

kvcache原理、参数量、代码详解
kv cache原理
kvcache一句话来说就是把每个token在过Transformer时乘以W_K,W_V这俩参数矩阵的结果缓存下来。训练的时候不需要保存。推理解码生成时都是自回归auto-regressive的方式,也就是每次生成一个token,都要依赖之前token的结果。如果没生成一个token的时候乘以W_K,W_V这俩参数矩阵要对所有token都算一遍,代价非常大,所以缓存起来就叫kvcache。
举个例子,假如prompt=“The largest city of China is”,输入是6个tokens,返回是"Shang Hai"这两个tokens。整个生成过程如下:
- 当生成"Shang"之前,kvcache把输入6个tokens都乘以W_K,W_V这两参数矩阵,也就是缓存了6个kv。这时候过self-attention+采样方案(greedy、beam、top k、top p等),得到"Shang"这个token
- 当生成"Shang"之后,再次过transformer的token只有"Shang"这一个token,而不是整个“The largest city of China is Shang”句子,这时再把"Shang"这一个token对应的kvcache和之前6个tokens对应的kvcache拼起来,成为了7个kvcache。"Shang"这一个token和前面6个tokens就可以最终生成"Hai"这个token
为什么有kv cache,没有q cache?
一句话来说q cache并没有用。展开解释就是整个scaled dot production公式 s o f t m a x ( Q K T d k ) V softmax(\frac{QK^T}{\sqrt{d_k}})V softmax(dkQKT)V,每次新多一个Q中的token时,用新多的这个token和所有tokens的K、V去乘就好了,Q cache就成多余的了。再拿刚才例子强调一下,当生成"Shang"之后,再次过transformer的token只有"Shang"这一个token,而不是整个“The largest city of China is Shang”句子
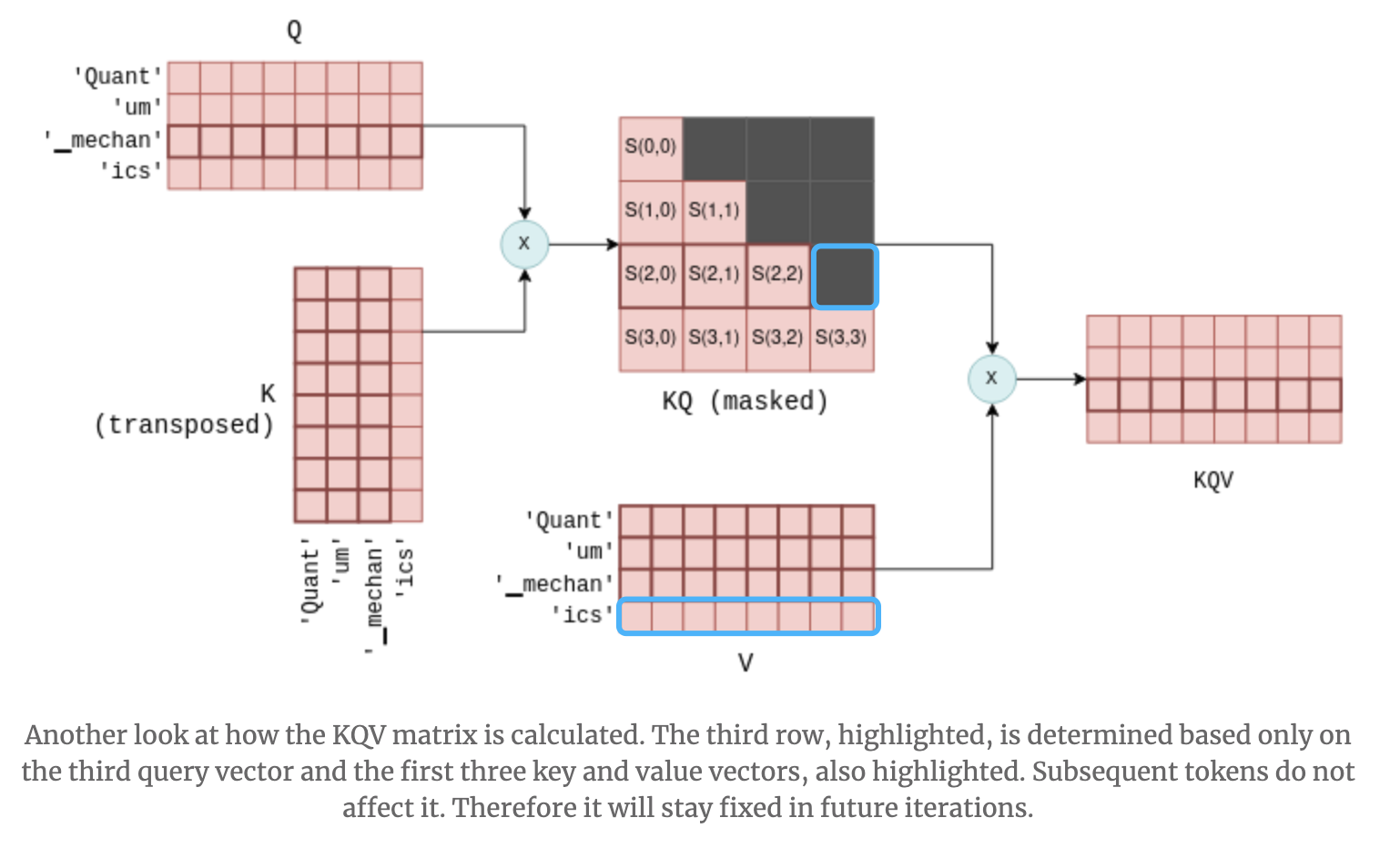
那么问题就又来了,生成"Shang"这个token时,感觉是“The largest city of China is”这6个tokens的query都用了,但是生成"Hai"这个token时,只依赖了"Shang"这个token的query嘛?这个问题其实是没有的,每个token的生成都只依赖前一个Q和之前所有的KV!!!借用https://www.omrimallis.com/posts/understanding-how-llm-inference-works-with-llama-cpp/#further-optimizing-subsequent-iterations里的下图来看:
- 训练的时候’Quant’,‘um’,'_mechan’的下一个token在矩阵乘法时对应的是蓝框,被mask没了
- 推理的时候在给定’Quant’,‘um’,'_mechan’的时候,已有的序列长度是3,矩阵乘法是由图中红框决定的,刚好和未来没读到的蓝框token没有任何关系。同时,‘_mechan’的下一个token只和’_mechan’的Q有关,和’Quant’,'um’的Q是无关的!!!所以每个token的生成都只依赖前一个Q和之前所有的KV,这也是kvcache能work下去的基础!
kv cache参数量估计
假设输入序列的长度为s,输出序列的长度为n,层数为l,以float16来保存KV cache,那么KV cache的峰值显存占用大小为
b
∗
(
s
+
n
)
h
∗
l
∗
2
∗
2
=
4
l
h
(
s
+
n
)
b*(s+n)h*l*2*2 =4lh(s +n)
b∗(s+n)h∗l∗2∗2=4lh(s+n)。这里第一个2表示K/V cache,第个2表示float16占2个bytes。
以GPT3为例,对比KV cache与模型参数占用显存的大小。GPT3模型占用显存大小为350GB。假设批次大小b=64,输入序列长度 =512,输出序列长度n =32,则KV cache占用显存大约为
4
l
h
(
s
+
n
)
4lh(s + n)
4lh(s+n)= 164,282,499,072bytes约等于164GB,大约是模型参数显存的0.5倍
提供一个删减版的kvcache代码
class GPT2Attention(nn.Module):
def __init__(self):
super().__init__()
# ...
def forward(
self,
hidden_states: Optional[Tuple[torch.FloatTensor]],
layer_past: Optional[Tuple[torch.Tensor]] = None,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = False,
output_attentions: Optional[bool] = False,
) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]], ...]:
# hidden_states对应query
# encoder_hidden_states对应key和value
if encoder_hidden_states is not None:
if not hasattr(self, "q_attn"):
raise ValueError(
"If class is used as cross attention, the weights `q_attn` have to be defined. "
"Please make sure to instantiate class with `GPT2Attention(..., is_cross_attention=True)`."
)
query = self.q_attn(hidden_states)
key, value = self.c_attn(encoder_hidden_states).split(self.split_size, dim=2)
attention_mask = encoder_attention_mask
else:
query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)
query = self._split_heads(query, self.num_heads, self.head_dim)
key = self._split_heads(key, self.num_heads, self.head_dim)
value = self._split_heads(value, self.num_heads, self.head_dim)
if layer_past is not None:
past_key, past_value = layer_past
# 切成多头以后,shape是[bs, num_heads, seq_length, head_dim],所以dim=-2就是seq_length对应的那个维度,拼一下就有了新的kvcache
key = torch.cat((past_key, key), dim=-2)
value = torch.cat((past_value, value), dim=-2)
if use_cache is True:
present = (key, value)
else:
present = None
if self.reorder_and_upcast_attn:
attn_output, attn_weights = self._upcast_and_reordered_attn(query, key, value, attention_mask, head_mask)
else:
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
attn_output = self._merge_heads(attn_output, self.num_heads, self.head_dim)
attn_output = self.c_proj(attn_output)
attn_output = self.resid_dropout(attn_output)
outputs = (attn_output, present)
if output_attentions:
outputs += (attn_weights,)
# 最后输出的present就是当前的kvcache
return outputs # a, present, (attentions)
以GPT2为例,分析下kvcache的传递链路
测试code:
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
text = "The largest city of China is"
encoded_input = tokenizer(text, return_tensors='pt')
forward_output = model(**encoded_input)
# forward_output['logits'].shape
# len(forward_output['past_key_values'])
generate_output = model.generate(**encoded_input)
generate_text = tokenizer.decode(generate_output[0])
print(generate_text)
这个脚本依赖了transformers库中的以下几个文件:
modeling_gpt2.py
文件位置anaconda3/envs/python37/lib/python3.7/site-packages/transformers/models/gpt2/modeling_gpt2.py
GPT2Model
class GPT2Model(GPT2PreTrainedModel):
_keys_to_ignore_on_load_missing = ["attn.masked_bias"]
def __init__(self, config):
super().__init__(config)
self.embed_dim = config.hidden_size
self.wte = nn.Embedding(config.vocab_size, self.embed_dim)
self.wpe = nn.Embedding(config.max_position_embeddings, self.embed_dim)
self.drop = nn.Dropout(config.embd_pdrop)
self.h = nn.ModuleList([GPT2Block(config, layer_idx=i) for i in range(config.num_hidden_layers)])
# 此处删去大量和kvcache无关的代码
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPastAndCrossAttentions]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
# 此处删去大量和kvcache无关的代码,开始进入和kvcache相关部分
# past_key_values 是所有层的kv cache
if past_key_values is None:
past_length = 0
past_key_values = tuple([None] * len(self.h))
else:
past_length = past_key_values[0][0].size(-2)
# 此处删去大量和kvcache无关的代码
for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
# Model parallel
if self.model_parallel:
torch.cuda.set_device(hidden_states.device)
# Ensure layer_past is on same device as hidden_states (might not be correct)
if layer_past is not None:
layer_past = tuple(past_state.to(hidden_states.device) for past_state in layer_past)
# Ensure that attention_mask is always on the same device as hidden_states
if attention_mask is not None:
attention_mask = attention_mask.to(hidden_states.device)
if isinstance(head_mask, torch.Tensor):
head_mask = head_mask.to(hidden_states.device)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if self.gradient_checkpointing and self.training:
# 训练的时候把kvcache给置空
def create_custom_forward(module):
def custom_forward(*inputs):
# None for past_key_value
return module(*inputs, use_cache, output_attentions)
return custom_forward
outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(block),
hidden_states,
None,
attention_mask,
head_mask[i],
encoder_hidden_states,
encoder_attention_mask,
)
else:
# 只有推理的时候才需要把kvcache存下来
outputs = block(
hidden_states,
layer_past=layer_past,
attention_mask=attention_mask,
head_mask=head_mask[i],
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
use_cache=use_cache,
output_attentions=output_attentions,
)
hidden_states = outputs[0]
if use_cache is True:
presents = presents + (outputs[1],)
if output_attentions:
all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (outputs[3 if use_cache else 2],)
# Model Parallel: If it's the last layer for that device, put things on the next device
if self.model_parallel:
for k, v in self.device_map.items():
if i == v[-1] and "cuda:" + str(k) != self.last_device:
hidden_states = hidden_states.to("cuda:" + str(k + 1))
hidden_states = self.ln_f(hidden_states)
hidden_states = hidden_states.view(output_shape)
# Add last hidden state
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [hidden_states, presents, all_hidden_states, all_self_attentions, all_cross_attentions]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=presents,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
GPT2Block
GPT2Model是由GPT2Block堆叠而成的,每一层GPT2Block都各自传入kvcache,在forward参数里叫做layer_past:
class GPT2Block(nn.Module):
def __init__(self, config, layer_idx=None):
super().__init__()
hidden_size = config.hidden_size
inner_dim = config.n_inner if config.n_inner is not None else 4 * hidden_size
self.ln_1 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
self.attn = GPT2Attention(config, layer_idx=layer_idx)
self.ln_2 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
if config.add_cross_attention:
self.crossattention = GPT2Attention(config, is_cross_attention=True, layer_idx=layer_idx)
self.ln_cross_attn = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
self.mlp = GPT2MLP(inner_dim, config)
def forward(
self,
hidden_states: Optional[Tuple[torch.FloatTensor]],
layer_past: Optional[Tuple[torch.Tensor]] = None,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = False,
output_attentions: Optional[bool] = False,
) -> Union[Tuple[torch.Tensor], Optional[Tuple[torch.Tensor, Tuple[torch.FloatTensor, ...]]]]:
residual = hidden_states
hidden_states = self.ln_1(hidden_states)
attn_outputs = self.attn(
hidden_states,
layer_past=layer_past,
attention_mask=attention_mask,
head_mask=head_mask,
use_cache=use_cache,
output_attentions=output_attentions,
)
attn_output = attn_outputs[0] # output_attn: a, present, (attentions)
outputs = attn_outputs[1:]
# residual connection
hidden_states = attn_output + residual
if encoder_hidden_states is not None:
# add one self-attention block for cross-attention
if not hasattr(self, "crossattention"):
raise ValueError(
f"If `encoder_hidden_states` are passed, {self} has to be instantiated with "
"cross-attention layers by setting `config.add_cross_attention=True`"
)
residual = hidden_states
hidden_states = self.ln_cross_attn(hidden_states)
cross_attn_outputs = self.crossattention(
hidden_states,
attention_mask=attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_attentions=output_attentions,
)
attn_output = cross_attn_outputs[0]
# residual connection
hidden_states = residual + attn_output
outputs = outputs + cross_attn_outputs[2:] # add cross attentions if we output attention weights
residual = hidden_states
hidden_states = self.ln_2(hidden_states)
feed_forward_hidden_states = self.mlp(hidden_states)
# residual connection
hidden_states = residual + feed_forward_hidden_states
if use_cache:
outputs = (hidden_states,) + outputs
else:
outputs = (hidden_states,) + outputs[1:]
# 最后注释展示使用kvcache时候outputs的tuple内容,present就是这一层的kvcache
return outputs # hidden_states, present, (attentions, cross_attentions)
GPT2Attention
class GPT2Attention(nn.Module):
def __init__(self, config, is_cross_attention=False, layer_idx=None):
super().__init__()
# 此处删除大量和kvcache无关的代码
self.embed_dim = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.embed_dim // self.num_heads
# 此处删除大量和kvcache无关的代码
if self.is_cross_attention:
self.c_attn = Conv1D(2 * self.embed_dim, self.embed_dim)
self.q_attn = Conv1D(self.embed_dim, self.embed_dim)
else:
self.c_attn = Conv1D(3 * self.embed_dim, self.embed_dim)
self.c_proj = Conv1D(self.embed_dim, self.embed_dim)
self.attn_dropout = nn.Dropout(config.attn_pdrop)
self.resid_dropout = nn.Dropout(config.resid_pdrop)
self.pruned_heads = set()
# 此处删除大量和kvcache无关的代码
def _attn(self, query, key, value, attention_mask=None, head_mask=None):
attn_weights = torch.matmul(query, key.transpose(-1, -2))
if self.scale_attn_weights:
attn_weights = attn_weights / torch.full(
[], value.size(-1) ** 0.5, dtype=attn_weights.dtype, device=attn_weights.device
)
# Layer-wise attention scaling
if self.scale_attn_by_inverse_layer_idx:
attn_weights = attn_weights / float(self.layer_idx + 1)
if not self.is_cross_attention:
# if only "normal" attention layer implements causal mask
query_length, key_length = query.size(-2), key.size(-2)
causal_mask = self.bias[:, :, key_length - query_length : key_length, :key_length]
mask_value = torch.finfo(attn_weights.dtype).min
# Need to be a tensor, otherwise we get error: `RuntimeError: expected scalar type float but found double`.
# Need to be on the same device, otherwise `RuntimeError: ..., x and y to be on the same device`
mask_value = torch.full([], mask_value, dtype=attn_weights.dtype).to(attn_weights.device)
attn_weights = torch.where(causal_mask, attn_weights.to(attn_weights.dtype), mask_value)
if attention_mask is not None:
# Apply the attention mask
attn_weights = attn_weights + attention_mask
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
# Downcast (if necessary) back to V's dtype (if in mixed-precision) -- No-Op otherwise
attn_weights = attn_weights.type(value.dtype)
attn_weights = self.attn_dropout(attn_weights)
# Mask heads if we want to
if head_mask is not None:
attn_weights = attn_weights * head_mask
attn_output = torch.matmul(attn_weights, value)
return attn_output, attn_weights
# 此处删除大量和kvcache无关的代码
def _split_heads(self, tensor, num_heads, attn_head_size):
"""
Splits hidden_size dim into attn_head_size and num_heads
"""
new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
tensor = tensor.view(new_shape)
return tensor.permute(0, 2, 1, 3) # (batch, head, seq_length, head_features)
def _merge_heads(self, tensor, num_heads, attn_head_size):
"""
Merges attn_head_size dim and num_attn_heads dim into hidden_size
"""
tensor = tensor.permute(0, 2, 1, 3).contiguous()
new_shape = tensor.size()[:-2] + (num_heads * attn_head_size,)
return tensor.view(new_shape)
def forward(
self,
hidden_states: Optional[Tuple[torch.FloatTensor]],
layer_past: Optional[Tuple[torch.Tensor]] = None,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = False,
output_attentions: Optional[bool] = False,
) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]], ...]:
# hidden_states对应query
# encoder_hidden_states对应k和v
if encoder_hidden_states is not None:
if not hasattr(self, "q_attn"):
raise ValueError(
"If class is used as cross attention, the weights `q_attn` have to be defined. "
"Please make sure to instantiate class with `GPT2Attention(..., is_cross_attention=True)`."
)
query = self.q_attn(hidden_states)
key, value = self.c_attn(encoder_hidden_states).split(self.split_size, dim=2)
attention_mask = encoder_attention_mask
else:
query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)
query = self._split_heads(query, self.num_heads, self.head_dim)
key = self._split_heads(key, self.num_heads, self.head_dim)
value = self._split_heads(value, self.num_heads, self.head_dim)
if layer_past is not None:
past_key, past_value = layer_past
# 切成多头以后,shape是[bs, num_heads, seq_length, head_dim],所以dim=-2就是seq_length对应的那个维度,拼一下就有了新的kvcache
key = torch.cat((past_key, key), dim=-2)
value = torch.cat((past_value, value), dim=-2)
if use_cache is True:
present = (key, value)
else:
present = None
if self.reorder_and_upcast_attn:
attn_output, attn_weights = self._upcast_and_reordered_attn(query, key, value, attention_mask, head_mask)
else:
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
attn_output = self._merge_heads(attn_output, self.num_heads, self.head_dim)
attn_output = self.c_proj(attn_output)
attn_output = self.resid_dropout(attn_output)
outputs = (attn_output, present)
if output_attentions:
outputs += (attn_weights,)
# 最后输出的present就是当前的kvcache
return outputs # a, present, (attentions)
GenerationMixin
Sample策略都在这个类中,代码路径在anaconda3/envs/python37/lib/python3.7/site-packages/transformers/generation/utils.py 中,以greedy_search为例,通过以下代码调用生成下一个token
# forward pass to get next token
outputs = self(
**model_inputs,
return_dict=True,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
)

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 30
30 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容









所有评论(0)