
6.1 Elasticsearch(一)Docker搭建ES集群
Elasticsearch是一个分布式搜索引擎服务器,搜索引擎有自己专门的搜索引擎服务器,而不是依靠数据库来做,我们搜索内容时,如果使用数据库来做,则需要模糊查询数据库中所有的数据,一条一条的去顺序比对,这种搜索效率是极低的;我们这里介绍Elasticsearch搜索引擎服务器,使用时需要将数据库中的数据同步到Elasticsearch服务器中,通过搜索引擎服务器去做搜索查询,因为其只支持搜索查询
文章目录
1.环境准备
Elasticsearch是一个分布式搜索引擎服务器,搜索引擎有自己专门的搜索引擎服务器,而不是依靠数据库来做,我们搜索内容时,如果使用数据库来做,则需要模糊查询数据库中所有的数据,一条一条的去顺序比对,这种搜索效率是极低的;
我们这里介绍Elasticsearch搜索引擎服务器,使用时需要将数据库中的数据同步到Elasticsearch服务器中,通过搜索引擎服务器去做搜索查询,因为其只支持搜索查询,专职于搜索服务的支持,其效率很高;
并且得益于其分布式结构,可以将数据分割到多个服务器中,搜索内容时,多个服务器一起检索自己服务器存放的内容,最后将结果进行汇总,将大大减少搜索时间;
1.1 关闭防火墙
后面我们要使用多个端口,为了避免繁琐的开放端口操作,我们关掉防火墙
# 关闭防火墙
systemctl stop firewalld.service
# 禁用防火墙
systemctl disable firewalld.service
1.2 准备虚拟机
我们使用 Docker 来运行 Elasticsearch,首先安装 Docker,可以参考第五篇第二节相关内容,我们这里直接使用此前准备好的docker-base虚拟机,克隆并重命名为es即可;
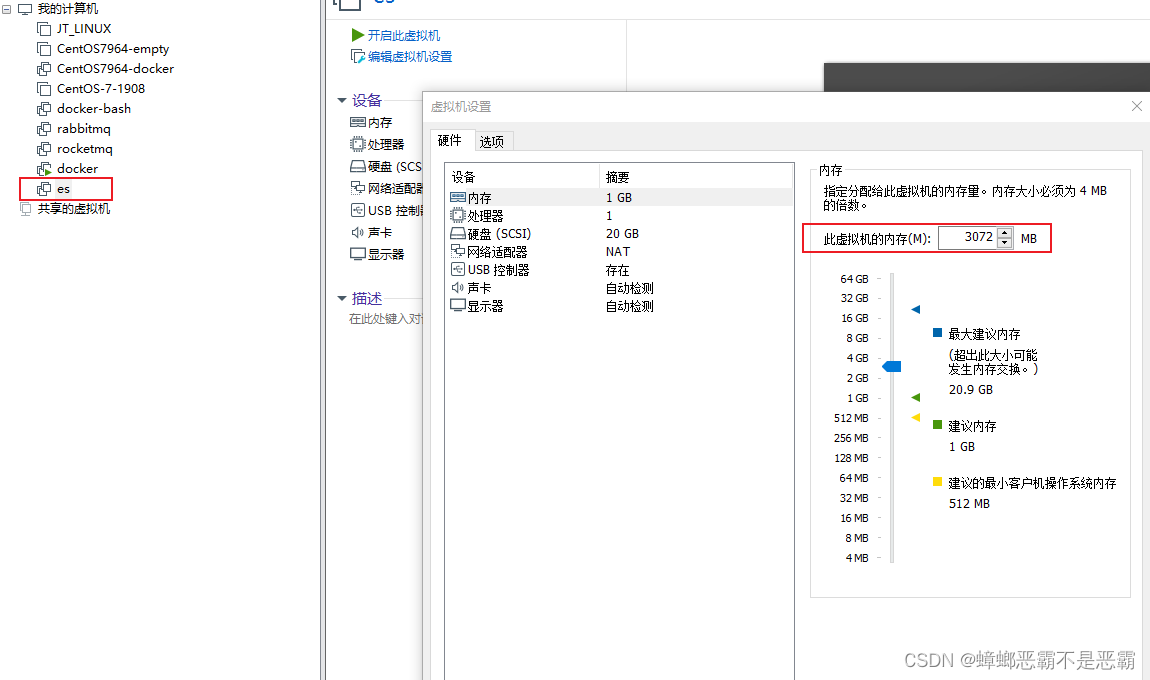
因为我们一共要启动3个镜像,所以需要将内存设置大一点,最小设置为2G,通过右键点击es虚拟机--设置--修改内存大小进行配置:

我们还需要设置ip:
./ip-static
ip: 192.168.64.181
ifconfig
1.3 导入镜像
我们可以在线下载Elastic Search 镜像文件:
docker pull elasticsearch:7.9.3
当然也可以直接使用本地准备好的镜像文件,通过mobaxterm连接虚拟机后,将elasticsearch文件夹中:pditems文件夹、elasticsearch-analysis-ik-7.9.3.zip、es-img.gz上传到容器根目录中,然后使用docker load -i es-img.gz命令导入镜像;
1.4 虚拟机设置 max_map_count
虚拟机必须修改系统参数 max_map_count,否则 Elasticsearch 无法启动:
在mobaxterm连接中,通过命令在 /etc/sysctl.conf 文件中添加 vm.max_map_count=262144
echo 'vm.max_map_count=262144' >>/etc/sysctl.conf
# 立即生效
sysctl -p
需要注意不能重复执行上面的命令,上面命令中的>>是指追加,多次执行会导致添加多个此项配置,执行后查看我们设置的参数是否成功:
cat /etc/sysctl.conf

完成后,使用shutdown -r now命令重新启动虚拟机:

重启时,服务器会暂时断开连接,需要等待重启完成后重新连接;
2.集群部署结构

在一台服务器上,使用Docker部署三个ES容器组成的集群
2.1 准备虚拟网络和挂载目录
我们首先创建虚拟网络,然后通过虚拟网络连接3个节点,并且在宿主机上创建/var/lib/es/node1/plugins目录,安装相关插件,创建/var/lib/es/node1/data存放相关文件;
# 创建虚拟网络
docker network create es-net
# node1 的挂载目录
mkdir -p -m 777 /var/lib/es/node1/plugins
mkdir -p -m 777 /var/lib/es/node1/data
# node2 的挂载目录
mkdir -p -m 777 /var/lib/es/node2/plugins
mkdir -p -m 777 /var/lib/es/node2/data
# node3 的挂载目录
mkdir -p -m 777 /var/lib/es/node3/plugins
mkdir -p -m 777 /var/lib/es/node3/data
2.2 启动 Elasticsearch 集群
Elasticsearch 集群启动是比较慢的,我们创建3个连接窗口,分别启动三个服务器,让其同时运行:

2.2.1 node1配置内容
docker run -d \
--name=node1 \
--restart=always \
--net es-net \
-p 9200:9200 \
-p 9300:9300 \
-v /var/lib/es/node1/plugins:/usr/share/elasticsearch/plugins \
-v /var/lib/es/node1/data:/usr/share/elasticsearch/data \
-e node.name=node1 \
-e node.master=true \
-e network.host=node1 \
-e discovery.seed_hosts=node1,node2,node3 \
-e cluster.initial_master_nodes=node1 \
-e cluster.name=es-cluster \
-e "ES_JAVA_OPTS=-Xms256m -Xmx256m" \
elasticsearch:7.9.3
2.2.2 node2配置内容
docker run -d \
--name=node2 \
--restart=always \
--net es-net \
-p 9201:9200 \
-p 9301:9300 \
-v /var/lib/es/node2/plugins:/usr/share/elasticsearch/plugins \
-v /var/lib/es/node2/data:/usr/share/elasticsearch/data \
-e node.name=node2 \
-e node.master=true \
-e network.host=node2 \
-e discovery.seed_hosts=node1,node2,node3 \
-e cluster.initial_master_nodes=node1 \
-e cluster.name=es-cluster \
-e "ES_JAVA_OPTS=-Xms256m -Xmx256m" \
elasticsearch:7.9.3
2.2.3 node3配置内容
docker run -d \
--name=node3 \
--restart=always \
--net es-net \
-p 9202:9200 \
-p 9302:9300 \
-v /var/lib/es/node3/plugins:/usr/share/elasticsearch/plugins \
-v /var/lib/es/node3/data:/usr/share/elasticsearch/data \
-e node.name=node3 \
-e node.master=true \
-e network.host=node3 \
-e discovery.seed_hosts=node1,node2,node3 \
-e cluster.initial_master_nodes=node1 \
-e cluster.name=es-cluster \
-e "ES_JAVA_OPTS=-Xms256m -Xmx256m" \
elasticsearch:7.9.3
2.2.4 环境变量说明
我们这里需要说明的是,这里的主节点指的是承担接收、分发客户端指定的工作节点,ES集群不存在主从架构,所以没有从节点的说法;
-d:后台运行--name=node1:节点在集群中的唯一名称为node1--restart=always:随系统重启--net es-net:连接到虚拟网络es-net(在前边的步骤中我们创建了虚拟网络,并取名为es-net)-p:端口映射,这里映射了俩个端口,容器启动后有俩个端口,分别为9200和9300;9200负责和客户端通信,执行客户端增删改查,是一个http的web应用端口;9300是多台服务器集群之间互相连接,内部通信使用的;-v:挂载,分别挂载了插件安装目录和文件存放目录,参考手册了解其具体路径;-e:代码环境变量,ES的运行需要创建集群,集群之间需要互相连接,通过-e配置集群的环境变量-e node.name:节点在集群中的唯一名称-e node.master:可以设置true或者false,表明其是否可以被选举为主节点,其主节点除了搜索任务,还要承担接收、分发客户端指令的任务;-e network.host:当前节点的地址(使用虚拟网络通信时,可以使用容器名来互相访问)
discovery.seed_hosts:集群中其他节点的地址列表cluster.initial_master_nodes·:候选的主节点地址列表,虽然我们这里配置了node1,但是其他节点也设置了可被选举为主节点,所以主节点也可能是其他节点;cluster.name:集群名ES_JAVA_OPTS:java虚拟机参数
详细变量说明可以参考官方文档: https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-network.html
2.3 查看启动结果
启动之后使用docker ps命令查看启动结果,3个服务器都存在:

浏览器访问:http://192.168.64.181:9200

浏览器访问:http://192.168.64.181:9200/_cat/nodes

3.chrome浏览器插件:elasticsearch-head
elasticsearch-head 项目提供了一个直观的界面,可以很方便地查看集群、分片、数据等等。elasticsearch-head最简单的安装方式是作为 chrome 浏览器插件进行安装。
-
在 elasticsearch-head 项目仓库中下载 chrome 浏览器插件:https://github.com/mobz/elasticsearch-head/raw/master/crx/es-head.crx,可以直接选用我们本地提供的文件
es-head.crx.zip; -
如果是下载的文件,需要将文件后缀改为 zip
-
将压缩文件解压缩
-
在 chrome 浏览器中选择“更多工具”–“扩展程序”
-
在“扩展程序”中确认开启了“开发者模式”
-
点击“加载已解压的扩展程序”
-
选择前面解压的插件目录
-
在浏览器中点击 elasticsearch-head 插件打开 head 界面

-
连接
http://192.168.64.181:9200/


一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)