用python实现chatgpt的联网功能
本文主要提供了如果获取谷歌API和搜索引擎ID,以及利用langchain和爬虫结合实现联网功能
chatgpt的联网功能
前置准备
一个谷歌账号
由于本项目调用的是谷歌浏览器的接口,所以必须要申请一个谷歌账号
一个chatgpt的API key
这个可点击获取API key这个链接,登录对应的gpt账号即刻获取。 点击里面的Create new secret key即可新建, 记得新建的key一定要保存好,他只能在新建时查看一次,以后就再也不能查看的,忘记的就只能再新建一个
具体页面如下:

python环境
python环境最低要求必须支持langchain框架,
需要用到的库有,langchain, request, re, bs4等
设置谷歌Json API
首先,我们调用谷歌搜索的api需要用到两个变量,一个是谷歌搜索引擎的API key,另一个自定义搜索引擎的ID
接下来我将说明如何获取这两个值
首先是谷歌的API key
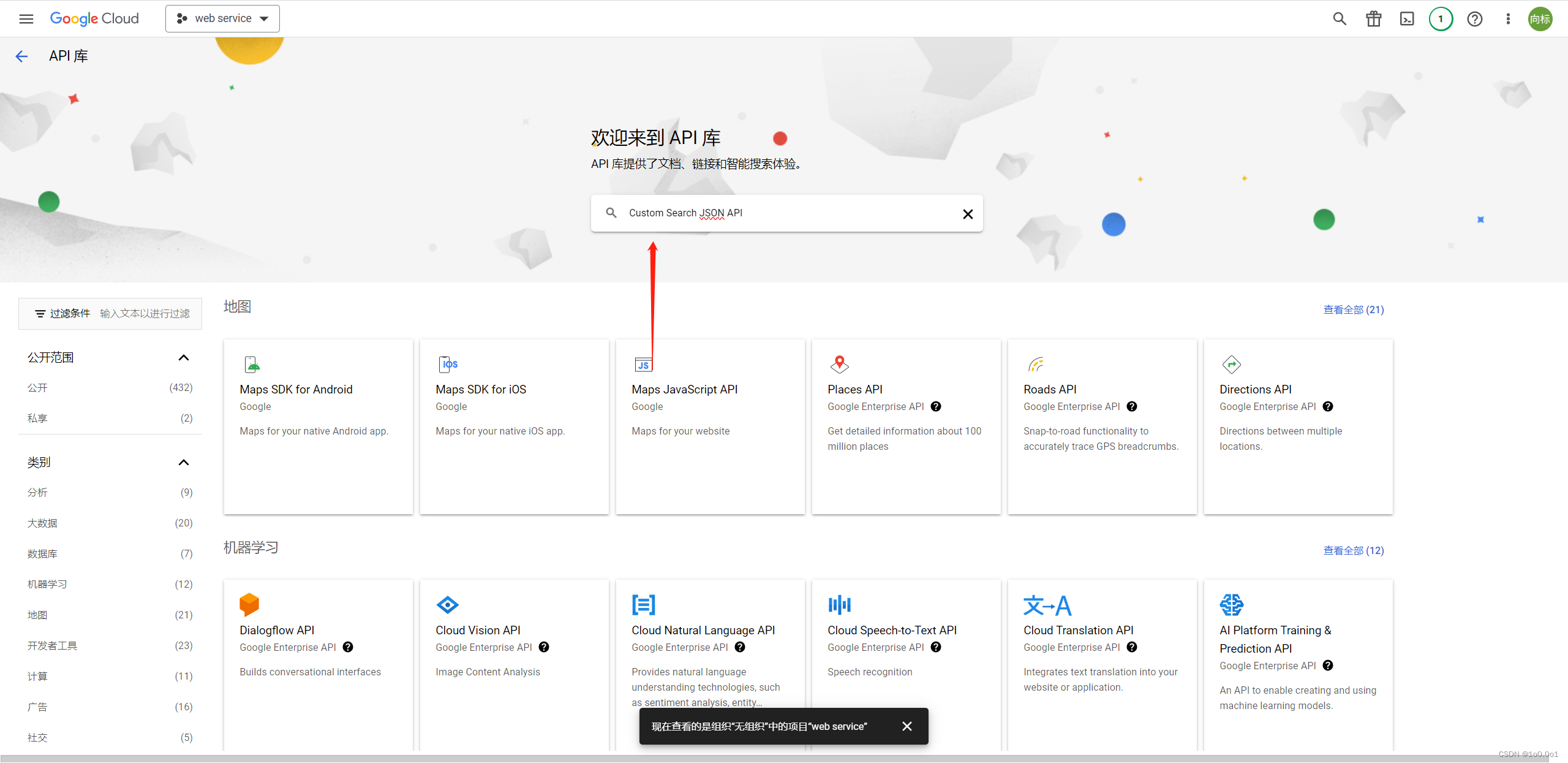
点击这个链接,进入谷歌的API服务中心,然后新建一个项目,这里点击上面的web service,这个是我创建的项目的名字,正常情况为空,可以自己创建一个项目


这里名字随便写,然后创建
接着,点击左侧的库,搜索Custom Search JSON API
进入Custom Search JSON API页面,并点击启用

之后回到开始页面,点击左侧的凭证,然后点击“创建凭据”并选择“API 密钥”。


这时候就能获取你谷歌的API key了

得到后先把它保存下来,接着我们获取个人引擎的ID
访问可编程搜索引擎管理页面,创建一个新的搜索引擎或选择一个现有的搜索引擎。在搜索引擎设置页面中,找到“搜索引擎ID”并复制它

这里记得创建时要选择在整个网络中搜索
创建后点击这个引擎,一进去就可以看见你的ID了

获取这两个后就可以开始我们代码编写了,需要注意的是,这个谷歌的JSON API 每天只有100次免费调用的额度,超过需要收费,调用需求大的可以考虑多建立几个谷歌账号,获取它们对应的ID和key然后循环使用
编写代码
我们整个代码的思路为:
用户输入问题->调用gpt接口过滤一些无关信息->调用谷歌搜索引擎->得到对应的标题和网站->采用爬虫获取对应的内容->调用gpt接口回答问题
配置环境变量
在这里设置你的代理
import os
os.environ['HTTP_PROXY'] = "127.0.0.1:you proxy port"
os.environ['HTTPS_PROXY']="127.0.0.1:you proxy port"
调用gpt接口来过滤信息
def fitter_inner(query):
# 配置环境变量
import os
os.environ['HTTP_PROXY'] = "127.0.0.1:you proxy port"
os.environ['HTTPS_PROXY']="127.0.0.1:you proxy port"
os.environ["OPENAI_API_KEY"]="you-api-key"
# 定义聊天模板
from langchain.prompts import ChatPromptTemplate
prompts ="""
你现在是一个问题提取机器人,现在我会给你一段文本,这段文本是用户输入给你的内容,这段内容可能会有一些混淆
的信息,你要做的就是提取里面可能需要联网才能查询到的信息出来,并且返回......(后面自己完善,建议加点例子)
(这一部分如果你懂langchain框架,可以自行修改,不懂建议不要改)
接下来是用户输入的内容:
{query}
返回格式为:
{response_schemas}
"""
ChatPrompt = ChatPromptTemplate.from_template(prompts)
# 定义返回格式
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
result_schema = ResponseSchema(name='result',
description="返回一个字符串,这个字符串表示的是真正需要联网的功能")
response_schemas = [result_schema]
out_parse = StructuredOutputParser(response_schemas=response_schemas)
format_instructions = out_parse.get_format_instructions() # format_instructions就是我们的格式
# 定义gpt模型和生成链
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
llm = ChatOpenAI(model_name="gpt-3.5-turbo-16k", temperature=0)
chain = LLMChain(llm=llm, prompt=ChatPrompt)
# 调用链
result = chain.run(query=query, response_schemas=format_instructions)
return out_parse.parse(result)
调用方法为:
question = """
123+ee42
广东天气怎样
"""
query = fitter_inner(question)
print(query)
这里的query返回值应该是一个json数据格式,你想获取直接的值的话,可通过query[‘result’]来获取
配置谷歌浏览器接口变量
# Google搜索函数
def google_search():
# 你的API密钥和自定义搜索引擎ID
api_key = "之前获取的谷歌API key"
cse_id = "之前获取的个人搜索引擎key"
url = "https://www.googleapis.com/customsearch/v1"
params = {
"q": query,
"key": api_key,
"cx": cse_id
}
response = requests.get(url, params=params)
return response.json()
通过这个json接口返回的是一个带有浏览器搜索的一个标题和链接,如下图

通过爬虫获取信息
接下来就要提取这些信息,并通过爬虫获取这些信息
def extract_content(self, query):
#这里调用了上面的谷歌接口
results = self.google_search(query)
inner = []
# 提取指定数量的链接的信息
for item in results["items"][:self.num_links]:
url = item['link']
try:
timeout_seconds = 10
# 使用requests库获取链接的内容,并设置超时时间
response = requests.get(url, timeout=self.timeout_seconds)
# 检查是否成功获取
if response.status_code == 200:
# 获取字符编码
encoding = response.encoding if 'charset' in response.headers.get('content-type', '').lower() else None
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.content, 'html.parser', from_encoding=encoding)
# 使用get_text()方法提取所有文本内容
text_content = soup.get_text()
# 对文本进行加工处理
cleaned_text = self.clean_text(text_content)
inner.append(cleaned_text)
# 打印提取的文本内容
else:
print(f"无法访问网页:{url}")
except requests.Timeout:
print(f"请求超时,超过了{self.timeout_seconds}秒的等待时间。链接:{url}")
return inner
def clean_text(self, text):
# 使用正则表达式替换连续的空白字符为单个空格
return re.sub(r'\s+', ' ', text).strip()
这样就能获取全部的内容了,如果考虑到gpt的api接口可能会有tokens限制,可以自行修改代码,让他能够人为的进行控制,具体代码我稍后会发在另一篇文章中
将获取的信息输入给gpt
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
os.environ["OPENAI_API_KEY"]="you-api-key"
llm = ChatOpenAI(temperature=0.7, model_name='gpt-3.5-turbo-16k')
prompt = """
现在你是一个问答机器人,我会给你一段来自互联网的文本,你根据这段文本和用户的问题来进行回答,如果文本提供的内容回答不了用户的问题,那么则回答我无法提供正确的回答
网络资料:
------------------------------------------
{inner}
-------------------------------------------
用户问题:
--------------------------------------------
{question}
---------------------------------------------
"""
prompts = PromptTemplate.from_template(prompt)
chain = LLMChain(llm=llm, prompt = prompts)
print(chain.run(question=query, inner = '\n'.join(inner)))
最后就可以得到结果:

完整代码
import requests
import re
from bs4 import BeautifulSoup
import time
class GoogleSearchExtractor:
def __init__(self, api_key, cse_id, num_links=3, timeout_seconds=10):
self.api_key = api_key
self.cse_id = cse_id
self.num_links = num_links
self.timeout_seconds = timeout_seconds
def google_search(self, query):
url = "https://www.googleapis.com/customsearch/v1"
params = {
"q": query,
"key": self.api_key,
"cx": self.cse_id
}
response = requests.get(url, params=params)
return response.json()
def clean_text(self, text):
# 使用正则表达式替换连续的空白字符为单个空格
return re.sub(r'\s+', ' ', text).strip()
def extract_content(self, query):
results = self.google_search(query)
inner = []
# 提取指定数量的链接的信息
for item in results["items"][:self.num_links]:
url = item['link']
try:
# 使用requests库获取链接的内容,并设置超时时间
response = requests.get(url, timeout=self.timeout_seconds)
# 检查是否成功获取
if response.status_code == 200:
# 获取字符编码
encoding = response.encoding if 'charset' in response.headers.get('content-type', '').lower() else None
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.content, 'html.parser', from_encoding=encoding)
# 使用get_text()方法提取所有文本内容
text_content = soup.get_text()
# 清理文本
cleaned_text = self.clean_text(text_content)
inner.append(cleaned_text)
# 打印提取的文本内容
else:
print(f"无法访问网页:{url}")
except requests.Timeout:
print(f"请求超时,超过了{self.timeout_seconds}秒的等待时间。链接:{url}")
return inner
# 使用示例
api_key = ""
cse_id = ""
query = "今天广东天气怎样"
extractor = GoogleSearchExtractor(api_key, cse_id)
inner = extractor.extract_content(query)
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
import os
os.environ["OPENAI_API_KEY"]="you-api-key"
llm = ChatOpenAI(temperature=0.7, model_name='gpt-3.5-turbo-16k')
prompt = """
现在你是一个问答机器人,我会给你一段来自互联网的文本,你根据这段文本和用户的问题来进行回答,如果文本提供的内容回答不了用户的问题,那么则回答我无法提供正确的回答
网络资料:
------------------------------------------
{inner}
-------------------------------------------
用户问题:
--------------------------------------------
{question}
---------------------------------------------
"""
prompts = PromptTemplate.from_template(prompt)
chain = LLMChain(llm=llm, prompt = prompts)
print(chain.run(question=query, inner = '\n'.join(inner)))
这个是不调用过滤的情况下,如果需要过滤的话,请自行将上面处理过滤信息的代码添加进去
以上就是利用python实现chatgpt联网功能的代码了,如果有好的建议欢迎在评论区留言

分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)