KDD-99数据集:机器学习实战网络入侵检测
随着互联网使用和机器学习的兴起,入侵检测已成为机器学习领域一个重要课题。

概述
随着互联网使用和机器学习的兴起,入侵检测已成为机器学习领域一个重要课题。入侵检测系统作为一种监控网络流量并在发生异常行为/连接时发出警报的系统。其目的是阻止入侵者访问网络并破坏网络。入侵者可能是网络中任何具有犯罪意图的不受欢迎的连接。
有需要的朋友关注公众号【小Z的科研日常】,获取更多内容。
01、项目描述
对于这个项目,我们使用了 KDD-cup-99 数据集,它是原始 KDD99 数据集的 10% 子集。该数据集在学术界广泛用于异常/入侵检测领域的研究。KDD-cup-99 或 KDD99 及其链接如下:KDD Cup 1999 Data
该数据集包含 42 个特征和 494,020 条记录。目标特征指定连接类型,可分为正常和异常连接类型。但是,异常连接可以进一步分为四种类型的网络攻击,即探测、拒绝服务 (DOS)、R2L(Root 2 Local)和 U2R(User 2 Root)。
02、数据清洗
该数据中有超过一半的冗余记录。删除这些记录后,我们剩下 145,585 条记录。数据中没有缺失值。接下来将定义输入和输出特征。
print(df.shape)
print(df.columns)
df.info()
input_cols = list(df.columns)[1:-1]
target_col = 'label'
numeric_cols = df.select_dtypes(include=np.number).columns.tolist()[:-1]
接下来我们进行数据预处理。使用 MinMaxScaler 缩放数值数据,使用 Label Encoder 将分类特征编码为数值。
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import LabelEncoder
scaler = MinMaxScaler()
scaler.fit(df[numeric_cols])
df[numeric_cols] = scaler.transform(df[numeric_cols])
le = LabelEncoder()
target = df['label']
df['label'] = le.fit_transform(target)
df['protocol_type'] = le.fit_transform(df['protocol_type'])
df['service'] = le.fit_transform(df['service'])
df['flag'] = le.fit_transform(df['flag'])
将数据集分为 70% 的训练集和 30% 的测试集,以训练模型并评估预测。
rom sklearn.model_selection import train_test_split
train_df, test_df = train_test_split(df, test_size=0.3, random_state=42)
print(train_df.shape)
print(test_df.shape)
train_inputs = train_df[input_cols].copy()
train_targets = train_df[target_col].copy()
test_inputs = test_df[input_cols].copy()
test_targets = test_df[target_col].copy()
数据集中我们具有足够的样本量,其中包含 41 个输入特征,但需要更长的计算时间,并且也会导致模型过拟合。因此,使用随机森林从数据集中选择最重要的特征。
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectFromModel
sel = SelectFromModel(RandomForestClassifier(n_estimators = 5, random_state=42))
sel.fit(train_inputs, train_targets)
selected_feat = train_inputs.columns[(sel.get_support())]
print(selected_feat)
print(len(selected_feat))
03、模型训练和预测
接下来我们将使用KDD99数据集进行模型训练和预测
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
rf = RandomForestClassifier(n_estimators = 1000, random_state = 42)
rf.fit(train_inputs[selected_feat], train_targets);
preds_rf = rf.predict(test_inputs[selected_feat])
score_rf = accuracy_score(test_targets, preds_rf)
print("Accuracy of Random Forests: ", score_rf)
from sklearn.tree import DecisionTreeClassifier
dc = DecisionTreeClassifier()
dc.fit(train_inputs[selected_feat], train_targets);
preds_dc = dc.predict(test_inputs[selected_feat])
score_dc = accuracy_score(test_targets, preds_dc)
print("Accuracy of Decision Tree: ", score_dc)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=7)
knn.fit(train_inputs[selected_feat], train_targets)
preds_knn = knn.predict(test_inputs[selected_feat])
score_knn = accuracy_score(test_targets, preds_knn)
print("Accuracy of K Nearest Neighbors: ", score_knn)
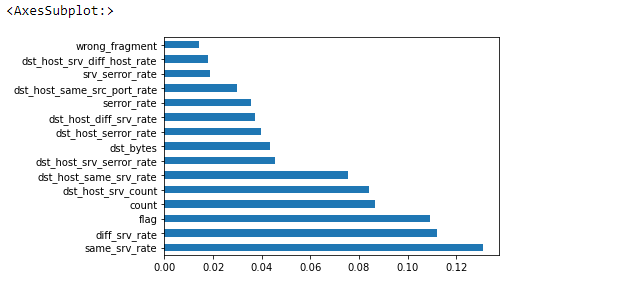
我们尝试绘制输入特征的特征重要性,看看是否可以从中提取一些有价值的信息。
model = RandomForestClassifier()
model.fit(train_inputs, train_targets)
(pd.Series(model.feature_importances_, index=train_inputs.columns)
.nlargest(15)
.plot(kind='barh'))
运行随机森林分类器进行特征选择后选择的特征是 serror_rate、same_srv_rate、diff_srv_rate、
dst_host_diff_srv_rate。
但是,根据条形图,我们绘制了最重要的七个特征,分别是 diff_srv_rate、same_srv_rate、dst_host_same_srv_rate、flag、count、dst_host_srv_count 和 dst_host_srv_serror_rate。
我们尝试这七个特征训练所有三个模型,观察是否有什么不同。
rf_1 = RandomForestClassifier(n_estimators = 1000, random_state = 42)
rf_1.fit(train_inputs[["diff_srv_rate", "same_srv_rate", "dst_host_same_srv_rate", "flag",
"count", "dst_host_srv_count", "dst_host_srv_serror_rate"]], train_targets);
preds_rf_1 = rf_1.predict(test_inputs[["diff_srv_rate", "same_srv_rate",
"dst_host_same_srv_rate", "flag", "count", "dst_host_srv_count", "dst_host_srv_serror_rate"]])
score_rf_1 = accuracy_score(test_targets, preds_rf_1)
print("Accuracy of Random Forest Classifier is: ", score_rf_1)
dc_1 = DecisionTreeClassifier()
dc_1.fit(train_inputs[["diff_srv_rate", "same_srv_rate", "dst_host_same_srv_rate",
"flag", "count", "dst_host_srv_count", "dst_host_srv_serror_rate"]], train_targets);
preds_dc_1 = dc_1.predict(test_inputs[["diff_srv_rate", "same_srv_rate",
"dst_host_same_srv_rate", "flag", "count", "dst_host_srv_count", "dst_host_srv_serror_rate"]])
score_dc_1 = accuracy_score(test_targets, preds_rf_1)
print("Accuracy of Decision Tree Classifier is :" score_dc_1)
knn_1 = KNeighborsClassifier(n_neighbors=7)
knn_1.fit(train_inputs[["diff_srv_rate", "same_srv_rate",
"dst_host_same_srv_rate", "flag", "count", "dst_host_srv_count", "dst_host_srv_serror_rate"]], train_targets)
preds_knn_1 = knn_1.predict(test_inputs[["diff_srv_rate",
"same_srv_rate", "dst_host_same_srv_rate", "flag", "count", "dst_host_srv_count", "dst_host_srv_serror_rate"]])
score_knn_1 = accuracy_score(test_targets, preds_knn_1)
print("Accuracy of K Nearest Neighbors is: ", score_knn_1)

通过使用比以前更多的相关特征,准确率如何从 96.6% 提高到 97.6%。随机森林和决策树的效果最好,准确率可达 97.65%,而 K 近邻的准确率略低,为 97.64%。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 26
26 0
0- 0


 已为社区贡献5条内容
已为社区贡献5条内容










 服务器0元试用
服务器0元试用
所有评论(0)