

【MacOS】openai 语音识别模型 whisper 本地部署教程(cpu+mps方案)
一些艰辛的解决报错历程目前macOS+whisper+mps的文章好像比较少 发一个分享一下如果有帮到大家 请多多点赞~
目录
2. 无法使用mac gpu 👉 使用whisper.cpp
系统环境:M1pro macOS 13.6
1. whisper 安装
openai-whisper
以下的语言全部支持识别,数字越小的识别越准确

参考视频链接与安装过程
-
安装homebrew
-
安装Python (不要超过3.10)
-
安装Pytorch
在官网按照以下方式选择以后,在终端输入下面的命令 安装pytorchvvhttps://pytorch.org/get-started/locally/https://pytorch.org/get-started/locally/
 https://pytorch.org/get-started/locally/
https://pytorch.org/get-started/locally/
-
安装ffmpeg
brew install ffmpeg -
安装rust
pip install rust -
安装whisper
pip install -U openai-whisper

注意事项
- python版本不要超过3.10
- 在Jupyter notebook使用 最好使用 homebrew 安装 ffmpeg
可能报错问题
-
homebrew安装报错 👉 使用命令2安装

2. 无法使用mac gpu 👉 使用whisper.cpp
GitHub - ggerganov/whisper.cpp: Port of OpenAI's Whisper model in C/C++Port of OpenAI's Whisper model in C/C++. Contribute to ggerganov/whisper.cpp development by creating an account on GitHub.![]() https://github.com/ggerganov/whisper.cpp 前面的whisper.ai我自己测试下来只能用cpu跑,命令行加上--device mps会报错,大家可以试一下,如果没问题的话可以继续用whisper.ai。
https://github.com/ggerganov/whisper.cpp 前面的whisper.ai我自己测试下来只能用cpu跑,命令行加上--device mps会报错,大家可以试一下,如果没问题的话可以继续用whisper.ai。
github上很多也反馈存在上述问题,无法使用mps。用cpu的处理速度比较慢,下面用whisper.cpp解决这个问题。测试下来速度有明显提升,大约3min可以用medium模型处理15min的日语视频。
操作步骤
1. 安装whisper.cpp
-
git clone <https://github.com/ggerganov/whisper.cpp.git> -
2. 打开网站,下载模型和对应.mlmodelc,放入whisper.cpp/model 文件夹中
ggerganov/whisper.cpp at main
https://huggingface.co/ggerganov/whisper.cpp/tree/main -
3. 把文件转换成wav文件(视频文件需要先事先提取音频)
ffmpeg -i ./xxxx.mp3 -ar 16000 -ac 1 -c:a pcm_s16le ./xxxx.wav -
4. 输入命令,并生成srt文件
./main -m models/ggml-medium.bin -f samples/xxxx.wav -l ja -osrt
可能报错问题
输入指令后一直卡死,把下面的进程kill掉

3. 生成翻译字幕
-
1. 生成英文字幕
./main -m models/ggml-medium.bin -f samples/test1.wav -l ja -osrt -tr -
2. 翻译成中文字幕
神经网络实用工具(整活)系列---使用OpenAI的翻译模型whisper实现语音(中、日、英等等)转中字,从此生肉变熟肉---基础篇_whisper模型翻译成中文-CSDN博客
https://blog.csdn.net/weixinhum/article/details/130998668- Google翻译方案成功,但是准确率一般
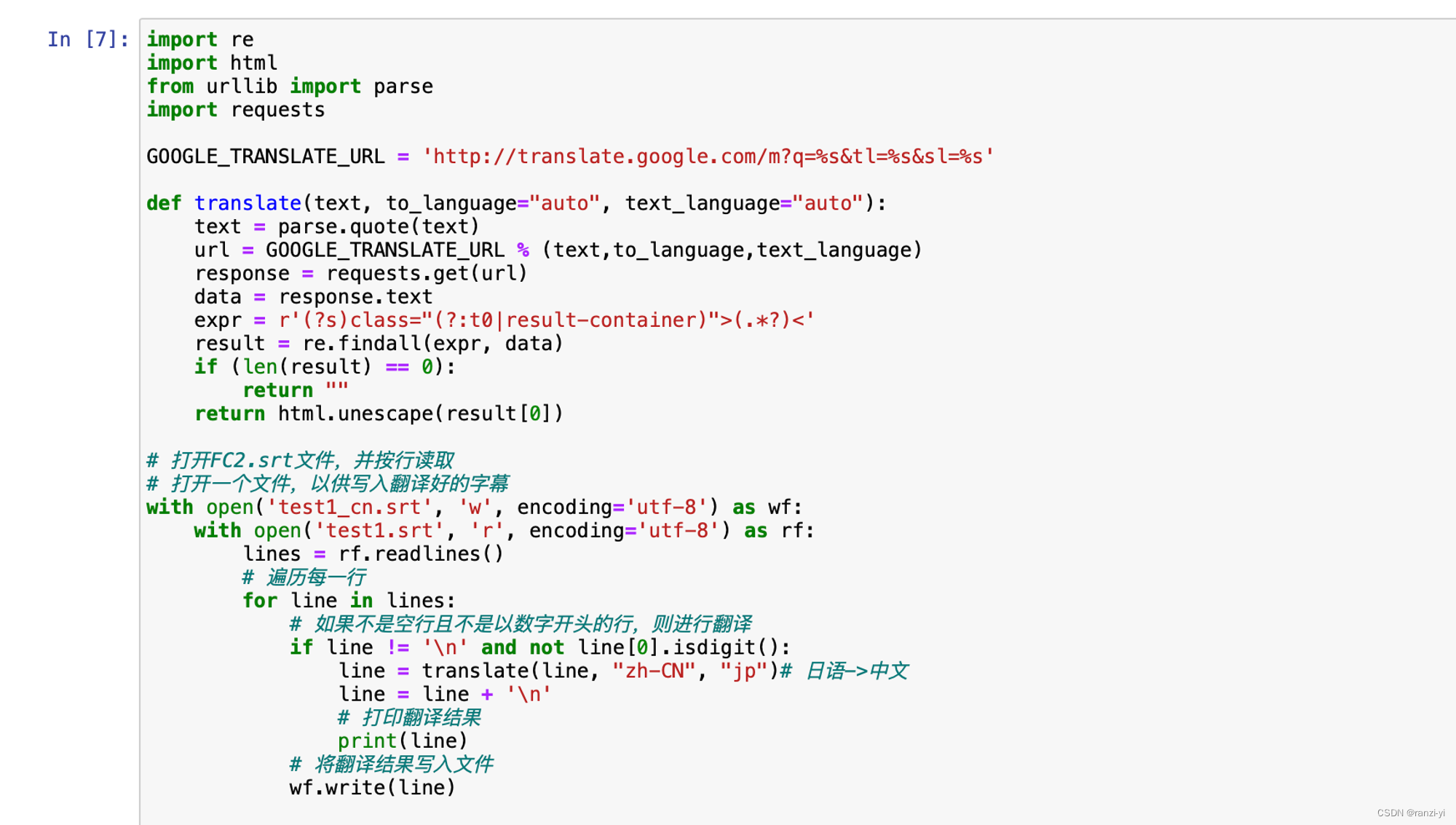
- Google翻译方案成功,但是准确率一般

一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)