Stable Diffusion|SD3已开源,内附工作流及模型!
SD3采用了与Sora相同的底层架构,并引入了全新的多模态DiT(Multimodal。

翘首以待的SD3终于在6月12日放出了开源模型,不过,稍显遗憾的是,仅放出了medium(2B)版本,完整版本的大模型依然未开源。根据官方通告,将来完整版依然会开源。
之前就有很多人在讨论,SD3是否会超越当前市场上的领头羊Midjourney,成为AI绘画领域的新标杆。
#01
/介绍
SD3采用了与Sora相同的底层架构,并引入了全新的多模态DiT(Multimodal
Diffusion
Transformer)模型,使得画面质量、文字渲染、复杂对象理解能力都有了显著提升。
新一代文生图大模型Stable Diffusion 3,在填写Waitlist后可以在HuggingFace免费下载,当前开源的包含三种中型参数模型,包括:
-
sd3_medium.safetensors 包括 MMDiT 和 VAE 权重,但不包括任何文本编码器。
-
sd3_medium_incl_clips_t5xxlfp8.safetensors 包含所有必要的权重,包括 T5XXL 文本编码器的 fp8 版本,提供质量和资源要求之间的平衡。
-
sd3_medium_incl_clips.safetensors 包括除 T5XXL 文本编码器之外的所有必需权重。它需要最少的资源,但如果没有 T5XXL 文本编码器,模型的性能将会有所不同。
三种不同规则的模型,可以根据自己的需求以及GPU选择。
图像质量与美学体系
SD3在图像质量上的提升是显而易见的。它不仅拥有DALL-E 3的文生图准确性,同时也具备Midjourney V6的美学体系。

通过对比测试,我们可以看到SD3在处理复杂场景和细节方面的能力远超前代产品。例如,在处理包含多个对象和文本元素的场景时,SD3能够更准确地理解和渲染用户输入的指令。
语义理解与指令展现
SD3的另一个显著优势是其对复杂语义的理解能力。在输入相同的prompt指令时,SD3能够更真实地展现美术风格,并对指令进行更精确的展现。
这一点在Midjourney中也有所体现,但SD3在理解和执行复杂指令方面表现得更为出色。

SD3的技术亮点
MMIDT架构
SD3采用了MMDiT架构,这是一种专为处理多模态能力而设计的架构。它结合了文本和图像两种模态。
通过三种不同的文本嵌入模型——两个CLIP模型和一个T5,以及一个自编码模型来编码图像token。
这种架构使得图像和文本信息之间可以相互流动和交互,从而在生成的结果中提高对内容的整体理解和视觉表现。
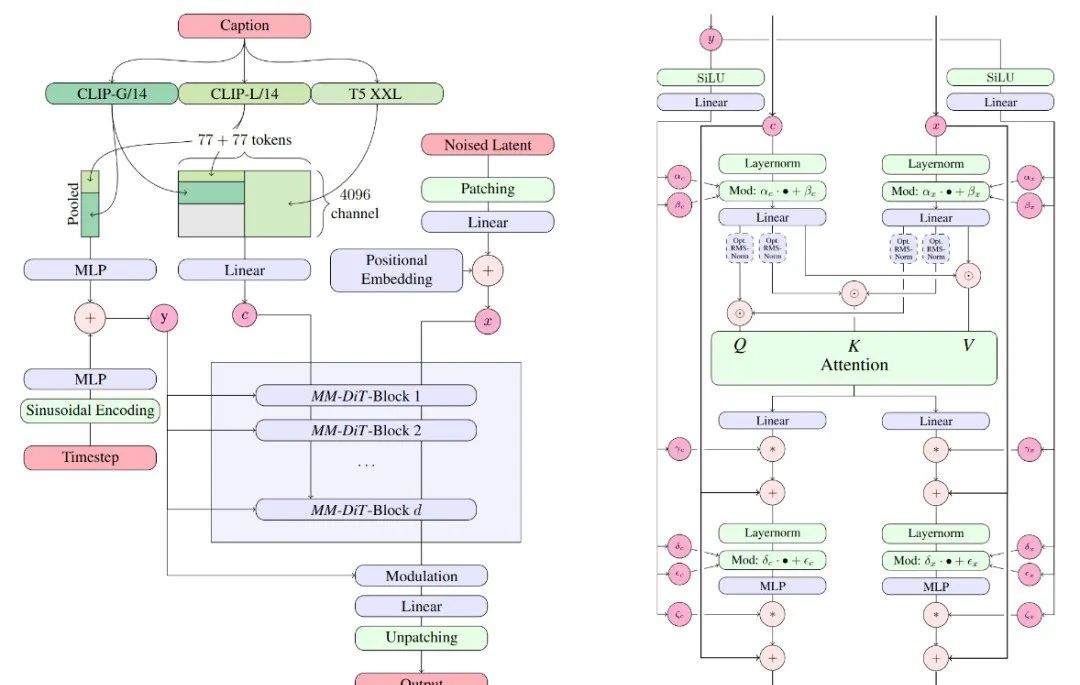
图像-文本对齐与VAE
SD3在图像-
文本对齐方面的表现尤为突出。它使用了强大的VAE(变分自编码器)技术,这不仅提高了模型的质量,而且实际上带来了更快的训练速度。这种技术的应用,使得SD3在512x512分辨率下的表现令人难以置信,即使在较小的图像尺寸下,也能捕捉到丰富的细节。

光影操控与IC-Light
除了核心的绘画功能,SD3还可能与IC-Light这样的AI图像照明操纵工具相结合,实现对光影的精细控制。
IC-Light能够在不依赖复杂提示的情况下,通过简单的文本描述或背景条件,对图像的光照进行调整,创造出各种光影效果。

#02
/使用
目前仅最新版的ComfyUI支持SD3,将ComfyUI更新到最新。
1、模型下载
2、模型安装
官方发布了一个2b的基础模型sd3_medium.safetensors,安装路径:ComfyUI\models\checkpoints
发布了三个clip模型:clip_g.safetensors、clip_l.safetensors、t5xxl_fp8_e4m3fn.safetensors,安装路径:ComfyUI\models\clip
3、基础工作流下载
加载工作流后,主要进行加载模型设置:
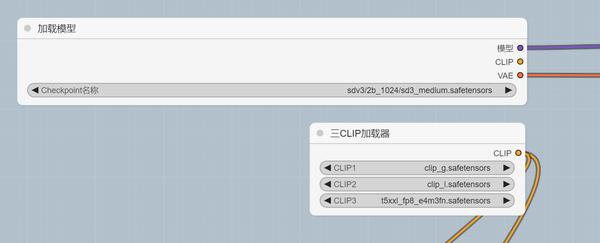
模型选择sd3_medium.safetensors,三个CLIP分别选择clip_g.safetensors、clip_l.safetensors、t5xxl_fp8_e4m3fn.safetensors。
其余配置采用默认即可。
4、官方推荐提示词:
a female character with long, flowing hair that appears to be made of
ethereal, swirling patterns resembling the Northern Lights or Aurora Borealis.
The background is dominated by deep blues and purples, creating a mysterious
and dramatic atmosphere. The character’s face is serene, with pale skin and
striking features. She wears a dark-colored outfit with subtle patterns. The
overall style of the artwork is reminiscent of fantasy or supernatural genres
Digital art, portrait of an anthropomorphic roaring Tiger warrior with full
armor, close up in the middle of a battle, behind him there is a banner with
the text “Open Source”.
photo of a dog and a cat both standing on a red box, with a blue ball in the
middle with a parrot standing on top of the ball. The box has the text “SD3”
selfie photo of a wizard with long beard and purple robes, he is apparently in
the middle of Tokyo. Probably taken from a phone.
A vibrant street wall covered in colorful graffiti, the centerpiece spells
“SD3 MEDIUM”, in a storm of colors
photo of a young woman with long, wavy brown hair tied in a bun and glasses.
She has a fair complexion and is wearing subtle makeup, emphasizing her eyes
and lips. She is dressed in a black top. The background appears to be an urban
setting with a building facade, and the sunlight casts a warm glow on her
face.
anime art of a steampunk inventor in their workshop, surrounded by gears,
gadgets, and steam. He is holding a blue potion and a red potion, one in each
hand
photo of picturesque scene of a road surrounded by lush green trees and
shrubs. The road is wide and smooth, leading into the distance. On the right
side of the road, there’s a blue sports car parked with the license plate
spelling “SD32B”. The sky above is partly cloudy, suggesting a pleasant day.
The trees have a mix of green and brown foliage. There are no people visible
in the image. The overall composition is balanced, with the car serving as a
focal point.
photo of young man in a black suit, white shirt, and black tie. He has a
neatly styled haircut and is looking directly at the camera with a neutral
expression. The background consists of a textured wall with horizontal lines.
The photograph is in black and white, emphasizing contrasts and shadows. The
man appears to be in his late twenties or early thirties, with fair skin and
short, dark hair.
photo of a woman on the beach, shot from above. She is facing the sea, while
wearing a white dress. She has long blonde hair
可SD3能非常好的理解自然语言,比SDXL更上一层楼。
5、跑图!
#03
/效果对比
1. 第一组内容提示词,看一下语义理解能力。
a cat,a destroyed badly damaged space ship,beautiful beach,broken windows,
grass and flowers grow
around,sunny,ocean(一只猫,一艘被摧毁的严重受损的宇宙飞船,美丽的海滩,破碎的窗户,周围长着草和鲜花,阳光明媚,海洋)

SD1.5:emmmmmm,这怎么成两张了,小猫咪看起来不太高兴啊,挎着个脸,海滩不太美丽雅,阳光呢?
SD2.0:不是,小猫怎么从船里长出来了,还有月亮你是怎么回事儿?不是说好的太阳吗。
SDXL:整体还行,但画面有点昏暗,配色不是很舒服。
SD3:王炸!语义理解能力极强,阳光明媚,美丽的海滩,鲜花……关键细节什么的都很好,画面也很和谐。
2. 再来测一下相对位置关系理解,这个更加考验模型能力。
a dog,hold hot dog,outdoors,grass(一只狗,叼着热狗,户外,草地)

SD1.5:emmmmmm,这小狗的热狗怎么悬空了啊?你的热狗怎么成香肠了?
SD2.0:SD2.0比较聪明,他直接把热狗放到了地上,哈哈这样你就挑不出我毛病了吧,但是语义理解不对啊大哥。
SDXL:基本理解了我的意思,但是这个画风,以及这个舌头衔接太奇怪了吧。
SD3:王炸!光效衔接都非常自然,小狗很可爱,热狗也很有食欲。
3.测试一下二次元动漫人物。
((anime style)),1girl, indoors, sitting on the sofa, living room, pink hair,
blue eyes, from back, from above, face towards viewer, playing video games,
holding controller, white shirt, short, parted lips, anime
production(((动漫风格)),1女孩,室内,坐在沙发上,客厅,粉红色的头发,蓝眼睛,从后面,从上面,脸朝向观众,玩电子游戏,拿着手柄玩游戏,白衬衫,短,分开的嘴唇,动漫制作)

SD1.5:底模过于抽象。。。很多细节都丢失了,对比着看一下吧,从头发到眼睛。
SD1.5:千手观音?
SDXL:有点感觉了,但是你的画风画质很难评
SD3:没的说,依然是王炸!从头发到眼镜,从整体画质,到细节,No1!
动漫还做了另一组对比图。

4. 再测试一下不同的科幻风格
robot droids, in the desert , colorful, dutch angle(机器人, 在沙漠中, 五颜六色)

SD1.5:这机器人,是营养不良吧?哈哈哈 还有说好的五颜六色呢?
SD2:右边这哥们你的手臂掉了~其他不必多说了,懂得都懂嘿嘿
SDXL:还行,但是这个机器人怎么这么丑呢,三条腿不对称
SD3:同样很Nice,依然是王炸,除了这颜色跟我理解的五颜六色不太一样。
5. 再测一组真人图片,难度也蛮大的,要求在水下。
1boy,underwater,green eyes,white skirt,looking at
viewer(1个男孩,水下,绿色眼睛,白色裙子,看着观众)

SD1.5:恐怖片。。。
SD 2.0:更恐怖了,有点像泡开的奥特曼。。
SDXL:还可以,凑合能看,就是这绿的啊。
SD3:非常NIce!
再测另一组真人的。

6. 来一组风景。
universe,stars,moon(宇宙、星星、月亮)

SD1.5:有点像我爸的微信头像。。。
SD 2.0:凑合,就是构图雪崩。
SDXL:SDXL是真的好容易画卡通。
SD3:这氛围就到位了。
7.最后一个SD3最棒的,文字嵌入。
Cyberpunk style,urban,1 robot,an electronic screen with“
Khazix”(赛博朋克风格,都市,1个机器人,一个带有“卡兹克斯”的电子屏幕)

这个就不评价了,因为过往的SD模型,都不支持文字嵌入,目前SD3是独一份。
文章使用的AI绘画SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,有需要的小伙伴文末扫码自行获取。
针对各位AIGC初学者,这里列举了一条完整的学习计划,感兴趣的可以阅读看看,希望对你的学习之路有所帮助,废话不多说,进入正题:

目标应该是这样的:
第一阶段(30天):AI-GPT从入门到深度应用
该阶段首先通过介绍AI-GPT从入门到深度应用目录结构让大家对GPT有一个简单的认识,同时知道为什么要学习GPT使用方法。然后我们会正式学习GPT深度玩法应用场景。
-----------
- GPT的定义与概述
- GPT与其他AI对比区别
- GPT超强记忆力体验
- 万能GPT如何帮你解决一切问题?
- GPT表达方式优化
- GPT多类复杂应用场景解读
- 3步刨根问底获取终极方案
- 4步提高技巧-GPT高情商沟通
- GPT深度玩法应用场景
- GPT高级角色扮演-教学老师
- GPT高级角色扮演-育儿专家
- GPT高级角色扮演-职业顾问
- GPT高级角色扮演-专业私人健身教练
- GPT高级角色扮演-心理健康顾问
- GPT高级角色扮演-程序UX/UI界面开发顾问
- GPT高级角色扮演-产品经理
- GPT高级技巧-游戏IP角色扮演
- GPT高级技巧-文本冒险游戏引导
- GPT实操练习-销售行业
- GPT实操练习-菜谱推荐
- GPT实操练习-美容护肤
- GPT实操练习-知识问答
- GPT实操练习-语言学习
- GPT实操练习-科学减脂
- GPT实操练习-情感咨询
- GPT实操练习-私人医生
- GPT实操练习-语言翻译
- GPT实操练习-作业辅导
- GPT实操练习-聊天陪伴
- GPT实操练习-育儿建议
- GPT实操练习-资产配置
- GPT实操练习-教学课程编排
- GPT实操练习-活动策划
- GPT实操练习-法律顾问
- GPT实操练习-旅游指南
- GPT实操练习-编辑剧本
- GPT实操练习-面试招聘
- GPT实操练习-宠物护理和训练
- GPT实操练习-吸睛爆款标题生成
- GPT实操练习-自媒体爆款软件拆解
- GPT实操练习-自媒体文章创作
- GPT实操练习-高效写作推广方案
- GPT实操练习-星座分析
- GPT实操练习-原创音乐创作
- GPT实操练习-起名/解梦/写诗/写情书/写小说
- GPT提升工作效率-Word关键字词提取
- GPT提升工作效率-Word翻译实现
- GPT提升工作效率-Word自动填写、排版
- GPT提升工作效率-Word自动纠错、建议
- GPT提升工作效率-Word批量生产优质文章
- GPT提升工作效率-Excel自动化实现数据计算、分析
- GPT提升工作效率-Excel快速生成、拆分及合并实战
- GPT提升工作效率-Excel生成复杂任务实战
- GPT提升工作效率-Excel用Chat Excel让效率起飞
- GPT提升工作效率–PPT文档内容读取实现
- GPT提升工作效率–PPT快速批量调整PPT文档
- GPT提升工作效率-文件批量创建、复制、移动等高效操作
- GPT提升工作效率-文件遍历、搜索等高效操作
- GPT提升工作效率-邮件自动发送
- GPT提升工作效率-邮件自动回复
- GPT接入QQ与QQ群实战
- GPT接入微信与微信群实战
- GPT接入QQ与VX多用户访问实战
- GPT接入工具与脚本部署实战
第二阶段(30天):AI-绘画进阶实战
该阶段我们正式进入AI-绘画进阶实战学习,首先通过了解AI绘画定义与概述 ,AI绘画的应用领域 ,PAI绘画与传统绘画的区别 ,AI绘画的工具分类介绍的基本概念,以及AI绘画工具Midjourney、Stable Diffusion的使用方法,还有AI绘画插件和模板的使用为我们接下来的实战设计学习做铺垫。
- -----------
AI绘画定义与概述 - AI绘画的应用领域
- AI绘画与传统绘画的区别
- AI绘画的工具分类介绍
- AI绘画工具-Midjourney
- AI绘画工具-百度文心一格
- AI绘画工具-SDWebUI
- AI绘画工具-Vega AI
- AI绘画工具-微信中的AI绘画小程序
- Midjourney学习-Discord账号的注册
- Midjourney Bot界面讲解
- Midjourney提示词入门
- Midjourney高级提示词
- Midjourney版本参数学解读
- Midjourney功能参数
- Midjourney上采样参数
- AI绘画组合应用1-Midjourney + GPT
- AI绘画组合应用2-Stable Diffusion + GPT
- AI绘画组合应用3-AI绘画+ GPT +小红书
- AI绘画组合应用4-AI绘画+ GPT +抖音
- AI绘画组合应用5-AI绘画+ GPT +公众号
- AI绘画组合应用6-AI绘画+ GPT + AI视频
- AI绘画组合应用7-AI绘画+ GPT + 小说人物/场景
- AI绘画设计-Logo设计
- AI绘画设计-套用万能公式
- AI绘画设计-引用艺术风格
- AI绘画设计-GPT加速设计方案落地
- AI绘画设计-Vega AI渲染线稿生成设计
- AI绘画设计-摄影
- AI绘画设计-头像设计
- AI绘画设计-海报设计
- AI绘画设计-模特换装
- AI绘画设计-家具设计
- AI绘画设计-潘顿椅设计
- AI绘画设计-沙发设计
- AI绘画设计-电视柜设计
- AI绘画设计-包装设计的提示词构思
第三阶段(30天):AI-视频高段位
恭喜你,如果学到这里,你基本可以找到一份AIGC副业相关的工作,比如电商运营、原画设计、美工、安全分析等岗位;如果新媒体运营学的好,还可以从各大自媒体平台收获平台兼职收益。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- -----------
AI视频定义与概述 - AI视频制作-方案与创新
- AI视频制作-各种工具实操
- AI视频制作-美学风格(油画/插画/日漫/水墨)
- AI视频制作-形象设定(人物形象服装/造型/表情)
- AI视频画面特效处理
- AI视频画面拼接
- AI视频画面配音
- AI视频画面包装
- AI视频锁定人物逐一精修
- 多种表情动作/情节
- 动态模型转换-视频内部元素关键帧
- 动态模型转换-图像整体运动
- 动态模型转换-虚拟人
- 动态模型转换-表面特效
- AI自媒体视频-深问GPT,获取方案
- AI自媒体视频-风格设置(诗歌/文言文等)
- AI自媒体视频-各行业创意视频设计思路
- AI视频风格转换
- AI视频字数压缩
- AI视频同类型衍生
- AI视频Pormpt公式
第四阶段(20天):AI-虚拟数字人课程
- -----------
AI数字人工具简介 - AI工作台界面功能展示及介绍
- AI数字人任务确定
- AI数字人素材准备
- AI知识、语料的投喂
- AI模型训练
- AI训练成果展示及改进
- AI数字人直播系统工具使用
- AI人物在各平台直播
- AI数字人在OBS平台直播
第五阶段(45天以上):AIGC-多渠道变现课程
该阶段是项目演练阶段,大家通过使用之前学习过的AIGC基础知识,项目中分别应用到了新媒体、电子商务等岗位能帮助大家在主流的新媒体和电商平台引流和带货变现。
-----------
- AI-小红书引流变现
- AI-公众号引流变现
- AI-知乎引流变现
- AI-抖音引流/带货变现
- AI-写作变现
- AI-B站引流变现
- AI-快手引流变现
- AI-百家号引流变现
- AI-制作素材模板出售变现
- AI-周边定制变现
- AI-手机壳图案定制变现
- AI-周边产品定制变现
- AI-服装图案定制变现
- AI-个性头像定制变现
- AI-起号与知识付费变现
- AI-实现淘宝销售变现
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名AIGC的正确特征了。
这份完整版的AIGC资料我已经打包好,需要的点击下方二维码,即可前往免费领取!


欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)