
2024年十大前沿图像分割模型汇总:工作机制、优点和缺点介绍
2024年十大前沿图像分割模型汇总:工作机制、优点和缺点介绍
《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
引言

图像分割是计算机视觉中的一项关键任务,涉及将图像分割成多个片段,从而更容易分析图像中的不同对象或区域。近年来,人们开发了众多型号来实现该领域的最先进性能,每种型号都带来了独特的优势。下面,我们将探讨2024年的十大图像分割模型,详细介绍它们的工作机制、优点和缺点。
1.Segment Anything Model(SAM)
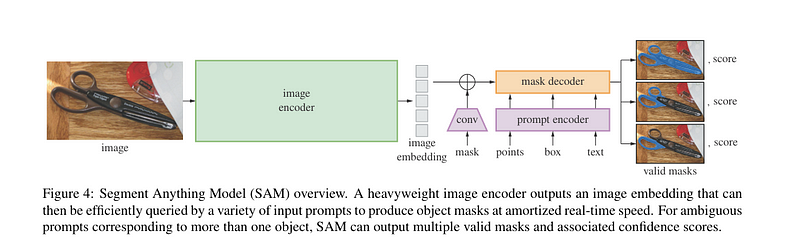
SAM是一种多功能分割模型,旨在处理任何图像,允许用户只需点击几下即可执行对象分割。它支持各种类型的输入提示,如边界框或文本,使其高度灵活。
SAM利用大规模的注释图像数据集,使用基于图像的方法进行分割。它使用视觉变换器(ViTs)作为主干,并通过用户指定的提示适应不同的分割需求。
优点
- 多功能: 可以处理多种类型的分割提示。
- 可扩展性: 在大规模数据集上进行预训练,使其具有高度的可推广性。
- 快速: 交互式应用程序的近实时性能。
缺点
- 高计算要求: 需要大量资源进行训练和推理。
- 有限的细粒度控制: 可能难以处理复杂图像中的微小精确细节。
2. DINOv2

DINOv2建立在自监督学习的基础上,可生成可用于分割和其他视觉任务的高质量图像特征。与其前身不同,DINOv2不需要手动标记数据进行训练。
DINOv 2使用ViT架构,使用自监督学习进行训练,以理解对象边界和语义。它可以在预训练后针对分割任务进行微调。
优点
- **无标签依赖性:**无需标签数据集即可实现高性能。
- **可转移特性:**可适应各种下游任务。
缺点
- 不专门用于分割: 需要进行微调,以获得最佳分割性能。
- 潜在过拟合: 在微调期间可能对特定数据集过拟合。
3. Mask2Former

Mask 2Former是一个通用的图像分割模型,它将语义、实例和全景分割的任务统一到一个框架中。
该模型引入了一个Masked-Attention Transformer,其中注意力机制被应用于被掩蔽的token。这使得模型能够专注于重要区域并相应地对其进行细分。
优点
- 统一框架: 可以有效地处理多个分段任务。
- 高精度: 在各种基准测试中获得最先进的结果。
缺点
- 复杂的体系结构: 基于transformer的方法是资源密集型的。
- 训练难度: 需要大量的计算能力进行训练。
4. Swin Transformer
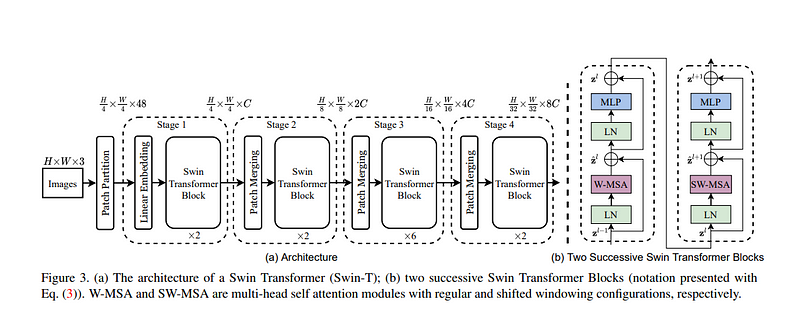
Swin Transformer是一个分层的Transformer模型,设计用于计算机视觉任务,包括图像分割。它建立在通过引入移位窗口机制将transformer用于视觉任务的想法之上。
Swin Transformer采用基于窗口的注意机制,每个窗口处理图像的局部区域,从而实现高效和可扩展的分割。
优点
- 高效的注意力: 基于窗口的机制减少了计算负载。
- 分层表示: 生成多尺度特征图,提高分割精度。
缺点
- 有限的全球背景: 专注于本地区域,可能缺少全球背景。
- 复杂性: 实施和微调需要先进的知识。
5. SegFormer

SegFormer是一个简单而有效的基于transformer的语义分割模型,它不依赖于位置编码,并使用分层架构进行多尺度特征表示。
SegFormer将轻量级MLP解码器与transformers集成在一起,以创建多尺度特征层次结构,从而提高性能和效率。
优点
- 简单高效: 避免复杂的设计选择,如位置编码。
- 强大的泛化能力: 在各种细分任务中表现良好。
缺点
- 限于语义分割: 不像其他一些模型那样通用。
- 缺乏精细控制: 可能难以处理较小的对象。
6. MaxViT
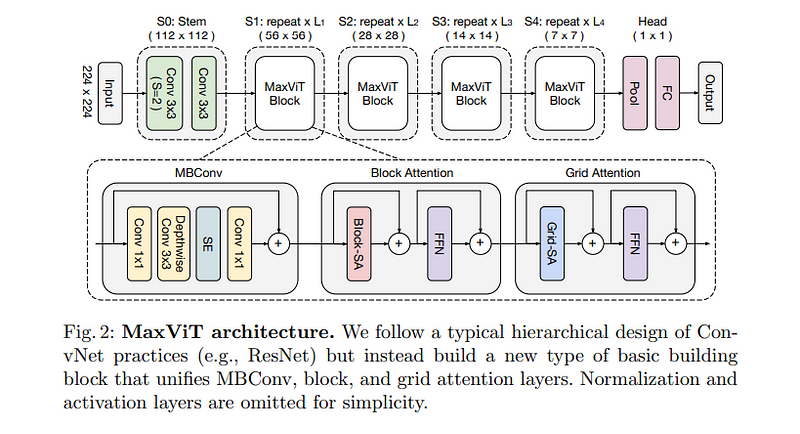
MaxViT引入了多轴Transformer架构,结合了局部和全局注意力机制,为各种视觉任务(包括分割)提供了强大的结果。
MaxViT利用基于窗口和基于网格的注意力,使模型能够有效地捕获局部和全局依赖关系。
优点
- 综合注意力: 局部和全局特征提取之间的平衡。
- 多功能: 在各种视觉任务中表现良好。
缺点
- 高复杂性: 需要大量的计算资源进行训练和推理。
- 难以实现: 复杂的架构使其更难在实践中应用。
7. HRNet
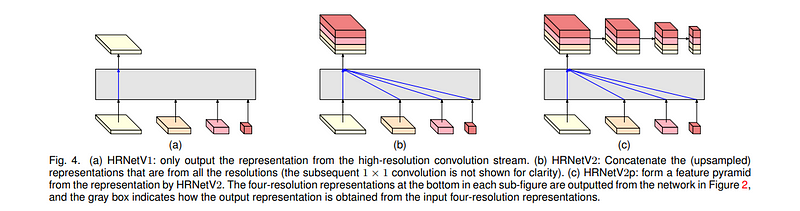
HRNet的设计目的是在整个模型中保持高分辨率的表示,而不像传统的架构那样对中间特征图进行下采样。
HRNet使用并行卷积构建高分辨率表示,确保空间信息在整个网络中得到保留。
优点
- **高分辨率输出:**擅长在分割过程中保留细节。
- **强大的性能:**Consistency在基准测试中提供高准确性。
缺点
- 重型模型: 计算成本高,尺寸大。
- 慢推理: 比一些轻量级模型慢,使其不太适合实时应用。
8. Deeplabv3+

DeepLabv3+是一个强大且广泛使用的语义分割模型,利用atrous卷积和空间金字塔池化模块来捕获多尺度上下文信息。
DeepLabv3+以多种速率应用atrous卷积来捕获多尺度特征,然后是用于精确对象边界的解码器模块。
优点
- 高度准确: 在语义分割任务中实现最佳性能。
- 良好的支持: 广泛用于工业和研究,有多种实现。
缺点
- 资源密集型: 需要大量的内存和计算能力。
- 不适合实时应用: 与最近的模型相比相对较慢。
9. U-Net++
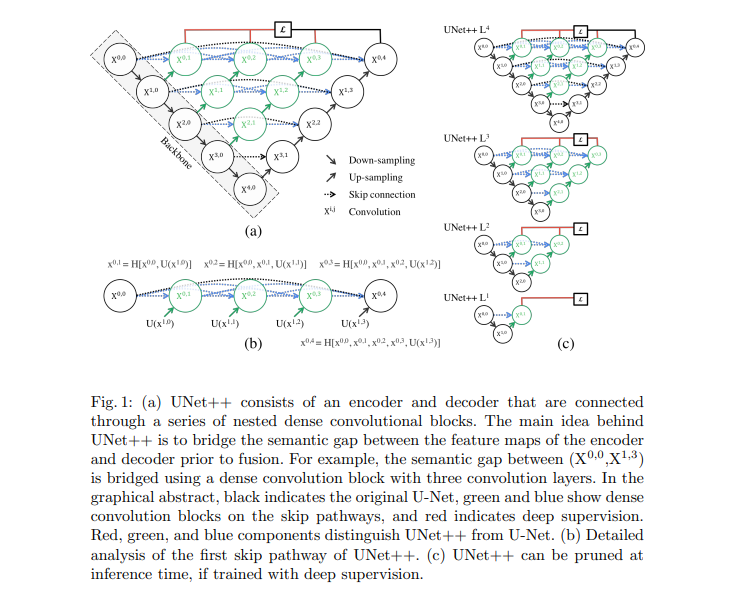
U-Net++是流行的U-Net架构的嵌套版本,旨在提高医学图像分割的性能。
U-Net++通过一系列嵌套和密集的跳跃连接修改了原始U-Net,有助于更好地捕获空间特征。
优点
- 在医学应用方面很强: 专门为医学图像分割任务而设计。
- 提高准确性: 在许多情况下实现比原始U-Net更好的结果。
缺点
- 医疗重点: 不像列表中的其他型号那样通用。
- 资源需求: 由于其嵌套架构,需要更多的资源。
10. GC-Net (Global Context Network)
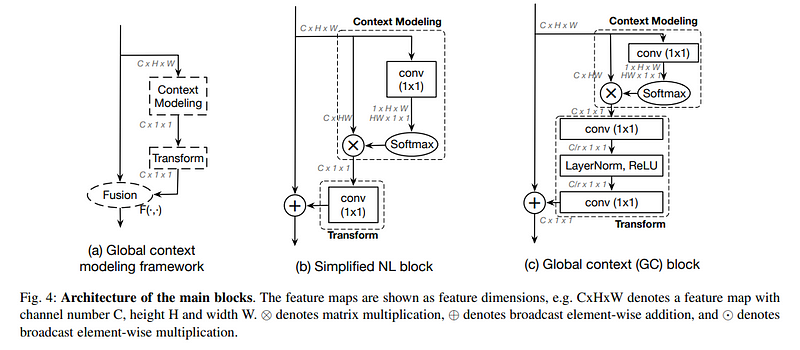
GC-Net引入了一个全局上下文模块,可以捕获图像中的长距离依赖关系,使其有效地执行语义和实例分割任务。全局上下文模块从整个图像中聚合上下文信息,从而在复杂场景中实现更好的分割精度。
GC-Net采用全局上下文块,通过从整个图像而不仅仅是局部区域捕获上下文来增强特征图。这种全局视图允许模型更准确地分割对象,特别是在上下文很重要的情况下(例如,大的或被遮挡的物体)。
优点
- 捕获长距离重复性: 非常适合在上下文相关的情况下分割复杂图像。
- 高效: 尽管它的功能强大,但全局上下文模块在计算上是高效的,使其适用于各种应用程序。
缺点
- 有限的实时应用: 虽然高效,但在需要极快推理时间的场景中仍然可能会遇到困难。
- 未针对小对象进行优化: 由于其专注于全局上下文,可能会与较小的对象发生冲突。
总结
本文总结了截至2024年顶级的图像分割模型,每个模型都提供了针对不同任务和背景定制的独特优势。从SAM和Mask 2Former等多功能框架到U-Net++和GC-Net等高度专业化的架构,该领域不断发展,效率和准确性都有所提高。在选择细分模型时,必须考虑特定的用例和资源约束。像Swin Transformer和DeepLabv 3+这样的高性能模型提供了出色的准确性,但更轻,更高效的模型,如SegFormer和GC-Net可能更适合实时应用。毫无疑问,这个充满活力和快速发展的领域将继续取得突破,新的模型将推动计算机视觉的可能性。
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
更多推荐



 56
56 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)