菜鸟也能快速搭建属于自己的大模型平台——千帆大模型平台
收集人类反馈奖励模型训练强化学习训练RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习),一种机器学习方法,它使智能系统能够从环境中学习并最大化特定目标。在RLHF中,通过对同一输入的多个生成结果进行人工排序,获得包含人类偏好反馈的标注数据,从而训练出一个奖励模型(Reward Model)。在强化学习的过程中,奖励模型将对大语言
1.示例目标
本文通过千帆大模型平台来搭建一个属于自己的知识搜索平台,让我们能快速的搜索到我们想到的内容。

2.前置环境需求
我们先需要去官网注册,环节也就是身份验证一下,用手机验证扫一下脸就完事,很快的。
千帆大模型平台登录入口:
https://console.bce.baidu.com/iam/#/iam/baseinfo
注册完成后我们去体验【文心一言】。
千帆大模型平台官网:https://cloud.baidu.com/product/wenxinworkshop?track=ae35a3396ecb3afe68e19773b574a198d1e6a9ce0382e4f3
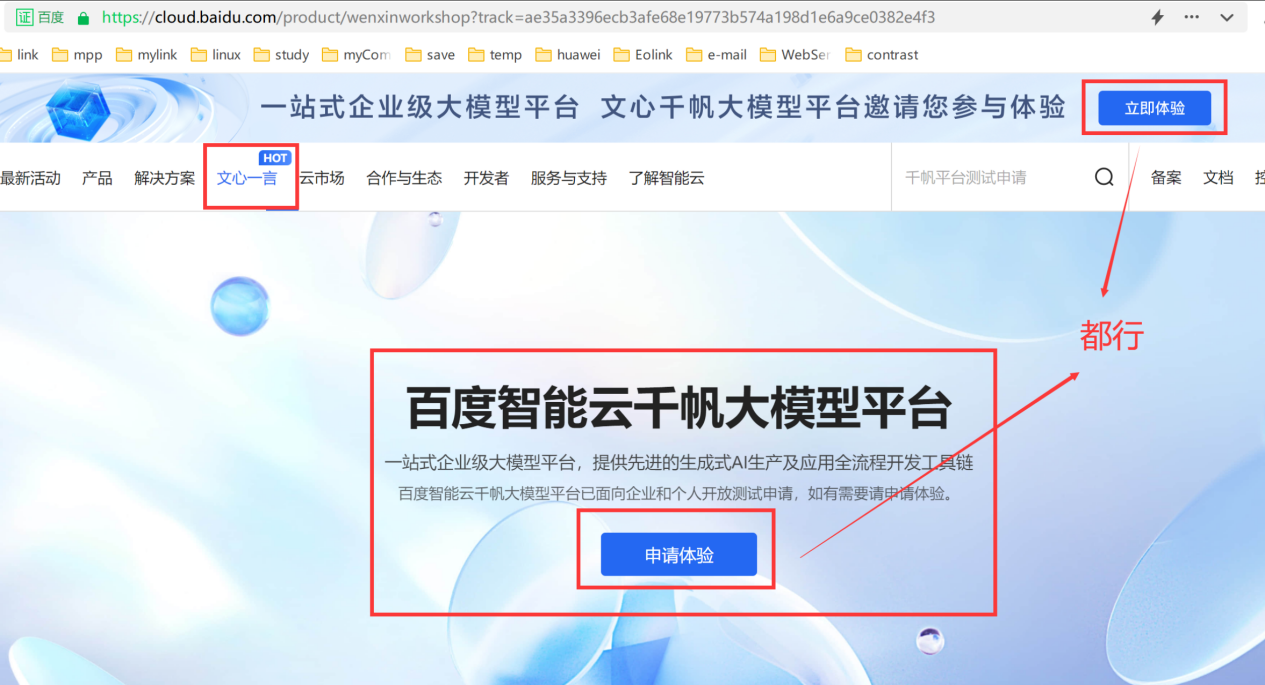
这里需要申请一下,使用咱们自己公司的名称与需求点填写对应内容即可。
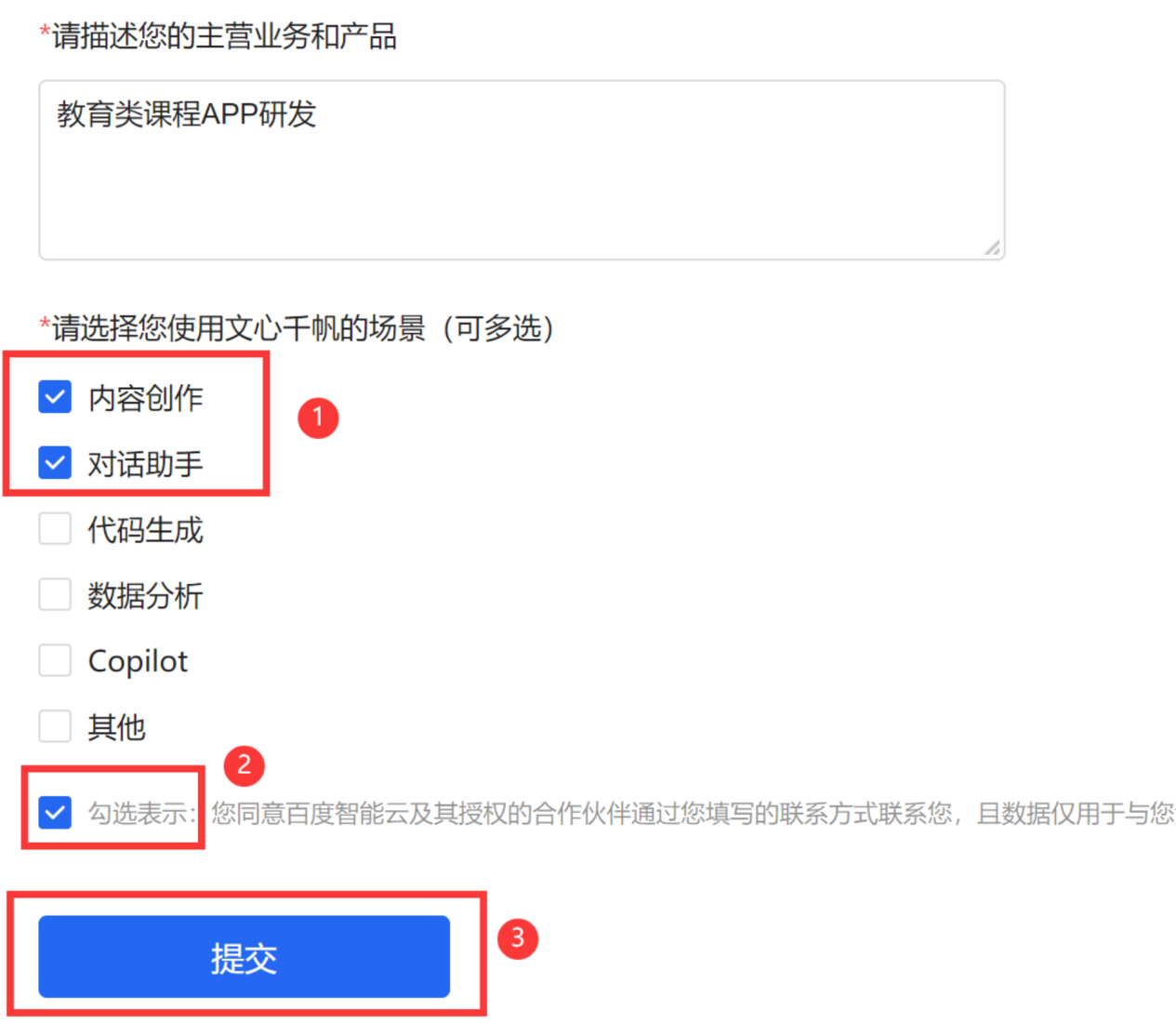
例如我的公司是做科技教育类产品的,我测试的目标场景也就是【内容创作】与【对话助手】
审核的时间比较快,去吃个饭回来也就可以用了。


吃个饭会来刷新一下,你就能看到下面的效果了。

使用文档:什么是千帆大模型平台 - 千帆大模型平台 | 百度智能云文档
文档给的也是比较详细的,也针对各类模型与训练都做了说明。就拿【什么是RLHF训练】来说,我们看看对应的解释详情。
3.什么是RLHF训练
RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习),一种机器学习方法,它使智能系统能够从环境中学习并最大化特定目标。在RLHF中,通过对同一输入的多个生成结果进行人工排序,获得包含人类偏好反馈的标注数据,从而训练出一个奖励模型(Reward Model)。在强化学习的过程中,奖励模型将对大语言模型的多个生成结果的排序进行判定。最终,强化学习通过更新大模型的参数,使得输出结果符合奖励模型的判定要求。这种方法减轻了传统强化学习中需要大量试错的问题,也降低了完全依赖于人工对所有大模型生成结果进行排序调整反馈的成本,使得智能系统更加高效、快速地学习任务。
RLHF已成功应用于百度智能云千帆大模型平台, 能够生成类似人类的文本并执行各种语言任务。RLHF使模型能够在大量文本数据语料库上进行训练,并在复杂的语言任务(如语言理解和生成)上取得令人印象深刻的结果。
RLHF的成功取决于人类提供的反馈的质量,根据任务和环境,反馈的质量可能是主观的和可变的。因此,开发有效且可扩展的收集和处理反馈的方法非常重要。
总的来说,RLHF 比传统的机器学习和强化学习提供了更多的指导,能够捕捉到人类偏好的全部内容,从而驱使人工智能系统与人类价值观相一致。即使 RLHF 不能完全解决对内部调整的担忧,它所识别的失败以及它赋予奖励和政策模型的知识也适用于提高社会和合作环境中人工智能的安全性、可靠性和可信度。
3.1 收集人类反馈
收集人类反馈为RHLF的基础步骤,千帆平台接入多轮对话-排序类和prompt语料数据集,作为奖励模型和强化模型训练的人类反馈。这部分内容主要产生两类模型:
- 预训练模型:只经过语料库训练而未经过fine-tune的模型;
- 监督基线模型:在预训练模型基础上使用测试数据集的fine-tune模型。
在初始模型被训练之后,人类训练者提供对模型表现的反馈。他们根据质量或正确性排名不同的模型生成的输出或行为。这些反馈被用来创建强化学习的奖励信号。
3.2 奖励模型训练
奖励模型(Reward Model, RM)训练的最终目的是刻画模型的输出是否在人类看来表现不错:
输入【提示(prompt),模型生成的文本】,输出表明文本质量的标量数字。
奖励模型接收一系列文本并返回标量的奖励值,数值和人类的偏好相对应。您可以采用端对端的方式用大语言模型建模,或者用模块化的系统建模(如对输出进行排名,再将排名转换为奖励)。奖励数值将用于接入强化模型训练中。
关于千帆的更多操作步骤详细可见奖励模型训练。
3.3 强化学习训练
强化学习(Reinforcement Learning, RL)又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。至少需要以下三个基本要素:
- 策略(policy):基于该语言模型,接收prompt作为输入,然后输出一系列文本(或文本的概率分布)。
- 动作空间(action space):词表所有token在所有输出位置的排列组合(单个位置通常有50k左右的token候选)。
- 奖励函数(reward):基于奖励模型计算得到初始reward,再叠加上一个约束项。
代理(agent)通过与环境的交互来学习策略。代理采取行动(含无动作行动),这些行动会影响代理所处的环境,而环境进而转换到新的状态并返回奖励。奖励是使强化学习代理能够调整其行动策略的反馈信号,当代理进行训练时,它会调整自己的策略,并采取一系列行动,使其回报最大化。
4.示例实操
下面是我整个的完整示例演示,分为模型prompt预制模板选择、应用接入、在线测试三个步骤。
4.1 预制模型
可以在模型仓库中看到很多的【预制模型】包括Llama 2全系列、ChatGLM2-6B、RWKV-4-World、MPT-7B-Instruct、Falcon-7B等
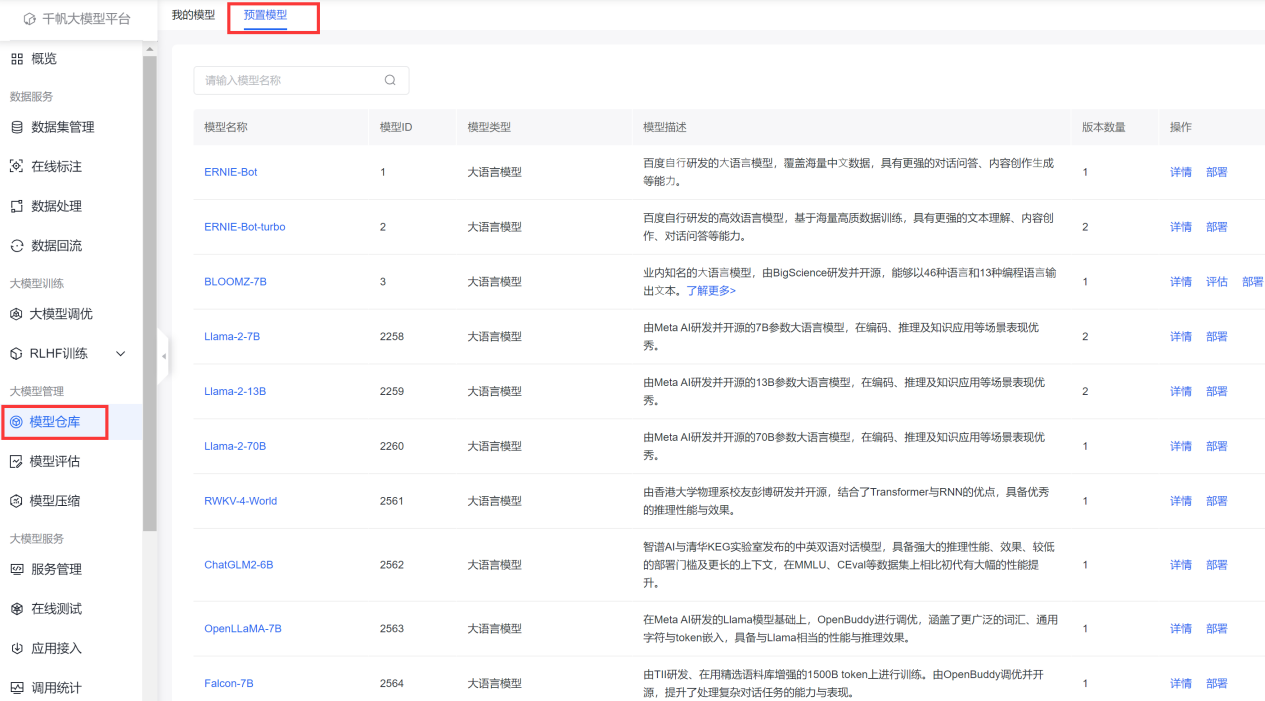
再向下拉动可以看到prompt预制模板。
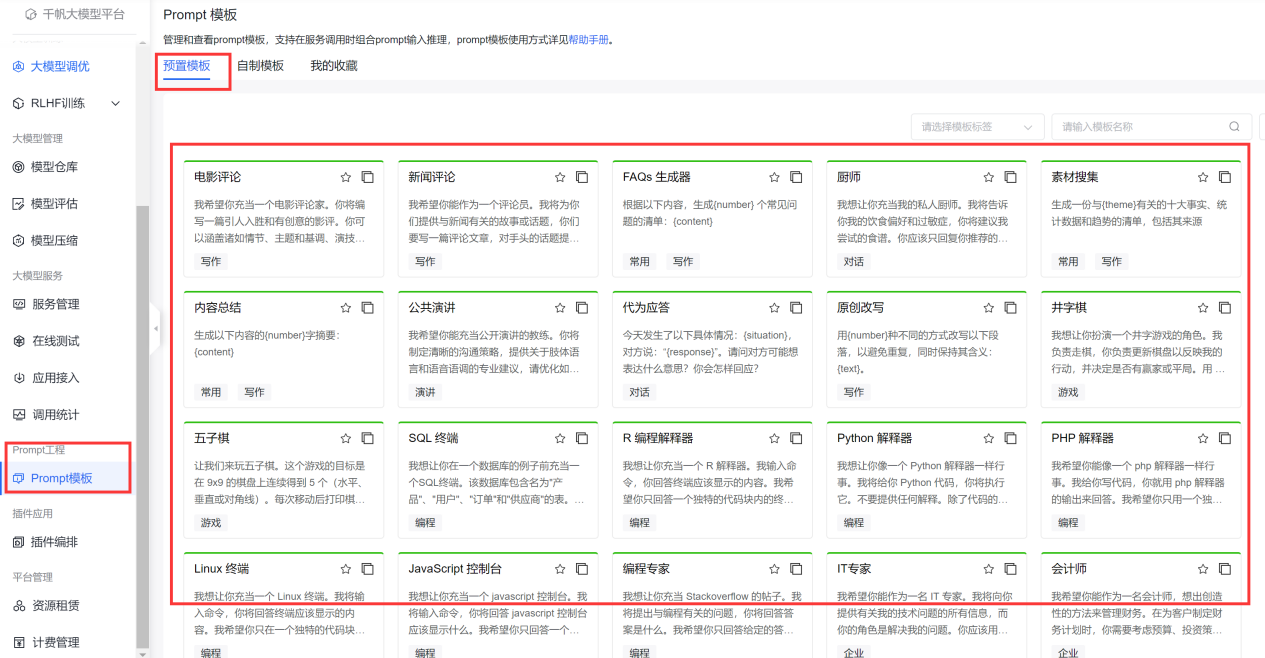
为什么使用prompt预制模型,因为,免费啊。
4.1.1 创建自定义模板
这里我们用【素材收集】来举例,点击这个对应的Prompt模板,保存至【自制模板】即可。
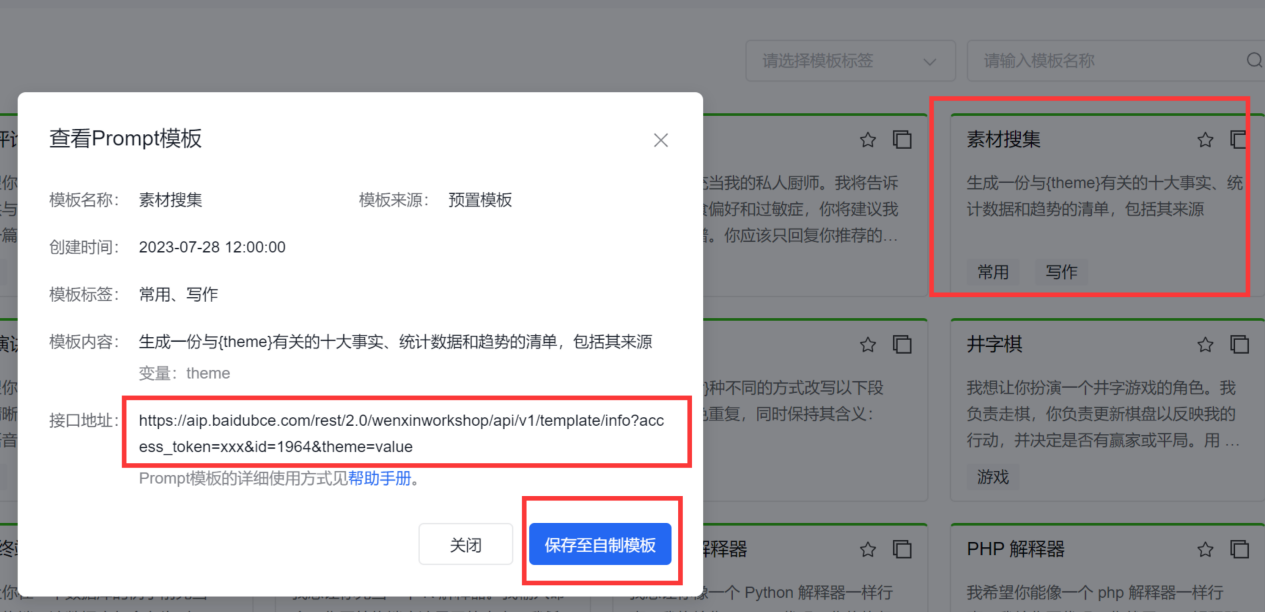
可以看到有接口地址,但是这里需要使用【access_token】才能用,所以我们需要https://ai.baidu.com/ai-doc/REFERENCE/Ck3dwjhhu这篇文章来告诉大家如何来获取它。
4.1.2 获取 Access_token
百度AI开放平台使用OAuth2.0授权调用开放API,调用API时必须在URL中带上Access_token参数,获取Access_token的流程如下:
请求URL数据格式
向授权服务地址https://aip.baidubce.com/oauth/2.0/token发送请求(推荐使用POST),并在URL中带上以下参数:
- grant_type: 必须参数,固定为client_credentials;
- client_id: 必须参数,应用的API Key;
- client_secret: 必须参数,应用的Secret Key;
我这里稍微改了一下,可以看到对应的效果:
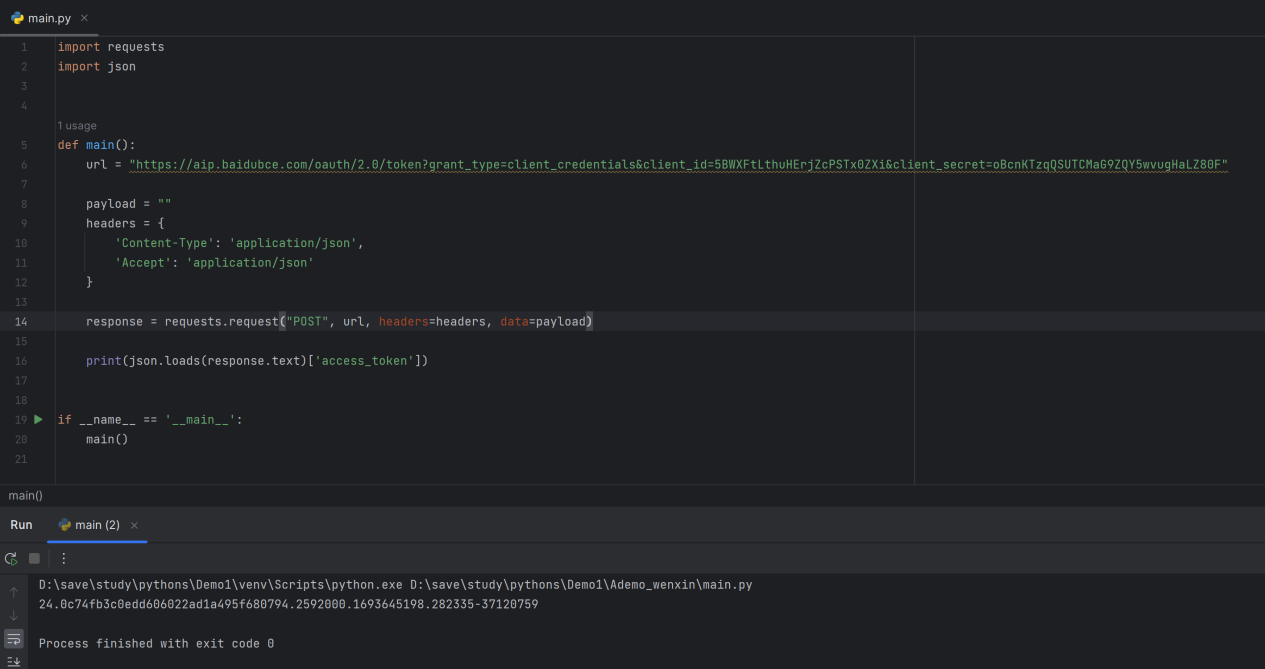
这个是访问效果

可以确定这个Access_token绝对是正确的。源码在下面。
Python
import requests
import json
def main():
"""
注意更换自己的appKey和selectKey
:return:
"""
url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=5BWXFtLthuHErjZcPSTx0ZXi&client_secret=oBcnKTzqQSUTCMaG9ZQY5wvugHaLZ80F"
payload = ""
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(json.loads(response.text)['access_token'])
if __name__ == '__main__':
main()创建自定义模板
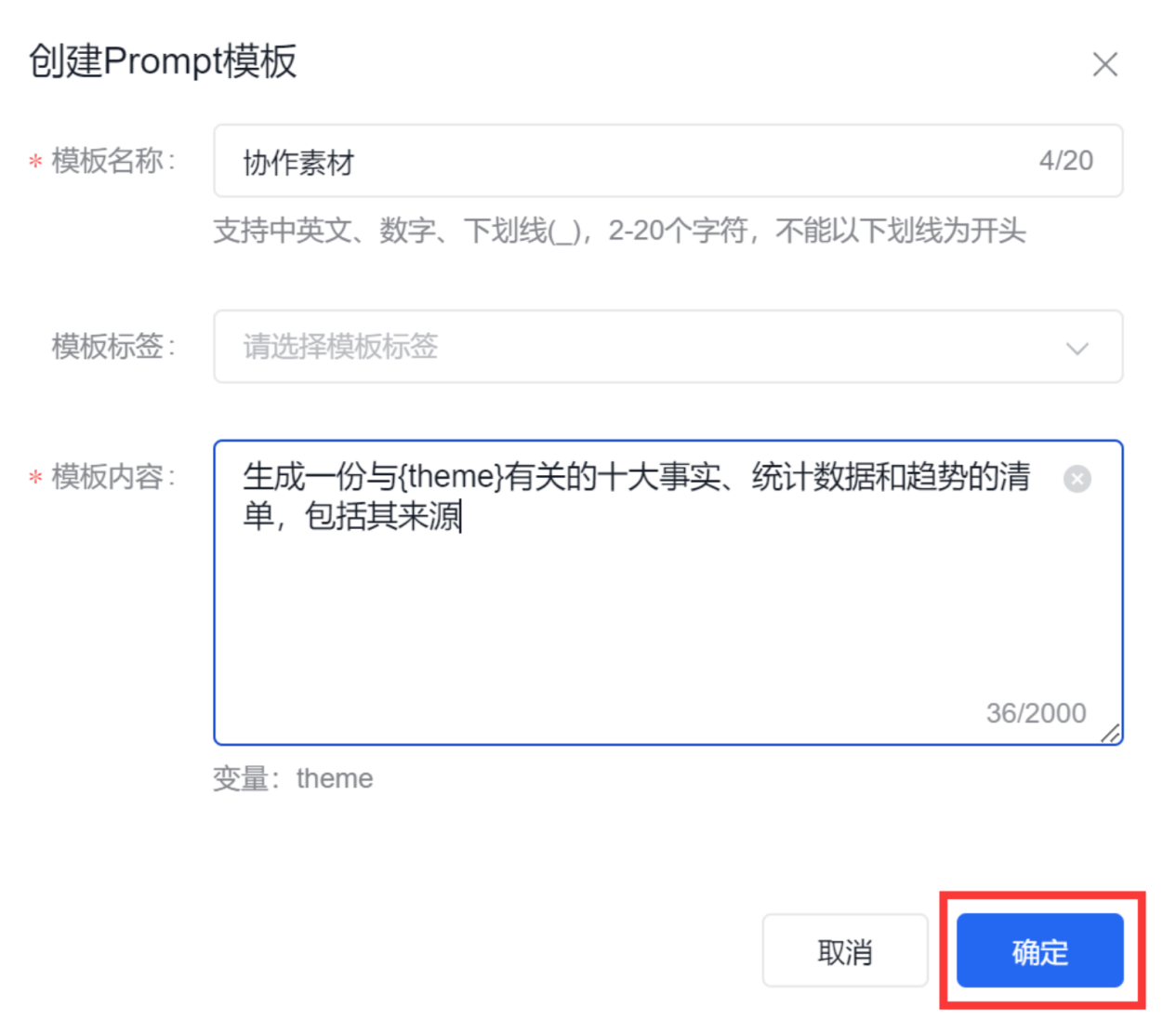
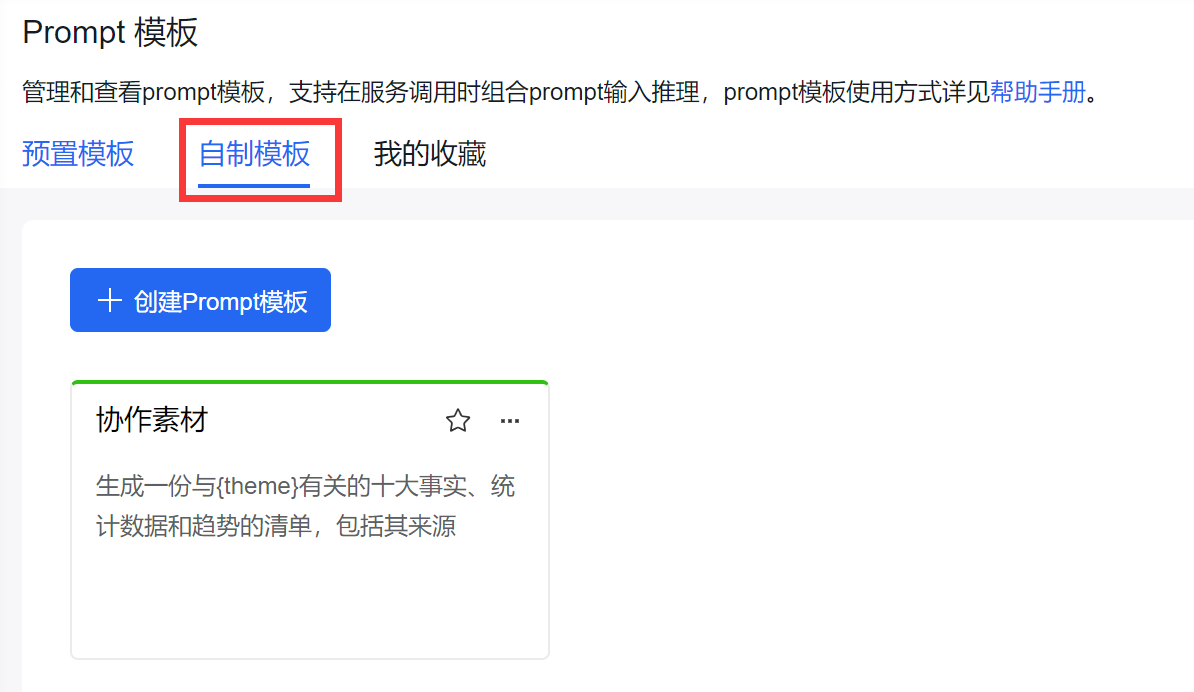
这里创建完毕后会显示在【自定义模板里】
4.2 应用接入
这个步骤直接在左侧菜单中选择【应用接入】,创建一个应用,添加上基本信息什么的即可。
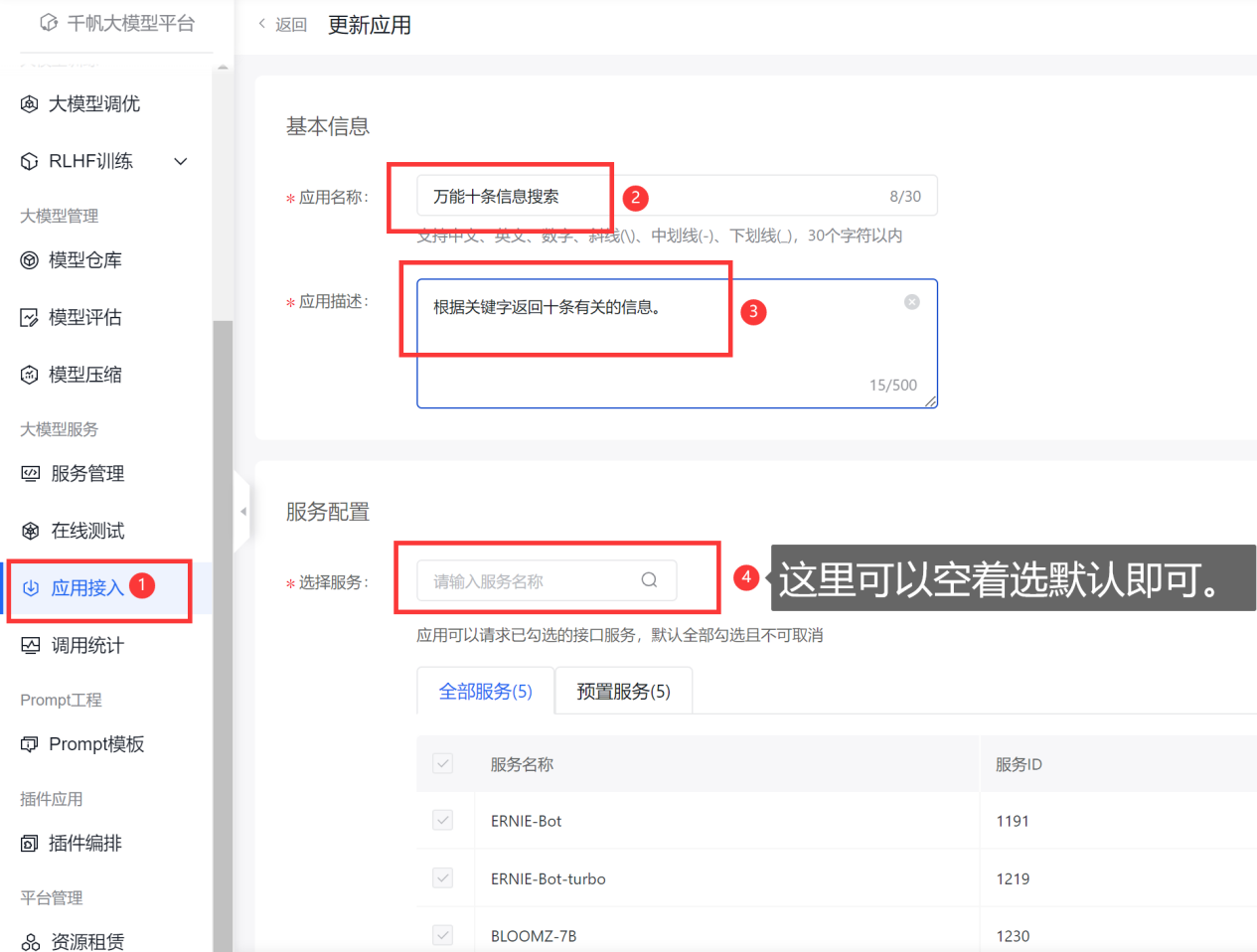
创建效果

4.3 在线测试
我们已经准备好了prompt预制模型以及应用,接下来我们在左侧的菜单中直接选择【在线测试】,按照下图进行操作即可。
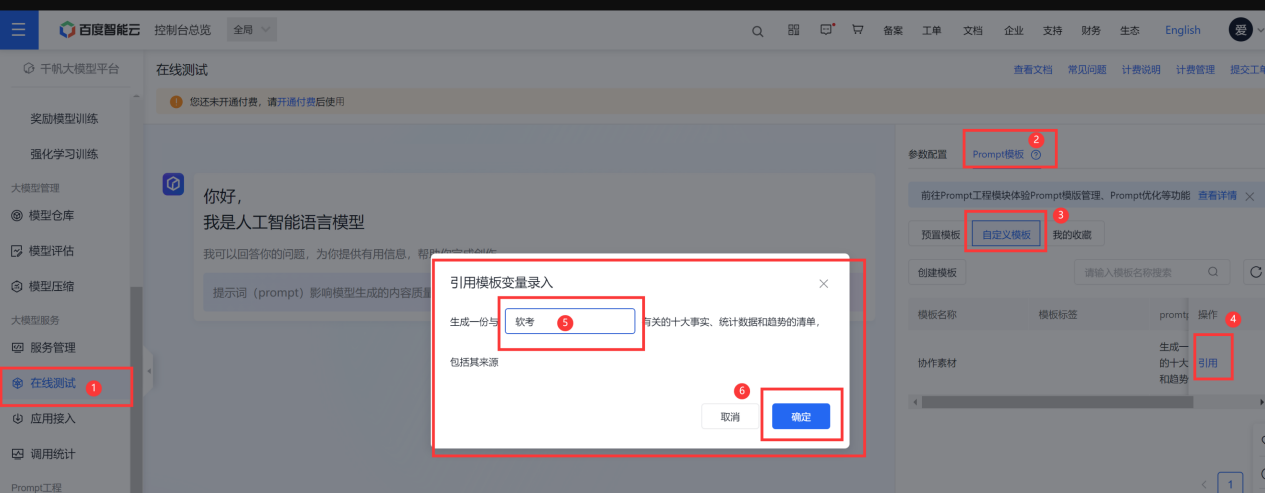
发送测试

在上图就可以看到我们的目标结果了,我们可以测试其它的内容都是可以的。
5.完整调用代码
这里需要提换自己的信息哦。
Python
import requests
import json
def access_token():
"""
注意更换自己的appKey和selectKey
:return:
"""
url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={appKey}&client_secret={selectKey}"
payload = ""
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
return json.loads(response.text)['access_token']
res = access_token()
html = requests.get(
"https://aip.baidubce.com/rest/2.0/wenxinworkshop/api/v1/template/info?access_token={0}&id=1964&theme=LK-99".format(
res))
ret = json.loads(html.text)["result"]["content"]
content_info = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/eb-instant?access_token=" + res
payload = json.dumps({
"messages": [
{
"role": "user",
"content": ret
}
]
})
headers = {
'Content-Type': 'application/json'
}
resp = requests.request("POST", content_info, headers=headers, data=payload)
print(resp.text)6.测试结果:
我测试的是LK-99材料的搜索,希望这个材料是真的。

用python我这里比较方便,如果要创建自己的接口用java也一样。
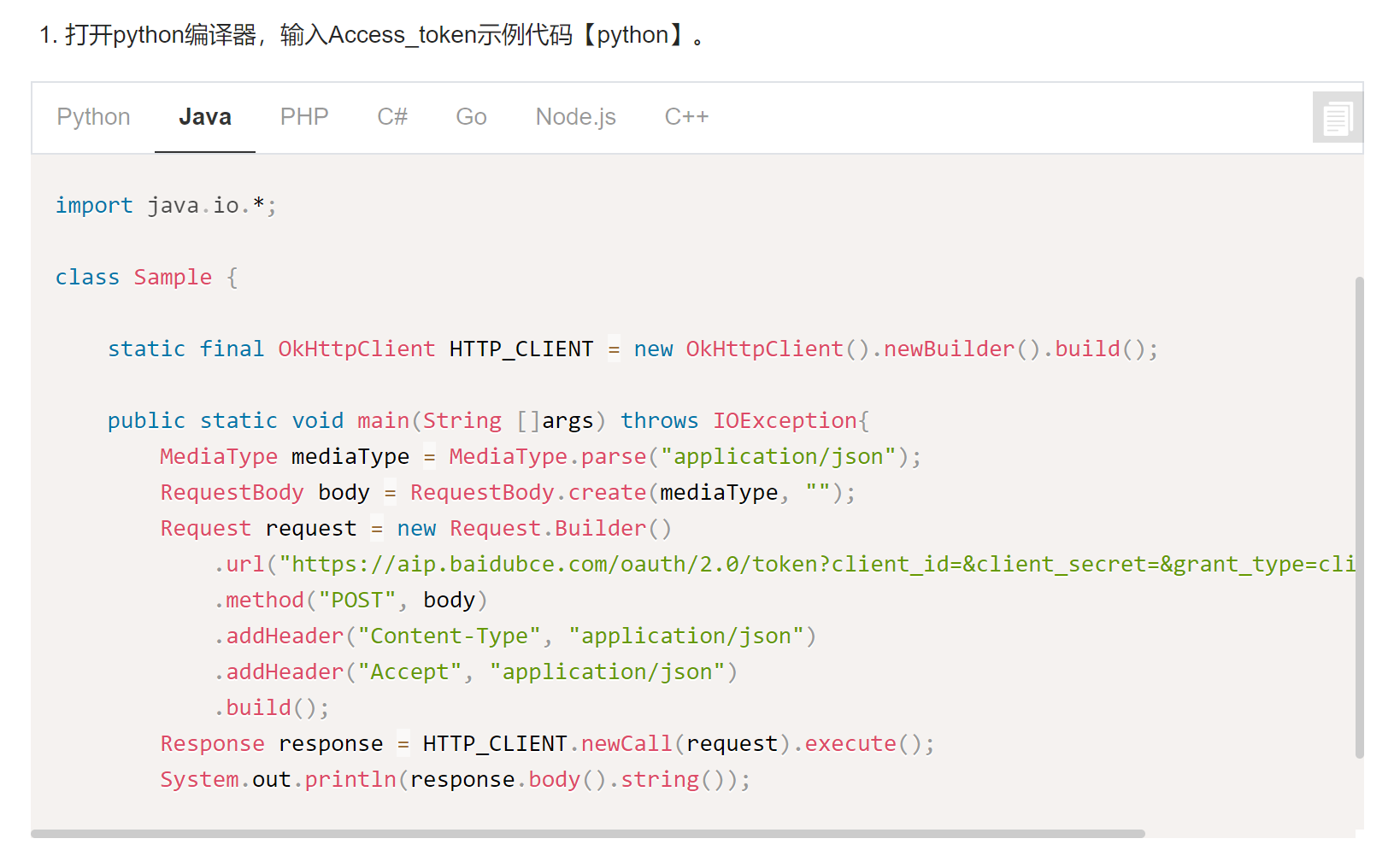
可以看到,提供了Java对应access_token的获取方法了。
7.总结
我所有的测试创建与测试时间加在一起也就一个小时左右,如果说纯使用,大概十来分钟,中间对RLHF训练的理解以及其它功能的查阅上消耗了一些时间,如果操作熟练一些,算一下,大概接出来一个文心的chat接口大概需要时间是20分钟足够,包含搭建springboot的时间。
祝大家在后面的工作中能通过千帆大模型平台的支持下都能升职加薪哦。

欢迎加入西安开发者社区!我们致力于为西安地区的开发者提供学习、合作和成长的机会。参与我们的活动,与专家分享最新技术趋势,解决挑战,探索创新。加入我们,共同打造技术社区!
更多推荐



 64
64 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)