaMA 使用的模型结构为例介绍代码实例。
第 2 部分介绍大语言模型的预训练,包括大语言模型预训练数据和分布式训练。该部分介绍了预训练需要使用的数据分布和数据预处理方法。除此之外,还介绍模型分布式训练中需要掌握的数据并行、流水线并行、张量并行及 ZeRO 系列优化方法。并以 DeepSpeed 为例介绍如何进行大语言模型预训练。
第 3 部分介绍大语言模型如何理解并服从人类指令,包括指令微调和强化学习。重点介绍模型微调技术、指令微调数据的构造策略,以及高效微调方法,如 LoRA、Delta Tuning 等方法。强化学习章节重点讲解其基础理论、策略梯度方法(REINFORCE 算法、广义优势估计、PPO 算法、PLOO 算法、GRPO 算法),推理模型的强化学习(以 DeepSeek-R1 和 Kimi k1.5 为例),RLHF 等,并结合实际案例,以 DeepSpeed-Chat 和 verl 框架为例,详细说明如何训练类 ChatGPT 系统。
第 4 部分围绕提升大语言模型的能力展开详细探讨,内容涵盖多模态大语言模型、大模型智能体和检索增强生成。多模态大语言模型章节重点介绍其基础理论、架构设计与训练策略,并探讨其在实际场景中的应用实践。智能体章节聚焦其发展历程与大语言模型智能体的架构设计,深入分析智能体的实现原理,并以 LangChain 和 Coze 为例详细阐述具体实践。RAG 章节介绍其核心思想与实现方式,涵盖检索增强框架的设计、检索模块与生成模块的协作机制,以及其在具体任务场景中的应用方法与实践。
第 5 部分围绕如何应用大语言模型展开讨论,内容涵盖大语言模型效率优化、大语言模型评估,以及大语言模型典型应用的开发与部署。效率优化章节重点介绍模型压缩与优化、训练效率优化和推理效率优化等提升模型效率的关键技术。大语言模型评估章节探讨其基本概念和难点,阐述评估体系的构建、评估方法的设计及实际评估的实施。大语言模型应用章节介绍典型的大语言模型应用场景,详细介绍其开发流程、开发工具及本地部署的实践方法。
新增章节亮点
- 多模态大语言模型:介绍典型架构及其与 LLM 的融合方法、多模态训练策略。
- 大模型智能体:剖析涵盖感知、规划、记忆机制及工具调用能力的核心架构,训练与实践方法。
- 检索增强生成(RAG):解析系统设计模式、训练优化策略、评估体系全流程。
- 大模型效率优化:围绕模型压缩、低精度训练、高效推理框架(如 vLLM)等全链路技术实践展开。
- 大语言模型基础:新增混合专家模型(MoE)相关内容。
- 强化学习:新增对「The Bitter Lesson」的理解、长思维链、推理模型的强化学习等内容。
作者团队简介
本书作者团队由来自复旦大学的张奇、桂韬、郑锐、黄萱菁等多位人工智能领域的优秀学者组成。团队长期专注于自然语言处理、大规模预训练模型、智能体、多模态学习等前沿方向,具备丰富的理论研究与工程实践经验。
张奇,复旦大学计算机科学技术学院教授、博士生导师。兼任上海市智能信息处理重点实验室副主任,中国中文信息学会理事、CCF 大模型论坛常务委员,CIPS 信息检索专委会常务委员、CIPS 大模型专委会委员。近年来在国际重要学术期刊和会议上发表论文 200 余篇。获得 WSDM 2014 最佳论文提名奖、COLING 2018 领域主席推荐奖、NLPCC 2019 杰出论文奖、COLING 2022 杰出论文奖。
桂韬,复旦大学副研究员。研究领域为预训练模型、类人对齐和智能体交互。在国际重要学术期刊和会议上发表论文 50 余篇,主持国家自然科学基金计算机学会和人工智能学会的多个人才项目。获得钱伟长中文信息处理科学技术一等奖、NeurIPS 2023 大模型对齐 Track 最佳论文奖,入选第七届「中国科协青年人才托举工程」、上海市启明星计划。
郑锐,博士毕业于复旦大学计算机科学技术学院,师从张奇教授。曾任字节跳动豆包大模型团队算法工程师,现就职于某前沿科技公司,研究方向为大模型对齐、复杂推理能力提升。获得 NeurIPS Workshop on Instruction Following 2024 最佳论文奖。在 ICLR、ICML、NeurIPS、ACL 等国际会议上发表多篇论文。
黄萱菁,复旦大学特聘教授、博士生导师。主要从事人工智能、自然语言处理和大语言模型研究。兼任中国计算机学会理事、自然语言处理专委会主任、中国中文信息学会理事、计算语言学学会亚太分会主席。在国际重要学术期刊和会议上发表论文 200 余篇,获优秀论文奖 8 项。获得钱伟长中文信息处理科学技术一等奖、上海市育才奖,以及人工智能全球女性学者、福布斯中国科技女性等多项荣誉。
专家点评
自《大规模语言模型:从理论到实践》首版问世以来,便受到了学术界与产业界的广泛关注。此次全新升级的第二版,内容更加丰富、体系更加完善,得到了多位人工智能领域权威专家的高度认可(按姓氏拼音排序):
「随着 ChatGPT 的问世,大语言模型展现出巨大潜力,对人工智能发展产生了深远影响。面对这一迅速发展的技术,如何快速理解其理论并参与实践是我们必须要面对的挑战。本书在第 1 版的基础上增加了多模态、智能体、RAG 等章节,并对指令微调和强化学习部分进行了大幅修改,旨在帮助读者深入理解大语言模型的原理,提供实操指导,值得阅读。」
——柴洪峰 中国工程院院士
「本书深入解析了大语言模型的基本原理,分析了当前几种有代表性的大语言模型的学理特点,分享了作者在这一领域的实践经验。本书的出版恰逢其时,是学术界和产业界不可多得的读物,将助力读者进一步探索和应用大语言模型。」
——蒋昌俊 中国工程院院士
「本书全面解析了大语言模型的发展历程、理论基础与实践方法,对大语言模型预训练、指令微调、强化学习、多模态、智能体、RAG 等前沿领域的研究进展有较好的覆盖。此外,本书深入探讨了大语言模型的实际应用场景与评价方法,为研究者提供了系统的理论指导与实践经验。相信本书对从事相关研究的学者和大语言模型开发者具有重要的参考价值。」
——周伯文 上海人工智能实验室主任、首席科学家、清华大学惠妍讲席教授
《大规模语言模型:从理论到实践(第 2 版)》的出版上市,希望可以让读者快速掌握大语言模型的研究与应用,更好地应对相关技术挑战,为推动这一领域的进步贡献力量。
....
#除了Ilya、Karpathy,离职OpenAI的大牛们,竟然创立了这么多公司
聚是一团火,散是满天星。
硅谷新势力已经崛起,这些创业者来自 OpenAI。
作为 ChatGPT 的缔造者,OpenAI 堪称当今人工智能领域最耀眼的明星。这家公司正以惊人的速度飙升至 3000 亿美元估值的同时,也催生了一批离职创业的成员。
OpenAI 的光环效应如此强大,以至于 Ilya Sutskever 的 AI 初创公司 Safe Superintelligence (SSI) 和 Mira Murati 的 Thinking Machines Lab 等企业尚未推出产品就获得数十亿美元融资。
这个新兴生态圈还包括诸多明星项目,以下是离职 OpenAI 的研究者打造的最受瞩目企业盘点。
Dario Amodei, Daniela Amodei, John Schulman — Anthropic
Dario Amodei 和 Daniela Amodei 兄妹二人于 2021 年离开 OpenAI,联合其他 OpenAI 高管共同创立了 Anthropic,专注于开发安全、可解释、对齐人类价值观的 AI 系统。
随后,OpenAI 联合创始人 John Schulman 于 2024 年加入 Anthropic,承诺要打造 AGI,但他仅在 Anthropic 工作了大约不到 5 个月,于 2025 年 2 月初正式离职。
Anthropic 开发了名为 Claude 的一系列大语言模型,与 OpenAI 的 ChatGPT 竞争。Claude 以其安全性和对话能力著称,设计上更注重避免有害内容和偏见, Claude 3.7 是现在最先进的大模型之一。
据《The Information》报道,从收入规模来看(2024 年 OpenAI 收入为 37 亿美元,Anthropic 为 10 亿美元),OpenAI 的体量仍是 Anthropic 的数倍。但 Anthropic 增长迅速,现已成为 OpenAI 最主要的竞争对手,并在 2025 年 3 月达到 615 亿美元的估值。
Pieter Abbeel, Peter Chen, Rocky Duan — Covariant
Covariant 创始队伍 (从左至右):Peter Chen(CEO),Pieter Abbeel(总裁兼首席科学家),Rocky Duan(CTO),Tianhao Zhang(研究科学家)
Pieter Abbeel 是强化学习大牛、UC 伯克利教授,Peter Chen 和 Rocky Duan 是其博士生。三人曾在 2016 至 2017 年间在 OpenAI 担任研究科学家,随后创办了 Covarian(公司另一创始人 Tianhao Zhang 也是其博士生),一家专注于为机器人构建基础 AI 模型(foundation AI models for robots)的公司。
Covariant 的技术依赖于机器人与现实世界的交互产生的体验和反馈,其 A1 系统 (CovariantBrain) 的特点之一是将大量真实机器人任务数据融入训练环节。团队为此开发了一种新型的人工智能架构,这种架构不受简单化假设的限制,能够内化与各种物品的无限组合中相互作用的经验。
Covariant 在 2024 年 3 月发布的机器人基础模型 RFM-1 是当时世界上首个基于真实任务数据训练的机器人大模型,也是最接近于解决真实世界任务的机器人大模型。
Covariant 获得了包括谷歌 Jeff Dean、斯坦福李飞飞、深度学习三巨头之一的 Hinton、LeCun,以及比尔・盖茨等顶级科学家和企业家的投资支持
2024 年,亚马逊聘用了 Covariant 的三位创始人及约四分之一团队成员,此次「准收购」被一些人视为大科技公司在规避反垄断审查背景下的战略动作。
Ilya Sutskever — Safe Superintelligence
OpenAI 联合创始人兼首席科学家 Ilya Sutskever 于 2024 年 5 月离开 OpenAI,据称他曾参与一场试图罢免 CEO Sam Altman 的未遂行动。不久之后,他创立了 Safe Superintelligence,简称 SSI,并表示其目标只有一个,产品也只有一个:打造「安全的超级智能(Superintelligence)」。
目前关于该初创公司的具体动向信息非常少:既没有推出产品,也尚无收入。但投资者的兴趣依然炽热,其已成功融资 20 亿美元,最新估值在本月 reportedly 上升到了 320 亿美元。
Andrej Karpathy — Eureka Labs
计算机视觉专家 Andrej Karpathy 是 OpenAI 的早期成员和研究科学家,2017 年离开后加入特斯拉(Tesla),领导其自动驾驶(Autopilot)项目。他于 2022 年 7 月离开特斯拉,之后短暂回归 OpenAI(2023-2024 年)。2024 年 7 月创办了自己的教育科技初创公司 Eureka Labs,该公司致力于构建 AI 辅助教学助手。
Andrej Karpathy 长期致力于人工智能普及和教育。他在斯坦福大学开设的 CS231n 课程、YouTube 上的 AI 教程以及「Zero-to-Hero AI」系列广受欢迎。Karpathy 认为,当前全球优质教育资源稀缺,而生成式 AI 的进步为「人人都能获得高质量个性化辅导」带来了可能。
Eureka Labs 的首个产品是 LLM101n—— 一门本科级别的课程,旨在指导学生训练自己的 AI 模型。课程材料将在线开放,并计划组织线上和线下学习小组,实现「教师 + AI 助教」的共生教育模式。
Mira Murati — Thinking Machines Lab
Thinking Machines Lab 的 CEO 为 OpenAI 前 CTO Mira Murati,她曾在 OpenAI 领导过研究、产品与安全方面的工作。去年 9 月,Murati 离开了 OpenAI。
在 OpenAI 工作期间,Mira 在 ChatGPT、DALL-E、Codex 等的开发中发挥了重要作用。除此以外, GPT-4o 以及 OpenAI o1,都是在 Mira 的领导下完成的。
Thinking Machines Lab 于 2025 年 2 月正式成立,旨在打造更可定制、更强大的人工智能。
这家位于旧金山的人工智能初创公司目前没有产品或收入,但拥有众多前 OpenAI 顶尖研究人员。

图源:https://thinkingmachines.ai/
在这份创始团队名单中,有很多行业大佬。比如 John Schulman 担任首席科学家,他是深度强化学习的一位先驱研究者,创造了著名的 PPO 算法。同时也是 OpenAI 的创始人之一,曾共同领导过 ChatGPT 和 OpenAI 后训练团队。
又比如 Barret Zoph 担任 CTO,也曾是 OpenAI 的一位技术主管,领导过 OpenAI 的后训练团队,涉及的研究方向包括对齐、工具使用、评估、ChatGPT、搜索、多模态等等。
据报道,该公司正在筹集 20 亿美元的种子轮融资,估值至少达到 100 亿美元。
Aravind Srinivas — Perplexity
Aravind Srinivas 曾在 OpenAI 工作一年,担任研究科学家,直至 2022 年离开,之后共同创办了 AI 搜索引擎 Perplexity。
Perplexity 利用大型语言模型(如 GPT-4、Claude、Llama 等)结合实时网络检索,能够理解用户的自然语言查询,自动从互联网和多种数据源中收集、分析并生成简洁准确的答案,同时在回答中附带信息来源链接,提升答案的可信度和透明度。
Perplexity 还提供「焦点」功能,用户可以限定搜索范围,例如只搜索 Reddit、YouTube 或学术论文等特定领域,以获得更精准的结果。
Perplexity 吸引了杰夫・贝索斯及英伟达等一系列高知名度的投资者。尽管 Perplexity 也因涉嫌不道德的数据抓取行为引发争议,但目前这家总部位于旧金山的公司正在以约 180 亿美元估值筹集约 10 亿美元融资(截至 2025 年 3 月)。
Kyle Kosic — xAI
Kyle Kosic 于 2023 年离开 OpenAI,成为创业公司 xAI 的联合创始人及基础设施负责人。xAI 是埃隆・马斯克(Elon Musk)创办的 AI 公司,旗下拥有对标聊天机器人的产品 Grok。然而到了 2024 年,Kyle Kosic 又回到了 OpenAI。

Grok 的最新版本为 2025 年 2 月发布的 Grok 3,被马斯克称为「地球上最聪明的人工智能」。Grok 3 由 xAI 自建的超级计算机「Colossus」支持,使用了约 20 万个 NVIDIA GPU 进行训练,累计训练时长高达 2 亿 GPU 小时,是目前规模最大、计算能力最强的 AI 训练之一。
xAI 收购了已更名为 X 的前推特公司(Twitter),合并实体的估值达到 1130 亿美元。全股票的交易模式引发了一些质疑,但若看好马斯克帝国的前景,则被视为一笔不错的交易。
Emmett Shear — Stem AI
Emmett Shear 是 Twitch 前 CEO,亦曾在 2023 年 11 月(在 Sam Altman 重返公司之前)短暂担任 OpenAI 临时 CEO(仅数日)。
根据 TechCrunch 2024 年的报道,Shear 正在运营自己的隐匿型初创公司 Stem AI。虽然目前关于该公司的业务和融资详情不多,但已获得 Andreessen Horowitz 的投资。
Jeff Arnold — Pilot
Jeff Arnold 曾于 2016 年在 OpenAI 任职五个月,担任运营主管,之后于 2017 年共同创办了会计初创公司 Pilot。
Pilot 专注为高速成长的科技初创公司和中小企业提供专业的财务服务,主要包括记账(bookkeeping)、税务(tax)和首席财务官(CFO)服务。
Pilot 在 2021 年完成了一轮 1 亿美元的 C 轮融资,估值达到 12 亿美元,投资方包括杰夫・贝索斯。Arnold 在 2024 年离开 Pilot,创立了自己的风险投资基金。
David Luan — Adept AI Labs
David Luan 曾担任 OpenAI 的工程副总裁(VP of Engineering),于 2020 年离职,随后经历了在谷歌的短暂工作后,于 2021 年共同创办了 Adept AI Labs,一家开发面向办公人员的 AI 工具的初创公司。
Adept 的旗舰产品是 AI 助手 ACT-1。它通过自然语言理解用户需求,能够自动在浏览器、招聘软件、表格等多种应用中执行操作,比如自动整理数据、填写表单、导入信息等,极大提升了工作效率。ACT-1 以「覆盖窗口」的方式工作,直接在现有软件之上操作,无需用户切换应用。
Adept 在 2023 年完成了 3.5 亿美元融资,估值超过 10 亿美元。但 Luan 于 2024 年 6 月离开,加入亚马逊,领导其新的 AI 智能体实验室(AI agents lab),此前亚马逊已聘请了 Adept 的创始团队。

Tim Shi — Cresta
Tim Shi 是 OpenAI 的早期成员之一,据其 LinkedIn 资料,他于 2017 年在 OpenAI 工作一年,专注于安全的 AGI 建设。
此后,他创办了 Cresta,这是一家专注于 AI 客服中心(AI contact center)解决方案的公司。Cresta 是全球最早将生成式 AI 大模型(如 GPT)大规模应用于企业生产环境的公司之一,2019 年便已在财富 500 强客户中部署相关系统。
据了解,Cresta 已从红杉资本(Sequoia Capital)、Andreessen Horowitz 等顶级风投机构累计融资超过 2.7 亿美元。
Tim Shi 本科毕业于清华大学姚班(以第一名成绩),后在斯坦福大学攻读人工智能方向博士,专注于自然语言处理和强化学习。也曾在 DJI 和 Dropbox 等公司从事深度学习与机器学习相关工作。
Maddie Hall — Living Carbon
Maddie Hall 曾在 OpenAI 从事「special projects」,但于 2019 年离职,并联合创立了 Living Carbon。
Living Carbon 是一家总部位于旧金山的初创公司,旨在研发能够吸收更多空气中碳元素的植物( engineered plants),以应对气候变化。

据一份新闻稿称,Living Carbon 在 2023 年完成了 2100 万美元的 A 轮融资,使其迄今为止的总融资额达到 3600 万美元。
Shariq Hashme — Prosper Robotics
根据 Shariq Hashme 个人资料显示,他于 2017 年在 OpenAI 工作了 9 个月,期间开发了一款可以玩热门电子游戏 Dota 的机器人。离职后,Hashme 加入初创公司 Scale AI 。
之后,Hashme 于 2021 年与他人共同创立了 Prosper Robotics 公司,总部位于伦敦。

该初创公司正在研发一款家居机器人管家,它可以做早餐、打扫办公室、整理床铺等等。目前,他们已经推出了首款机器人产品 Alfie。
Jonas Schneider — Daedalus
Jonas Schneider 在 OpenAI 工作期间,创立并领导了 OpenAI 机器人软件工程团队,该团队致力于通过学习与物理世界交互的「软件 + 机器学习 + 硬件」系统推进机器学习和人工智能研究。该团队训练了一只类似人类的机械手来解开魔方,并以前所未有的灵巧度操控其他物体。
Schneider 于 2019 年离职,之后成为 Daedalus 联合创始人。

Daedalus 公司主要研究最先进的精密零部件,致力于为机械、航空航天、半导体、能源等领域的公司生产零部件。
去年在 Khosla Ventures 等公司的投资下,该公司完成了 2100 万美元的 A 轮融资。
Margaret Jennings — Kindo
Margaret Jennings 曾于 2022 年和 2023 年在 OpenAI 工作,在此期间担任 OpenAI 应用 AI 部门负责人,之后离开并成为 Kindo AI 的联合创始人。
Kindo AI 成立的初衷是让企业能够安全地采用和管理人工智能技术,包括生成式人工智能。
该公司于 2023 年 9 月完成了由 Riot Ventures 领投的 700 万美元种子轮融资。目前,该公司已筹集超过 2700 万美元的资金。
另据 LinkedIn 个人资料显示,Margaret Jennings 于 2024 年离开了 Kindo AI,前往法国 AI 初创公司 Mistral 担任产品和研究主管。

参考链接:https://techcrunch.com/2025/04/26/the-openai-mafia-15-of-the-most-notable-startups-founded-by-alumni/
....
#Efficient Pretraining Length Scaling
字节Seed团队PHD-Transformer突破预训练长度扩展!破解KV缓存膨胀难题
最近,DeepSeek-R1 和 OpenAI o1/03 等推理大模型在后训练阶段探索了长度扩展(length scaling),通过强化学习(比如 PPO、GPRO)训练模型生成很长的推理链(CoT),并在奥数等高难度推理任务上取得了显著的效果提升。
受此启发,研究人员开始探索预训练阶段的长度扩展,已有方法包括在序列中插入文本、插入潜在向量(如 Coconut)、复用中间层隐藏状态(如 CoTFormer)以及将中间隐藏状态映射为概念(如 COCOMix)。不过,这些方法普遍存在问题,比如需要更大的 KV 缓存导致推理慢 / 占内存多。
本文中,来自 ByteDance Seed 团队的研究者提出了更简单的方法:直接重复输入 tokens(1/2/3/4 次),不做中间层处理。他们观察到了训练损失和模型性能随重复倍数扩展的趋势,如下图 1a 和 1b 所示。但是,直接重复 tokens 也带来了新问题,包括 KV 缓存规模线性增加,内存压力大;预填充时间超线性增加;解码延迟变长。这些都是实现预训练长度扩展需要重点解决的挑战。
- 论文标题:Efficient Pretraining Length Scaling
- arXiv 地址:https://arxiv.org/pdf/2504.14992
研究者提出了一种推理友好的新颖长度扩展方法,核心是 PHD-Transformer(Parallel Hidden Decoding Transformer),它保持了与原始 transformer 相同的 KV 缓存大小,同时实现有效的长度扩展。PHD-Transformer 通过创新的 KV 缓存管理策略实现了这些能力。
具体来讲,研究者将第一个 token 表示原始 token,将重复的 token 表示为解码 token。同时仅保留从原始 token 生成的 KV 缓存来用于长距离依赖建模,并在隐藏解码 token 用于下一个 token 预测之后丢弃它们的 KV 缓存。因此,PHD-Transformer 提供了与原始 transformer 相同的 KV 缓存,同时相较于简单的 token 重复实现了显著的推理加速(如图 1d 所示)。
另外,为了更好地保留隐藏解码 token 的 KV 缓存的性能优势,研究者引入了一种滑动窗口注意力 ——PHD-SWA,保持了这些 token 的局部滑动窗口缓存,在实现显著性能提升的同时,仅需要

的额外 KV 缓存内存。
研究者还注意到,在 PHD-SWA 中,隐藏解码 token 的 KV 缓存表现出了顺序依赖关系,这导致预填充时间呈线性增长。为了解决这个问题,研究者提出了逐块滑动窗口注意力 —— PHD-CSWA,从而限制了每个块内的顺序依赖关系。
因此,得益于只有最后一个块的预填充时间呈线性增长,PHD-CSWA 显著缩短了预填充时间(如图 1c 所示)。

方法概览
PHD 的架构下图 2 所示,与原始 Transformer 相比,PHD 保留了相同的模型架构,仅在输入序列和注意力矩阵的设计上有所不同。具体而言,他们仅允许原始 token

生成 KV 缓存,并且可以被所有 token 全局关注;同时隐藏状态的 KV 缓存在并行隐藏解码后会被立即丢弃。注意力矩阵的策略具体如下:
研究者在推理过程中实现了与原始 Transformer 相同的 KV 缓存大小和内存访问模式。虽然需要 K 次 FLOP,但这些计算可以并行处理,从而在内存受限的推理场景中最大限度地降低延迟开销。该架构的核心优势在于原始 token 和隐藏解码 token 之间的解耦。在预填充期间,只有原始 token 需要计算。
这种设计确保预填充时间与原始 Transformer 相同,并且无论扩展因子 K 如何变化,预填充时间都保持不变。而对于损失计算,研究者仅使用 token 的最终副本进行下一个 token 的预测。总之,使用 token 的第一个副本进行 KV 缓存生成,使用 token 的最后一个副本进行下一个 token 的预测。

内核设计
M^ij_mn 的简单实现会导致注意力层计算量增加 K^2 倍,FFN 层计算量也增加 K 倍。然而,由于注意力是稀疏计算的,

的注意力可以大幅降低。因此,研究者将原始 token 和隐藏解码 token 分成两组,并将它们连接在一起。
下图 3 展示了 K = 3 的示例,可以得到一个包含 t 个原始 token 的序列和一个包含 2t 个隐藏解码序列的序列。通过重新排列 token 的位置,研究者将掩码注意力的位置保留在一个连续块中,从而优化了注意力计算,将注意力计算复杂度降低到

。

PHD-SWA 和 PHD-CSWA
与简单的 token 重复相比,PHD-Transformer 在保持原始 KV 缓存大小的同时实现了长度扩展。然而通过经验观察到,为隐藏解码 token 保留一些 KV 缓存可以带来显著的性能提升。因此,为了在保持效率的同时获得这些优势,研究者引入了 PHD-SWA,将滑动窗口注意力限制在 W 个先前的隐藏解码 token 上。
如下图 4 所示,PHD-SWA 的注意力模式将对原始 token 的全局访问与对 W 个最近隐藏解码 token 的局部访问相结合。这种改进的注意力机制实现了显著的性能提升,同时仅需要

的额外 KV 缓存内存。
虽然 PHD-SWA 滑动窗口方法提升了模型性能,但由于隐藏解码 token 的 KV 缓存中存在顺序依赖关系,它会产生 K 倍的预填充开销。为了解决这个问题,研究者引入了 PHD-CSWA,它可以在独立的块内处理注意力。
如下图 4 所示,PHD-CSWA 将滑动窗口注意力限制在单个块内运行。这种架构创新将额外的预填充开销减少到最终块内的 K 次重复,而不是整个序列重复,这使得额外的计算成本几乎可以忽略不计,同时保留了局部注意力模式的优势。

实验结果
在实验中,研究者使用 OLMo2 作为代码库,并在 ARC、HellaSwag、PIQA、Winogrande、MMLU 和 CommonsenseQA 等公开基准测试集上进行了评估。
训练细节:研究者使用 1.2B 参数规模的模型,它是一个 16 层的密集模型。每个 token 的隐藏层维数设置为 2048,FFN 层的隐藏层大小设置为 16384。同时使用组查询注意力 (Group-Query Attention,GQA),它包含 32 个查询头和 8 个键 / 值头,每个头的隐藏层维数设置为 64。研究者使用 500B 个 token 训练该模型。
对于本文提出的 PHD 系列设置,研究者预训练了以下两种 PHD-CSWA 变体:
- PHD-CSWA-2-16-32,其中训练 token 重复两次。保留一个包含 16 个 token 的局部窗口,并将块大小设置为 32 个 token。
- PHD-CSWA-3-16-32,其中训练 token 重复三次。局部窗口大小和块大小与 PHD-CSWA-2-16-32 的设置相同。
PHD-CSWA 在各个基准测试中均实现了持续的性能提升。下图 5 中展示了训练曲线,下表 1 中展示了主要结果。本文提出的 PHD-CSWA-2-16-32 在这些基准测试中平均实现了 1.5% 的准确率提升,训练损失降低了 0.025;而 PHD-CSWA-3-16-32 在这些基准测试中平均实现了 2.0% 的准确率提升,训练损失降低了 0.034。


研究者还分析了 PHD 和 PHD-SWA 的扩展性能,以分析扩展解码计算的性能。 训练细节:使用相同的 550M 模型配置,将窗口大小 W 设置为 16,并在 {2, 3, 5} 范围内改变扩展因子 K。对于局部窗口大小,研究者在所有实验中都将窗口大小设置为 16。
PHD-SWA 的性能在增加扩展因子时有效扩展。如下图 8 所示,使用固定窗口大小时,损失曲线和下游性能会随着 token 重复次数而有效扩展。通过将扩展因子设置为 5,可以实现接近 0.06 的损失降低,同时显著提升下游性能。
下表 2 中的定量结果表明,当扩展至 K = 5 时,所有基准测试的平均准确率提高了 1.8%,这证实了本文的方法在更激进的扩展方面仍然有效。


....
#DFloat11
70% Size, 100% Accuracy,模型压缩到70%,还能保持100%准确率,无损压缩框架DFloat11来了
大型语言模型(LLMs)在广泛的自然语言处理(NLP)任务中展现出了卓越的能力。然而,它们迅速增长的规模给高效部署和推理带来了巨大障碍,特别是在计算或内存资源有限的环境中。
例如,Llama-3.1-405B 在 BFloat16(16-bit Brain Float)格式下拥有 4050 亿个参数,需要大约 810GB 的内存进行完整推理,超过了典型高端 GPU 服务器(例如,DGX A100/H100,配备 8 个 80GB GPU)的能力。因此,部署该模型需要多个节点,这使得它昂贵且难以获取。
本文,来自莱斯大学等机构的研究者提出了一种解决方案,可以将任何 BFloat16 模型压缩到原始大小的 70%,同时还能在任务上保持 100% 的准确性。
- 论文标题: 70% Size, 100% Accuracy: Lossless LLM Compression for Efficient GPU Inference via Dynamic-Length Float
- 论文地址:https://arxiv.org/pdf/2504.11651
- 项目地址:https://github.com/LeanModels/DFloat11
为了应对 LLM 不断增长的模型尺寸,通常会采用量化技术,将高精度权重转换为低位表示。这显著减少了内存占用和计算需求,有助于在资源受限的环境中实现更快的推理和部署。然而,量化本质上是一种有损压缩技术,引入了一个基本缺点:它不可避免地改变了 LLMs 的输出分布,从而影响模型的准确性和可靠性。
相比之下,无损压缩技术在有效减少 LLM 规模的同时,保留了精确的原始权重,确保模型的输出分布与未压缩表示(例如 BFloat16)完全相同。然而,现有的无损方法主要集中在提高 LLMs 的存储效率上,例如缩小模型检查点或优化针对专用硬件如 FPGA 的性能上。
本文提出了 DFloat11(Dynamic-Length Float),这是一种无损压缩框架,可以在保持与原始模型完全相同的输出的情况下,将 LLM 的规模减少 30%。
DFloat11 的提出源于当前 LLM 模型中 BFloat16 权重表示的低熵问题,这暴露出现有存储格式存在显著的低效性。通过应用熵编码技术,DFloat11 根据权重出现频率为其分配动态长度编码,在不损失任何精度的情况下实现了接近信息理论极限的压缩效果。
为了支持动态长度编码的高效推理,该研究还开发了定制化的 GPU 内核来实现快速在线解压缩。其设计包含以下内容:
- 将内存密集型查找表(LUT)分解为适应 GPU SRAM 的紧凑型查找表;
- 采用双阶段内核设计,通过轻量级辅助变量协调线程读写位置;
- 实现 Transformer 块级解压缩以最小化延迟。
该研究在 Llama-3.1、Qwen-2.5 和 Gemma-3 等最新模型上进行了实验:DFloat11 能在保持比特级(bit-for-bit)精确输出的同时,将模型体积缩减约 30%。与将未压缩模型部分卸载到 CPU 以应对内存限制的潜在方案相比,DFloat11 在 token 生成吞吐量上实现了 1.9–38.8 倍的提升。在固定 GPU 内存预算下,DFloat11 支持的上下文长度是未压缩模型的 5.3–13.17 倍。
值得一提的是,基于该方法 Llama-3.1-405B(810GB)在配备 8×80GB GPU 的单节点上实现了无损推理。
方法介绍
LLM 的权重通常使用浮点数表示,包括 BFloat16 或 BF16,其在数值精度和内存效率之间取得了平衡。然而,BFloat16 表示信息并不高效。
针对 BFloat16 表示法中存在的信息效率低下问题,本文提出了一种无损压缩框架,通过熵编码技术对浮点参数进行压缩。
具体实现包括:基于语言模型线性投影矩阵中所有 BFloat16 权重的指数分布构建霍夫曼树,对指数部分采用霍夫曼编码压缩,同时保留原始符号位和尾数位。压缩后的指数经过紧密比特打包存入字节数组 EncodedExponent,而未压缩的符号位和尾数则存储在独立字节数组 PackedSignMantissa 中。图 2 展示了 DFloat11(Dynamic-Length Float)或 DF11,该格式可实现模型参数的高效紧凑表示。

虽然动态长度浮点数能有效实现 LLM 的无损压缩,但关键挑战依然存在:如何利用这些压缩权重进行高效的 GPU 推理。接下来,文章详细介绍了解决方案,其中包括三个关键组成部分:
- 将一个庞大的无前缀查找表(LUT)分解为多个适合 GPU SRAM 的紧凑 LUTs;
- 引入一个两阶段的内核设计,利用轻量级辅助变量来高效协调线程的读写操作;
- 在 transformer 块级别执行解压缩,以提高吞吐量并最小化延迟。
算法 1 是将 DFloat11 解压缩为 BFloat16 的 GPU 内核过程。

实验
研究人员评估了 DF11 压缩方法在 GPU 上的有效性及推理效率,将多个主流大语言模型(包括 LLaMA、Qwen、Gemma 等)从 BFloat16 压缩为 DF11 格式,并报告其压缩比和性能表现。
在软硬件环境方面,研究人员使用 CUDA 和 C++ 实现了 DF11 解压缩内核,并集成至 Transformers 推理框架。实验基于 HuggingFace Accelerate 框架评估未压缩模型在 CPU 分流(CPU offloading)和多 GPU 场景下的性能。
为全面分析 DF11 内核在不同硬件配置下的表现,团队在多种 GPU 和 CPU 组合的机器上进行实验。
实验结果
DF11 压缩比:DF11 将大语言模型压缩至原始大小的约 70%(等效位宽为 11 位)。

表 2 展示了 DF11 在 LLaMA、Qwen、Gemma 等模型上的压缩效果。所有模型的线性投影层参数均被压缩为 DF11 格式,压缩比稳定在 70%。
无损特性验证:为验证 DF11 的无损特性,研究人员使用 lm-evaluation-harness 工具在 MMLU、TruthfulQA、WikiText 和 C4 数据集上评估模型性能。
结果表明,压缩后的模型在准确率和困惑度(Perplexity)上与原始 BFloat16 模型一致(见表 3)。此外,研究人员逐位对比 DF11 解压后的权重矩阵与原始矩阵,确认其完全相同。

推理性能:研究人员在多个硬件平台上比较了 DF11 与 BFloat16 模型的推理效率。对于 BFloat16 模型,当模型超出单 GPU 显存时,需将部分计算分流至 CPU,而 DF11 模型可完全加载至单 GPU。
评估指标包括延迟(Latency)和吞吐量(Throughput),结果显示 DF11 模型的性能显著优于 BFloat16 模型,延迟减少 1.85 至 38.83 倍(见图 3)。

节省的显存可支持更长生成序列:DF11 的显存节省使模型能够支持更长的生成序列。如图 4 所示,在 batch size 为 1 时,DF11 模型的显存消耗显著降低,相比 BFloat16 模型最多可生成 5.33 至 13.17 倍的 tokens。

消融研究
延迟分析:研究团队以 Llama-3.1-8B-Instruct 为例,对比了其在 BFloat16 与 DF11 格式下不同 batch 大小时的延迟组成,结果如图 5 所示。

相比原始模型,DF11 压缩模型因解压 Transformer 模块与语言建模头引入了额外延迟但该开销与 batch size 无关,因此通过提升 batch size 可有效摊销解压延迟,使总推理时间之间的差距显著缩小。
解压性能对比:研究人员将 DF11 解压内核的延迟与吞吐表现分别与两种基线方案进行对比:
- 将模型权重存储于 CPU 内存并在需要时传输到 GPU;
- 使用 NVIDIA 的 nvCOMP 库中的 ANS(不对称数值系统,Asymmetric Numeral System)解压方法。
实验以 Llama-3.1-8B-Instruct 语言建模头权重矩阵为例,结果如图 6 所示,DF11 的解压吞吐量最高分别为 CPU-GPU 传输和 ANS 解码的 24.87 倍和 15.12 倍。此外,DF11 的压缩比为 70%,优于 nvCOMP 的 78%。值得注意的是,随着权重矩阵规模的增大,DF11 的解压吞吐呈上升趋势,原因是更好的 GPU 线程利用率。

....
#ToolRL
首个系统性工具使用奖励范式,ToolRL刷新大模型训练思路
钱成目前是伊利诺伊大学香槟分校 (UIUC) 一年级博士生,导师为季姮教授。本科就读于清华大学,导师为刘知远教授。其工作集中在大语言模型工具使用与推理以及人工智能体方向。曾在 ACL,EMNLP,COLM,COLING,ICLR 等多个学术会议发表论文十余篇,一作及共一论文十余篇,谷歌学术引用超 500,现担任 ACL Area Chair,以及 AAAI,EMNLP,COLM 等多个会议 Reviewer。
「工欲善其事,必先利其器。」 如今,人工智能正以前所未有的速度革新人类认知的边界,而工具的高效应用已成为衡量人工智能真正智慧的关键标准。大语言模型凭借卓越的推理与规划能力,正在快速融入人类生产与生活,但传统的监督训练方法在面对复杂或全新的工具场景时,却常常显得捉襟见肘。如何帮助人工智能突破这一瓶颈,拥有真正自如运用工具的能力?ToolRL 的出现为我们带来了答案。
伊利诺伊大学香槟分校的研究团队率先提出了一项开创性的研究 ——ToolRL。不同于传统的监督式微调,ToolRL 首次系统性地探讨了强化学习范式下的工具使用训练方法,通过精细化的奖励设计,有效解决了工具推理中的泛化难题。
- 标题:ToolRL: Reward is All Tool Learning Needs
- 论文链接:https://arxiv.org/pdf/2504.13958
- 代码仓库:https://github.com/qiancheng0/ToolRL

图 1: 主要 Benchmark 任务上不同训练策略效果对比。精细化奖励设计 ToolRL + GRPO 冷启动能够在不同模型上表现出最佳效果。观察右侧训练曲线,随着训练数据增加,奖励也呈现迅速攀升。
Tool-Integrated Reasoning:LLM 的 「工具链式思维」
在 ToolRL 中,研究者将工具调用问题建模为 Tool-Integrated Reasoning (TIR) 的任务范式。这种任务不仅仅要求模型 「用」 工具,更要求它以合理顺序和逻辑调用多个工具,并基于中间结果灵活调整接下来的思维路径。
TIR 任务的关键特征包括:
- 多步交互:一个任务通常需要多次调用工具,每步都有中间观察结果(如 API 反馈)。
- 组合调用:每一步可调用一个或多个工具,模型需生成参数化调用。
- 推理驱动:模型必须在自然语言 「思考」 后决定调用哪些工具、输入什么参数。

图 2: SFT 在工具推理上难以泛化,可能造成过度推理等问题,而基于 RL 的方法具有更好的泛化能力。
设计的关键 —— 不是 「对」 就够了
ToolRL 首次系统性地分析了工具使用任务中的奖励设计维度,包括:
- 尺度:不同奖励信号之间如何平衡?
- 粒度:如何拆解奖励信号粒度而非仅是二值选择?
- 动态性:训练过程中,奖励信号应否随时间变化?
研究表明,粗粒度、静态、或者仅以最终答案匹配为目标的奖励往往无法最有效地指导模型学习工具推理能力。为此,ToolRL 引入了一种结构化奖励设计,结合 「格式规范」 与 「调用正确性」,确保模型不仅生成合理的工具链式思维,更能准确理解工具含义与调用语义,激发更好更精准的模型工具推理能力。

图 3: 工具推理中的 Rollout 示意图,以及精细化奖励设计示例。除了正确性外,奖励信号额外涉及 「工具名称」,「参数名称」 以及 「参数内容」 进行精细化匹配,以取得更好的工具推理奖励效果。
实验:从模仿到泛化,ToolRL 如何激发工具智能?
为了验证 ToolRL 在多工具推理任务中的有效性,研究团队在多个基准上进行了系统实验,涵盖从工具调用(Berkeley Function Calling Leaderboard)、API 交互(API-Bank)到问答任务(Bamboogle)的真实应用场景。
实验设置
- 模型:使用 Qwen2.5 和 LLaMA3 系列作为基础模型;
- 训练方式:对比原始模型、监督微调(SFT)、近端策略优化(PPO)以及 ToolRL 提出的 GRPO + 奖励设计策略;
- 评估维度:准确率、对新任务 / 工具的泛化能力等。
核心结果
- 显著性能提升:在多个下游任务中,ToolRL 训练的模型准确率相比 SFT 平均提升超过 15%,比原模型基线表现超过 17%;
- 更强的泛化能力:在未见过的工具、语言或任务目标中,ToolRL 模型依然保持领先表现,展现出主动性和抗干扰能力;
- 调用更合理:在问答类任务中,ToolRL 模型能灵活控制调用次数,避免无意义操作,效率更高,推理更稳健。
实验结果表明,ToolRL 不仅提升了语言模型的工具使用能力,更重要的是,它促使模型学会 「何时该调用工具、如何调用工具」—— 这正是智能体走向自主智能的关键一步。


表 1-3: 在三个 Benchmark 上的测试结果,文章发现 GRPO 冷启动的方法往往能取得最好的效果
结语:ToolRL 不仅是一个方法,更是一套通用的奖励范式
结论:ToolRL 不仅是一种方法,更开创了基于工具调用的强化学习奖励新范式。通过大规模实验与深入对比分析,文章验证了三个核心发现:
- 简洁胜于冗长 —— 过度展开的推理路径在工具使用上并不能带来更高的性能,反而可能引入噪声导致过度推理;
- 动态奖励助力平滑过渡 —— 基于训练步数实时调整的奖励机制,能够使模型能从简单目标泛化至复杂目标,逐步积累工具推理能力;
- 细粒度反馈是关键 —— 针对每一次工具调用的精细化奖惩,极大提升了模型执行多步操作并正确利用外部工具的能力。

表 4-5: TooRL 训练出的模型在不相关工具检测(BFCL 子任务)中表现出更好的泛化性与合理平衡工具调用以及自我知识的主动性。
相比于传统强化学习研究往往单纯以「结果正确性」为唯一优化目标,ToolRL 在奖励信号设计上引入了更丰富的维度,不仅量化了 「是否正确」,还反映了 「工具名称」、「参数规范」 等多方面指标,弥补了现有方法对复杂工具链学习的欠缺。展望未来,ToolRL 所提出的奖励扩展框架不仅能适配更多样的任务类别,也为 LLM 与外部工具协同带来了更灵活、更可控的训练思路。我们期待基于这一范式的后续研究,进一步深化多模态工具交互、知识检索与规划生成等领域的智能化水平。
....

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐



 36
36 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)