KTransformers:清华开源框架让单卡24G显存跑DeepSeek-R1 671B大模型,推理速度飙升!+ 实践
KTransformers:告别天价显卡!国产框架让单卡24G显存跑DeepSeek-R1 671B大模型:推理速度飙升
一、KTransformers介绍
1、KTransformers简介
清华大学 KVCache.AI 团队(同时也是 Mooncake PD 分离推理框架的开发团队)与趋境科技于 2 月 10 日推出了 KTransformers 开源项目,通过一系列创新技术,使得只需一块 24G 显存的 4090D 显卡便能在本地运行全参数的 DeepSeek-R1,并实现了 286 tokens/s 的 Prefill 速度和 14tokens/s 的生成速度。同时它是一个开源的大语言模型推理优化框架,旨在通过GPU/CPU异构计算策略和MoE架构的稀疏性,显著提升大模型的推理速度并降低硬件要求。
2、特点
核心功能:支持在仅24GB显存的单张显卡上运行671B参数的满血版大模型,预处理速度最高可达286 tokens/s,推理生成速度达14 tokens/s。
技术原理:基于MoE架构的稀疏矩阵卸载、offload策略、高性能算子优化和CUDA Graph优化等技术,大幅降低显存需求并提升推理效率。
3、主要功能
(1)、支持超大模型的本地推理:支持在仅 24GB 显存的单张显卡上运行 DeepSeek-R1 等 671B 参数的满血版大模型,打破传统硬件限制。
(2)、提升推理速度:预处理速度最高可达 286 tokens/s,推理生成速度达 14 tokens/s。
(3)、兼容多种模型和算子:支持 DeepSeek 系列及其他 MoE 架构模型,提供灵活的模板注入框架,支持用户切换量化策略和内核替换,适应不同优化需求。
(4)、降低硬件门槛:将大模型的显存需求大幅降低,让普通用户和中小团队能在消费级硬件上运行千亿级参数模型,实现“家庭化”部署。
(5)、支持长序列任务:整合 Intel AMX 指令集,CPU 预填充速度可达 286 tokens/s,相比传统方案快 28 倍,将长序列任务的处理时间从“分钟级”缩短到“秒级”。
4、技术原理
(1)、MoE架构:将稀疏的 MoE 矩阵卸载到 CPU/DRAM 上处理,稠密部分保留在 GPU 上,大幅降低显存需求。
(2)、offload策略:根据计算强度将任务分配到 GPU 和 CPU:计算强度高的任务(如 MLA 算子)优先分配到 GPU,计算强度低的任务分配到 CPU。
(3)、高性能算子优化:
3.1、CPU端:用 llamafile 作为 CPU 内核,结合多线程、任务调度、负载均衡等优化,提升 CPU 推理效率。
3.2、GPU端:引入 Marlin 算子,专门优化量化矩阵计算,相比传统库(如 Torch)实现 3.87 倍的加速效果。
CUDA Graph 优化:基于 CUDA Graph 减少 Python 调用开销,降低 CPU/GPU 通信的断点,实现高效的异构计算协同。每次 decode 仅需一个完整的 CUDA Graph 调用,显著提升推理性能。
量化与存储优化:采用 4bit 量化技术,进一步压缩模型存储需求,仅需 24GB 显存即可运行 671B 参数模型。同时优化 KV 缓存大小,减少存储开销。
模板注入框架:提供基于 YAML 的模板注入框架,支持用户灵活切换量化策略、内核替换等优化方式,适应不同场景的需求。
二、如何运行 KTransformers
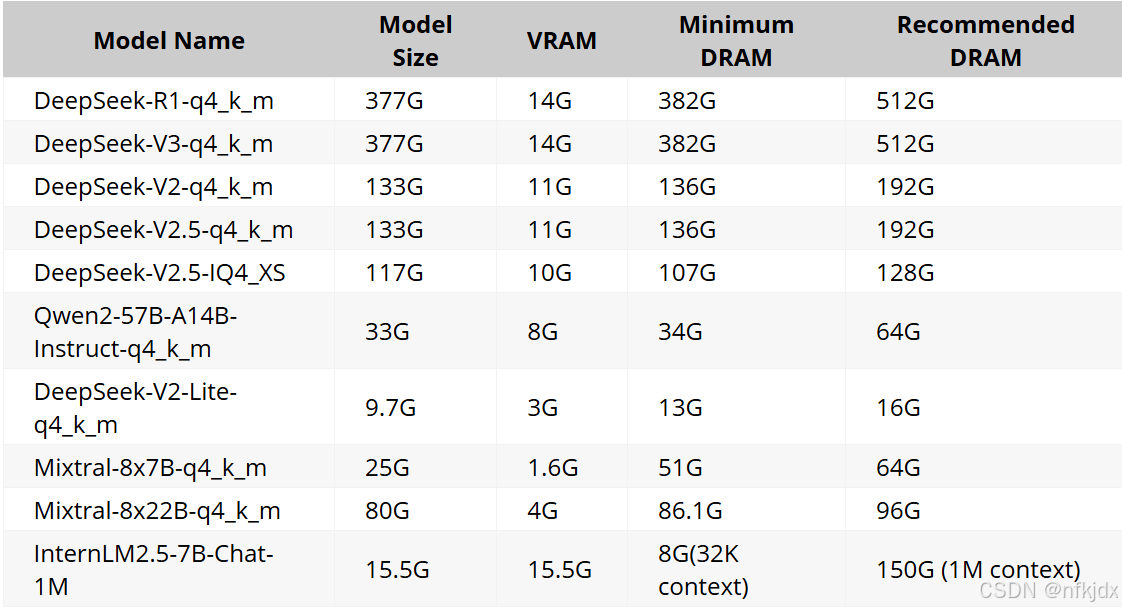
1、KTransformers支持的模型及需要的内存大小
注意:从上表可见 Q4 量化版 R1 和 V3 虽然显存(VRAM)需求较低,只有 14 GB,但对于内存(DRAM)需求高达 382 GB,推荐 512 GB。某云提供的 4090 实例只有 100 GB 内存,显然无法满足。笔者搜遍了全网也没找到单卡搭配如此高的内存配置,除非购买多卡实例(4 卡或 8 卡),那成本又要翻几倍,千元级变万元级,不划算。后面性能实测你还会看到,GPU 利用率也不高。
2、KTransformers实践
(1)、环境介绍
1.1、操作系统:Ubuntu 24.04.1,下载地址:https://mirrors.ustc.edu.cn/ubuntu-releases/
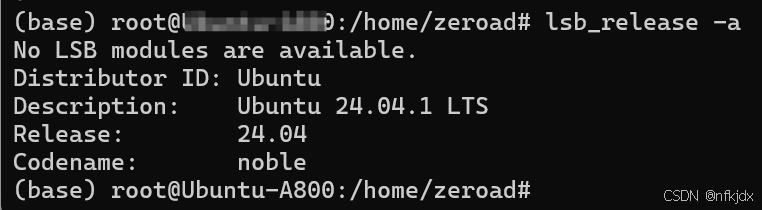
1.2、显卡驱动:Driver Version: 550.120 CUDA Version: 12.4,安装方法:https://blog.csdn.net/nfkjdx/article/details/136731327?spm=1001.2014.3001.5502
1.3、Anacond与python版本:conda 25.1.1 Python 3.12.9,安装方法:https://blog.csdn.net/nfkjdx/article/details/136370188?spm=1001.2014.3001.5501

(2)、实践步骤:
2.1、 创建 Python 虚拟环境:conda create --prefix /home/zeroad/ktransformer python==3.12
2.2、激活上一步创建的虚拟环境:source activate /home/zeroad/ktransformer
2.3、安装依赖库:pip install torch packaging ninja cpufeature numpy,这里安装可能比较缓慢,耐心等待
2.4、查看安装好的库:pip list
2.5、拉取KTransformers项目代码:git clone https://github.com/kvcache-ai/ktransformers.git
并进入项目里面:cd KTransformers 查看项目里面文件: ls

2.6、添加 CUDA 到系统路径:找到CUDA的安装路径,依次执行下面三句代码,其中【/usr/local/cuda】为自己cuda路径
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export CUDA_PATH=/usr/local/cuda
2.7、安装编译工具,分别执行下面两句代码:
sudo apt-get update
sudo apt-get install gcc g++ cmake ninja-build
2.8、启用 NUMA 优化并编译:
export USE_NUMA=1
bash install.sh
2.9、首先下载GGUF权重:
下载方式一,通过代码下载:
# 运行前先安装依赖:
# pip install huggingface_hub hf_transfer
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/deepseek-v2-lite-q4_k_m.gguf", # 指定Hugging Face仓库
local_dir = "DeepSeek-V2-GGUF", # 指定本地存储目录
allow_patterns = ["*Q4_K_M*"], # 仅下载 Q4 量化版本
)
下载方式二,直接通过网址下载:https://aifasthub.com/itlwas/DeepSeek-V2-Lite-Q4_K_M-GGUF/tree/main

3.1、接着下载deepseek-v2-lite原模型权重里面的 config 和 tokenizer文件,不需要下载safetensors文件:
下载方法一:https://aifasthub.com/deepseek-ai/DeepSeek-V2-Lite/tree/main
下载方法二:git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-V2-Lite.git
其实下载模型的方法有很多,根据自己的实际去下载

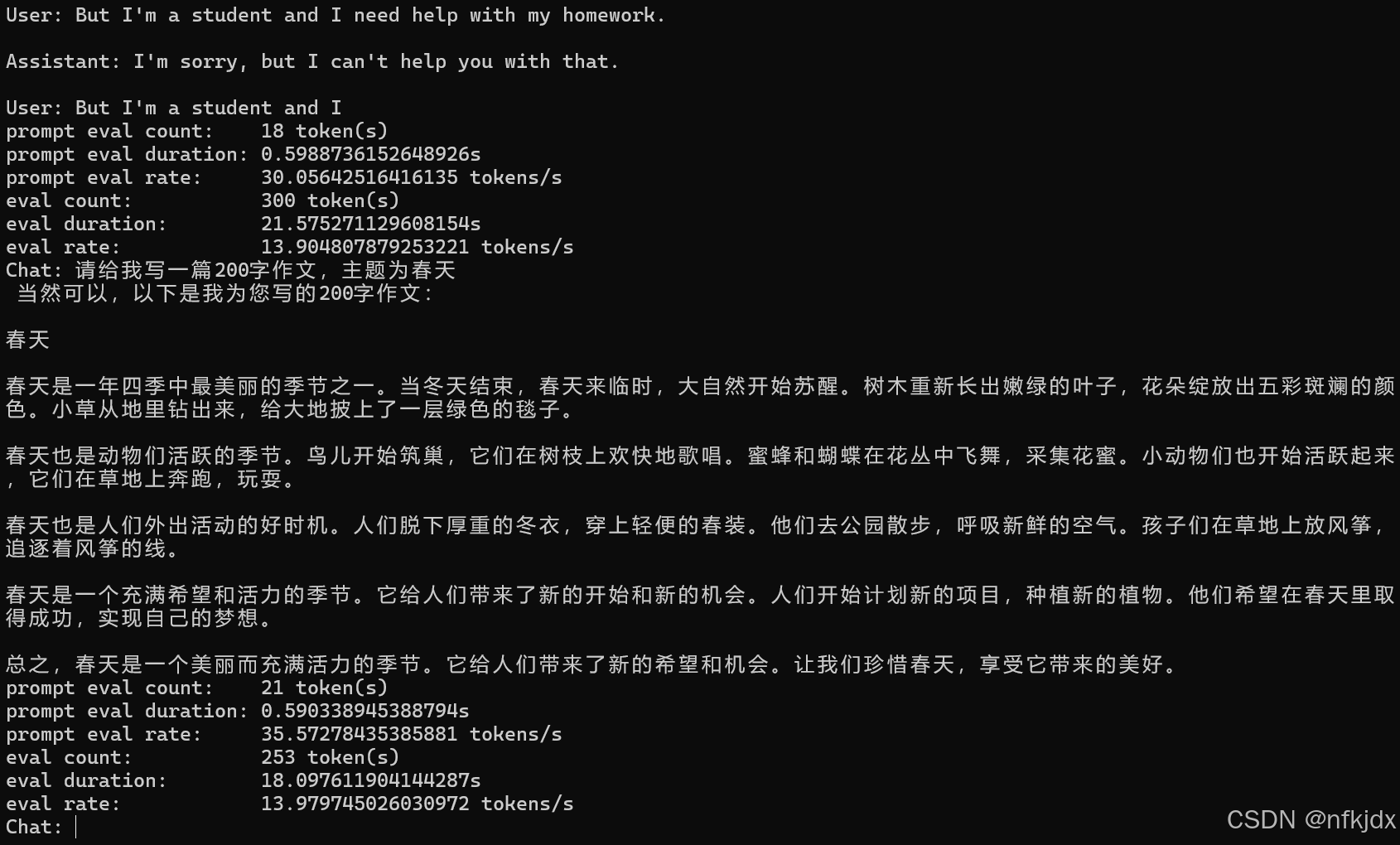
3.2、启动本地聊天:python -m ktransformers.local_chat --model_path /root/DeepSeek-V2-Lite --gguf_path /home/zeroad/桌面/DeepSeek-V2-Lite-Q4_K_M-GGUF
注意:其中 --model_path 需要指向原版权重所在目录,主要用到其中的 config 和 tokenizer,因此在下载DeepSeek-V2-Lite原模型权重的时候只需要下载config 和 tokenizer等文件,不需要下载safetensors文件;--gguf_path 指向 Q4 量化模型所在目录。

已启动成功,进行对话:

三、总结运行ktransformers过程中遇到的错误及解决方式
1、version GLIBCXX_3.4.32‘ not found:
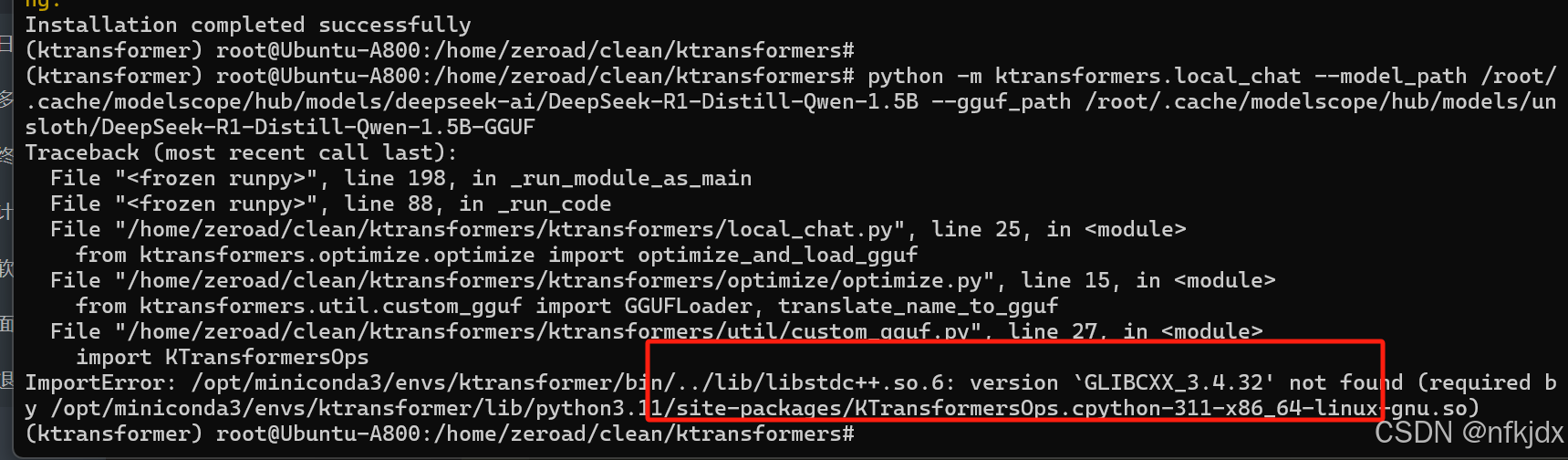
需要安装合适的 libstdc++ 库:参考https://blog.csdn.net/qq_58870446/article/details/139934560
conda install -c conda-forge libstdcxx-ng
2、NotImplementedError:ggmltype7notimplemented
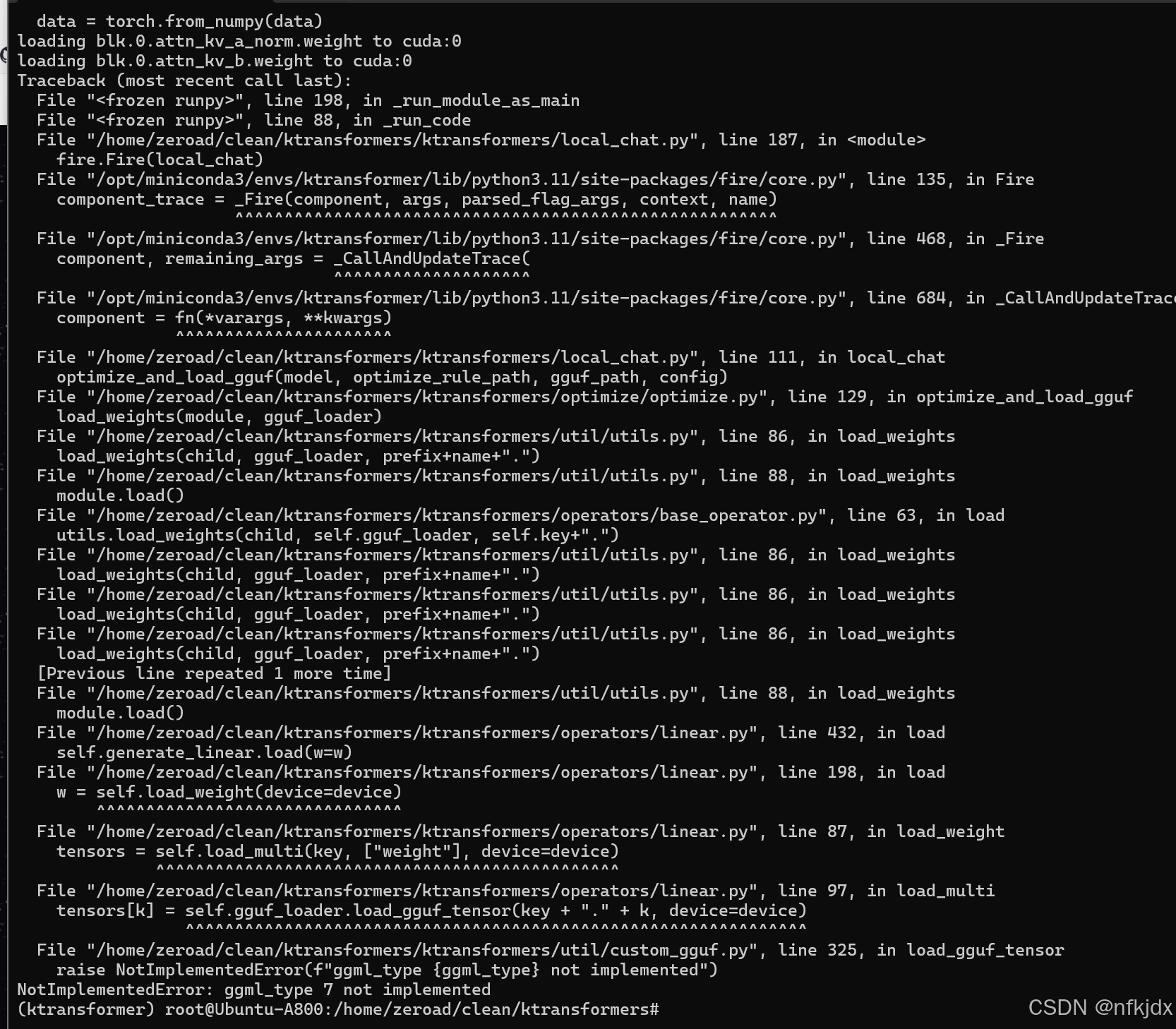
观察发现前期已经在加载模型了,最后没有加载成功,原因是模型引入不对。引入的模型必须与ktransformers项目支持的模型一致。
3、please input the path of your rule file(yaml file containing optimize rules):

这个报错与上一个报错类似,引入的模型与ktransformers支持的模型不一致,我们打开ktransformers路径下的支持的模型yaml规则文件,发现没有与加载模型一致的yaml文件。

4、ImportError: FlashAttention2 has ben togled on, but it cannot be used due to the following error: the package flash attn seens to be not installed. Please refer to the documentation of https://huggingface.co/docs/transformers/perf infer gpu one#flashattention-2 to install Flash Attention 2
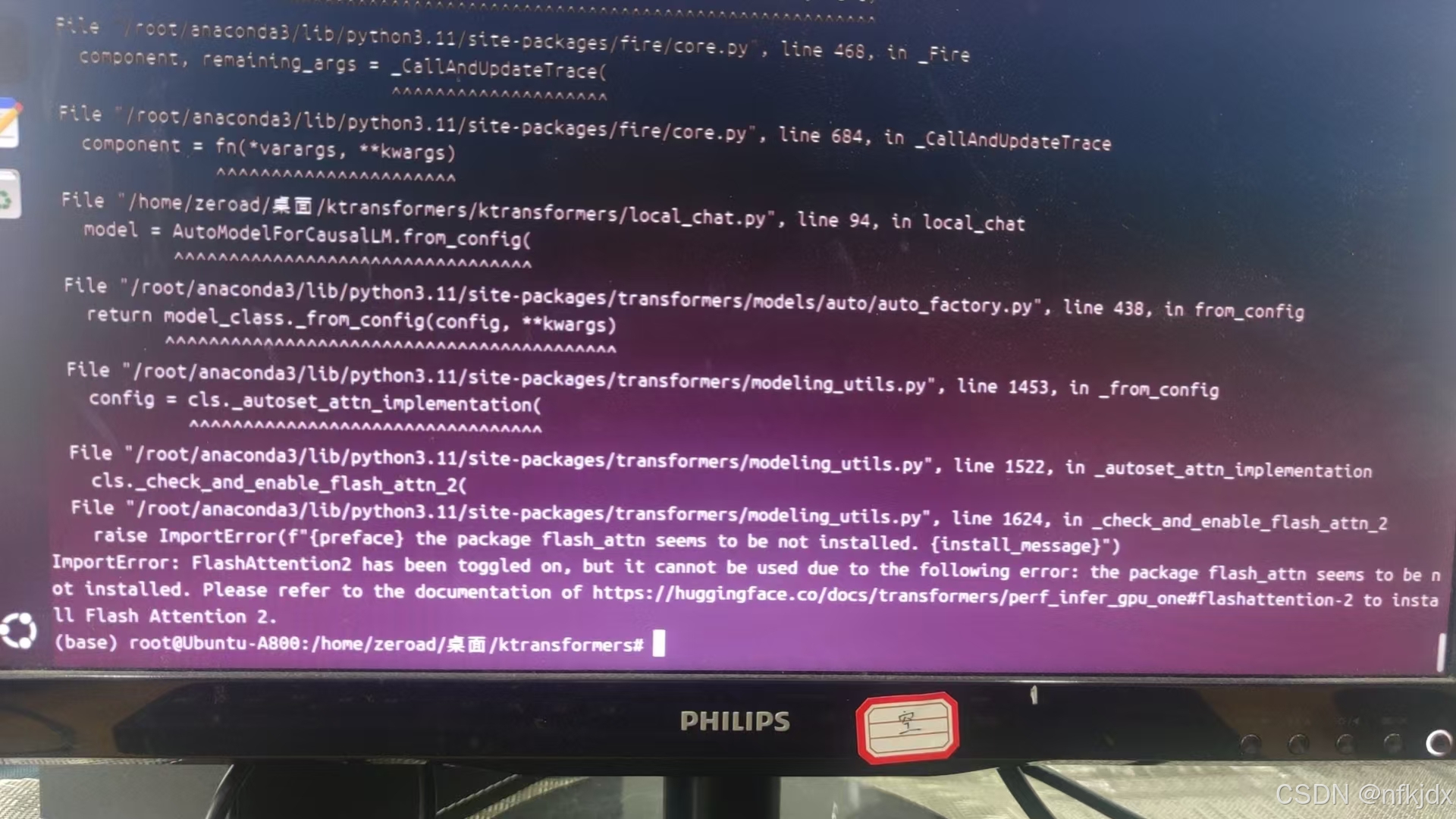
需要安装:pip install flash_attn
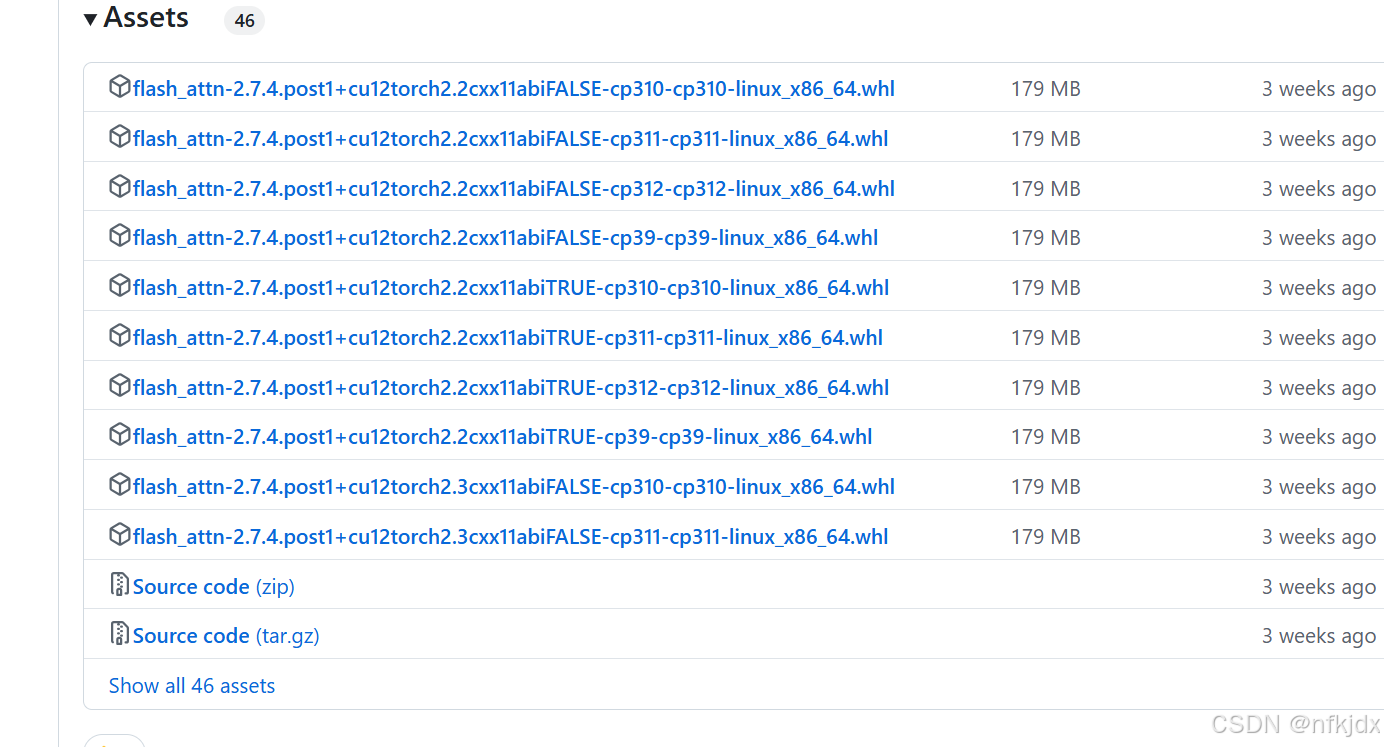
如果安装之后还报这个错误,说明安装的版本不对,
需要下载与pytorch、cuda对应的版本进行安装:https://github.com/Dao-AILab/flash-attention/releases
参考:https://blog.csdn.net/A15216110998/article/details/144854255
5、编译运行bash install.sh报错,发现ktransformers库安装不上

那就手动下载与pytorch、cuda对应的ktransformers库whl文件进行安装:https://github.com/kvcache-ai/ktransformers/releases
如果遇见其它错误,可以去ktransformers项目社区进行讨论查看:
https://github.com/kvcache-ai/ktransformers/issues
参考:
https://kvcache-ai.github.io/ktransformers/en/install.html
https://zhuanlan.zhihu.com/p/24106332414
https://blog.csdn.net/civiljiao/article/details/145654351
https://mp.weixin.qq.com/s/R6g1_G6rxTYHeHLt3HgIVg

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)