k8s-daemonSet和HPA学习
K8s-DaemonSet和HPA自动扩缩容的学习记录
k8s-资源调度-DaemonSet学习
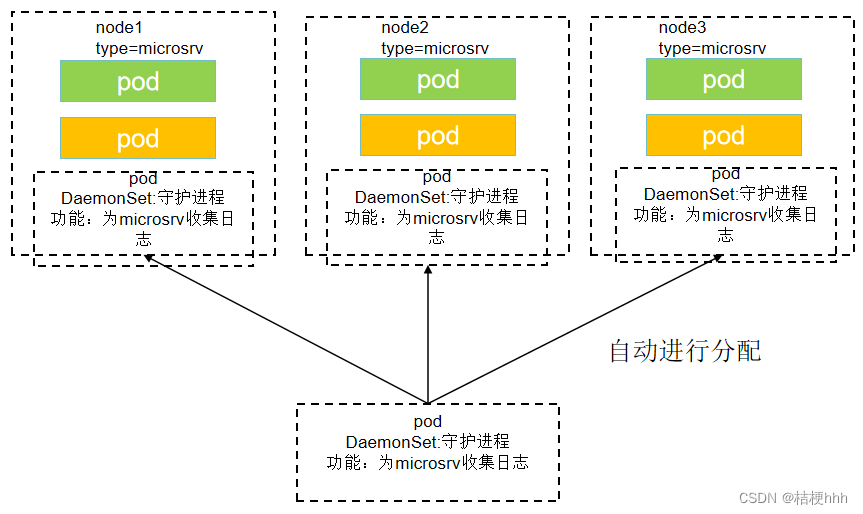
1)DaemonSet也就是守护进程,当启用DaemonSet后其会根据label自动挂载到指定的节点,无需手动分配。
2)如下图所示有3个node节点,其标签为microsrv,每个节点中的pod中部署了应用服务,每个服务都需要进行日志的收集。假设如果使用手动的方式,若有1000个node节点,则需要对1000个节点进行配置,十分麻烦。但是如果使用DaemonSet则只需要将该日志收集中的nodeSelector设置为node节点对应的标签,系统就会进行自动分配,可以减少很多的工作量。

1.配置文件
本配置文件的名称为fluentd-ds.yaml。
apiVersion: apps/v1
kind: DaemonSet #创建 DaemonSet类型资源
metadata:
name: fluentd #名字
spec:
selector:
matchLabels:
app: logging
template:
metadata:
labels:
app: logging
id: fluentd
name: fluentd
spec:
containers:
- name: fluentd-es
image: agilestacks/fluentd-elasticsearch:v1.3.0
env: #环境变量配置
- name: FLUENTD_ARGS #环境变量的key
value: -qq #环境变量的value
volumeMounts: #加载数据卷,避免数据丢失
- name: containers # 数据卷的名字
mountPath: /var/lib/docker/containers # 将数据卷挂载到容器内的那个目录
- name: varlog
mountPath: /varlog
volumes: # 定义数据卷
- hostPath: # 数据卷类型,主机路径的模式,也就是与 node 共享目录
path: /var/lib/docker/containers # node中的共享目录
name: containers # 定义的数据卷名称
- hostPath:
path: /var/log
name: varlog
# 使用以下命令进行对DaemonSet的创建
kubectl create -f fluentd-ds.yaml
2.给指定node节点添加DaemonSet
1)在本文中主要介绍nodeSelector的方式来进行添加,也就是将DaemonSet只调度到匹配指定 label 的 Node 上。
2)当按以上方式创建好DaemonSet后,通过对DaemonSet进行查看,会发现有2个DaemonSet在运行。这是因为本文中只搭建了三个节点,一个master,两个node。因此DaemonSet默认分配两个DaemonSet给两个node节点使用。
# 查看DaemonSet信息
kubectl get ds
3)随后使用nodeSelector的方式来进行对节点添加DaemonSet。
# 先给node1节点添加上标签
kubectl label nodes node1 type=microservices
# 修改DaemonSet文件
kubectl edit ds fluentd (本文中创建的DaemonSet为fluentd)
# 在再 daemonset 配置中设置 nodeSelector,其位置如下,在第二个spec下面添加nodeSelector以及node的标签及名称
spec:
template:
spec:
nodeSelector:
type: microservices
4)随后再通过查看DaemonSet,此时会发现只有一个在运行。这是因为之前是未进行分配,现在只给一个node1加了mmicroservices的标签,所以只能找到一个节点。
5)给node2节点也加入DaemonSet。在进行对DaemonSet观察会发现,会发现现在有2个DaemonSet在运行。
# 再给node2节点添加上标签
kubectl labe2 nodes node1 type=microservices
6)到此就结束了分别对node1和node2节点进行DaemonSet类型资源的部署。
3.DaemonSet的更新
1)DaemonSet默认的更新方式为滚动更新,但是并不建议使用 RollingUpdate,建议使用 OnDelete 模式,这样避免频繁更新 DaemonSet。这是因为假设有1000个node节点,如果使用滚动更新那么所有节点都会更新,然而有时可能只需要更新几个节点进行测试,并不需要所有节点进行更新。
2)OnDelete这种更新方式就是node删除要更新的DaemonSet对应的pod,然后会为node自动重启一个更新后的pod。
3)OnDelete更新方式的替换。
# 修改DaemonSet配置
kubectl edit ds fluentd
# 找到updateStrategy这一栏,然后进行修改,如下图所示


HPA自动扩容/缩容
(1)HPA主要通过观察 pod 的 cpu、内存使用率或自定义 metrics 指标进行自动的扩容或缩容 pod 的数量。
(2)通常用于 Deployment和satefulSet,不适用于无法扩/缩容的对象,如 DaemonSet。
(3)控制管理器每隔30s(可以通过–horizontal-pod-autoscaler-sync-period修改)查询metrics的资源使用情况。
1.使用HPA示例
实现 cpu 或内存的监控,首先有个前提条件是该对象必须配置了 resources.requests.cpu 或者resources.requests.memory 才可以,所以本文中以Deployment为例。
1)首先创建一个Deployment资源。(Deployment资源的配置文件在之前的学习记录中有)。
2)对Deployment资源加上CPU和内存的限制指标,如下图所示。

3)执行以下命令实现对创建好的Deployment应用进行HPA应用。当创建好了后再查看deploy就会发现已经扩容到2个了。(因为deployment的配置文件中副本数设置的为1)。
# 对deploy应用进行自动扩容,当cpu占用率到20时扩容,扩容至最多5个最少2个。
kubectl autoscale deploy <应用名称> --cpu-percent=20 --min=2 --max=5
# 该名称使用以下命令查看
kubectl get deploy
4)在这里为了方便后期查看pod的内存占用率,所以下载一个指标服务,命令如下所示。
# 下载 metrics-server 组件配置文件
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml -O metrics-server-components.yaml
如果在下载指标时遇到问题,则可以参考以下方法进行解决。如果没有解决,可以看看其他大佬的帖子。
# 如果wget没有安装
yum install wget
# 如果遇到sll连接失败
# 安装apache
yum install httpd
# 安装SSL模块
yum install mod_ssl
# 重启apache
service httpd restart
然后进行metrics-server配置的修改。
# 修改镜像地址为国内的地址
sed -i 's/k8s.gcr.io\/metrics-server/registry.cn-hangzhou.aliyuncs.com\/google_containers/g' metrics-server-components.yaml
# 使用以下命令查看镜像是否安装成功了
grep image metrics-server-components.yaml
# 如果没有安装成功则直接修改配置文件
vim metrics-server-components.yaml
# 找到其中的image,将其手动换为阿里云镜像
registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.6.2
最后修改metrics-server文件的配置,如下图位置所示。
# 进入到下载的metrics-server-components.yaml文件进行编辑
vim metrics-server-components.yaml
# 找到containers一栏,添加配置
--kubelet-insecure-tls

对组件进行安装。
# metrics组件安装
kubectl apply -f metrics-server-components.yaml
# 组件状态查看,安装成功后就可以看到 metrics-server启动了
kubectl get po --all-namespaces | grep mettrics
# 使用以下命令就可以看到每个pod内存,CPU资源的使用情况,如下图所示
kubectl top pods

2.测试HPA
(1)首先将之间创建的2个nginx的deploy聚合成一个service方便测试。
# 创建一个nginx-svc.yaml文件
vim nginx-svc.yaml
# 编写配置文件
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
labels:
app: nginx
spec:
selector:
app: nginx-deploy
ports:
- port: 80
targetPort: 80
name: web
type: NodePort
# 创建service
kubectl create -f nginx-svc.yaml
# 查看svc是否创建成功
kubectl get svc
(2)使用node1和node2循环访问该service服务,使其CPU使用率变高。
# 先查看service的ip地址,然后替换到以下命令中
while true; do wget -q -O- http://<ip:port> > /dev/null ; done
(3)通过以下图片可以发现,当node1和node2分别循环访问nginx-svc时,CPU占用率一直上升,然后HPA自动进行扩容,最多到5个(因为配置文件中写的最多扩容到5个),随后当停止了node1和node2的访问后,nginx的副本数又降到了2个。
1)占用率超过了20。

2)进行nginx的自动扩容。

3)最大扩容到5个

4)占用率变小后进行自动缩容。


K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 22
22 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)