

YOLOv8/YOLOv7/YOLOv5注意力机制全家福,内涵多尺度空洞注意力、大型分离卷积、多尺度双视觉、可变形大核注意力、通道优先卷积注意力、多维协作注意、可变形自注意力、EMA等
本文属于原创独家改进:2023年全新注意力大派送,内涵多尺度空洞注意力、大型分离卷积、多尺度双视觉、可变形大核注意力、通道优先卷积注意力、多维协作注意、可变形自注意力、EMA,喜迎1024,创新度十足适合科研,强烈推荐,推荐指数五颗星
💡💡💡本文属于原创独家改进:2023年全新注意力大派送,内涵多尺度空洞注意力、大型分离卷积、多尺度双视觉、可变形大核注意力、通道优先卷积注意力、多维协作注意、可变形自注意力、EMA,喜迎1024,创新度十足适合科研
💡💡💡在各个数据集能够涨点,强烈推荐,推荐指数五颗星
目录
1.多尺度空洞注意力(MSDA) | 中科院一区顶刊 DilateFormer 2023.9
2.大型分离卷积注意力模块( Large Separable Kernel Attention),实现暴力涨点同时显著减少计算复杂性和内存 | 2023.8月最新发表
3.Dual-ViT:一种多尺度双视觉Transformer ,Dualattention助力检测| 顶刊TPAMI 2023
4.可变形大核注意力,超越自注意力,实现暴力涨点 | 2023.8月最新发表
5.通道优先卷积注意力,效果秒杀CBAM和SE等 |中科院2023.6月发布
6.多维协作注意模块MCA,暴力涨点,效果秒杀ECA、SRM、CBAM等
7.可变形自注意力Attention,暴力涨点 | 即插即用系列2023年最新发表
8.ICASSP2023 EMA基于跨空间学习的高效多尺度注意力、效果优于ECA、CBAM、CA
1.多尺度空洞注意力(MSDA) | 中科院一区顶刊 DilateFormer 2023.9
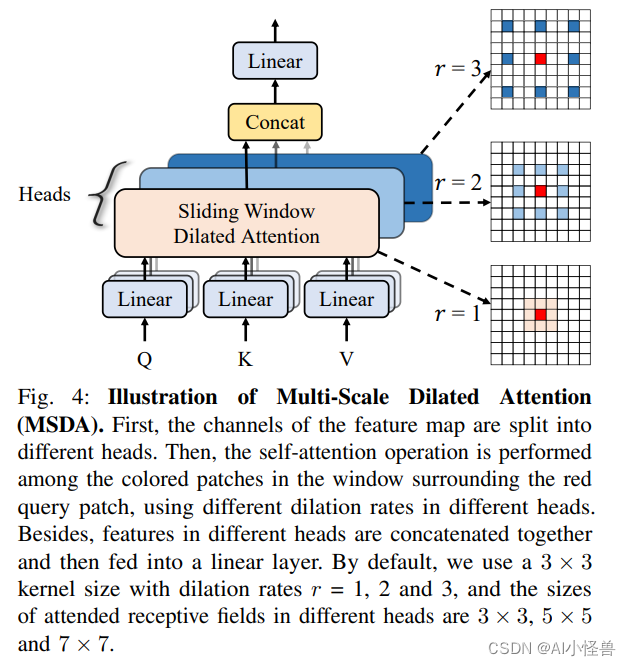
本文全网首发独家改进:多尺度空洞注意力(MSDA)采用多头的设计,在不同的头部使用不同的空洞率执行滑动窗口膨胀注意力(SWDA),全网独家首发,创新力度十足,适合科研
1)与C2f结合;2)作为注意力MSDA使用;
多尺度空洞注意力(MSDA) | 亲测在红外弱小目标检测涨点,map@0.5 从0.755提升至0.784
为了克服这些问题,作者提出了一种新的注意力机制——多尺度空洞注意力(MSDA)。MSDA 能够模拟小范围内的局部和稀疏的图像块交互,这些发现源自于对 ViTs 在浅层次上全局注意力中图像块交互的分析。作者发现在浅层次上,注意力矩阵具有局部性和稀疏性两个关键属性,这表明在浅层次的语义建模中,远离查询块的块大部分无关,因此全局注意力模块中存在大量的冗余。

DilateFormer 是一个以金字塔结构为基础的深度学习模型,它主要设计用来处理基础的视觉任务。DilateFormer 的关键设计概念是利用多尺度空洞注意力(Multi-Scale Dilated Attention, MSDA)来有效捕捉多尺度的语义信息,并减少自注意力机制的冗余。
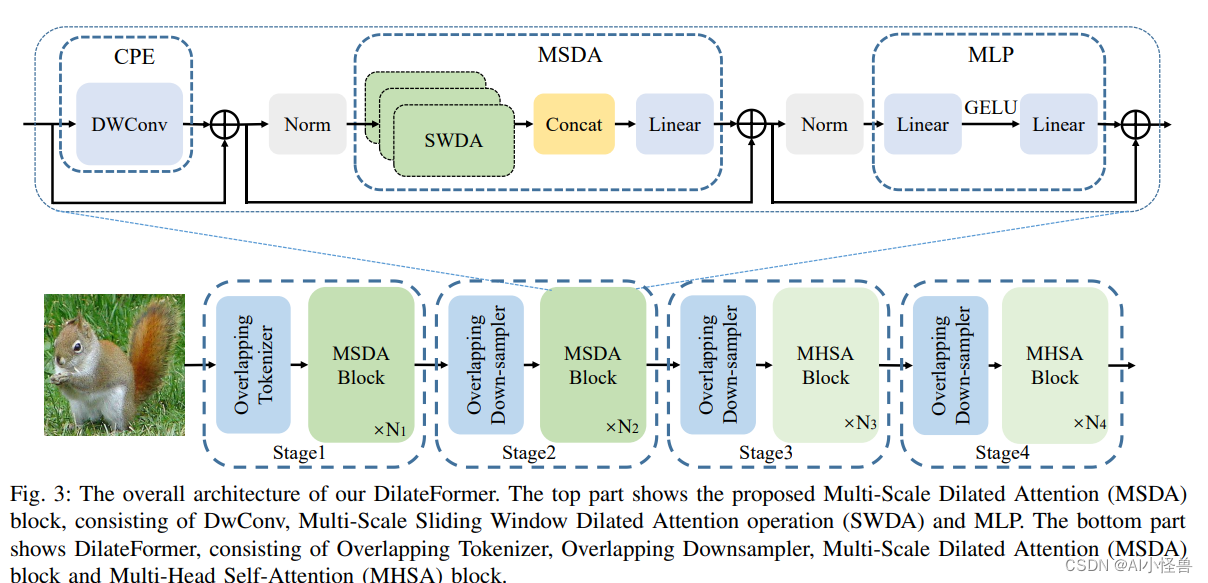
如下图所示,MSDA 模块同样采用多头的设计,将特征图的通道分为 n 个不同的头部,并在不同的头部使用不同的空洞率执行滑动窗口膨胀注意力(SWDA)。这样可以在被关注的感受野内的各个尺度上聚合语义信息,并有效地减少自注意力机制的冗余,无需复杂的操作和额外的计算成本。
总体来说,DilateFormer 通过这种混合使用多尺度空洞注意力和多头自注意力的方式,成功地处理了长距离依赖问题,同时保持了计算效率,并能够适应不同尺度和分辨率的输入。
YOLOv8改进:全网原创首发 | 多尺度空洞注意力(MSDA) | 中科院一区顶刊 DilateFormer 2023.9-CSDN博客
2.大型分离卷积注意力模块( Large Separable Kernel Attention),实现暴力涨点同时显著减少计算复杂性和内存 | 2023.8月最新发表
本文独家改进:大型分离卷积注意力模块( Large Separable Kernel Attention),大卷积核大幅提升检测精度的同时,LSKA模块提供了随着卷积核大小的增加而显著减少计算复杂性和内存 footprints

论文: https://arxiv.org/pdf/2309.01439.pdf
原理部分详见论文
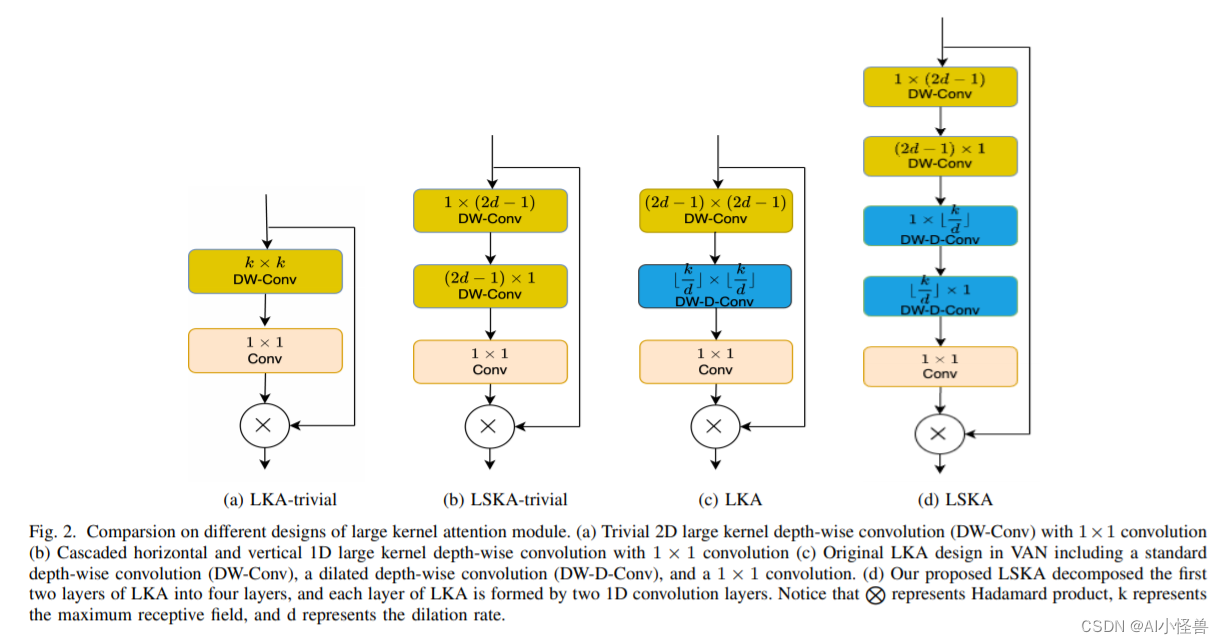
摘要:视觉注意力网络(VAN)和大型卷积注意力(LKA)模块已经证明能够在多种视觉任务中提供卓越的表现,超过视觉转换器(ViTs)的表现。然而,这些LKA模块的depthwise卷积层在增加卷积核大小时导致计算和内存 footprints的 Quadratic 增长。为了缓解这些问题并允许在Van的注意力模块中使用极其大的卷积核,我们提出了一种名为LSKA的大型分离卷积注意力模块家族。LSKA将depthwise卷积层的2D卷积核分解为串联的1D卷积核。与标准LKA设计不同,我们提出的分解使在注意力模块中使用大型卷积核可以直接使用,而不需要额外的块。我们证明,在Van中提出的LSKA模块可以与标准LKA模块实现相似的性能,并导致计算复杂性和内存 footprints的降低。我们还发现,LSKA设计将Van更偏向对象的形状,而不是纹理,随着卷积核大小的增加。此外,我们比较了Van中的LKA和LSKA模块、ViTs和最近的卷积神经网络(CNN)实例在损坏的ImageNet数据集上的表现,在前作中未充分探索的数据集上进行了测试。我们的广泛实验结果表明,在Van中提出的LSKA模块提供了随着卷积核大小的增加而显著减少计算复杂性和内存 footprints,同时优于ViTs、CNN实例和与Van中的LKA模块在对象识别、对象检测、语义分割和鲁棒测试中的表现相似。
我们首先讨论如何通过使用一维卷积核来设计 LSKA 模块来重构 LKA 模块(使用和不使用扩张的深度卷积)。 然后我们总结了 LSKA 模块的几个关键属性,然后对 LSKA 进行了复杂性分析。
3.Dual-ViT:一种多尺度双视觉Transformer ,Dualattention助力检测| 顶刊TPAMI 2023
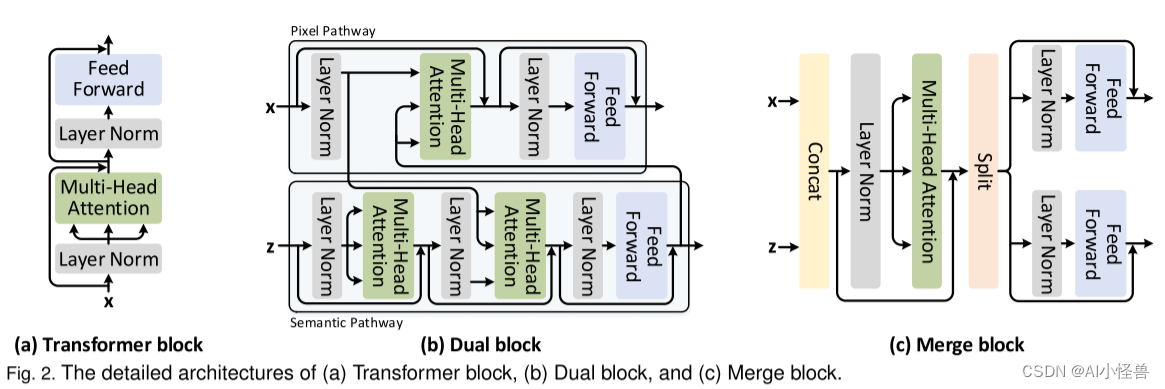
本文独家改进:DualViT:一种新的多尺度视觉Transformer主干,它在两种交互路径中对自注意力学习进行建模,即学习更精细像素级细节的像素路径和提取整体全局语义信息的语义路径,性能表现出色,Dualattention引入到YOLOv8实现创新涨点!!!
如上图(d)所示,双ViT由两个特殊路径组成,分别称为“语义路径”和“像素路径”。通过构造的“像素路径”进行局部像素级特征提取是强烈依赖于“语义路径”之外的压缩全局先验。由于梯度同时通过语义路径和像素路径,因此双ViT训练过程可以有效地补偿全局特征压缩的信息损失,同时减少局部特征提取的困难。前者和后者都可以并行显著降低计算成本,因为注意力大小较小,并且两条路径之间存在强制依赖关系。

在本文中,我们提出了一种新颖的 Transformer 架构,它优雅地利用全局语义进行自注意力学习,即双视觉 Transformer (Dual-ViT)。
全网首发YOLOv8暴力涨点:Dual-ViT:一种多尺度双视觉Transformer ,Dualattention助力检测| 顶刊TPAMI 2023_AI小怪兽的博客-CSDN博客
4.可变形大核注意力,超越自注意力,实现暴力涨点 | 2023.8月最新发表
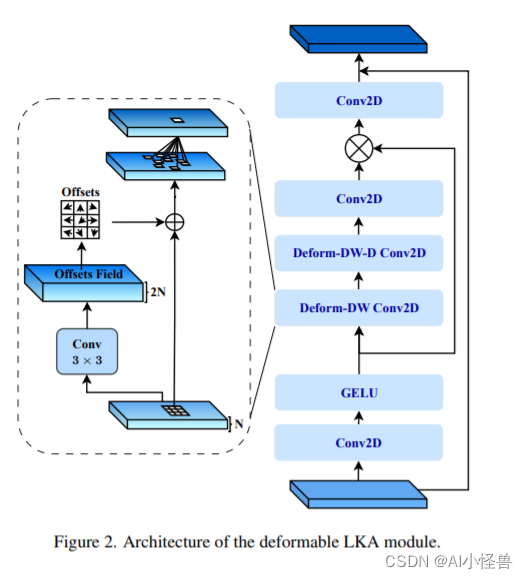
本文独家改进:可变形大核注意力(D-LKA Attention),采用大卷积核来充分理解体积上下文的简化注意力机制,来灵活地扭曲采样网格,使模型能够适当地适应不同的数据模式
摘要:医学图像分割通过 Transformer 模型得到了显着改进,该模型在掌握深远的上下文和全局上下文信息方面表现出色。 然而,这些模型不断增长的计算需求(与平方令牌数量成正比)限制了它们的深度和分辨率能力。 目前的大多数方法都是逐片处理 D 体图像数据(称为伪 3D),缺少关键的片间信息,从而降低了模型的整体性能。 为了应对这些挑战,我们引入了可变形大核注意力(D-LKA Attention)的概念,这是一种采用大卷积核来充分理解体积上下文的简化注意力机制。 这种机制在类似于自注意力的感受野中运行,同时避免了计算开销。 此外,我们提出的注意力机制受益于可变形卷积来灵活地扭曲采样网格,使模型能够适当地适应不同的数据模式。我们设计了 D-LKA 注意力的 2D 和 3D 适应,后者在跨深度方面表现出色 数据理解。 这些组件共同塑造了我们新颖的分层 Vision Transformer 架构,即 D-LKA Net。根据流行的医学分割数据集(Synapse、NIH 胰腺和皮肤病变)上的领先方法对我们的模型进行的评估证明了其卓越的性能。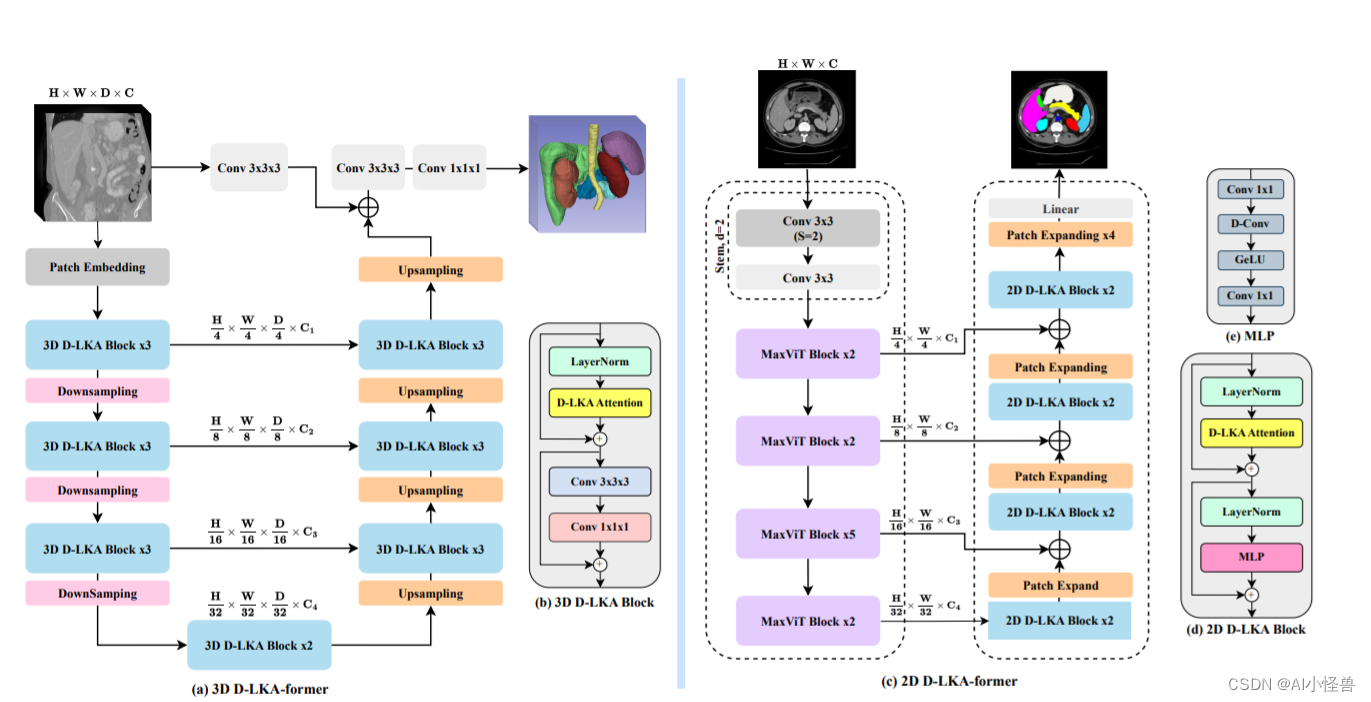
为了解决这些挑战,我们引入了Deformable Large Kernel Attention (D-LKA Attention)}的概念,这是一种采用大卷积核来充分理解体积上下文的简化注意力机制。
这种机制在类似于自注意力的感受野中运行,同时避免了计算开销。 此外,我们提出的注意力机制受益于可变形卷积来灵活地扭曲采样网格,使模型能够适当地适应不同的数据模式。 我们设计了 D-LKA Attention 的 2D 和 3D 适应,后者在跨深度数据理解方面表现出色。
全网原创首发Yolov8涨点神器:可变形大核注意力,超越自注意力,实现暴力涨点 | 2023.8月最新发表_AI小怪兽的博客-CSDN博客
5.通道优先卷积注意力,效果秒杀CBAM和SE等 |中科院2023.6月发布
本文独家改进:通道优先卷积注意力,采用多尺度结构来增强卷积运算捕获空间关系的能力,解决CBAM 整合了通道注意和空间注意,但它在其输出特征的所有通道上强制执行一致的空间注意分布。相反,SE只整合了通道注意,这限制了它选择重要区域的能力
现有研究问题点:
虽然 CBAM 整合了通道注意和空间注意,但它在其输出特征的所有通道上强制执行一致的空间注意分布。相反,SE(图 1(a))只整合了通道注意,这限制了它选择重要区域的能力。
本文创新:
- 如图 1(c) 所示,作者提出了一种新的通道优先卷积注意力(Channel Prior Convolutional Attention,CPCA)方法,采用多尺度的深度可分离卷积模块构成空间注意力,可以在通道和空间维度上动态分配注意权重。
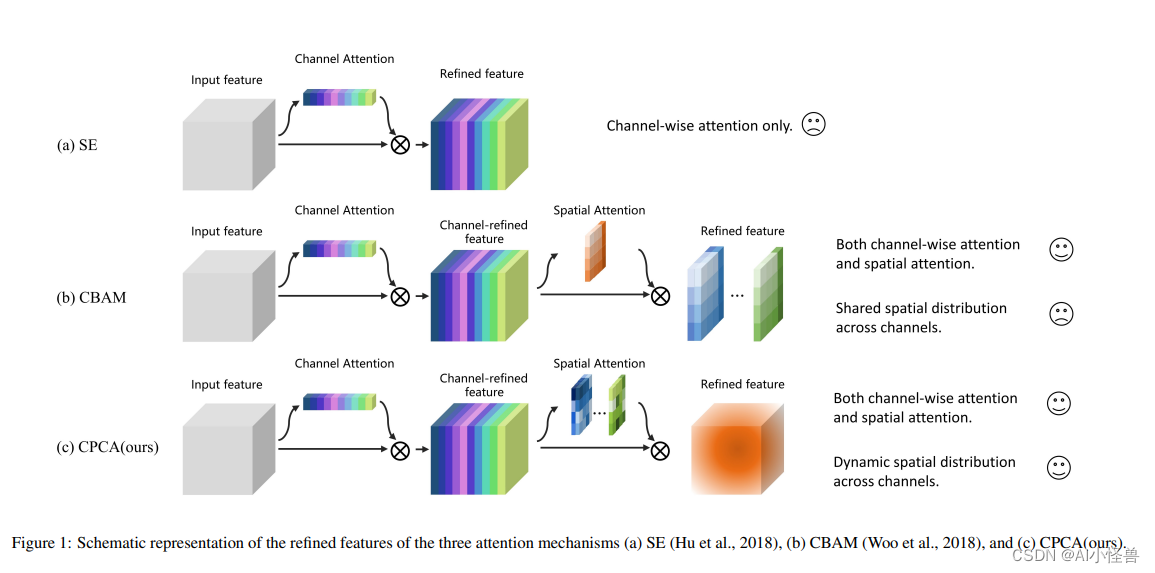
图3:通道先验卷积注意力(CPCA)的整体结构包括通道注意力和空间注意力的顺序放置。特征图的空间信息是由通道注意力通过平均池化和最大池化等操作来聚合的。 随后,空间信息通过共享 MLP(多层感知器)进行处理并添加以生成通道注意力图。 通道先验是通过输入特征和通道注意力图的元素相乘获得的。 随后,通道先验被输入到深度卷积模块中以生成空间注意力图。 卷积模块接收空间注意力图以进行通道混合。 最终,通过通道混合结果与通道先验的逐元素相乘,获得细化的特征作为输出。 通道混合过程有助于增强特征的表示
YoloV8优化:通道优先卷积注意力,效果秒杀CBAM和SE等 |中科院2023.6月发布_AI小怪兽的博客-CSDN博客
6.多维协作注意模块MCA,暴力涨点,效果秒杀ECA、SRM、CBAM等
本文属于原创独家改进:多维协作注意模块MCA,暴力涨点,效果秒杀ECA、SRM、CBAM,创新性十足,可直接作为创新点使用。
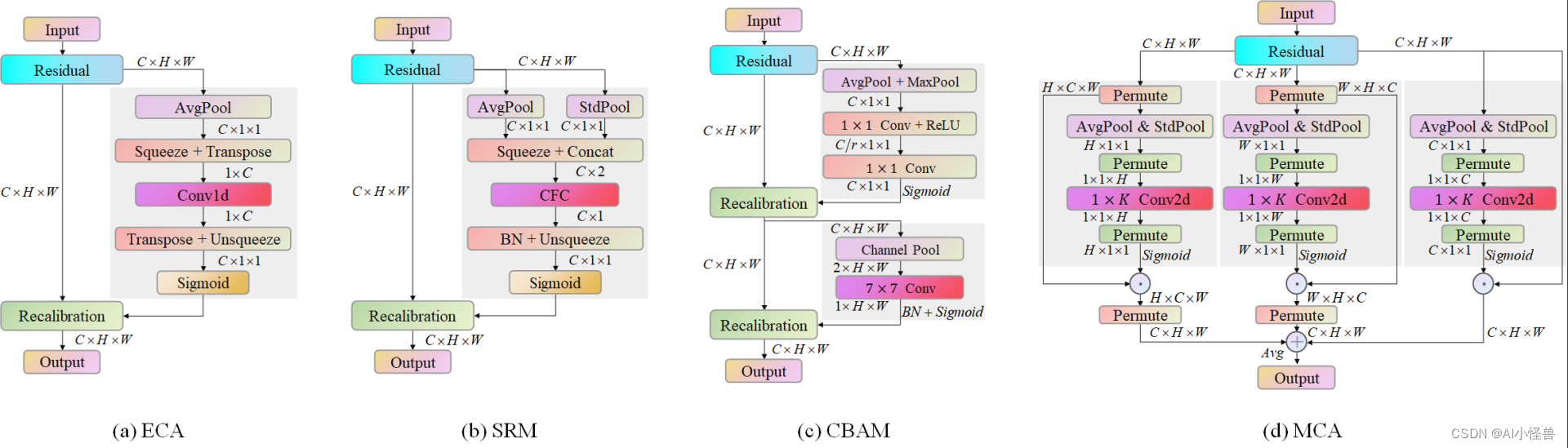
图 1:所提出的多维协作注意模块 (d) 与 ECA 模块 (a)、SRM (b) 和 CBAM (c) 的示意图比较。
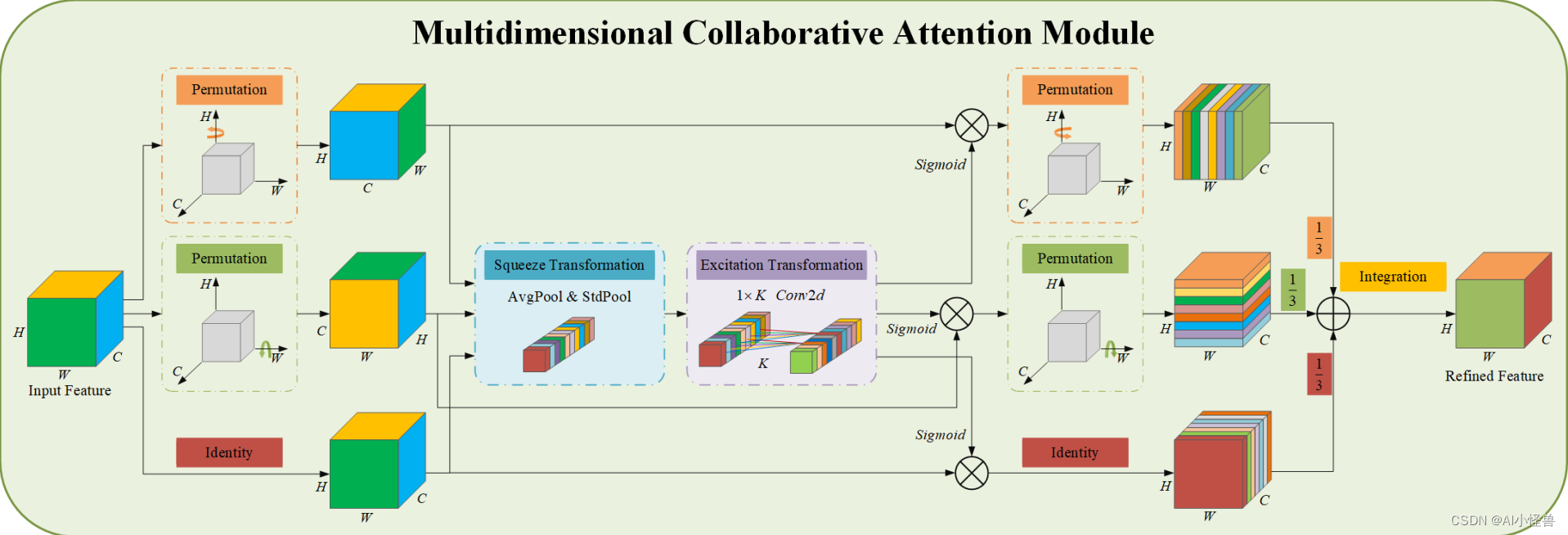
图 2:所提出的具有三个分支的 MCA 模块的总体架构。
顶部分支用于捕获空间维度 W 中特征之间的交互。类似地,中间分支用于捕获空间维度 H 中特征之间的交互。底部分支负责捕获通道之间的交互。 在前两个分支中,我们采用置换操作来捕获通道维度与任一空间维度之间的远程依赖性。 最后,在积分阶段通过简单平均来聚合所有三个分支的输出。

图 3:原始残差块的架构(左)、MCA 集成到基本残差块(中)以及 MCA 集成到瓶颈残差块(右)。
YoloV8改进:原创独家首发 | 多维协作注意模块MCA,暴力涨点,效果秒杀ECA、SRM、CBAM等 | 即插即用系列-CSDN博客
7.可变形自注意力Attention,暴力涨点 | 即插即用系列2023年最新发表
本文属于原创独家改进:当你停留在可形变卷积上(DCNV1,DCNV2,DCNV3等),可形变Attention助力检测,创新性十足,不仅增强了 sparse attention 的表征能⼒,同时具有线性空间复杂度。
本文提出了一种简单有效的可变形的自注意力模块,并在此模块上构造了一个强大的Pyramid Backbone,即可变形的注意力Transformer(Deformable Attention Transformer, DAT),用于图像分类和各种密集的预测任务。研究者们让所有 query 都跟同一组 key 和 value 交互,通过对每个输⼊图像学习⼀组偏移量,移动 key 和 value 到重要的位置。这种设计不仅增强了 sparse attention 的表征能⼒,同时具有线性空间复杂度。
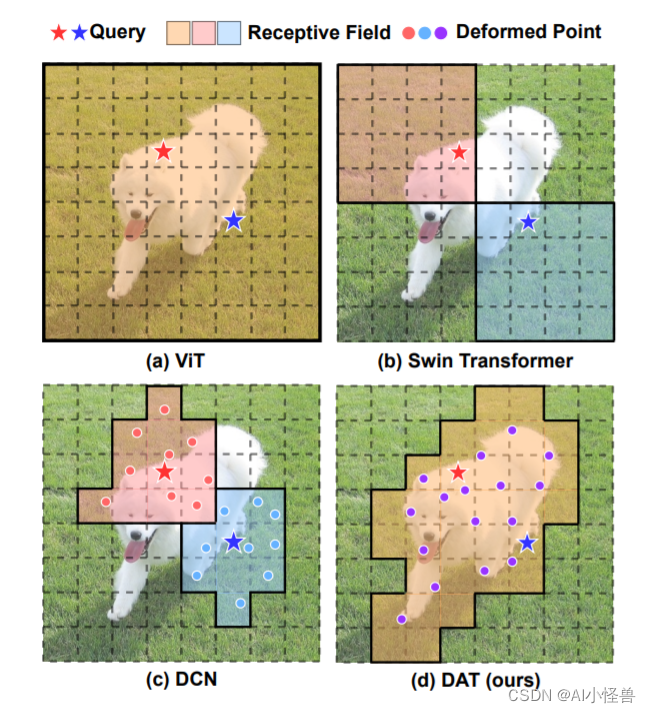
可变形注意机制的图示。 (a) 呈现可变形注意力的信息流。在左侧部分,一组参考点均匀地放置在特征图上,其偏移量是通过偏移网络从查询中学习到的。然后根据变形点从采样的特征中投影出变形的键和值,如右图所示。相对位置偏差也由变形点计算,增强了输出变形特征的多头注意力。我们只展示了 4 个参考点以进行清晰的展示,实际实施中还有更多参考点。 (b) 揭示了偏移生

YoloV8改进:原创独家首发 | 可变形自注意力Attention,暴力涨点 | 即插即用系列2023年最新发表-CSDN博客
8.ICASSP2023 EMA基于跨空间学习的高效多尺度注意力、效果优于ECA、CBAM、CA
本文提出了一种新的跨空间学习方法,并设计了一个多尺度并行子网络来建立短和长依赖关系。
1)我们考虑一种通用方法,将部分通道维度重塑为批量维度,以避免通过通用卷积进行某种形式的降维。
2)除了在不进行通道降维的情况下在每个并行子网络中构建局部的跨通道交互外,我们还通过跨空间学习方法融合两个并行子网络的输出特征图。
3)与CBAM、NAM[16]、SA、ECA和CA相比,EMA不仅取得了更好的结果,而且在所需参数方面效率更高。
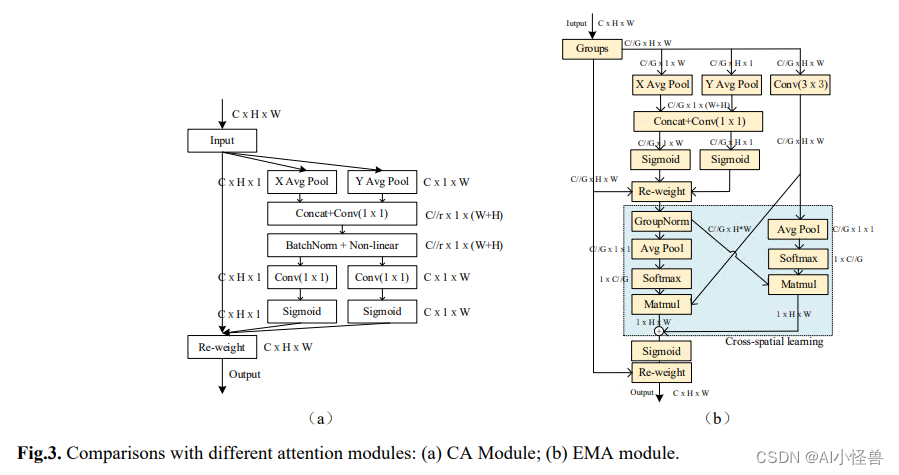
CA块首先可以被视为与SE注意力模块类似的方法,其中利用全局平均池化操作对跨通道信息进行建模。通常,可以通过使用全局平均池化来生成信道统计信息,其中全局空间位置信息被压缩到信道描述符中。与SE微妙不同的是,CA将空间位置信息嵌入通道注意图以增强特征聚合。
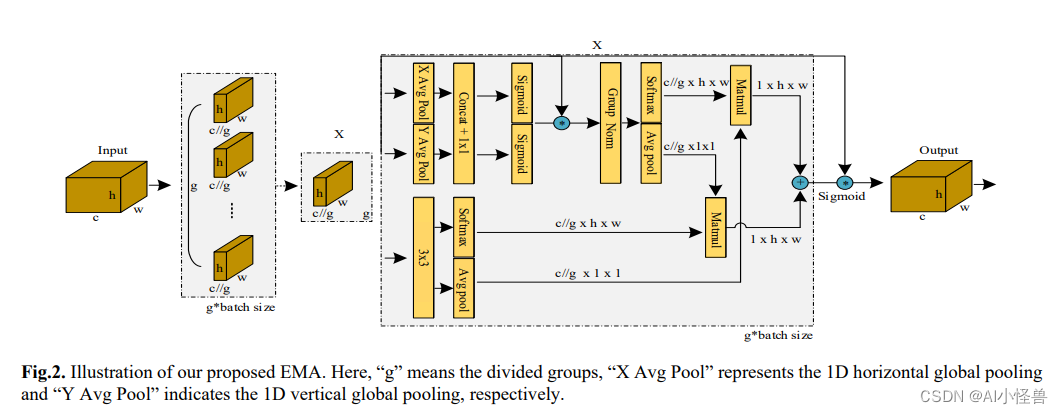
并行子结构帮助网络避免更多的顺序处理和大深度。给定上述并行处理策略,我们在EMA模块中采用它。EMA的整体结构如图3 (b)所示。在本节中,我们将讨论EMA如何在卷积操作中不进行通道降维的情况下学习有效的通道描述,并为高级特征图产生更好的像素级注意力。具体来说,我们只从CA模块中挑选出1x1卷积的共享组件,在我们的EMA中将其命名为1x1分支。为了聚合多尺度空间结构信息,将3x3内核与1x1分支并行放置以实现快速响应,我们将其命名为3x3分支。考虑到特征分组和多尺度结构,有效地建立短期和长程依赖有利于获得更好的性能。
Yolov8改进---注意力机制:ICASSP2023 EMA基于跨空间学习的高效多尺度注意力、效果优于ECA、CBAM、CA | 小目标涨点明显_AI小怪兽的博客-CSDN博客

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 47
47 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)