排序算法合集
这些排序函数都是自己零零散散写的,也没有经过深思熟虑和优化,纯粹是为了自娱自乐。代码里有两种实现方式,感觉第二种比较正宗,第一种跟插入排序相似度很高。本人没有完整的计算机科班的教育经历,但是一直在兢兢业业,努力学习。此处可以看出,插入排序和冒泡排序还是有很大的不同。按照次序,每次挑选一个最小的,放到相应的次序位置。快速排序一种是本人自己写的,一种是算法书上的源码。快速排序是冒泡排序的1000倍。

F B I W a r n i n g : \color{red}FBI \qquad Warning: FBIWarning:
本人没有完整的计算机科班的教育经历,但是一直在兢兢业业,努力学习。
这些排序函数都是自己零零散散写的,也没有经过深思熟虑和优化,纯粹是为了自娱自乐。
- 冒泡排序:
代码里有两种实现方式,感觉第二种比较正宗,第一种跟插入排序相似度很高。
int bubbleSortInc(int data[], int size) {
if (size <= 0)
{
return -1;
}
for (int i = 0; i <= size - 1; i++) {
for (int j = 0; j < i; j++)
{
if (data[j] > data[j + 1])
{
int tmp = data[j];
data[j] = data[j + 1];
data[j + 1] = tmp;
}
}
}
return 0;
}
int bubbleSortDec(int data[], int size) {
if (size <= 0)
{
return -1;
}
for (int i = size - 1; i >= 0; i--) {
for (int j = 0; j < i; j++)
{
if (data[j] > data[j + 1])
{
int tmp = data[j];
data[j] = data[j + 1];
data[j + 1] = tmp;
}
}
}
return 0;
}
- 插入排序:
此处可以看出,插入排序和冒泡排序还是有很大的不同。
int insertSort(int data[], int size) {
int cnt = 0;
if (size <= 1)
{
return 0;
}
for (int i = 0; i < size - 1; i++)
{
if (data[i] > data[i + 1])
{
int tmp = data[i + 1];
data[i + 1] = data[i];
data[i] = tmp;
for (int j = i; j > 0; j--)
{
if (data[j] < data[j - 1])
{
int tmp2 = data[j];
data[j] = data[j - 1];
data[j - 1] = tmp2;
}
}
}
}
return cnt;
}
- 选择排序
按照次序,每次挑选一个最小的,放到相应的次序位置。
int selectLeast(int data[], int datalen, int idx) {
for (int i = idx + 1; i < datalen; i++)
{
if (data[idx] > data[i])
{
idx = i;
}
}
return idx;
}
int selectionSort(int data[], int datalen) {
for (int i = 0; i < datalen; i++)
{
int least = selectLeast(data, datalen, i);
if (least != i) {
int tmp = data[i];
data[i] = data[least];
data[least] = tmp;
}
}
return 0;
}
- shell排序
void shellInsert(int arr[],int arrsize, int dk) {
for (int i = dk ;i <= arrsize - 1;i ++)
{
if (arr[i] < arr[i-dk])
{
int tmp = arr[i];
int j = i - dk;
for (;j >= 0 && tmp < arr[j];j -= dk)
{
arr[j + dk] = arr[j];
}
arr[j + dk] = tmp;
}
}
}
void shellSort(int arr[], int size, int delta[], int deltasize) {
for (int i = 0;i < deltasize; i ++)
{
shellInsert(arr, size, delta[i]);
}
}
shell排序中,步长的计算方式一般是n/2,n/4,n/8,…,1。
- 二分插入排序
void binaryInsertSort(int* data,int size) {
for (int i = 1;i < size;i ++)
{
int tmp = data[i];
int low = 0;
int high = i - 1;
while (low <= high) {
int m = (low + high ) / 2;
if (data[i] < data[m])
{
high = m - 1;
}
else {
low = m + 1;
}
}
for ( int j = i - 1;j >= high + 1; j --)
{
data[j + 1] = data[j];
}
data[high + 1] = tmp;
}
}
- 快速排序
快速排序一种是本人自己写的,一种是算法书上的源码。
int partition(int data[], int low, int high) {
int pivot = data[low];
while (low < high)
{
while (low < high && data[high] >= pivot) // 从右向左找第一个小于x的数
high--;
if (low < high)
data[low++] = data[high];
while (low < high && data[low] < pivot) // 从左向右找第一个大于等于x的数
low++;
if (low < high)
data[high--] = data[low];
}
data[low] = pivot;
return low;
}
void quickSort(int s[], int low, int high)
{
if (low < high)
{
int pivot = partition(s, low, high);
quickSort(s, low, pivot - 1);
quickSort(s, pivot + 1, high);
}
}
int fastSort(int data[], int left, int right) {
if (right - left <= 1)
{
return 0;
}
int pos = left;
int tmp = data[pos];
int empty = pos;
int low = left;
int high = right;
while (low < high)
{
while (low < high)
{
if (data[high] > tmp)
{
high--;
if (high <= low)
{
break;
}
}
else {
data[empty] = data[high];
empty = high;
high--;
break;
}
}
while (low < high)
{
if (low == pos)
{
low++;
if (high <= low)
{
break;
}
}
if (data[low] < tmp)
{
low++;
if (high <= low)
{
break;
}
}
else {
data[empty] = data[low];
empty = low;
low++;
break;
}
}
}
data[empty] = tmp;
fastSort(data, left, low - 1);
fastSort(data, low + 1, right);
return 0;
}
每次交换时,交换的是low和high,而不是low和high跟pivot的值。一定要理解清楚算法的原理,死记硬背很容易犯错。
- 堆排序
堆排序是我最喜欢的一种排序。有3种实现方式(后面两种是我根据算法的思路自己写的)。
void swap(int* a, int* b) {
int temp = *b;
*b = *a;
*a = temp;
}
void max_heapify(int arr[], int start, int end) {
// 建立父節點指標和子節點指標
int dad = start;
int son = dad * 2 + 1;
while (son <= end) { // 若子節點指標在範圍內才做比較
if (son + 1 <= end && arr[son] < arr[son + 1]) // 先比較兩個子節點大小,選擇最大的
son++;
if (arr[dad] > arr[son]) //如果父節點大於子節點代表調整完畢,直接跳出函數
return;
else { // 否則交換父子內容再繼續子節點和孫節點比較
swap(&arr[dad], &arr[son]);
dad = son;
son = dad * 2 + 1;
}
}
}
void heap_sort(int arr[], int len) {
int i;
// 初始化,i從最後一個父節點開始調整
for (i = len / 2 - 1; i >= 0; i--)
max_heapify(arr, i, len - 1);
// 先將第一個元素和已排好元素前一位做交換,再重新調整,直到排序完畢
for (i = len - 1; i > 0; i--) {
swap(&arr[0], &arr[i]);
max_heapify(arr, 0, i - 1);
}
}
void swap(int& i, int& k) {
int tmp = k;
k = i;
i = tmp;
}
void heapAdjust(int arr[], int num, int arrsize) {
int pos = num;
for (int j = 2 * num + 1; j < arrsize; j = j * 2 + 1)
{
if (j < arrsize - 1 && arr[j] < arr[j + 1])
{
j++;
}
if (arr[pos] < arr[j])
{
break;
}
else {
arr[num] = arr[j];
num = j;
}
}
arr[num] = arr[pos];
}
void heapSort2(int arr[], int arrsize) {
for (int i = arrsize / 2 - 1; i >= 0; i--) // n/2-1 is previous root dot
{
heapAdjust(arr, i, arrsize);
}
for (int i = arrsize - 1; i >= 0; i--)
{
swap(arr[0], arr[i]);
heapAdjust(arr, 0, i);
}
}
void heapify(int arr[], int arrsize, int num) {
int lowest = num;
int lchild = 2 * num + 1; //lchild
int rchild = 2 * num + 2; //rchild
if (lchild < arrsize && arr[lchild] > arr[lowest])
{
lowest = lchild;
}
if (rchild < arrsize && arr[rchild]> arr[lowest])
{
lowest = rchild;
}
if (lowest != num)
{
swap(arr[num], arr[lowest]);
heapify(arr, arrsize, lowest);
}
}
// 0
// 1 2
// 3 4 5 6
//7 8 9 10 11 12 13 14
void heapSort(int arr[], int arrsize) {
for (int i = arrsize / 2 - 1; i >= 0; i--) // n/2-1 is previous root dot
{
heapify(arr, arrsize, i);
}
for (int i = arrsize - 1; i >= 0; i--)
{
swap(arr[0], arr[i]);
heapify(arr, i, 0);
}
}
- 归并排序
void MSort(int* data,int start, int end) {
int size = end - start;
if (size <= 1) {
return;
}
if (size >= 2) {
int m = (end + start) / 2;
int h1 = m - start;
int h2 = end - m;
if (h1 >= 2) {
MSort(data, start, m);
}
if (h2>=2) {
MSort(data, m, end );
}
int* tmp = new int[size];
int i = start;
int k = 0;
int j = m;
for (; i < m &&j <end; k++) { //why "i < m, j <end " is error?
if (data[j] < data[i]) {
tmp[k] = data[j];
j++;
}
else {
tmp[k] = data[i];
i++;
}
}
if (i != m) {
for (int n = i; n < m; n++,k++) {
tmp[k] = data[n];
}
}
if (j != end) {
for (int n = j; n < end; n++,k ++) {
tmp[k] = data[n];
}
}
for (int l = start,k = 0; l < size; l++,k ++) {
data[l] = tmp[k];
}
delete tmp;
}
return;
}
int mergeSort(int* data, int size) {
if (size <= 1) {
return 0;
}
MSort(data, 0, size);
return 0;
}
测试3轮4096个随机整数,上述8中排序算法的时间对比:
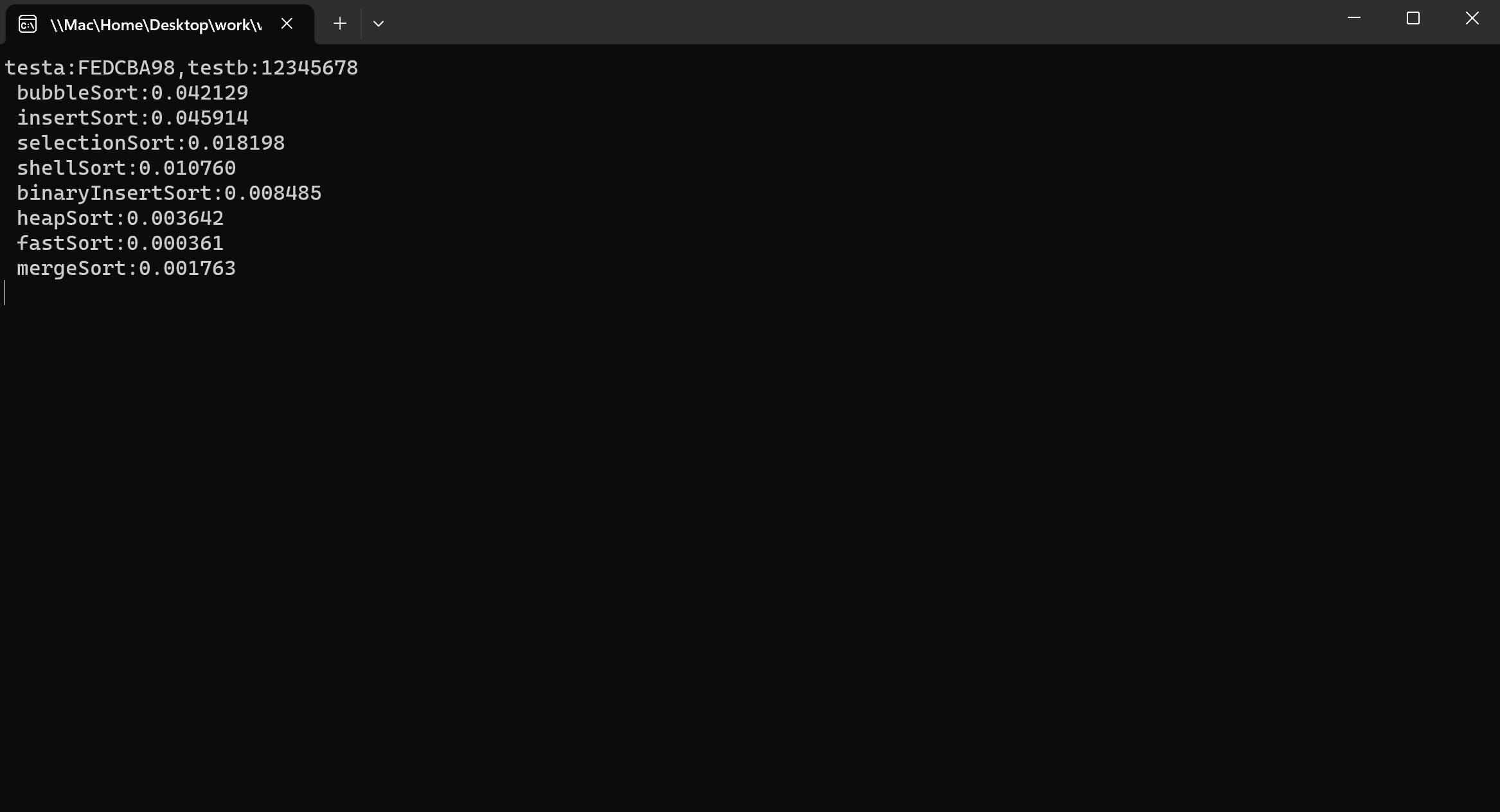
测试3轮65536个随机整数,上述8中排序算法的时间对比: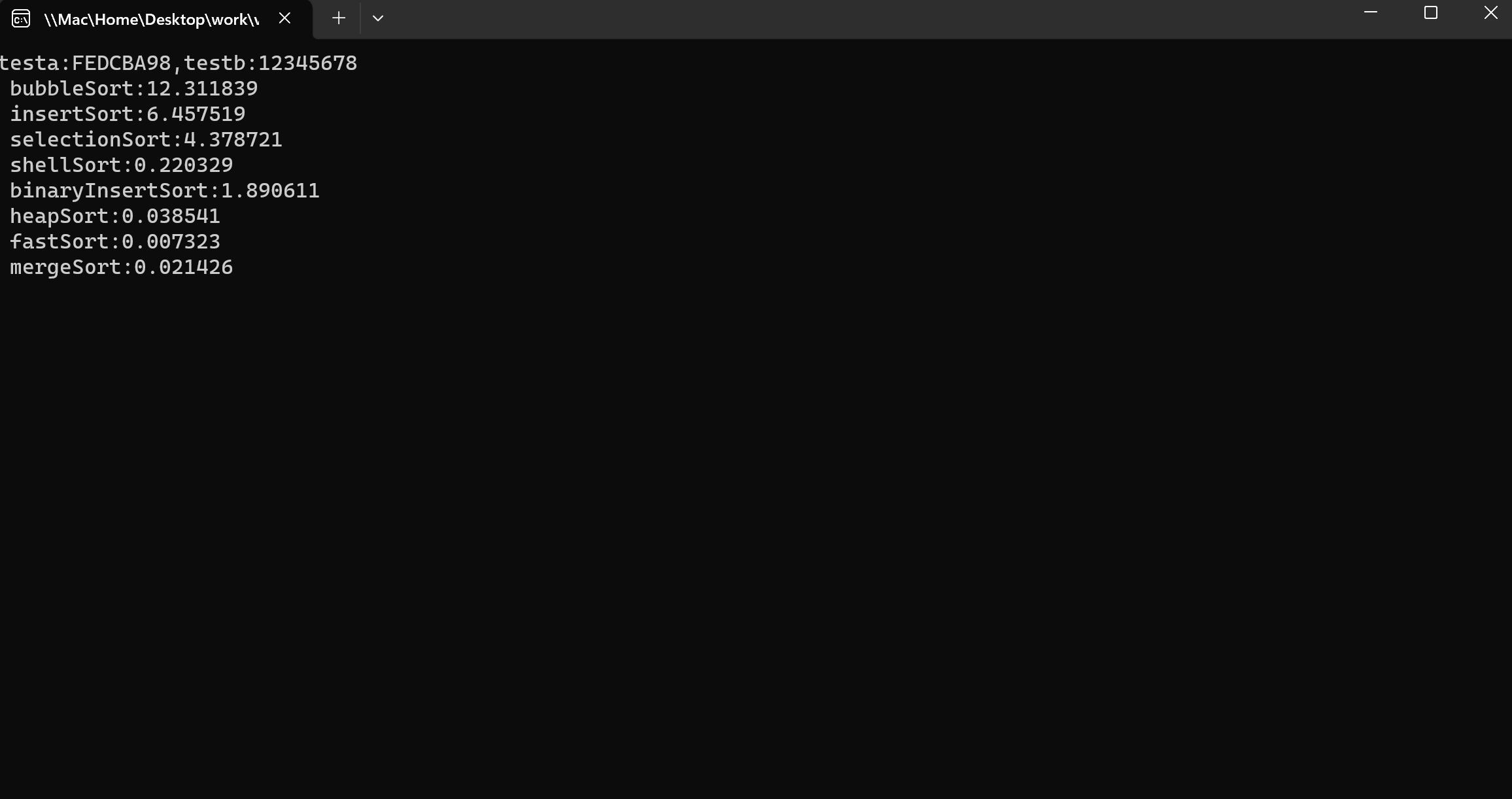
几点体会:
- 先进的排序算法中,快速排序 > 归并排序 > 堆排序。
快速排序未优化,优化后速度还会更快,归并排序没想到会比堆排序更快,主要的原因是快速排序和归并排序对缓存cache友好。实际上,这三种算法,堆排序不需要额外的内存地址,内存开销最小,算法理论也最先进,但是其不支持cpu缓存,导致对于连续内存地址的排序,效果大打折扣。相反的,快速排序和归并排序,可以充分利用计算机的cpu缓存机制,将速度优化到极限,非常适合计算机中连续内存地址的数据排序。但是,这并不能说明堆排序一无是处,恰恰相反,因为测试用例使用的int型数组,所以在这里堆排序的劣势被无限放大了。实际上计算机的内存操作大部分是指针操作,这种情况下,cpu缓存机制是失效的,这种情况下的堆排序无疑是最好的排序算法。
-
普通排序算法中,选择排序 > 插入排序 > 冒泡排序 。
-
快速排序是冒泡排序的1000倍。也就说,排序算法对数据量比较大的情况大,所起的作用是非常关键的。
-
希尔排序和二分插入排序是对普通排序的改进,总体效率接近先进排序。 希尔排序 > 二分插入排序 。
工程项目地址:https://github.com/satadriver/dataStruct


分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐
 0
0 0
0- 0


 已为社区贡献1条内容
已为社区贡献1条内容
 OpenCV
OpenCV
所有评论(0)